
大模型基石:从“字词”到“Token”,一文讲透LLM如何理解人类语言
Token是大模型处理文本的基本单元,它将人类语言拆解为模型可理解的离散片段。文章从概念、必要性、技术实现到应用场景全面解析了Token:1)作为语言"积木",Token通过子词切分解决词汇表爆炸问题;2)采用BPE等算法实现跨语言统一处理;3)直接影响GPU显存、算力等硬件需求;4)在并发测试中体现为吞吐量、响应延迟等关键指标。商用场景按Token计费因其准确反映算力消耗,形
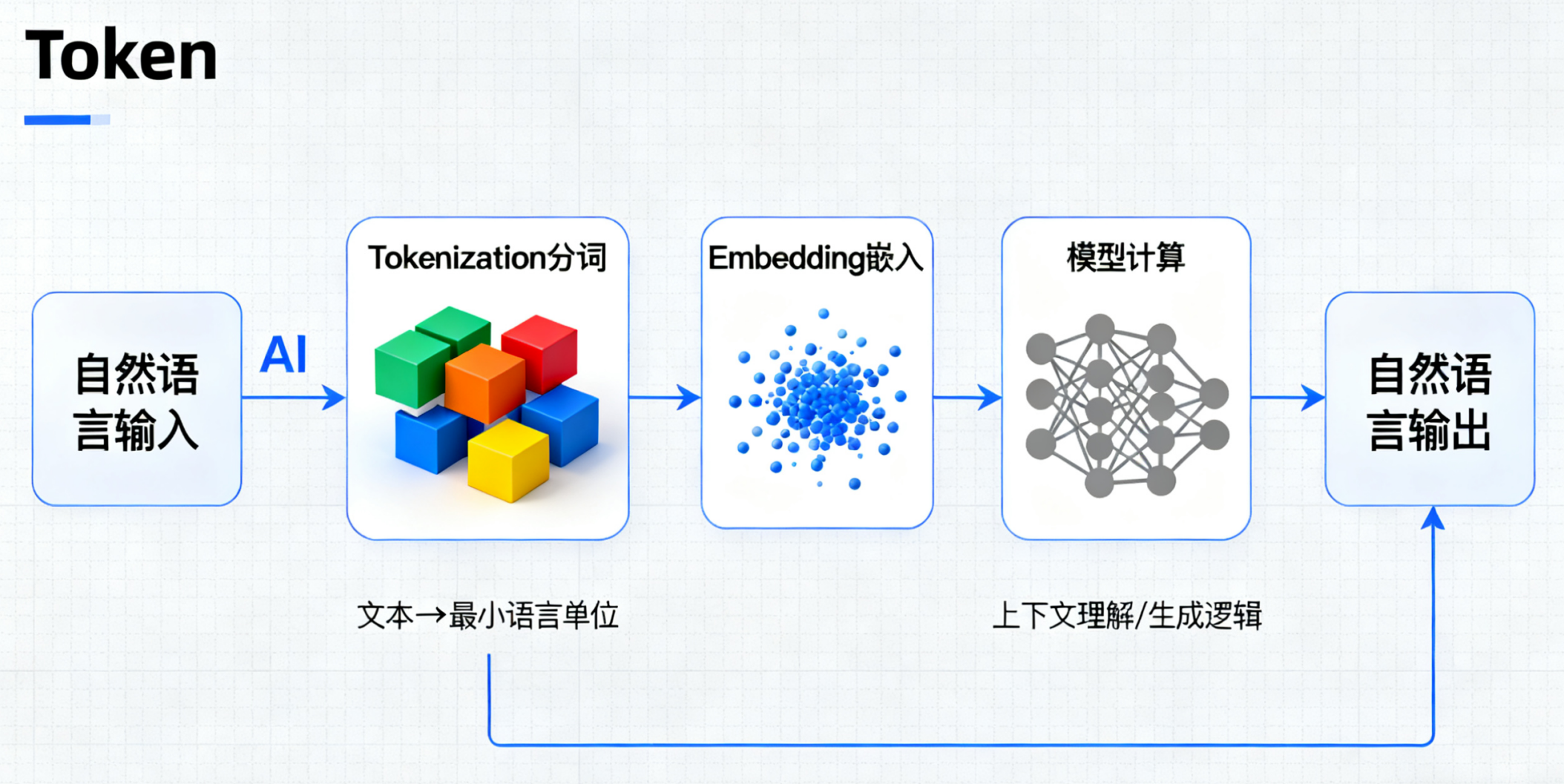
一、Token 是什么?
