
2025云栖大会,阿里亮出王牌,万亿参数和全模态大模型齐发,我直接好家伙!
阿里不愧为原神
这是苍何的第 436 篇原创!
大家好,我是苍何。
还是做博主好,有机会能来阿里云栖大会。
要知道,以前我只能一边搬砖一边云参展。
更别提,还能受邀参与直播探展了。

逛完展,给我最大的感受是震撼,今年能明显感觉到越来越多的 Agent 和 AI 应用出来了。

这个机器人做的拉花咖啡很有意思,自拍后通过阿里云函数计算,调用Qwen-Image 生成卡通形象,然后给机器人做拉花咖啡。
这么多的应用底层都离不开大模型的加持,这次逛展发现,阿里又发布了不少新东西。
千问 3 家族又迎来了不少新成员,先给大家介绍下:
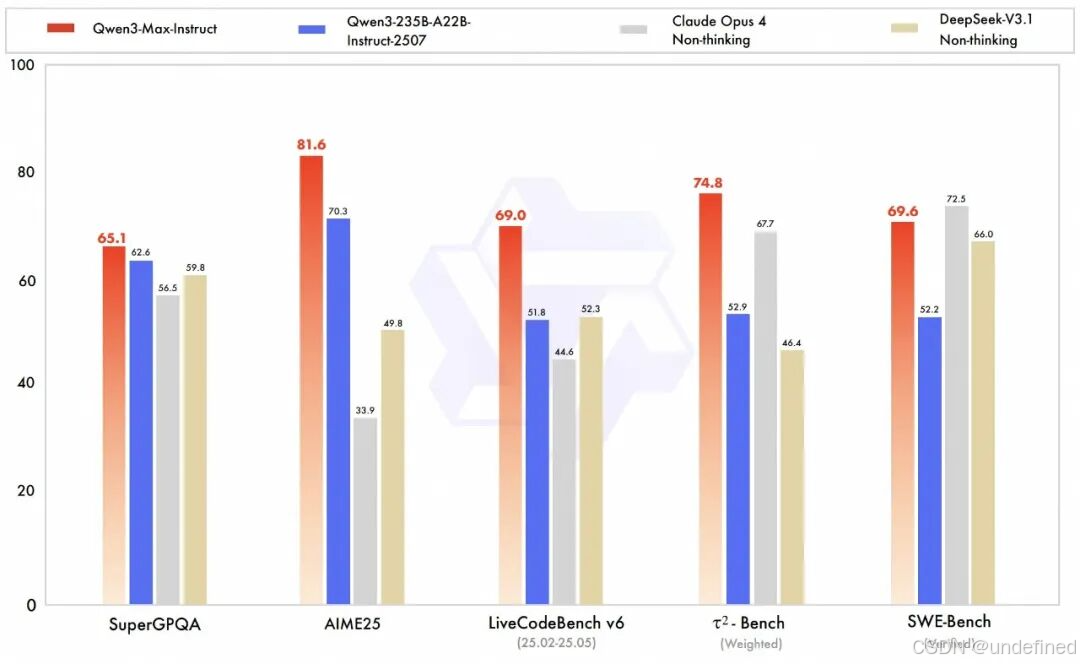
