
AI智能体开发实战:17种核心架构模式详解与Python代码实现
在构建一个大规模 AI 系统时,我们其实就是在把不同的“智能体设计模式(agentic design patterns)”组合起来。不管系统多复杂都可以拆解成有限的几种"设计模式"。这些模式各有各的用法——有的专门负责思考优化,有的处理工具调用,有的管多智能体协作。主要就这么几类:多智能体系统让不同角色分工协作;集成决策让多个智能体投票选最优解;思维树(ToT)探索多条推理路径再择优;反思式架构能
在构建一个大规模 AI 系统时,我们其实就是在把不同的“智能体设计模式(agentic design patterns)”组合起来。不管系统多复杂都可以拆解成有限的几种"设计模式"。这些模式各有各的用法——有的专门负责思考优化,有的处理工具调用,有的管多智能体协作。
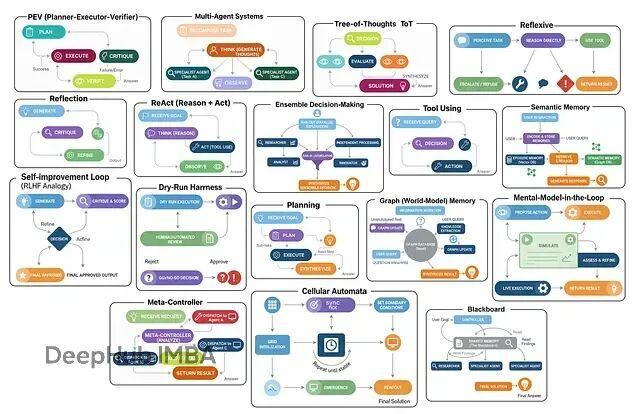
主要就这么几类:多智能体系统让不同角色分工协作;集成决策让多个智能体投票选最优解;思维树(ToT)探索多条推理路径再择优;反思式架构能自我审视和改进;ReAct循环在思考与行动间迭代。
本文将逐一深入解析这17种不同的智能体架构,不仅阐述其核心原理和设计思想,还将通过完整的代码实现来演示其工作机制,并用真实数据验证每种架构的实际效果和适用场景。
环境配置
开始之前得把工具链搞定。现在的RAG或智能体系统,LangChain、LangGraph和LangSmith基本成了标配——前者提供基础组件,LangGraph负责编排流程,LangSmith可以进行调试和监控。
导入
import os
from typing import List, Dict, Any, Optional, Annotated, TypedDict
from dotenv import load_dotenv # 从 .env 文件加载环境变量
# 用于数据建模/校验的 Pydantic
from pydantic import BaseModel, Field
# LangChain & LangGraph 组件
from langchain_nebius import ChatNebius # Nebius LLM 封装器
from langchain_tavily import TavilySearch # Tavily 搜索工具集成
from langchain_core.prompts import ChatPromptTemplate # 用于组织提示词
from langgraph.graph import StateGraph, END # 构建状态机图
from langgraph.prebuilt import ToolNode, tools_condition # 预置的节点与条件
# 便于更好地输出结果
from rich.console import Console # 终端样式化输出
from rich.markdown import Markdown # 在终端渲染 Markdown为了作为演示,我还接了Tavily API做实时搜索,避免智能体被训练数据的时效性限制住。每月1000次调用的免费额度已经够用了了。
环境变量这样配:
# Nebius LLM 的 API key(用于 ChatNebius)
NEBIUS_API_KEY="your_nebius_api_key_here"
# LangSmith(LangChain 观测/遥测平台)的 API key
LANGCHAIN_API_KEY="your_langsmith_api_key_here"
# Tavily 搜索工具(用于 TavilySearch 集成)的 API key
TAVILY_API_KEY="your_tavily_api_key_here"加载和验证:
load_dotenv() # 加载环境变量
# 启用 LangSmith 跟踪以便监控/调试
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = "Implementing 17 Agentic Architectures" # 用于分组轨迹的项目名
# 校验所需的 API key 是否齐全
for key in ["NEBIUS_API_KEY", "LANGCHAIN_API_KEY", "TAVILY_API_KEY"]:
if not os.environ.get(key): # 若环境变量中未找到
print(f"{key} not found. Please create a .env file and set it.")反思架构(Reflection)
反思可能是智能体工作流里最基础也最实用的模式。核心思路就是让智能体"退一步看自己的输出,然后想办法改进"。
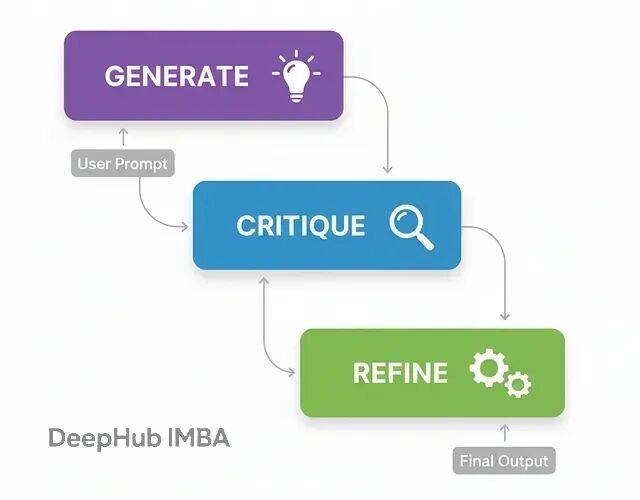
这个模式特别适合那种对结果质量要求很高的场景,比如生成复杂代码、写技术文档什么的。如果只给个草稿通常质量都不好,所以需要这个模式。
流程非常简单:
生成(Generate):基于用户需求先出个初版
批判(Critique):切换视角,从代码审查员的角度挑毛病
精炼(Refine):基于批评意见,输出改进版本
实现上用Pydantic模型来约束LLM的输出格式,这样多步骤之间的数据传递会更稳定:
class DraftCode(BaseModel):
"""Schema for the initial code draft generated by the agent."""
