
【人工智能通识专栏】第二十三讲:数据处理与分析
数据处理与分析是日常办公中不可或缺的基本技能。借助DeepSeek可以更快速、准确地完成数据的处理、理解、分析与呈现,提高处理和决策的效率。
在学习和科研之外,数据处理、图表展示与PPT制作几乎贯穿了日常办公和工作汇报的全过程。DeepSeek在办公应用中可以作为智能助手,提高工作效率与表达质量。
本章将以数据分析、可视化图表和PPT制作为主线,展示DeepSeek如何帮助我们完成从数据洞察到成果展示的全链路优化,让报告更直观、图表更清晰、演示更具说服力。
数据处理与分析是日常办公中不可或缺的基本技能。借助DeepSeek可以更快速、准确地完成数据的处理、理解、分析与呈现,提高处理和决策的效率。
8.1.1 数据获取与预处理
传统的数据预处理要根据原始数据的格式和存在问题手动调整或编写代码,过程繁琐且容易出错。使用DeepSeek通过自然语言指令可以方便、准确地实现结构标准化、数据清洗和数据标准化等数据预处理任务,大幅提升效率。
联网搜索数据
数据收集是数据处理与分析的基础。互联网上有大量可公开获取的数据资源,例如政策法规、新闻资讯、统计数据、金融行情、商品价格等。DeepSeek的“联网搜索”提供了轻松获取外部数据的途径,使用户可以快速获取并整理这些公开数据,用于分析与决策支持。
例如,检索和整理Intel i7处理器的参数。开启DeepSeek的联网搜索功能,并输入提问:【请搜索英特尔官方网址,以表格形式输出英特尔i7处理器的名称、内核数、最大频率、缓存和GPU型号,并标注数据来源。】。DeepSeek就能快速搜索和整合数据,以表格形式输出搜索结果,如图8-1所示。
需要注意的是:(1)联网搜索要遵守法律法规,例如禁止爬取个人隐私数据,获取商业数据要遵守平台规定;(2)DeepSeek搜索结果可能存在编造事实,需要对数据来源进行核实或交叉验证。
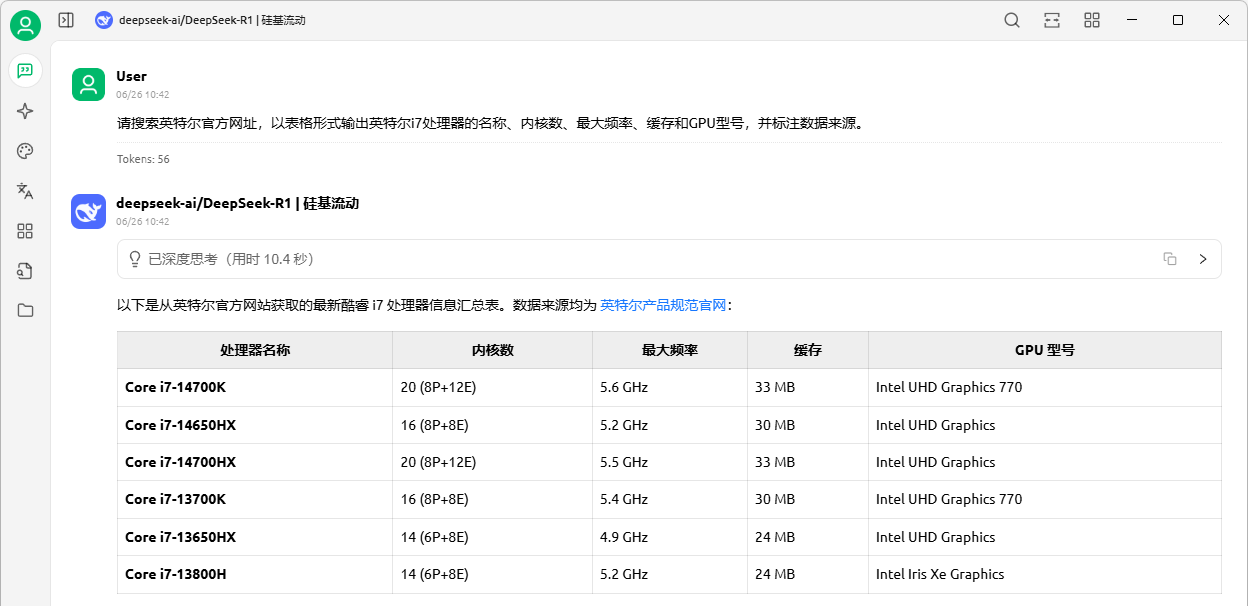
图8-1:使用DeepSeek联网搜索数据
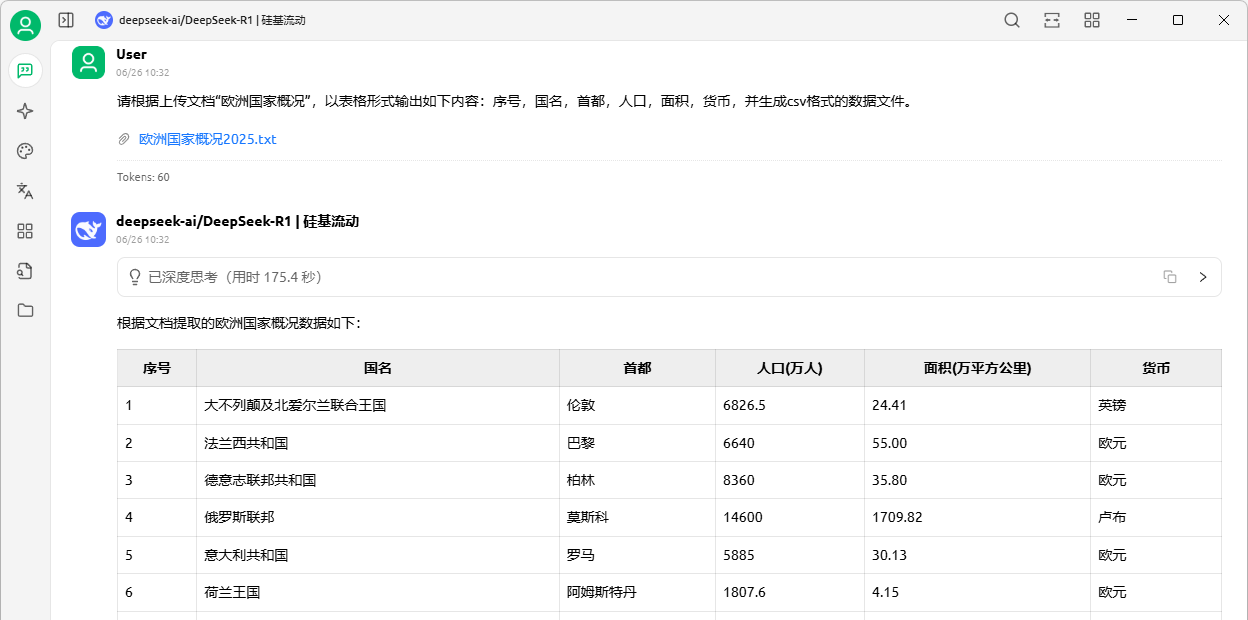
图8-2:使用DeepSeek解析文档提取数据
分析文本提取数据
学术研究中经常需要从文档资料中提取结构化数据,例如对图书论文进行定量分析、从报告中提取实验数据,手工处理不仅耗时费力,而且容易出现疏漏。
