
基于可逆网络的电镜图像去噪无监督域自适应方法|文献速递-最新医学人工智能文献
Title题目Unsupervised Domain Adaptation for EM ImageDenoising With Invertible Networks基于可逆网络的电镜图像去噪无监督域自适应方法01文献速递介绍电子显微镜图像去噪相关研究进展与本文方法 电子显微镜(EM)是生物医学图像分析领域的关键成像技术。其卓越的成像分辨率能够实现纳米尺度生物结构的分析。然而,图像质量与采集时间
Title
题目
Unsupervised Domain Adaptation for EM ImageDenoising With Invertible Networks
基于可逆网络的电镜图像去噪无监督域自适应方法
01
文献速递介绍
电子显微镜图像去噪相关研究进展与本文方法 电子显微镜(EM)是生物医学图像分析领域的关键成像技术。其卓越的成像分辨率能够实现纳米尺度生物结构的分析。然而,图像质量与采集时间之间存在根本性权衡:获取高质量EM图像需要更长的停留时间,导致获取高信噪比清晰图像的过程耗时冗长。例如,Zheng等人[1]为获取成年黑腹果蝇的全脑数据集,耗时约16个月。相反,以较短停留时间采集的EM图像往往噪声明显、信噪比降低。因此,迫切需要有效的去噪算法[3]来加快成像流程,从而获取高信噪比的清晰图像。 传统去噪方法主要依赖非局部和稀疏表征技术,存在耗时久、计算成本高的问题。近年来,基于深度学习的方法在图像去噪领域占据主导地位。早期,一系列基于深度卷积神经网络(CNN)的有监督去噪方法在非盲去噪(如去除加性高斯白噪声,AWGN)任务中展现出优异性能。但这类方法依赖大量带噪-清晰配对图像进行有监督训练,而此类数据的采集与对齐过程十分耗时。此外,仅在合成带噪图像上训练的去噪模型,往往难以有效泛化到真实带噪图像,这主要是由于噪声分布存在域偏移。如图1所示,分别在噪声标准差σ=10和σ=70的加性高斯白噪声图像上训练的去噪算法DnCNN-G10与DnCNN-G70,因噪声分布存在域偏移,在处理σ=25的带噪图像时泛化效果较差(出现残留噪声与伪纹理);而在σ=25的带噪图像上训练、无域偏移的DnCNN-G25则能实现最佳去噪性能。尽管已有仅基于带噪图像训练的自监督去噪方法,但这类方法假设噪声服从特定统计分布。遗憾的是,在实际场景中,真实噪声分布复杂且与图像高度交织(如图2所示),这些假设往往不成立,导致其在真实场景中的去噪效果受限。 理论上,在未知清晰信号与准确噪声分布的情况下,仅基于带噪图像进行去噪极具挑战性。幸运的是,尽管获取大量配对数据存在困难,我们仍可利用大量真实带噪图像,结合少量非配对清晰图像开展研究。该策略能显著降低数据采集与配准的成本和工作量,同时实现噪声分布的学习。基于这一思路,多种非配对去噪方法应运而生。早期非配对去噪方法[16-18]尝试利用生成对抗网络(GAN)生成逼真的带噪图像,这些生成的伪带噪图像可与对应清晰图像配对,用于训练去噪网络。然而,真实噪声分布的复杂性给简单对抗网络的学习带来挑战,导致其效果受限。随着生成式图像转换方法的成功,近期的非配对去噪方法(尤其在生物医学图像领域)采用图像到图像转换的思路应对固有挑战。但需注意的是,这类方法严重依赖图像转换(一项本身具有高复杂性的任务),且忽略了EM图像的固有特征与合成带噪图像的潜在价值,限制了其整体去噪性能。因此,开发稳健、高效的非配对去噪技术仍有较大改进空间。 为填补这一空白,我们结合EM图像的特征(即生物医学样本具有相似纹理,如囊泡、细胞膜等),提出首个面向真实EM图像去噪的无监督域自适应方法。具体而言,该方法首先通过域对齐构建共享的、与域无关的内容空间,连接源域(合成带噪图像)与目标域(真实带噪图像)。实现方式为:从每个域的带噪图像中分离出内容表征与噪声成分,随后对两个域的内容表征进行域对抗训练。为确保精准域对齐,我们通过内容表征与噪声成分重建伪带噪图像,实施域正则化——重建过程需精准捕捉噪声成分所来源带噪图像的特征,同时与内容表征所来源带噪图像保持语义一致性。为保证表征分解与图像重建的无损性,我们引入“分离-重建可逆网络”。与现有非配对去噪算法中的循环一致性约束相比,该设计既降低了计算成本,又确保了无损耗的双射变换。最终,我们得到与真实带噪图像高度相似的伪带噪图像(如图2所示)。这些生成的伪带噪图像与源域的合成带噪图像可分别与对应清晰图像配对,极大助力去噪网络的训练。通过这种方式,我们的方法既保留了现有非配对方法的优势,又在合成与真实数据集上均实现了当前最优的EM图像去噪性能。 本研究的贡献如下: - 从无监督域自适应视角出发,提出首个EM图像去噪方法,该方法充分利用EM图像特征,搭建了合成源域与真实目标域之间的桥梁。 - 设计“分离-重建可逆网络”,实现无损的表征分解与高保真的带噪图像重建。 - 构建包含不同停留时间的真实带噪-清晰配对扫描电镜(SEM)图像数据集,为EM去噪方法的开发与评估提供支持。 - 通过大量实验验证,该方法在EM图像去噪任务上实现当前最优性能,并提升了神经元分割精度。
Aastract
摘要
Electron microscopy (EM) image denoising iscritical for visualization and subsequent analysis. Despitethe remarkable achievements of deep learning-based nonblind denoising methods, their performance drops significantly when domain shifts exist between the trainingand testing data. To address this issue, unpaired blinddenoising methods have been proposed. However, thesemethods heavily rely on image-to-image translation andneglect the inherent characteristics of EM images, limiting their overall denoising performance. In this paper,we propose the first unsupervised domain adaptive EMimage