
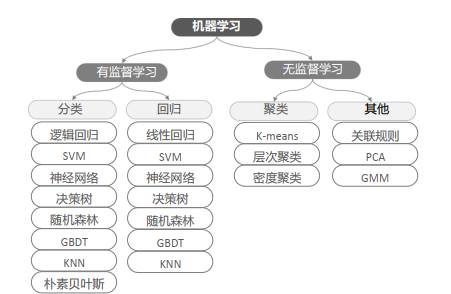
学习华为昇腾AI教材机器学习部分Day2
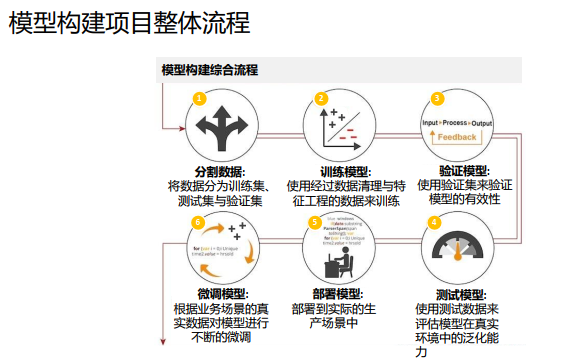
03机器学习的整体流程
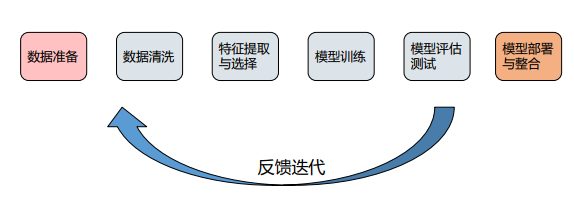
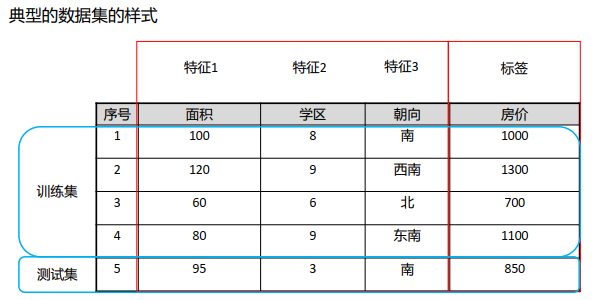
数据集分为训练集和测试集两类。反映事物在某方面的表现或性质的事项或属性称为特征。
大部分情况下, 数据需要经过预处理后才能够为算法所使用, 预处理的操作主要包括以 下几个部分:数据过滤、 处理数据缺失、 处理可能的错误或者异常值、 合并多个数据源数据 、数据汇总。
真实数据中存在着一些质量问题,比如说不完整、多噪音、不一致等等。
对数据进行初步的预处理后, 需要将其转换为一种适合机器学习模型的表示形式, 以下是一些常见的数据转化的形式。
在分类问题中,将类别数据编码成为对应的数值表示。 数值数据转换为类别数据以减少变量的值(对年龄分段)。
其他数据: 在文本中,通过词嵌入将词转化为词向量(一般使用word2vec模型, BERT模型等)。 处理图像数据(颜色空间,灰度化,几何变化, haar特征等,图像增强)。
特征工程: 对特征进行归一化、标准化,以保证同一模型的不同输入变量的值域相同。 特征扩充:对现有变量进行组合或转换以生成新特征,比如平均数。
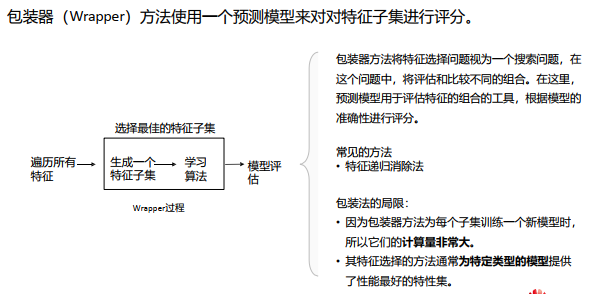
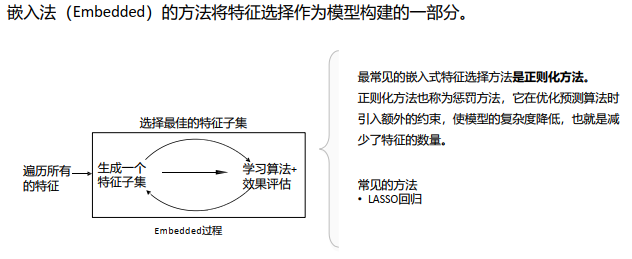
特征选择的方法包括Filter、Wrapper、Embedded。

