
Sign2MCP
Sign2MCP项目摘要(148字): Sign2MCP是一个融合手语识别与大语言模型的创新项目,旨在构建实时人机交互接口。系统采用"视觉关键词捕捉+语义补全"技术路线,通过OpenCV/MediaPipe实现手语识别,结合LangChain编排Kimi K2模型生成可执行指令。技术架构包含Vue3前端、FastAPI后端和模块化AI处理流程,支持低延迟视频流处理。项目对比了C
1. 项目背景与动机
近年来,随着深度神经网络的飞速发展,尤其是在计算机视觉和自然语言处理领域的突破性进展,我对其强大的表征和学习能力产生了浓厚的兴趣。在学习过程中,我始终坚信技术的价值在于解决实际问题。我不满足于仅仅理解理论模型,更渴望亲手实现一个能够连接虚拟智能与物理世界的完整应用。手语识别,这个恰好融合了视觉识别与语言理解两大挑战的领域,自然而然地吸引了我的目光。它不仅是检验我深度学习知识的绝佳试金石,更是一个极具社会价值和人文关怀的应用方向。
通过前期调研,我发现许多优秀的手语识别项目大多集中于两个方向:一是高精度的孤立词识别,二是复杂的连续语句翻译。前者交互性有限,后者技术门槛极高,难以实现低延迟的实时应用。与此同时,大型语言模型正展现出前所未有的自然语言理解和指令生成能力。我萌生了一个想法:能否找到一个巧妙的结合点?与其追求一步到位地翻译整句话,不如先精准地识别出一个个关键的手语词汇,然后利用大模型的“推理”和“组织”能力,将这些词汇转化为流畅、自然且可操作的指令。这种“视觉感知+语言生成”的范式,既降低了实时识别的难度,又极大地扩展了手语的应用边界。
这个想法催生了 Sign2MCP 项目。我们的愿景远不止于一个技术demo,而是旨在打造一个高效的、实时的人机交互接口。我们希望这座桥梁的一端,是听障人士或任何使用手语的用户最自然、最本能的表达;另一端,则是能够理解其意图并控制各类数字工具或智能设备的标准化指令。
技术目标:实现一个低延迟、高准确率的端到端系统,验证“手语关键词捕捉 + 大模型语义补全”这一技术路线的可行性。
应用愿景:让手语不仅能用于人与人之间的沟通,更能成为人机交互的新范式。用户或许可以通过简单的手势控制智能家居、进行PPT演示、或者生成代码片段,为信息无障碍 access 和人机交互创新提供一种新的可能性。
总结而言,Sign2MCP 是我个人学习深度神经网络的一次实践性总结,更是一次将前沿AI技术应用于解决现实沟通难题的积极探索。 我们期待它能从一个兴趣驱动的项目,逐步成长为一个真正有用的工具。
本项目当前支持对手语视频流进行实时识别,每次可精准检测并解析出一个独立单词或手势动作,随后借助大语言模型进行语义推理与生成,并将结果实时返回给用户。系统后端基于 FastAPI 构建高性能 RESTful 接口,处理识别请求与模型调用;前端则采用 Vue3 框架,构建出响应迅速、用户界面友好的交互应用。
