
2025年主流大语言模型与多模态大模型技术全景
本文全面剖析2025年主流大语言模型(LLM)和多模态大模型的技术架构、工作原理及发展趋势。涵盖GPT系列、Claude、Gemini、LLaMA等核心模型,深入探讨Transformer架构演进、多模态融合技术等关键技术突破。
·
发布日期:2025年9月30日
摘要
本文全面剖析2025年主流大语言模型(LLM)和多模态大模型的技术架构、工作原理及发展趋势。涵盖GPT系列、Claude、Gemini、LLaMA等核心模型,深入探讨Transformer架构演进、多模态融合技术等关键技术突破。
1. 2025年大语言模型生态全景
1.1 模型家族技术路线图
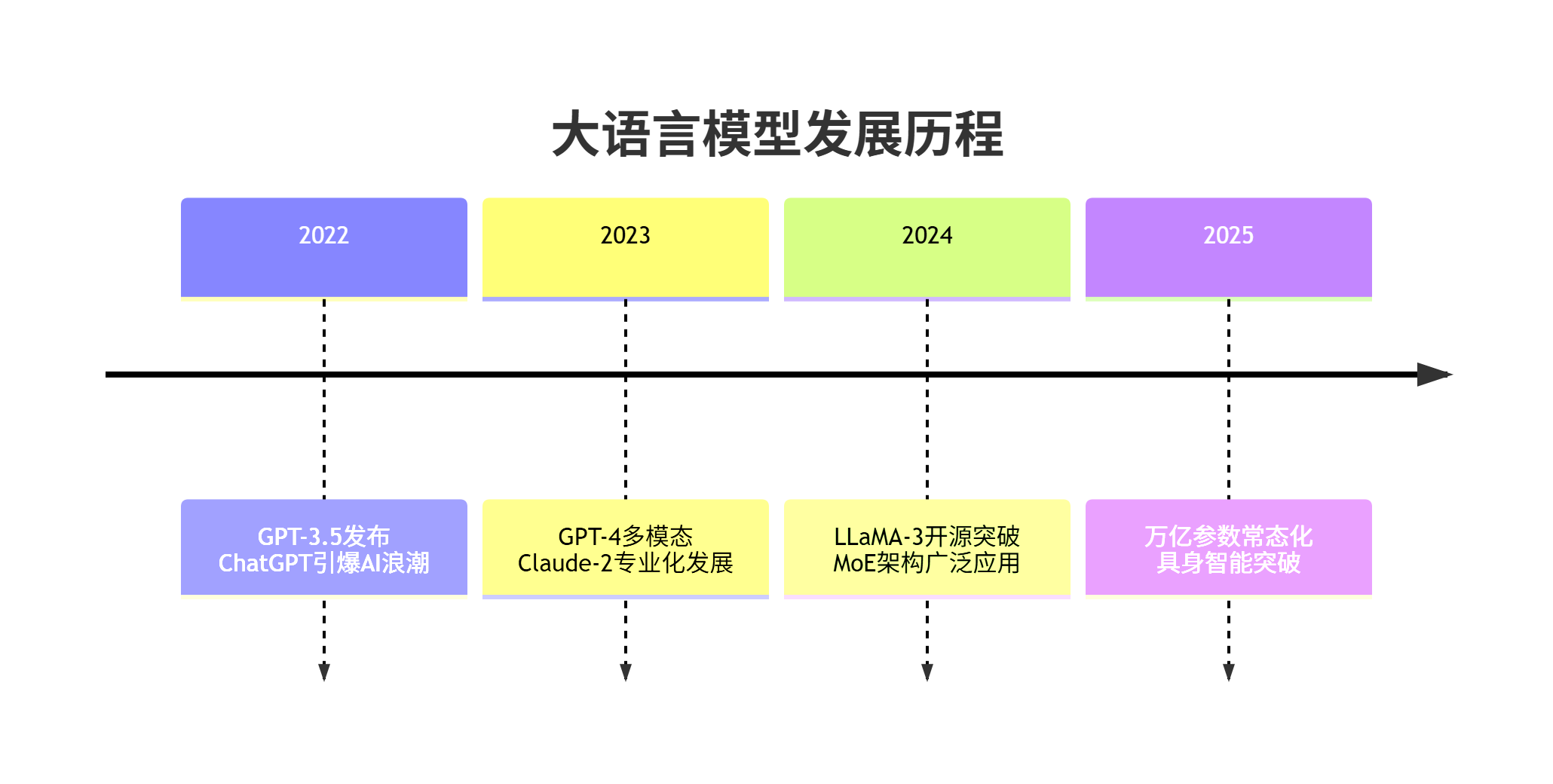
1.2 2025年主流模型对比
|
模型系列 |
开发商 |
参数量 |
特色技术 |
主要应用 |
|---|---|---|---|---|
|
GPT-5系列 |
OpenAI |
1.8T |
递归Transformer |
通用AI助手 |
|
Claude-3.5 |
Anthropic |
800B |
宪法AI |
安全敏感场景 |
|
Gemini 2.0 |
1.2T |
多模态原生 |
跨模态推理 |
|
|
LLaMA-4 |
Meta |
700B |
开源MoE |
企业定制 |
|
文心4.0 |
百度 |
900B |
知识增强 |
中文场景 |
2. 核心架构技术深度解析
2.1 Transformer架构演进
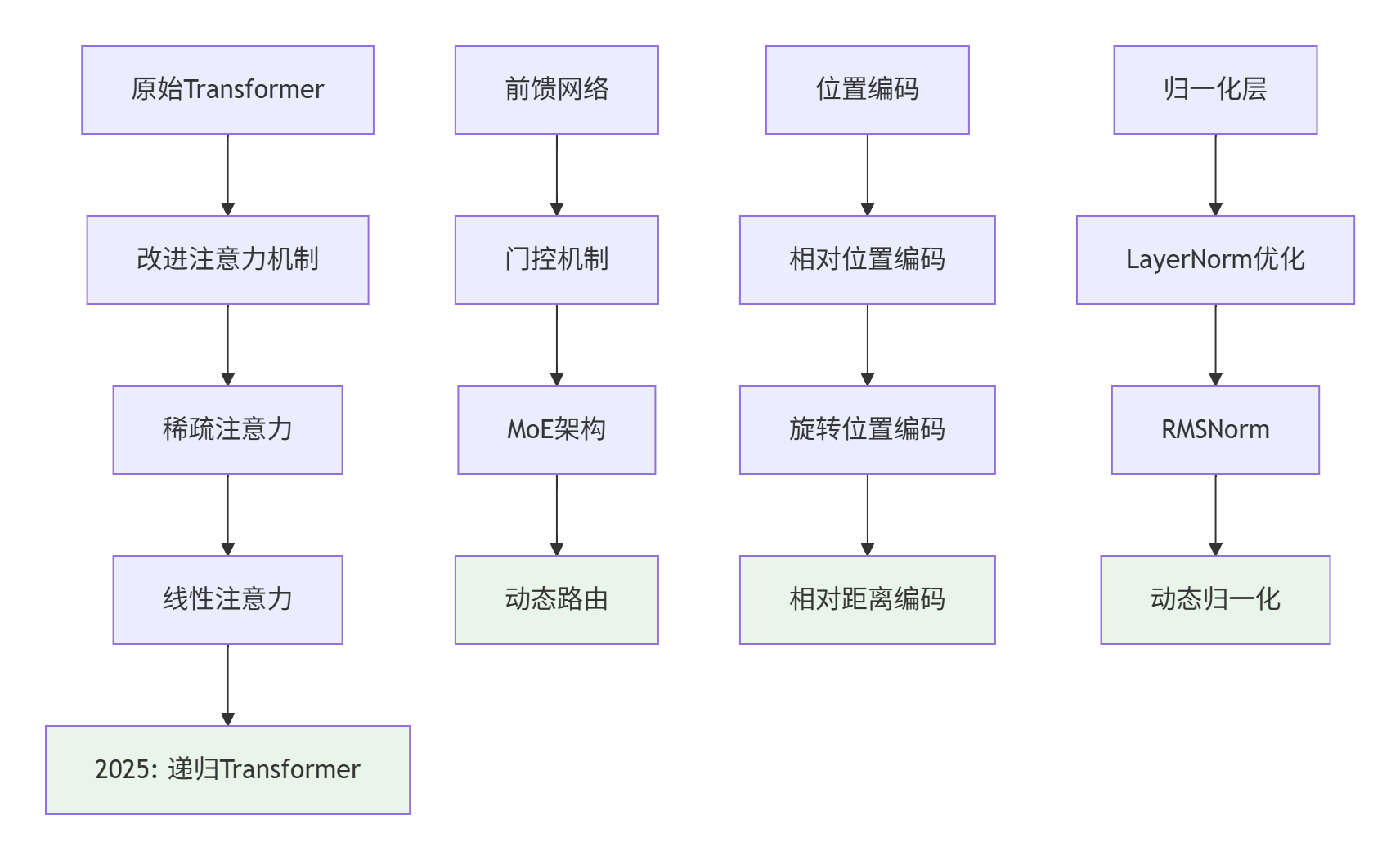
2.1.1 递归Transformer代码实现
class RecursiveTransformerBlock(nn.Module):
def __init__(self, dim, num_heads, recursive_depth=3):
super().__init__()
self.recursive_depth = recursive_depth
self.layers = nn.ModuleList([
TransformerLayer(dim, num_heads)
for _ in range(recursive_depth)
])
self.state_compressor = StateCompressor(dim)
def forward(self, x, previous_states=None):
"""递归Transformer前向传播"""
current_states = []
for i in range(self.recursive_depth):
# 融合之前的状态信息
if previous_states and i < len(previous_states):
state_input = self.state_compressor(
x, previous_states[i]
)
else:
state_input = x
x = self.layers[i](state_input)
current_states.append(x)
return x, current_states
class StateCompressor(nn.Module):
