
YOLOv8【卷积创新篇·第29节】一文搞懂,Knowledge Distillation卷积知识蒸馏!
🏆 本文收录于 《YOLOv8实战:从入门到深度优化》,该专栏持续复现网络上各种热门内容(全网YOLO改进最全最新的专栏,质量分97分+,全网顶流),改进内容支持(分类、检测、分割、追踪、关键点、OBB检测)。且专栏会随订阅人数上升而涨价(毕竟不断更新),当前性价比极高,有一定的参考&学习价值,部分内容会基于现有的国内外顶尖人工智能AIGC等AI大模型技术总结改进而来,嘎嘎硬核。 ✨ 特惠福利
🏆 本文收录于 《YOLOv8实战:从入门到深度优化》,该专栏持续复现网络上各种热门内容(全网YOLO改进最全最新的专栏,质量分97分+,全网顶流),改进内容支持(分类、检测、分割、追踪、关键点、OBB检测)。且专栏会随订阅人数上升而涨价(毕竟不断更新),当前性价比极高,有一定的参考&学习价值,部分内容会基于现有的国内外顶尖人工智能AIGC等AI大模型技术总结改进而来,嘎嘎硬核。
✨ 特惠福利:目前活动一折秒杀价!一次订阅,永久免费,所有后续更新内容均免费阅读!
全文目录:
⏩ 0. 摘要
大家好呀,欢迎回到我们的《YOLOv8专栏》!👋 在前面的章节里,我们探索了各种为模型“瘦身”的极限技术,如二值化(BNN),但也感受到了随之而来的精度下降的“阵痛”。那么,有没有一种方法,能让小模型“继承”大模型的智慧,从而在保持轻量化的同时,也能拥有强大的性能呢?答案是肯定的!这就是我们今天要探讨的魔法——知识蒸馏(Knowledge Distillation, KD)。
它通过构建一个“教师-学生”的学习范式,将一个强大而复杂的教师网络(Teacher Network)所学到的知识,提炼并“蒸馏”给一个轻量级的学生网络(Student Network)。本文将从知识蒸馏的核心思想“暗知识”出发,深入剖析主流的蒸馏策略(基于响应、基于特征),并重点探讨如何在目标检测任务中巧妙地应用这些策略。最后,我们将提供一份详尽的YOLOv8知识蒸馏实战指南,带你一步步修改代码,为你的轻量级YOLOv8模型请来一位“良师”,见证其性能的显著飞跃!准备好开启这场知识的传承之旅了吗?🌟
⏩ 1. 上期回顾:Binary Neural Network二值卷积
小伙伴们,我们又见面啦!👋 在上一节 《YOLOv8【卷积创新篇·第28Binary Neural Network二值卷积》 中,我们一起探索了模型压缩的终极形态——二值化。通过将权重和激活值压缩到仅仅1-bit,我们实现了高达32倍的理论存储优化,并将复杂的乘加运算替换为了高效的位运算,为模型在极端资源受限设备上的部署打开了想象空间。
然而,我们也认识到,这种极限压缩的代价是显著的精度下降。BNN的训练过程充满挑战,模型表达能力的损失使得它在复杂任务上难以匹敌全精度模型。这不禁让我们思考:有没有一种方法,可以帮助这些“身材苗条”但“体质稍弱”的轻量级模型,弥补它们在性能上的短板呢?