denoising method, which is grounded in the observation that EM images from similar samples share commoncontent characteristics. Specifically, we first disentanglethe content representations and the noise componentsfrom noisy images and establish a shared domain-agnosticcontent space via domain alignment to bridge the synthetic images (source domain) and the real images (targetdomain). To ensure precise domain alignment, we further incorporate domain regularization by enforcing that:the pseudo-noisy images, reconstructed using both content representations and noise components, accuratelycapture the characteristics of the noisy images fromwhich the noise components originate, all while maintaining semantic consistency with the noisy images fromwhich the content representations originate. To guaranteelossless representation decomposition and image reconstruction, we introduce disentanglement-reconstructioninvertible networks. Finally, the reconstructed pseudo-noisyimages, paired with their corresponding clean counterparts, serve as valuable training data for the denoisingnetwork. Extensive experiments on synthetic and real EMdatasets demonstrate the superiority of our method in
电子显微镜(EM)图像去噪的重要性及相关方法研究 电子显微镜(EM)图像去噪对于图像可视化及后续分析至关重要。尽管基于深度学习的非盲去噪方法已取得显著成果,但当训练数据与测试数据之间存在域偏移时,其性能会大幅下降。为解决这一问题,研究人员提出了无配对盲去噪方法。然而,这类方法严重依赖图像到图像的转换,且忽略了电子显微镜图像的固有特征,从而限制了其整体去噪性能。 在本文中,我们提出了首个无监督域自适应电子显微镜图像去噪方法。该方法的核心依据是:来自相似样本的电子显微镜图像具有共同的内容特征。具体而言,我们首先从含噪图像中分离出内容表征与噪声成分,并通过域对齐构建一个共享的、与域无关的内容空间,以连接合成图像(源域)与真实图像(目标域)。 为实现精准的域对齐,我们进一步引入域正则化,确保以下条件:利用内容表征与噪声成分重建得到的伪含噪图像,既能准确捕捉噪声成分所来源的含噪图像的特征,同时又能与内容表征所来源的含噪图像保持语义一致性。 为保证表征分解与图像重建的无损性,我们引入了分离-重建可逆网络。最后,将重建得到的伪含噪图像与其对应的干净图像配对,作为去噪网络的有效训练数据。在合成及真实电子显微镜数据集上开展的大量实验表明,我们提出的方法具有优越性。
Method
方法
We aim to learn an effective denoising model for real noisyimages without paired supervision. This process is visuallydepicted in Fig. 3. To achieve this goal, we utilize two distinctsets of unpaired images: 1) We start with a set of real cleanEM images denoted as Y = {yi}i=1,...,N , which we use toartificially generate noisy images X S = {xi S }i=1,...,N via noisemodeling that forms the source domain S; 2) Additionally,we have another set consisting of real noisy EM images,denoted as X R = {x R j }j=1,...,M , which forms the targetdomain T . Our framework consists of three fundamentalcomponents: 1) Domain alignment: Our initial step involvesaligning both domains to obtain a domain-agnostic contentspace; 2) Domain regularization: We subsequently introducea domain regularization step to ensure precise domain alignment. This step also helps in generating pseudo-noisy images;Denoising network training: Finally, we train our denoisingnetwork using pairs of generated pseudo-noisy images andtheir corresponding clean images.