def __init__(self, hidden_dim):
super().__init__()
self.attention = nn.MultiheadAttention(hidden_dim, 8)
self.compressor = nn.Sequential(
nn.Linear(hidden_dim * 2, hidden_dim),
nn.GELU(),
nn.Linear(hidden_dim, hidden_dim)
)
def forward(self, current, previous):
# 跨时间步注意力机制
attended, _ = self.attention(current, previous, previous)
compressed = self.compressor(torch.cat([current, attended], dim=-1))
return compressed2.2 混合专家模型(MoE)架构
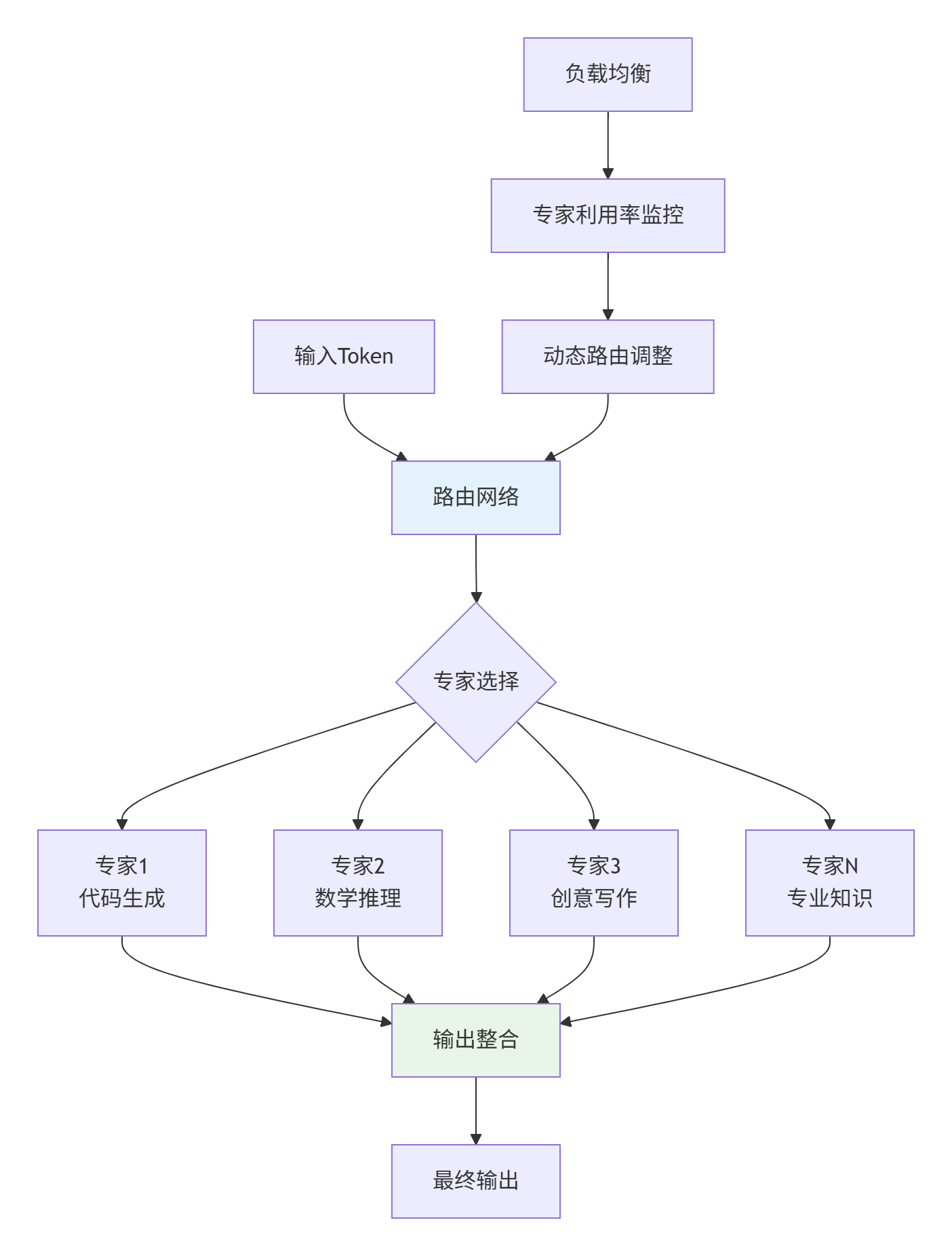
2.2.2 MoE路由算法实现
class AdaptiveMoELayer(nn.Module):
def __init__(self, num_experts, expert_capacity, hidden_size):
super().__init__()
self.num_experts = num_experts
self.expert_capacity = expert_capacity
self.hidden_size = hidden_size
# 专家网络池
self.experts = nn.ModuleList([
ExpertNetwork(hidden_size) for _ in range(num_experts)
])
# 门控路由网络
self.gate = nn.Sequential(
nn.Linear(hidden_size, num_experts * 4),
nn.GELU(),
nn.Linear(num_experts * 4, num_experts),
nn.Softmax(dim=-1)
)
# 负载均衡损失
self.balance_loss = ExpertBalanceLoss()
def forward(self, x, aux_loss_weight=0.01):
batch_size, seq_len, hidden_dim = x.shape
# 计算路由权重
gate_logits = self.gate(x) # [batch, seq_len, num_experts]
# Top-k专家选择 (k=2)
topk_weights, topk_experts = torch.topk(gate_logits, k=2, dim=-1)
topk_weights = torch.softmax(topk_weights, dim=-1)
# 创建专家分配掩码
expert_mask = torch.zeros(
batch_size, seq_len, self.num_experts,
device=x.device
)
# 将token分配给专家
outputs = torch.zeros_like(x)
aux_loss = 0