答案是肯定的!今天我们要学习的知识蒸馏,正是解决这一问题的最佳方案之一。它不改变模型结构,而是通过一种更聪明的“训练方法”,将一个强大模型的“智慧”传授给轻量级模型。让我们看看这神奇的“知识传承”是如何发生的吧!🚀
⏩ 2. 核心思想:当小模型有了“名师指点”
2.1 “教师-学生”范式:知识的传承
知识蒸馏(KD)的核心思想非常符合直觉,它模拟了现实世界中“教师”与“学生”的教学过程:
- 教师网络 (Teacher Network):一个已经训练好的、庞大而复杂的模型。它可能因为参数量巨大、计算量过高而难以实际部署,但它在目标任务上拥有非常高的性能(例如,一个在COCO数据集上精度很高的YOLOv8x模型)。
- 学生网络 (Student Network):一个我们希望最终部署的、轻量级的模型。它结构简单、参数量少、计算速度快,但如果从零开始独立训练,其性能可能无法满足要求(例如,一个YOLOv8n或我们用GhostNet、ShuffleNet改造过的模型)。
知识蒸馏的目标,就是在训练学生网络的过程中,不仅仅使用数据集的真实标签(Ground Truth)进行监督,还要利用教师网络的输出作为额外的、更丰富的监督信号,学生网络的学习。
2.2 精髓所在:被忽略的“暗知识” (Dark Knowledge)
为什么教师网络的输出是“更丰富的监督信号”?这要归功于“深度学习教父” Geoffrey Hinton 提出的**“暗知识”(Dark Knowledge)**概念。
传统的训练方式使用硬标签(Hard Labels)。例如,对于一张猫的图片,其标签是 0, 1, 0, 0, ...](假设“猫”是第2类),这是一个非此即彼的one-hot向量。它告诉模型“这张图是猫”,但没有提供任何额外信息。
而一个训练好的教师网络,在预测这张图时,其输出(经过Softmax后)可能是一个软标签(Soft Labels),比如 [0.01, 0.9, 008, 0.005, ...]。这个软标签告诉我们:
- 这张图极大概率是猫(概率为0.9)。
- 它有那么一点点像狗(概率为0.08),但几乎不像汽车(概率为0.005)。
这种类别之间的相似性信息,就是所谓的“暗知识”。它揭示了数据结构中更深层次的关联性,这是硬标签无法提供的。学生网络通过学习这些软标签,不仅能学到“是什么”,还能学到“像什么,不像什么”,从而获得对数据更深刻的理解,更容易收敛到更好的状态。
2.3 知识蒸馏在目标检测中的价值
对于像YOLOv8这样的目标检测任务,知识蒸馏的价值尤其巨大:
- 提升小模型mAP:这是最直接的应用。一个经过蒸馏的YOLOv8n,其mAP可以显著超过独立训练的YOLOv8n,有时甚至能接近中等大小的YOLOv8s的性能。
- 弥补压缩损失:对于我们之前讨论过的量化、剪枝、二值化等压缩技术,知识蒸馏是恢复精度损失的黄金搭档。
- 加速收敛:教师网络提供了更丰富的梯度信息,可以帮助学生网络在训练初期更快地找到正确的优化方向。
⏩ 3. 主流蒸馏策略深度剖析
知识蒸馏的方法多种多样,但主要可以分为两大类:基于响应的蒸馏和基于特征的蒸馏。
3.1 基于响应的蒸馏 (Response-Based Distillation)
这是最经典、最原始的知识蒸馏形式,它关注教师和学生网络最终的输出。
3.1.1 温度缩放 (Temperature Scaling) 与软标签
为了让教师网络的输出包含更丰富的“暗知识”,而不是一个接近one-hot的尖锐分布,Hinton引入了**温度(Temperature, T)**这个超参数。在计算Softmax时,我们将原始的logits(送入Softmax前的数值)先除以一个温度T:
q i = exp ( z ) ∑ j exp ( z j / T ) q_i = \frac{\exp(z_)}{\sum_j \exp(z_j / T)} qi=∑jexp(zj/T)exp(z)
- 当
