
从GPT-1到GPT-3:生成式预训练语言模型的演进之路
本文系统梳理了OpenAI GPT系列模型从GPT-1到GPT-3的核心技术演进。GPT-1首次提出“无监督预训练 + 有监督微调”的两阶段范式,基于单向Transformer解码器实现多任务自然语言理解;GPT-2通过扩大模型规模与采用字节级BPE分词器,摒弃任务特定微调,转向零样本学习,仅依靠自然语言提示即可泛化至多种任务;GPT-3进一步将参数规模提升至1750亿,全面拥抱上下文中的少样本(
GPT-1
GPT-1(Generative Pre-Training)是 OpenAI 于 2018 年提出的首个 GPT 系列模型,其论文题为《Improving Language Understanding by Generative Pre-Training》。GPT-1 的核心思想是通过无监督预训练 + 有监督微调的两阶段范式,提升模型在多种自然语言理解(NLU)任务上的表现。
第一阶段:无监督预训练(Unsupervised Pre-training)
在大规模无标注文本语料上训练一个语言模型,目标是学习通用的语言表示。
架构
- 基于 Transformer 的解码器(Decoder-only),共 12 层,隐藏层维度为768,12个注意力头。
- 每层包含:
- 掩码多头自注意力机制(Masked Multi-head Self-Attention)
- 位置前馈网络(Position-wise Feed-Forward Network)
- 残差连接(Residual Connection)和层归一化(Layer Normalization)
- 使用 字节对编码(Byte Pair Encoding, BPE) 作为子词分词器,词表大小为 40,000。
注意:GPT-1 的 Transformer 解码器去掉了掩码多头注意力中的“编码器-解码器注意力”部分,仅保留带掩码的自注意力,确保预测第 t t t 个词时只能看到前 t − 1 t-1 t−1 个词。
预训练目标函数:标准语言模型(自回归)
GPT-1 的预训练目标是最大化给定前文条件下下一个词的对数似然,即标准的自回归语言建模目标。
设无标注语料为序列 U = { u 1 , u 2 , … , u n } U = \{u_1, u_2, \dots, u_n\} U={u1,u2,…,un},模型参数为 Θ \Theta Θ,则目标函数为:
L 1 ( U ) = ∑ t = 1 n log P ( u t ∣ u 1 , u 2 , … , u t − 1 ; Θ ) \mathcal{L}_1(U) = \sum_{t=1}^{n} \log P(u_t \mid u_1, u_2, \dots, u_{t-1}; \Theta) L1(U)=t=1∑nlogP(ut∣u1,u2,…,ut−1;Θ)
其中,条件概率通过 Transformer 解码器建模:
h 0 = U W e + W p h l = t r a n s f o r m e r _ b l o c k ( h l − 1 ) ∀ l ∈ [ 1 , L ] P ( u t ∣ u < t ; Θ ) = softmax ( h L W e ⊤ ) \begin{align} h_0&= U W_e + W_p \\ h_l&=transformer\_block(h_{l-1})\forall l \in[1,L]\\ P(u_t \mid u_{<t}; \Theta) &= \text{softmax}(h_LW_e^\top) \end{align} h0hlP(ut∣u<t;Θ)=UWe+Wp=transformer_block(hl−1)∀l∈[1,L]=softmax(hLWe⊤)
- h l h_l hl 是 Transformer 在第 l l l 层输出的隐藏状态
- L L L 是 Transformer 层数
