
一文看懂视觉-语言与语音语言模型架构,小白也能掌握的多模态大模型入门指南!
本文详细介绍了多模态大模型的架构与训练方法,重点讲解了视觉-语言模型(VLM)和语音-语言模型(SLM)。VLM包括对比学习、掩码预测、生成式学习和映射学习四种训练思路;SLM探讨了输入输出模式、语音表示方法及语音文本融合架构。这些模型结合不同模态信息,使AI具备看图说话、听懂回答等接近人类的能力,为人机交互提供了更自然的方式。
前言
随着 Transformer 架构 的成功,人工智能不仅在语言处理上突飞猛进,在视觉、语音等领域也迎来了突破。如今,研究者们已经能够把“看”和“听”的能力与“语言”结合起来,形成了功能强大的 视觉-语言模型 和 音频-语言模型。
在这些多模态模型中,常见的设计方式有几种:
- 双编码器架构:就像给视觉和语言各自配备一个大脑,然后再把它们的理解结果对齐。
- 融合架构:直接把不同模态的信息搅拌在一起,让模型在同一个空间中学习。
- 编码器-解码器架构:一部分负责理解输入,另一部分则负责生成输出,类似翻译的过程。
随着研究的深入,这些架构也在不断进化。比如,引入 混合模态注意力机制,让模型能更灵活地在图像、语音和文字之间建立联系;利用 对比学习,帮助模型更好地区分和匹配不同模态的信息;再结合 强化学习,让模型通过试错不断优化表现。
这些进步让多模态 AI 的能力越来越接近人类,可以看图说话、可以听懂再回答,甚至在复杂任务中展现出很强的适应性和创造力。
1 视觉语言模型架构
视觉语言模型(Vision-Language Models,简称 VLM)是一类能同时理解图像和文本的人工智能模型。它们的目标是把 计算机视觉(“看”)和 自然语言处理(“说”)结合起来。得益于 Transformer 技术的兴起,这类模型在近几年发展非常迅速。
在训练方法上,研究人员总结出了四种主要的思路:
1. 对比学习:让模型学会配对
可以把它想象成一种找对象的训练方式。模型会看到一对图像和文字描述,如果它们本来就是匹配的(比如一张猫的照片和描述“这是一只猫”),模型就要把它们的表示变得接近;如果是不相关的组合(猫的照片配“这是一辆车”),模型就要把它们分开。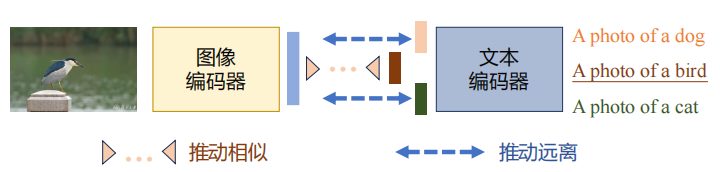
这种方法的代表就是 CLIP 模型,它通过大量图片和说明文字的组合,学会了在同一个“语义空间”中对齐图像和文本。
2. 掩码预测:让模型学会完形填空
在这种训练里,模型会遇到缺了一块的图片,或者少了几个词的句子,它需要根据上下文把缺失的信息补回来。
比如,给出一张被打了马赛克的苹果图,让模型预测“这是一个苹果”;或者把“这是一只 ___”遮掉,让模型从图片里推断出答案。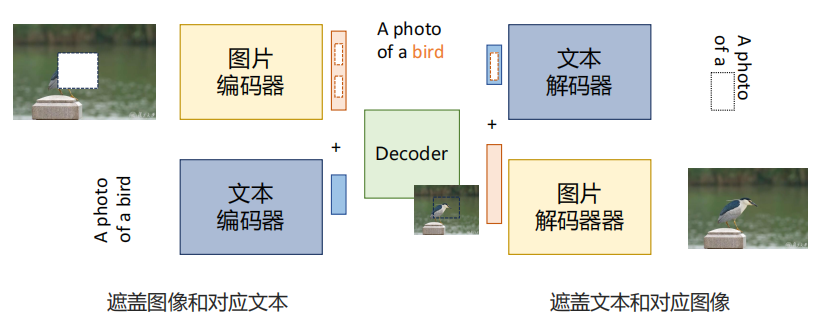
这类方法的代表是 FLAVA 模型,它通过对图像和文本做掩码预测来同时学习两种模态的信息。
