
ChatBI的学习
最后大模型生成的逻辑 SQL 会进入我们后处理模块,这个模块实现会对一些幻觉问题(比如字段或者表名不存在等)进行重试,接着会把逻辑 SQL 转换成我们定义好的 DSL 结构,有了这个 DSL 以后就可以对结果做一些校正澄清,也就是我们的智能感透出功能,比如用户问”东的销售额“的时候,我们发现“东北”和“华东”里都包含了”东“这个关键词,会提示用户让用户选择确认。另外用户也可以配置一些后处理的规则,
参考:(2 封私信) 有数 ChatBI:大模型驱动下的数据分析技术探索和实践 - 知乎
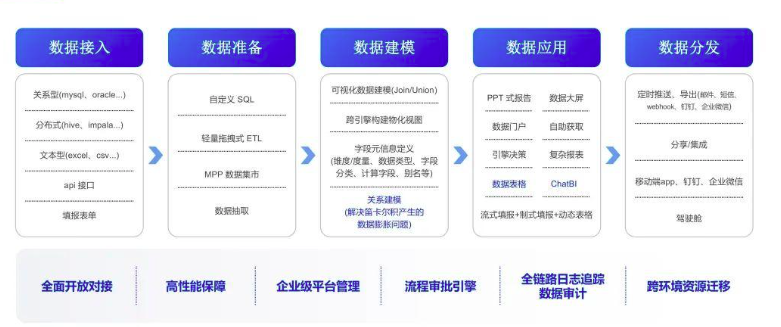
- 数据建模:通过拖拉拽的方式进行数据建模,在建模阶段我们支持跨引擎构建物化视图,通过物化视图 + CK 大宽表查询优势,可以将报表查询性能发挥到极致,另外最近一年我们上了关系模型的功能,可以彻底解决因为笛卡尔积产生的数据膨胀问题。
- 数据应用:有了宽表模型定义以后,我们就可以基于模型做一些报告、取数、大屏等数据应用,图中蓝色的部分是我们最近 2 年发布的两个新的产品模块,一个是数据表格,解决中国复杂式报表制作的场景,比如财务报表、监管报送、会计审计等报表,另外一个功能是今天要分享的 ChatBI 模块,可以利用大语言模型的能力直接通过自然语言提问的方式进行数据分析。
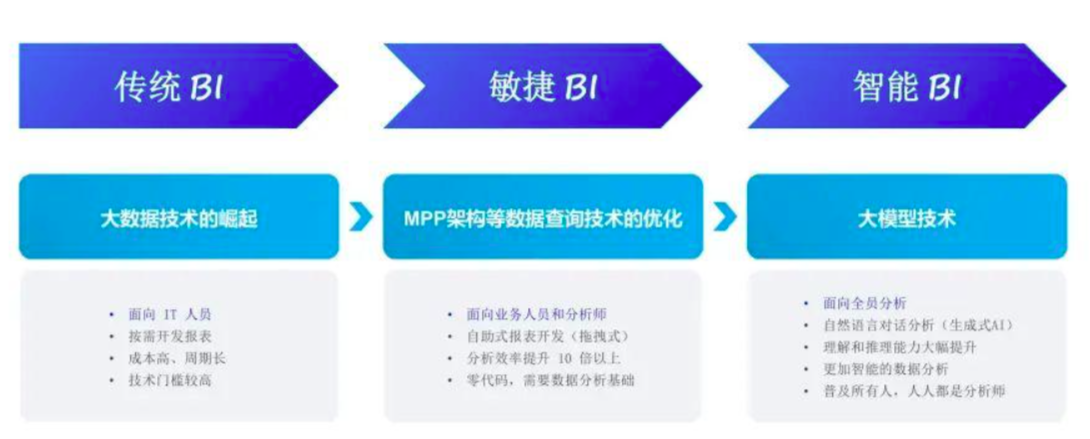
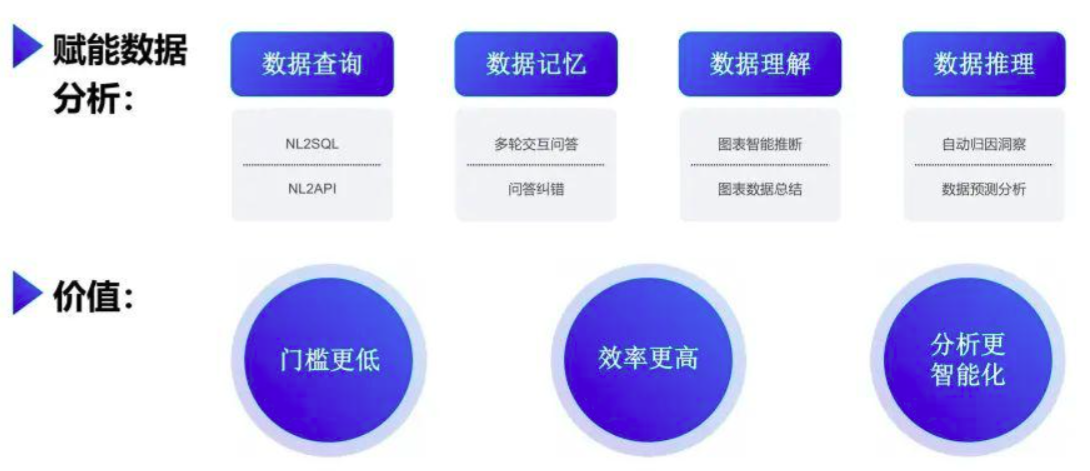
结合大模型的理解能力,通过 NL2SQL 和 NL2API 等方式可以轻松实现自然语言的数据查询能力;另外大模型的上下文记忆能力,让多轮交互数据问答实现成为可能,并可以进行问题的自动纠错等能力;在数据理解和数据推理上,我们借助大模型可以实现图表的智能解读以及数据的归因洞察等高级分析功能。
每个做智能 BI 厂商都可能面临的问题:
- 准确性和可信问题:大模型有个致命的问题就是幻觉,但是数据分析本身又是一个很严谨的事情,另外缺少行业知识和属性,再加上用户问题缺少规范化,如何解决数据的信任问题成了智能 BI 最大的挑战。
- 查询性能问题:智能问答都是很随机的问题,查询复杂性会更高,包括大模型推理、数据查询、数据渲染都有一定的耗时,会让性能问题更加凸显。
- 客户场景落地难点:如果没有完善的工程化能力的辅助,AI 的价值很难变现,客户场景问题千奇百怪,我们如何运营和优化成了在客户场景落地的难点。
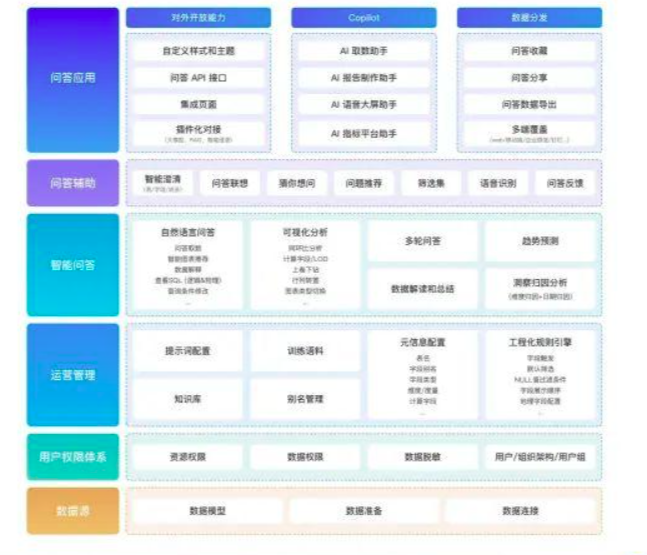
我们就可以通过 chat 的方式实现智能取数、多轮问答、数据分析等高级能力。另外在问答应用上,我们支持很多对外开放的能力,支持开放的数据问答 API,集成页面的嵌入等,另外我们将 ChatBI 作为 Copilot 助手,辅助我们各种数据应用的开发。同时支持问答收藏、分享、移动端等数据分发的能力,可以实现和业务系统的完美融合。
-----------------------------------------------------------------------------------
Copilot,其字面意思是“副驾驶”或“联合飞行员”,在现代科技语境下,尤其指代一类由人工智能驱动的辅助工具或系统。这类工具旨在作为人类用户的智能助手,通过理解上下文、提供建议、生成内容或执行任务来增强人类的生产力和创造力。
最著名的例子是 GitHub Copilot,它是一个基于人工智能的代码补全工具,能够根据开发者在集成开发环境(IDE)中编写的注释和代码,实时建议下一行甚至整个函数的代码。它由 GitHub 与 OpenAI 合作开发,利用了 OpenAI 的大型语言模型技术。
更广泛地说,Copilot 已成为一个品牌或概念,被应用于多个领域:
- Microsoft 365 Copilot:集成在 Word、Excel、PowerPoint、Outlook 等办公套件中的人工智能助手,帮助用户撰写文档、分析数据、制作演示文稿、总结邮件等。
