
人工智能-机器学习day4
分类问题用标称数据,回归问题用连续数据,预处理方法完全不同!
线性回归
分类的目标变量是标称型数据,回归是对连续型的数据做出预测。
标称型数据(Nominal Data)是统计学和数据分析中的一种数据类型,它用于分类或标记不同的类别或组别,数据点之间并没有数值意义上的距离或顺序。例如,颜色(红、蓝、绿)、性别(男、女)或产品类别(A、B、C)。
连续型数据(Continuous Data)表示在某个范围内可以取任意数值的测量,这些数据点之间有明确的数值关系和距离。例如,温度、高度、重量等
| 数据类型 | 定义 | 典型示例 |
|---|---|---|
| 标称型数据 (Nominal) | 用于分类或标记,无数学意义 | 性别(男/女)、颜色(红/蓝/绿)、产品类别(A/B/C) |
| 连续型数据 (Continuous) | 可测量、可无限细分的数值 | 温度(36.5℃)、身高(175.3cm)、价格(¥9.99) |
2. 核心特点对比
| 特性 | 标称型数据 | 连续型数据 |
|---|---|---|
| 顺序性 | ❌ 无序(类别间无大小关系) | ✅ 有序(数值可比较大小) |
| 数学运算 | ❌ 不可加减乘除 | ✅ 可计算均值、方差等 |
| 数据细分 | ❌ 有限离散类别 | ✅ 无限可分(如2.5→2.53→2.537...) |
| 统计方法 | 频数、众数、卡方检验 | 均值、标准差、回归分析 |
| 可视化工具 | 条形图、饼图 | 直方图、箱线图、散点图 |
3. 机器学习中的应用
| 任务类型 | 适用算法 | 数据示例 |
|---|---|---|
| 分类问题(标称型目标变量) | 决策树、随机森林、SVM | 预测西瓜好坏(好/坏)、垃圾邮件分类(是/否) |
| 回归问题(连续型目标变量) | 线性回归、随机森林回归 | 预测西瓜价格(¥5.2)、房屋面积(120.5㎡) |
4. 数据预处理差异
| 操作 | 标称型数据 | 连续型数据 |
|---|---|---|
| 缺失值处理 | 填充众数或新类别 | 填充均值/中位数 |
| 特征编码 | 需要独热编码(One-Hot)或标签编码 | 通常直接使用或标准化 |
| 异常值处理 | 较少关注(除非类别错误) | 需处理(如3σ原则) |
5. 通俗类比
-
标称型数据:像贴标签 → 比如给水果贴“苹果”“香蕉”标签,不能计算“苹果+香蕉”。
-
连续型数据:像尺子测量 → 比如量身高,可以算平均身高、谁更高。
6. 实际案例
-
西瓜数据集:
-
标称型:颜色(深绿/浅绿)、纹理(清晰/模糊)→ 用于分类是否好瓜。
-
连续型:甜度(0.8/0.9)、重量(4.2kg)→ 用于回归预测价格。
-
一句话总结
标称型数据 = 分类标签(是什么),连续型数据 = 可测数值(有多少)
-
分类问题用标称数据,回归问题用连续数据,预处理方法完全不同!
一、回归
回归就是用一个数学公式(回归方程),根据已知的输入数据(x)来预测一个具体的数值结果(y)。
核心思想
-
输入(x):影响结果的因素(如年薪、听广播时间)。
-
输出(y):要预测的连续数值(如汽车功率、房价、温度)。
-
回归方程:
y = a*x1 + b*x2 + ... + c(其中a/b/c是回归系数)
| 回归 | 分类 | |
|---|---|---|
| 输出 | 连续数值(多少) | 离散类别(是什么) |
| 例子 | 预测汽车功率 | 判断汽车品牌 |
| 算法 | 线性回归、决策树回归 | 逻辑回归、随机森林 |
一句话总结
回归 = 用数学公式算出一个具体的数!
二、线性回归
线性回归是一种通过拟合最佳直线(或超平面)来描述自变量(X)和因变量(y)之间线性关系的回归方法。
-
输入:一个或多个数值型特征(X)。
-
输出:连续型预测值(y)。
-
模型:
y = wX + b(w是权重,b是截距)。
就像用尺子在一堆散点中画一条“最贴合”的直线,用来预测新数据(比如温度→植物高度)。
| 特点 | 说明 |
|---|---|
| 有监督学习 | 需要带标签的训练数据(已知X和y)。 |
| 连续型输出 | 预测结果是数值(如价格、高度)。 |
| 模型简单 | 假设X和y是线性关系(可扩展为非线性)。 |
线性回归 = 用一条直线拟合数据,预测数值结果!
数学公式是理想状态,是100%对的,而人工智能是一种基于实际数据求解最优最接近实际的方程式,这个方程式带入实际数据计算后的结果是有误差的.
人工智能中的线性回归:数据集中,往往找不到一个完美的方程式来100%满足所有的y目标
我们就需要找出一个最接近真理的方程式
比如:
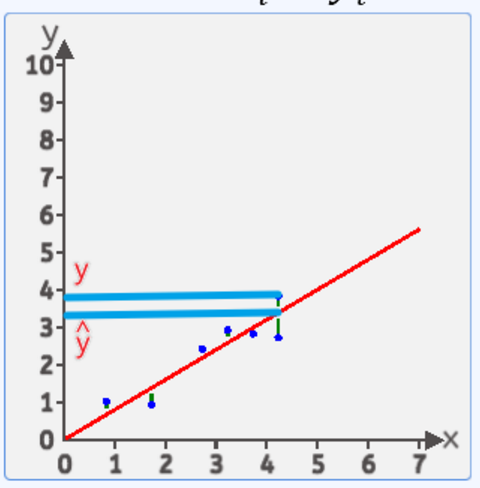
有这样一种植物,在不同的温度下生长的高度是不同的,对不同温度环境下,几颗植物的环境温度(横坐标),植物生长高度(纵坐标)的关系进行了采集,并且将它们绘制在一个二维坐标中,其分布如下图所示:
坐标分别为[4.2, 3.8],[4.2, 2.7],[2.7, 2.4],[0.8, 1.0],[3.7, 2.8],[1.7, 0.9],[3.2, 2.9]。
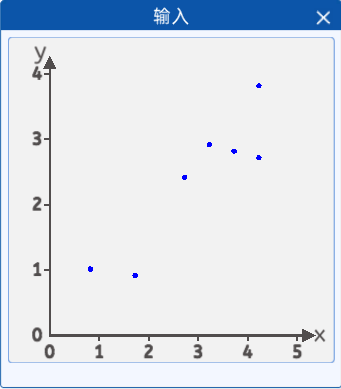
我们发现这些点好像分布在一条直线的附近,那么我们能不能找到这样一条直线,去“拟合”这些点,这样的话我们就可以通过获取环境的温度大概判断植物在某个温度下的生长高度了。
于是我们的最终目的就是通过这些散点来拟合一条直线,使该直线能尽可能准确的描述环境温度与植物高度的关系。
三、损失函数
损失函数(Loss Function)用于量化模型预测值与真实值之间的差异。对于线性回归,常用均方误差作为损失函数
数据:[[4.2, 3.8],[4.2, 2.7],[2.7, 2.4],[0.8, 1.0],[3.7, 2.8],[1.7, 0.9],[3.2, 2.9]]
目标是找到最接近完美直线(穿过所有点的直线)的直线
方程设为:
y=wx+b
均方差:就是每个点到线的竖直方向的距离平方 求和 在求平均 最小时 这条直接就是最优直线
预测值和真实值之间差距存在正负,可以选择绝对值或者是平方
均方误差(MSE):计算的是 竖直方向距离的平方的平均值,公式为:
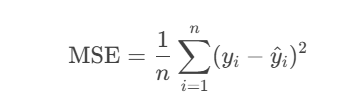
平均绝对误差(MAE):计算的是 竖直方向距离的绝对值的平均值,公式为:
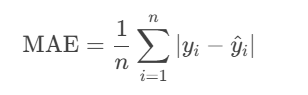
平均的目的:
消除样本数量对总误差的影响
假设: y=wx+b
把x_1,x_2,x_3...带入进去 然后得出:
y_1^,=wx_1+b
y_2^,=wx_2+b
y_3^,=wx_3+b
...
