
中科院类脑大模型SpikingBrain,2%数据,百倍速度
中国科学院自动化研究所的李国齐、徐波团队发布全球首款大规模类脑脉冲大模型SpikingBrain 1.0。处理一段400万token的超长文本,它的速度比现在主流的Transformer模型快了100多倍。更离谱的是,它的训练数据量,只有别人家的2%。
中国科学院自动化研究所的李国齐、徐波团队发布全球首款大规模类脑脉冲大模型SpikingBrain 1.0。

处理一段400万token的超长文本,它的速度比现在主流的Transformer模型快了100多倍。更离谱的是,它的训练数据量,只有别人家的2%。
大模型,要换个脑子了?
我们今天用的大语言模型,比如GPT系列,基本都构建在Transformer架构上。这套架构的核心是自注意力机制,非常强大,但有个致命的问题:计算复杂度。
简单说,你给它的文本长度增加一倍,它的计算量不是增加一倍,而是暴增到四倍,也就是二次方(O(n²))关系。处理长文本时,它就像一辆陷入泥潭的跑车,不仅慢,还巨耗油(显存和能耗)。
这就是为什么我们很难让AI一次性读完一部长篇小说或者分析一整套法律卷宗。成本太高,效率太低。
中科院的科学家们把目光投向了自然界最牛的智能系统——人脑。
人脑里有千亿级的神经元,连接数量更是天文数字,但它的功耗只有区区20瓦,比你家灯泡还省电。
团队提出了一个概念,把现在堆料的Transformer路线叫做“基于外生复杂性”,就是靠外部的堆砌来提升性能。而他们走的路叫“基于内生复杂性”,意思是把功夫花在单元内部,让每一个“神经元”本身就更聪明、更高效,师从大脑。
SpikingBrain,一套从里到外的颠覆
SpikingBrain(瞬悉)的核心,就是用一套全新的架构,模拟大脑神经元的工作方式。它有两个版本,一个70亿参数的SpikingBrain-7B,一个760亿参数的SpikingBrain-76B。
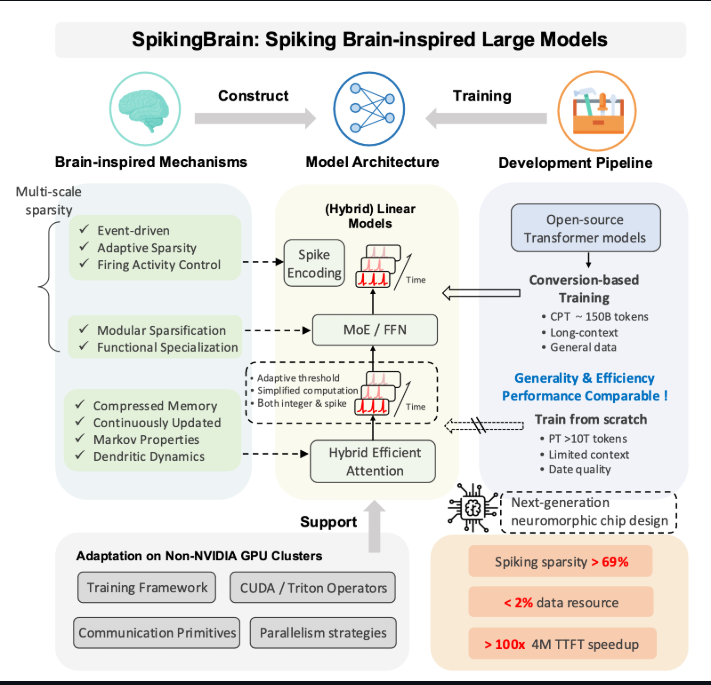
它到底颠覆了什么?
