
DeepSeek-V4即将发布,海外热议!同时V3.2版本也在悄悄更新!
【摘要】近期AI大模型领域动态频频:Claude4.5和Gemini3即将发布,但焦点集中在DeepSeek系列。DeepSeek-V3.2模型卡在HuggingFace反复出现又消失,引发开发者关注;更重磅的是网传10月发布的DeepSeek-V4将支持1MTokens上下文窗口,采用GRPOTurbo多步思考模式,并提升推理效率。文章同时对比了Qwen与DeepSeek在技术路线上的相似性,如
经典的假期搞事情,真不让放假啊!!?😠
Qwen 的疯狂发布的余温还在呢,我还没测完呢……
俺来帮你列列最近的消息:
-
Claude 4.5 即将在 1~2 周内到来;
-
Gemini 3 将在咱国庆左右发布;
-
DeepSeek-V4 将在 10 月发布;
-
DeepSeek-V3.2 的模型卡已经被创建。
前两条,已经炒了很久了,有点审美疲劳,今天的重点不在于它们(不值得让我为它们专门写一篇招“黑粉”的爆料新闻)
我们将聚焦于 DeepSeek-V4 和 DeepSeek-V3.2 的爆料信息与来源。
⚠️ 注:我们将在模型正式发布时第一时间更新文章,期待您的关注。
首先,我们先来说说 DeepSeek-V3.2。
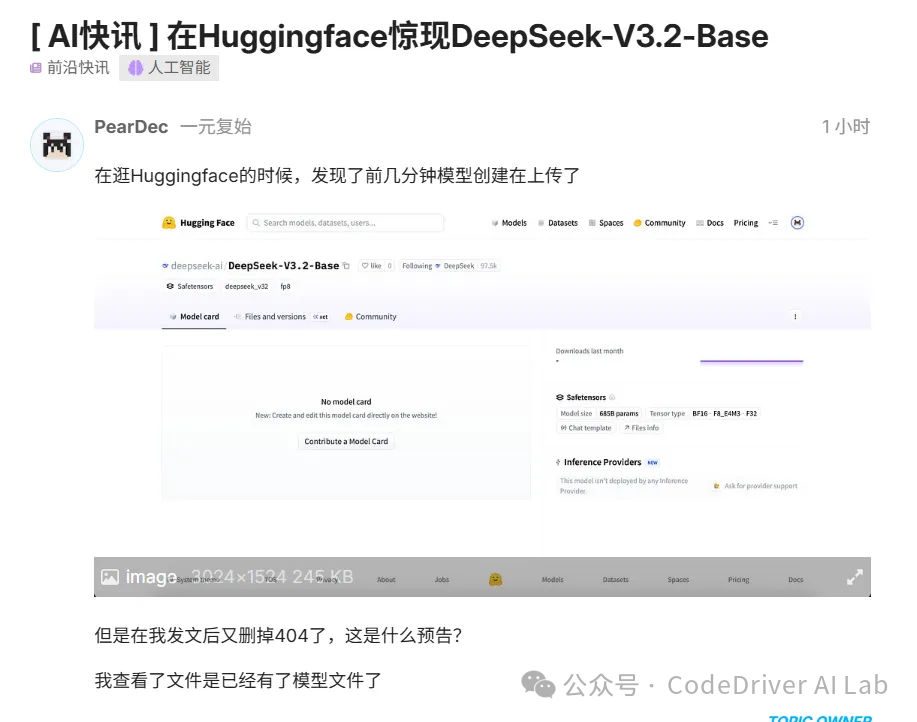
我得知到这条消息来自于网友关注到 DeepSeek 官方在抱脸(HuggingFace)平台上偷偷上传了名为 DeepSeek-V3.2-Base 的模型卡。
随后我也持续跟进该模型卡的状态;
从创建到删除404,一个下午应该重复了三四次。开发者们也为此抓狂……
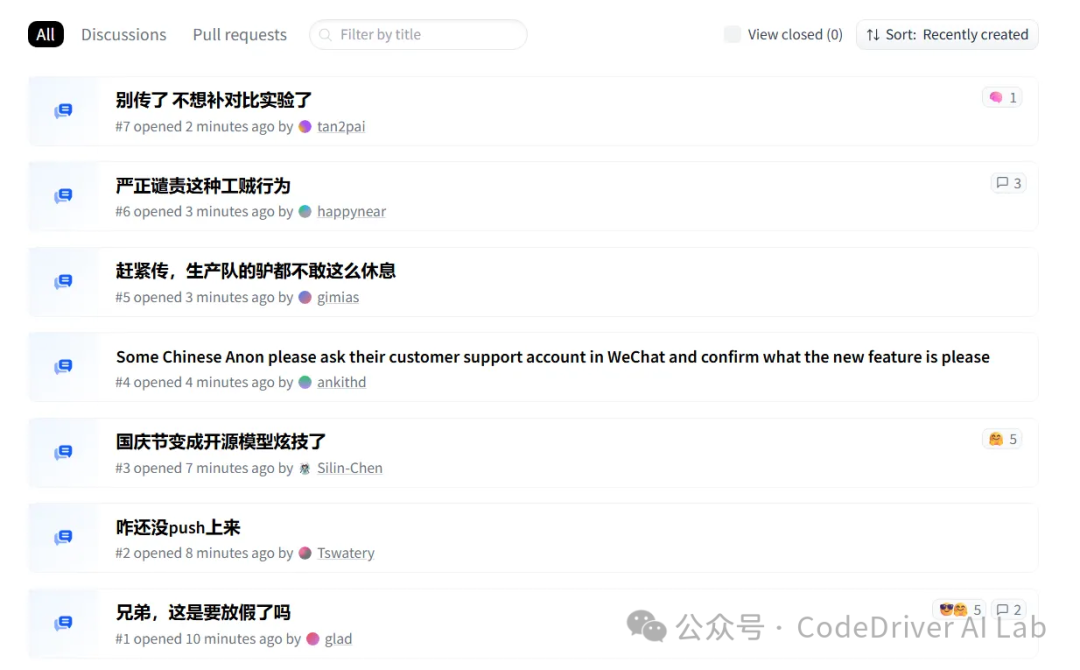
小编认为,V3.2 还是非常值得期待的。
至少相较于最近几份爆料信息来说,它是一个实打实的“官方”爆料。
但也有可能,是在为 V4 预预热?
这倒像是 OpenAI 的风格……

