
学习华为昇腾AI教材深度学习和大模型基础部分Day2
通过前一节课我们可以知道已经表现出了它能解决复杂问题(拟合复杂函数) 的能力, 但是它中间层只有两个单元, 并且它那继续, 是否能进一步提升能力呢?深度学习一般指深度神经网络,(多层)。用于模拟人类的神经网络构建,在人工神经网络设计及应用研究中,通常需要考虑方面的内容,即通过单层感知机到多层感知机的变化发现, 网络不仅可以增加层数, 还可以增加单层上网络节点的数量。那么, 如果只增加单层网络中的节
02全连接神经网络及训练流程
一、深度神经网络
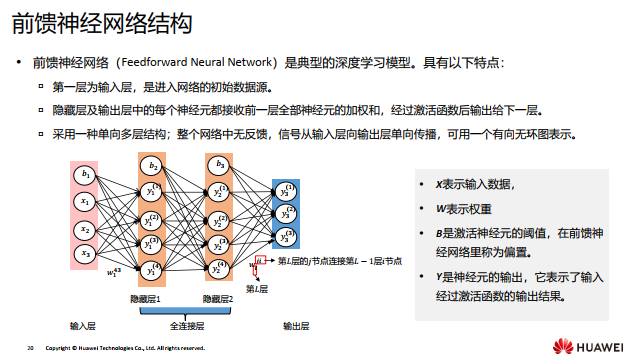
通过前一节课我们可以知道多层感知机已经表现出了它能解决复杂问题(拟合复杂函数) 的能力, 但是它中间层只有两个单元, 并且它只能解决二分类问题。
那继续增加中间层的节点数和网络结构层数, 是否能进一步提升能力呢?
深度学习一般指深度神经网络, 深度指神经网络的层数(多层)。用于模拟人类的神经网络构建,在人工神经网络设计及应用研究中,通常需要考虑三个方面的内容,即神经元作用函数、神经元之间的连接形式和网络的学习(训练)。
隐藏层越多,神经网络的分辨能力越强。
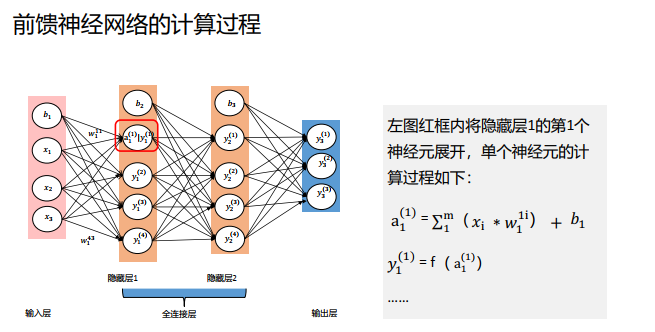
通过单层感知机到多层感知机的变化发现, 网络不仅可以增加层数, 还可以增加单层上网络节点的数量。 那么, 如果只增加单层网络中的节点数量, 是否可以增强网络能力呢?
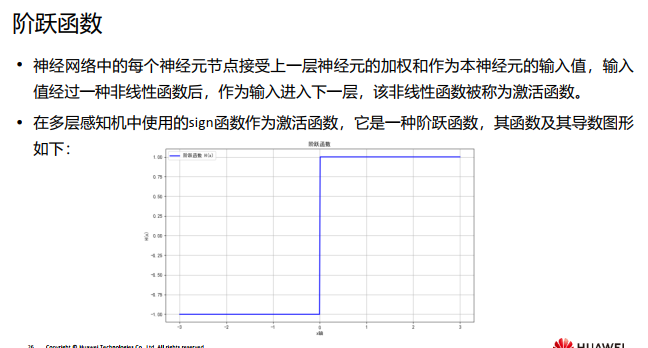
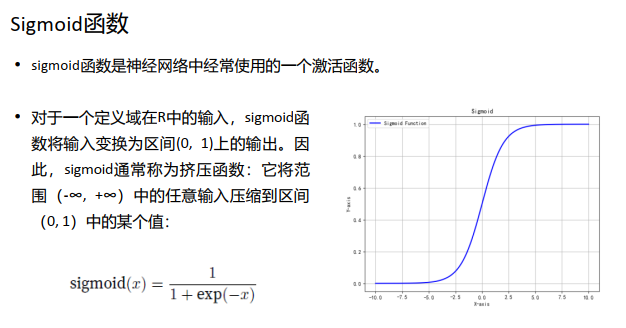
二、常见的激活函数(重点内容,对应图形也需要理解记忆)
不仅是多层感知机, 深度神经网络如果不使用非线性激活函数, 依然不能产生非线性能力,因此我们需要利用非线性激活函数来产生非线性能力,那么,常见的激活函数有哪些呢?