- W e ∈ R ∣ V ∣ × d W_e \in \mathbb{R}^{|V| \times d} We∈R∣V∣×d 是输出词表投影矩阵( ∣ V ∣ |V| ∣V∣ 为词表大小, d d d 为隐藏维度)
- W p ∈ R n × d W_p \in \mathbb{R}^{n \times d} Wp∈Rn×d 是位置嵌入矩阵
- U W e UW_e UWe把 U U U 当作 one-hot 矩阵,但实际实现上是通过索引查表, u t ∈ [ 1 , 2 , … , ∣ V ∣ ] u_t \in [1,2,\dots,|V|] ut∈[1,2,…,∣V∣], E m b e d ( u t ) = W e [ u t , : ] Embed(u_t)=W_e[u_t,:] Embed(ut)=We[ut,:]
第二阶段:有监督微调(Supervised Fine-tuning)
在特定下游任务(如文本分类、问答、蕴含等)的小规模标注数据上,对预训练模型进行微调,以适配具体任务。
假设有一个带标签的下游任务数据集 C = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , … , ( x n , y n ) } \mathcal{C} = \{(x^1, y^1), (x^2, y^2), \dots, (x^n, y^n)\} C={(x1,y1),(x2,y2),…,(xn,yn)},其中:
- x = ( x 1 , x 2 , … , x m ) x = (x_1, x_2, \dots, x_m) x=(x1,x2,…,xm) 是输入序列(如句子或句子对)
- y y y 是标签(如分类类别、是否蕴含等)
GPT-1 将输入序列送入预训练好的 Transformer,取最后一个 token 的隐藏状态 h l h_l hl(即第 m m m 个位置的输出),通过一个可训练的线性分类头 W y W_y Wy 预测标签:
P ( y ∣ x 1 , x 2 , … , x m ) = softmax ( h l W y ) P(y \mid x_1, x_2, \dots, x_m) = \text{softmax}(h_lW_y) P(y∣x1,x2,…,xm)=softmax(hlWy)
微调阶段的目标函数由两部分组成:
L 2 ( C ) = ∑ ( x , y ) ∈ C log P ( y ∣ x 1 , x 2 , … , x m ) + λ ⋅ L 1 ( C ) \mathcal{L}_2(\mathcal{C}) = \sum_{(x,y) \in \mathcal{C}} \log P(y \mid x_1, x_2, \dots, x_m) + \lambda \cdot \mathcal{L}_1(\mathcal{C}) L2(C)=(x,y)∈C∑logP(y∣x1,x2,…,xm)+λ⋅L1(C)
- 第一项:标准的监督分类损失(负对数似然)
- 第二项:语言模型辅助目标(可选),对输入序列本身(不含标签)进行自回归语言建模,即预测每个 token 的下一个 token(和预训练阶段一致),以防止模型遗忘预训练学到的语言知识,有助于提升性能。
- λ \lambda λ 是一个超参数(论文中设为 0.5)
不同任务的输入格式
GPT-1 通过统一的序列格式处理不同任务,如下图:
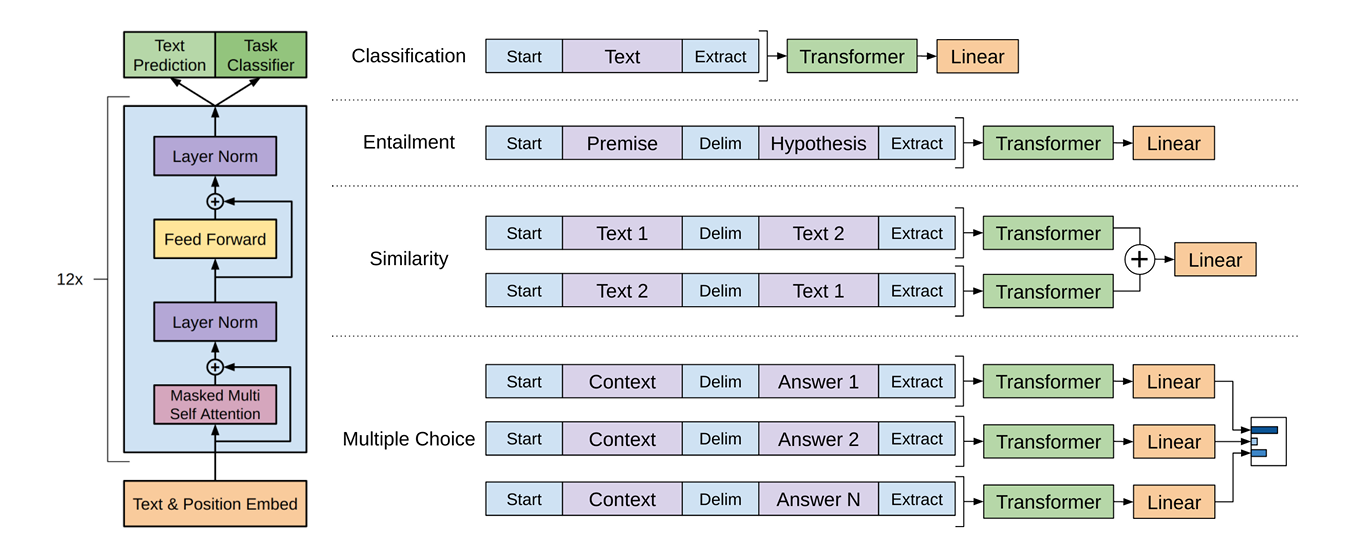
所有任务都使用相同的 Transformer 架构,仅在最后加任务特定的分类头。
GPT-1 VS BERT
GPT-1
- 架构:基于Transformer的解码器(Decoder)部分,采用单向自注意力机制。
- 特点:仅关注当前及之前的上下文信息,通过预测下一个词实现自回归生成。这种设计使其天然适合生成任务(如文本补全、对话系统),但无法利用未来信息,对上下文的理解存在局限性。
- 任务类型:自回归语言建模(Autoregressive Language Modeling)。