T = 1时,这就是标准的Softmax。 - 当
T > 1时,概率分布会变得更加平滑(soften)。T越高,分布越平滑,暗知识越明显。 - 当
T趋近于无穷大时,概率分布趋近于一个均匀分布。
在蒸馏时,我们会用一个较高的T(例如T=4或`T=20)来计算教师和学生的软标签,用于它们之间的知识传递。
3.1.2 蒸馏损失函数:KL散度
知识蒸馏的损失函数:
在知识蒸馏(Knowledge Distillation, KD)中,我们通常衡量 学生网络的软标签 与 教师网络的软标签 之间的差距。常用的指标是 KL 散度(Kullback–Leibler Divergence),用于衡量两个概率分布的差异。
总损失函数由两部分组成:
-
学生与真实标签的损失
- 学生网络在温度
T=1下使用硬标签计算标准损失 - 常见选择:交叉熵损失
- 记作: L C E L_{CE} LCE
- 学生网络在温度
-
学生与教师的蒸馏损失
- 学生网络和教师网络在温度
T > 1下输出的分布差异 - 使用 KL 散度 作为衡量标准
- 记作: L K L L_{KL} LKL
- 学生网络和教师网络在温度
总损失公式:
L t o t a l = ( 1 − λ ) ⋅ L C E ( y t r u e , p s t u d e n t T = 1 ) + λ ⋅ T 2 ⋅ L K L ( q t e a c h e r T > 1 , q s t u d e n t T > 1 ) L_{total} = (1 - \lambda) \cdot L_{CE}(y_{true}, p_{student}^{T=1}) + \lambda \cdot T^2 \cdot L_{KL}(q_{teacher}^{T>1}, q_{student}^{T>1}) Ltotal=(1−λ)⋅LCE(ytrue,pstudentT=1)+λ⋅T2⋅LKL(qteacherT>1,qstudentT>1)
其中:
- y t r u e y_{true} ytrue:真实标签(硬标签)
- p s t u d e n t p_{student} pstudent:学生网络在
T=1下的预测输出 - q s t u d e n t q_{student} qstudent:学生网络在
T>1下的预测输出 - q t e a c h e r q_{teacher} qteacher:教师网络在
T>1下的预测输出 - λ \lambda λ:平衡两部分损失的超参数
- T 2 T^2 T2:温度平方因子,用于保持不同温度下梯度量级一致
3.2 基于特征的蒸馏 (Feature-Based Distillation)
仅仅模仿最终的“答案”可能还不够。一个更强大的策略是让学生网络去模仿教师网络的**“思考过程”**,即模仿间层的 特征图(Feature Maps)。
3.2.1 模仿“思考过程”,而不仅仅是答案
基于中间层特征的知识蒸馏:
教师网络的中间层特征包含了从原始像素到高级语义的丰富层次化信息。
通过强迫学生网络的特征图去逼近教师网络的特征图,相当于为学生的学习提供了更底层、更结构性的指导。
这种方法在训练 非常深 或 非常小 的网络时尤其有效。
FitNets 方法:
代表性工作 FitNets 的核心思想是: 在网络的某些中间层(称为 hint layers),最小化教师和学生特征图之间的差异。
常用的损失函数是 L2 损失:
L F e a t u r e = ∑ l ∈ L s e l e c t e d ∣ f T l − f S l ∣ 2 2 L_{Feature} = \sum_{l \in L_{selected}} | f_T^l - f_S^l |_2^2 LFeature=l∈Lselected∑∣fTl−fSl∣22
3.2.2 核心挑战:特征对齐
一个直接的问题是,教师和学生的特征图尺寸、通道数可能不同,如何计算它们之间的差异?