真实带噪图像去噪模型的学习目标与框架组成 我们旨在为真实带噪图像学习一种无需配对监督的有效去噪模型,该过程的可视化展示如图3所示。为实现这一目标,我们利用两组不同的非配对图像:1)首先使用一组真实清晰电子显微镜(EM)图像(记为(Y = {y_i}{i=1,...,N})),通过噪声建模人工生成带噪图像(X_S = {x_i^S}{i=1,...,N}),构成源域(S);2)此外,我们还有另一组真实带噪电子显微镜图像(记为(X_R = {x_j^R}_{j=1,...,M})),构成目标域(T)。 我们的框架包含三个基本组件:1)域对齐:第一步对两个域进行对齐,以获得与域无关的内容空间;2)域正则化:随后引入域正则化步骤,确保域的精准对齐,该步骤同时有助于生成伪带噪图像;3)去噪网络训练:最后,利用生成的伪带噪图像及其对应的清晰图像配对,训练去噪网络。
Conclusion
结论
In this paper, we present a novel unpaired EM imagedenoising method from the perspective of domain adaptation.Inspired by the observation that biomedical EM images sharecontent characteristics, our method begins with establishinga domain-agnostic content space between synthetic and realnoisy images through domain alignment learning. We furtherintroduce domain regularization to ensure precise domainalignment and generate pseudo-noisy images that conform tothe real noise distribution, obtaining image pairs for denoisingnetwork training. To achieve lossless representation disentanglement and image reconstruction, we adopt invertiblenetworks in our framework. Extensive experiments on synthetic and real datasets demonstrate the superiority of ourmethod over existing methods quantitatively and qualitatively.
本文从域自适应的角度,提出了一种新型的非配对电子显微镜(EM)图像去噪方法。基于生物医学EM图像具有共同内容特征这一观察,我们的方法首先通过域对齐学习,在合成噪声图像与真实噪声图像之间建立一个域无关的内容空间。我们进一步引入域正则化,以确保精准的域对齐,并生成符合真实噪声分布的伪噪声图像,从而获得用于去噪网络训练的图像对。为实现无损的表征解纠缠与图像重建,我们在框架中采用了可逆网络。在合成数据集与真实数据集上开展的大量实验,从定量和定性两方面证明了我们的方法相较于现有方法的优越性。
Results
结果
A. Compared Methods
To thoroughly assess our proposed method, we conduct acomprehensive comparison with a range of advanced denoising techniques, categorized into six classes:Non-learning based: This category includes two classicalimage denoising algorithms, BM3D [4] and WNNM .Supervised† (Real noise): In this ideal case, supervisednetworks are trained on real noisy-clean image pairs,and the training data match the test data distribution.The denoising results obtained through these methodscan be considered as an upper bound.Supervised (Board noise): Networks are trained on abroad range of simulated noisy images paired with theircorresponding clean labels, and testing is performed onreal noisy images. We simulate noisy training images byadding AWGN with a random σ between 10 and 85.Supervised (Specific noise): Networks are trained onsynthetic image pairs, and the simulated noise followsa specific distribution. We simulate the training noisyimages by adding AWGN with σ = 55.Self-supervised: These methods are trained only onnoisy images. We include four exceptional selfsupervised methods: DIP, ZSn2n, N2V ,and B2U .Unpaired supervised: These methods are trained onunpaired clean and noisy images, which is also oursetting. We include CycleGAN [19] and four state-ofthe-art unpaired denoising methods: ISCL , ADN, C2N , and DRGAN All methods except “Supervised† (Real noise)” are trainedwithout the knowledge of noise distribution of testing data. Foreach class of supervised training, we apply four popular networks: DnCNN [6], CBDNet , DIDN [8], and RIDNet .
