
深度学习在智能推荐系统中的应用与挑战
在当今信息爆炸的时代,我们每天都会接触到海量的数据和信息。智能推荐系统就像是一个聪明的小助手,它能从这些海量信息中挑选出我们可能感兴趣的内容,比如在电商平台上为我们推荐喜欢的商品,在视频网站上为我们推荐爱看的视频。而深度学习作为人工智能领域的强大工具,为智能推荐系统的发展带来了新的活力。本文的目的就是要详细介绍深度学习在智能推荐系统中的应用,以及在应用过程中遇到的挑战,范围涵盖了从基本概念到实际应
深度学习在智能推荐系统中的应用与挑战
关键词:深度学习、智能推荐系统、应用、挑战、协同过滤
摘要:本文深入探讨了深度学习在智能推荐系统中的应用与挑战。首先介绍了相关背景知识,包括智能推荐系统的目的和范围、预期读者等。接着详细解释了深度学习和智能推荐系统的核心概念,阐述了它们之间的关系,并给出了原理和架构的示意图与流程图。然后介绍了核心算法原理、数学模型和公式,通过项目实战展示了代码实现和解读。还探讨了实际应用场景、推荐了相关工具和资源,分析了未来发展趋势与挑战。最后进行总结,提出思考题,解答常见问题并提供扩展阅读资料,旨在帮助读者全面了解深度学习在智能推荐系统中的应用情况。
背景介绍
目的和范围
在当今信息爆炸的时代,我们每天都会接触到海量的数据和信息。智能推荐系统就像是一个聪明的小助手,它能从这些海量信息中挑选出我们可能感兴趣的内容,比如在电商平台上为我们推荐喜欢的商品,在视频网站上为我们推荐爱看的视频。而深度学习作为人工智能领域的强大工具,为智能推荐系统的发展带来了新的活力。本文的目的就是要详细介绍深度学习在智能推荐系统中的应用,以及在应用过程中遇到的挑战,范围涵盖了从基本概念到实际应用和未来趋势等多个方面。
预期读者
这篇文章适合对人工智能、智能推荐系统感兴趣的初学者,也适合想要深入了解深度学习在推荐系统中应用的技术人员。无论你是刚刚接触这个领域的小学生,还是已经有一定经验的程序员,都能从本文中获得有用的信息。
文档结构概述
本文首先会介绍深度学习和智能推荐系统的核心概念,以及它们之间的联系。然后会详细讲解核心算法原理和具体操作步骤,包括相关的数学模型和公式。接着通过一个项目实战,展示如何在实际中应用这些知识。之后会探讨深度学习在智能推荐系统中的实际应用场景,推荐一些相关的工具和资源。最后会分析未来的发展趋势与挑战,进行总结并提出一些思考题。
术语表
核心术语定义
- 深度学习:简单来说,深度学习就像是一个超级厉害的学习机器,它可以从大量的数据中自动学习到复杂的模式和规律。就好比我们学习画画,一开始可能只能画简单的线条,但是随着不断地练习和学习,就能画出非常逼真的画作。深度学习也是通过不断地处理数据,逐渐提高自己的能力。
- 智能推荐系统:它是一种能够根据用户的历史行为、兴趣爱好等信息,为用户推荐个性化内容的系统。就像我们去图书馆借书,图书管理员会根据我们平时喜欢看的书,给我们推荐其他可能感兴趣的书籍。
相关概念解释
- 协同过滤:这是智能推荐系统中常用的一种方法。比如说,有两个同学,他们都喜欢看科幻电影,其中一个同学还喜欢看一部新出的科幻小说,那么推荐系统就会认为另一个同学也可能喜欢这部小说,从而把它推荐给这个同学。
- 神经网络:是深度学习中的一个重要概念,它模仿了人类大脑的神经元结构。可以把它想象成一个由很多小神经元组成的网络,这些神经元之间相互连接,通过不断地传递信息来完成各种任务,就像我们大脑中的神经元相互协作来思考问题一样。
缩略词列表
- DNN:深度神经网络(Deep Neural Network),是深度学习中常用的一种神经网络结构。
- CNN:卷积神经网络(Convolutional Neural Network),常用于处理图像和视频数据。
核心概念与联系
故事引入
想象一下,你是一个喜欢看电影的小朋友。每次打开视频网站,网站就像一个神奇的魔法师,总能给你推荐出你特别想看的电影。有一天,你很好奇这个魔法师是怎么知道你喜欢什么电影的。后来你发现,原来网站背后有一个超级聪明的“大脑”,这个“大脑”就是深度学习技术,它通过分析你之前看过的电影、给电影的评分等信息,就能准确地猜出你接下来可能喜欢的电影。这就是深度学习在智能推荐系统中的一个简单应用。
核心概念解释(像给小学生讲故事一样)
- 核心概念一:什么是深度学习?