好模型的标准:泛化能力即能否在实际的业务数据也能预测准确(最重要) ;可解释性即预测的结果是否容易被解释 ;预测速率即每一条数据的预测需要多长时间。
泛化能力就是相当于应用能力,在训练样本时能够实现良好效果,同时,也能够适用于其他样本。
误差分为训练误差(训练集上的误差)和泛化误差(新样本上的误差)。
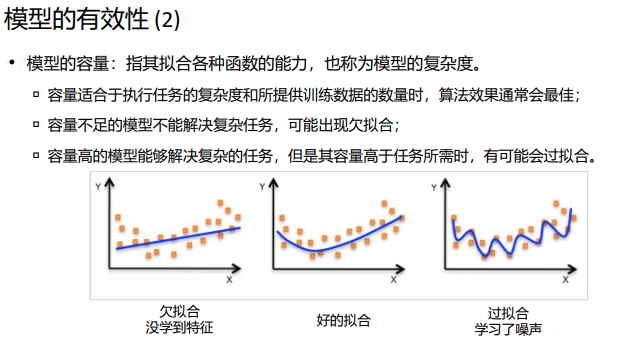
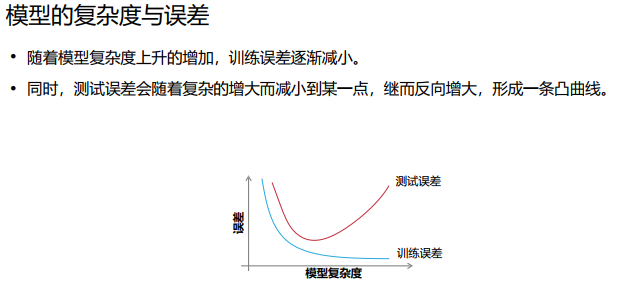
过拟合:过于复杂的数学模型比较容易发生过拟合,适当简化数学模型、在过拟合前提前结束训练、采用Dropout/Weight Decay手段等,可以减轻过拟合现象。
欠拟合:过于简单的数学模型,或训练时间太短,则可能引起欠拟合。对于前者,需使用更复杂的模型,对于后者,只需延长训练时间,即可有效缓解欠拟合现象。
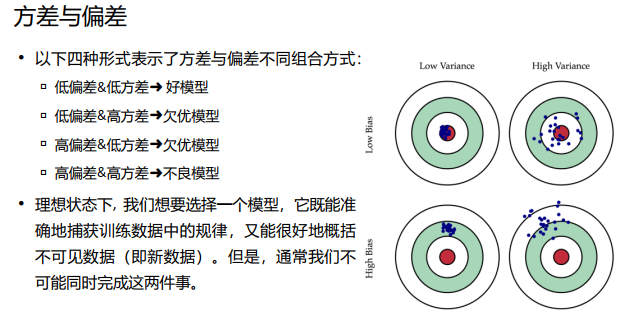
过拟合的原因在于存在误差,最终预测的总误差= 偏差的平方 + 方差 + 不可消解的误差

