
学习华为昇腾AI教材深度学习和大模型基础部分Day3
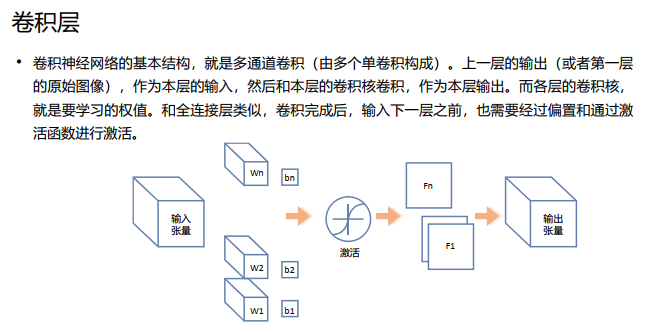
卷积神经网络是一种前馈神经网络,他的神经元可以,即避免了对图像的复杂前期预处理,可以直接输入原始图像。卷积神经网络主要分为三部分,即对图像(不同的数据窗口数据)和滤波矩阵(一组固定的权重:因为每个神经元的权重固定,所以又可以看做一个恒定的滤波器filter(kernel))做内积(逐个元素相乘再求和)的操作就是所谓的卷积操作,也是卷积神经网络的名字来源。
03卷积神经网络
一、概念
卷积神经网络是一种前馈神经网络,他的神经元可以响应一部分覆盖范围内的单元,即避免了对图像的复杂前期预处理,可以直接输入原始图像。卷积神经网络主要分为三部分,即卷积层、池化层、全连接层。
对图像(不同的数据窗口数据)和滤波矩阵(一组固定的权重:因为每个神经元的权重固定,所以又可以看做一个恒定的滤波器filter(kernel))做内积(逐个元素相乘再求和)的操作就是所谓的卷积操作,也是卷积神经网络的名字来源。
二、核心思想
局部感知:由于图像的空间联系也是局部的像素联系较为紧密,而距离较远的像素相关性则较弱,因此每个神经元没有必要对全局图像进行感知。
参数共享:卷积核自带的参数就是权重,权值共享一位置每一个卷积核在遍历整个图像的时候,卷积核的参数是固定不变的。
三、卷积神经网络架构
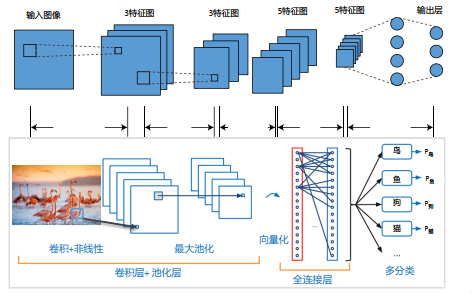
输入层,用于数据的输入。
卷积层,卷积神经网路中每层卷积层由若干卷积单元组成,每个卷积单元的参数都是通过反向传播算法优化得到的。卷积运算的目的是提取输入的 不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网络能从低级特征中迭代提取更复杂的特征。
线性整流层,这一层神经的活性化函数使用线性整流即ReLU: f(x)=max(0,x)。
池化层,通常在卷积层之后会得到维度很大的特征,将特征切成几个区域,取其最大值或平均值,得到新的、维度较小的特征。
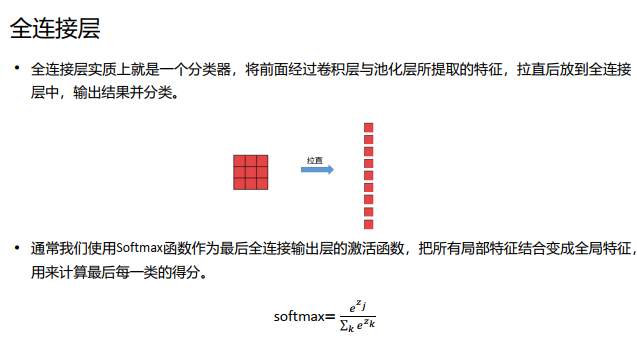
全连接层, 把所有局部特征结合变成全局特征,用来计算最后每一类的得分。
输出层,用于输出最终结果。
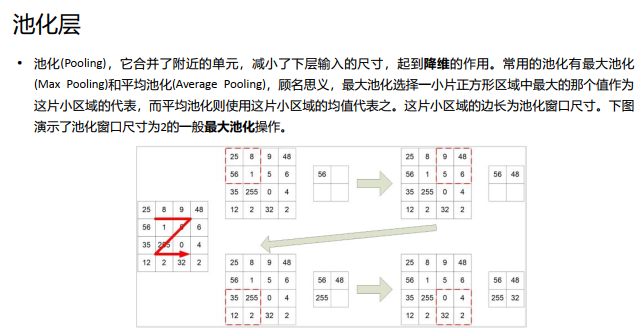
实际的分类网络,基本上都是卷积层和池化层交替互联,形成的前馈网络。 池化层有如下作用: 不变性: MaxPooling在一定范围内保证了不变性,因为一片区域的最大值无论 在这篇区域的何处,最后输出都是它。 减小下一层输入大小: Pooling有效降低了下一层输入数据的尺寸,减少了参数 个数,减小了计算量。 获得定长数据:通过合理设置Pooling的窗口尺寸和Stride,可以在变长输入中得 到定长的输出。 增大尺度:相当于扩大了尺度,可以从更大尺度上提炼上一层的特征。 防止过拟合: Pooling简化了网络,降低了拟合的精度,因此可以防止过拟合 (注意有可能带来的欠拟合)。
04基于循环神经网络RNN的模型架构
一、RNN
循环神经网络(RNN) 是一种通过隐藏层节点周期性的连接, 来捕捉序列化数据中动态信息的神经网络, 可以对序列化的数据进行分类。
