
Flume工具
Apache Flume 是Apache基金会开发的分布式日志采集工具,专为海量流式数据(如服务器日志、传感器数据)设计,提供可靠传输至HDFS、HBase等存储系统。其核心架构基于Agent(Source采集→Channel缓冲→Sink输出),支持事务机制确保数据不丢失,可通过多Agent串联构建复杂采集拓扑。特性包括:持久化通道(FileChannel/KafkaChannel)、拦截器数据
Apache Flume 是一款由 Apache 软件基金会开发的、分布式的、可靠的、高可用的日志收集与聚合工具,主要用于从大量不同的数据源(如 Web 服务器日志、应用程序日志、传感器数据等)中高效采集、聚合并移动大量流式日志数据到数据存储系统(如 HDFS、HBase、Elasticsearch 等),是大数据生态中 “数据采集层” 的核心组件之一。
一、Flume 的核心定位与应用场景
Flume 的设计初衷是解决 “海量日志数据的实时 / 准实时采集与传输” 问题,其核心价值在于简化分散数据源到集中存储的链路,确保数据在传输过程中的可靠性与完整性。
1. 核心定位
- 数据管道(Data Pipeline):连接 “数据源” 与 “数据存储”,充当两者之间的 “传送带”,实现数据的无缝流转。
- 日志专家:对日志类数据(文本格式为主,也支持二进制数据)的采集、过滤、格式化有深度优化,支持多种日志生成场景。
- 分布式架构:可通过横向扩展(增加 Agent 节点)应对超大规模数据量(如 TB 级 / 天)的采集需求。
2. 典型应用场景
- Web 日志采集:采集多台 Web 服务器(如 Nginx、Apache)的访问日志(Access Log),聚合后存入 HDFS 用于后续用户行为分析、流量统计。
- 应用程序日志采集:采集分布式应用(如微服务集群)的运行日志(Error Log、Info Log),传输到 Elasticsearch 配合 Kibana 实现日志实时检索与监控。
- 传感器 / 设备数据采集:采集物联网(IoT)设备(如温度传感器、工业设备)产生的实时数据流,传输到 HBase 或时序数据库(如 InfluxDB)存储。
- 业务数据准实时同步:将业务系统产生的增量数据(如订单表变更日志)采集后,准实时同步到数据仓库,支撑近实时分析场景。
二、Flume 的核心架构与组件
Flume 采用 “Agent 节点分布式部署,组件模块化组合” 的架构,每个 Agent 是一个独立的进程,多个 Agent 可串联或并联形成复杂的采集拓扑,以适应不同的数据源场景。
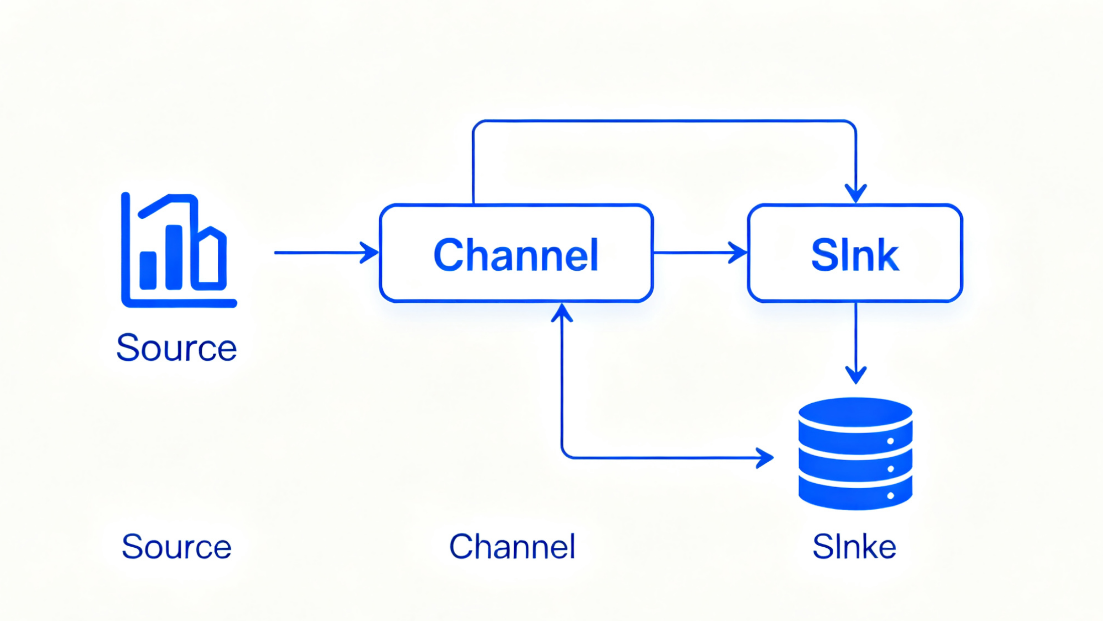
1. 核心架构图
plaintext
[数据源] → [Source(采集)] → [Channel(缓冲)] → [Sink(输出)] → [数据存储]
↓(可选,多Agent串联)
[另一Agent的Source] → ... → [最终存储]
2. 三大核心组件(Source/Channel/Sink)
Flume 的最小工作单元是 Agent,每个 Agent 内部包含 Source、Channel、Sink 三大核心组件,三者协同完成 “采集 - 缓冲 - 输出” 的完整流程。
| 组件 | 核心作用 | 常见实现类型 |
|---|---|---|
| Source | 负责从数据源采集数据,将数据转换为 Flume 内部的 “事件(Event)” 格式后发送到 Channel。 | - 日志文件:ExecSource(执行命令如 tail -F)、SpoolingDirectorySource(监控目录新增文件)- 网络数据:NetcatSource(监听 TCP 端口接收数据)、AvroSource(跨 Agent 通信)- 其他:KafkaSource(从 Kafka 主题消费数据)、JmsSource(从消息队列 JMS 采集) |