- GitHub Copilot Chat:在开发环境中提供对话式编程支持,可以解释代码、调试错误、生成测试等。
- Windows Copilot:集成在 Windows 操作系统中的 AI 助手,帮助用户执行系统操作、获取信息、与应用程序交互等。
核心特征:
- 上下文感知:能够理解用户当前正在处理的任务或内容。
- 主动建议:不仅仅是被动响应,还能主动提供预测和建议。
- 自然语言交互:通常支持通过自然语言进行指令输入和对话。
- 增强而非替代:设计初衷是作为“副驾驶”,辅助人类决策和工作,而非完全取代人类。
总而言之,Copilot 代表了一种人机协作的新范式,即利用强大的 AI 模型作为智能副手,帮助用户更高效、更智能地完成各种任务。
----------------------------------------------------------------------------
瞄准数据可信,从而解决 AI + BI 分析最棘手的问题,用户对大模型返回的数据的信任其实是 ChatBI 可用可落地的前提,既要追求查询的准确率更要追求数据的可信。
从数据可理解、用户可干预、过程可验证、产品可运营四个方面阐述如何打造可信的 ChatBI。
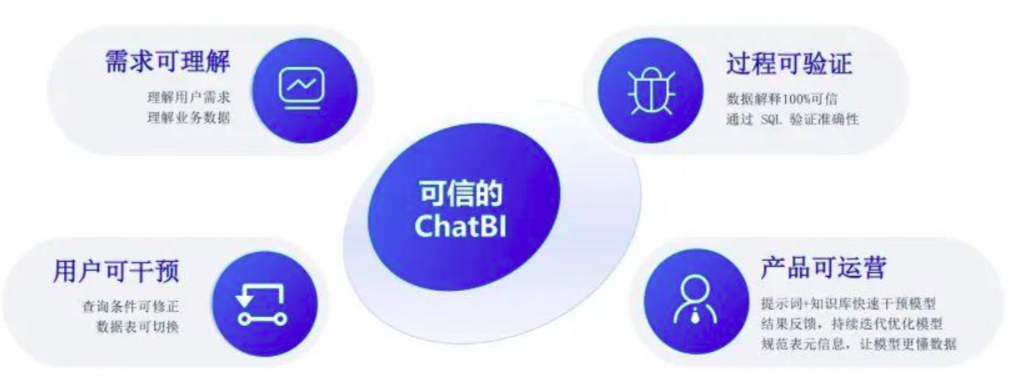
我们将 SQL 的执行过程翻译成用户可以理解的语言描述,这个描述一定代表了背后 sql 的执行逻辑,用户可以通过数据解析快速验证数据的对错,从而保证了数据的百分之百可信。
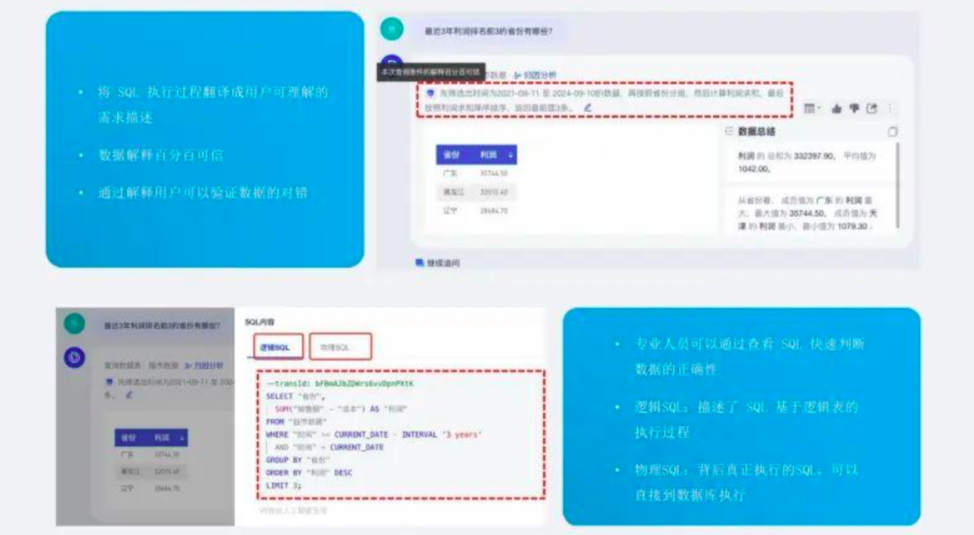
另外对于专业的人员,可以通过查看 sql 判断数据的正确性,逻辑 sql 是大模型基于逻辑表生成 sql,物理 sql 是背后数据库真正执行的 sql,通过这两种方式保证了查询过程的可理解。
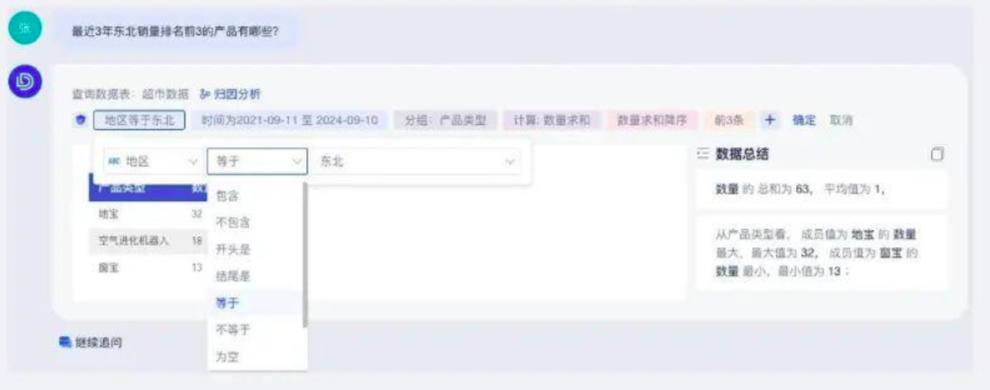

知识库、训练语料、提示词等成熟的运营手段来提高问答的准确率
ChatBI 技术原理
