
[论文阅读] 人工智能 | 突破AI大模型算力瓶颈:下一代计算范式的三大演进路径探索
现代AI大模型依规模扩展定律持续扩容至近万亿参数,引发算法、硬件、工程领域多重困境,Transformer架构计算效率低、访存需求大的瓶颈凸显,还加剧了通用人工智能(AGI)路径争议。针对此,当前已形成注意力机制优化、低精度量化等算法改进方向,及集群并行、硬件DSA化等工程优化方向。同时,下一代计算范式正脱离“Next Token Prediction”核心,分为更高抽象层次预测(如Diffusi
突破AI大模型算力瓶颈:下一代计算范式的三大演进路径与实践
一、论文信息
| 信息类别 | 具体内容 |
|---|---|
| 论文原标题 | 下一代AI 大模型计算范式洞察 |
| 主要作者及研究机构 | 熊先奎、王程晨、蔡文豪(中兴通讯股份有限公司,中国 深圳 518057) |
| APA引文格式 | Xiong, X. K., Wang, C. C., & Cai, W. H. (2025). Insights into next generation AI model and computational paradigm. ZTE Technology Journal. https://link.cnki.net/urlid/34.1228.TN.20250926.1148.002 |
| 网络首发日期 | 2025-09-26 |
二、一段话总结
论文指出,现代AI大模型依规模扩展定律持续扩大,近万亿参数量引发算法、硬件、工程领域多重困境,Transformer架构计算效率低、访存需求大的瓶颈凸显,还促使学界和工业界反思通用人工智能(AGI)实现路径;当前针对自回归Transformer架构,已形成注意力机制优化、低精度量化等算法改进方向,及集群系统优化、硬件升级等工程改进方向,同时下一代计算范式正脱离“Next Token Prediction”核心,分为更高抽象层次预测架构(如Diffusion LLM)与物理第一性原理模型(如液态神经模型)两类路径,且新型范式与计算基材结合有望破解软硬件割裂难题,中兴通讯也通过存内计算、循环式Transformer等实践验证了部分技术可行性。
三、思维导图
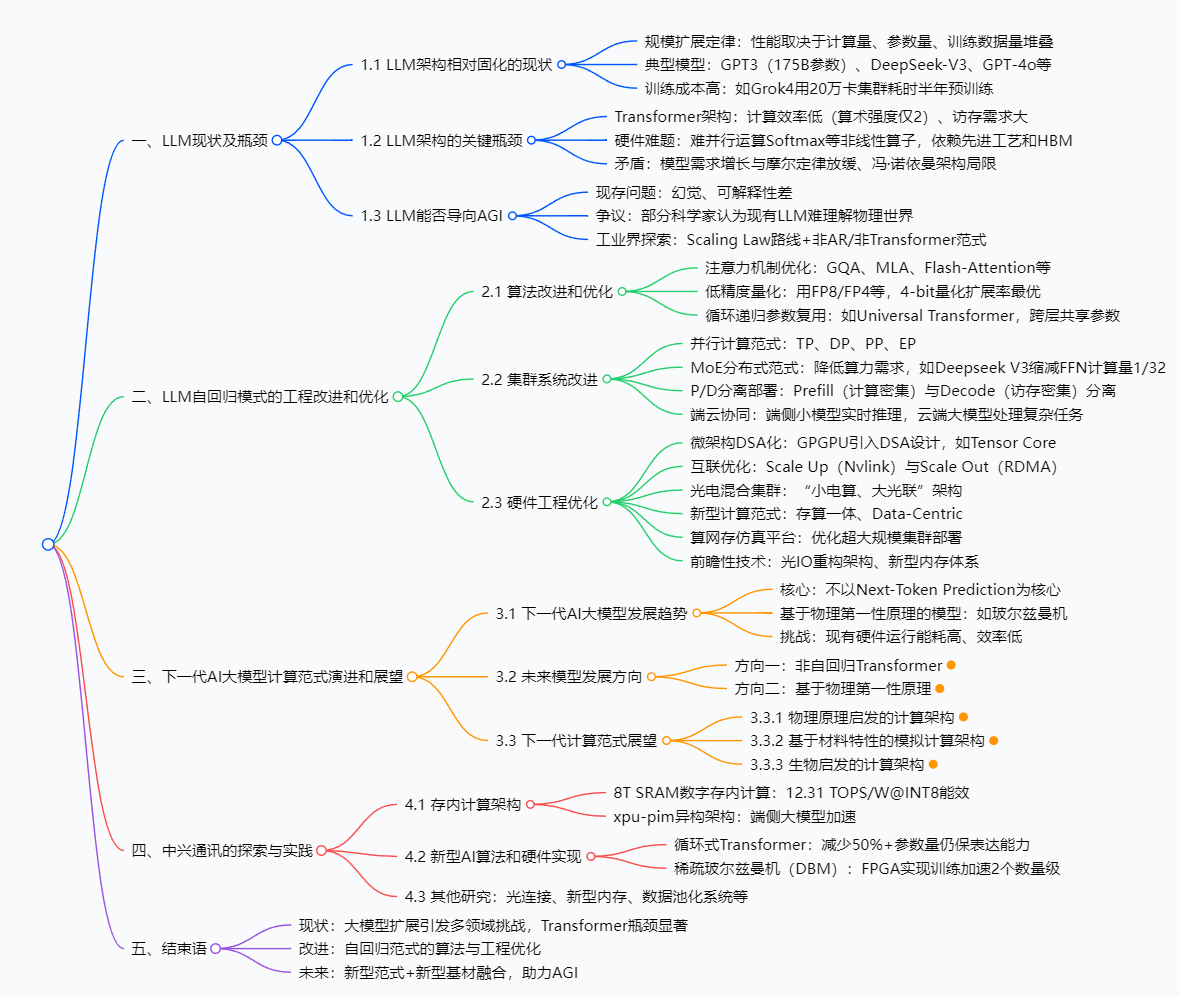
四、研究背景
1. 大模型的“规模竞赛”与成本困境
2020年OpenAI提出的“规模扩展定律(Scaling Laws)”,如同给AI大模型按下了“扩容加速键”——模型性能直接取决于计算量、参数量、训练数据量的“堆叠式增长”。比如参数量达1750亿的GPT-3,在自然语言理解、知识问答等任务中表现远超同期模型;近年DeepSeek-V3、GPT-4o、Llama4等模型也持续验证这一定律。
但“大”的代价极其高昂:X.AI的Grok4模型,需在2个150兆瓦功率的数据中心、20万张算力卡组成的分布式集群中,耗时半年才完成预训练。这就像“建一座超大型工厂”,不仅要投入巨额资金采购设备,还需消耗海量能源,导致只有工业界能承担大规模预训练,学术界只能聚焦小模型(参数量<70亿)和理论研究。
2. Transformer架构的“先天不足”