3. 生成式学习:让模型学会创作
这一类方法不再只是“理解”语音、文字或图像,而是具备了直接生成新内容的能力。换句话说,它们不光能看懂,还能“创作”。

举个例子:
- 从一张图片生成文字描述(也就是图像到字幕,比如看到一张狗在公园里跑的照片,模型能自动写出“草地上有一只狗在奔跑”)。
- 反过来,从文字生成图像(也就是文生图,比如输入“黄昏下的未来城市”,模型就能画出对应的画面)。
在这种方法里,文字和图像都会被转成同一种形式:统一的 Token 序列。模型不再区分“这是字”还是“这是图”,而是把它们都当作相同的输入,然后通过一个统一的大模型进行处理和生成。
比较有代表性的模型包括:
- PaLI(Pathways Language and Image model):这是 Google 提出的一个多模态大模型。它能够同时处理图像和文本输入,完成图像字幕生成、视觉问答、跨语言图像描述等任务。PaLI 的核心思路就是把图像转化为序列,再和文字一起输入模型,让它们在同一空间里对齐。
- Kosmos-1(微软提出):这是一个“多模态大语言模型”,不仅能读懂文字和图片,还能把它们结合起来做推理,比如看一张图表回答问题,或者对一张漫画生成解释文字。Kosmos-1 的特别之处是,它在训练时就强调了“统一输入”的思路,把视觉和语言数据都映射到同一个 Token 序列里进行建模。
我们可能更熟悉的 Stable Diffusion、Imagen 等模型,实际上也是这种统一建模思路的应用。它们的输入和输出都通过 Token 化的方式转化到同一个表示空间,然后利用大模型进行生成,从而实现“文字生图”甚至“图像转图像”的创作能力。
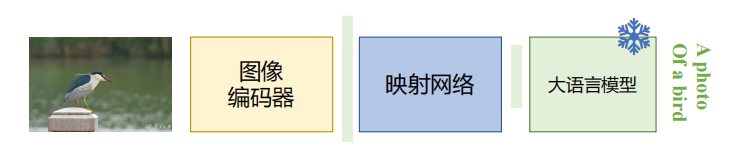
4. 映射学习:让模型学会“翻译”
训练一个从零开始的多模态大模型,往往需要海量的算力和庞大的数据集,这在实际中非常昂贵。于是研究者提出了一个更聪明的办法——映射学习(Mapping Learning)。
它的核心想法是:与其从头训练一个“既懂语言又懂图像”的大模型,不如直接把现成的 大语言模型(LLM) 和 图像编码器 连接起来,中间加一个“特征映射器”。
这样,图像特征会先通过图像编码器提取,再经过映射器转换成语言模型能理解的语义表示,最后输入到 LLM 里。于是,原本只会处理文字的语言模型,就被赋予了“看图”的能力。
这一思路的早期代表是 BLIP-2。它通过“Q-Former”模块,把视觉特征转化为一组紧凑的语义表示,再对接到大语言模型中。这种做法大幅降低了训练成本,同时效果还相当不错。
在 BLIP-2 的启发下,现在流行的 MiniGPT-4、LLaVA、Qwen-VL 等多模态模型,基本上都是基于映射学习发展起来的。它们的不同点主要体现在映射器的设计和优化策略上,但整体思路都是“语言模型不用重新训练,只需要学会接收图像信息”。