- 尺寸不同:可以通过上采样/下采样操作(如插值、转置卷积)来统一尺寸。
- 通道同:通常在学生网络的特征图后面接一个1x1的卷积层,作为一个“适配器”(Adapter)或“回归器”(Regressor),将通道数变换到与教师网络一致。这个1x1卷积层也是可学习的。
⏩ 4. 知识蒸馏在YOLOv8中的定制化应用
现在,让我们把这些理论应用到YOLOv8这个具体的目标检测模型上。YOLO的输出头(Head)包含分类和回归两个分支,并且其网络结构(骨干、颈部)提供了丰富的中间特征,这为我们施展各种蒸馏策略提供了绝佳的舞台。
4.1 分类头蒸馏:学习更丰富的类别关系
这是基于响应的蒸馏的直接应用。我们可以提取YOLOv8检测头中负责分类的logits,然后使用带温度的KL散度损失来让学生网络模仿教师网络的分类输出。
4.2 回归头蒸馏:更精准的定位指导
对于负责边界框(bounding box)定位的回归分支,我们也可以进行蒸馏。教师网络预测的框通常比学生网络更精准。我们可以直接让学生网络预测的框去拟合教师网络预测的框。
- 损失函数:可以使用L2损失或GIoU/CIoU等更先进的IoU Loss来计算学生和教师预测框之间的差异。
- 注意点:通常只对教师网络认为“置信度较高”的预测框进行蒸馏,避免被教师的错误预测所干扰。
4.3 特征图蒸馏:YOLO性能提升的关键
对于YOLO这类复杂的检测模型,基于特征的蒸馏往往比基于响应的蒸馏要,效果也更好。因为检测任务高度依赖高质量的特征表示。
4.3.1 在何处蒸馏:骨干与颈部的关键节点
- 骨干网络 (Backbone):可以在每个下采样阶段(Stage)的输出处进行特征蒸馏。这能帮助学生网络学习到与教师网络相似的多尺度特征提取能力。
- 颈部网络 (Neck - FPN/PAN):颈部负责融合深层和浅层的特征,对检测小目标至关重要。对颈部输出的特征图进行蒸馏,可以帮助学生网络更好地进行多尺度特征融合。
4.3.2 蒸馏区域选择:只关注“重要”的地方
直接对整个特征图进行L2损失计算可能不是最优的。因为背景区域的特征可能包含大量“噪声”或无用信息。一些更先进的方法,如 FGD (Focal and Globalistillation),提出了焦点蒸馏的思想:
- 生成注意力图:利用教师网络的激活值或梯度,生成一个注意力图,该图上前景物体(尤其是难样本)区域的权重更高。
- 加权蒸馏:在计算特征图差异时,使用这个注意力图进行加权,让学生网络重点关注前景物体区域的特征学习,而忽略不重要的背景区域。
4.4 YOLOv8蒸馏架构图
下面的Mermaid图清晰地展示了可以在YOLOv8架构中应用蒸馏的各个位置:
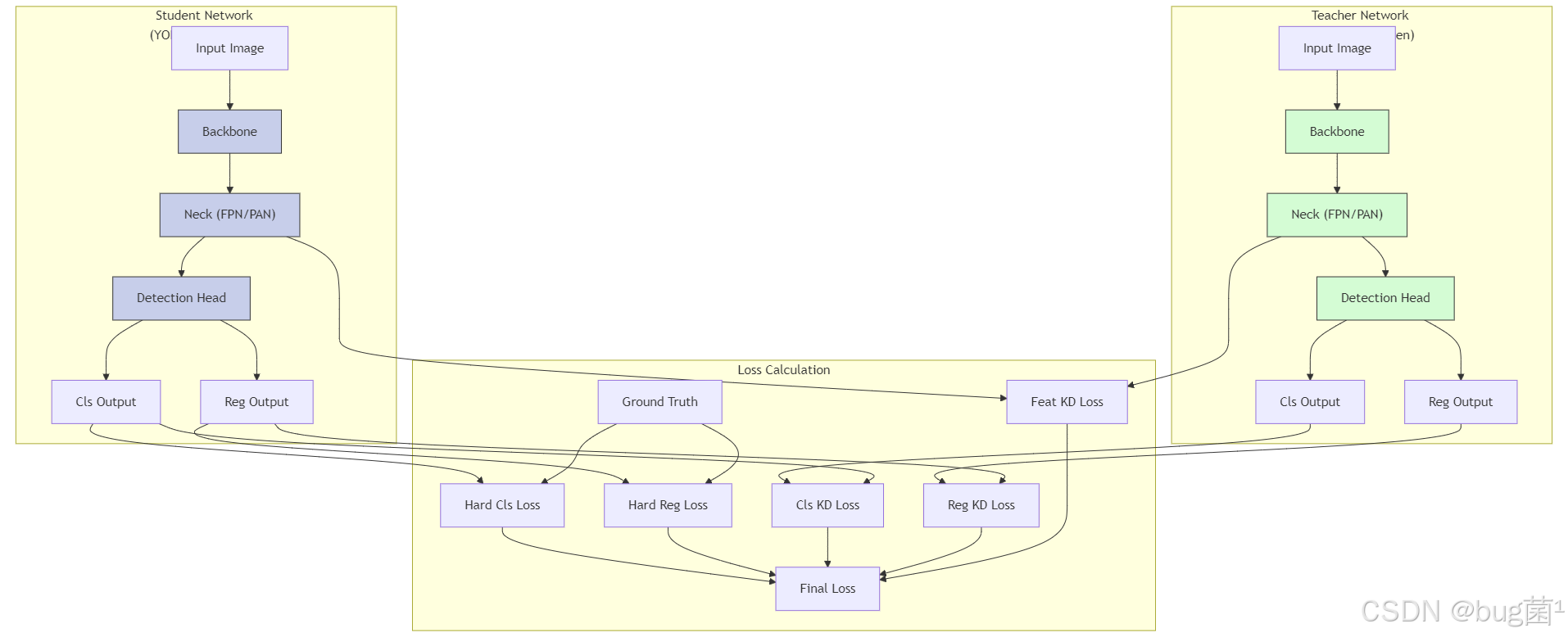
图解:红色的虚线代表不同类型的蒸馏损失,它们将教师网络的输出(分类、回归、特征)与学生网络的相应输出联系起来,共同指导学生网络的训练。
⏩ 5. YOLOv8知识蒸馏实战指南
免责声明:实现知识蒸馏需要对Ultralytics YOLOv8的源码进行一定的修改。这里的代码是教学性的,旨在清晰地展示核心逻辑和关键修改点,你需要根据你使用的YOLOv8版本进行适配。