你可以把Token想象成模型能看懂的“积木块”或“碎片”。
- 对我们人类来说,我们看的是文字,比如“我喜欢吃苹果”。
- 对模型来说,它看不懂整个句子,需要把句子打碎成一个个小单元,这些小单元就是Token。
1、一个精妙的比喻:乐高积木
-
人类读文章:理解为由字、词、句组成的连续语义流。
-
模型读文章:理解为由一个个离散的Token“积木”拼接而成的序列。
-
结论:Token就是模型用来构建语言大厦的基本积木块。
2、直观感受:中英文分词对比
-
我喜欢吃苹果:这句话就被打碎成了6个Token,“我”、“喜”、“欢”、“吃”、“苹”、“果”。
-
unbelievable:可能会被拆成“un”、“believe”、“able”三个Token。
# 导入Transformers库中的AutoTokenizer,用于加载不同大模型的分词器
from transformers import AutoTokenizer
# 加载常用大模型的分词器(以GPT-3.5 Turbo为例,可替换为其他模型如"bert-base-chinese"等)
tokenizer = AutoTokenizer.from_pretrained("gpt-3.5-turbo")
# 替换为目标中文文本和英文文本
text_zh = "我喜欢吃苹果" # 原文本“我喜欢吃披萨!”替换为“我喜欢吃苹果”
text_en = "unbelievable" # 原文本“I love pizza!”替换为“unbelievable”
# 使用分词器对中英文文本进行Token拆分
tokens_zh = tokenizer.tokenize(text_zh)
tokens_en = tokenizer.tokenize(text_en)
# 打印分词结果,直观展示Token拆分逻辑
print(f"中文「{text_zh}」的分词结果: {tokens_zh}")
# 输出示例: ['我', '喜欢', '吃', '苹', '果']
# (注:不同模型分词规则略有差异,GPT系列对中文单字/常用词拆分更灵活,部分模型可能拆为['我', '喜欢', '吃', '苹果'])
print(f"英文「{text_en}」的分词结果: {tokens_en}")
# 输出示例: ['un', 'believ', 'able']
# (注:英文分词常基于BPE算法,会将长单词拆分为子词单元,“unbelievable”因长度较长,会拆为前缀“un”、词根“believ”和后缀“able”)3、简单总结:Token就是大模型处理信息时使用的最小单位
- 模型读东西(输入)和写东西(输出),都是在处理一个个的Token
二、为何需要 Token?