A. 对比方法 为全面评估本文所提方法,我们将其与多种先进去噪技术进行综合对比,并将这些对比方法分为以下六类: 1) 非基于学习的方法:该类别包含两种经典图像去噪算法,即BM3D[4]和WNNM[5]。 2) 有监督方法†(真实噪声):在这种理想场景下,有监督网络基于真实带噪-清晰图像对进行训练,且训练数据分布与测试数据分布一致。通过这类方法得到的去噪结果可视为性能上限。 3) 有监督方法(广谱噪声):网络基于大量模拟带噪图像及其对应清晰标签进行训练,测试则在真实带噪图像上开展。我们通过添加标准差(\sigma)在10至85之间随机取值的加性高斯白噪声(AWGN),生成模拟带噪训练图像。 4) 有监督方法(特定噪声):网络基于合成图像对进行训练,且模拟噪声服从特定分布。我们通过添加标准差(\sigma=55)的加性高斯白噪声(AWGN),生成模拟带噪训练图像。 5) 自监督方法:这类方法仅基于带噪图像进行训练。我们选取了四种性能优异的自监督方法,分别为DIP、ZSn2n、N2V和B2U[。 6) 非配对有监督方法:这类方法基于非配对的清晰图像与带噪图像进行训练,与本文方法的训练数据设置一致。我们选取了CycleGAN[以及四种当前主流的非配对去噪方法,即ISCL]、ADN、C2N和DRGAN。 除“有监督方法†(真实噪声)”外,其余所有方法的训练过程均不依赖测试数据的噪声分布信息。对于每一类有监督训练,我们均采用四种常用网络架构:DnCNN[6]、CBDNet[7]、DIDN[8]和RIDNet。
Figure
图

Fig. 1. Visual comparison of denoising results with/without domain shift。
图1 存在/不存在域偏移时的去噪结果可视化对比
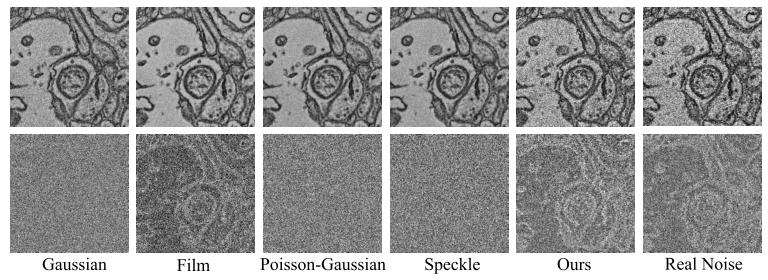
Fig. 2. Top row: An example of common types of synthetic noisyimages (i.e., Gaussian, film, Poisson-Gaussian, speckle), a noisy imagegenerated as a byproduct by our proposed method, and a real-world EMnoisy image. Bottom row: the corresponding noise maps for each of thenoisy images.