code: str = Field(description="The Python code generated to solve the user's request.") # 原始草稿
explanation: str = Field(description="A brief explanation of how the code works.") # 推理说明
class Critique(BaseModel):
"""Schema for the self-critique of the generated code."""
has_errors: bool = Field(description="Does the code have any potential bugs or logical errors?") # 错误排查
is_efficient: bool = Field(description="Is the code written in an efficient and optimal way?") # 性能/最佳实践检查
suggested_improvements: List[str] = Field(description="Specific, actionable suggestions for improving the code.") # 具体改进建议
critique_summary: str = Field(description="A summary of the critique.") # 评审概述
class RefinedCode(BaseModel):
"""Schema for the final, refined code after incorporating the critique."""
refined_code: str = Field(description="The final, improved Python code.") # 打磨后的版本
refinement_summary: str = Field(description="A summary of the changes made based on the critique.") # 修改说明Critique这个模型设计得比较巧妙,它强制智能体必须从错误检查、效率评估等具体维度来审视代码,而不是泛泛地说"看起来还行",这样保证了检查的质量。
生成器节点就是标准的prompt调用:
def generator_node(state):
"""Generates the initial draft of the code."""
console.print("--- 1. Generating Initial Draft ---")
# 初始化 LLM,并让其输出结构化 DraftCode 对象
generator_llm = llm.with_structured_output(DraftCode)
prompt = f"""You are an expert Python programmer. Write a Python function to solve the following request.
Provide a simple, clear implementation and an explanation.
Request: {state['user_request']}
"""
draft = generator_llm.invoke(prompt)
return {"draft": draft.model_dump()}批评节点是这个架构的核心,它让智能体作为"资深开发者"来审视自己刚写的代码:
def critic_node(state):
"""Critiques the generated code for errors and inefficiencies."""
console.print("--- 2. Critiquing Draft ---")
# 初始化 LLM,并让其输出结构化 Critique 对象
critic_llm = llm.with_structured_output(Critique)
code_to_critique = state['draft']['code']
prompt = f"""You are an expert code reviewer and senior Python developer. Your task is to perform a thorough critique of the following code.
Analyze the code for:
1. **Bugs and Errors:** Are there any potential runtime errors, logical flaws, or edge cases that are not handled?
2. **Efficiency and Best Practices:** Is this the most efficient way to solve the problem? Does it follow standard Python conventions (PEP 8)?
Provide a structured critique with specific, actionable suggestions.