通过DeepSeek上传文档并输入提取指令,系统将自动识别文本中的关键数据,生成精准数据表格,并支持导出CSV格式数据文件。
例如,根据给定的文件《欧洲国家概况》整理欧洲各国基本信息。上传文档后向DeepSeek提问:【请根据上传文档“欧洲国家概况”,以表格形式输出如下内容:序号,国名,首都,人口,面积,货币,并生成csv格式的数据文件。】。如图8-2所示,DeepSeek阅读和解析文档内容,提取到所需的数据以表格形式输出,并提供CSV格式输出。
打开DeepSeek深度思考过程,可看到DeepSeek处理文档提取数据的方法和步骤如下。
DeepSeek:我们被要求从用户上传的文档"欧洲国家概况2025.txt"中提取以下信息:国名、首都、人口、面积、货币,并以表格形式输出,包括序号。最后还要生成CSV格式的数据文件。
分析文档内容:
1. 文档包含了多个欧洲国家的概况,每个国家以"【国 名】"等标题分隔。
2. 我们需要的信息在每个国家的概况中都有出现,格式类似。
步骤:
1. 按国家分割文档:通过观察,文档中每个国家的大标题是"国名国家概况"(如"英国国家概况"),但每个国家的详细内容中都有"【国 名】"等条目。
2. 提取每个国家的:国名、首都、人口、面积、货币。
- 注意:有些国家的条目中有补充说明(比如英国的面积包括内陆水域,人口有统计年份),我们只需要提取主要数字和名称,忽略括号内的说明。
- 人口和面积的单位要统一:人口单位为万人(或直接写数字),面积单位为万平方公里(或平方公里,看文档如何写)。
- 货币单位直接提取。
3. 序号:按我们提取国家的顺序编号。
4. 生成表格:表头:序号,国名,首都,人口(万人),面积(万平方公里),货币。
5. 具体提取规则:
- 国名:在【国名】后面的内容,注意有些国家有长名称和简称,我们取长名称。
- 首都:在【首都】后面的内容,通常是一个城市名,注意可能有城市说明,我们只需要城市名。
- 人口:在【人口】后面的数字,注意单位,因为需要生成表格,我们统一用万人。
数据预处理‒结构标准化
结构标准化是指通过处理多层表头、跨页重复标题、修复缺失列名等方法,确保数据在字段定义、行列关系和数值维度上的一致性,从而消除解析冲突和分析障碍。
1. 处理多层表头。