图2 上排:常见类型合成带噪图像(即高斯噪声图像、胶片噪声图像、泊松-高斯噪声图像、散斑噪声图像)、本文方法生成的伪带噪图像(作为副产品),以及一幅真实电子显微镜(EM)带噪图像。 下排:上述各带噪图像对应的噪声图。
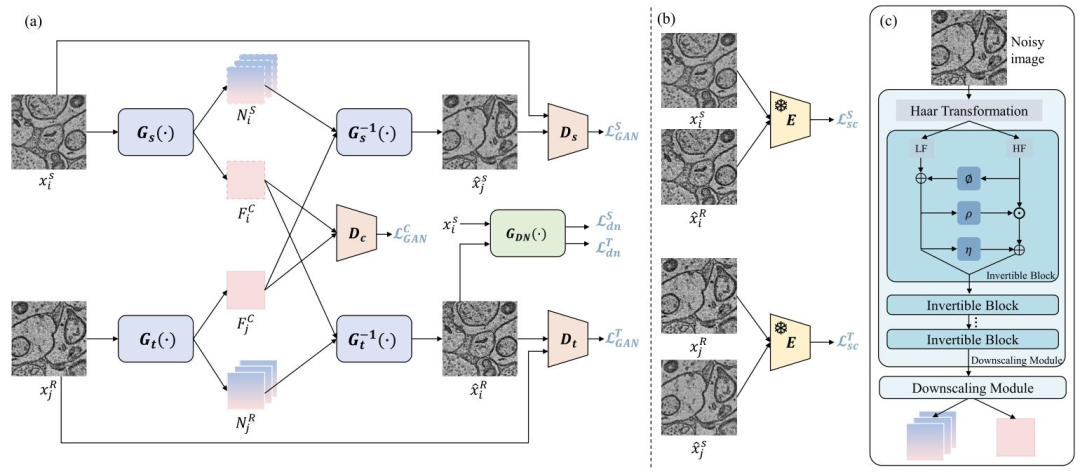
Fig. 3. (a) Overview of our proposed framework. (b) Semantic consistency constraints through a pre-trained encoder E. (c) Specific architecture ofdisentanglement-reconstruction invertible networks Gs (·)/Gs −1 (·) and Gt (·)/Gt −1 (·)
图3 (a)本文所提框架的整体概览; (b)通过预训练编码器(E)实现的语义一致性约束; (c)分离-重建可逆网络(G_s(\cdot)/G_s^{-1}(\cdot))与(G_t(\cdot)/G_t^{-1}(\cdot))的具体架构
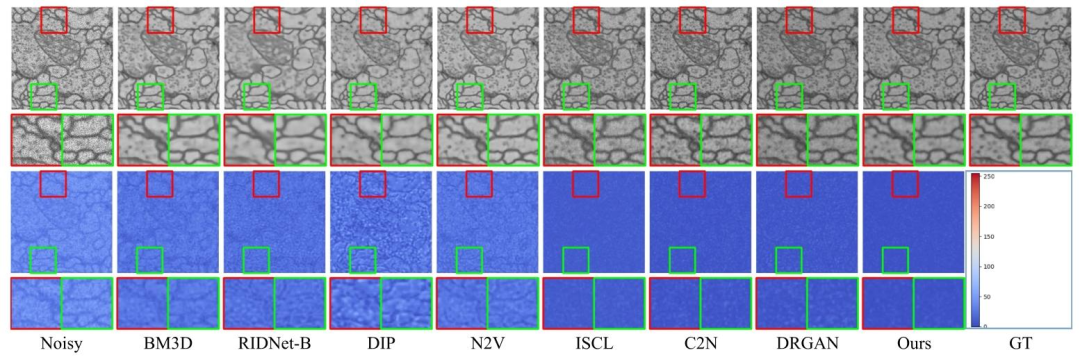
Fig. 4. Visual comparison (denoising results and error maps) on synthetic test data.
图4 合成测试数据的可视化对比(去噪结果与误差图)
Fig. 5. Exemplar segmentation results on the denoising results of a synthetic noisy image. Each pseudo color represents one neuron.
图5 合成带噪图像去噪结果的典型分割结果 (图中每种伪彩色代表一个神经元。)
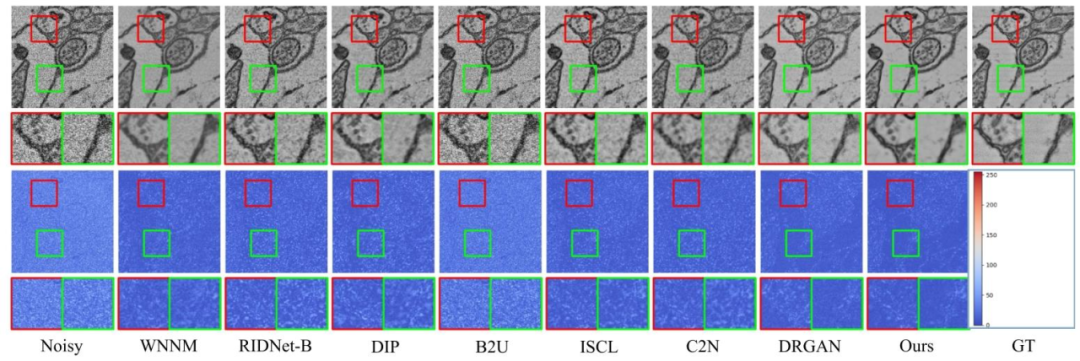
Fig. 6. Visual comparison (denoising results and error maps) on real test data.