Code to Review: {code_to_critique}
```
"""
critique = critic_llm.invoke(prompt)
return {"critique": critique.model_dump()}
精炼节点负责把批评意见落地成实际的代码改动:
def refiner_node(state):
"""Refines the code based on the critique."""
console.print("--- 3. Refining Code ---")
# 初始化 LLM,并让其输出结构化 RefinedCode 对象
refiner_llm = llm.with_structured_output(RefinedCode)
draft_code = state['draft']['code']
critique_suggestions = json.dumps(state['critique'], indent=2)
prompt = f"""You are an expert Python programmer tasked with refining a piece of code based on a critique.
Your goal is to rewrite the original code, implementing all the suggested improvements from the critique.
**Original Code:**
```python
{draft_code}
```
**Critique and Suggestions:**
{critique_suggestions}
Please provide the final, refined code and a summary of the changes you made.
"""
refined_code = refiner_llm.invoke(prompt)
return {"refined_code": refined_code.model_dump()}
用LangGraph把这三个节点串成工作流:
class ReflectionState(TypedDict):
"""Represents the state of our reflection graph."""
user_request: str
draft: Optional[dict]
critique: Optional[dict]
refined_code: Optional[dict]
初始化 state graph
graph_builder = StateGraph(ReflectionState)
添加节点
graph_builder.add_node("generator", generator_node)
graph_builder.add_node("critic", critic_node)
graph_builder.add_node("refiner", refiner_node)
线性流程
graph_builder.set_entry_point("generator")
graph_builder.add_edge("generator", "critic")
graph_builder.add_edge("critic", "refiner")
graph_builder.add_edge("refiner", END)
编译为可运行应用
reflection_app = graph_builder.compile()

拿经典的斐波那契数列来测试效果。这个问题很适合:因为简单递归容易写但效率极差,改进空间明显。
user_request = "Write a Python function to find the nth Fibonacci number."
initial_input = {"user_request": user_request}
console.print(f"[bold cyan]🚀 Kicking off Reflection workflow for request:[/bold cyan] '{user_request}'\n")
流式运行并获取最终状态
final_state = None
for state_update in reflection_app.stream(initial_input, stream_mode="values"):
final_state = state_update
console.print("\n[bold green]✅ Reflection workflow complete![/bold green]")
结果对比:
--- ### Initial Draft ---
Explanation: This function uses a recursive approach to calculate the nth Fibonacci number... This approach is not efficient for large values of n due to the repeated calculations...
1 def fibonacci(n):
2 if n <= 0:
3 return 0
4 elif n == 1:
5 return 1
6 else:
7 return fibonacci(n-1) + fibonacci(n-2)
--- ### Critique ---
Summary: The function has potential bugs and inefficiencies. It should be revised to handle negative inputs and improve its time complexity.
Improvements Suggested:
- The function does not handle negative numbers correctly.
- The function has a high time complexity due to the repeated calculations. Consider using dynamic programming or memoization.
- The function does not follow PEP 8 conventions...
--- ### Final Refined Code ---
Refinement Summary: The original code has been revised to handle negative inputs, improve its time complexity, and follow PEP 8 conventions.
1 def fibonacci(n):
2 """Calculates the nth Fibonacci number."""
3 if n < 0:
4 raise ValueError("n must be a non-negative integer")
5 elif n == 0:
6 return 0
7 elif n == 1:
8 return 1
9 else:
10 fib = [0, 1]
11 for i in range(2, n + 1):
12 fib.append(fib[i-1] + fib[i-2])
13 return fib[n]
初版是标准的递归实现,复杂度O(2^n),完全不实用。改进版改成动态规划,复杂度降到O(n),还加了输入验证和文档字符串。
为了量化改进效果,可以再加个评分机制:
class CodeEvaluation(BaseModel):
"""Schema for evaluating a piece of code."""
correctness_score: int = Field(description="Score from 1-10 on whether the code is logically correct.")
efficiency_score: int = Field(description="Score from 1-10 on the code's algorithmic efficiency.")
style_score: int = Field(description="Score from 1-10 on code style and readability (PEP 8). ")
justification: str = Field(description="A brief justification for the scores.")
def evaluate_code(code_to_evaluate: str):
prompt = f"""You are an expert judge of Python code. Evaluate the following function on a scale of 1-10 for correctness, efficiency, and style. Provide a brief justification.
