
DeepSeekV3.2即将发布,献礼国庆
DeepSeek新模型V3.2即将发布,引发六大核心期待:1)R2和V3.2模型在代码生成、多语言推理和AGI能力上的突破;2)AI智能体实现低干预、高自主操作;3)提升国产算力适配和成本效率;4)强化多模态处理能力;5)深化开源生态和商业化落地;6)增强国际竞争力,打破美企垄断。市场期待DeepSeek在技术突破与实用价值间取得平衡,成为国产AI标杆。
不是假消息,有链接有图为证,deepseek正在上传V3.2模型。
链接:
https://huggingface.co/organizations/deepseek-ai/activity/all
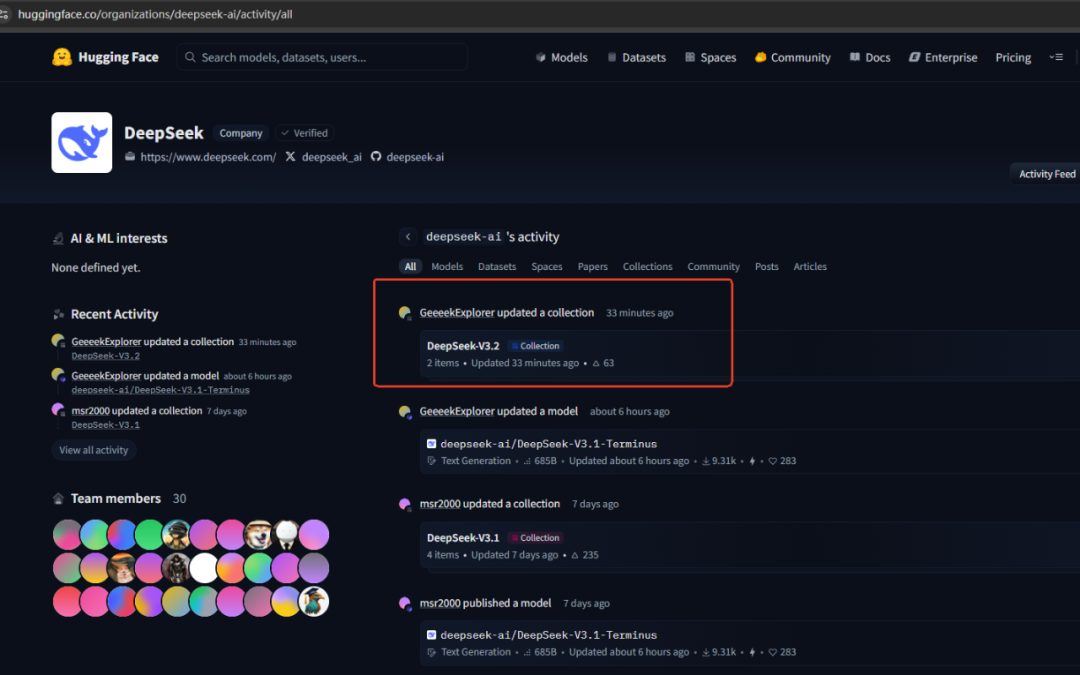
不愧是大模型届的国货之光,总在关键时候出手。
大家对DeepSeek新版本的期待其实很久了,不过屡次被小版本迭代放鸽子,我整理一下各界对DeepSeek新版本的期待可归纳为六大核心方向,涵盖模型能力、技术突破、场景落地等关键维度,具体如下:
一、核心模型迭代:R2 与 V3.2 成焦点,期待关键能力 “跨越式升级”
作为 DeepSeek 下一代核心模型(R 系列侧重实用能力,V 系列瞄准 AGI),市场对 R2 和 V3.2的能力提升期待最为集中,具体聚焦 3 点:
- 代码生成与多语言推理 “再突破”
R1 已在代码基准(如 LiveCodeBench)和多语言任务中展现竞争力,而各方期待 R2 能进一步超越 —— 不仅要 “对标 Claude Sonnet 4 等顶尖模型”,还需支持更复杂的代码场景(如全栈开发、漏洞修复),同时强化非英语语言(尤其是低资源语言)的推理精度,为中国企业出海和全球开发者提供 “平替 Cursor、Trae 等工具” 的能力。
- V3.2 的 AGI 方向 “落地信号”
新版本将是 DeepSeek“探索通用人工智能(AGI)” 的关键模型,当前期待集中于 “AGI 能力的具象化”:无需过度强调 “通用” 概念,而是需在 “跨领域任务迁移”(如从数学推理无缝切换到科学文献分析)、“长期记忆与自我进化”(基于历史交互优化决策)等方面给出可验证的技术细节,打破 “AGI 仅停留在概念” 的现状。
- R2 与 V3.2的 “发布节奏与稳定性”
因早期 R2 “3 月发布” 传闻被否认,当前期待其能按 “2025 年 5 月” 预期时间落地,且需避免 “仓促上线导致性能波动”—— 尤其需在基准测试(如 MMLU、HumanEval)中明确超越前代及竞品,同时提供 “可复现的性能数据”,消除开发者对 “版本迭代质量不稳定” 的担忧。
二、AI 智能体技术:期待 “低干预 + 高自主”,抢占 “人机交互新赛道”
随着 2025 年被称为 “AI 智能体元年”,且政策要求 2027 年智能体普及率超 70%,各方对 DeepSeek 智能体的期待聚焦 “实用性突破”:
- “少提示、多自主” 的核心能力
期待年底推出的智能体(摘要 4)能实现 “仅需少量指令即可完成复杂操作”,例如:无需人工拆解步骤,就能自主完成 “数据爬取 - 分析 - 生成可视化报告”“代码调试 - 部署 - 运维监控” 等多链路任务,同时具备 “历史操作学习能力”,减少重复干预。
- 场景落地与成本控制
一方面期待智能体覆盖 “企业自动化(如金融风险预测)、智能家居、个人助理” 等高频场景;另一方面,延续 DeepSeek “低成本” 优势,期待其智能体 “Token 使用成本较 V3.1 再降 10%-15%”(参考 V3.1 较旧版本降 13% 的数据),推动中小企也能负担智能体部署。
- 弥补现有短板
针对 V3.1 在 “数学推理、逻辑分析、幻觉控制” 的不足,期待新一代智能体通过 “多轮反馈机制”“事实性校验模块” 减少错误,尤其在医疗、政务等 “高准确性要求场景” 中具备可靠表现。