for expert_idx in range(self.num_experts):
# 选择分配给当前专家的token
expert_positions = (topk_experts == expert_idx).any(dim=-1)
if not expert_positions.any():
continue
expert_input = x[expert_positions]
# 容量限制:选择前k个token
if expert_input.shape[0] > self.expert_capacity:
expert_scores = gate_logits[expert_positions, expert_idx]
_, indices = torch.topk(expert_scores, self.expert_capacity)
expert_input = expert_input[indices]
expert_positions = ... # 更新位置信息
# 专家处理
expert_output = self.experts[expert_idx](expert_input)
outputs[expert_positions] += topk_weights[expert_positions, expert_idx].unsqueeze(-1) * expert_output
# 计算辅助损失
aux_loss += self.balance_loss(gate_logits, expert_idx)
return outputs, aux_loss * aux_loss_weight3. 多模态大模型技术突破
3.1 统一多模态架构
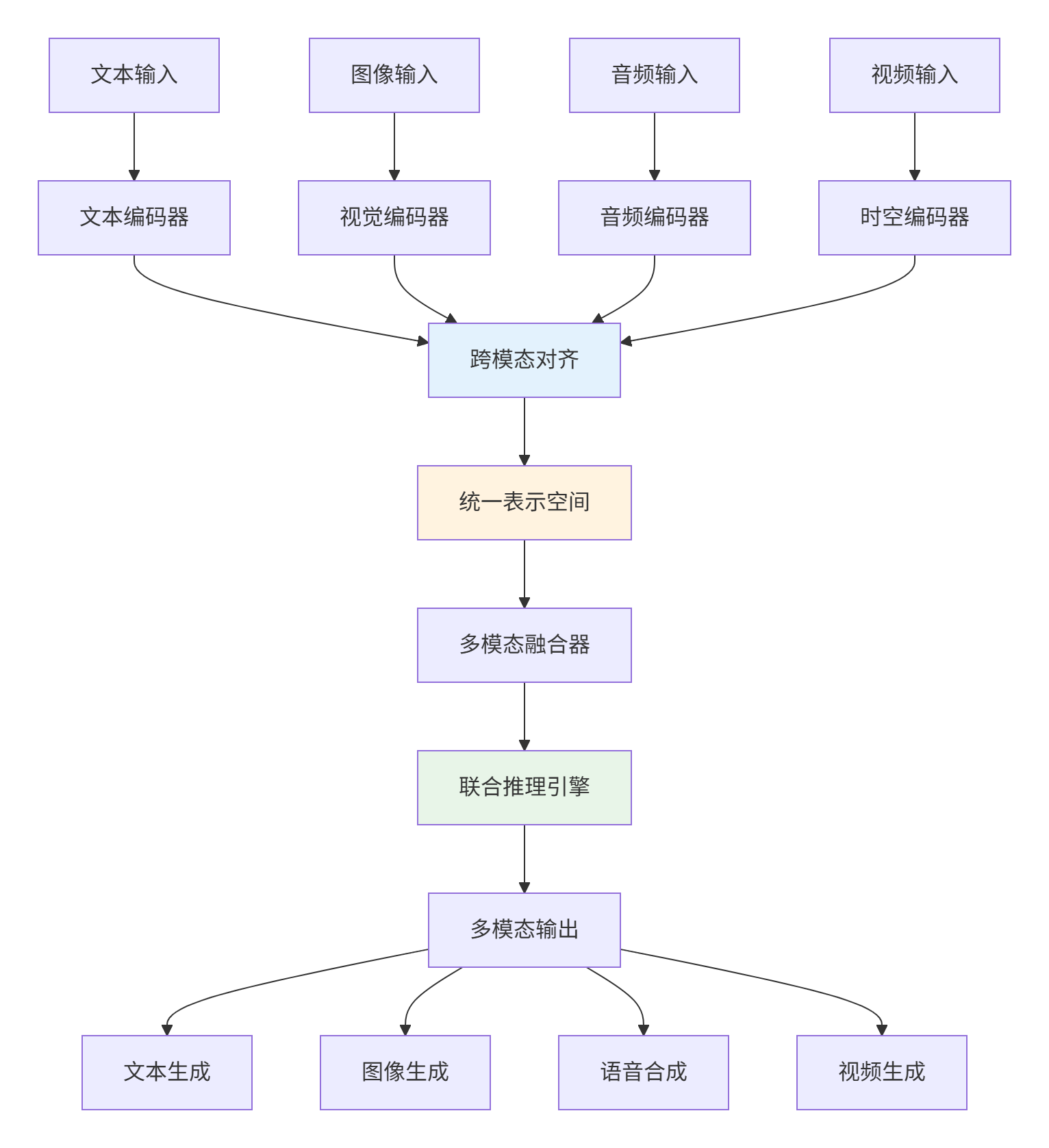
3.2 多模态对齐技术
class UnifiedMultimodalModel(nn.Module):
def __init__(self, text_dim, vision_dim, audio_dim, fusion_dim):
super().__init__()
# 各模态编码器
self.text_encoder = TransformerEncoder(text_dim, 12, 768)
self.vision_encoder = VisionTransformer(vision_dim, 16, 1024)
self.audio_encoder = AudioSpectrogramEncoder(audio_dim, 8, 512)
# 跨模态注意力融合
self.cross_modal_fusion = CrossModalAttention(
text_dim, vision_dim, audio_dim, fusion_dim
)
# 统一表示投影
self.unified_projector = nn.Sequential(
nn.Linear(fusion_dim, fusion_dim * 2),
nn.GELU(),
nn.Linear(fusion_dim * 2, fusion_dim)
)
def forward(self, text_input, image_input, audio_input):