当前大模型普遍采用的Transformer架构,存在类似“燃油车油耗过高”的先天问题:其Decode-only自回归结构的“算术强度”仅为2(每读取1字节数据只能完成2次计算),而卷积神经网络(CNN)的算术强度可达数百。这意味着Transformer需要频繁搬运数据,却只能完成少量计算,导致算力利用率(MFU)极低。
更麻烦的是,Transformer中的Softmax、Layer-norm等“特殊组件”难以用现有硬件并行计算,还高度依赖先进芯片工艺和高带宽存储器(HBM)——就像高端燃油车必须加98号汽油,缺一不可,进一步推高了成本和应用门槛。
3. AGI路径的“十字路口”
随着模型参数量逼近万亿、推理场景需要“长思维链输出”(如AI写代码需连贯逻辑)、AI for Science(如生物制药模拟)等新需求出现,上述问题愈发尖锐,还与“摩尔定律放缓”(芯片性能提升变慢)、“冯·诺依曼架构局限”(计算和存储分离导致数据搬运耗能耗时)形成突出矛盾。
更关键的是,现有大模型还面临“能否走向AGI”的争议:虽然规模扩展掩盖了“幻觉”“可解释性差”等问题,但AI科学家Yann Lecun等认为,基于“Next Token Prediction”(预测下一个词)的核心逻辑,让大模型难以真正理解物理世界——就像只会背菜谱的机器人,无法理解“火候”“食材新鲜度”对味道的影响,更无法自主做饭。
五、创新点
- 首次系统划分下一代计算范式的“双路径框架”:明确将脱离“Next Token Prediction”的新范式分为“更高抽象层次预测”(如Diffusion LLM、JEPA)和“物理第一性原理模型”(如液态神经模型、能量模型),为AGI技术路线提供清晰指引。
- 提出“软硬件协同破局”的核心思路:指出仅靠算法优化或硬件升级无法解决根本问题,需结合新型计算范式(如存算一体)与新型基材(如光器件、神经形态芯片),从底层重构AI计算体系,破解传统软硬件割裂难题。
- 工业界视角的“落地性验证”:通过中兴通讯的实践(如8T SRAM存内计算、循环式Transformer、FPGA加速DBM),验证了部分新范式的工程可行性,填补了“理论研究”与“产业落地”的 gap,避免技术方向“纸上谈兵”。
- 聚焦“能效优先”的未来导向:不同于传统研究只关注“算力提升”,论文强调未来AI计算的核心约束将是“能耗”,并围绕光计算、类脑计算等低能耗技术展开分析,契合全球“低碳算力”发展趋势。
六、研究方法和思路
论文采用“问题诊断—现有优化—未来探索—实践验证”的四步研究思路,逻辑清晰且层层递进:
步骤1:诊断现有大模型的核心问题(问题导向)
- 从“规模—效率—成本—AGI路径”四个维度,梳理当前LLM的痛点:先基于Scaling Laws分析规模扩张的必然性与代价,再通过Transformer与CNN的算术强度对比,量化架构效率问题,最后结合学界争议和工业界实践,指出AGI路径的不确定性。
- 数据支撑:引用GPT-3、Grok4等典型模型的参数量、训练资源数据,及Transformer算术强度(2)、CNN算术强度(数百)等量化指标,增强说服力。
步骤2:梳理现有改进方案(现状总结)
- 算法层:分类总结注意力机制优化(GQA、Flash-Attention等)、低精度量化(4-bit扩展率最优)、参数共享(循环式Transformer)三大方向,对比各技术的优势与局限。