三、技术效率革新:期待 “国产算力适配 + 低成本” 双突破
DeepSeek 过往模型(如 V3)以 “低训练 / 部署成本” 著称,当前期待进一步强化 “效率优势”,且与国产产业深度绑定:
- 深度适配国产算力,降低 “外卡依赖”
“新版本可能在推理侧深度适配国产算力”,这是行业核心期待之一:一方面需支持主流国产 GPU(如华为昇腾、海光 DCU),且性能损耗控制在 10% 以内;另一方面,通过优化架构(如 MoE 激活策略),让国产算力也能支撑 “128K 长上下文 + 高并发推理”,推动 “国产算力 + 国产模型” 的生态闭环。
- 训练与部署成本 “再降维”
期待 R2/V3.2 延续 “MoE 架构优势”,进一步压缩训练时长(如从 V3 的 57 天降至 40 天内)、减少 GPU 消耗(如 H800 用量从 278.8 万小时再降 20%);同时推出更多 “轻量级版本”(参考 R1 的 8B 蒸馏版),支持手机、边缘设备等 “本地离线部署”,兼顾隐私与效率。
四、多模态能力:期待 “从‘有’到‘优’”,对标国际顶尖水平
当前多模态是 AI 核心趋势,各方对 DeepSeek 的期待集中于 “突破文本局限,实现高质量跨模态交互”:
-
“新版本可能具备多模态能力,支持文本、图像甚至视频处理”,市场期待这一功能并非 “基础拼接”,而是能实现 “复杂场景理解”—— 例如:精准识别科学文献中的公式 + 图表并生成分析结论、根据文本描述生成 “符合设计规范的 UI 原型”、对视频内容进行 “逻辑拆解与关键信息提取”,达到 “与 OpenAI、Anthropic 多模态模型同台竞争” 的水平。
五、生态与商业化:期待 “开源深化 + 行业赋能”,解决 “收入可持续性” 争议
针对《金融时报》对 DeepSeek “收入来源可持续性” 的质疑,以及开源生态的潜力,当前期待聚焦两点:
- 开源生态 “更开放、更易用”
期待 R2/V3.2 延续 “MIT 协议开源”(参考 V3.1),同时提供 “一站式工具链”—— 包括更便捷的微调框架(降低数据准备、蒸馏难度)、适配主流云平台(如腾讯云、移动云)的部署插件,以及 “行业垂直数据集”(如医疗影像、金融财报),让开发者无需 “重复造轮子”,快速落地场景应用。
- 商业化 “从‘量’到‘质’”
期待 DeepSeek 在 “政府、金融等已验证场景”基础上,拓展更多垂直领域(如工业质检、教育个性化辅导);同时通过 “API 分层定价”“企业私有部署服务” 等模式,提升付费转化率,用 “季度收入环比增长 30%+” 的实际数据回应 “收入可持续性” 质疑。
六、国际竞争力:期待 “国产模型破局”,提升中国 AIGC 话语权
在全球 AI 竞争白热化背景下,各方期待 DeepSeek 成为 “国产模型走向国际” 的代表:
-
一方面,期待 R2/V3.2 在国际基准(如 MMLU、BBH、SWE-bench)中 “稳定进入全球前三”,打破 “国际顶尖模型由美企垄断” 的格局;另一方面,通过 “多语言优化 + 本地化合规适配”,在东南亚、中东等新兴市场获得更多开发者与企业客户,推动 “中国 AIGC 技术标准输出”(如多模态交互协议、长上下文处理规范),改变 “国际规则由西方主导” 的现状。
综上,当前对 DeepSeek 的期待本质是 “‘技术突破’与‘实用价值’的平衡”—— 既希望其在 AGI、多模态等前沿领域 “敢创新”,也要求其在成本、落地性、生态上 “接地气”,最终成为 “既能引领技术趋势,又能解决行业实际问题” 的国产 AI 标杆。
更多推荐
 14
14 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)