带有多层表头的复杂表格可能导致数据结构歧义、数据错位,处理目的是降多层表头转化为标准二维表格。使用DeepSeek处理多层表头的指令示例如下:
【对上传的文档“***”,请识别多层表头层级,将父级标题与子级标题拼接(如“2023_课程成绩_高等数学”),将复合列名拆分成独立字段,删除冗余标题行,以csv格式输出。】。
2. 处理重复表头。
重复表头通常出现于表格分页显示时,每页顶部重复出现标题行。使用DeepSeek处理重复表头的指令示例如下:
【对上传的文档“***”,请识别重复表头,删除冗余标题行,以csv格式输出。】。
3. 修复缺失列名。
修复缺失列名是指为未正确命名的数据列(如系统生成的 Unnamed: 0 或空白列头)赋予语义明确的标识符。使用DeepSeek修复缺失列名的指令示例如下:
【对上传的文档“***”,请检测并修复当前表格中的缺失列名,规则如下:1、扫描所有 Unnamed 或空白列名的列,2、根据列数据类型和前5行值推断语义,3、对首列纯数字索引保留列名“行ID”,4、以csv格式输出,5、生成修复报告供确认。】。
对于特殊场景,可以根据具体情况追加修复规则。
数据预处理‒数据清洗
数据清洗是指识别并修正错误、不完整或不合理的数据,以保障数据分析的准确性和可靠性。数据清洗的常用方法包括缺失值、异常值和重复数据的处理。
1. 缺失值处理。
缺失值处理是通过填充、删除或标记等方法来修复数据集中的空白值,以确保数据结构的完整性。使用DeepSeek处理缺失值的指令示例如下。
【请对上传的文档data.csv中的age列进行缺失值处理,规则如下:1、用该列中位数填充空白,2、以csv格式输出,3、生成修复报告供确认。】。
根据具体情况可以选择不同的处理规则,例如:删除所有含缺失值的行、将所有缺失值替换为-1作为特殊标识、根据模型预测缺失值。
2. 异常值处理。
异常值处理是指识别超出合理范围的值,采用删除、替换或调整的方法来修正,以提升数据分析的可靠性。
处理异常值的核心逻辑是先定义异常判定规则,再选择处理策略(如替换、加权或删除)。使用DeepSeek处理异常值的指令示例如下。
【请对上传的文档data.csv中的age列进行异常值处理,规则如下:1、对于小于0或大于99的数值判定为异常值,2、用该列中位数填充异常值,3、以csv格式输出,4、生成修复报告供确认。】。
3. 文本脏数据的处理。