2. 项目简介
核心功能
- 🎥 实时手语识别: 使用 OpenCV 和 MediaPipe 进行高精度手语检测
- 🧠 智能指令生成: 通过 LangChain 编排 Kimi K2 模型生成 MCP 指令
- ⚡ 实时处理: 低延迟的端到端处理流程
- 🔧 可扩展架构: 模块化设计,支持自定义扩展
技术架构
手语输入 → OpenCV识别 → LangChain处理 → Kimi K2 LLM → MCP指令 → 执行器
3. 技术架构与实现
技术栈图示
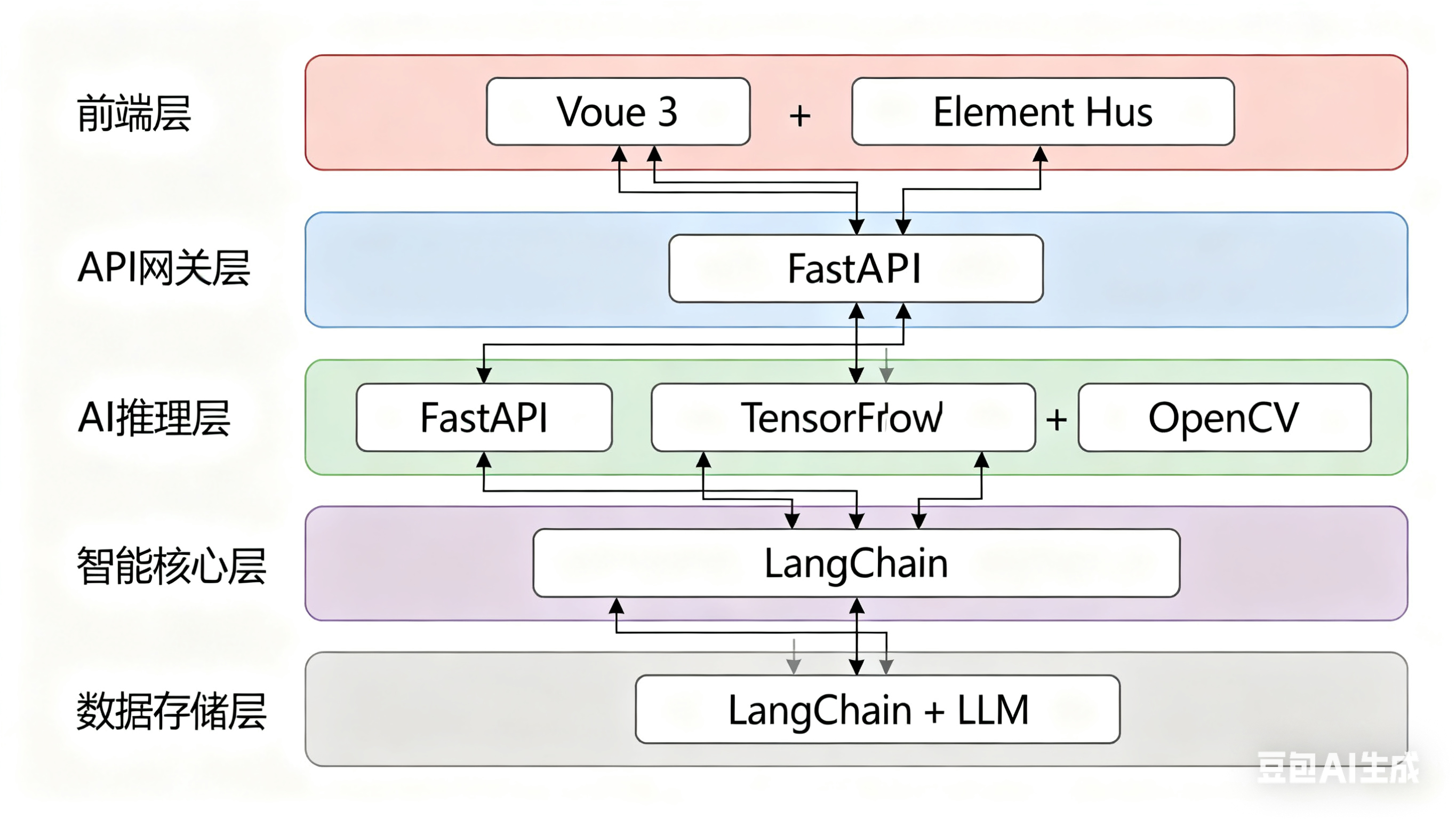
前端 (Vue 3)
技术选型:Vue 3 + Vite + Element Plus
选择理由:
组合式 API:Vue 3 的 Composition API 提供了更好的代码组织性,使得复杂功能的逻辑可以更好地复用和维护
响应式体验:基于 Proxy 的响应式系统比 Vue 2 的 Object.defineProperty 更高效,特别适合实时视频流处理
性能优势:Virtual DOM 优化和 Tree-shaking 支持,确保手语识别这种计算密集型应用的流畅性
生态完善:丰富的第三方库支持,如用于摄像头访问的 WebRTC API 封装
开发效率:Vite 提供极速的开发服务器启动和热更新
后端 (FastAPI)
技术选型:FastAPI + Uvicorn + WebSocket
选择理由:
高性能异步框架:基于 Starlette 和 Pydantic,异步处理能力极强,非常适合实时的 AI 推理场景
自动 API 文档:自动生成 OpenAPI/Swagger 文档,便于前后端协作和接口调试
类型安全:Pydantic 的数据验证确保图像数据、模型输入的完整性和正确性
WebSocket 原生支持:支持双向实时通信,满足手语识别的实时视频流处理需求
Python AI 生态:无缝集成 TensorFlow、OpenCV 等机器学习库
视觉模型 (OpenCV + MediaPipe)
技术选型:OpenCV + TensorFlow + PIL
选择理由:
OpenCV:业界标准的计算机视觉库,提供稳定的图像预处理功能
MediaPipe 替代方案:虽然当前使用传统方法,但架构支持集成 MediaPipe
TensorFlow:成熟的深度学习框架,支持模型部署和推理优化
图像处理管道:Base64 解码 → 灰度化 → 尺寸调整 → 归一化的完整预处理流程
模型兼容性:支持多种模型格式(.keras、.h5),便于模型迭代更新