然后计算{y_1-y_1^,} 表示第一个点的真实值和计算值的差值 ,然后把第二个点,第三个点...最后一个点的差值全部算出来
有的点在上面有点在下面,如果直接相加有负数和正数会抵消,体现不出来总误差,平方后就不会有这个问题了
所以最后:
总误差(也就是传说中的损失):
loss1={(y_1-y_1^,)^2}+{(y_2-y_2^,)^2}+....{(y_n-y_n^,)^2}
平均误差(总误差会受到样本点的个数的影响,样本点越多,该值就越大,所以我们可以对其平均化,求得平均值,这样就能解决样本点个数不同带来的影响)
这样就得到了损失函数:
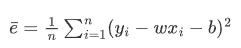
为了简化计算,假设b=0;
展开算式:
$$
\begin{aligned} \bar e &=\frac{1}{n} \textstyle\sum_{i=1}^{n}(w x_{i}-y_{i})^{2}\\ &={\frac{1}{n}}\sum_{i=1}^{n}x_{i}^{2}w^{2}-{\frac{2}{n}}\sum_{i=1}^{n} x_{i}y_{i}w+{\frac{1}{n}}\sum_{i=1}^{n} y_{i}^{2}\\ &x_i,y_i都是已知的因此:\\ &= {a w^{2}+b w+c} \\ &= 10w^{2}-15.9w+6.5 \end{aligned}
$$
令其值为0:
$$
10w^2-15.9w+6.5=0
$$
求出w的值为0.795(抛物线求顶点)
$$
y=0.795x+0
$$
这样就求出最优解的函数
总结:
1.实际数据中 x和y组成的点 不一定是全部落在一条直线上
2.我们假设有这么一条直线 y=wx+b 是最符合描述这些点的
3.最符合的条件就是这个方程带入所有x计算出的所有y与真实的y值做 均方差计算
4.找到均方差最小的那个w
5.这样就求出了最优解的函数(前提条件是假设b=0)
交叉熵损失(Cross-Entropy Loss):
定义:交叉熵损失衡量的是 你的模型预测的概率分布 (Q) 与 真实的概率分布 (P) 之间的差异程度。
-
用来衡量你的预测概率(比如
[A:10%, B:20%, C:60%, D:10%])和真实情况(比如正确答案是C)之间差距的“坏分数”。分数越大,预测越差。 -
它怎么算? 核心就是计算正确答案对应的那个预测概率,计算
-log(这个概率)。 -
怎么算分(损失)?
-
只盯住正确答案 C 对应的那个预测概率(这里是 60%)。
-
然后,他拿出一个神奇的“计算器”:
-
计算器上有个
-log(你的预测概率)按钮。 -
你把
60%(即0.6)输进去,按下按钮,算出一个数(大约0.51)。
-
-
这个数
0.51就是你这次预测的“交叉熵损失”。 -
情景1:你预测 C 只有 10% 可能性。惩罚:
-log(0.1) ≈ 2.3 -
情景2:你预测 C 有 60% 可能性。惩罚:
-log(0.6) ≈ 0.51 -
情景3:你预测 C 有 90% 可能性。惩罚:
-log(0.9) ≈ 0.105 -
情景4:你预测 C 有 100% 可能性。惩罚:
-log(1) = 0
-
-
为什么这么算?为什么用
-log?-
-log(概率)的特性:-
概率越高(越接近1),惩罚越低(越接近0)。 如果你100%确定是C (
概率=1),-log(1) = 0,完美,不扣分! -
概率越低(越接近0),惩罚越高(飙升到无穷大)! 如果你觉得C的可能性只有1% (
概率=0.01),-log(0.01) ≈ 4.6,罚分很重!如果你觉得C是0% (概率=0),-log(0)会变成无穷大!(电脑里会避免0,但意思就是:完全忽略正确答案)
-
-
-负号的作用: 因为log(概率)本身是负数(概率<1),加个负号让它变成正数,这样损失值越大表示预测越差。
-
-
它有什么特点?
-
你对正确答案越自信(预测概率越高),损失越小。
-
你对正确答案越不自信(预测概率越低),损失越大。
-
-
为什么用它? 在训练分类模型(比如图片识别猫狗)时,电脑就用这个损失函数当“考官”。电脑的目标就是通过不断学习调整,让自己在所有题目上的这个“坏分数”(总损失)变得最小。分数最小的时候,就意味着它对正确答案的判断最自信、最准确
四、多参数回归
多参数回归就是:用多个因素(比如温度、湿度、运动量)一起预测一个结果(比如健康程度)。
公式: 预测值 = w₁×因素₁ + w₂×因素₂ + ... + wₙ×因素ₙ + 基础分
-
w₁, w₂...:每个因素的“重要性”(权重)。
-
基础分:所有因素为0时的默认值(比如“躺平”时的健康分)。
如何求解权重?
方法1:解方程(理想情况)
-
如果有8个因素,需要解8元一次方程。
-
问题:现实中数据有误差,方程可能无解!
方法2:最小化误差(实际做法)
-
先随机猜一组权重(比如全设1)。
-
计算预测值和真实值的差距(损失函数):
误差 = (预测健康分 - 实际健康分)² 的平均值
-
用数学方法(如梯度下降)调整权重,让误差越来越小。
-
最终得到最优权重,使预测最准。
通俗理解: 像调收音机旋钮,直到杂音最小 → 找到最清晰的信号(最优权重)。
API
核心类:LinearRegression
from sklearn.linear_model import LinearRegression
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
fit_intercept |
bool | True |
是否计算截距项(y = wX + b中的b) |
copy_X |
bool | True |
是否复制特征数据(避免修改原数据) |
n_jobs |
int | None |
并行计算核数(-1用全部CPU) |
positive |
bool | False |
强制权重为正(适用于某些物理场景) |
| 属性 | 说明 |
|---|---|
coef_ |
权重数组(w₁, w₂, ..., wₙ) |
intercept_ |
截距项(b,若fit_intercept=False则为0) |
rank_ |
特征矩阵的秩 |
singular_ |
特征矩阵的奇异值 |
| 方法 | 说明 |
|---|---|
fit(X, y) |
训练模型(X: 特征矩阵, y: 目标值) |
predict(X) |
预测新样本 |
score(X, y) |
计算R²决定系数(评估模型) |
示例:
(预测房价,基于面积、卧室数、房龄)
假设我们有以下房价数据:
| 面积(m²) | 卧室数 | 房龄(年) | 价格(万元) |
|---|---|---|---|
| 80 | 2 | 10 | 300 |
| 95 | 3 | 5 | 450 |
| 120 | 4 | 2 | 500 |
import numpy as np
from sklearn.linear_model import LinearRegression
# 特征(面积, 卧室数, 房龄)
X = np.array([
[80, 2, 10],
[95, 3, 5],
[120, 4, 2]
])
# 目标值(价格)
y = np.array([300, 450, 500])
# 创建模型(包含截距项)
model = LinearRegression(fit_intercept=True)
# 训练
model.fit(X, y)
# 输出权重和截距
print("权重(面积, 卧室数, 房龄):", model.coef_)
print("截距:", model.intercept_)
# 预测新房子:面积=100m², 卧室=3, 房龄=0年
new_house = np.array([[100, 3, 0]])
predicted_price = model.predict(new_house)
print("预测价格:", predicted_price[0], "万元")
# 输出:
# 权重(面积, 卧室数, 房龄): [ -2.61377614 4.55104551 -36.93111931]
# 截距: 869.311193111932
# 预测价格: 621.5867158671588 万元
五、最小二乘法MSE
最小二乘法 = 通过矩阵运算直接求解最优权重,最小化预测误差的平方和!