2 语音语言模型架构
语音语言模型(Speech-Language Models,简称 SLM)是一类能够同时理解语音和文字的多模态大模型。它们的目标是把 语音处理(“听”)和 语言理解(“说”)结合起来,从而实现更自然的人机交互。
与传统的“语音识别 → 转成文字 → 再处理”的串联方法不同,SLM 直接在端到端的架构里学习语音和文本之间的对应关系,这样模型的泛化能力更强,能更好地适应开放世界的场景。
SLM 在很多场景里都有应用,比如:
- 语音识别(把语音转成文字);
- 语音合成(把文字变成自然的语音);
- 语音翻译(直接把外语语音转成另一种语言的文字或语音);
- 智能语音助手、语音交互等。
1. SLM 的输入和输出模式
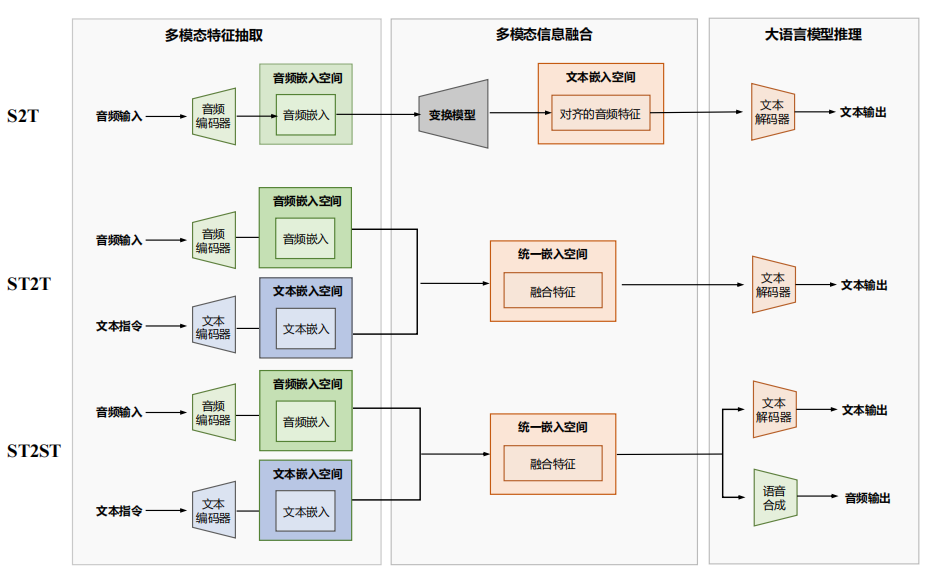
根据任务不同,SLM 的输入输出方式大致可以分为三类:
- S2T(Speech-to-Text):语音 → 文本。
最基础的模式,用来做自动语音识别(ASR),比如把录音转写成文字。它主要依赖音频编码器提取特征,然后解码成文字。 - ST2T(Speech & Text-to-Text):语音 + 文本 → 文本。
这是目前最常用的模式。它不仅能处理语音,还能接受文字提示,比如“把这段语音翻译成英语”。这种方式能做语音翻译、语音情感分析等更复杂的任务。 - ST2ST(Speech & Text-to-Speech & Text):语音 + 文本 → 语音 + 文本。
这是更高级的模式,既能输出文字,也能直接生成语音。例如同时完成语音识别 + 语音合成,实现更自然的语音翻译助手。
2. 语音表示学习:让模型听得更懂
要让 AI 听懂语音,必须先学会把原始的声音信号变成有用的特征表示。近年来,研究者提出了几种主要的预训练方法:
- 基于 CNN(卷积神经网络)
CNN 在图像处理中很常见,在语音里也很好用。它可以把原始语音信号转成“频谱图”,再提取其中的局部特征。比如 PANNs 模型就用 CNN 来学习声音特征。不过,CNN 擅长分析短时特征,对长时间依赖的处理能力有限。 - 基于 Transformer
Transformer 的优势在于捕捉长程依赖关系,因此在语音建模中越来越受欢迎。
- Wav2vec 2.0:先用 CNN 提取局部特征,再用 Transformer 捕捉全局信息,并通过掩码和对比学习的方式进行训练。
- Whisper:由 OpenAI 提出,支持多任务训练,比如语音识别和翻译。它能在不同场景下保持很好的泛化能力。
- AST、HTSAT、AudioMAE:这些模型探索了完全基于注意力的方式,甚至把图像领域的“掩码自编码器”方法搬到了音频上,从而让模型学会在被遮盖的情况下重建声音特征。
- 基于 Codec(离散化的语音表示)