# 各模态独立编码
text_features = self.text_encoder(text_input)
vision_features = self.vision_encoder(image_input)
audio_features = self.audio_encoder(audio_input)
# 跨模态融合
fused_features = self.cross_modal_fusion(
text_features, vision_features, audio_features
)
# 统一表示
unified_representation = self.unified_projector(fused_features)
return unified_representation
class CrossModalAttention(nn.Module):
def __init__(self, text_dim, vision_dim, audio_dim, output_dim):
super().__init__()
self.text_to_vision = nn.MultiheadAttention(text_dim, vision_dim, output_dim)
self.vision_to_text = nn.MultiheadAttention(vision_dim, text_dim, output_dim)
self.audio_integration = nn.MultiheadAttention(output_dim, audio_dim, output_dim)
def forward(self, text, vision, audio):
# 文本-视觉交叉注意力
text_enhanced, _ = self.text_to_vision(text, vision, vision)
vision_enhanced, _ = self.vision_to_text(vision, text, text)
# 多模态融合
multimodal = (text_enhanced + vision_enhanced) / 2
# 音频集成
final_output, _ = self.audio_integration(multimodal, audio, audio)
return final_output4. 2025年关键技术创新
4.1 神经符号推理集成
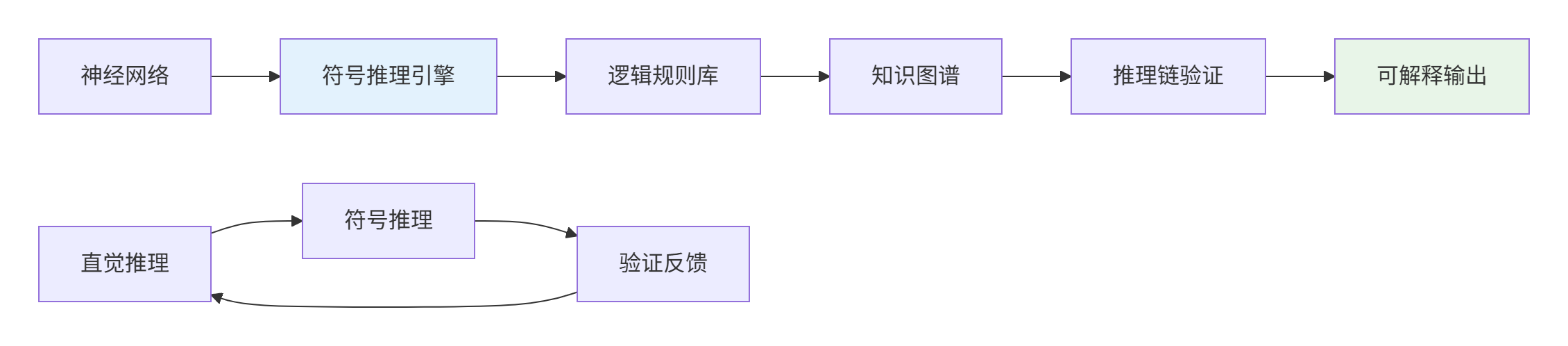
4.1.1 神经符号推理实现
class NeuroSymbolicReasoner:
def __init__(self, neural_model, symbolic_engine):
self.neural_model = neural_model # 神经网络模型
self.symbolic_engine = symbolic_engine # 符号推理引擎
self.knowledge_graph = KnowledgeGraph()
def reason(self, question, context=None):
"""神经符号联合推理"""
# 第一阶段:神经网络直觉推理
neural_response = self.neural_model.generate(question, context)