1、应对“词汇表爆炸”
如果以“词”为单位,模型需要维护一个包含数百万甚至上千万词的巨型词汇表,计算和存储成本极高。
- 致命痛点
- 存储成本失控
大模型的 “嵌入层(Embedding Layer)” 需要为每个单词分配一个专属的向量(用于后续计算),若词汇表有 1000 万词,每个向量按 1024 维(常见维度)、float32 精度(4 字节 / 维度)计算,仅嵌入层的存储需求就达 1000 万 ×1024×4 字节 = 4GB—— 这还只是模型的 “基础存储成本”,叠加其他网络层后,普通硬件根本无法承载。
- 计算效率骤降
人类语言中存在大量 “长尾词汇”(如生僻词、专有名词),这些词汇使用频率极低,但若不纳入词汇表,模型遇到时就会以 “未知词()” 替代,直接切断语义理解链条 —— 这意味着 “以词为单位” 的方案,要么承受高昂成本,要么牺牲处理能力,陷入两难。
- 存储成本失控
- 破局思路
- 子词切分:把 “大词” 拆成 “可复用小单元”
Token 不执着于保留单词的完整性,而是将单词拆分为更基础、可重复使用的子词片段,是通过 BPE(字节对编码)、WordPiece 等算法,从海量语料中统计 “高频子串组合” 生成。
- 词汇表瘦身:规模可控,成本骤降
通过子词切分,模型只需维护一个包含 3 万~5 万个 Token 的词汇表(如 GPT-3 的词汇表约 5 万 Token,BERT-base-chinese 的词汇表约 2.1 万 Token),就能覆盖 99% 以上的日常语言和专业领域文本。
- 子词切分:把 “大词” 拆成 “可复用小单元”
- 代码示例
- 模拟 “输入新词时 Token 的拆分逻辑”,直观验证其如何避免 “词汇表新增词条”
# 1. 导入依赖库,加载GPT-3.5 Turbo分词器(词汇表约5万Token) from transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained("gpt-3.5-turbo") # 2. 定义“长尾新词”(这类词未直接收录在基础词汇表中) # 中文:专业术语“量子计算芯片”、网络新词“AI生成式绘画” # 英文:复合词“self-driving-robotaxi”(自动驾驶无人出租车)、生僻词“antidisestablishmentarianism”(反政教分离主义) new_words_zh = ["量子计算芯片", "AI生成式绘画"] new_words_en = ["self-driving-robotaxi", "antidisestablishmentarianism"] # 3. 对新词进行Token拆分,观察结果 print("=== 中文新词的Token拆分结果 ===") for word in new_words_zh: tokens = tokenizer.tokenize(word) print(f"新词「{word}」→ Token拆分:{tokens}") print(f"拆分后Token数量:{len(tokens)}(无需在词汇表新增「{word}」这一词条)\n") print("\n=== 英文新词的Token拆分结果 ===") for word in new_words_en: tokens = tokenizer.tokenize(word) print(f"新词「{word}」→ Token拆分:{tokens}") print(f"拆分后Token数量:{len(tokens)}(无需在词汇表新增「{word}」这一词条)\n") # 4. 验证:检查新词是否被识别为“未知词(<UNK>)” print("=== 验证未知词情况 ===") # 若词汇表未覆盖,会输出<UNK>,此处因Token拆分,无未知词 for word in new_words_zh + new_words_en: input_ids = tokenizer.encode(word, add_special_tokens=False) has_unk = tokenizer.unk_token_id in input_ids print(f"新词「{word}」是否为未知词:{'是' if has_unk else '否'}") - 运行结果
=== 中文新词的Token拆分结果 === 新词「量子计算芯片」→ Token拆分:['量', '子', '计', '算', '芯', '片'] 拆分后Token数量:6(无需在词汇表新增「量子计算芯片」这一词条) 新词「AI生成式绘画」→ Token拆分:['AI', '生', '成', '式', '绘', '画'] 拆分后Token数量:6(无需在词汇表新增「AI生成式绘画」这一词条) === 英文新词的Token拆分结果 === 新词「self-driving-robotaxi」→ Token拆分:['self', '-', 'driving', '-', 'robot', 'axi'] 拆分后Token数量:6(无需在词汇表新增「self-driving-robotaxi」这一词条) 新词「antidisestablishmentarianism」→ Token拆分:['anti', 'dis', 'establishment', 'arian', 'ism'] 拆分后Token数量:5(无需在词汇表新增「antidisestablishmentarianism」这一词条) === 验证未知词情况 === 新词「量子计算芯片」是否为未知词:否 新词「AI生成式绘画」是否为未知词:否 新词「self-driving-robotaxi」是否为未知词:否 新词「antidisestablishmentarianism」是否为未知词:否