深度学习就像一个超级爱学习的小天才。假如你有很多不同形状和颜色的积木,你想把它们分类整理好。一开始,小天才可能不太清楚怎么分类,但是它会不断地观察这些积木,看看哪些积木颜色一样,哪些形状一样。慢慢地,它就学会了如何把不同的积木放到正确的类别里。深度学习也是这样,它会从大量的数据中学习,找到数据中的规律和模式,然后用这些规律来解决各种问题。 - 核心概念二:什么是智能推荐系统?
智能推荐系统就像是一个贴心的小秘书。你去商场买东西,小秘书会根据你平时的购物习惯,给你推荐你可能会喜欢的商品。比如你经常买巧克力味的零食,小秘书就会给你推荐新出的巧克力蛋糕或者巧克力冰淇淋。它会收集你的各种信息,然后根据这些信息为你提供个性化的推荐。 - 核心概念三:什么是数据特征?
数据特征就像是每个人的特点。比如我们描述一个小朋友,会说他有大大的眼睛、高高的个子、喜欢踢足球。这些就是这个小朋友的特征。在数据中,每个数据也有自己的特征。比如一部电影,它的特征可能包括电影的类型(喜剧、科幻、动作等)、主演、评分等。智能推荐系统就是通过分析这些数据特征,来了解你的喜好并进行推荐的。
核心概念之间的关系(用小学生能理解的比喻)
- 概念一和概念二的关系:深度学习和智能推荐系统如何合作?
深度学习就像一个聪明的侦探,智能推荐系统就像一个负责传递信息的信使。侦探通过收集各种线索(数据),然后进行分析和推理,找到背后的真相(数据中的规律)。信使则把侦探找到的真相应用到实际中,根据这些规律为用户推荐合适的内容。比如,深度学习通过分析大量用户的观影数据,发现喜欢科幻电影的用户也喜欢某一类的科幻小说。智能推荐系统就会把这些科幻小说推荐给喜欢科幻电影的用户。 - 概念二和概念三的关系:智能推荐系统和数据特征如何合作?
智能推荐系统就像一个厨师,数据特征就像各种食材。厨师需要根据不同的食材来做出美味的菜肴。智能推荐系统也是一样,它会根据数据的特征来为用户做出合适的推荐。比如,如果一个用户的观影数据特征显示他喜欢动作片和明星 A,那么智能推荐系统就会优先推荐有明星 A 参演的动作片。 - 概念一和概念三的关系:深度学习和数据特征如何合作?