# 第二阶段:符号逻辑验证
symbolic_representation = self.extract_symbolic_facts(neural_response)
logical_constraints = self.apply_rules(symbolic_representation)
# 第三阶段:知识图谱验证
kg_validation = self.validate_with_knowledge_graph(
symbolic_representation, logical_constraints
)
# 第四阶段:生成可解释结果
explanation = self.generate_explanation(
neural_response, symbolic_representation, kg_validation
)
return {
'answer': neural_response,
'symbolic_facts': symbolic_representation,
'validation': kg_validation,
'explanation': explanation
}
def extract_symbolic_facts(self, text):
"""从文本提取符号事实"""
# 使用LLM提取实体和关系
extraction_prompt = f"""
从以下文本中提取事实:
{text}
格式要求:
- 实体:[类型] 名称
- 关系:主体 → 关系 → 客体
- 属性:实体.属性 = 值
"""
facts = self.neural_model.generate(extraction_prompt)
return self.parse_facts(facts)4.2 持续学习与自适应机制
class ContinualLearningFramework:
def __init__(self, base_model, memory_size=10000):
self.model = base_model
self.memory_buffer = ExperienceReplayBuffer(memory_size)
self.plasticity_regulator = PlasticityRegulator()
def learn_continuously(self, new_data, task_id):
"""持续学习流程"""
# 1. 知识巩固:防止灾难性遗忘
consolidation_loss = self.consolidate_previous_knowledge()
# 2. 选择性学习:重要知识优先
important_samples = self.select_important_examples(new_data)
# 3. 弹性学习:调整学习率
learning_rate = self.plasticity_regulator.adjust_learning_rate(
task_id, self.model.performance_history
)
# 4. 增量训练
for batch in important_samples:
loss = self.model.train_step(batch, learning_rate)