- 模拟 “输入新词时 Token 的拆分逻辑”,直观验证其如何避免 “词汇表新增词条”
2、解决“未知词(OOV)”问题
以 “词” 为单位的模型,会陷入 “未知词(Out-of-Vocabulary,OOV)” 困境:当遇到未收录的新词(如 AI 领域的 “ChatGPT”“Stable Diffusion”、网络热词 “绝绝子”、专业术语 “元宇宙基建”)时,无法识别且无处理方案,只能用 “” 符号替代 —— 这不仅会切断语义理解链条(比如 “用 ChatGPT 生成图片” 变成 “用生成图片”,模型无法判断的含义),还会导致生成内容断层(无法输出 “Stable Diffusion” 这类新词,影响实用价值)。
而 Token 通过 “子词拆分” 轻松破解这一问题:无需新增词汇表,只需将新词拆分为已有的基础 Token 单元。例如:
- “ChatGPT” 拆分为 ["Chat", "G", "PT"],模型通过 “Chat”(聊天)、“G”(常关联 GPT 系列)、“PT”(Pre-trained 缩写)的组合,能理解其为 AI 对话模型。
- “Stable Diffusion” 拆分为 ["Stable", "Diffusion"],“Stable”(稳定)与 “Diffusion”(扩散)的语义关联,让模型识别其为图像生成工具。
这种拆分逻辑,让模型即使面对未见过的新词,也能通过已知 Token 的组合理解含义并正常生成,彻底摆脱 “困境”。
3、实现跨语言统一处理
Token 通过 “底层编码统一” 打破了这种割裂:依托 BPE、SentencePiece 等算法,将所有语言的文本先转化为基础字节流,再映射到同一个共享的 Token ID 空间。例如:
- 中文 “人工智能” 拆分为 ["人","工","智","能"],英文 “Artificial Intelligence” 拆分为 ["Art","ificial","Intelligence"],两种语言的 Token 虽不同,但共享同一套 ID 编码规则
- 甚至词边界模糊的日语(如 “こんにちは”)、形态复杂的德语(如 “unabhängigkeit”),也能拆分为通用子词 Token 并纳入统一空间。
三、Token 关联 GPU 哪些参数?

1、显存(VRAM)
- 作用类比:显存是 GPU 的 “专属工作台 + 仓库”,既要存放大模型的所有参数(相当于 “生产原料”),也要临时存储处理 Token 时产生的中间数据(如文本转化的向量、计算过程中的激活值,相当于 “半成品”)。
- 与 Token 的核心关系:Token 数量直接决定显存占用量 —— 输入的 Token 越多(如长文档)、生成的 Token 越多(如长输出),需要存储的中间数据量就越大,对显存容量的要求越高。
- 实际影响:若显存不足,会直接导致任务中断(如提示 “Out of Memory”),无法完成 Token 的拆分、计算与生成。
2、算力(FLOPS)
- 作用类比:算力是 GPU 的 “工人数量与工作速度”,衡量每秒能完成的浮点数计算次数,而大模型处理每个 Token 都需要执行大量矩阵运算(如语义向量计算、注意力权重更新)。
- 与 Token 的核心关系:算力强弱直接决定 Token 处理速度 —— 算力越高,GPU 每秒能处理 / 生成的 Token 数量(Tokens per Second,TPS)越多,比如同样生成 1000 个 Token,高算力 GPU 可能只需几秒,低算力则需十几秒。
- 实际影响:算力不足会导致 Token 生成卡顿,尤其是长文本生成时,等待时间会显著增加,影响使用体验。
3、内存宽带(Memory Bandwidth)
- 作用类比:内存带宽是连接显存与计算核心的 “高速公路宽度”,负责将显存中存储的模型参数、Token 数据,快速搬运到计算核心进行处理。
- 与 Token 的核心关系:带宽速度决定数据供给效率 ——Token 生成是 “逐次进行” 的,每生成一个 Token 都需要反复从显存读取模型参数,若带宽不足,计算核心会因 “等数据” 陷入闲置(即 “带宽瓶颈”)。
- 实际影响:即使显存足够、算力充足,低带宽仍会拖慢 Token 生成速度,导致 “硬件性能无法完全发挥”,出现 “算力过剩但速度上不去” 的情况。
四、Token 如何生成?