| Channel | 作为 Source 与 Sink 之间的 “缓冲池”,临时存储 Event,解耦 Source 的采集速度与 Sink 的写入速度,确保数据不丢失。 | - 内存缓冲:MemoryChannel(速度快,内存溢出或进程崩溃会丢失数据,适合非核心数据)- 持久化缓冲:FileChannel(数据写入本地磁盘,崩溃后可恢复,适合核心数据,性能略低)- 分布式缓冲:KafkaChannel(基于 Kafka 主题做缓冲,兼具可靠性与分布式能力) |
| Sink | 从 Channel 中拉取 Event,将数据写入到目标存储系统,完成数据的最终输出。 | - Hadoop 生态:HdfsSink(写入 HDFS)、HBaseSink(写入 HBase)- 日志分析:ElasticSearchSink(写入 Elasticsearch)- 消息队列:KafkaSink(写入 Kafka 主题)、AvroSink(发送到另一 Agent 的 AvroSource)- 其他:LoggerSink(打印到控制台,用于测试)、FileRollSink(写入本地文件) |
3. 关键概念:Event(事件)
Event 是 Flume 内部数据传输的最小单位,所有数据在 Flume 中都以 Event 形式流转。其结构包含两部分:
- Headers(头部):键值对(Key-Value)格式的元数据,用于存储数据的附加信息(如数据来源、时间戳、文件名、数据类型等),可用于后续过滤、路由。
- Body(主体):二进制格式的实际业务数据(如一条日志的文本内容),Flume 不对 Body 内容做解析,仅负责传输。
三、Flume 的核心特性
Flume 能成为大数据采集领域的主流工具,源于其具备以下关键特性:
1. 可靠性(Reliability)
- 数据不丢失保障:通过
FileChannel或KafkaChannel的持久化存储,即使 Agent 进程崩溃或服务器宕机,重启后可从磁盘 / Kafka 中恢复未传输完成的数据。 - 事务支持:Source 到 Channel、Channel 到 Sink 的数据传输均基于 “事务”:
- Source 向 Channel 写入数据时,若写入成功则提交事务,否则重试;
- Sink 从 Channel 读取数据时,若写入目标存储成功则删除 Channel 中的数据(提交事务),否则回滚(数据保留在 Channel 中,等待下次重试)。
2. 分布式与可扩展性(Distributed & Scalable)
- 多 Agent 拓扑:支持串联(Agent1 的 Sink 指向 Agent2 的 Source)、并联(多个 Agent 同时采集不同数据源,输出到同一目标)、扇入(多个 Agent 输出到同一个 Agent)、扇出(一个 Agent 输出到多个目标存储)等复杂拓扑,适应大规模分布式环境。
- 横向扩展:当单 Agent 性能不足时,可通过增加 Agent 节点(如将数据源分片到多个 Agent 采集)提升整体采集能力。
3. 灵活性与可定制性(Flexibility & Customization)
- 组件可插拔:Source、Channel、Sink 均采用接口化设计,用户可根据业务需求开发自定义组件(如自定义 Source 采集特定格式的日志,自定义 Sink 写入专有存储)。