此外,刚刚官方也发布公告宣布更新,但似乎只是一次小更新,还不是V3.2?

再来看看 DeepSeek V4,它来源于 X 上 DeepSeek 社区内的爆料。
网传,DeepSeek V4 将在十月发行,并具备极其强悍的性能。
是的,它不只是数字更大了,也不是模型参数更大了。
而是:
拥有 1M Tokens 的上下文窗口;
GRPO Turbo 无缝切换多步思考模式;
更快+更便宜的推理效率。
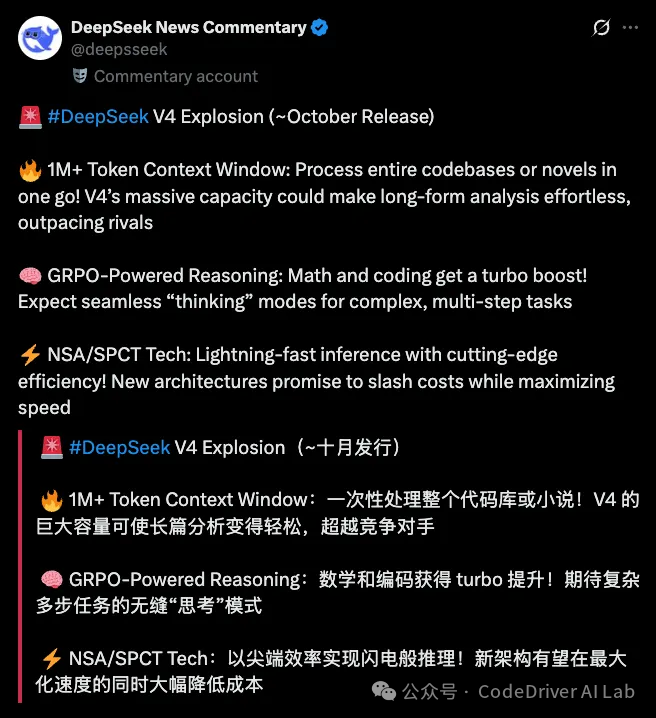
后两条在 DeepSeek V4 版本上还是非常可信的。
从 23 年以来,Qwen 和 DeepSeek 似乎就有千丝万缕的联系。
例如,GRPO 算法在 2024 年初就随着 DeepSeekMath 一同发布,而在年中的 Qwen2-Math 也同时借用了 GRPO 以提升模型在数学任务的推理能力。
那时,GRPO 还没有开源。
当然,不排除 Qwen 直接根据论文公式进行复现的可能。(因为我当时也想做同样的事情)
当时,我还特地到开发群咨询了当时 DeepSeek 的关键开发者,她直接告诉了我一条“简单”路径:
说远了…… 回到正题。
总之,不知道你有没有和我一样的印象。Qwen 和 DeepSeek 在技术路线上,好像都很相近。
而在前段时间,Qwen 也发布了他们主打训推性价比的模型:Qwen3-Next。
而在 Qwen 3 的整个 MoE 模型体系上,也采用了原生稀疏注意力(NSA),以解决 LLM 在处理长序列时面临的计算量和内存占用过大的问题。
具体来说,传统的注意力机制需要计算序列中每个词(Token)与所有其他词之间的关系,其计算复杂度会随着序列长度的平方 (O(n2)) 增长,这导致了模型在处理长文本时变得非常低效和昂贵。
而 NSA 正是引入了“稀疏性”来优化这一过程,它不再计算所有词之间的关系,而是有选择性地计算一部分最重要的关系,从而显著降低计算和内存需求。
更多关于 NSA 的内容等发布那天再来细讲吧,我让 Gemini 简单说了下,感兴趣的可以看看~

那么,长上下文,也变得理所应当了。
毕竟,Qwen 最近也在主打长上下文嘛……
此外,它会开源吗?
会的!
好了,以上就是所有相关信息啦,感兴趣的同学可以通过以下链接找到更多相关信息噢~
AI大模型从0到精通全套学习大礼包
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
只要你是真心想学AI大模型,我这份资料就可以无偿共享给你学习。大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
如果你也想通过学大模型技术去帮助就业和转行,可以点扫描下方👇👇
大模型重磅福利:入门进阶全套104G学习资源包免费分享!
01.从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点
02.AI大模型学习路线图(还有视频解说)
全过程AI大模型学习路线

03.学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

04.大模型面试题目详解


05.这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
所有的视频由智泊AI老师录制,且资料与智泊AI共享,相互补充。这份学习大礼包应该算是现在最全面的大模型学习资料了。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
更多推荐
 5
5 0
0- 0



 已为社区贡献170条内容
已为社区贡献170条内容

所有评论(0)