首先,它把Transformer那个二次方复杂度的自注意力机制给扔了,换成了一套“混合线性注意力架构”。
思路很巧妙。它把几种不同的注意力机制组合起来用:线性注意力负责看全局、抓要点,滑窗注意力负责看局部、抠细节。在7B模型里,这两种注意力一层一层地交替堆叠。在更强的76B模型里,它们甚至在同一层里并行开工,还时不时插入一层标准的全注意力来“校准”一下。
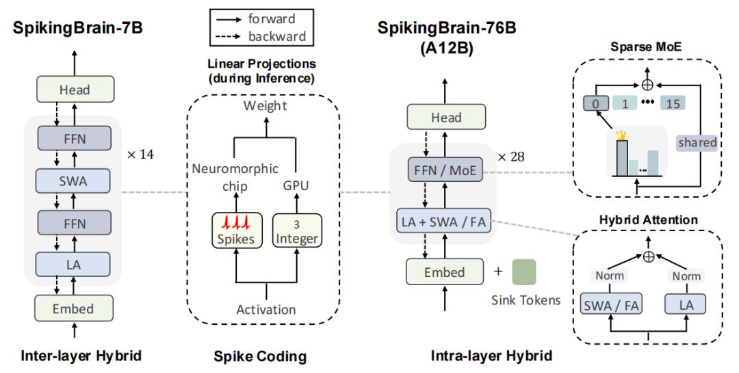
这么一搞,计算复杂度直接从二次方降到了线性(O(n))。处理长文本的效率,自然就坐上了火箭。
其次,也是最“类脑”的一点,是它用了“自适应阈值脉冲神经元”。
传统AI模型里的神经元,不管有没有活干,都在那里傻乎乎地参与计算。但大脑神经元不是,它们平时很安静,只有当接收到的信号强度超过一个“阈值”时,才会“发放”一个脉冲,也就是“说句话”。这种事件驱动的方式极其节能。
过去的脉冲神经网络(SNNs)模型虽然模仿了这一点,但总做不好,要么神经元集体“沉默”,要么集体“过度兴奋”,模型很难训练。
SpikingBrain的创新在于,这个“阈值”不是固定的,而是自适应的。它会根据神经元的状态动态调整,确保每个神经元都处在一个恰到好处的活跃水平。这就好比给每个员工都设定了一个弹性的KPI,既不会让他闲着,也不会把他累死,整个公司(模型)的运行效率就高了。
这种机制带来的直接好处就是“稀疏性”。数据显示,SpikingBrain的计算稀疏度高达69.15%,在处理长序列时,真正被激活的脉冲占比只有1.85%。这意味着绝大部分时间里,大部分神经元都在“节能模式”,能耗自然就降下来了。
最后,还有一个非常务实的技术:高效模型转换。
从头训练一个大模型,烧钱跟烧纸一样。团队开发了一套技术,可以直接把现有的Transformer模型“改造”成SpikingBrain架构,而不是一切推倒重来。整个转换和继续训练过程,所需要的计算量,还不到从头训练一个同等规模模型的2%。
国产芯上跑出的“中国速度”
这一整套颠覆性的工作,都是在国产GPU算力集群上完成的。
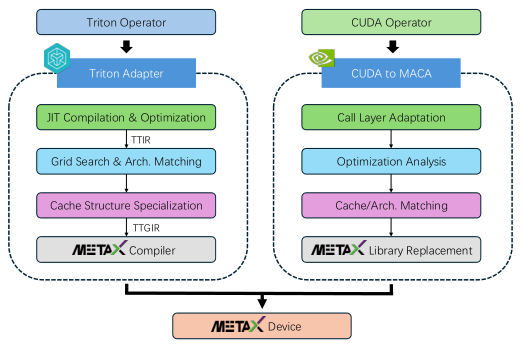
团队攻克了在非英伟达平台上进行大规模分布式训练的种种难题,开发了配套的算子库和通信框架,硬是把这块硬骨头啃了下来。
下表,能最直观地看到SpikingBrain的性能有多“炸裂”。