最小二乘法(Least Squares Method)是一种通过最小化预测值与真实值之间的平方误差来求解回归模型参数的方法。
-
目标:找到一组权重 W,使得 ||XW-y||^2(误差平方和)最小。
-
数学本质:求解线性方程组XW=y的最优近似解
损失函数(MSE):
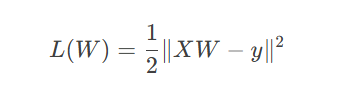
SKlearn API
from sklearn.linear_model import LinearRegression
# 创建模型(默认使用最小二乘法)
model = LinearRegression(fit_intercept=True) # fit_intercept=True 表示计算截距 w0
# 训练
model.fit(X, y)
# 输出结果
print("权重:", model.coef_) # w1 到 wm
print("截距:", model.intercept_) # w0
参数说明:
-
fit_intercept:是否计算截距项(默认True)。
示例:
from sklearn.linear_model import LinearRegression
import numpy as np
# 构造数据
X = np.array([
[1, 2],
[2, 4],
[3, 6],
[4, 8]
])
y = np.array([2, 4, 6, 8])
# 创建并训练模型
model = LinearRegression(fit_intercept=True)
model.fit(X, y)
print("权重:", model.coef_)
print("截距:", model.intercept_)
# 输出:
# 权重: [0.4 0.8]
# 截距: 0.0
六、梯度下降
梯度下降是优化线性回归模型的核心算法,用于自动找到使损失函数最小的权重参数。
核心思想
-
问题:线性回归的损失函数(MSE)为凸函数,存在全局最小值。
-
解决思路:从随机点出发,沿梯度反方向逐步调整参数,逼近最小值。
-
类比:像蒙眼下山,每步都找最陡的方向下降。
数学本质:
梯度:损失函数对参数的偏导数向量
负梯度方向:函数值下降最快的方向
损失函数(MSE):

正规方程的局限性:
-
非凸函数问题:
-
正规方程要求损失函数为凸函数(如MSE)才能获得全局最优解
-
实际机器学习中损失函数常为非凸函数,导数为0会得到多个局部极值,无法保证最优解
-
示例:复杂损失函数可能存在多个山谷和山峰
-
-
计算效率问题:
-
正规方程时间复杂度:O(n^3)(n为特征数)
-
特征数量翻倍时,计算时间变为2^3=8倍
-
现实场景特征量极大(如深度学习模型百万级特征),正规方程不可行
-
1、学习率
学习率
学习率(Learning Rate),通常用希腊字母 α(alpha)或 η(eta)表示,是梯度下降算法中一个至关重要的超参数。
-
作用: 它控制着模型参数(在线性回归中就是权重
w和偏置b)在每次迭代(每次梯度计算)后更新的幅度。 -
类比: 想象你在山顶(代表高损失/误差),目标是走到山谷最低点(代表最低损失/误差)。梯度下降就像沿着最陡峭的下山方向走。学习率就相当于你每一步迈出的距离。
-
步子太大(学习率太高):你可能一步跨过了山谷最低点,甚至跳到更高的地方(发散),或者在谷底两侧反复横跳(震荡),始终无法稳定到达最低点。
-
步子太小(学习率太低):你需要走非常非常多的步才能接近谷底(收敛速度极慢),耗费大量时间和计算资源,甚至可能卡在某个小坑里(局部极小点)出不来。
-
-
公式体现: 在线性回归的梯度下降参数更新中,学习率直接乘以梯度:
w_new = w_old - α * (∂J/∂w)b_new = b_old - α * (∂J/∂b)其中:-
w_old,b_old: 当前迭代的参数值。 -
J: 损失函数(如均方误差 MSE)。 -
∂J/∂w,∂J/∂b: 损失函数J对参数w和b的梯度(偏导数),指明了损失下降最快的方向。 -
α: 学习率,决定了沿着梯度方向移动的步长。 -
w_new,b_new: 更新后的参数值。
-
学习率的影响:
学习率的值对梯度下降的收敛性、收敛速度和最终结果有着决定性的影响:
-
学习率太小:
-
优点: 理论上总能收敛(如果优化问题是凸的,如线性回归)到(局部)最小值点附近。
-
缺点:
-
收敛速度极慢: 需要非常多的迭代步数才能接近最优解,训练时间大大延长。
-
可能陷入局部极小点: 在非凸问题中,小步长更容易被困在不是全局最优的局部极小点中(虽然线性回归是凸的,但了解这点对理解更广泛的机器学习很重要)。
-
计算成本高: 每一步计算梯度都需要遍历数据(或批次数据),迭代次数多意味着计算开销巨大。
-
-
-
学习率太大:
-
缺点:
-
震荡/发散: 这是最常见的问题。参数更新幅度过大,导致损失函数值在最小值点附近剧烈震荡,甚至完全偏离最小值点,损失值越来越大(发散),模型永远无法收敛。
-
跳过最优解: 更新步长过大,可能直接“跨过”了最优解点。
-
无法收敛: 损失函数值无法稳定下降到一个较低的水平。
-
-
-
学习率适中:
-
理想情况: 损失函数值能够稳定、快速地下降,并在合理的迭代次数内收敛到一个(接近)最优解的点。
-
2、梯度下降步骤
1.参数初始化
目的:为算法设置起点
操作:
-
随机生成一组符合正态分布(高斯分布)的初始权重
-
为什么用正态分布?
-
中心极限定理保证数据分布更均衡
-
避免对称性导致的优化停滞
-
2、梯度计算
目的:确定参数更新方向
操作:
-
计算损失函数对每个参数的偏导数
-
几何意义:
-
梯度是损失函数曲面上当前点的切线斜率
-
负梯度方向是函数值下降最快的方向
-
3、参数更新
目的:沿最优方向调整参数
w_new = w_old - α * (∂J/∂w) b_new = b_old - α * (∂J/∂b) 其中:
-
w_old,b_old: 当前迭代的参数值。 -
J: 损失函数(如均方误差 MSE)。 -
∂J/∂w,∂J/∂b: 损失函数J对参数w和b的梯度(偏导数),指明了损失下降最快的方向。 -
α: 学习率,决定了沿着梯度方向移动的步长。 -
w_new,b_new: 更新后的参数值。
| 梯度符号 | 参数变化 | 物理意义 |
|---|---|---|
| g < 0 | w增大 | 位于最小值左侧(上坡方向) |
| g > 0 | w减小 | 位于最小值右侧(下坡方向) |
4、收敛判断
-
目的:确定何时停止迭代
-
判断是否收敛,如果收敛跳出迭代,如果没有达到收敛,回第2步再次执行2~4步收敛的判断标准是:随着迭代进行查看损失函数Loss的值,变化非常微小甚至不再改变,即认为达到收敛
3、梯度下降公式
梯度下降的核心公式为:
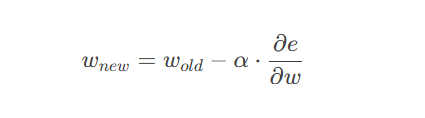
其中:
-
Wold:当前参数值
-
Wnew:更新后的参数值
-
α:学习率(步长)
-
∂e/∂w:损失函数对参数 w的梯度(导数)
关于随机的w在左边和右边问题:
因为导数有正负
如果在左边 导数是负数 减去负数就是加 往右移动
如果在右边 导数是正数 减去正数就是减 往左移动
-
梯度符号是方向控制器:
-
负梯度 → 增加参数值
-
正梯度 → 减小参数值
-
始终向损失函数最小值移动
-
-
学习率是步长调节器:
-
过大:跳过最优点(震荡)
-
过小:收敛缓慢
-
黄金法则:初始设为0.01,根据损失曲线调整
-
4、自己实现梯度下降
梯度下降实现核心步骤