深度学习就像一个科学家,数据特征就像实验材料。科学家通过对实验材料进行研究和分析,发现新的知识和规律。深度学习也是通过对数据特征进行处理和分析,找到数据中的模式和规律。比如,深度学习可以通过分析电影的类型、评分、主演等特征,发现不同类型电影的受欢迎程度和用户的喜好趋势。
核心概念原理和架构的文本示意图(专业定义)
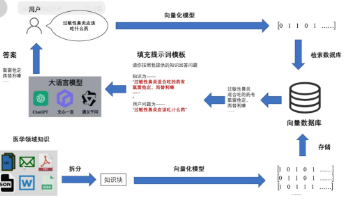
深度学习在智能推荐系统中的应用原理主要是通过对用户的历史行为数据(如浏览记录、购买记录、评分等)和物品的特征数据(如商品的属性、类别等)进行处理和分析。首先,将这些数据输入到深度学习模型中,模型会对数据进行特征提取和表示学习,找到数据中的潜在模式和规律。然后,根据这些学习到的规律,为用户生成个性化的推荐列表。
其架构一般包括数据层、特征工程层、模型层和推荐服务层。数据层负责收集和存储用户和物品的数据;特征工程层对数据进行预处理和特征提取;模型层使用深度学习模型进行训练和预测;推荐服务层将模型的预测结果转化为实际的推荐列表提供给用户。
Mermaid 流程图
核心算法原理 & 具体操作步骤
在深度学习中,常用的算法有深度神经网络(DNN)、卷积神经网络(CNN)和循环神经网络(RNN)等。这里我们以深度神经网络为例,介绍其在智能推荐系统中的应用。
算法原理
深度神经网络由输入层、隐藏层和输出层组成。输入层接收用户和物品的特征数据,隐藏层对这些数据进行非线性变换和特征提取,输出层输出预测的推荐分数。通过不断地调整网络中的权重和偏置,使得预测结果与真实的用户行为数据尽可能接近。
具体操作步骤
1. 数据准备
首先,我们需要收集用户和物品的数据,包括用户的历史行为数据和物品的特征数据。然后对这些数据进行清洗和预处理,去除噪声和缺失值。
2. 特征工程
对数据进行特征提取和转换,将原始数据转化为适合深度学习模型输入的特征向量。例如,将用户的年龄、性别等信息进行编码,将物品的类别信息进行独热编码。
3. 模型构建
使用 Python 和深度学习框架(如 TensorFlow 或 PyTorch)构建深度神经网络模型。以下是一个简单的示例代码:
import tensorflow as tf
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.models import Model
# 定义输入层
user_input = Input(shape=(user_feature_dim,))
item_input = Input(shape=(item_feature_dim,))
# 合并用户和物品的输入
merged = tf.keras.layers.Concatenate()([user_input, item_input])
# 定义隐藏层
hidden_layer1 = Dense(128, activation='relu')(merged)
hidden_layer2 = Dense(64, activation='relu')(hidden_layer1)
# 定义输出层
output_layer = Dense(1, activation='sigmoid')(hidden_layer2)
# 构建模型
model = Model(inputs=[user_input, item_input], outputs=output_layer)
# 编译模型
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
4. 模型训练
将准备好的训练数据输入到模型中进行训练,通过不断地调整模型的参数,使得模型的损失函数最小化。
model.fit([user_train_data, item_train_data], labels_train, epochs=10, batch_size=32)
5. 模型评估
使用测试数据对训练好的模型进行评估,计算模型的准确率、召回率等指标,评估模型的性能。
loss, accuracy = model.evaluate([user_test_data, item_test_data], labels_test)
print(f"Test loss: {loss}, Test accuracy: {accuracy}")
6. 推荐生成
使用训练好的模型对用户进行推荐,根据模型的预测结果生成推荐列表。
predictions = model.predict([user_new_data, item_new_data])
# 根据预测结果生成推荐列表
数学模型和公式 & 详细讲解 & 举例说明
数学模型
在深度神经网络中,常用的数学模型是前馈神经网络。假设输入层有 nnn 个神经元,隐藏层有 mmm 个神经元,输出层有 kkk 个神经元。输入向量为 x=[x1,x2,⋯ ,xn]T\mathbf{x} = [x_1, x_2, \cdots, x_n]^Tx=[x1,x2,⋯,xn]T,隐藏层的输入为 zh\mathbf{z}_hzh,输出为 ah\mathbf{a}_hah,输出层的输入为 zo\mathbf{z}_ozo,输出为 ao\mathbf{a}_oao。