- 工程层:分析集群并行(TP/DP/PP/EP)、P/D分离部署、端云协同的实现逻辑,结合Deepseek V3(FFN计算量减至1/32)等案例说明效果。
- 硬件层:拆解微架构DSA化、光IO互联、新型内存体系等优化手段,明确各技术的适用场景(如光电混合集群适合万卡以上规模)。
步骤3:探索下一代计算范式(未来预测)
- 路径1(更高抽象层次):
- Diffusion LLM:将自回归“串行生成”改为“从粗到细并行生成”,通过LLaDA等模型验证“10倍吞吐量+1/10能耗”的效果。
- JEPA:将多模态数据编码到“高层潜空间”,用能量模型替代概率模型,提升世界模型的抽象表达能力。
- 路径2(物理第一性原理):
- 液态神经模型:基于生物神经动力学,构建时间连续RNN(如LSSM),通过公式(\frac{d x(t)}{d t}=-\frac{x(t)}{\tau}+f(x(t), I(t), t, \theta) \times(A-x(t)))描述动态特性,优化时间序列预测性能。
- 能量模型(EBM):基于统计物理自旋玻璃模型,定义能量函数(E=-\sum {i<j}J{ij}m_{i}m_{j}+\sum h_{i}m_{i}),解决复杂概率分布建模问题。
步骤4:工业界实践验证(落地验证)
- 中兴通讯通过三类实践验证技术可行性:
- 存内计算:用8T SRAM实现12.31 TOPS/W@INT8的高能效加速器,突破冯·诺依曼架构“内存墙”。
- 循环式Transformer:以GPT-2 small单一层为“基块”,减少50%参数量仍保持模型性能(最佳损失3.30,接近原12层模型的3.35)。
- DBM加速:用FPGA实现数千神经元稀疏连接,将单batch训练时间从GPU的10小时缩至5分钟,加速超2个数量级。
七、主要成果和贡献
1. 核心成果总结
| 成果类别 | 具体内容 | 价值体现 |
|---|---|---|
| 理论成果 | 下一代计算范式“双路径框架” | 为AGI技术路线提供清晰划分,避免研究方向混乱 |
| 技术验证 | 8T SRAM存内计算(12.31 TOPS/W@INT8) | 突破传统架构能效瓶颈,可直接应用于端侧低功耗场景 |
| 循环式Transformer(减50%参数量) | 降低大模型训练/推理成本,让中小规模模型也能有高性能 | |
| FPGA加速DBM(120倍训练提速) | 解决能量模型“训练慢”难题,推动端侧部署 | |
| 工程方案 | 集群并行、P/D分离、端云协同 | 提升现有大模型算力利用率,降低工业界应用成本 |
2. 领域贡献
- 对科研人员:明确了下一代AI研究的“重点赛道”,不用再在“盲目扩容”上浪费精力,可聚焦Diffusion LLM、液态神经模型等方向。
- 对企业:提供了“降本增效”的具体方案——比如用循环式Transformer减少参数量,或用存内计算降低端侧设备能耗,让大模型从“奢侈品”变成“日用品”。
- 对行业:指出“软硬件协同”是未来趋势,推动芯片厂商(如设计存算一体芯片)、算法公司(如开发适配新硬件的模型)、应用企业(如部署端侧AI)形成协同生态,加速AGI落地。
- 无开源代码或数据集提及。
八、关键问题
问题1:当前Transformer架构的“低效”主要体现在哪里?为什么会导致算力浪费?