-
定义损失函数
-
明确优化目标(单变量、多变量或高维函数)
-
-
计算梯度(偏导数)
-
手动推导或使用自动微分
-
-
参数初始化
-
随机生成符合正态分布的初始值
-
-
设置超参数
-
学习率(固定或动态衰减)
-
最大迭代次数
-
-
迭代更新
-
计算当前梯度
-
更新参数:w = w - \alpha \cdot \nabla J(w)
-
-
收敛判断
-
梯度接近零
-
损失变化小于阈值
-
达到最大迭代次数
-
示例1:假设损失函数是只有一个w_1特征的抛物线:
$$
loss(w_1)=(w_1-3)^2+2
$$
import numpy as np import matplotlib.pyplot as plt #构建损失函数 x = np.array([1, 2, 3, 4]) y = np.array([2, 4, 6, 8]) def e(w): return (w-3)**2+2 def draw_loss(): #生成0到10的100个点 point_w=np.linspace(0,10,100) #计算对应的损失函数值 point_e=e(point_w) plt.plot(point_w,point_e) draw_loss() plt.show()
import numpy as np
import matplotlib.pyplot as plt
# 定义损失函数
def e(w):
return (w-3)**2 + 2
# 定义损失函数的导数(梯度)
def g(w):
return 2*(w-3) # 直接返回梯度值,而不是返回函数
# 绘制损失函数曲线
def draw_loss():
# 生成0到10的100个点
point_w = np.linspace(0, 10, 100)
# 计算对应的损失函数值
point_e = e(point_w)
plt.plot(point_w, point_e)
plt.xlabel('w')
plt.ylabel('Loss')
plt.title('Loss Function')
# 随机化初始W
np.random.seed(42)
w = 1000 # 初始权重值
t0 = 1 # 初始学习率
# 记录权重和损失值的变化过程
w_history = [w]
loss_history = [e(w)]
# 梯度下降迭代
for i in range(1000):
# 计算梯度
grad = g(w)
# 动态调整学习率(随着迭代次数增加而减小)
learning_rate = t0 / (100 + i)
# 更新权重
w = w - learning_rate * grad
# 记录当前状态
w_history.append(w)
loss_history.append(e(w))
# 每100次打印一次进度
if i % 100 == 0:
print(f"Iteration {i}: w = {w:.6f}, loss = {e(w):.6f}, grad = {grad:.6f}")
# 绘制损失函数曲线
plt.figure(figsize=(10, 6))
draw_loss()
# 在损失曲线上标记梯度下降路径
plt.scatter(w_history, loss_history, c='red', s=20, alpha=0.5)
plt.plot(w_history, loss_history, 'r-', alpha=0.3)
plt.legend()
plt.grid(True)
plt.show()
# 打印最终结果
print(f"\nOptimization result:")
print(f"Final w: {w:.6f}")
print(f"Final loss: {e(w):.6f}")
print(f"Target w: 3.0")
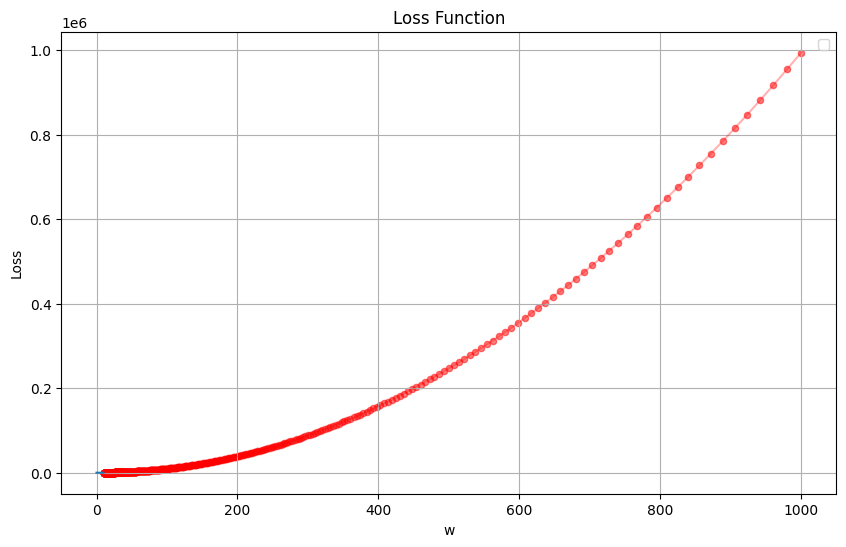
示例2:假设损失函数是有两个w_1,w_2特征的椎体
import numpy as np
# 定义损失函数
def loss(w1, w2):
return w1**2 + w2**2
# 定义梯度
def gradient(w1, w2):
return 2*w1, 2*w2 # 分别对w1和w2求偏导
# 梯度下降参数
learning_rate = 0.1#学习效
max_iter = 100 #最大迭代次数
tolerance = 1e-6#阈值
# 初始化参数(随机起点)
w1, w2 = 5.0, -3.0 # 故意选择远离最小值的点
# 梯度下降主循环
for i in range(max_iter):
# 计算当前梯度
grad_w1, grad_w2 = gradient(w1, w2)
# 检查收敛条件(梯度接近0)
if abs(grad_w1) < tolerance and abs(grad_w2) < tolerance:# abs()函数用于计算参数绝对值
print(f"在第{i+1}次迭代收敛")
break
# 更新参数
w1 = w1 - learning_rate * grad_w1
w2 = w2 - learning_rate * grad_w2
# 打印进度(每10次迭代)
if i % 10 == 0:
print(f"Iter {i}: w1={w1:.4f}, w2={w2:.4f}, loss={loss(w1, w2):.4f}")
# 输出最终结果
print(f"\n优化结果: w1={w1:.6f}, w2={w2:.6f}")
print(f"最小损失值: {loss(w1, w2):.6f} (理论最小值: 0.0)")
mport numpy as np
np.random.seed(42)
data=np.random.randint(1,10,(4,3)) #随机生成一个4*3的矩阵
x=data[:,:-1] #取所有行,去掉最后一列
y=data[:,-1] #取所有行,最后一列
print(x)
print(y)
#构建模型函数
def model(x,w):
return np.dot(x,w) #矩阵乘法
#定义损失函数
def loss(w,x): #预测值和真实值之间的误差
return
#随机初始化参数
w=np.random.randn(3,1)
print(w)
print(loss(w,x))
def loss(w1,w2):
return (w1-5)**2+(w2-5)**2 # 损失函数
def g_w1(w1,w2):
return 2*(w1-5) # w1的导数
def grad_w2(w1,w2):
return 2*(w2-5) # w2的导数
#初始化参数w1,w2
w1=w2=0
print(loss(w1,w2))
for i in range(1000):# 迭代1000次
w1=w1-0.01*g_w1(w1,w2)# 更新w1
w2=w2-0.01*grad_w2(w1,w2)# 更新w2
print(loss(w1,w2))
5、sklearn梯度下降
官方的梯度下降API常用有三种:
批量梯度下降BGD(Batch Gradient Descent)
小批量梯度下降MBGD(Mini-BatchGradient Descent)
随机梯度下降SGD(Stochastic Gradient Descent)。
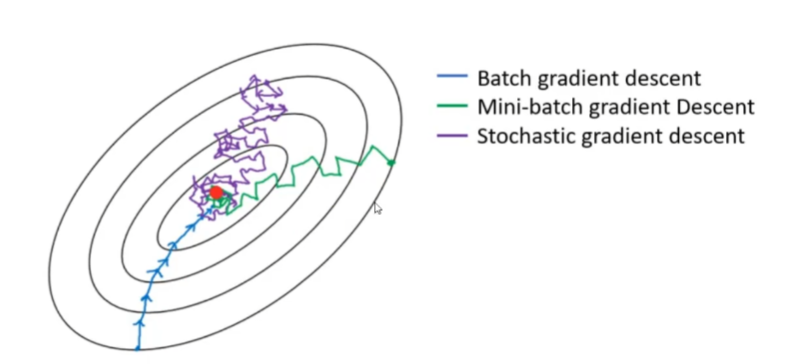
三种梯度下降有什么不同呢?