当𝛽 = 0 时, Swish 函数变成线性函数𝑥/2.当𝛽 = 1 时, Swish 函数在𝑥 > 0时近似线性, 在𝑥 < 0 时近似饱和,同时具有一定的非单调性.当𝛽 → +∞ 时, 𝜎(𝛽𝑥) 趋向于离散的0- 1 函数, Swish 函数近似为ReLU 函数。因此, Swish 函数可以看作线性函数和ReLU 函 数之间的非线性插值函数,其程度由参数𝛽 控制。
三、训练神经网络
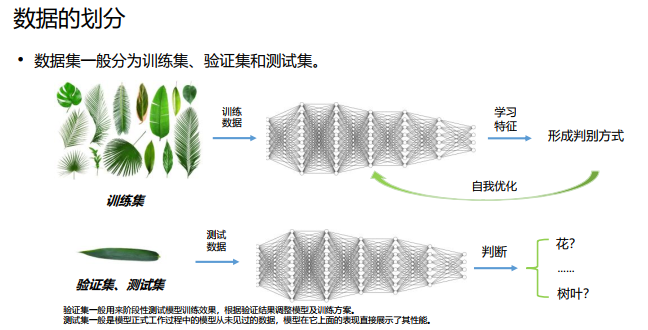
数据是机器学习的命根子。从数据中寻找答案、从数据中发现模式、根据数据讲故事。 这些机器学习所做的事情,如果没有数据的话,就无从谈起。因此,数据是机器学习的核心。这种数据驱动的方法,也可以说脱离了过往以人为中心的方法。



随机梯度下降算法走向了另一个极端,即每个样例都更新权值。因为训练样例中一般是含有噪声的,因此到了精确逼近极值的阶段,梯度往往会在极值附近横冲直撞,难以收敛到极值。

全量梯度下降法每次学习都使用整个训练集,因此每次更新都会朝着正确的方向进行, 最后能够保证收敛于极值点,凸函数收敛于全局极值点,非凸函数可能会收敛于局部极值点,缺陷就是学习时间太长,消耗大量内存。

小批量梯度下降兼顾了效率和梯度的稳定性,容易冲过局部极小值,是实际工作中最常用的梯度下降算法, BS的取值因具体问题而异,一般取32。
如图所示,反向传播的计算顺序是,将信号loss乘以节点的局部导数然后将结果传递给下一个节点。


四、优化器
在梯度下降算法中, 有各种不同的改进版本。 在面向对象的语言实现中, 往往把不同的梯度下降算法封装成一个对象, 称为优化器。
算法改进的目的, 包括但不限于: 加快算法收敛速度; 尽量避过或冲过局部极值; 减小手工参数的设置难度,主要是学习率(Learning Rate)。
常见的优化器如:普通SGD优化器、 动量优化器、 Adagrad、 RMSprop、 Adam等。

动量优化器的优点是: 增加了梯度修正方向的稳定性,减小突变。 在梯度方向比较稳定的区域,小球滚动会越来越快(当然,因为𝛼 < 1,其有一个速度上限),这有助于小球快速冲过平坦区域,加快收敛。 带有惯性的小球更容易滚过一些狭窄的局部极值。
动量优化器的缺点是:学习率𝜂以及动量𝛼仍需手动设置,这往往需要较多的实验来确定合适的值。

从Adagrad优化算法中可以看出, 随着算法不断迭代, 𝑟会越来越大, 整体的学习率会越来越小。 这样做的原因是随着更新次数的增大, 我们希望学习率越来越慢。 因为我们认为在学习率的最初阶段, 我们距离损失函数最优解还很远, 随着更新次数的增加, 越来越接近最优解, 所以学习率也随之变慢。
优点: 学习率自动更新,随着更新次数增加,学习率随之变慢。
缺点: 分母会不断累积,最终学习率变得非常小,算法会失去效用。