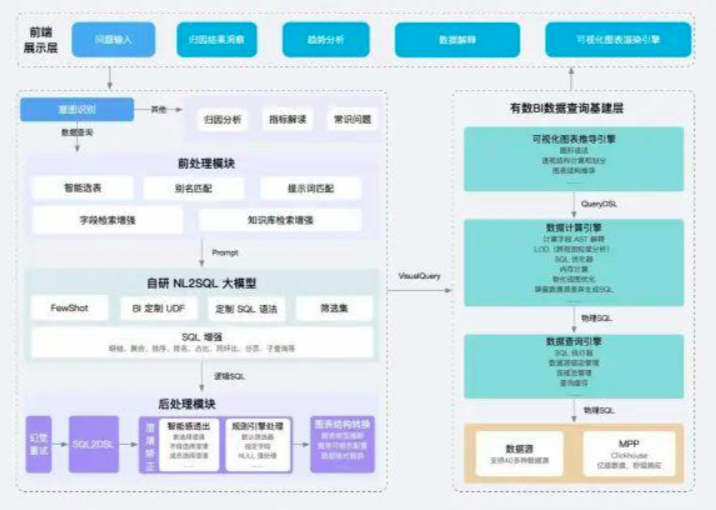
当用户输入问题后会经过我们意图识别模块,意图识别主要包括数据查询、归因分析、指标解读等能力,如果发现是数据查询会经过我们下面的核心查询流程,包括前处理模块、自研 NL2SQL 大模型、后处理模块、数据查询基建层四个模块
- 前处理模块:
首先前处理模块主要是基于用户配置的提示词、知识库、筛选集等信息,使用智能选表和检索增强等技术优化 prompt,最后输入给自研的 NL2SQL 大模型。
- 自研 NL2SQL 大模型:
自研的 NL2SQL 大模型是经过专门调优训练的,在聚合、排序、排名、同环比等方面都做了非常大的增强,同时支持一些自定义的特性,比如 UDF 函数、筛选集等。其中同环比函数由于涉及到子查询生成的 SQL 较为复杂,就是通过自定义 UDF 函数能力实现的。
- 后处理模块:
最后大模型生成的逻辑 SQL 会进入我们后处理模块,这个模块实现会对一些幻觉问题(比如字段或者表名不存在等)进行重试,接着会把逻辑 SQL 转换成我们定义好的 DSL 结构,有了这个 DSL 以后就可以对结果做一些校正澄清,也就是我们的智能感透出功能,比如用户问”东的销售额“的时候,我们发现“东北”和“华东”里都包含了”东“这个关键词,会提示用户让用户选择确认。另外用户也可以配置一些后处理的规则,比如添加默认筛选器、返回指定字段等,这些自定义的规则会在规则引擎中进行处理最后生成一个完整的 DSL。接着根据这个 DSL 进行图表类型的推断、图表可视化配置、字段格式配置推断等,最终生成我们的有数 BI 图表配置结构 VisualQuery。
- 数据查询基建层:
有了 VisualQuery 进入了架构图图的右侧,是我们有数 BI 已有的数据查询基建层,包括可视图图表推导引擎、数据计算引擎、数据查询引擎三个核心模块,最终生成可执行的物理 SQL 并将数据返回给前端进行展示。

更多推荐


 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)