1、分词器工作原理
分词器的核心任务是将原始文本转换成模型能理解的数字序列,这个过程的关键步骤如下:
# 分词器的完整工作流程
原始文本 → 预处理 → 分词算法 → 映射为ID → 模型输入
"Hello world!" → "hello world!" → ["hello", "world", "!"] → [123, 456, 789] → 模型处理2、主流分词算法简介
-
BPE(Byte Pair Encoding):GPT系列使用。从字符开始,逐步合并最高频的符号对。
-
工作原理:从字符级别开始,逐步合并最高频的字符对。
训练过程示例:
# 假设初始词汇表(字符级) 初始词汇表:{'l', 'o', 'w', 'e', 'r', 'd', 'h', 't'} # 训练文本:"lower lower lower lowest" 统计字符对频率: ('l','o')出现4次, ('o','w')出现3次, ('e','r')出现3次... # 第一轮合并:合并最高频的字符对('l','o')→'lo' 新词汇表加入'lo' 文本变为:"lo wer lo wer lo wer lo west" # 第二轮合并:合并('lo','w')→'low'(因为'low'出现3次) 新词汇表加入'low' 文本变为:"low er low er low er low est" # 如此继续,直到达到预设的词汇表大小代码实现简化版:
import re from collections import Counter def train_bpe(text, vocab_size): # 初始化为字符级别 vocab = set(text) merges = {} while len(vocab) < vocab_size: # 统计所有相邻符号对的频率 pairs = Counter() words = text.split() for word in words: symbols = word.split() for i in range(len(symbols)-1): pairs[(symbols[i], symbols[i+1])] += 1 if not pairs: break # 合并最高频的符号对 best_pair = max(pairs, key=pairs.get) merged = ''.join(best_pair) merges[best_pair] = merged vocab.add(merged) # 更新文本中的该符号对 text = text.replace(' '.join(best_pair), merged) return vocab, merges # 使用示例 text = "low lower lowest new newer newest" vocab, merges = train_bpe(text, vocab_size=20)
-
-
WordPiece:BERT系列使用。与BPE类似,但合并策略基于概率而非频率。
-
与BPE的关键区别:
-
BPE:基于频率,合并最高频的符号对
-
WordPiece:基于概率,选择能最大程度提高语言模型概率的合并
-
-
合并评分公式:选择能使这个分数最大的符号对进行合并。
score = freq(pair) / (freq(first) * freq(second))
-
-
SentencePiece:不依赖预分词,可直接从原始文本学习,对多语言和带空格语言更友好。
独特优势:-
不依赖预分词:直接将原始文本作为输入
-
统一处理空格:将空格视为普通字符(用
_表示) -
多语言友好:无需针对不同语言设计不同的预处理规则
import sentencepiece as spm # SentencePiece的处理示例 text = "Hello world! 你好世界!" # 空格会被转换为特殊符号:▁ # 可能分词为:["▁He", "llo", "▁world", "!", "▁你", "好", "世", "界", "!"]
-
-
分词器的训练过程实战演示
from transformers import AutoTokenizer # 1. 准备训练数据 training_data = [ "机器学习是人工智能的重要分支。", "深度学习通过神经网络学习数据表示。", "自然语言处理让计算机理解人类语言。", # ... 数百万个句子 ] # 2. 训练分词器(简化流程) def train_tokenizer_from_scratch(texts, vocab_size=30000): from tokenizers import Tokenizer from tokenizers.models import BPE from tokenizers.trainers import BpeTrainer from tokenizers.pre_tokenizers import Whitespace # 初始化分词器 tokenizer = Tokenizer(BPE()) tokenizer.pre_tokenizer = Whitespace() # 配置训练器 trainer = BpeTrainer( vocab_size=vocab_size, special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"] ) # 开始训练 tokenizer.train_from_iterator(texts, trainer) return tokenizer # 3. 