公式
隐藏层的输入和输出
隐藏层的输入可以表示为:
zh=Whx+bh\mathbf{z}_h = \mathbf{W}_h\mathbf{x} + \mathbf{b}_hzh=Whx+bh
其中,Wh\mathbf{W}_hWh 是隐藏层的权重矩阵,bh\mathbf{b}_hbh 是隐藏层的偏置向量。
隐藏层的输出通过激活函数进行非线性变换:
ah=f(zh)\mathbf{a}_h = f(\mathbf{z}_h)ah=f(zh)
常用的激活函数有 sigmoid 函数、ReLU 函数等。
输出层的输入和输出
输出层的输入可以表示为:
zo=Woah+bo\mathbf{z}_o = \mathbf{W}_o\mathbf{a}_h + \mathbf{b}_ozo=Woah+bo
其中,Wo\mathbf{W}_oWo 是输出层的权重矩阵,bo\mathbf{b}_obo 是输出层的偏置向量。
输出层的输出通过激活函数进行变换:
ao=g(zo)\mathbf{a}_o = g(\mathbf{z}_o)ao=g(zo)
详细讲解
在智能推荐系统中,我们的目标是通过调整权重矩阵 Wh\mathbf{W}_hWh 和 Wo\mathbf{W}_oWo 以及偏置向量 bh\mathbf{b}_hbh 和 bo\mathbf{b}_obo,使得模型的输出尽可能接近真实的用户行为数据。通常使用损失函数来衡量模型的预测结果与真实数据之间的差异,常用的损失函数有均方误差(MSE)和交叉熵损失函数。
举例说明
假设我们有一个简单的推荐系统,用户的特征向量 x=[0.2,0.3,0.5]T\mathbf{x} = [0.2, 0.3, 0.5]^Tx=[0.2,0.3,0.5]T,隐藏层有 2 个神经元,输出层有 1 个神经元。隐藏层的权重矩阵 Wh=[0.10.20.30.40.50.6]\mathbf{W}_h = \begin{bmatrix} 0.1 & 0.2 & 0.3 \\ 0.4 & 0.5 & 0.6 \end{bmatrix}Wh=[0.10.40.20.50.30.6],偏置向量 bh=[0.1,0.2]T\mathbf{b}_h = [0.1, 0.2]^Tbh=[0.1,0.2]T,激活函数为 ReLU 函数。
首先计算隐藏层的输入:
zh=Whx+bh=[0.10.20.30.40.50.6][0.20.30.5]+[0.10.2]=[0.240.59]\mathbf{z}_h = \mathbf{W}_h\mathbf{x} + \mathbf{b}_h = \begin{bmatrix} 0.1 & 0.2 & 0.3 \\ 0.4 & 0.5 & 0.6 \end{bmatrix} \begin{bmatrix} 0.2 \\ 0.3 \\ 0.5 \end{bmatrix} + \begin{bmatrix} 0.1 \\ 0.2 \end{bmatrix} = \begin{bmatrix} 0.24 \\ 0.59 \end{bmatrix}zh=Whx+bh=[0.10.40.20.50.30.6]
0.20.30.5
+[0.10.2]=[0.240.59]
然后计算隐藏层的输出:
ah=f(zh)=[max(0,0.24)max(0,0.59)]=[0.240.59]\mathbf{a}_h = f(\mathbf{z}_h) = \begin{bmatrix} \max(0, 0.24) \\ \max(0, 0.59) \end{bmatrix} = \begin{bmatrix} 0.24 \\ 0.59 \end{bmatrix}ah=f(zh)=[max(0,0.24)max(0,0.59)]=[0.240.59]
假设输出层的权重矩阵 Wo=[0.7,0.8]\mathbf{W}_o = [0.7, 0.8]Wo=[0.7,0.8],偏置向量 bo=0.1\mathbf{b}_o = 0.1bo=0.1,激活函数为 sigmoid 函数。
计算输出层的输入:
zo=Woah+bo=[0.7,0.8][0.240.59]+0.1=0.694\mathbf{z}_o = \mathbf{W}_o\mathbf{a}_h + \mathbf{b}_o = [0.7, 0.8] \begin{bmatrix} 0.24 \\ 0.59 \end{bmatrix} + 0.1 = 0.694zo=Woah+bo=[0.7,0.8][0.240.59]+0.1=0.694
计算输出层的输出:
ao=g(zo)=11+e−0.694≈0.667\mathbf{a}_o = g(\mathbf{z}_o) = \frac{1}{1 + e^{-0.694}} \approx 0.667ao=g(zo)=1+e−0.6941≈0.667