图6 真实测试数据的可视化对比(去噪结果与误差图)
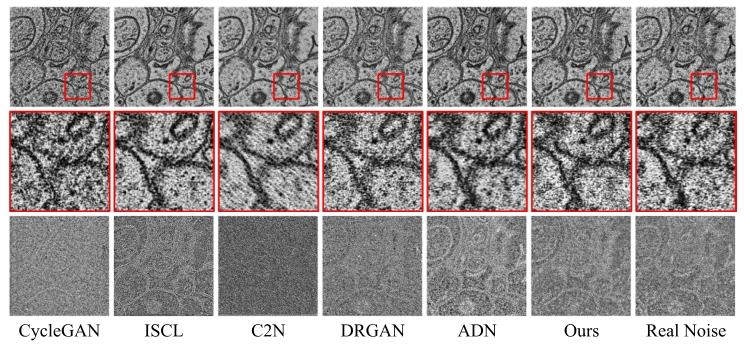
Fig. 7. Visual comparison (generated pseudo-noisy images and thecorresponding noise maps) of unpaired denoising methods
图7 非配对去噪方法的可视化对比(生成的伪带噪图像及对应噪声图)
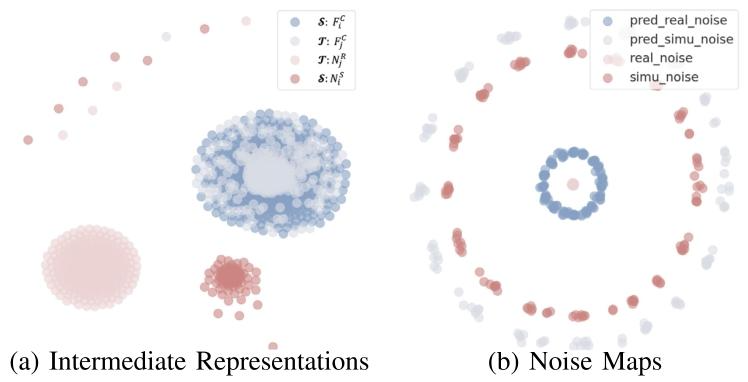
Fig. 8. t-SNE visualization of the distribution of (a) intermediate representations and (b) noise maps.
图 8 t-SNE 可视化结果
(a)中间特征表示的分布;(b)噪声图的分布。
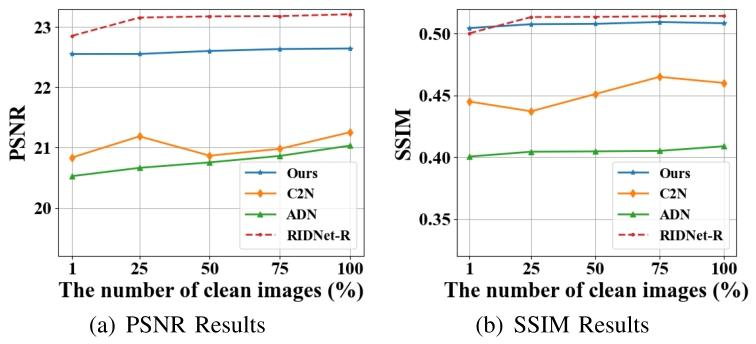
Fig. 9. Quantitative results on real dataset with fewer clean images.
图9 清洁图像数量较少时在真实数据集上的定量结果
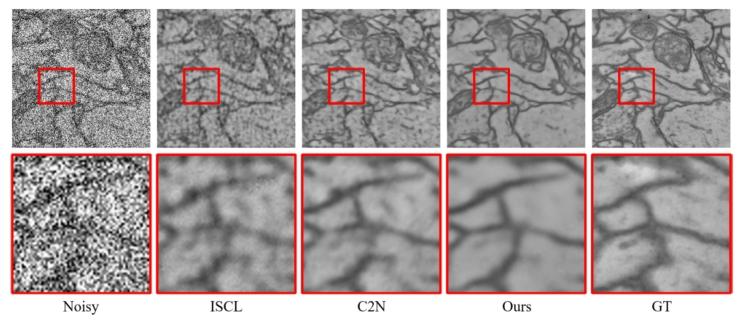
Fig. 10. Visual comparison of denoising results on LR noisy images.