五、正则化
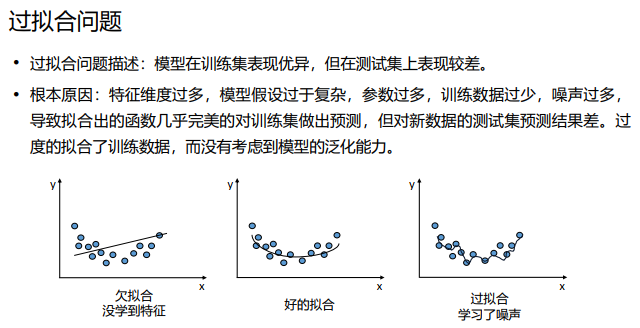
过拟合主要是有两个原因造成的:数据太少+模型太复杂:在深度学习中,经常出现的问题是,训练数据量小,模型复杂度高,这就使得模型在训练数据上的预测准确率高,但是在测试数据上的准确率低,这时就是出现了过拟合。
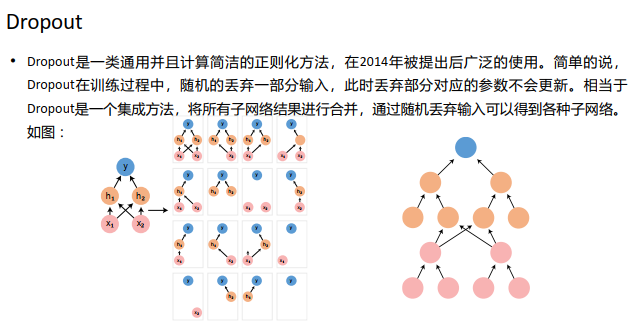
解决措施:获取更多数据 :从数据源头获取更多数据;数据增强(Data Augmentation);使用合适的模型:减少网络的层数、神经元个数等均可以限制网络的拟合能力;Dropout;正则化,在训练的时候限制权值变大;限制训练时间;通过评估测试;增加噪声 Noise: 输入时+权重上(高斯初始化) ; 数据清洗(data ckeaning/Pruning):将错误的label 纠正或者删除错误的数据;结合多种模型: Bagging用不同的模型拟合不同部分的训练集; Boosting只使用 简单的神经网络。


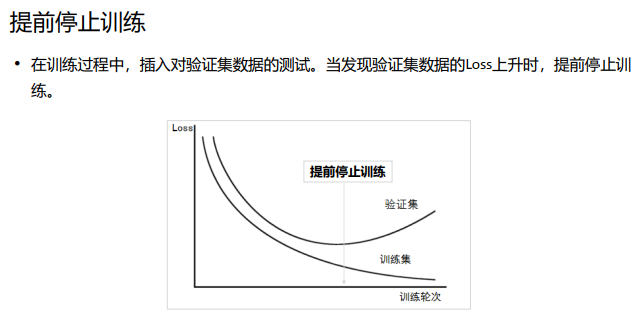
我们往往会设置一个比较大的迭代次数n。首先我们要保存好现在的模型(网络结构和 权值),训练num_batch次(即一个epoch),得到新的模型。将测试集作为新模型的输入,进 行测试。如果我们发现测试误差比上次得到的测试误差大,我们并不会马上终止测试, 而是再继续进行几个epoch的训练与测试,如果测试误差依旧没有减小,那么我们就 认为该试验在上一次达到最低测试误差时停下来训练模型时,
一般的做法是记录到目前为止最好的测试集准确率p,之后连续m个周期没有超过最 佳测试集准确率p时,则可以认为p不再提高了,此时便可以提前停止迭代(EarlyStopping)。
从图中可以看出,测试误差在前几个epoch中逐渐减小,但是训练到某个epoch后,测 试误差又有了小幅度的增大。这说明此时发生了过拟合。
发生过拟合是我们所不愿意看见的,我们可以利用提前终止(early stopping) 来防止过拟合的发生。
提前终止是指:在测试误差开始上升之前,就停止训练,即使此时训练尚未收敛(即训练误差未达到最小值)。

更多推荐

 10
10 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)