文本脏数据是指因采集/存储错误、编码不兼容或人工输入失控导致的非标准文本内容,包括乱码、无效符号、异常编码、无意义片段或格式污染。
使用DeepSeek处理文本脏数据的指令示例如下。
【请清理comment_text列,移除所有非中英文字符(保留汉字、字母及数字),压缩连续空格至单空格。】。
【请修复news_content中的乱码,检测不可解码片段并将其替换为[UNK],将繁体字符转换为简体字符。】。
【请清洗json_log中的脏数据,提取被<script>...</script>包裹的正文文本,删除广告模板字符串。】。
4. 重复数据的处理。
重复数据处理是通过识别并删除(或合并)数据集中完全一致或关键特征重复的记录,保证数据唯一性与分析准确性的过程。
处理重复数据的逻辑是先定义重复规则(如全字段匹配或关键字段匹配),再选择处理策略(如删除、合并或标记)。使用DeepSeek处理重复数据的指令示例如下。
【请对数据集user_logs.csv进行重复数据处理,删除sales_orders表中所有字段完全相同的重复行。】
【基于user_id、time两列判断重复行,保留首次出现的记录并删除后续重复项。】。
【合并customer_feedback的重复记录,对同一 order_id 的反馈文本取最新版本】。
5. 冗余列的处理。
冗余列是指数据集中与其它列相同或高度相关的特征列,通常可以进行删除或合并。使用DeepSeek处理冗余列的指令示例如下。
【请对数据集user_logs.csv进行冗余列处理,删除其中完全重复的列。】
数据预处理‒数据标准化
数据标准化是将不同量纲、格式的数据转化为统一标准和尺度,为分析提供一致性、可比性的基础。数据标准化的常用方法包括统一量纲、格式标准化和数据归一化。
1. 统一量纲。
统一量纲是指将所有数值转换为统一的度量单位,如将长度单位统一为米、将金额统一为万元。使用DeepSeek统一量纲的指令示例如下。
【请对数据集result.csv进行统一量纲处理:1、将weight列的单位统一为kg,注意识别原始单位(如lbs或g)并自动转换转换为kg,2、将length列的单位统一为mm。】
2. 格式标准化。
格式标准化是指将数据中的非结构化或异构表达(如日期、文本、代码等)转换为统一结构和逻辑规范的过程。
(1)日期时间标准化。DeepSeek指令示例:【对log_date列中的日期标准化处理,转换或补全为YYYY-MM-DD格式。】