self.memory_buffer.add(batch, loss.item())
# 5. 记忆回放
if len(self.memory_buffer) > 1000:
replay_batch = self.memory_buffer.sample_replay_batch()
self.model.train_step(replay_batch, learning_rate * 0.1)
def select_important_examples(self, data):
"""选择重要的学习样本"""
importance_scores = []
for example in data:
# 基于信息熵的重要性评估
entropy = self.calculate_information_entropy(example)
# 基于新颖性的重要性
novelty = self.calculate_novelty_score(example)
# 基于实用性的重要性
utility = self.calculate_utility_score(example)
importance = entropy * 0.4 + novelty * 0.3 + utility * 0.3
importance_scores.append((example, importance))
# 选择重要性最高的样本
important_samples = sorted(importance_scores, key=lambda x: x[1], reverse=True)
return [sample for sample, _ in important_samples[:len(data)//2]]5. 实际应用与部署架构
5.1 企业级模型部署架构
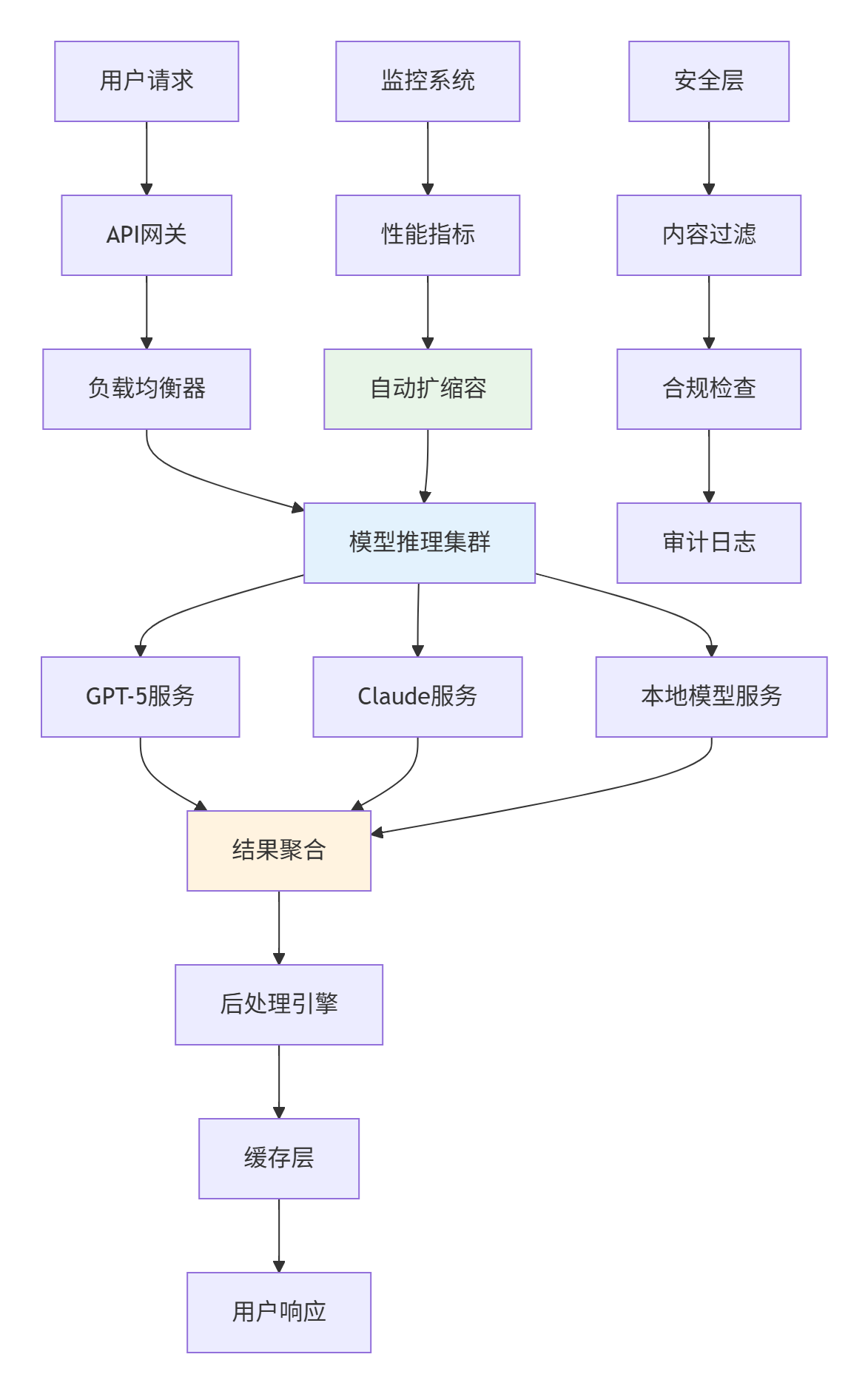
5.2 模型服务化实现
class ModelServiceOrchestrator:
def __init__(self, model_configs):
self.models = {}
self.load_balancer = AdaptiveLoadBalancer()
self.monitor = RealTimeMonitor()
# 初始化模型服务
for config in model_configs:
self.initialize_model_service(config)
async def process_request(self, request):
"""处理用户请求"""
# 1. 请求分析和路由
optimal_model = self.select_optimal_model(request)
# 2. 负载均衡
model_instance = self.load_balancer.get_instance(optimal_model)
# 3. 并行处理(如果需要多模型协作)
if request.requires_multi_model:
tasks = []
for model_name in request.model_list:
task = asyncio.create_task(
