
什么是向量数据库,为什么AI时代向量数据库这么重要?
向量数据库是大模型时代的核心基础设施,支持语义检索、RAG、私有知识库等AI能力。本文深入解析其原理、架构、应用场景与技术趋势。
🧠 1. 从“记忆缺失”的AI系统谈起
2024年底,一家知名客服 SaaS 厂商在引入大语言模型(LLM)后遇到一系列“幻觉”问题:用户问“退货政策”,模型却返回“请联系您的银行”;当问“有没有双十一活动”,模型居然输出了2022年的新闻稿链接。
他们很快发现,问题不在大模型本身,而是它“不记得”企业内部知识、更新不及时、无法根据上下文理解搜索意图。最终,他们引入了向量数据库(如 Milvus + Qdrant),通过向量化企业知识库并与大模型检索对接,使“记忆+推理”能力成为现实。
这,正是 AI 进入“RAG 时代”后的真实缩影。
🔍 2. 向量数据库是什么?
向量数据库(Vector Database),是一种专门用于 存储、索引和快速检索高维向量数据 的数据库系统。它不同于传统结构化数据库,用来处理的是神经网络生成的“语义表示”(Embedding 向量)。
例如:
- 一段文本经过 BERT 编码,变成 768 维向量;
- 一张图像经过 ResNet 提取,生成 2048 维向量;
- 一段语音被 Wav2Vec 转换成 1024 维向量;
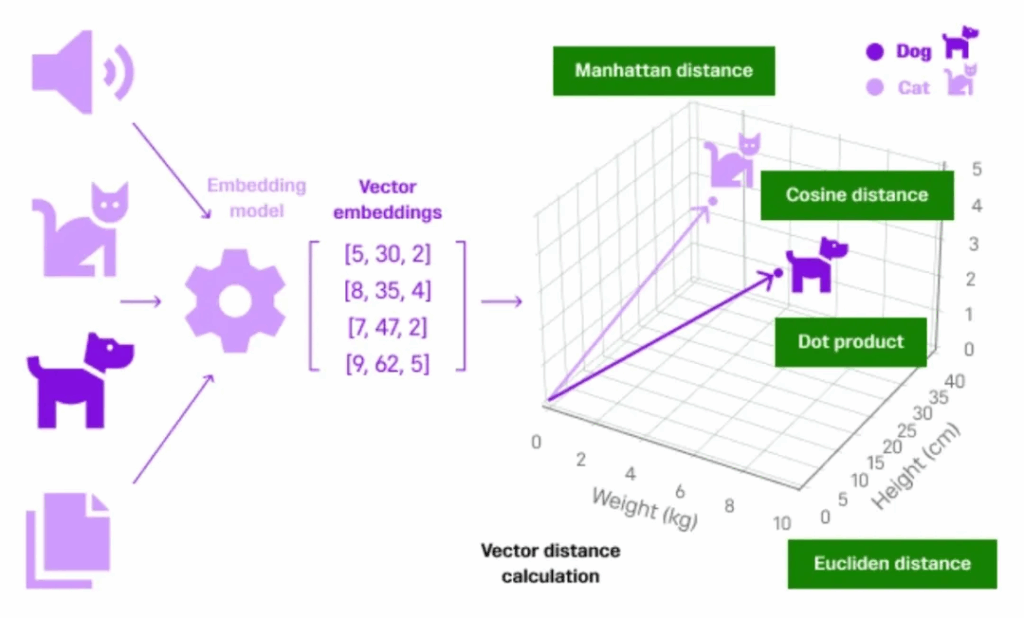
这些向量,不能用“相等”去比较,而是用“相似度”来检索最接近的内容。
🧊 为什么不能用传统数据库?