另一种思路是把连续的音频信号“离散化”,变成一串类似文字的 Token,这样语音就可以和语言模型更好地结合。
- SoundStream:通过量化机制把语音压缩成离散单元,再重建高质量音频。
- Encodec:在此基础上加入了 LSTM 和 Transformer,使语音重建和建模效果更好。
- 语音和文本表示融合架构
在多模态大模型里,光有语音信息还不够,还得把它和文本信息结合起来,这样模型才能做出更准确的推理。简单来说,就是要让“听到的”和“看到的文字”说同一种语言。现在主要有两条路线:
-
把语音转换到文本空间
这种做法比较常见。因为大多数大语言模型本来就是为文本设计的,所以我们先把语音特征转化成“像文字一样”的表示,再交给模型处理。这种方法的好处是简单高效,但问题是——在语音变成“文字风格”表示的过程中,难免会丢失一部分信息。
-
直接投射(Direct Projection):通过一个“转换器”,把语音特征直接映射到文本嵌入空间。这样得到的语音向量可以和文字向量拼在一起,一起送进大模型里。
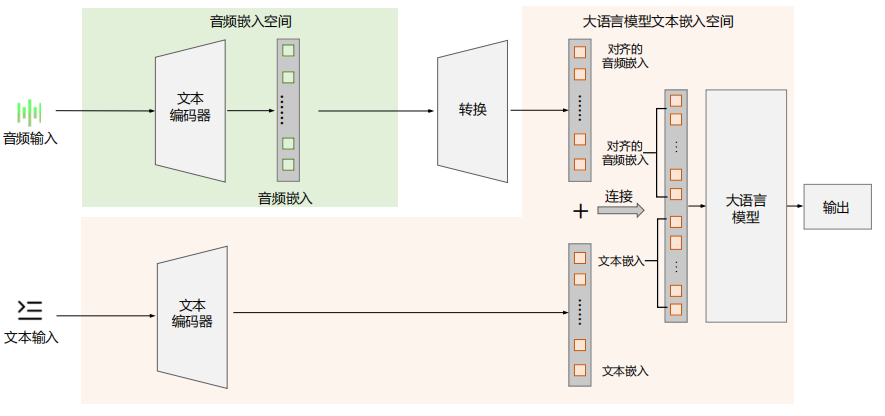
-
Token 映射(Token Mapping):把语音特征转换成类似于文本 Token 的形式,然后和文字 Token 排在同一个序列里。这样模型就能把语音和文字当成同一套符号来理解。
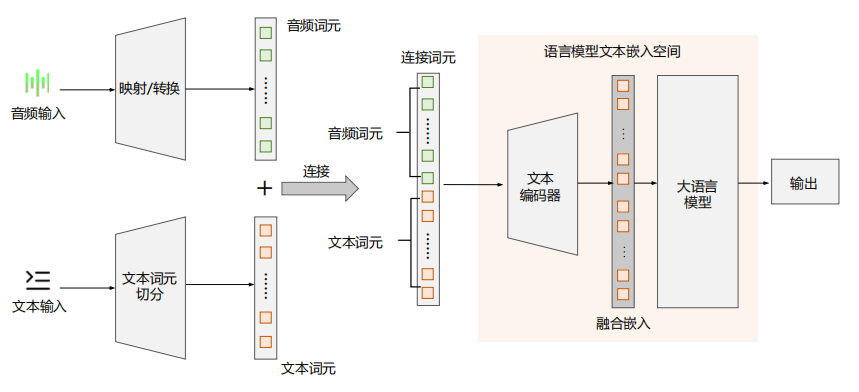
- 语音和文本直接融合在同一个空间
为了减少信息丢失,一些研究者提出了另一种方式:不再把语音硬转成“文本形式”,而是直接在大语言模型的输入空间里加入语音 Token。
- 做法是:先把语音特征提取出来,生成一批专属的“语音 Token”;然后把这些语音 Token 和文本 Token 拼接,形成一个更大的 Token 序列;最后交给大模型进行统一建模。
- 这样一来,模型可以同时接触语音和文字的原始特征,不需要再额外做模态转换,保留信息也更完整。
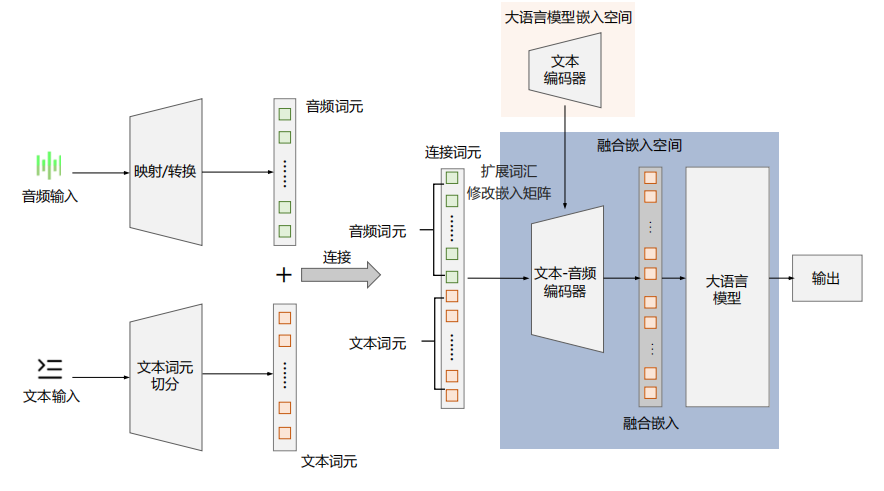
总结一下:
- 语音→文本空间的方法:快、简洁,但可能丢信息。
- 语音+文本联合空间的方法:复杂一些,但能更好地保留语音的原貌。
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。
最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。
600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。
AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
更多推荐
 18
18 0
0- 0



 已为社区贡献41条内容
已为社区贡献41条内容

所有评论(0)