-
Batch Gradient Descent (BGD): 在这种情况下,每一次迭代都会使用全部的训练样本计算梯度来更新权重。这意味着每一步梯度更新都是基于整个数据集的平均梯度。这种方法的优点是每次更新的方向是最准确的,但缺点是计算量大且速度慢,尤其是在大数据集上。
-
Mini-Batch Gradient Descent (MBGD): 这种方法介于批量梯度下降和随机梯度下降之间。它不是用全部样本也不是只用一个样本,而是每次迭代从数据集中随机抽取一小部分样本(例如,从500个样本中选取32个),然后基于这一小批样本的平均梯度来更新权重。这种方法在准确性和计算效率之间取得了一个平衡。
-
Stochastic Gradient Descent (SGD): 在随机梯度下降中,每次迭代仅使用随机单个样本(或有时称为“例子”)来计算梯度并更新权重。这种方法能够更快地收敛,但由于每次更新都基于单个样本,所以会导致权重更新路径不稳定。
1、批量梯度下降BGD
-
基本思想:
-
假设我们有一个包含 ( m ) 个训练样本的数据集 \{(x^{(i)}, y^{(i)})\}_{i=1}^{m},其中 x^{(i)} 是输入特征, y^{(i)} 是对应的标签。我们的目标是最小化损失函数 J(\theta) 相对于模型参数 \theta 的值。
损失函数可以定义为: J(\theta) = \frac{1}{2m} \sum_{i=1}^{m} (h_\theta(x^{(i)}) - y^{(i)})^2
其中 h_\theta(x^{(i)}) 是模型对第 i 个样本的预测输出。
批量梯度下降的更新规则为: \theta_j := \theta_j - \alpha \frac{1}{m} \sum_{i=1}^{m} (h_\theta(x^{(i)}) - y^{(i)}) \cdot x_j^{(i)} 对于 j = 0, 1, \ldots, n (其中 n 是特征的数量),并且 \alpha 是学习率。
特性 批量梯度下降 (BGD) 对比其他方法 梯度计算 使用全部样本,梯度估计准确 随机梯度下降(SGD)用单个样本,小批量梯度下降(Mini-batch GD)用部分样本,梯度有噪声 收敛性 稳定收敛到全局最优(凸函数)或局部最优(非凸) SGD可能震荡,Mini-batch GD是折中方案 计算效率 每次迭代计算成本高,尤其大数据集 SGD和Mini-batch GD更适合大数据集 内存需求 需加载全部数据到内存 Mini-batch GD可分批加载 更新频率 每轮迭代更新一次参数 SGD每样本更新一次,Mini-batch GD每批更新一次
通俗易懂版:
集体决策的“老教授”
想象你是一位老教授,要教一群学生(模型参数)找到山谷的最低点(最小化损失函数)。BGD的工作方式是这样的:
-
全班一起讨论: 每次上课时,你会集合所有学生(全部训练数据),让他们各自说出自己认为的“下山方向”(梯度)。 → 相当于用全部数据计算梯度
-
民主投票决定方向: 你把所有学生的意见汇总,取一个平均方向(平均梯度),然后让大家一起朝这个方向走一步。 → 参数更新:全体数据梯度的平均值
-
稳步前进: 因为听取了所有人的意见,每一步的方向都很靠谱,不会乱跑,但速度慢(每次都要等全班发言完才能动)。 → 收敛稳定但计算慢
2、随机梯度下降SGD
原理:
小批量梯度下降的基本思想是在每个迭代步骤中使用一小部分(即“小批量”)训练样本来计算损失函数的梯度,并据此更新模型参数。这样做的好处在于能够减少计算资源的需求,同时保持一定程度的梯度准确性。
工作方式:假设我们有一个包含 ( m ) 个训练样本的数据集 \{(x^{(i)}, y^{(i)})\}_{i=1}^{m},其中 x^{(i)} 是输入特征,y^{(i)} 是对应的标签。我们将数据集划分为多个小批量,每个小批量包含 ( b ) 个样本,其中 ( b ) 称为批量大小(batch size),通常 ( b ) 远小于 ( m )。
损失函数可以定义为:
J(\theta) = \frac{1}{2b} \sum_{i=1}^{m} (h_\theta(x^{(i)}) - y^{(i)})^2
-
其中 h_\theta(x^{(i)}) 是模型对第 i 个样本的预测输出。
-
小批量梯度下降的更新规则为:
-
\theta_j := \theta_j - \alpha \frac{1}{b} \sum_{i \in B} (h_\theta(x^{(i)}) - y^{(i)}) \cdot x_j^{(i)}
-
对于 j = 0, 1, \ldots, n (其中 n 是特征的数量
**
特点
-
计算效率:相比于批量梯度下降,小批量梯度下降每次更新只需要处理一部分数据,减少了计算成本。
-
梯度估计:相比于随机梯度下降,小批量梯度下降提供了更准确的梯度估计,这有助于更稳定地接近最小值。
-
内存需求:相比批量梯度下降,小批量梯度下降降低了内存需求,但仍然比随机梯度下降要高。
-
收敛速度与稳定性:小批量梯度下降能够在保持较快的收敛速度的同时,维持相对较高的稳定性。
关键特点:
✅ 计算高效:适合大规模数据(无需加载全部数据)
✅ 逃离局部最优:随机性可能跳出局部最小值
❌ 更新震荡:梯度估计噪声大,收敛路径不稳定
使用场景
-
中等规模数据集:当数据集大小适中时,小批量梯度下降是一个很好的折衷方案,既能够高效处理数据,又能够保持良好的收敛性。
-
在线学习:在数据流式到达的场景下,小批量梯度下降可以有效地处理新到来的数据批次。
-
分布式环境:在分布式计算环境中,小批量梯度下降可以更容易地在多台机器上并行执行。
实现注意事项
-
选择合适的批量大小:批量大小的选择对性能有很大影响。较大的批量可以减少迭代次数,但计算成本增加;较小的批量则相反。
-
选择合适的学习率:选择合适的学习率对于快速且稳定的收敛至关重要。如果学习率太小,收敛速度会很慢;如果太大,则可能会导致不收敛。
-
数据预处理:对数据进行标准化或归一化,可以提高小批量梯度下降的效率。
-
监控损失函数:定期检查损失函数的变化趋势,确保算法正常工作并朝着正确的方向前进。
API
from sklearn.linear_model import SGDRegressor
# 初始化模型
model = SGDRegressor(
loss='squared_error', # 损失函数(均方误差)
penalty='l2', # 正则化项(L2正则)
alpha=0.0001, # 正则化强度
learning_rate='invscaling', # 学习率策略
eta0=0.01, # 初始学习率
max_iter=1000, # 最大迭代次数
tol=1e-3, # 收敛阈值
shuffle=True, # 每轮迭代是否打乱数据
random_state=42
)
# 训练模型
model.fit(X_train, y_train)
# 获取参数
print("权重:", model.coef_) # 特征权重
print("偏置:", model.intercept_) # 截距项
| 参数 | 作用 | 常见值 |
|---|---|---|
learning_rate |
控制更新步长 | 0.01, 0.001(需调参) |
momentum |
动量系数,加速收敛并减少震荡 | 0.9(推荐) |
nesterov |
是否使用Nesterov动量(更智能的动量更新) | True/False |
weight_decay |
L2正则化强度(PyTorch) | 0.001~0.1 |
penalty |
正则化类型(Scikit-Learn) | 'l1', 'l2', 'elasticnet' |
loss |
损失函数类型 | 'squared_error', 'log_loss' |
shuffle |
是否每轮打乱数据顺序 | True(推荐) |
示例:(加州房价预测)
# Scikit-Learn 示例
from sklearn.datasets import fetch_california_housing
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import SGDRegressor
from sklearn.metrics import mean_squared_error
import numpy as np
#加载数据集
x,y=fetch_california_housing(return_X_y=True,data_home="./")
#数据集划分
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=42)
#数据集标准化
scaler=StandardScaler() # 创建一个数据集标准化对象
scaler.fit(x_train) # 训练
x_train=scaler.transform(x_train) # 标准化
#创建模型