5.1 准备工作:定义你的“教师”与“学生”
在你的训练脚本中,你需要同时加载教师和学生模型。
import torch
from ultralytics import YOLO
# 1. 加载一个强大的、预训练好的教师模型
teacher_model = YOLO('yolov8l.pt')
teacher_model.model.eval() # 设置为评估模式
teacher_model.model.cuda() # 移动到GPU
# 2. 定义并加载你的学生模型
student_model = YOLO('yolov8n.yaml') # 从配置文件构建
# 或者 student_model = YOLO('yolov8n.pt') # 从预训练权重开始
# 确保教师网络不参与梯度计算
for param in teacher_model.model.parameters():
param.requires_grad = False
5.2 核心改造:构建 `DistillationLoss 模块
最好的方式是创建一个新的损失类,它封装了YOLOv8的原始损失和我们新增的蒸馏损失。你需要修改ultralytics/utils/loss.py或在训练器中直接定义。
5.2.1 整体框架设计
import torch.nn as nn
import torch.nn.functional as F
from ultralytics.utils.metrics import BboxMetrics
from ultralytics.utils.loss import v8DetectionLoss, VarifocalLoss
class DistillationLoss:
def __init__(self, student_model, teacher_model, args):
self.student_loss = v8DetectionLoss(student_model) # YOLOv8的原始损失
self.teacher_model = teacher_model
# 定义各种蒸馏损失的权重
self.lambda_cls = args.kd_cls_loss_weight # e.g., 1.0
self.lambda_reg = args.kd_reg_loss_weight # e.g., 2.0
self.lambda_feat = args.kd_feat_loss_weight # e.g., 5.0
self.temperature = args.kd_temperature # e.g., 20.0
# 用于特征蒸馏的适配器
# (需要根据教师和学生特征图的通道数动态创建)
self.feature_adapters = self._create_feature_adapters(student_model, teacher_model)
def _create_feature_adapters(self, student, teacher):