04其他机器学习重要方法
机器学习训练方法——梯度下降
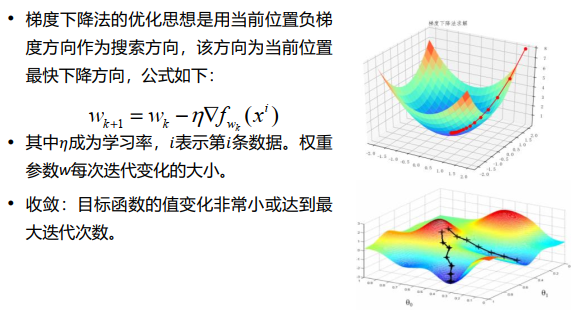
通常情况下,在接近目标点区域的极小范围内,下降的幅度是越来越小的。但是,在目标点一定范围内可能存在梯度不稳定的情况。
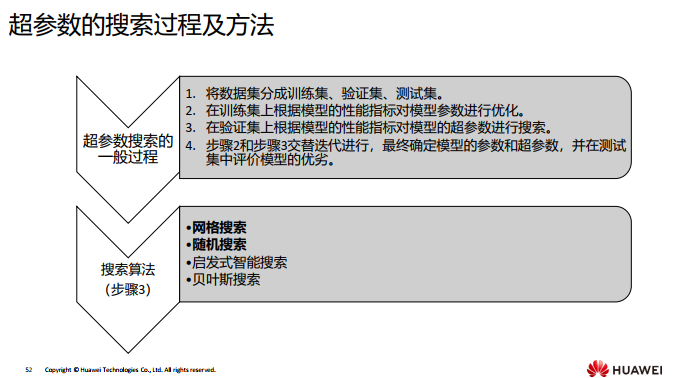
模型中不但有参数, 还有超参数的存在。 其目的是为了让模型能够学习到最佳的参数。
参数由模型自动学习;
超参数由人工手动设定。

参数作为模型从历史训练数据中学到的一部分,是机器学习算的关键。有以下特征:进行模型预测时需要模型参数。模型参数值可以定义模型功能。模型参数用数据估计或数据学习得到。模型参数一般不由实践者手动设置。模型参数通常作为学习模型的一部分保存。
模型参数的一些例子包括:人造神经网络中的权重。支持向量机中的支持向量。线性回归或逻辑回归中的系数。


交叉验证:是用来验证分类器的性能一种统计分析方法, 基本思想是把在某种意义下将 原始数据进行分组, 一部分作为训练集, 另一部分作为验证集, 首先用训练集对分类器 进行训练, 再利用验证集来测试训练得到的模型, 以此来做为评价分类器的性能指标。
𝑘-折交叉验证(𝑲 − 𝑪𝑽) : 将原始数据分成𝑘组(一般是均分)。 将每个子集数据分别做一次验证集,其余的𝑘 − 1组子集数据作为训练集,这样会得到𝑘个模型。 用这𝑘个模型最终的验证集的分类准确率的平均数作为此𝐾 − 𝐶𝑉下分类器的性能指标。
将数据集分成固定的训练集和固定的测试集后,若测试集的误差很小,这将是有问题 的。一个小规模的测试集意味着平均测试误差估计的统计不确定性。使得很难判断算 法𝐴是否比算法𝐵在给定任务上做得更好。当数据集有十万计或者更多的样本时,这 不会是一个严重的问题。当数据集太小时,也有替代方法允许我们使用所有的样本估 计平均测试误差,代价是增加计算量。
𝑘折交叉验证: 𝑘一般大于等于2,实际操作时一般从3开始取,只有在原始数据集合数据量小的时候才会尝试取2。 𝐾 − 𝐶𝑉 可以有效的避免过学习以及欠学习状态的发生, 最后得到的结果也比较具有说服性。注意: K折交叉验证的K值,属于超参数。
05机器学习的常见算法
一、线性回归
线性回归是利用数理统计中回归分析, 来确定两种或两 种以上变量间相互依赖的定量关系的一种统计分析方法。 线性回归是一种有监督学习。

多项式回归, 是线性回归的拓展, 通常数据集的复杂度会超过用一条直线来拟合的可能性, 也就是使用原始的线性回归模型会明显欠拟合。 解决的办法就是使用多项式回归。 多项式回归仍然是线性回归的一种, 是因为其非线性体现在特征的维度上, 而其权重参数𝑤之间的关系仍然是线性的。