1、Qwen3 Max:拥有超万亿参数,是目前为止通义千问家族中最大、最强的模型,在多项主流权威基准测试中展现出全球领先的性能;
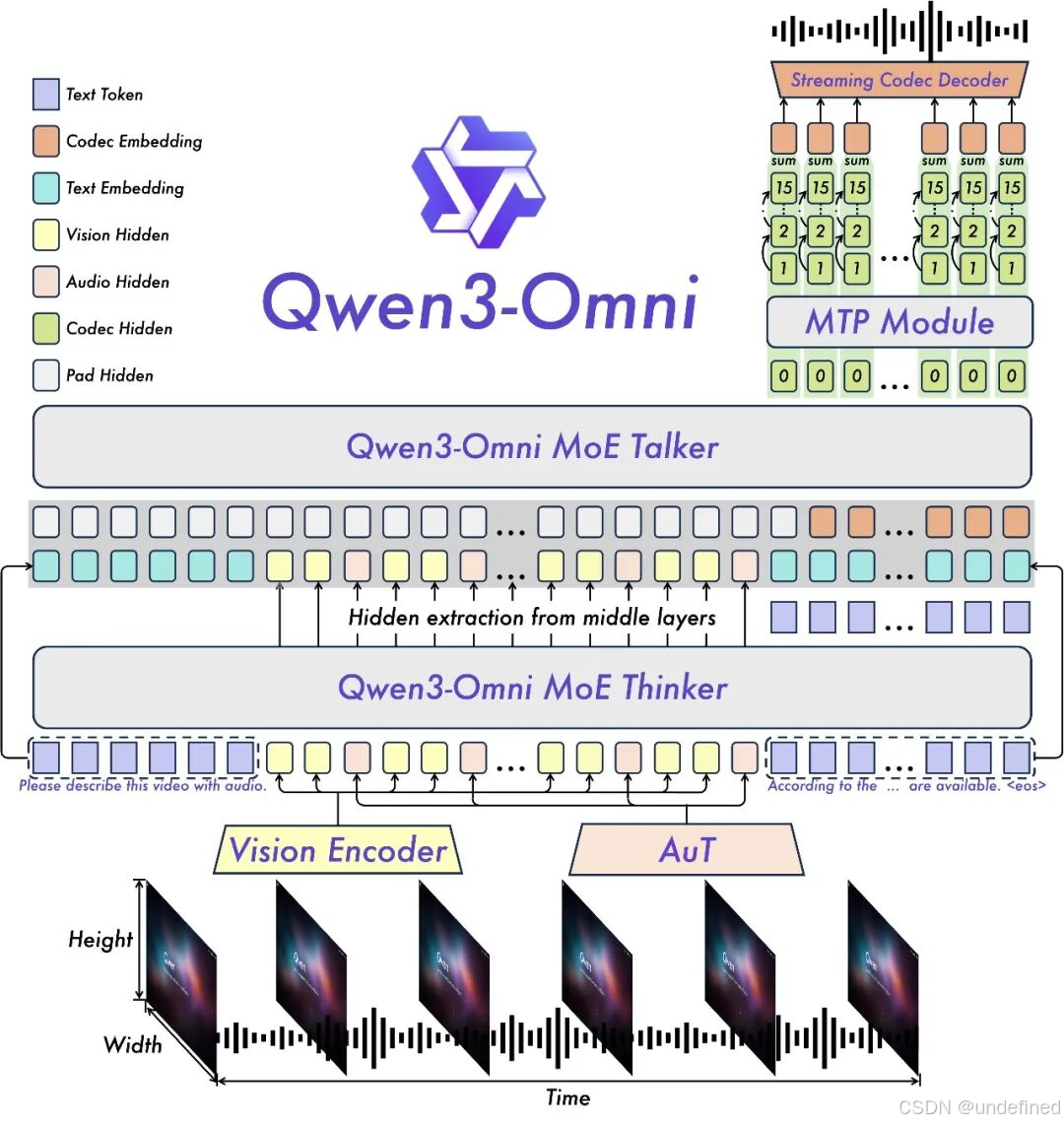
2、Qwen3-Omni:这是首个原生端到端全模态开源大模型,将文本、图像、音频和视频统一在一个模型中,无需权衡模态,能够无缝处理文本、图像、音频和视频等多种输入形式。
3、Qwen3-Next:该模型拥有 800 亿参数仅激活 30 亿,性能就可媲美千问 3 旗舰版 235B 模型,实现了模型计算效率的重大突破。
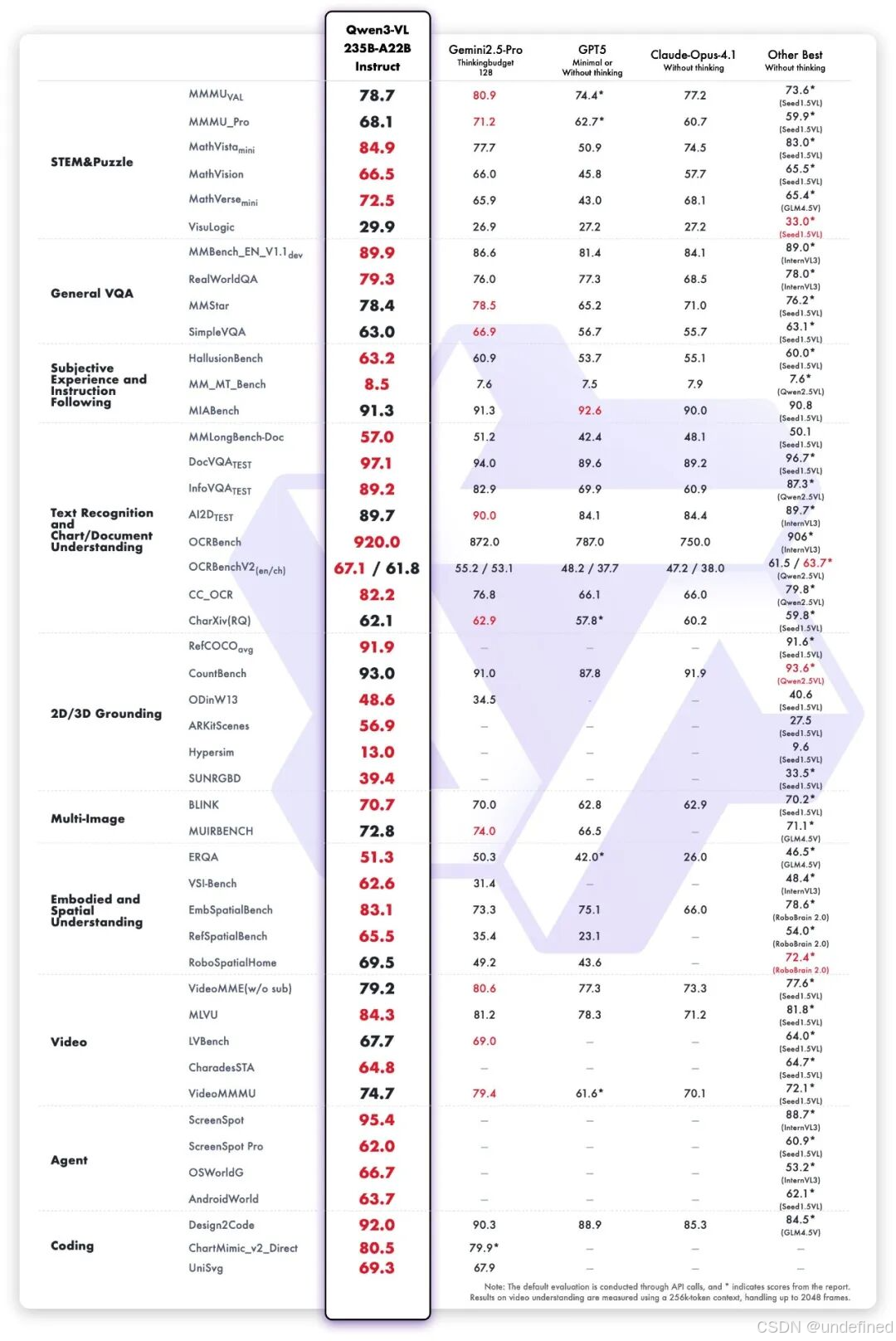