Code:
```python
{code_to_evaluate}
```
"""
return judge_llm.invoke(prompt)
评分结果一目了然:
--- Evaluating Initial Draft ---
{
'correctness_score': 2,
'efficiency_score': 4,
'style_score': 2,
'justification': 'The function has a time complexity of O(2^n)...' }
--- Evaluating Refined Code ---
{
'correctness_score': 8,
'efficiency_score': 6,
'style_score': 9,
'justification': 'The code is correct... it has a time complexity of O(n)...' }
数据说明反思机制确实有效果,不是简单的表面修改。
## 工具调用架构(Tool Using)
没有外部工具的话,LLM只能依赖训练时的知识,无法访问实时数据或执行具体操作。工具调用架构就是为了解决这个问题。在生产级AI系统中,这几乎是必需的——不管是客服查询订单、金融系统获取股价,还是代码生成器执行测试都离不开工具集成。
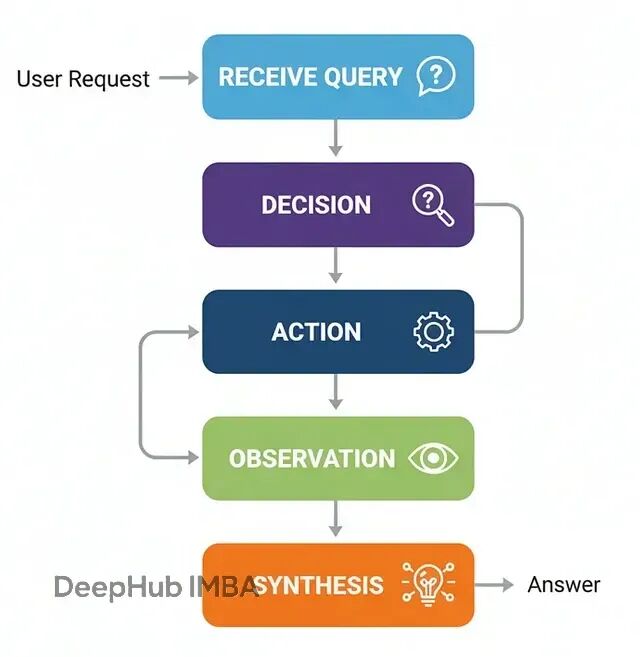
流程如下:
接收查询:智能体收到用户请求
决策分析:判断是否需要调用工具来获取信息
工具调用:按正确格式执行工具调用
结果处理:获取工具输出并整合
生成回复:结合工具结果给出最终答案
我们需要先配置一个搜索工具。这里用TavilySearch,并且工具描述要写清楚,LLM会根据这个自然语言描述来判断什么时候该用:
初始化工具。设置返回结果数量以保持上下文简洁。
search_tool = TavilySearchResults(max_results=2)
为工具提供明确的名称与描述,便于智能体理解
search_tool.name = "web_search"
search_tool.description = "A tool that can be used to search the internet for up-to-date information on any topic, including news, events, and current affairs."
tools = [search_tool]
智能体的状态结构比反思架构简单,就是维护消息历史:
class AgentState(TypedDict):
messages: Annotated[list[AnyMessage], add_messages]
不过最关键步骤是让LLM"感知"到工具的存在。用bind_tools把工具信息注入到系统提示中:
llm = ChatNebius(model="meta-llama/Meta-Llama-3.1-8B-Instruct", temperature=0)
绑定工具,使 LLM 具备"工具感知"
llm_with_tools = llm.bind_tools(tools)
LangGraph工作流需要两个核心节点:agent_node负责推理决策,tool_node负责执行工具:
def agent_node(state: AgentState):
"""主要节点:调用 LLM 决定下一步动作。"""
console.print("--- AGENT: Thinking... ---")
response = llm_with_tools.invoke(state["messages"])
return {"messages": [response]}
ToolNode 是 LangGraph 的预置节点,用于执行工具
tool_node = ToolNode(tools)
路由逻辑比较简单:检查最后一条消息是否包含tool_calls,有的话就去执行工具,否则就结束:
if hasattr(last_message, 'tool_calls') and last_message.tool_calls:
console.print("--- ROUTER: 检测到工具调用请求 ---")
return "call_tool"
else:
console.print("--- ROUTER: 准备输出最终答案 ---")
return "__end__"
整个的工作流就是把这些节点用LangGraph串起来。条件边的设计可以让智能体能在推理和工具调用间形成循环:
graph_builder = StateGraph(AgentState)
更多推荐

 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)