传统数据库(MySQL/PostgreSQL)通过索引字段(如主键、时间)定位数据。但 AI 时代的语义表示通常是“模糊搜索”:
“How to return a product” ≈ “退货流程是怎样的?” ≠ “退货政策”
在这种语义不匹配、表达多样的场景下,只有向量数据库可以根据 向量之间的距离(如欧氏距离、余弦相似度) 实现相似语义搜索。
📦 3. 应用场景全景图
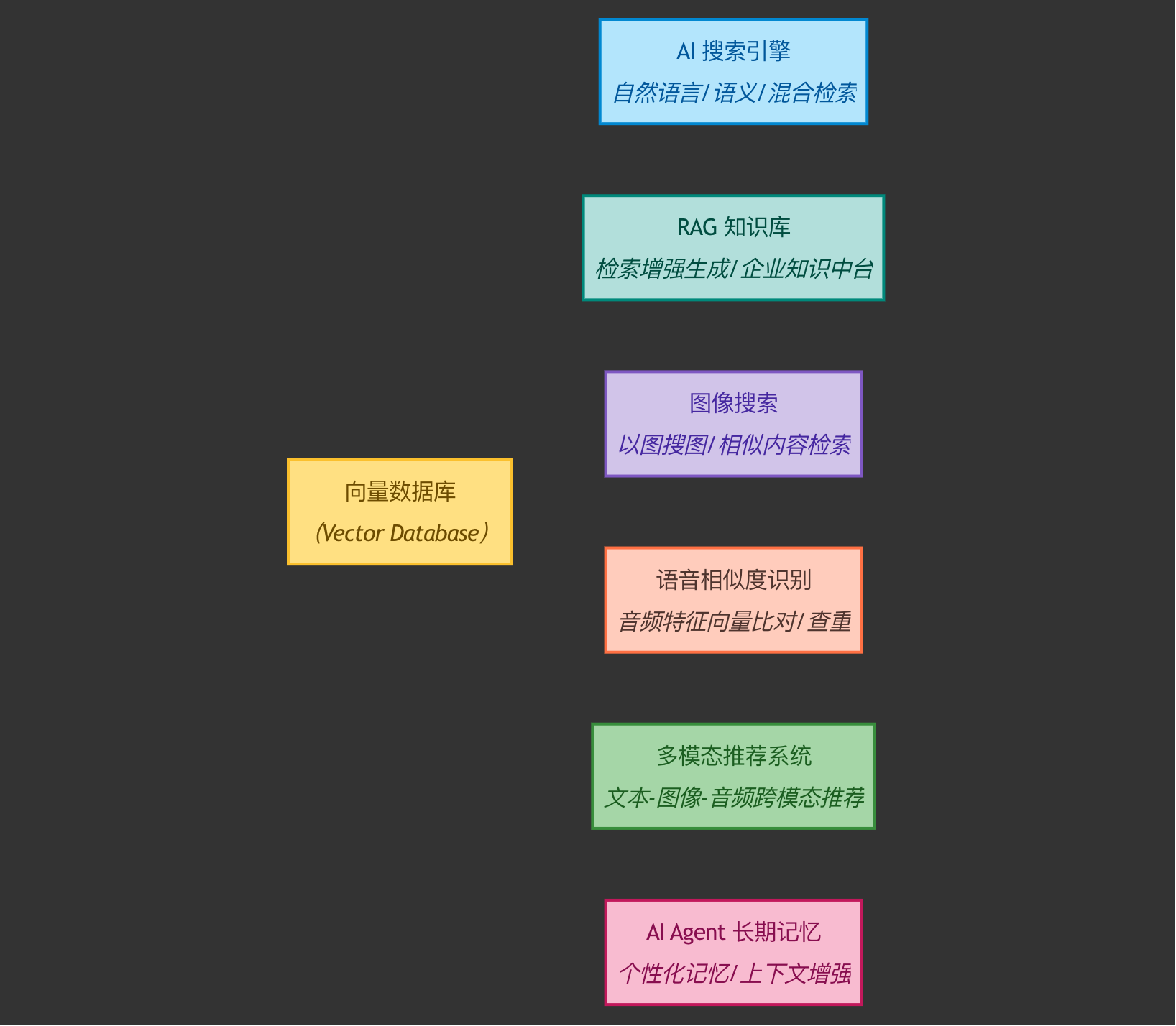
向量数据库是以下系统的“语义记忆体”:
- 企业文档问答系统(Chat Your Docs)
- 金融问答助手、医疗解读系统
- 商品图像搜索(以图搜图)
- 声音检测与异常识别(如机器音)
- AI客服与AI Agent 的记忆管理
- AI Copilot 系统中的知识召回模块
⚙️ 4. 技术底层:向量 + 相似度 + 索引
向量数据库的技术本质包括三部分:
| 模块 | 描述 | 示例技术 |
|---|---|---|
| 向量化 | 把文本/图片/语音转成浮点向量 | BERT, CLIP, Whisper |
| 相似度计算 | 判断两个向量是否“相似” | Cosine, Inner Product |
| 高效索引 | 加速在千万级向量中查找最近的TopK | HNSW, IVF, PQ, ScaNN |
举例:
用户提问“如何重置密码”,系统首先将该问题转换为一个向量,然后在文档向量库中检索与其语义最接近的FAQ内容,再通过大模型生成自然语言答案。

🚀 5. 为什么向量数据库在 AI 时代变得重要?