智能核心 (LangChain + Kimi K2)
技术选型:LangChain + 自定义 LLM 集成
选择理由:
LangChain 工作流编排:提供标准化的 LLM 调用流程,支持提示模板管理和链式调用
可扩展架构:自定义 LLM 类设计,支持快速切换不同的语言模型(DeepSeek、Kimi等)
提示工程:结构化的提示模板确保手语识别结果能够准确转换为语义通顺的文本
异步处理:支持异步调用大模型,避免阻塞手语识别的实时性
错误处理:完善的异常处理机制,确保模型调用失败时的优雅降级
整体架构优势
前后端分离:清晰的职责划分,便于团队开发和维护
实时性能:WebSocket + 异步处理确保低延迟的手语识别体验
模块化设计:各组件松耦合,支持独立升级和替换
AI 友好:完整的 Python 机器学习生态支持
生产就绪:容器化部署支持,环境变量管理,日志记录完善
4. 快速开始
git clone https://gitee.com/yang-shanghao/shouyushibie.git
基础用法示例
模型介绍
在模型架构的探索上,本项目实现并对比了多种经典的深度学习模型,以全面评估其在不同场景下的手语识别性能。具体包括:
基础卷积神经网络(CNN):作为基线模型,用于验证数据处理流程和基础特征提取能力。
残差神经网络(ResNet):通过引入残差连接结构,有效缓解深层网络训练中的梯度消失问题,提升特征复用与模型表达能力。
基于MobileNetV2的迁移学习:利用在ImageNet等大型数据集上预训练的MobileNetV2模型权重,通过微调(Fine-tuning)适配手语识别任务。该模型兼具轻量化与高精度的特点,其倒残差结构和线性瓶颈层设计使其非常适合移动端及实时应用场景,能显著加快收敛速度并提升模型泛化能力。
通过对比不同架构的表现,我们能够更深入地理解模型复杂度、训练效率与最终性能之间的权衡,为后续的模型优化与选型提供了重要的实证依据。
5.致谢
- TensorFlow团队提供的优秀机器学习框架
- Vue.js团队提供的前端框架
- Element Plus团队提供的UI组件库
- FastAPI团队提供的高性能Web框架
各位CSDN的朋友们,大家好!
我在学习过程中完成了一个将手语识别与大语言模型(LLM) 相结合的项目——Sign2MCP,并撰写了一篇博客详细介绍了实现过程和技术思路。作为一名仍在学习和探索中的开发者,我非常希望能得到各位前辈和同行的宝贵意见,无论是批评、建议还是交流探讨,对我都至关重要!
更多推荐
 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)