图10 低分辨率(LR)带噪图像去噪结果的可视化对比
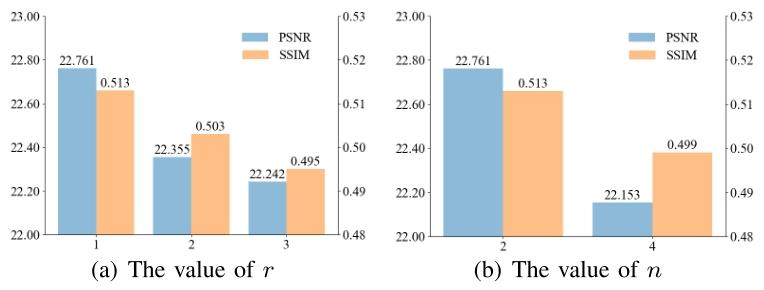
Fig. 11. Ablation results of hyperparameters of Gs( · )/Gt ( · ).
图11 生成器Gₛ(·)/Gₜ(·)超参数的消融实验结果
Table
表
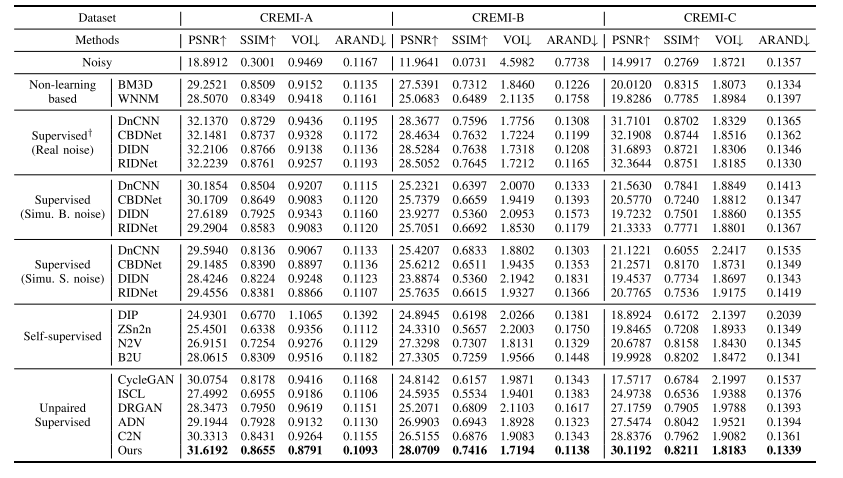
TABLE I QUANTITATIVE RESULTS OF IMAGE DENOISING ON SYNTHETIC TEST IMAGES FROM THE CREMI DATASET [2], IN TERMS OF IMAGE RESTORATIONFIDELITY (PSNR / SSIM) AND NEURON SEGMENTATION ACCURACY (VOI / ARAND).NOTE THAT † STANDS FOR IDEAL SUPERVISION WHICH IS NOT ALWAYS AVAILABLE IN REAL CASES
表1 CREMI数据集合成测试图像的去噪定量结果 (评价指标包括图像恢复保真度(峰值信噪比PSNR/结构相似性SSIM)与神经元分割精度(体积重叠误差VOI/调整兰德指数ARAND)。注:†代表理想监督模式,在实际场景中并非总能实现。)
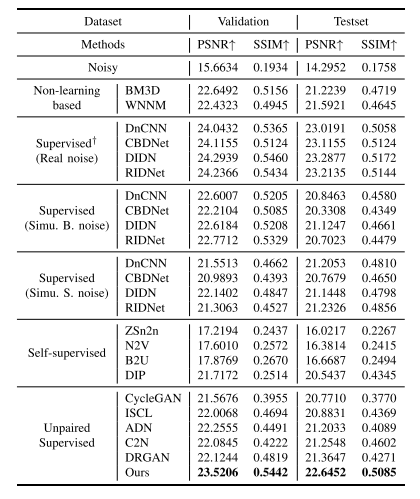
TABLE II QUANTITATIVE DENOISING RESULTS (PSNR / SSIM) ON REALIMAGES FROM THE RETINA DATASET
表2 视网膜数据集(Retina Dataset)真实图像的去噪定量结果(峰值信噪比PSNR/结构相似性SSIM)
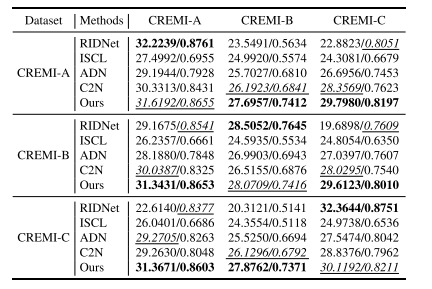
TABLE III QUANTITATIVE RESULTS (PSNR / SSIM) OF GENERALIZATIONANALYSIS ON CREMI DATASET
表3 CREMI数据集泛化性分析的定量结果(峰值信噪比PSNR/结构相似性SSIM)
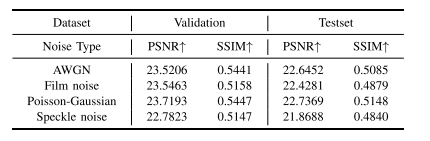
TABLE IV QUANTITATIVE RESULTS OF DIFFERENT SOURCE NOISE MODELINGSTRATEGY ON THE RETINA DATASET
表4 视网膜数据集(Retina Dataset)上不同源噪声建模策略的定量结果
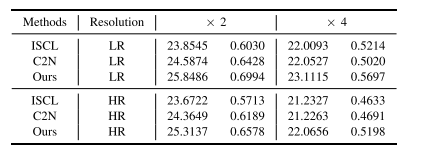
TABLE V QUANTITATIVE COMPARISON OF DENOISING RESULTS ON NOISY IMAGES WITH VARYING RESOLUTIONS
表5 不同分辨率带噪图像上的去噪结果定量对比
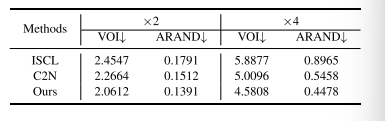