4、Qwen3-VL:这是 Qwen 系列迄今为止最强大的视觉理解模型,它能操作电脑和手机界面,识别 GUI 元素、理解按钮功能、调用工具、执行任务,目前已开源。
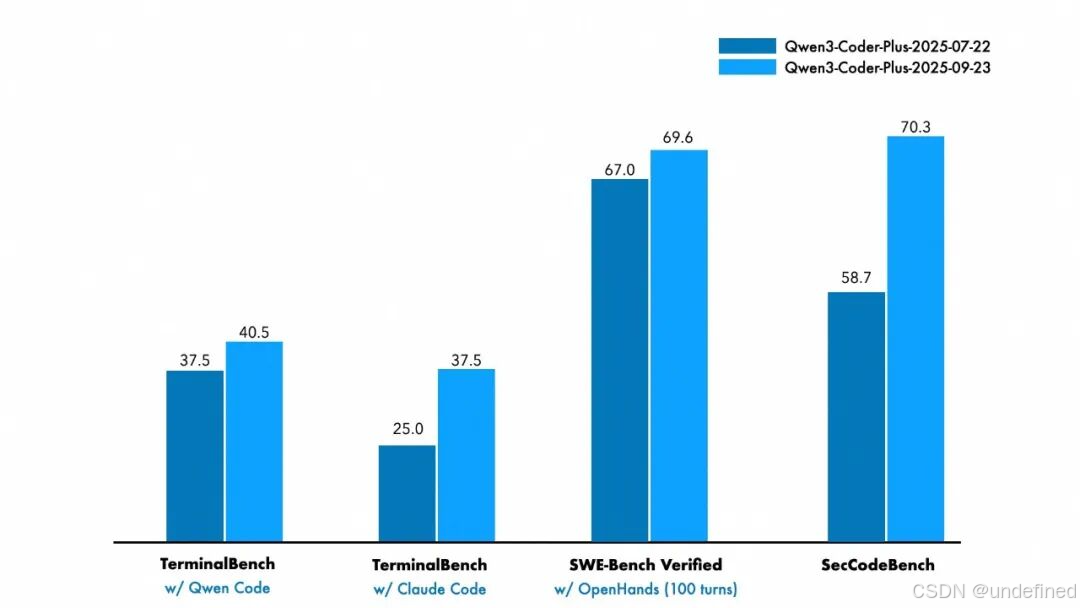
5、Qwen3-Coder-Plus:这是代码模型 Qwen 3-Coder 的一次升级,增强了终端任务功能,并提高了 Terminal Bench 的性能,推理速度更快,token 消耗更少,同时代码安全性上也有增强。
除了千问,阿里还发布了通义万相 Wan2.5-preview系列模型,涵盖文生视频、图生视频、文生图和图像编辑四大模型。
麻了,这次云栖大会,阿里连着发模型,把人看傻了。
不过,作为一名合格的野生 AI 博主,我还是想亲自尝试这些新的模型。