model=SGDRegressor(loss="squared_error",learning_rate="constant",eta0=0.001,fit_intercept=True,max_iter=10000,shuffle=True)# 创建一个模型
model.fit(x_train,y_train)# 训练
print("w:",model.coef_)
print("b",model.intercept_)
#评估
x_test=scaler.transform(x_test)
y_hat=model.predict(x_test)
loss=mean_squared_error(y_test,y_hat)
print("测试集的准确率:",loss)
3、小批量梯度下降MBGD
小批量梯度下降是一种介于批量梯度下降(BGD)与随机梯度下降(SGD)之间的优化算法,它结合了两者的优点,在机器学习和深度学习中被广泛使用。
原理
小批量梯度下降的基本思想是在每个迭代步骤中使用一小部分(即“小批量”)训练样本来计算损失函数的梯度,并据此更新模型参数。这样做的好处在于能够减少计算资源的需求,同时保持一定程度的梯度准确性。
更新规则
假设我们有一个包含 ( m ) 个训练样本的数据集 \{(x^{(i)}, y^{(i)})\}_{i=1}^{m},其中 x^{(i)} 是输入特征,y^{(i)} 是对应的标签。我们将数据集划分为多个小批量,每个小批量包含 ( b ) 个样本,其中 ( b ) 称为批量大小(batch size),通常 ( b ) 远小于 ( m )。
损失函数可以定义为: J(\theta) = \frac{1}{2b} \sum_{i=1}^{m} (h_\theta(x^{(i)}) - y^{(i)})^2
其中 h_\theta(x^{(i)}) 是模型对第 i 个样本的预测输出。
小批量梯度下降的更新规则为: \theta_j := \theta_j - \alpha \frac{1}{b} \sum_{i \in B} (h_\theta(x^{(i)}) - y^{(i)}) \cdot x_j^{(i)} 对于 j = 0, 1, \ldots, n (其中 n 是特征的数量),并且 \alpha 是学习率, B 表示当前小批量中的样本索引集合。
| 特性 | MBGD | 对比 BGD | 对比 SGD |
|---|---|---|---|
| 计算效率 | ✅ 中等(适合GPU并行) | ❌ 低(全数据计算) | ✅ 高(单样本计算) |
| 梯度噪声 | ✅ 适中(比SGD稳定) | ✅ 无噪声(精确梯度) | ❌ 高噪声(震荡大) |
| 内存需求 | ✅ 中等(需存小批量数据) | ❌ 高(全数据) | ✅ 低(单样本) |
| 收敛速度 | ✅ 快(结合向量化加速) | ❌ 慢(每轮迭代时间长) | ✅ 快(但路径不稳定) |
使用场景
中等规模数据集:当数据集大小适中时,小批量梯度下降是一个很好的折衷方案,既能够高效处理数据,又能够保持良好的收敛性。
-
在线学习:在数据流式到达的场景下,小批量梯度下降可以有效地处理新到来的数据批次。
-
分布式环境:在分布式计算环境中,小批量梯度下降可以更容易地在多台机器上并行执行。
实现注意事项
-
选择合适的批量大小:批量大小的选择对性能有很大影响。较大的批量可以减少迭代次数,但计算成本增加;较小的批量则相反。
-
选择合适的学习率:选择合适的学习率对于快速且稳定的收敛至关重要。如果学习率太小,收敛速度会很慢;如果太大,则可能会导致不收敛。
-
数据预处理:对数据进行标准化或归一化,可以提高小批量梯度下降的效率。
-
监控损失函数:定期检查损失函数的变化趋势,确保算法正常工作并朝着正确的方向前进。
算法步骤
1、初始化参数:随机初始化权重 θ 和学习率 α
2、数据分批次:将训练集划分为多个小批量(如每批64个样本)。*
3、迭代更新 :对每个小批量:计算梯度和更新参数
4、终止条件:达到最大迭代次数或者梯度足够小终止
API
from sklearn.linear_model import SGDRegressor
# 初始化模型(通过partial_fit实现小批量训练)
model = SGDRegressor(
loss='squared_error', # 损失函数(均方误差)
penalty='l2', # 正则化项
alpha=0.0001, # 正则化强度
learning_rate='invscaling', # 学习率衰减策略
eta0=0.01, # 初始学习率
max_iter=1, # 每轮epoch仅用1次迭代(需手动控制)
shuffle=True, # 打乱数据顺序
random_state=42
)
# 手动分批次训练
batch_size = 32
for epoch in range(100):
for i in range(0, len(X_train), batch_size):
X_batch = X_train[i:i+batch_size]
y_batch = y_train[i:i+batch_size]
model.partial_fit(X_batch, y_batch) # 关键API:增量更新权重
# 预测与评估
y_pred = model.predict(X_test)
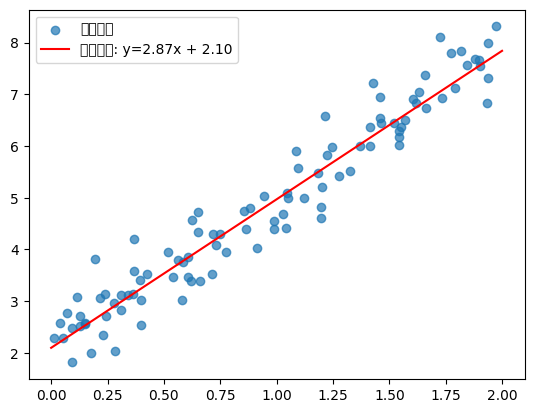
示例:
#生成模拟数据
import numpy as np
import matplotlib.pyplot as plt
# 生成线性数据 y = 3x + 2 + 噪声
np.random.seed(42)
X = 2 * np.random.rand(100, 1) # 100个样本,1个特征
y = 3 * X + 2 + np.random.randn(100, 1) * 0.5 # 添加高斯噪声
# 可视化数据
plt.scatter(X, y, alpha=0.7)
plt.xlabel("X")
plt.ylabel("y")
plt.title("模拟数据 (y = 3x + 2 + 噪声)")
plt.show()
#小批量梯度下降实现
def minibatch_gd(X, y, batch_size=10, lr=0.01, epochs=100):
m, n = X.shape
theta = np.random.randn(n + 1, 1) # 随机初始化参数 [w, b]
# 添加偏置项 (x0=1)
X_b = np.c_[X, np.ones((m, 1))]
loss_history = []
for epoch in range(epochs):
# 打乱数据顺序
shuffled_indices = np.random.permutation(m)
X_shuffled = X_b[shuffled_indices]
y_shuffled = y[shuffled_indices]
# 分批次训练
for i in range(0, m, batch_size):
# 获取当前小批量
xi = X_shuffled[i:i+batch_size]
yi = y_shuffled[i:i+batch_size]
# 计算梯度 (MSE损失)
gradients = 2/batch_size * xi.T.dot(xi.dot(theta) - yi)
# 更新参数
theta -= lr * gradients
# 记录损失
loss = np.mean((X_b.dot(theta) - y)**2)
loss_history.append(loss)
# 打印进度
if epoch % 10 == 0:
print(f"Epoch {epoch}, Loss: {loss:.4f}")
return theta, loss_history
# 运行小批量梯度下降
theta, losses = minibatch_gd(X, y, batch_size=16, lr=0.1, epochs=50)
# 输出最终参数
print(f"\n最终参数: w = {theta[0][0]:.3f}, b = {theta[1][0]:.3f}")
print("(真实参数: w=3.0, b=2.0)")
# 绘制损失函数曲线
# 绘制损失下降曲线
plt.plot(losses)
plt.xlabel("Epoch")
plt.ylabel("MSE Loss")
plt.title("训练损失下降曲线")
plt.show()
# 绘制拟合直线
plt.scatter(X, y, alpha=0.7, label="原始数据")
X_test = np.array([[0], [2]])
plt.plot(X_test, theta[0]*X_test + theta[1], 'r-', label=f"拟合直线: y={theta[0][0]:.2f}x + {theta[1][0]:.2f}")
plt.legend()
plt.show()
6、梯度化下降优化
1、标准化
在梯度下降优化中,数据标准化(Standardization) 是一个至关重要的预处理步骤,它能显著提高优化算法的性能和收敛速度。
为什么需要标准化?