和其他前向神经网络不同, RNN可以保存一种上下文的状态, 甚至能够在任意长的上下文窗口中存储、 学习、 表达相关信息, 而且不再局限于传统神经网络在空间上的边界, 可以在时间序列上有延拓, 直观上讲, 就是本时间的隐藏层和下一时刻的隐藏层之间的节点间有边。
RNN广泛应用在和序列有关的场景, 如一帧帧图像组成的视频, 一个个片段组成的音频, 和一个个词汇组成的句子。

标准RNN结构解决了信息记忆的问题, 但是对长时间记忆的信息会衰减。 很多任务需要保存长时间的记忆信息,如推理小说开头埋下的伏笔,可能到结尾时候才解答。 在记忆单元容量有限的情况下, RNN会丢失长时间间隔的信息。 我们希望记忆单元能够选择性记住重点信息。
二、LSTM长短记忆性网络
LSTM核心知识点:遗忘门。 LSTM中的第一步是决定从细胞状态中丢弃什么信息。这个决定通过遗忘门完成。 该门会读取ℎ𝑡−1和𝑥𝑡, 输出一个在0到1之间的数值给每个在细胞状态 𝐶𝑡−1中的数字。 1表示“完全保留” , 0表示“完全舍弃” 。
LSTM核心知识点:输入门 。这一步确定什么样的新信息被存放在细胞状态中。 这里包含两个部分:Sigmoid层称“输入门层”决定什么值将要更新; 一个tanh层创建一个新的候选值向量,会被加入到状态中。
LSTM核心知识点:更新信息。更新旧细胞状态的时间: 𝐶𝑡−1更新为𝐶𝑡。 我们把旧状态与𝑓𝑡相乘, 丢弃掉我们确定需要丢弃的信息。 接着加上𝑖𝑡*𝐶𝑡。 这就是新的候选值,根据我们决定更新每个状态的程度进行变化。
LSTM核心知识点:输出门。运行一个Sigmoid层来确定细胞状态的哪个部分将输出出去。 接着, 细胞状态通过tanh进行处理(得到一个在-1到1之间的值) 并将它和Sigmoid门的输出相乘, 最终我们仅仅会输出我们确定输出的那部分。
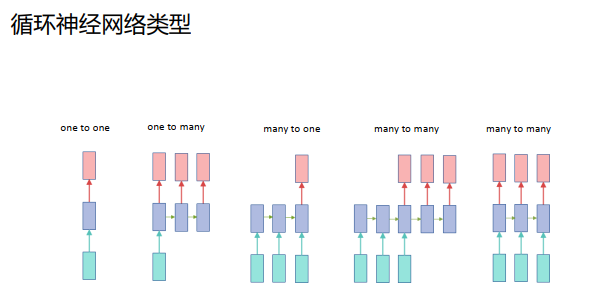
三、Seq2Seq
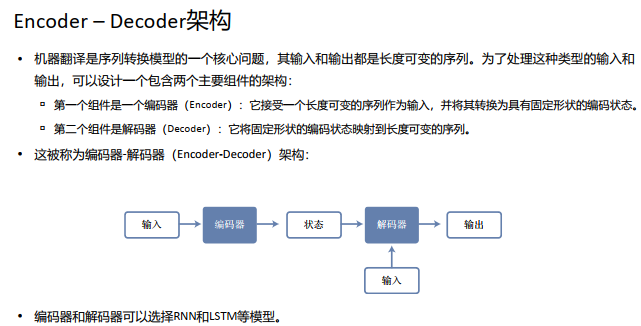
Seq2Seq(是 Sequence-to-sequence 的缩写即序列到序列学习) , 输入一个序列, 输出另一个序列。 它是一个典型的 Encoder-Decoder模型, 编码器对输入数据进行编码, 解码器对被编码的数据进行解码。 同时, 它也是一种时序问题解决方案。蓝色为编码部分, 第一个<eos>表示编码结束。 白色为解码部分, <bos>是第一个输入, 表示解码 开始, 第二个<eos>表示解码结束。


Seq2Seq的应用 – 机器翻译
虽然Seq2Seq能解决序列问题, 但是它依然存在一些问题: Encoder 和 Decoder 之间只有一个向量 C来传递信息,且 C 的长度固定。 语义向量无法完全表示整个序列的信息: c长度固定,如果输入数据过长,数据被压缩到指定长度, 会丢失信息,输入越长,压缩越大,丢失的信息越多。 当句子长度较大时,容易丢失信息:通过RNN编码得到的c,会逐渐丢失前面的信息。 基于 RNN 的 Seq2Seq 模型不能并行计算,效率低。 由于RNN计算t时刻数据时,都需要上一时刻的输出,因此无法实现高度并行。基于CNN的Seq2Seq参数量较大,训练复杂。推理过程中,必须要先输出前一个词才能预测下一个词,推理速度慢。
05Transformer架构
从Seq2Seq的缺陷中我们能够了解其所存在的问题,所以,我们如何解决这种缺陷呢?