答:主要体现在“算术强度低”和“硬件适配难”两方面。算术强度仅为2,意味着每读取1字节数据只能完成2次计算,而数据搬运过程本身会消耗大量算力和带宽——就像快递员每次只送1个小包裹,却要跑一趟远路,效率极低;同时,Transformer中的Softmax、Layer-norm等非线性算子无法用现有硬件并行计算,导致部分算力单元闲置,进一步加剧浪费。
问题2:下一代计算范式为什么要脱离“Next Token Prediction”?有哪些具体替代方案?
答:因为“Next Token Prediction”的核心是“预测下一个词”,本质是基于文本规律的“概率游戏”,无法让模型真正理解物理世界(如无法解释“杯子掉地上会碎”的因果关系),难以走向AGI。具体替代方案分两类:一是更高抽象层次预测,如Diffusion LLM(并行生成内容,提升效率)、JEPA(学习多模态数据的抽象表示,理解世界模型);二是物理第一性原理模型,如液态神经模型(模拟生物神经动态,优化时间序列预测)、能量模型(基于物理能量规律建模,提升泛化能力)。
问题3:中兴通讯的“循环式Transformer”是如何做到“减少50%参数量还不降低性能”的?
答:核心是“参数共享+循环计算”。传统Transformer需要多层独立参数(如GPT-2有12层,每层参数独立),而循环式Transformer用单个Transformer层作为“基块”,通过多次循环计算替代多层独立计算——就像用1个多功能工具重复完成12次任务,替代12个单一工具各做1次任务。实验显示,用GPT-2 small单一层循环12次,最佳损失3.65(接近原12层的3.35);若用6层基块循环6次,最佳损失达3.30,甚至优于原模型,实现“少参数高性能”。
问题4:论文认为未来AI计算的核心约束会从“算力”变成“能耗”,为什么?如何解决?
答:因为现有AI计算依赖冯·诺依曼架构,用高精度二进制操作“模拟”神经网络——就像用超级计算机算“1+1”,大量能量浪费在数据搬运和纠错上。随着模型规模扩大,能耗增长速度远超算力增长速度(如Grok4训练消耗的能源相当于数千户家庭一年的用电量),未来“能不能用得起”会比“有没有算力”更关键。解决思路是采用非冯·诺依曼架构和存内计算,如光计算(用光子传数据,低能耗高速度)、类脑计算(模拟大脑神经元,高效处理低精度任务)、存算一体(计算和存储结合,减少数据搬运)。
九、总结
论文系统分析了当前AI大模型面临的“规模扩张—效率低下—成本高昂—AGI路径模糊”四大难题,先梳理了注意力机制优化、集群并行等现有改进方案,再创新性地提出下一代计算范式的“双路径框架”,最后通过中兴通讯的存内计算、循环式Transformer等实践,验证了部分技术的落地可行性。
整体而言,论文不仅为科研人员提供了清晰的AGI研究方向,也为企业提供了“降本增效”的工程方案,更指出“软硬件协同”是突破当前瓶颈的核心——只有让算法适配新硬件、硬件支撑新算法,才能让AI大模型从“追求规模”转向“追求效率”,真正迈向通用人工智能。
更多推荐

 11
11 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)