self.process_single_model(model_name, request)
)
tasks.append(task)
results = await asyncio.gather(*tasks)
final_result = self.aggregate_results(results)
else:
final_result = await model_instance.process(request)
# 4. 后处理和验证
validated_result = self.postprocess_and_validate(final_result)
return validated_result
def select_optimal_model(self, request):
"""基于请求特性选择最优模型"""
model_scores = {}
for model_name, model_info in self.models.items():
score = self.calculate_model_fitness(model_info, request)
model_scores[model_name] = score
return max(model_scores, key=model_scores.get)
def calculate_model_fitness(self, model, request):
"""计算模型与请求的匹配度"""
fitness = 0
# 领域匹配度
domain_match = self.calculate_domain_similarity(
model.domains, request.domain
)
fitness += domain_match * 0.3
# 复杂度匹配
complexity_match = self.calculate_complexity_match(
model.capabilities, request.complexity
)
fitness += complexity_match * 0.25
# 性能要求匹配
performance_match = self.calculate_performance_match(
model.performance, request.performance_requirements
)
fitness += performance_match * 0.25
# 成本考虑
cost_factor = self.calculate_cost_factor(model.cost, request.budget)
fitness += cost_factor * 0.2
return fitness6. 未来发展趋势与挑战
6.1 2026年技术预测
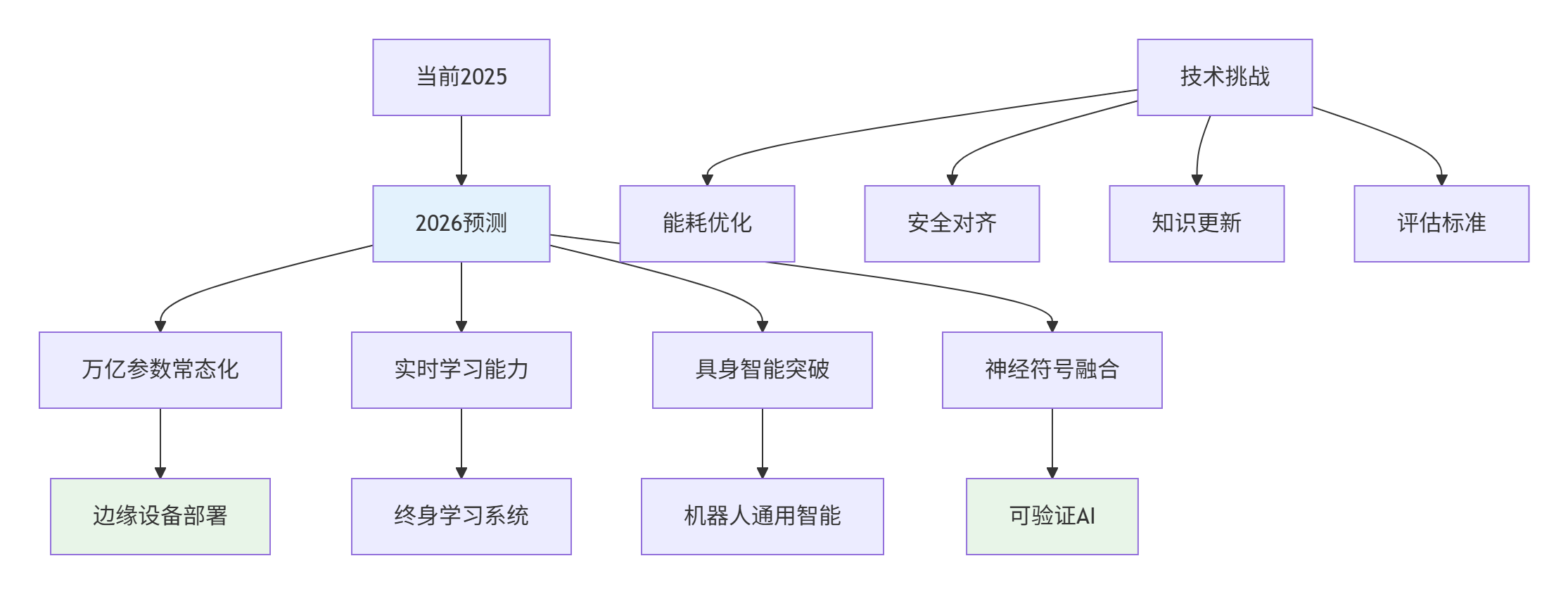
6.2 伦理与安全框架
class AISafetyFramework:
def __init__(self, model, safety_rules, monitoring_system):
self.model = model
self.safety_rules = safety_rules
self.monitor = monitoring_system