通过引入Attention机制, Attention(注意力) 机制其实来源于人类的认知能力。 比如当人们观察一个场景或处理 一件事情时, 人们往往会关注场景的显著性物体, 处理事情时则希望抓住主要矛盾。 注意力机制使得人类能够关注事物的重要部分, 忽略次要部分, 更高效的处理所面临的各 种事情。即相当于哲学中的抓住主要矛盾,忽略次要矛盾,就是“抓大头”。
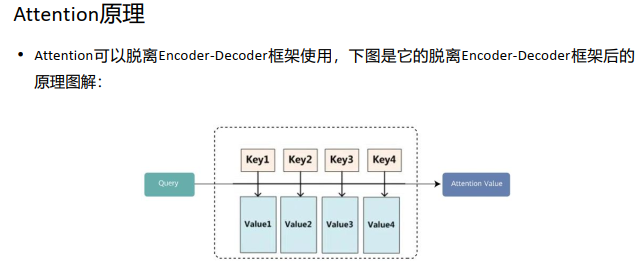
Attention在现实中的理解:图书馆(source) 里有很多书(value) , 为了方便查找, 我们给书做了编号(key) 。 当 我们想要了解漫威(query) 的时候, 我们就可以看看那些动漫、电影、 甚至二战(美国队长)相关的书籍。
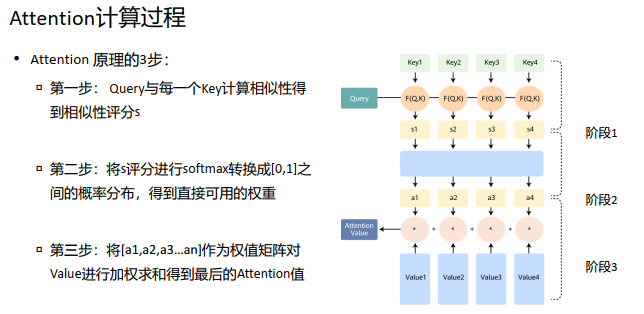
从上面的建模,我们可以大致感受到 Attention 的思路简单, 四个字“带权求和”就可以高度概括,大道至简。做个不太恰当的类比,人类学习一门新语言基本经历四个阶段:死记硬背(通过阅读背诵学习语法练习语感) ->提纲挈领(简单对话靠听懂句子中的关键词汇准确理解核心意思) ->融会贯通(复杂对话懂得上下文指代、语言背后的联系,具备了举一反三的学习能力) ->登峰造极(沉浸地大量练习)。这也如同attention的发展脉络, RNN 时代是死记硬背的时期, attention 的模型学会了提纲挈领,进化到transformer,融汇贯通,具备优秀的表达学习能力,再到 GPT、 BERT,通过多任务大规模学习积累实战经验,战斗力爆棚。
注意力机制的三大优点是: 参数少:模型复杂度跟 CNN、 RNN 相比,复杂度更小,参数也更少。所以对算力的要求也就更小。 速度快: Attention 解决了 RNN 不能并行计算的问题。 Attention机制每一步计算不依赖于上一步的计算结 果,因此可以和CNN一样并行处理。 效果好:在 Attention 机制引入之前,长距离的信息会被弱化,就好像记忆能力弱的人,记不住过去的事情是一样的。
2017年谷歌在一篇名为《Attention Is All You Need》 的论文中,提出了一个基于Attention(自注意力机制)结构来处理序列相关的问题的模型, 名为Transformer。
Transformer在很多不同NLP任务中获得了成功, 例如:文本分类、 机器翻译、 阅读理解等。
在解决这类问题时, Transformer模型摒弃了固有的定式, 并没有用任何CNN或者RNN的结构, 而是使用了Attention注意力机制, 自动捕捉输入序列不同位置处的相对关联, 善于处理较长文本, 并且该模型可以高度并行地工作, 训练速度很快。


06大模型基础架构
随着计算能力的提升和数据量的增长, 训练更大更深的神经网络成为了可能。 以 GPT系列、 LLaMA、GLM等为代表的大模型, 通过海量的数据和计算资源, 训练出了具有强大生成能力和泛化能力的模型。 这些模型不仅能够在单一任务上取得优异性能, 还能够通过微调的方式, 快速适应新的任务和数据。这就是大模型阶段。