# ... 此处逻辑:遍历需要蒸馏的层,
# 如果学生和教师的通道数不匹配,创建一个 nn.Conv2d(1, 1, ...)
# 并返回一个 nn.ModuleList
pass
def __call__(self, student_preds, teacher_preds, batch):
# 1. 计算学生模型的标准损失
loss_original, loss_items = self.student_loss(student_preds, batch)
# 2. 计算蒸馏损失
loss_kd_cls = self._calculate_cls_kd_loss(student_preds, teacher_preds)
loss_kd_reg = self._calculate_reg_kd_loss(student_preds, teacher_preds, batch)
loss_kd_feat = self._calculate_feat_kd_loss(student_preds['features'], teacher_preds['features'])
# 3. 组合损失
total_loss = loss_original +
self.lambda_cls * loss_kd_cls +
self.lambda_reg * loss_kd_reg +
self.lambda_feat * loss_kd_feat
# 返回总损失和各项损失的日志
return total_loss, {**loss_items, 'kd_cls': loss_kd_cls, 'kd_reg': loss_kd_reg, 'kd_feat': loss_kd_feat}
5.2.2 分类与回归蒸馏损失实现
# 在 DistillationLoss 类中
def _calculate_cls_kd_loss(self, s_preds, t_preds):
"""计算分类蒸馏损失 (KL散度)"""
# 提取分类预测 logits
s_cls_logits = s_preds['cls_logits'] # 假设模型输出一个包含logits的字典
t_cls_logits = t_preds['cls_logits'].detach()
# 使用温度进行Softmax
s_soft_labels = F.log_softmax(s_cls_logits / self.temperature, dim=-1)
t_soft_labels = F.softmax(t_cls_logits / self.temperature, dim=-1)
# 计算KL散度损失
# T^2 是为了保持梯度量级
loss = F.kl_div(s_soft_labels, t_soft_labels, reduction='batchmean') * (self.temperature ** 2)
return loss
def _calculate_reg_kd_loss(self, s_preds, t_preds, batch):
"""计算回归蒸馏损失 (例如 L2 loss)"""
# 提取回归预测
s_reg_preds = s_preds['reg_preds']
t_reg_preds = t_preds['reg_preds'].detach()
# ... 这里需要复杂的逻辑来匹配学生和教师的预测框 ...
# 一个简化的思路:只对真值框(GT Box)附近的预测进行蒸馏
# 伪代码:
# 1. 获取 GT boxes
# 2. 对每个GT, 找到教师和学生网络中与之匹配的预测框
# 3. 计算这些匹配的预测框之间的 L2 或 GIoU 损失
# 简化实现:直接计算所有预测框的L2损失(效果可能不佳,但用于演示)
loss = F.mse_loss(s_reg_preds, t_reg_preds, reduction='mean')
return loss
5.2.3 特征蒸馏损失实现
# 在 DistillationLoss 类中
def _calculate_feat_kd_loss(self, s_feats, t_feats):
"""计算特征图蒸馏损失 (L2 Loss)"""
loss = 0.0
# s_feats 和 t_feats 是包含多个尺度特征图的列表
for i, (s_f, t_f) in enumerate(zip(s_feats, t_feats)):
t_f = t_f.detach()
# 通过适配器对齐通道数
s_f = self.feature_adapters[i](s_f)
# 对齐空间尺寸 (如果需要)
if s_f.shape != t_f.shape:
s_f = F.interpolate(s_f, size=t_f.shape[2:], mode='bilinear', align_corners=False)
loss += F.mse_loss(s_f, t_f, reduction='mean')
return loss
5.3 关键步骤:修改训练流程
你需要修改训练器(ultralytics/engine/trainer.py)的核心训练循环。
5.3.1 同时执行教师与学生网络的前向传播
在训练的每一步,你需要从数据加载器获取一个批次的数据,然后分别送入教师和学生网络。
# 在 Trainer._do_train 或类似方法中
...
self.student_model.train() # 学生模型设为训练模式
self.teacher_model.eval() # 教师模型设为评估模式
# ... 获取数据批次 batch ...
# 学生网络前向传播
student_preds = self.student_model(batch['img'])
# 教师网络前向传播,不计算梯度
with torch.no_grad():
# 为了获取中间特征,可能需要修改模型的forward方法
# 或者使用hook来捕获特征
# Ultralytics的YOLO类支持 `visualize=True`来返回特征
teacher_preds = self.teacher_model.model(batch['img'], visualize=True)
注意:为了从教师网络获取中间特征图,你可能需要修改YOLO.forward方法或使用PyTorch的hooks。一个简单的技巧是,修改模型定义文件,让模型的forward方法不仅返回最终预测,还返回指定层的特征图。
5.3.2 整合蒸馏损失与原始损失
将两个网络的输出都传给你的DistillationLoss实例。
# 接上文
# 假设 student_preds 和 teacher_preds 都是包含预测和特征的字典
loss, loss_items = self.distill_loss(student_preds, teacher_preds, batch)
# 后续的反向传播和优化器步骤不变
...