🔹 1)RAG 架构的基础设施
RAG(Retrieval Augmented Generation)是将“搜索 + 生成”结合的典型架构:

其中“向量数据库”是整个系统是否能“答得准、答得新”的关键。
🔹 2)解决 LLM 的幻觉与更新难题
大模型参数固定,更新周期慢;但企业知识、法规变更、实时信息更新却是动态的。向量数据库允许:
- 不重训模型,知识实时更新
- 结合文档元信息(时间、角色、标签)做精细过滤
- 多模态融合(如图+文)场景更易扩展
🔹 3)嵌入式搜索能力延伸到终端和边缘设备
得益于 Milvus Lite、Qdrant + WebAssembly、FAISS Mobile 等轻量化部署能力,向量数据库开始:
- 本地运行在 Android/iOS 端,助力智能助手实现记忆检索
- 嵌入边缘网关实现图像内容筛选、事件去重等任务
🧱 6. 主流向量数据库选型对比
向量数据库在近两年迎来爆发式增长,以下是当前主流产品的功能对比:
| 特性 | Milvus | Qdrant | Weaviate | FAISS | Pinecone |
|---|---|---|---|---|---|
| 架构类型 | 分布式/云/本地 | 轻量/边缘/云 | 内建模块丰富 | 本地/轻量 | 云服务 |
| 数据持久化 | ✅ RocksDB | ✅ WAL+存储分离 | ✅ 内建模块 | ❌ 非持久化 | ✅ 云自动持久 |
| 向量索引 | IVF, HNSW, PQ | HNSW | HNSW, Flat | 多种 | HNSW (自研) |
| 多模态支持 | ✅ | ✅ | ✅ | ❌ | ❌ |
| 社区活跃度 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐(闭源) |
| 适合场景 | 大规模生产部署 | 嵌入式/边缘 | 语义搜索/多模态 | 快速原型 | 云原生方案 |
选型建议:
- Milvus:适合企业级大规模部署,配合 Zilliz Cloud 提供商用支持。
- Qdrant:轻量、易部署,适合本地知识库、边缘部署。
- FAISS:研究、实验首选;但缺乏服务能力。
- Weaviate:语义丰富、嵌入Graph特性,适合 NLP/推荐等复杂搜索场景。
- Pinecone:闭源云服务,操作简单但不可自托管,适合中小项目。
🌐 7. 部署模式与系统架构
向量数据库部署有三种典型模式:

向量数据库部署架构
- 嵌入模型服务:如 sentence-transformers、OpenAI Embeddings、DeepSeek Embedding API
- 向量服务层:将 Embedding 与向量库查询逻辑封装为统一接口
- 向量数据库集群:支持索引构建、TopK检索、增删改查
✅ 推荐使用 FastAPI + Milvus/Qdrant + PG 构建中小型知识库系统。
📌 8. 实际案例场景
案例一:医疗知识问答助手(中国三甲医院)
- 使用 Qdrant + BGE-Large 向量化超过 40 万条医疗问答记录
- 平均响应时间 180ms,准确率提高至 93.5%
- 敏感术语过滤使用向量距离 + Rule-based 安全体系
案例二:AI图像搜索系统(电商平台)
- 商品图像用 CLIP 编码为向量后存入 Milvus
- 用户上传图片后在 5M+ 商品中实现“以图搜图”
- 支持图+文本联合检索,提升转化率12.3%
案例三:AI代码助手记忆模块(SaaS开发平台)
- 使用 FAISS 构建本地记忆缓存(Context Retrieval)
- 快速检索代码段相关函数、接口、注释
- 与 LLM结合后准确率提升 >20%
🔄 9. 多模态AI系统中的向量数据库
随着多模态大模型(如 DeepSeek-VL、GPT-4o)的兴起,向量数据库正逐步支持更复杂的 Embedding 结构:
| 模态类型 | 示例模型 | 向量维度 | 应用场景 |