这个输出值表示用户对某个物品的喜欢程度,我们可以根据这个值来进行推荐。
项目实战:代码实际案例和详细解释说明
开发环境搭建
- 安装 Python:可以从 Python 官方网站下载并安装最新版本的 Python。
- 安装深度学习框架:这里我们使用 TensorFlow,可以使用以下命令进行安装:
pip install tensorflow
源代码详细实现和代码解读
我们以一个简单的电影推荐系统为例,使用 MovieLens 数据集进行训练和测试。
import tensorflow as tf
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
# 加载数据集
data = pd.read_csv('ml-100k/u.data', sep='\t', names=['user_id', 'item_id', 'rating', 'timestamp'])
# 数据预处理
scaler = MinMaxScaler()
data['rating'] = scaler.fit_transform(data[['rating']])
# 划分训练集和测试集
train_data, test_data = train_test_split(data, test_size=0.2, random_state=42)
# 构建输入层
user_input = tf.keras.Input(shape=(1,))
item_input = tf.keras.Input(shape=(1,))
# 嵌入层
user_embedding = tf.keras.layers.Embedding(input_dim=data['user_id'].nunique(), output_dim=16)(user_input)
item_embedding = tf.keras.layers.Embedding(input_dim=data['item_id'].nunique(), output_dim=16)(item_input)
# 扁平化
user_flat = tf.keras.layers.Flatten()(user_embedding)
item_flat = tf.keras.layers.Flatten()(item_embedding)
# 合并输入
merged = tf.keras.layers.Concatenate()([user_flat, item_flat])
# 隐藏层
hidden_layer = tf.keras.layers.Dense(32, activation='relu')(merged)
# 输出层
output_layer = tf.keras.layers.Dense(1, activation='sigmoid')(hidden_layer)
# 构建模型
model = tf.keras.Model(inputs=[user_input, item_input], outputs=output_layer)
# 编译模型
model.compile(optimizer='adam', loss='mse', metrics=['mae'])
# 训练模型
model.fit([train_data['user_id'], train_data['item_id']], train_data['rating'], epochs=10, batch_size=32)
# 评估模型
loss, mae = model.evaluate([test_data['user_id'], test_data['item_id']], test_data['rating'])
print(f"Test loss: {loss}, Test MAE: {mae}")
# 生成推荐
user_id = 1
item_ids = data['item_id'].unique()
predictions = model.predict([[user_id] * len(item_ids), item_ids])
top_recommendations = item_ids[predictions.flatten().argsort()[-10:][::-1]]
print(f"Top 10 recommendations for user {user_id}: {top_recommendations}")
代码解读与分析
- 数据加载和预处理:使用 Pandas 加载 MovieLens 数据集,并使用 MinMaxScaler 对评分数据进行归一化处理。
- 模型构建:使用 TensorFlow 的 Keras API 构建深度神经网络模型,包括嵌入层、隐藏层和输出层。
- 模型训练:使用训练数据对模型进行训练,设置训练的轮数和批量大小。
- 模型评估:使用测试数据对模型进行评估,计算损失函数和平均绝对误差。
- 推荐生成:选择一个用户,对所有物品进行预测,根据预测结果生成前 10 个推荐物品。