- 拦截器(Interceptor):支持在 Event 从 Source 发送到 Channel 前对数据进行加工(如过滤无效日志、添加 / 修改 Headers、格式化数据),常见拦截器包括
TimestampInterceptor(添加时间戳)、HostInterceptor(添加数据源主机名)、RegexFilteringInterceptor(按正则过滤数据)。 - 通道选择器(Channel Selector):支持将 Source 产生的 Event 路由到不同的 Channel(如按 Headers 中的关键字路由),分为
ReplicatingChannelSelector(复制到所有 Channel)和MultiplexingChannelSelector(按规则路由到指定 Channel)。
4. 高可用性(High Availability)
- Sink 组与故障转移:将多个 Sink 配置为一个 “Sink 组”,并指定 “故障转移(Failover)” 策略。当主 Sink 故障时,系统自动切换到备用 Sink,确保数据输出不中断。
- 集群部署:结合 ZooKeeper 可实现 Flume Agent 的集群管理与配置同步,避免单点故障。
四、Flume 与同类工具的对比
在大数据采集领域,Flume 常与 Apache Kafka Connect、Fluentd、Logstash 等工具对比,不同工具的定位与优势各有侧重:
| 工具 | 核心优势 | 适用场景 | 不足 |
|---|---|---|---|
| Apache Flume | 专为日志采集设计,与 Hadoop 生态兼容性极强,可靠性高 | 大规模日志采集、HDFS/HBase 为目标存储的场景 | 对非日志类数据(如数据库变更)支持较弱,配置较复杂 |
| Apache Kafka Connect | 基于 Kafka,适合分布式数据同步,支持海量数据源与存储 | 数据库(MySQL/Oracle)变更同步、跨系统数据传输 | 依赖 Kafka,单独使用时灵活性不足,日志采集功能较弱 |
| Fluentd | 轻量级,插件生态丰富,支持多语言,跨平台性好 | 容器日志(Docker/K8s)采集、多源数据聚合 | 高并发场景下性能不如 Flume,与 Hadoop 生态集成略弱 |
| Logstash | 与 Elasticsearch/Kibana(ELK 栈)深度集成,过滤能力强 | 日志实时检索与监控(ELK 栈场景) | 资源占用较高(JVM 进程),单机性能有限,需配合 Beats 使用 |
Apache Flume 是大数据生态中日志采集领域的经典工具,其核心优势在于 “分布式架构、高可靠性、与 Hadoop 生态深度集成”,能高效解决海量日志数据的采集与聚合问题。
- 适用场景:若需采集分布式系统的日志数据,并将其写入 HDFS、HBase 等存储,Flume 是首选工具;
- 注意事项:需根据数据重要性选择 Channel 类型(核心数据用 FileChannel,非核心用 MemoryChannel),并合理配置 Sink 的重试策略与故障转移,避免数据丢失;
- 生态协同:在实际项目中,Flume 常与 Kafka 配合使用(Flume 采集日志写入 Kafka,Kafka 作为缓冲层供下游消费),或与 ELK 栈集成(Flume 采集日志写入 Elasticsearch),形成完整的数据采集 - 存储 - 分析链路。
更多推荐
 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)