|---|---|---|---|
| 文本 | BERT / BGE | 768 | 文档问答、FAQ搜索 |
| 图像 | CLIP / DINO | 512 ~ 2048 | 以图搜图、图文推荐 |
| 语音 | Wav2Vec / Whisper | 1024 | 音频搜索、机器音诊断 |
| 多模态联合 | DeepSeek-VL / MiniGPT | 4096+ | 图文对齐问答、视频分析 |
挑战:
- 向量长度差异较大,索引结构需适配
- 数据更新频繁,需支持增量更新与在线构建索引
- 多模态数据需要标准化处理接口与元信息对齐能力
⚙️ 10. 向量数据库性能优化方法
🔍 近似搜索(ANN)与索引策略
为了应对百万、千万级向量检索带来的性能瓶颈,主流向量数据库通常采用 Approximate Nearest Neighbor(ANN)技术。
常见算法与适用场景:
| 索引算法 | 原理 | 适用规模 | 特点 |
|---|---|---|---|
| HNSW(Hierarchical Navigable Small World) | 多层图搜索结构 | 百万+ | 精度高,搜索快 |
| IVF(Inverted File Index) | 向量聚类倒排 | 千万+ | 内存低、支持分片 |
| PQ / OPQ(Product Quantization) | 向量压缩 + 分桶 | 亿级 | 内存占用极小,适合离线检索 |
💡 优化建议:
- 调整 ef_search 和 M 参数(HNSW)可在精度与速度间权衡
- 将向量长度统一,避免低维/高维混合
- 对高频查询数据构建专属快速索引缓存
🛡️ 11. 私有化部署与安全性设计
在政企、金融、医疗等行业中,向量数据库的私有化部署能力至关重要:
私有部署关注点:
- 资源隔离:使用容器化(Docker/K8s)封装数据库服务
- 数据加密:支持磁盘加密、向量字段加密存储(AES、SM4)
- 访问控制:集成 OAuth2、LDAP、JWT 实现细粒度权限
- 向量内容脱敏:如图像向量中包含敏感面孔特征,应加入扰动机制
- 日志审计:记录每次查询的来源、操作内容、响应内容
💬 推荐架构:
Nginx + FastAPI + Milvus/Qdrant + PostgreSQL,可根据业务场景进行模块热插拔。
📈 12. 向量数据库的未来趋势
📌 趋势一:
融合大模型与多模态能力
- 向量数据库将不仅仅是搜索工具,而是 RAG 系统的“语义记忆引擎”
- 支持联合检索:图像+文本、语音+视频 的多模态索引查询将成为主流
📌 趋势二:
RAG & LLM 集成标准化
- 各大平台正在推出标准化 RAG 组件,如 LangChain、LlamaIndex
- 向量数据库将成为底层“知识检索器”,接入 LLM 构建企业专属大模型助手
📌 趋势三:
轻量级与边缘部署
- 针对 IoT、机器人等终端设备,将催生轻量、离线部署的向量引擎(如 liteQdrant)
- 离线语义搜索将助力私域大模型在低带宽环境中落地
📌 趋势四:
数据可控性与隐私增强
- 数据主权意识增强,向量数据也需要“可撤回”“可追踪”“可匿名化”
- 向量数据库未来可能集成差分隐私、联邦学习接口
总结与行业建议
向量数据库不再只是 AI 搜索技术中的“新物种”,而是正在逐步演进为支持企业 语义检索、智能问答、多模态理解、私有知识构建 的关键基础设施。
在构建 AI 驱动系统时,如何组织数据、如何构建语义索引、如何实现实时智能,将是决定产品智能化能力的核心因素。
✅ 面向 CTO/技术团队的建议:
- 明确业务是否需要语义检索、相似匹配、模糊问答
- 选择支持私有部署、RAG对接、向量扩展能力强的产品
- 构建可持续的数据流:原始数据 → 向量生成 → 索引更新 → 实时检索
更多推荐

 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)