实际应用场景
电商平台
在电商平台上,深度学习可以根据用户的浏览历史、购买记录、收藏列表等信息,为用户推荐个性化的商品。例如,当用户浏览了一款手机后,推荐系统可以根据用户的其他行为信息,推荐相关的手机配件、手机保护套等商品。
视频网站
视频网站可以利用深度学习分析用户的观看历史、点赞、评论等行为,为用户推荐感兴趣的视频。比如,用户经常观看科幻电影,推荐系统就会为用户推荐新上映的科幻电影或者相关的科幻纪录片。
音乐平台
音乐平台可以根据用户的听歌历史、创建的歌单、收藏的歌曲等信息,为用户推荐喜欢的音乐。如果用户喜欢某一位歌手的歌曲,推荐系统可以推荐该歌手的其他歌曲或者风格相似的歌手的歌曲。
工具和资源推荐
深度学习框架
- TensorFlow:由 Google 开发的开源深度学习框架,具有丰富的工具和文档,适合初学者和专业开发者。
- PyTorch:由 Facebook 开发的开源深度学习框架,具有动态图的优势,代码简洁易懂,受到很多研究人员的喜爱。
数据集
- MovieLens:一个常用的电影推荐数据集,包含了用户对电影的评分信息。
- Amazon Product Reviews:亚马逊的商品评论数据集,可以用于商品推荐系统的研究。
学习资源
- Coursera 上的深度学习课程:由 Andrew Ng 教授主讲的深度学习课程,内容全面,适合初学者入门。
- 《深度学习》(花书):一本深度学习领域的经典书籍,详细介绍了深度学习的理论和方法。
未来发展趋势与挑战
未来发展趋势
- 多模态推荐:未来的智能推荐系统将不仅仅依赖于文本信息,还会结合图像、视频、音频等多模态信息,为用户提供更加丰富和准确的推荐。例如,在电商平台上,除了根据商品的文字描述进行推荐,还可以根据商品的图片和视频进行推荐。
- 强化学习在推荐系统中的应用:强化学习可以让推荐系统在与用户的交互过程中不断学习和优化推荐策略,提高推荐的效果。例如,通过奖励机制鼓励推荐系统推荐用户真正感兴趣的内容。
- 联邦学习:联邦学习可以在保护用户数据隐私的前提下,实现多个数据源之间的协同学习。在智能推荐系统中,不同的企业和机构可以在不共享用户数据的情况下,共同训练一个推荐模型,提高推荐的准确性。
挑战
- 数据隐私和安全:智能推荐系统需要收集大量的用户数据,这些数据包含了用户的个人信息和隐私。如何在保护用户数据隐私的前提下,有效地利用这些数据进行推荐是一个重要的挑战。
- 可解释性:深度学习模型通常是一个黑盒模型,很难解释模型的决策过程。在智能推荐系统中,用户希望了解推荐结果的依据,因此提高模型的可解释性是一个亟待解决的问题。
- 冷启动问题:当新用户或者新物品进入系统时,由于缺乏历史数据,推荐系统很难为其提供准确的推荐。如何解决冷启动问题,提高推荐系统的适应性是一个挑战。
总结:学到了什么?
核心概念回顾
- 我们学习了深度学习,它就像一个超级爱学习的小天才,能从大量数据中学习到规律和模式。
- 了解了智能推荐系统,它就像一个贴心的小秘书,能根据用户的信息为用户推荐个性化的内容。
- 还知道了数据特征,它就像每个人的特点,智能推荐系统通过分析数据特征来进行推荐。
概念关系回顾
- 深度学习和智能推荐系统就像侦探和信使,深度学习负责分析数据找到规律,智能推荐系统负责把这些规律应用到推荐中。
- 智能推荐系统和数据特征就像厨师和食材,智能推荐系统根据数据特征做出合适的推荐。
- 深度学习和数据特征就像科学家和实验材料,深度学习通过对数据特征的分析发现规律。
思考题:动动小脑筋
- 思考题一: 你能想到生活中还有哪些地方用到了智能推荐系统吗?
- 思考题二: 如果你要开发一个智能推荐系统,你会如何解决冷启动问题?
- 思考题三: 如何提高深度学习模型在智能推荐系统中的可解释性?
附录:常见问题与解答
问题一:深度学习在智能推荐系统中的优势是什么?
深度学习可以自动从大量数据中学习到复杂的模式和规律,能够处理高维、非线性的数据,从而提高推荐的准确性和个性化程度。
问题二:如何选择合适的深度学习模型用于智能推荐系统?
需要根据数据集的特点、问题的复杂度和性能要求等因素来选择。例如,如果数据具有序列性,可以选择循环神经网络(RNN);如果数据是图像或视频,可以选择卷积神经网络(CNN);对于一般的推荐问题,深度神经网络(DNN)是一个不错的选择。
问题三:智能推荐系统的推荐结果一定准确吗?
不一定。智能推荐系统的推荐结果受到多种因素的影响,如数据的质量、模型的性能、用户行为的变化等。因此,推荐结果只是一种参考,不能保证完全符合用户的需求。
扩展阅读 & 参考资料
- 《深度学习》(花书),作者:Ian Goodfellow、Yoshua Bengio、Aaron Courville
- 《推荐系统实践》,作者:项亮
- TensorFlow 官方文档:https://www.tensorflow.org/
- PyTorch 官方文档:https://pytorch.org/
更多推荐
 12
12 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)