loss.backward()
self.optimizer.step()
5.3.3 训练循环伪代码
# 初始化教师、学生模型和蒸馏损失计算器
teacher = init_teacher_model()
student = init_student_model()
distill_loss_calculator = DistillationLoss(student, teacher, args)
optimizer = init_optimizer(student)
# 开始训练循环
for epoch in range(num_epochs):
for batch in train_loader:
# 1. 前向传播
student_output = student(batch['img'], return_features=True)
with torch.no_grad():
teacher_output = teacher(batch['img'], return_features=True)
# 2. 计算总损失
total_loss, loss_dict = distill_loss_calculator(
student_preds=student_output,
teacher_preds=teacher_output,
batch=batch
)
# 3. 反向传播与优化(只更新学生模型)
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
# 4. 记录日志
log(loss_dict)
⏩ 6. 实验结果分析与实用技巧
6.1 预期效果:学生模型的显著提升
正确实施知识蒸馏后,你应该能观察到:
- mAP提升:学生模型(如YOLOv8n)的最终mAP会比未使用蒸馏时高出几个百分点。
- 收敛加快:在训练初期,模型的性能提升速度可能更快。
- 更好的泛化:蒸馏后的模型通常具有更好的泛化能力。
6.2 蒸馏“炼丹”技巧 (Tips)
知识蒸馏的效果很大程度上取决于超参数的调整,这很像“炼丹”!😉
- 教师的选择:不一定“越强越好”。教师和学生之间的“知识鸿沟”不宜过大。如果学生模型太小,可能无法有效学习一个过于强大的教师。用YOLOv8l指导YOLOv8n通常比用一个巨大的Transformer模型指导YOLOv8n效果更好。
- 权重 (
λ) 的调整:这是最重要的超参数。通常可以从lambda_cls=1.0,lambda_reg=1.0,lambda_feat=1.0开始,然后根据各项损失的大小和收敛情况进行调整。特征蒸馏的权重通常可以设置得更高一些。 - **温度 (
T) 的选择:T值越高,软标签越平滑。常见取值范围在[4, 20]之间。可以从小到大尝试。 - 分阶段蒸馏:可以先只用特征蒸馏训练一段时间,帮助学生网络打好特征基础,然后再加入分类和回归蒸馏。
- 从预训练学生开始:使用一个在目标数据集上已经收敛得不错的学生模型作为初始权重,再进行蒸馏训练,通常比从零开始蒸馏效果更好、更稳定。
⏩ 7. 全文总结
太棒了!你又一次坚持到底,完成了对知识蒸馏这项强大技术的全面学习!👍
在本节中,我们从“教师-学生”的生动比喻入手,理解了知识蒸馏的核心——传递“暗知识”。我们深入剖析了基于响应和**基于特征两大主流蒸馏策略,并详细探讨了它们在YOLOv8检测任务中的具体应用,包括如何蒸馏分类、回归和至关重要的中间特征。
更重要的是,我们通过一份详尽的实战指南,了解了将知识蒸馏集成到YOLOv8代码库中的关键步骤:从创建教师和学生模型,到构建自定义的DistillationLoss,再到修改训练循环。最后,我们还分享了许多宝贵的“炼丹”技巧。
知识蒸馏是一个极其强大的性能提升工具。它优雅地将大模型的智慧迁移到小模型中,是模型压缩、轻量化道路上不可或缺的一环。掌握了它,你就拥有了在不增加任何推理成本的情况下,显著提升模型性能的“独门秘籍”!💖
⏩ 8. 下期预告:卷积创新技术综合评估与选择指南
在过去的二十多个章节里,我们一起遨游在卷积创新的海洋中,从轻量化的GhostConv、Shuffleet,到动态的DynamicConv,再到注意力加持的SE, CA,以及最新的DCNv4\,我们学习了数十种令人眼花缭乱的卷积变体。
现在,一个非常实际的问题摆在了我们面前:面对我的具体任务,到底择哪种卷积技术呢?