使用训练好的分词器 def demonstrate_tokenization(text): tokenizer = AutoTokenizer.from_pretrained("gpt-2") print(f"原始文本: {text}") print(f"Token列表: {tokenizer.tokenize(text)}") print(f"Token ID列表: {tokenizer.encode(text)}") print(f"每个Token对应的文本: {[tokenizer.decode([token_id]) for token_id in tokenizer.encode(text)]}") # 演示 demonstrate_tokenization("Unbelievable! 这是一个测试。")
3、不同模型,不同的“方言”
-
代码示例:对比不同模型对同一文本的分词结果,说明“词表”的差异。
from transformers import AutoTokenizer def compare_tokenizers(text): models = { "GPT-2 (BPE)": "gpt2", "BERT (WordPiece)": "bert-base-uncased", "T5 (SentencePiece)": "t5-base", "Bloom": "bigscience/bloom-560m" } print(f"测试文本: \"{text}\"") print("-" * 60) for name, model_path in models.items(): try: tokenizer = AutoTokenizer.from_pretrained(model_path) tokens = tokenizer.tokenize(text) print(f"{name:>20}: {tokens}") except Exception as e: print(f"{name:>20}: 加载失败 - {e}") # 对比中英文分词 print("=== 英文文本分词对比 ===") compare_tokenizers("unbelievable tokenization") print("\n=== 中文文本分词对比 ===") compare_tokenizers("自然语言处理很有趣") -
预期输出示例:
测试文本: "unbelievable tokenization" ------------------------------------------------------------ GPT-2 (BPE): ['un', 'bel', 'ieve', 'able', ' token', 'ization'] BERT (WordPiece): ['un', '##be', '##lie', '##vable', 'token', '##ization'] T5 (SentencePiece): ['▁un', 'be', 'lie', 'vable', '▁token', 'ization'] Bloom: ['un', 'belie', 'vable', 'Ġtoken', 'ization']
4、分词策略对模型性能的影响
| 算法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| BPE | 简单高效,能较好平衡词汇表大小和覆盖度 | 可能产生不直观的子词 | GPT系列,通用文本 |
| WordPiece | 基于概率的合并更"智能" | 训练复杂度较高 | BERT系列,需要更好语言建模 |
| SentencePiece | 语言无关,统一处理空格 | 分词结果可能较细粒度 | 多语言模型,T5系列 |
五、Token 在大模型并发测试输出中如何体现?
在并发测试(同时有很多用户向模型提问)中,Token是衡量模型性能和效率的核心指标。主要体现在以下几个方面:
1、吞吐量(Throughput)
- 作用类比:类似餐厅单位时间内的 “总出餐份数”,在大模型并发场景中,体现为每秒处理的总 Token 数(Tokens/s) 。
- 核心含义:不聚焦单个用户请求,而是衡量整个系统的 “全局处理能力”。并发时,系统会将多个用户的 Token 请求(如 A 的提问、B 的文本生成需求)打包后,利用 GPU 的并行计算能力批量处理,减少资源闲置 —— 就像餐厅将多桌客人的订单整合后同步备餐,效率更高。
- 并发场景影响:吞吐量直接决定系统的 “用户承载上限”。例如,吞吐量为 1500 Tokens/s 的系统,若单用户平均每次请求需处理 300 Token,理论上每秒可服务 5 个用户;若优化后吞吐量提升至 3000 Tokens/s,同一时间可服务 10 个用户,服务能力翻倍。