下面开始吧,文章有些长,建议先点赞收藏。
Qwen 3 Max
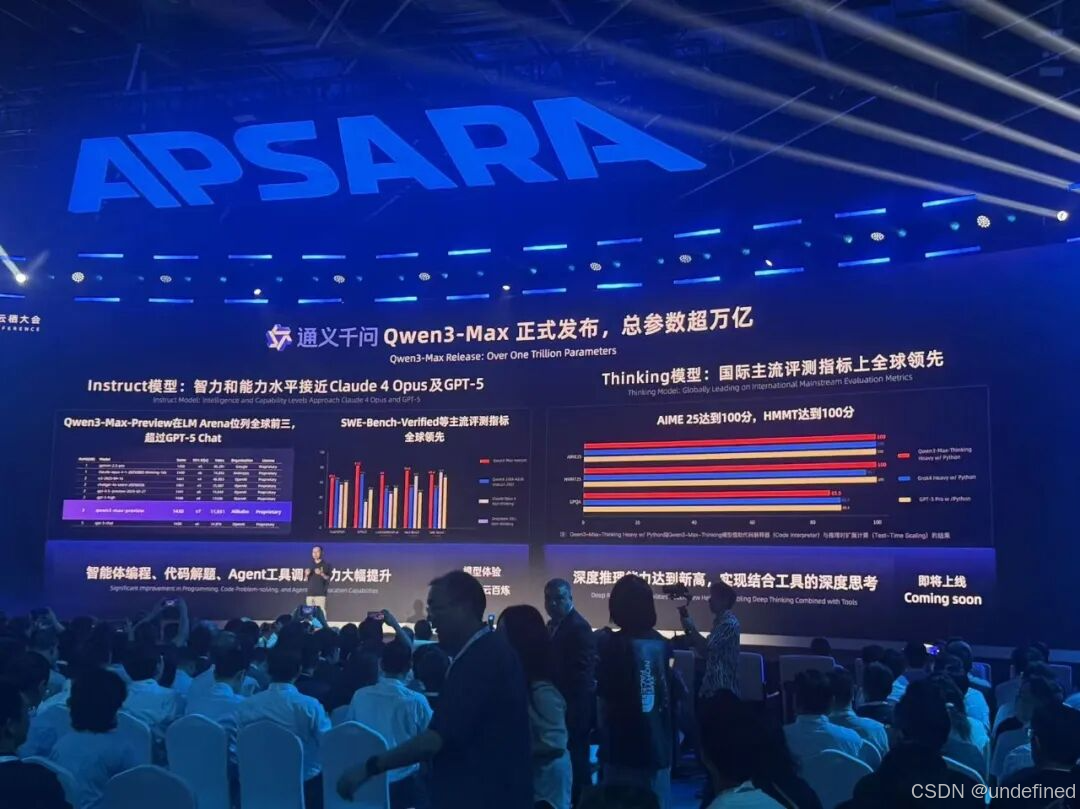
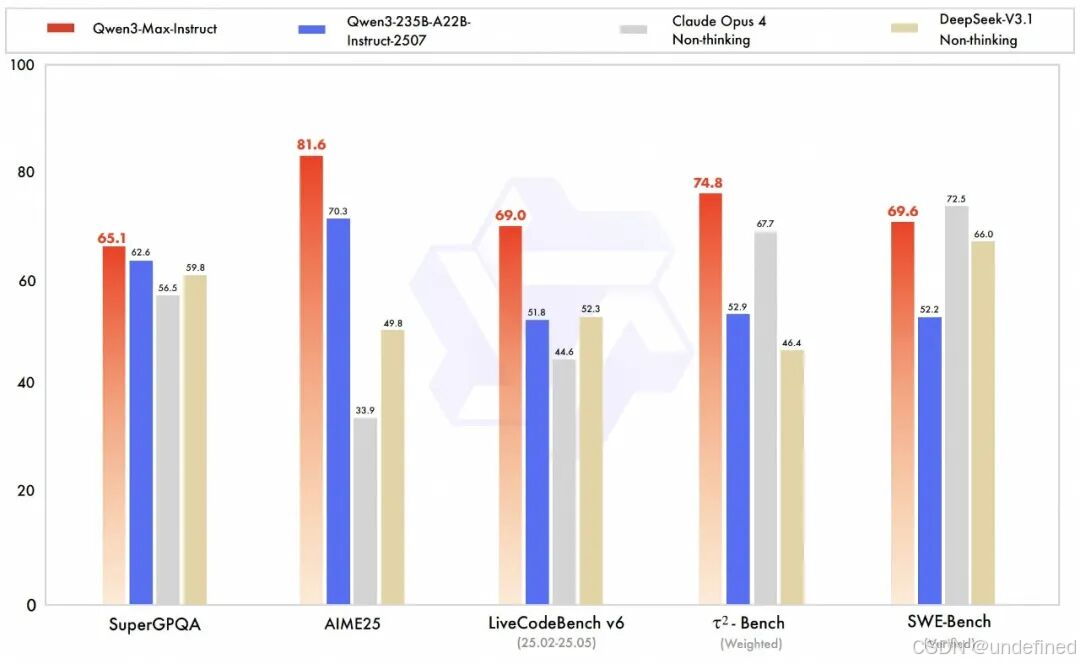
Qwen 3 Max 是目前最强的通义大模型,拥有超万亿的参数。其中 Qwen 3 Max 包括 instruct 和 Thinking 两款。
其中 Instruct 模型的智力和能力水平接近 Claude 4 Opus 以及 GPT-5。
Thinking 模型具备很强的深度推理能力,在国际主流评测指标上全球领先。
现在 chat.qwen.ai 上就可以直接使用了。
先来个六边形重力小球实验,看看出来的效果:

我们和以前的 Qwen 2.5 Max 做下对比。

Qwen 2.5 Max 就有些抽象了,压根都出不来😂。
一个模型的实用性最终还是要落地到 coding 和 Agent 能力,下面我们再是一个 breakout游戏的 case。

Claude 4 效果如下:
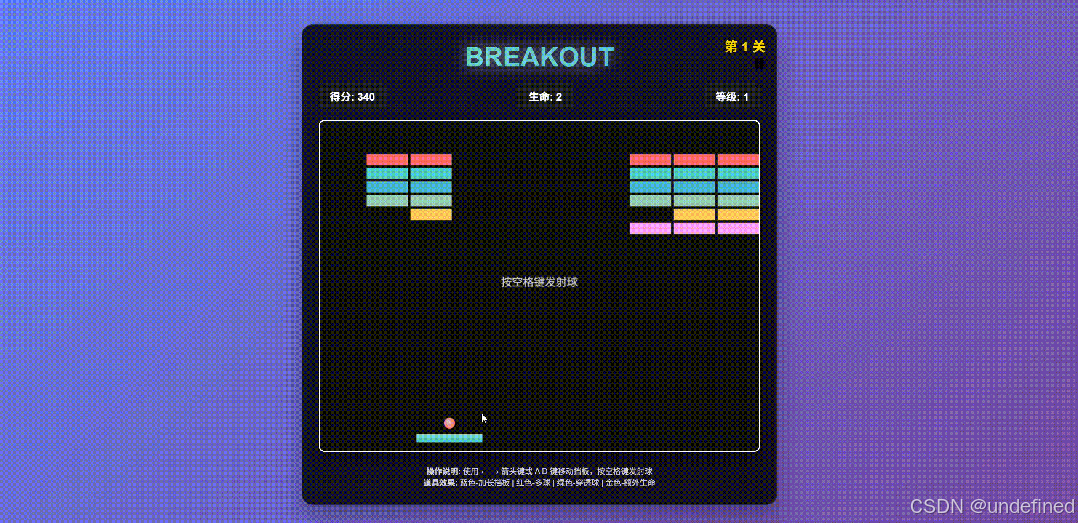
可以看到 Claude 4 生成的游戏中间缺失元素了直接。Qwen 3 Max 可玩性上更有优势。
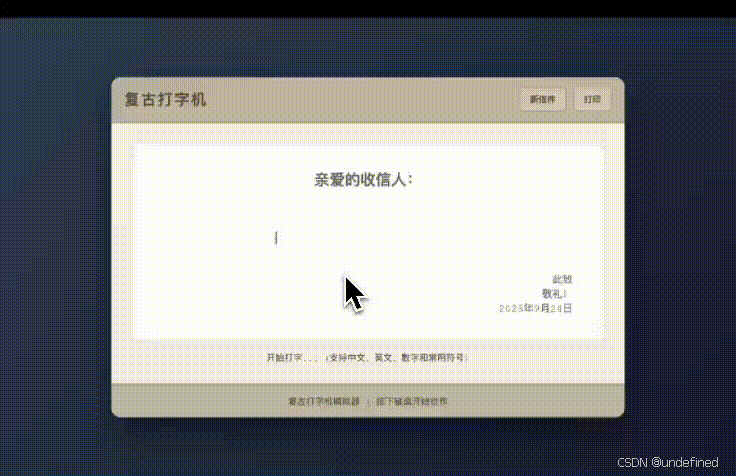
这个是我用 Qwen 3 Max 做的复古打印机,效果也很赞。
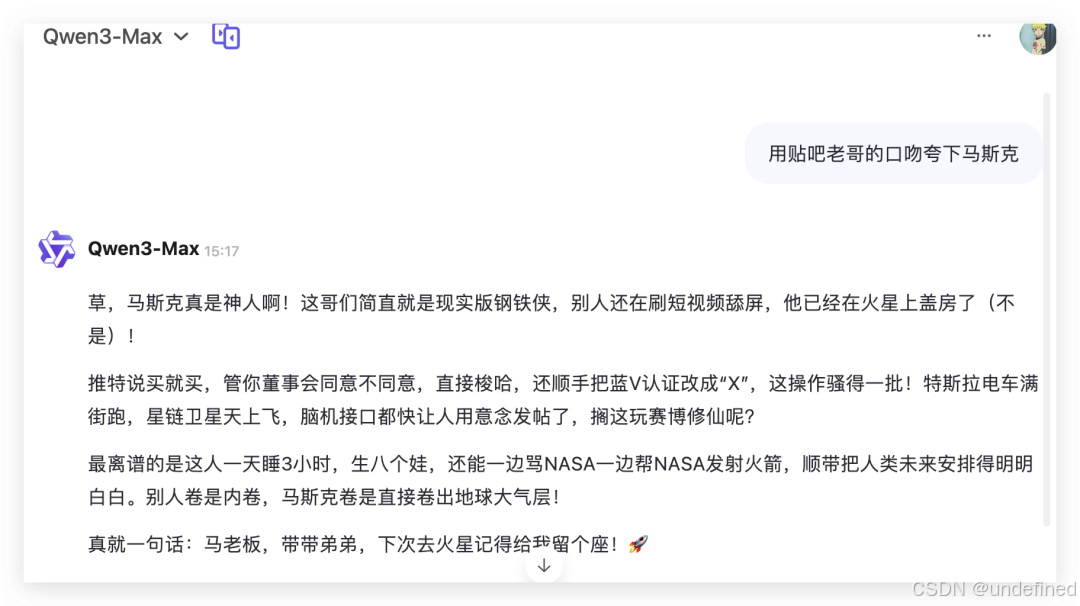
然后看下 Qwen 3 Max 的文风,我觉得相对上个版本,还是有了很大的增强,特别是在风格仿写上。
Wan 2.5-preview

今天在现场,最为炸裂的当属万相的 Wan 2.5-preview,终于也能像 VEO 3 一样生成带声音的视频了。
后排的小姐姐,激动的连说了好几句卧槽。

目前可以在夸克造点和万相平台上体验:
1、夸克造点
https://zaodian.quark.cn/r/ai-studio-pc/main/gen-video?click=ai_video
2、万相平台
https://tongyi.aliyun.com/wan/generate/video/text-to-video?model=wan2.5
其中,要想视频能生成声音,需要手动开启一下这个音效设置:
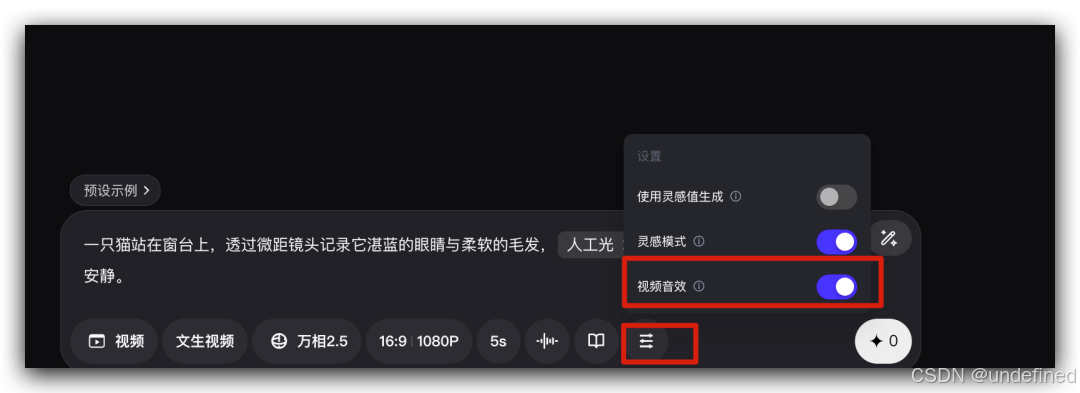
看了下,感觉整体效果相当 nice,甚至在细节和画质上比 veo3 还要更好些。