梯度下降算法对特征的尺度(Scale)非常敏感。当不同特征的数值范围差异较大时:
-
收敛速度慢:参数在较大尺度特征方向上更新缓慢(需要更小的学习率)。
-
震荡现象:参数在较小尺度特征方向上可能过度更新,导致震荡。
-
无法使用统一学习率:不同特征方向需要不同的学习率调整。
API
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() X_scaled = scaler.fit_transform(X)
2、正则化
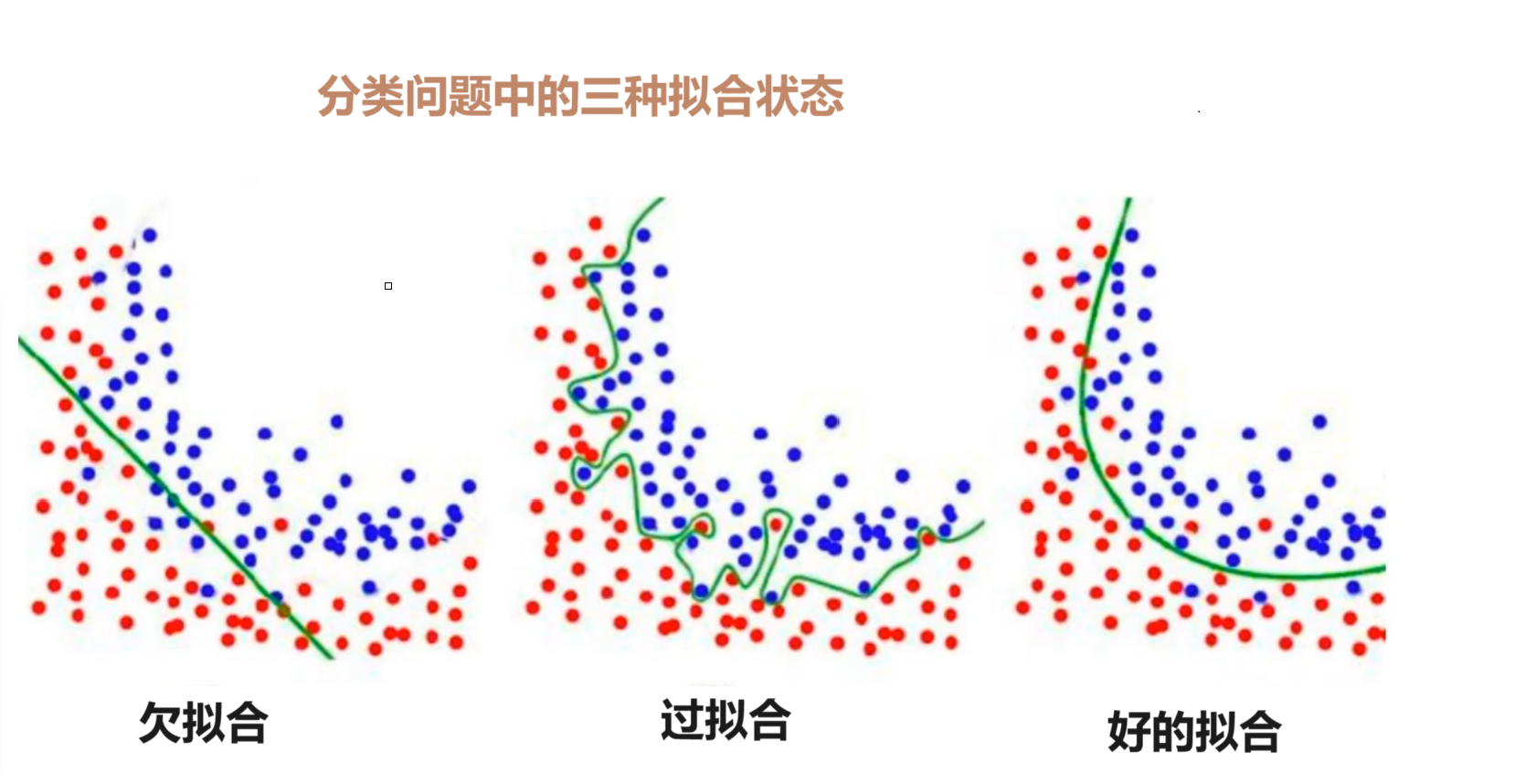
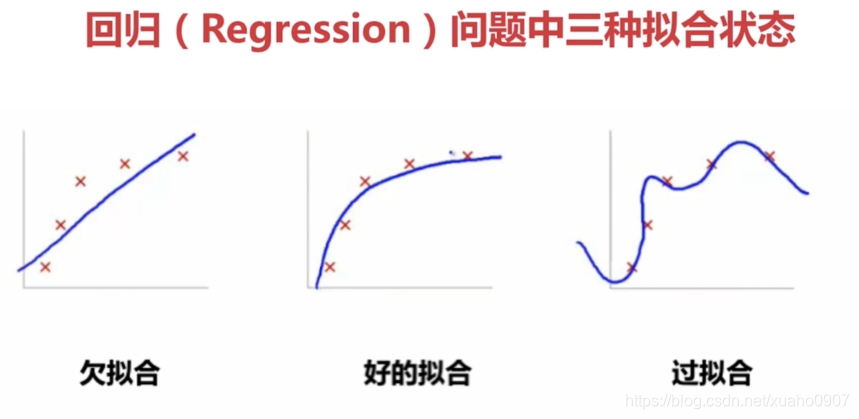
1.欠拟合
欠拟合是指模型在训练数据上表现不佳,同时在新的未见过的数据上也表现不佳。这通常发生在模型过于简单,无法捕捉数据中的复杂模式时。欠拟合模型的表现特征如下:
-
训练误差较高。
-
测试误差同样较高。
-
模型可能过于简化,不能充分学习训练数据中的模式。
2.过拟合
过拟合是指模型在训练数据上表现得非常好,但在新的未见过的数据上表现较差。这通常发生在模型过于复杂,以至于它不仅学习了数据中的真实模式,还学习了噪声和异常值。过拟合模型的表现特征如下:
-
训练误差非常低。
-
测试误差较高。
-
模型可能过于复杂,以至于它对训练数据进行了过度拟合。
3.正则化
因此将原来的损失函数加上一个惩罚项使得计算出来的模型W相对小一些,就是正则化。
目的
-
防止过拟合:约束模型复杂度,避免过度依赖训练数据噪声
-
提升鲁棒性:增强模型对输入扰动(噪声/异常值)的抵抗力
-
提高泛化能力:确保模型在未知数据上的预测稳定性
数学原理
损失函数重构: J'(w) = J(w) + λ·R(w)
-
J(w):原始损失函数(如MSE) -
R(w):正则化惩罚项 -
λ:正则化强度(超参数),控制惩罚力度
惩罚机制:
-
L1正则(Lasso):
R(w) = ||w||₁ = Σ|wᵢ| -
L2正则(Ridge):
R(w) = ||w||₂² = Σwᵢ²(注:实际使用时L2常省略平方根以简化求导)
| 特性 | L1正则 (Lasso) | L2正则 (Ridge) |
|---|---|---|
| 解的性质 | 产生稀疏解(部分权重=0) | 权重整体压缩但不归零 |
| 特征选择 | 天然支持(自动筛选特征) | 不支持 |
| 抗噪声能力 | 强(抑制无关特征) | 较强(平滑权重分布) |
| 梯度特性 | 在0点不可导(需次梯度) | 处处可导(优化更稳定) |
| 几何解释 | 菱形约束域(角点解) | 圆形约束域(边界解) |
3、岭回归Ridge
在标准线性回归的损失函数(均方误差MSE)基础上,增加一个L2正则化惩罚项(所有权重的平方和)。
通过惩罚较大的权重系数,降低模型的复杂度,从而提高模型的泛化能力。
$$
J(w)=\frac{1}{n} \textstyle\sum_{i=1}^{m}(h_w(x_i)-y_{i})^{2}+ λ\textstyle\sum_{j=1}^nw_j^2\\
$$
均方差除以2是因为方便求导,w_j指所有的权重系数, λ指惩罚型系数,又叫正则项力度
特点:
-
权重压缩但不归零:
-
所有特征权重被均匀压缩趋近于0,但不会完全归零
-
保留所有特征信息,适合特征选择不重要的场景
-
-
多重共线性处理:
-
当特征高度相关时,普通线性回归解不稳定
-
岭回归提供唯一稳定解,改善病态矩阵问题
-
API
sklearn.linear_model.Ridge 类
class sklearn.linear_model.Ridge(
alpha=1.0,
*,
fit_intercept=True,
copy_X=True,
max_iter=None,
tol=0.001,
solver='auto',
positive=False,
random_state=None
)
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| alpha | float | 1.0 | 正则化强度:控制权重收缩程度的关键参数 • 值越大 → 正则化越强 → 权重越接近0 • 值过小 → 接近普通线性回归 • 值过大 → 可能导致欠拟合 |
| fit_intercept | bool | True | 是否计算截距项: • True:计算偏置项 • False:假设数据已中心化 |
| solver | str | 'auto' | 求解算法: • 'auto':自动选择最佳求解器 • 'svd':奇异值分解(小数据集) • 'cholesky':标准闭式解法 • 'lsqr':专用最小二乘算法 • 'sparse_cg':稀疏矩阵优化 • 'sag'/'saga':随机平均梯度下降(大数据集) • 'lbfgs':拟牛顿法优化器 |
| max_iter | int | None | 最大迭代次数(仅迭代求解器需要) • None:使用求解器默认值 • 'sag'/'saga' 默认15000 |
| tol | float | 1e-3 | 优化精度容差: • 当损失变化小于该值时停止迭代 |
| positive | bool | False | 是否强制权重为正 • True:仅允许正权重系数 |
| random_state | int | None | 随机种子(仅sag/saga需要) • 确保结果可复现 |
| 属性 | 类型 | 说明 |
|---|---|---|
| coef_ | ndarray | 回归权重系数(特征重要性) • 形状:(n_features,) 或 (n_targets, n_features) |
| intercept_ | float/ndarray | 模型截距(偏置项) • 当 fit_intercept=True 时存在 |
| n_iter_ | None/ndarray | 实际迭代次数 • 仅迭代求解器返回该值 |
| 方法 | 说明 |
|---|---|
fit(X, y[, sample_weight]) |
训练岭回归模型 |
predict(X) |
使用模型进行预测 |
score(X, y[, sample_weight]) |
返回模型决定系数 R² |
get_params([deep]) |
获取模型参数 |
set_params(**params) |
设置模型参数 |
编写代码参考思路:
1、加载数据
2、划分训练集和测试集
3、标准化
4、创建岭回归模型
5、得出模型
6、模型评估
示例:
#Ridge岭回归