2、首Token延时(Time to First Token)
- 作用类比:对应餐厅从客人下单到 “上第一道菜” 的耗时,在大模型场景中,指从用户发送请求(如输入 “写一篇游记”)到收到模型输出第一个 Token(如 “今”)的时间,单位多为毫秒(ms)。
- 核心含义:直接影响用户的 “即时体验”。即使生成完整文本需几秒,若首 Token 能在 200ms 内输出,用户会直观感受到 “响应快”;反之,若首 Token 延时超过 1 秒,用户易产生 “系统卡住” 的焦虑感。
- 并发场景影响:并发请求数越多,首 Token 延时可能越高。例如,当并发用户从 10 人增至 50 人时,系统需排队处理请求,首 Token 延时可能从 100ms 增至 300ms—— 这也是并发测试中重点监控的 “用户体验临界指标”。
3、输出延时(Per-Token Latency / Time per Output Token)
- 作用类比:类似餐厅上第一道菜后,后续每道菜的 “间隔时间”,在大模型场景中,指输出第一个 Token 后,后续每个 Token 生成的平均间隔时间,同样以毫秒(ms)为单位。
- 核心含义:决定文本生成的 “流畅度”。若输出延时稳定在 50ms,文本会像打字机一样匀速呈现(每秒 20 个 Token),用户阅读体验流畅;若延时波动大(如忽快忽慢,甚至卡顿 1 秒),会打断用户的阅读节奏,降低体验。
- 并发场景影响:高并发下,GPU 计算资源被分摊,输出延时可能升高或波动。例如,低并发时输出延时稳定 40ms,高并发(如 100 用户同时请求)时,可能升至 80ms 且出现波动,导致文本生成 “时断时续”。
在实际并发测试报告中,常以 “并发请求数 + Token 三指标” 的组合呈现性能,例如:
当并发请求数为 50 时,模型服务的吞吐量达 1500 Tokens/s,首 Token 延时平均 200ms,输出延时平均 50ms”
这段话的核心信息拆解:
- 承载能力:系统可同时稳定服务 50 个用户,无明显崩溃或超时。
- 全局效率:每秒能处理 1500 个 Token,按单用户平均请求 300 Token 计算,50 用户的请求可在 10 秒内完成(50×300÷1500=10 秒)。
- 用户体验:200ms 的首 Token 延时让用户快速感知 “响应”,50ms 的输出延时保证文本匀速生成,整体体验流畅。
六、如何高效与Token打交道?
1、在线工具推荐:实时体验分词,快速掌握 Token 逻辑
OpenAI Tokenizer 输入任意中英文文本(如 “用大模型生成一篇旅行攻略”“Generate a travel guide with LLM”),可实时显示 3 类关键信息。
2、估算你的文本消耗:快速预判 Token 用量,避免超限制
在实际使用中(如写 Prompt、处理长文档),无需每次依赖工具,可通过 “经验法则 + 代码工具” 快速估算 Token 数量:
- 经验法则(快速估算,误差≤10%)
- 英文文本:1 个 Token ≈ 0.75 个单词(或 1 个单词 ≈ 1.33 个 Token)。
示例:“I want to generate a 500-word article about AI”(共 13 个单词),估算 Token 数≈13×1.33≈17 Token(实际拆分后约 16 Token,误差极小)。
- 中文文本:1 个汉字 ≈ 1.5-2 个 Token(纯中文短句偏 1.5,含英文 / 数字 / 标点偏 2)。
示例 1:纯中文 “今天天气很好,适合出门散步”(14 个汉字),估算 Token 数≈14×1.5≈21 Token(实际约 20 Token)。
示例 2:含英文的 “用 AI 生成今天的工作周报”(12 个汉字 + 2 个英文),估算 Token 数≈12×2 + 2×1≈26 Token(实际约 25 Token)。
- 注意事项:长文本(超过 500 字 / 词)估算误差会略增,建议结合工具二次验证;含特殊符号(如表情、公式)时,Token 消耗会增加(如 “😊” 可能占 2-3 个 Token)。
- 代码工具(精准计算,适合开发者)
若需在程序中自动估算 Token 数,可基于 Hugging Face Transformers 库编写轻量函数,示例代码如下(以 GPT-3.5 分词器为例):
# 安装依赖:pip install transformers
from transformers import AutoTokenizer
def estimate_token_count(text, model_name="gpt-3.5-turbo"):
"""
估算文本的Token数量
:param text: 输入文本(str,中英文均可)
:param model_name: 模型名称(默认GPT-3.5,可替换为其他模型)
:return: 估算的Token数(int)
"""