二、逻辑回归
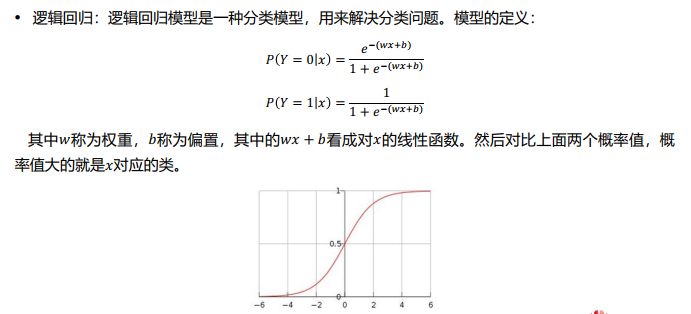

追加正则项之后,逻辑回归也可以防止过拟合。
逻辑回归常用于二分类问题, 如果是多分类问题, 我们通常使用Softmax函数。
Softmax回归是逻辑回归的一般化, 适用于K分类的问题。
Softmax函数的本质就是将一个K维的任意实数向量压缩(映射) 成另一个K维的实数向量, 其中向量中的每个元素取值都介于(0, 1) 之间。
Softmax为多类问题中的每个分类分配了概率值。 这些概率加起来等于1。
三、决策树
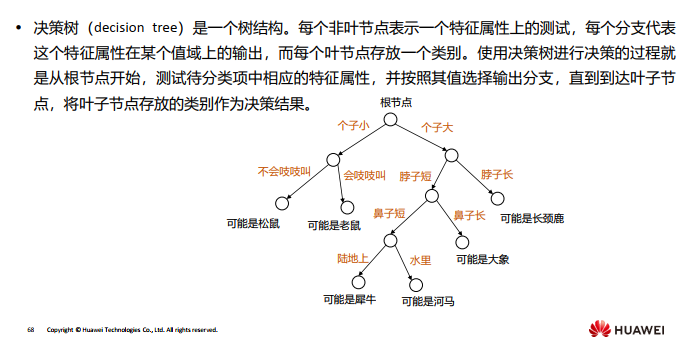
决策树最重要的是决策树的构造。所谓决策树的构造就是进行属性选择度量确定各个 特征属性之间的拓扑结构。构造决策树的关键步骤是分裂属性,即在某个节点处按照 某一特征属性的不同划分构造不同的分支。
决策树的学习算法用来生成决策树,常用的学习算法为ID3, C4.5, CART。
除了根节点之外的其它节点统称为叶子节点。


四、支持向量机
支持向量机是一种二分类模型, 它的基本模型是定义在特征空 间上的间隔最大的线性分类器。 SVM还包括核技巧, 这使它成为实质上的非线性分类器。 支持向 量机的学习算法是求解凸二次规划的最优化算法。
SVM的主要思想可以概括为两点: ①对于线性不可分的情况,通过使用非线性映射算法将低维输入空间线性不可分 的样本转化为高维特征空间使其线性可分,从而使得高维特征空间采用线性算 法对样本的非线性特征进行线性分析成为可能。 ②它基于结构风险最小化理论之上特征空间中构建最优超平面,使得学习器得到 全局最优化,并且在整个样本空间的期望以某个概率满足一定上界。
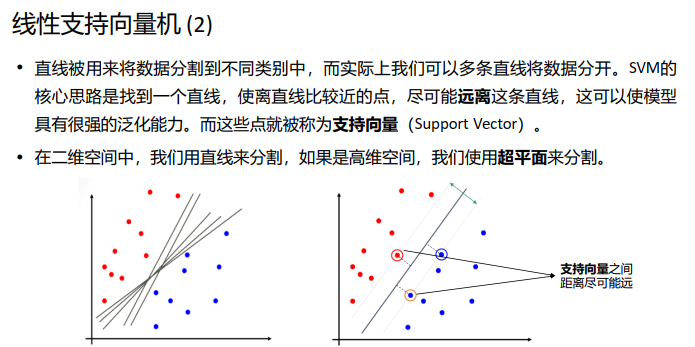
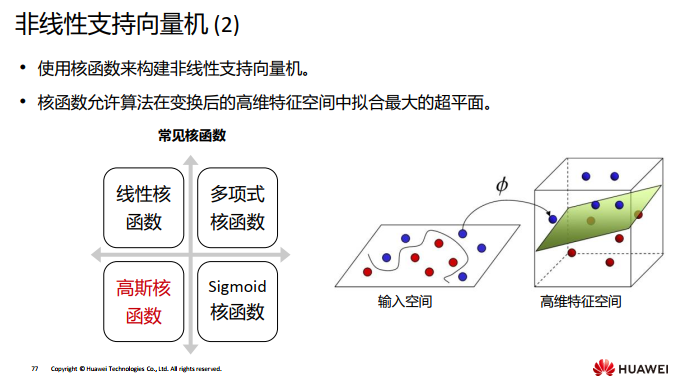
其中,高斯核函数用的最多。
五、K最邻近算法
K最近邻KNN 分类算法, 是一个理论上比较成熟的方法, 也是最简单的机器学习算法之一。 该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别, 则该样本也属于这个类别。
KNN的核心思想是“近朱者赤, 近墨者黑” , 其在逻辑上十分的简洁。
KNN是非参数方法, 常用在决策边界非常不规则的数据集中使用。
KNN在分类预测时,一般采用多数表决法; KNN在做回归预测时,一般采用平均值法。
KNN需要非常大的计算量。