TABLE VI QUANTITATIVE COMPARISON OF SEGMENTATION RESULTS ON DENOISED IMAGES AT DIFFERENT RESOLUTIONS
表6 不同分辨率去噪图像上的分割结果定量对比
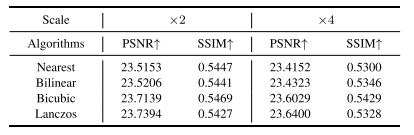
TABLE VII QUANTITATIVE COMPARISON OF DENOISING RESULTS (PSNR / SSIM)WITH DIFFERENT DOWNSAMPLING ALGORITHMS AND DOWNSAMPLING FACTORS IN THE CONTENT GUIDANCE LOSS
表7 内容引导损失中采用不同下采样算法与下采样因子时的去噪结果定量对比(峰值信噪比PSNR/结构相似性SSIM)
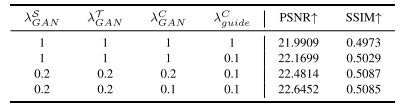
TABLE VIII QUANTITATIVE RESULTS OF DIFFERENT LOSS WEIGHTS ON RETINA TESTSET (λ T dn = 1, λ S dn = 1, λsc = 0.05)
表8 视网膜测试集(Retina Testset)上不同损失权重的定量结果(λT dn = 1,λS dn = 1,λ_sc = 0.05)
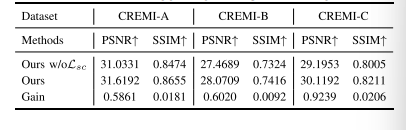
TABLE IX QUANTITATIVE COMPARISON OF RESULTS WITH/WITHOUT A PRE-TRAINED ENCODER ON THE CREMI DATASET
表9 CREMI数据集上使用/不使用预训练编码器的结果定量对比
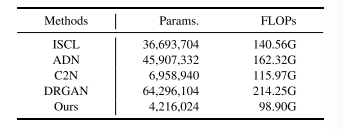
TABLE X PARAMETER COUNT AND COMPUTATIONAL COST COMPARISON OFDENOISING ALGORITHMS
表10 去噪算法的参数量与计算成本对比
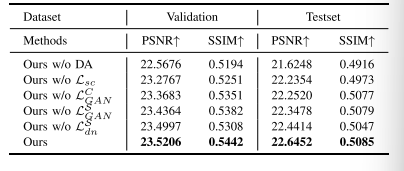
TABLE XI ABLATION RESULTS (PSNR / SSIM) ON RETINA DATASET
表11 视网膜数据集上的消融实验结果(峰值信噪比PSNR/结构相似性SSIM)
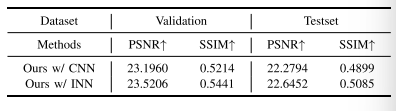
TABLE XII QUANTITATIVE COMPARISON OF RESULTS WITH/WITHOUT USING INVERTIBLE NETWORKS ON THE RETINA DATASET
表12 视网膜数据集上使用/不使用可逆网络(Invertible Networks)的结果定量对比
更多推荐

 17
17 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)