tokenizer = AutoTokenizer.from_pretrained(model_name)
# encode函数返回文本对应的Token ID列表,长度即Token数
token_ids = tokenizer.encode(text, add_special_tokens=False) # 不包含模型特殊Token(如<|endoftext|>)
return len(token_ids)
# 测试示例
test_text_zh = "用大模型生成一篇1000字的产品介绍文档"
test_text_en = "Generate a 1000-word product introduction document with LLM"
print(f"中文文本Token数:{estimate_token_count(test_text_zh)}") # 输出约22 Token
print(f"英文文本Token数:{estimate_token_count(test_text_en)}") # 输出约18 Token3、给开发者的建议:建立 “Token 意识”,优化开发效率
在设计大模型应用(如对话机器人、长文档分析工具)时,“Token 管理” 直接影响应用性能与成本,需重点关注以下 3 点:
- 设计 Prompt 时:精简冗余信息,控制 Token 消耗
- 避免添加无关描述(如 “你好,我需要你帮我做一件事,就是生成...” 可简化为 “生成...”),每减少 10 个 Prompt Token,单次请求成本可降低约 5%(按 API 计费规则)。
- 若需提供示例(Few-shot Prompt),优先选择短示例(每个示例控制在 50 Token 内),避免因示例过长导致用户输入文本被压缩。
- 处理长文本时:拆分 + 分段,适配模型上下文限制
- 当输入文本超过模型最大 Token 限制(如 GPT-3.5 的 4096 Token),需按 “逻辑段落” 拆分(如将 10000 字报告拆为 5 段,每段约 2000 字,对应 Token 数≈3000,低于限制)。
- 拆分后可采用 “分段总结→整合全文” 的逻辑(先让模型生成每段总结,再基于所有总结生成全文报告),避免因单次输入超量导致任务失败。
- 监控 Token 用量:避免突发成本超支
- 在应用中添加 Token 计数逻辑(如调用 5.2 中的代码函数),对单次请求的 “输入 Token + 输出 Token” 进行上限限制(如设定单次请求总 Token≤2000)。
- 针对商用场景,可按用户 / 功能模块设置每日 Token 配额(如普通用户每日 10000 Token,付费用户每日 50000 Token),防止因异常请求(如恶意输入超长文本)导致成本失控。
七、商用大模型为何按 Token 计费?
1、最公平的 “按工作量收费”
大模型像 “文字加工厂”,GPU 运转消耗的算力(电力、时间),直接取决于处理的 Token 数量:输入问题越长(输入 Token 多)、生成回答越长(输出 Token 多),“机器” 运转越久。按 Token 收费,本质是 “用多少算力付多少钱”,避免 “一刀切” 的不公平。
2、统一 “输入 + 输出” 的成本核算
一次 AI 交互包含 “用户提问” 和 “模型回答”,两者都消耗资源:
- 输入 Token:模型需理解问题,问题越复杂(如粘贴长论文),消耗越多。
- 输出 Token:生成回答是资源消耗大头,回答越长,消耗越多。
若按 “次数” 收费,会出现 “用户 A 问‘你好’(2 Token)却要长回答,用户 B 发长论文(10000 Token)却要短回答” 的成本失衡。按 “输入 + 输出 Token 总数” 收费,完美解决这一问题。
3、对用户:清晰、可控、好预算
- 透明:像出租车里程表,Token 数直观反映消费,知道钱花在哪。
- 可控:想省钱可优化 —— 精简提问(少输入 Token)、限制回答长度(少输出 Token)。
- 好预算:根据历史 Token 消耗,能估算每月成本,避免超支。
4、对厂商:与核心成本强挂钩
厂商最大成本是 GPU 的算力与电费,而 GPU 消耗直接和 Token 数量相关:处理 Token 越多,GPU 占用时间越长,成本越高。按 Token 定价,让厂商收入与成本线性关联,保证商业模式可持续(不会 “卖得越多亏得越惨”)。
5、一个好理解的比喻:像打印店按 “纸张数” 收费
大模型服务类似打印店:
- 输入 Token = 你给的原稿张数(店员需读稿)。
- 输出 Token = 给你的复印件张数(打印机需耗材)。
打印店按 “原稿 + 复印件总张数” 收费,大模型按 “输入 + 输出总 Token 数” 收费,逻辑完全一致 —— 合理且易接受。
八、结语
Token虽小,却是连接人类自然语言与机器数字世界的核心桥梁,是理解大模型一切行为的基础。现在你明白了,模型的长度限制、计费方式,都源于这个最基础的设计选择。未来可能出现更高效的语言表示方式,但理解Token将是读懂这一演进过程的起点。
更多推荐


 25
25 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)