六、朴素贝叶斯

类条件独立性:贝叶斯分类法假定一个属性值在给定类上的影响独立于其他属性的值。 做此假定是为了简化计算,并在此意义下成为“朴素的”。
贝叶斯分类器应用于大型数据库具有较高的准确性和快速的速度。

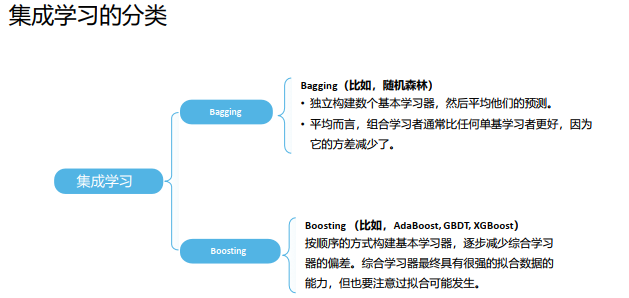
七、集成学习
集成学习是一种机器学习范式, 在这种范式中, 多个学习者被训练和组合以解决同一个问题。 通过使用多个学习者, 集成的泛化能力可以比单个学习者强得多。 如果随机向数千人提出一个复杂的问题, 然后汇总他们的答案。 在许多情况下, 会发现这个汇总的答案比专家的答案更好。 这就是群众智慧。
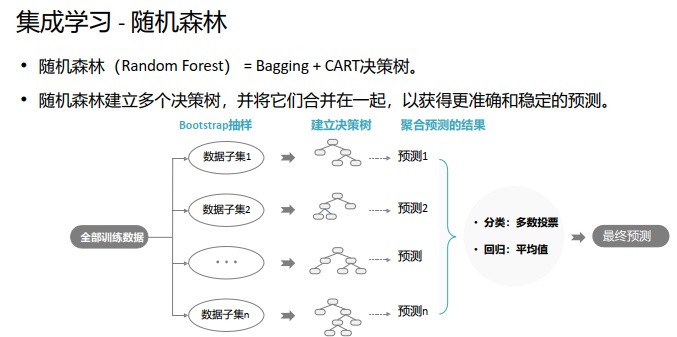
随机森林可以用于分类和回归问题。
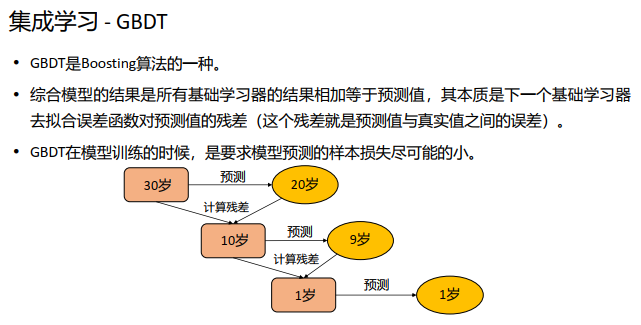

更多推荐

 38
38 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)