from sklearn.linear_model import Ridge
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_iris
# 加载数据集
iris = load_iris()
X, y = iris.data, iris.target
#数据集划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 数据标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)#训练数据
X_test = scaler.transform(X_test)
#创建岭回归模型
model=Ridge(alpha=1.0,fit_intercept=True,max_iter=1000,tol=0.001,solver='auto',positive=False,random_state=42)
model.fit(X_train,y_train)
#预测
y_pred = model.predict(X_test)
print("loss:", mean_squared_error(y_test, y_pred))
print("模型系数:", model.coef_)
print("模型截距:", model.intercept_)
# 输出:
# loss: 0.03722004011576201
# 模型系数: [-0.06957282 -0.03730416 0.40242631 0.42288966]
# 模型截距: 0.9916666666666669
4、拉索回归Lasso
通过引入L1正则化,拉索回归可以防止过拟合,并且能够产生稀疏模型(即部分特征的权重变为0),从而实现特征选择。
拉索回归是一种线性回归的L1正则化变体,通过在损失函数中添加所有权重的绝对值之和作为惩罚项:
$$
\text{J(w)}= \frac{1}{2n}\sum_{i=1}^n (h_w(x_i)-y_i)^2 + \lambda \sum_{j=1}^p |w_j|
$$
其中:
-
n 是样本数量,
-
p 是特征的数量,
-
y_i 是第 i 个样本的目标值,
-
x_i 是第 i 个样本的特征向量,
-
w是模型的参数向量,
-
\lambda 是正则化参数,控制正则化项的强度。
特点:
-
拉索回归可以将一些权重压缩到零,从而实现特征选择。这意味着模型最终可能只包含一部分特征。
-
适用于特征数量远大于样本数量的情况,或者当特征间存在相关性时,可以从中选择最相关的特征。
-
拉索回归产生的模型可能更简单,因为它会去除一些不重要的特征。
API
sklearn.linear_model.Lasso()
参数:
-
alpha (float, default=1.0):
-
控制正则化强度;必须是非负浮点数。较大的 alpha 增加了正则化强度。
-
-
fit_intercept (bool, default=True):
-
是否计算此模型的截距。如果设置为 False,则不会使用截距(即数据应该已经被居中)。
-
-
precompute (bool or array-like, default=False):
-
如果为 True,则使用预计算的 Gram 矩阵来加速计算。如果为数组,则使用提供的 Gram 矩阵。
-
-
copy_X (bool, default=True):
-
如果为 True,则复制数据 X,否则可能对其进行修改。
-
-
max_iter (int, default=1000):
-
最大迭代次数。
-
-
tol (float, default=1e-4):
-
精度阈值。如果更新后的系数向量减去之前的系数向量的无穷范数除以 1 加上更新后的系数向量的无穷范数小于 tol,则认为收敛。
-
-
warm_start (bool, default=False):
-
当设置为 True 时,再次调用 fit 方法会重新使用之前调用 fit 方法的结果作为初始估计值,而不是清零它们。
-
-
positive (bool, default=False):
-
当设置为 True 时,强制系数为非负。
-
-
random_state (int, RandomState instance, default=None):
-
随机数生成器的状态。用于随机初始化坐标下降算法中的随机选择。
-
-
selection ({'cyclic', 'random'}, default='cyclic'):
-
如果设置为 'random',则随机选择坐标进行更新。如果设置为 'cyclic',则按照循环顺序选择坐标。
-
属性:
-
coef_
-
系数向量或者矩阵,代表了每个特征的权重。
-
-
intercept_
-
截距项(如果 fit_intercept=True)。
-
-
n_iter_
-
实际使用的迭代次数。
-
-
n_features_in_ (int):
-
训练样本中特征的数量。
-
编写代码参考思路:
1、加载数据
2、划分训练集和测试集
3、标准化
4、创建拉索回归模型
5、训练模型
6、模型评估
示例:
#Lasso 拉索回归
from sklearn.linear_model import Lasso
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
#加载数据集
iris = load_iris()
X, y = iris.data, iris.target
#数据集划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
#标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
#创建Lasso模型
lasso = Lasso(alpha=1.0)
lasso.fit(X_train, y_train)
#预测
y_pred = lasso.predict(X_test)
print("loss:",mean_squared_error(y_test, y_pred))
print("Lasso模型系数:", lasso.coef_)
print("Lasso模型截距:", lasso.intercept_)
# 输出:
# loss: 0.7006249999999998
# Lasso模型系数: [ 0. -0. 0. 0.]
# Lasso模型截距: 0.9916666666666667更多推荐


 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)