以上视频分别来自X老哥:@Dork_sense、@higgsfield_ai、@PhotogenicWeekE
Qwen 3-VL
Qwen 3-VL 是 Qwen 系列迄今为止最强大的视觉语言模型!
旗舰型号 Qwen3-VL-235B-A22B 现已开源,并提供 Instruct 和 Thinking 两个版本:
✅ Instruct 在关键视觉基准测试中的表现优于 Gemini 2.5 Pro
✅ Thinking 在多模态推理任务上实现了最佳 (SOTA) 性能
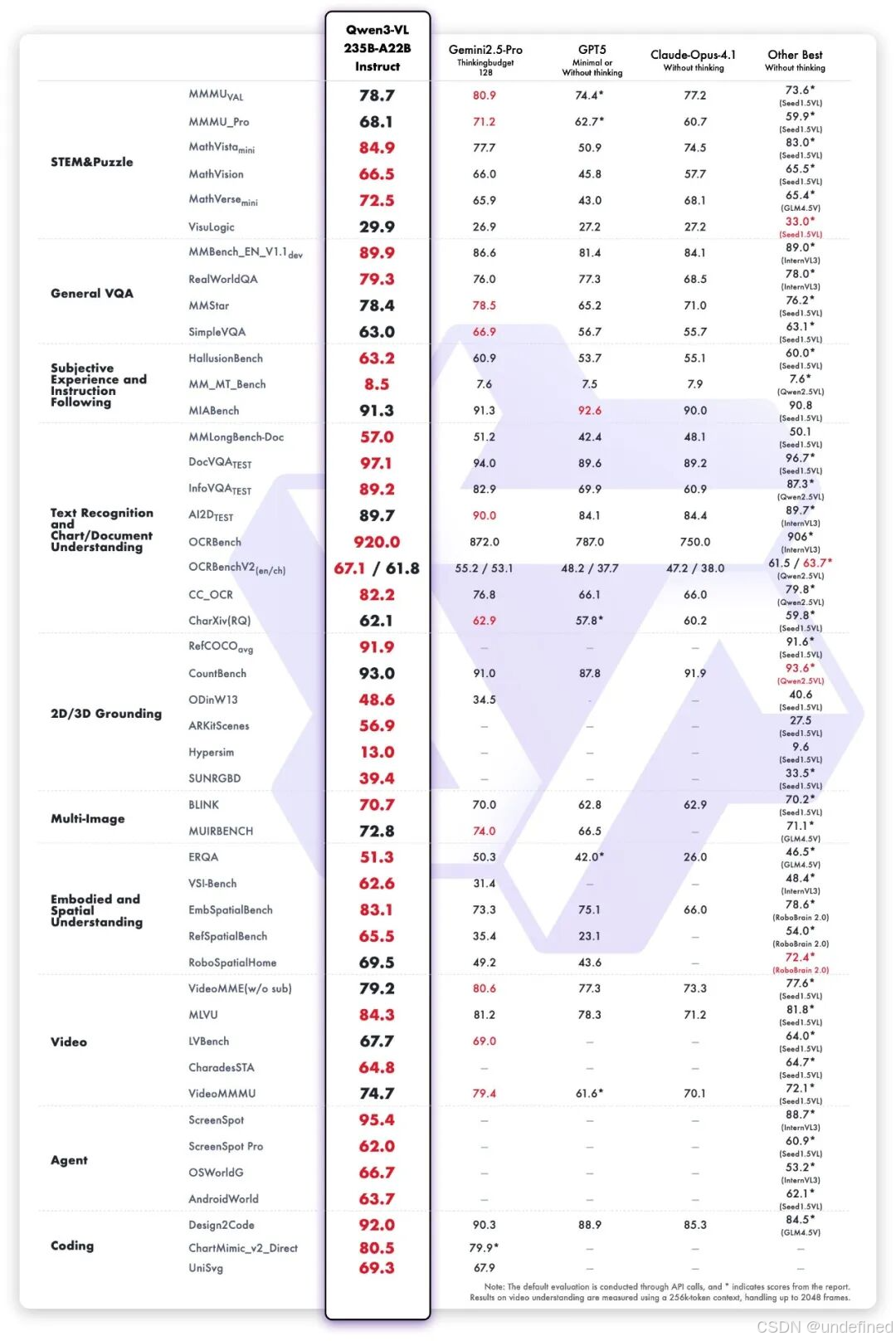
能力方面,我直接放官方的一张图,大家可以感受下。