- 微调策略:目标函数为下游任务目标+语言模型目标(辅助目标)。由于保留语言模型目标,微调阶段需足够数据平衡两个目标。数据量不足时,辅助目标可能主导训练,导致任务性能下降。
BERT
- 架构:基于Transformer的编码器(Encoder)部分,采用双向自注意力机制。
- 特点:同时捕捉左右上下文信息,通过掩码语言模型(MLM)学习双向表示。这种设计使其在理解型任务(如问答、分类)中表现卓越,但不适合直接用于文本生成。
- 任务类型:掩码语言模型(MLM)和下一句预测(NSP)。
- 微调策略:仅使用下游任务目标函数进行微调。预训练已学习丰富的语言表示,微调阶段仅需少量任务数据即可达到较好性能。
GPT-2
GPT-2 是 OpenAI 于 2019年推出的第二代生成式预训练模型,其论文题为Language Models are Unsupervised Multitask Learners,它通过无监督学习在海量文本数据上预训练,展现了强大的文本生成能力和多任务适应性。
模型架构
- 沿用了GPT-1 的结构,基于单向 Transformer 解码器结构,通过堆叠多层Transformer块实现自回归生成。
- 最大版本参数规模达 1.5 B,是前代GPT-1的10倍以上,显著提升了生成质量和泛化能力。
- 在分词上,GPT-2 引入了一种 字节级 Byte Pair Encoding(BPE) 分词器,该分词器具有 完全可逆性(reversible),即从 token 序列可以无损地还原原始文本。
下游任务输入
GPT-1
在构建下游任务输入时,需引入模型未见过的特殊符号来标记任务类型。特殊符号需在微调阶段学习,无法直接处理零样本任务。这种方式虽然有效,但每个任务都需要独立的标注数据和训练流程,任务之间隔离性强,迁移成本高。
GPT-2
GPT-2 采用零样本学习(zero-shot learning) 范式,无需任务特定微调即可完成多种任务。它仅通过预训练阶段学习通用语言建模能力,在执行下游任务时,不使用任何任务特定的标注数据,也不更新模型参数,而是直接通过自然语言提示(prompt)引导模型完成任务。例如在做翻译时,输入为 Translate English to French: The house is wonderful,模型直接生成法语翻译。这种零样本学习方式相较于 GPT - 1 的微调方式,大大降低了对任务特定标注数据的依赖,提高了模型的通用性和迁移能力。
Zero-shot learning 指模型在未见过任何特定任务的标注数据的情况下,仅通过任务描述或上下文提示,直接完成新任务的能力。其核心在于模型通过预训练阶段学习到的通用知识,能够理解并执行从未明确训练过的任务。
GPT-3
GPT-3(Generative Pre-trained Transformer 3)是由美国人工智能公司 OpenAI 于2020年6月发布的第三代大型语言模型,论文题为 Language Models are Few-Shot Learners。它是自然语言处理(NLP)领域的一项重要突破,以其强大的语言生成和理解能力而广受关注。
核心特点:
规模庞大:
- GPT-3 拥有约 1750亿个参数,是当时公开发布的最大语言模型之一(在其发布时远超前代 GPT-2 的 15 亿参数)。
无监督预训练:
- GPT-3 采用“预训练+提示(prompting)”的方式工作,无需针对特定任务进行微调(fine-tuning)。
少样本/零样本学习
- 支持零样本学习(zero-shot)、单样本学习(one-shot)和少样本学习(few-shot):只需在输入中提供任务描述或几个示例,模型就能完成新任务,如翻译、问答、写作、编程等。
多功能性:
- 能够生成高质量的文本,包括新闻文章、诗歌、故事、技术文档、代码等。
- 可用于多种应用场景:聊天机器人、内容创作、自动摘要、语言翻译、教育辅助、代码生成(如通过 Codex 衍生模型)等。
更多推荐

 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)