self.red_team_testing = RedTeamTester()
async def safe_generation(self, prompt, user_context):
"""安全约束下的文本生成"""
# 1. 输入安全检查
safety_check = await self.check_input_safety(prompt, user_context)
if not safety_check['is_safe']:
return self.get_safe_fallback_response(safety_check['risks'])
# 2. 约束生成
constrained_prompt = self.apply_safety_constraints(prompt)
# 3. 监控生成过程
async for token in self.model.stream_generate(constrained_prompt):
# 实时安全性检查
current_text = self.get_current_text()
safety_status = self.real_time_safety_check(current_text)
if not safety_status['is_safe']:
# 触发安全干预
return await self.handle_safety_violation(safety_status)
yield token
# 4. 输出后验证
final_output = self.get_final_output()
final_safety_check = self.comprehensive_safety_audit(final_output)
if not final_safety_check['passed']:
return self.apply_output_sanitization(final_output)
return final_output
def apply_safety_constraints(self, prompt):
"""应用安全约束"""
constrained_prompt = f"""
请以安全、负责任的方式回答以下问题。
安全准则:
1. 不生成有害、歧视性内容
2. 不提供危险建议
3. 保护用户隐私
4. 遵守法律法规
原始问题:{prompt}
请确保回答符合上述安全准则。
"""
return constrained_prompt总结
2025年的大语言模型和多模态大模型在架构创新、能力扩展和应用落地方面取得了显著进展。从Transformer架构的持续优化到多模态技术的深度融合,从MoE架构的效率提升到神经符号推理的可解释性增强,这些技术进步正在推动AI向更智能、更安全、更实用的方向发展。
关键洞察:
-
架构创新:递归Transformer、MoE等新架构提升模型能力
-
多模态融合:统一表示空间实现真正的跨模态理解
-
持续学习:模型具备适应新知识的能力
-
安全伦理:AI安全框架确保技术负责任发展
随着技术的不断演进,大模型将在更多领域发挥重要作用,但同时也需要持续关注安全、伦理和社会影响等问题。
更多推荐

 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)