测了这么多 VLM 模型,下面用几个经典的例子来拷打一下它的能力吧。
1、文字倒放:
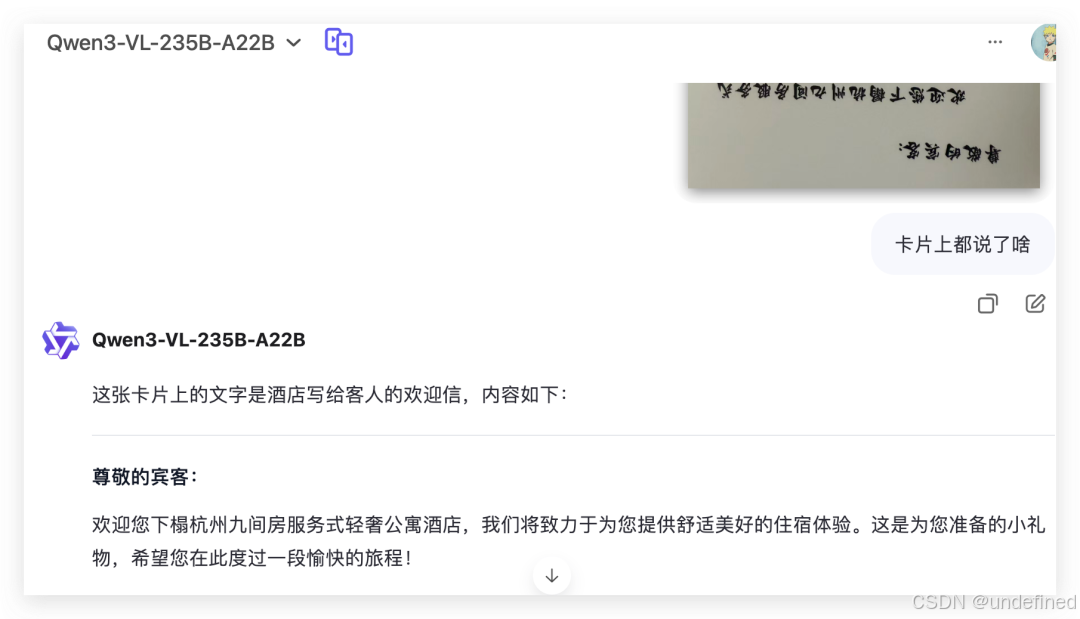
prompt:卡片上都说了啥。

Qwen 3-VL 很快能正确识别,这里需要做的第一步是要将文字旋转摆正后再 OCR 识别。
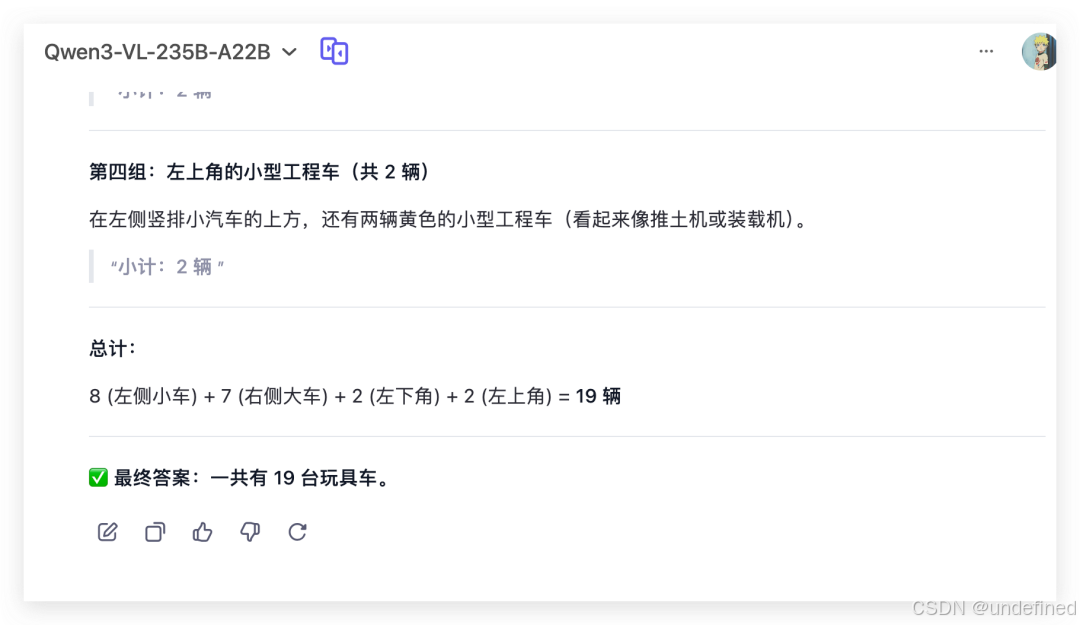
2、数车子
prompt:帮我数下一共有多少台玩具车?