OpenAI的第一个版本的GPT-1当时称之为GPT。
使用Transformer而不使用LSTM在于, 虽然预训练有助于捕获一些语言信息,但LSTM 模型限制了他们在短期内的预测能力。相反, Transformer的选择使我们能够捕获更长远的语言结构,同时在其他不同的任务中泛化性能更好。
GPT-1使用的是Transformer的Decoder框架。
GPT-1 保留了Decoder的Masked Multi-Attention 层和Feed Forward层,并扩大了网络的规模。将层数扩展到12层, GPT-1还将Attention 的维数扩大到768(原来为512),将 Attention的头数增加到12层(原来为8层),将Feed Forward层的隐层维数增加到3072 (原来为2048),总参数达到1.17亿。
对于位置编码的部分,实际上GPT-1和普通的Transformer的区别还是很大的,普通的 Transformer的位置编码,是由余弦+正弦的方式表示出来的,而GPT-1中,采用与词向量相似的随机初始化,并在训练中进行更新,即是把每一个位置当做一个要学习的 embedding来做。
BERT于2018年发布, 是一种双向模型, 它分析完整序列的上下文, 然后进行预测。 该模型在纯文本语料库和 Wikipedia 上 进行训练, 使用了 33 亿个单词 和3.4亿个参数。 BERT可以回答问题、 预测语句和翻译文本。
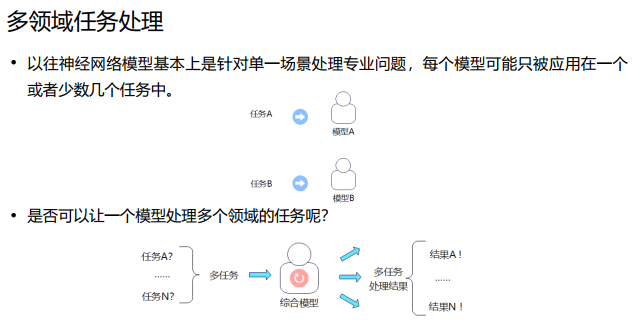
在实际的数据分布中,存在着很多天然的子集,如不同的domain、 topic,不同的语言、 不同的模态等等,在使用单个模型进行学习,且模型capacity较小的情况下,不同子 集会起到噪声的作用,干扰模型的拟合,导致模型训练慢、泛化困难。
对于传统的学习模型来说,训练的主要目的是使最终模型能够在不同的场景下执行多 种任务。但这种训练方式也使得模型在对相应场景进行权重更新的同时,也会影响到 模型对其它场景的权重。这种权重的互相影响称为干扰效应 。 干扰效应越强,模型的学习速率越慢,而且最终模型的泛化性也会越差。
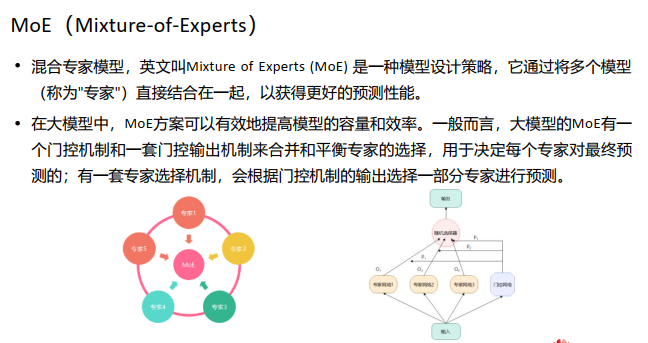
模型规模是提升模型性能的关键因素之一,这也是为什么今天的大模型能取得成功。 在有限的计算资源预算下,用更少的训练步数训练一个更大的模型,往往比用更多的步数训练一个较小的模型效果更佳。
MoE 的一个显著优势是它们能够在远少于 Dense 模型所需的计算资源下进行有效的预训练。这意味着在相同的计算预算条件下,您可以显著扩大模型或数据集的规模。特别是在预训练阶段,与稠密模型相比,混合专家模型通常能够更快地达到相同的质量水平。
更多推荐

 14
14 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)