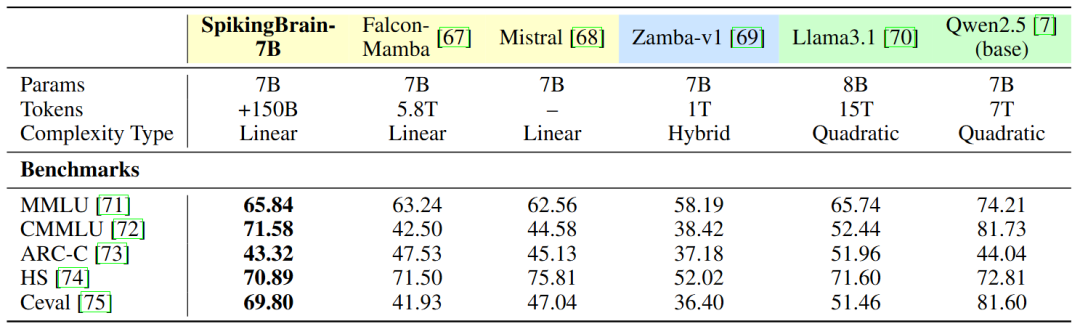
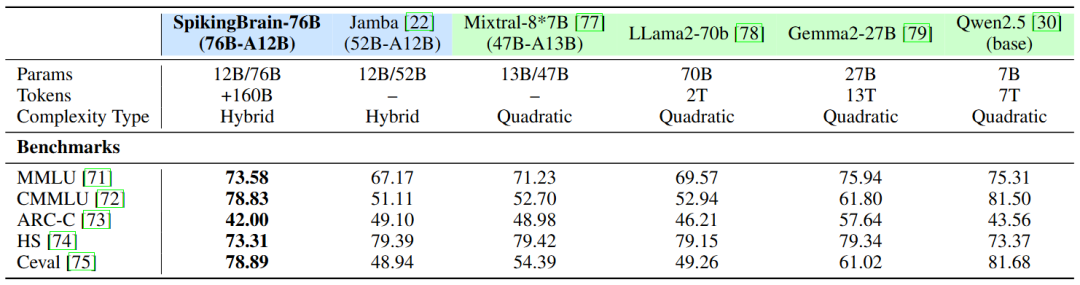
训练数据只用2%,性能却能和主流模型打平。
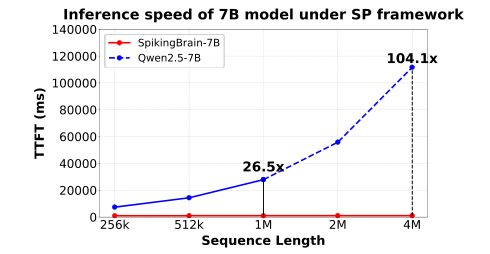
处理百万、四百万token级别的超长文本,推理启动速度提升几十倍甚至上百倍。
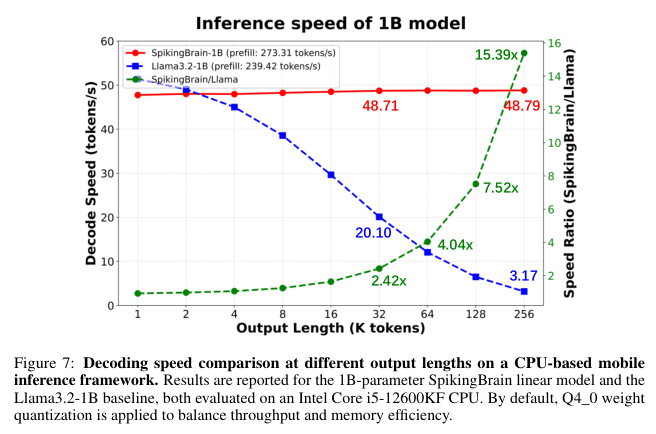
把模型压缩后放到手机CPU上跑,解码速度还能甩开对手十几倍。
能耗显著降低,稀疏度极高。
不只发论文,直接开源
技术报告同时发布在了学术网站arXiv和代码托管平台GitHub上,中英文双版本,把所有技术细节和盘托出。
团队直接把SpikingBrain-7B模型的权重、完整代码、推理框架全部开源,放在了魔搭(ModelScope)和GitHub上,人人都可以下载使用。76B的模型也提供了在线试用。
SpikingBrain 1.0的问世,宣告了在Transformer的“规模法则”之外,还存在着另一条通往通用人工智能的道路。
类脑新赛道,才是新未来吗?
免费试用:
https://controller-fold-injuries-thick.trycloudflare.com/
GitHub:
https://github.com/BICLab/SpikingBrain-7B
ModelScope:
-
Pre-trained model (7B): https://www.modelscope.cn/models/Panyuqi/V1-7B-base
-
Chat model (7B-SFT): https://www.modelscope.cn/models/Panyuqi/V1-7B-sft-s3-reasoning
-
Quantized weights (7B-W8ASpike): https://www.modelscope.cn/models/Abel2076/SpikingBrain-7B-W8ASpike
参考资料:
http://www.ia.ac.cn/xwzx/ttxw/202509/t20250908_7963509.html
https://arxiv.org/html/2509.05276v1
END
更多推荐
 15
15 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)