回答正确!
3、网页复刻
prompt:帮我复刻一下这个网站
这个 case 失败了:

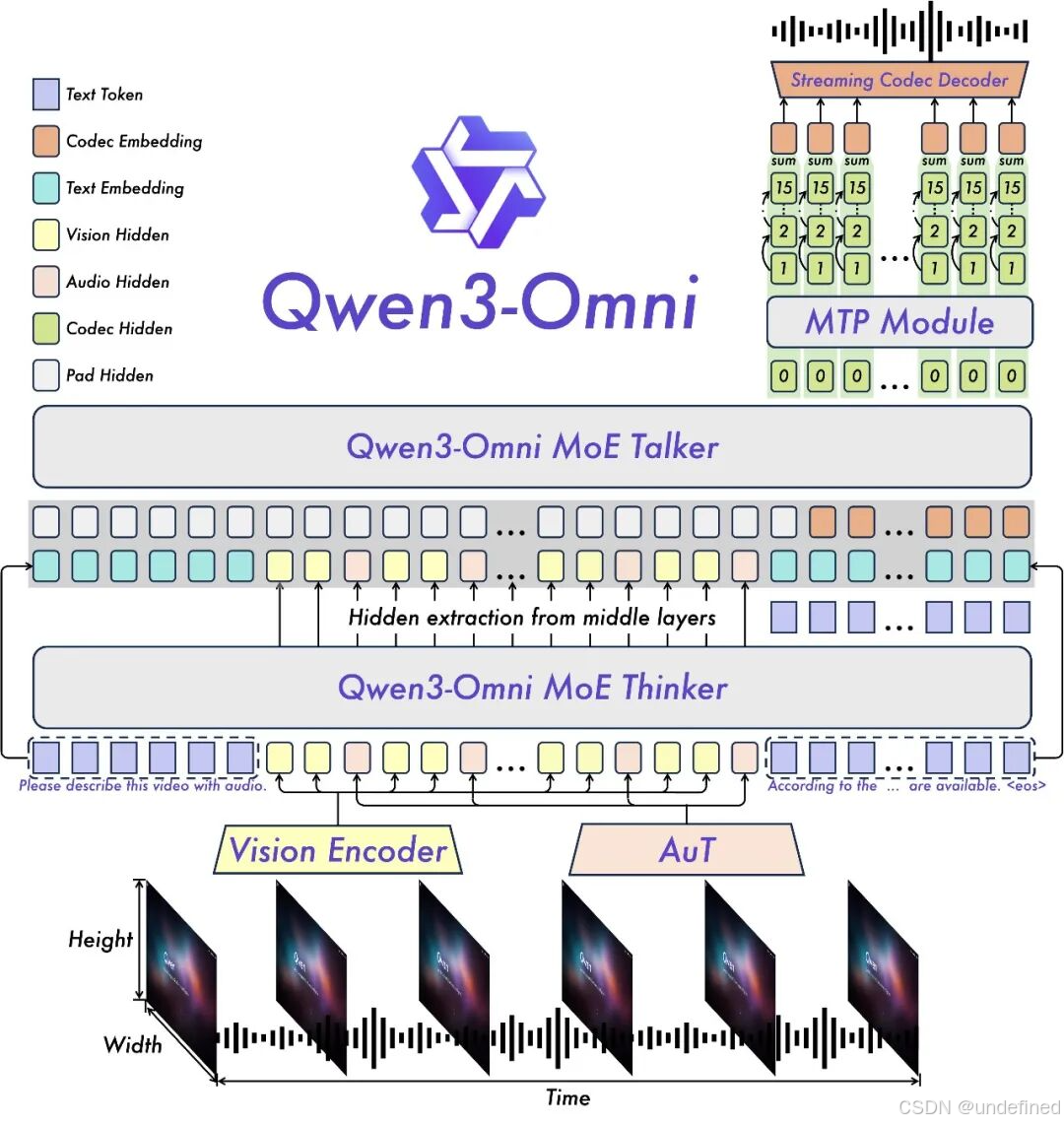
Qwen 3-Omni

这是首个原生端到端全模态大模型,能将文本、图像、音频和视频统一在一个模型中,无需权衡模态!
也就是一个模型就支持文本和多模态能力,可以说是一个超级大脑了,也更贴近真人。

目前已经开源了 Qwen3-Omni-30B-A3B-Instruct、Qwen3-Omni-30B-A3B-Thinking 和 Qwen3-Omni-30B-A3B-Captioner。
同时在22/36 音频和 AV 基准测试中 SOTA
目前也可以使用 Qwen Chat 上的语音聊天和视频聊天功能来体验 Qwen3-Omni 模型。
Qwen 3-Next

从名字上来看,这是下一代模型的全新标准。
Qwen 3-Next 主要实现了模型计算效率的重大突破,总参数80B仅激活 3B,性能就可足以媲美千问3旗舰版235B模型。
而且 Qwen 3-Next 的训练成本更低,长文本推理吞吐量更高了。
Qwen 3-Coder-Plus

Qwen 3-Coder 刚出来的时候,苍何也第一时间做了评测,具体可看:对标Claude Code,阿里发布最强开源模型Qwen3-Coder(附教程)
这次云栖大会上发布的主要是对 Qwen 3-Coder 的升级。
主要在推理速度和同时执行任务的效率上更高,代码安全性也更好。
这里的具体实测,就需要花费更长时间了,不过可以持续关注苍何,到时给大家带来使用上的体验。
好了,今天的内容就到这里了。
讲真的,逛完一天,我人是麻的。
技术的迭代速度,已经不是按年来算了,而是按天,甚至是按小时。我们以为的未来,可能在 AI 眼里,只是个开场白。
但焦虑归焦虑,兴奋也是真的。
这个时代,最怕的就是站在原地,一成不变。
我们无法预测未来,但可以创造未来。
与其被浪潮拍在沙滩上,不如学着怎么去冲浪。
与各位共勉。
好了,今天就聊到这,如果对你有帮助,希望可以 点赞、在看、分享。
更多推荐
 22
22 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)