- 是追求极致的速度?还是最高的精度?或是在二者之间找到最佳平衡?
- 不同的技术适用于哪些场景?(例如,小目标检测、移动端部署、遥感图像…)
- 它们的实现复杂度如何?会给训练带来哪些挑战?
在**《YOLOv8专栏》【卷积创新篇】的收官之作**—— 0节《卷积创新技术综合评估与选择指南》 中,我们将对之前介绍的所有卷积创新技术进行一次全面的横向评梳理。我们将从性能、速度、参数量、适用场景、实现难度等多个维度出发,为你提供一份清晰、实用的技术选型手册。这将是我们“卷积创新篇”的完美句点,帮助你将所学知识融会贯通,真正做到游刃有余地为你的YOLOv8“魔改”升级!敬请期待这场干货满满的最终总结!✨✨✨
希望本文所提供的YOLOv8内容能够帮助到你,特别是在模型精度提升和推理速度优化方面。
PS:如果你在按照本文提供的方法进行YOLOv8优化后,依然遇到问题,请不要急躁或抱怨!YOLOv8作为一个高度复杂的目标检测框架,其优化过程涉及硬件、数据集、训练参数等多方面因素。如果你在应用过程中遇到新的Bug或未解决的问题,欢迎将其粘贴到评论区,我们可以一起分析、探讨解决方案。如果你有新的优化思路,也欢迎分享给大家,互相学习,共同进步!
🧧🧧 文末福利,等你来拿!🧧🧧
文中讨论的技术问题大部分来源于我在YOLOv8项目开发中的亲身经历,也有部分来自网络及读者提供的案例。如果文中内容涉及版权问题,请及时告知,我会立即修改或删除。同时,部分解答思路和步骤来自全网社区及人工智能问答平台,若未能帮助到你,还请谅解!YOLOv8模型的优化过程复杂多变,遇到不同的环境、数据集或任务时,解决方案也各不相同。如果你有更优的解决方案,欢迎在评论区分享,撰写教程与方案,帮助更多开发者提升YOLOv8应用的精度与效率!
OK,以上就是我这期关于YOLOv8优化的解决方案,如果你还想深入了解更多YOLOv8相关的优化策略与技巧,欢迎查看我专门收集YOLOv8及其他目标检测技术的专栏《YOLOv8实战:从入门到深度优化》。希望我的分享能帮你解决在YOLOv8应用中的难题,提升你的技术水平。下期再见!
码字不易,如果这篇文章对你有所帮助,帮忙给我来个一键三连(关注、点赞、收藏),你的支持是我持续创作的最大动力。
同时也推荐大家关注我的公众号:「猿圈奇妙屋」,第一时间获取更多YOLOv8优化内容及技术资源,包括目标检测相关的最新优化方案、BAT大厂面试题、技术书籍、工具等,期待与你一起学习,共同进步!
🫵 Who am I?
我是bug菌,CSDN | 掘金 | InfoQ | 51CTO | 华为云 | 阿里云 | 腾讯云 等社区博客专家,C站博客之星Top30,华为云多年度十佳博主,掘金多年度人气作者Top40,掘金等各大社区平台签约作者,51CTO年度博主Top12,掘金/InfoQ/51CTO等社区优质创作者;全网粉丝合计 30w+;更多精彩福利点击这里;硬核微信公众号「猿圈奇妙屋」,欢迎你的加入!免费白嫖最新BAT互联网公司面试真题、4000G PDF电子书籍、简历模板等海量资料,你想要的我都有,关键是你不来拿。

-End-
更多推荐
 11
11 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)