(2)数据格式标准化。DeepSeek指令示例:【对price列中的金额标准化处理,删除人民币符号¥和千分位逗号(如1,000.5→1000.50),保留两位小数。】
(3)文本中的关键实体标准化。DeepSeek指令示例:【将product_name列中的CPU名称标准化处理为“Intel [i级别]-[型号][后缀]”格式,如将i5 12400F转换为Intel i5-12400F、将intel12代酷睿i5转换为Intel i5-12xxx。并生成映射报告。】
8.1.2 数据分析与建模
数据分析是从数据中提取有价值的信息,包括统计汇总、趋势识别和关联判断等。借助DeepSeek可以用自然语言描述数据分析任务,提升分析效率与表达质量。
数据概况与汇总
统计总数,计算平均值、最大值、最小值等基础信息。
1. 数据概览,快速把握数据的全局状态。使用DeepSeek进行数据概览的指令示例如下。
【请总结这组销售数据的基本情况,说明各行列的标题、类型和单位。】。
2. 数据统计。使用DeepSeek指令示例如下:
【请分析这组实验数据的数据总量、平均值、最大值和最小值。】。
【根据上传的销售报表,分析销售额最高和最低的月份。】。
3. 探索性分析。
对于《新能源汽车销售数据表》进行探索性分析。上传文档后向DeepSeek提问如下。
【请对上传文件“销售数据表.csv”,1、介绍数据表的主要内容,2、进行探索性分析。】。
如图8-3所示,DeepSeek可以自动识别行列数据,理解数据内容,还从数据趋势、产品竞争力和关键发现等多角度进行探索性分析,这使我们能够快速概览数据的基本信息。
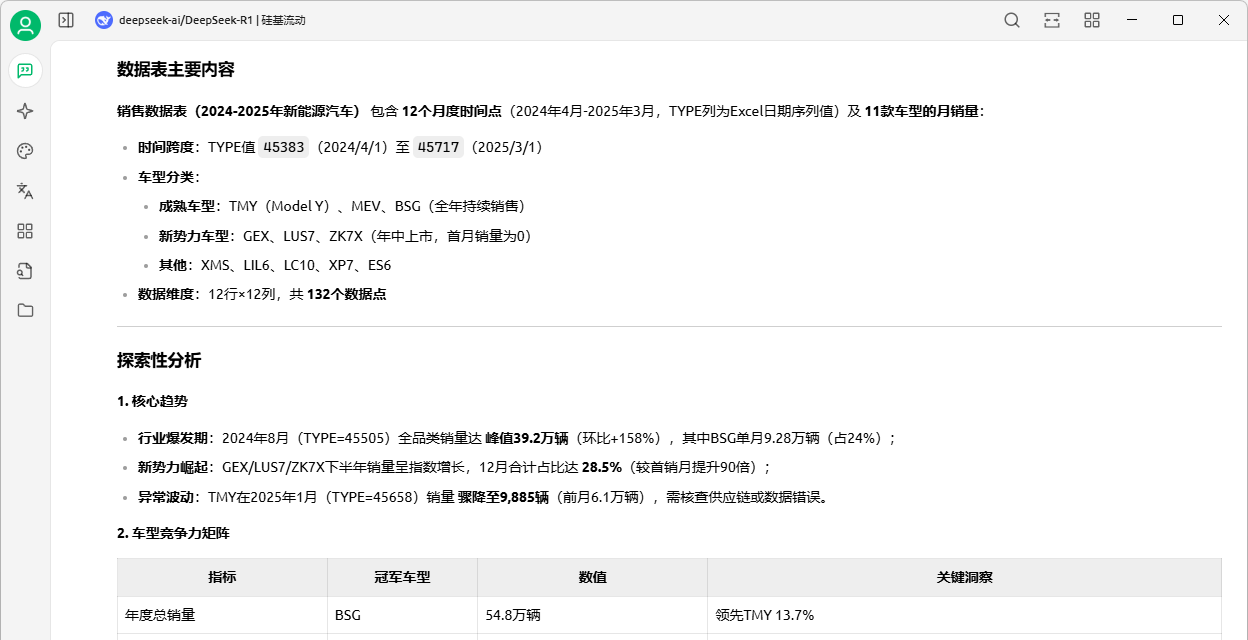
图8-3:使用DeepSeek对数据进行探索性分析
趋势分析
趋势分析是数据分析中识别数据随时间变化的走向、周期性变化或潜在规律的关键步骤,有助于预测未来或优化决策。
对新能源汽车销售数据进行趋势分析,向DeepSeek提问的指令示例如下。
【请根据上传文件“销售数据表.csv”, 分析各车型销量的月度趋势,识别整体增长方向、季节性波动规律及异常拐点。】。
如图8-4所示,DeepSeek基于销售数据分析了整体增长趋势、积极性波动规律,识别异常拐点并分析形成原因。
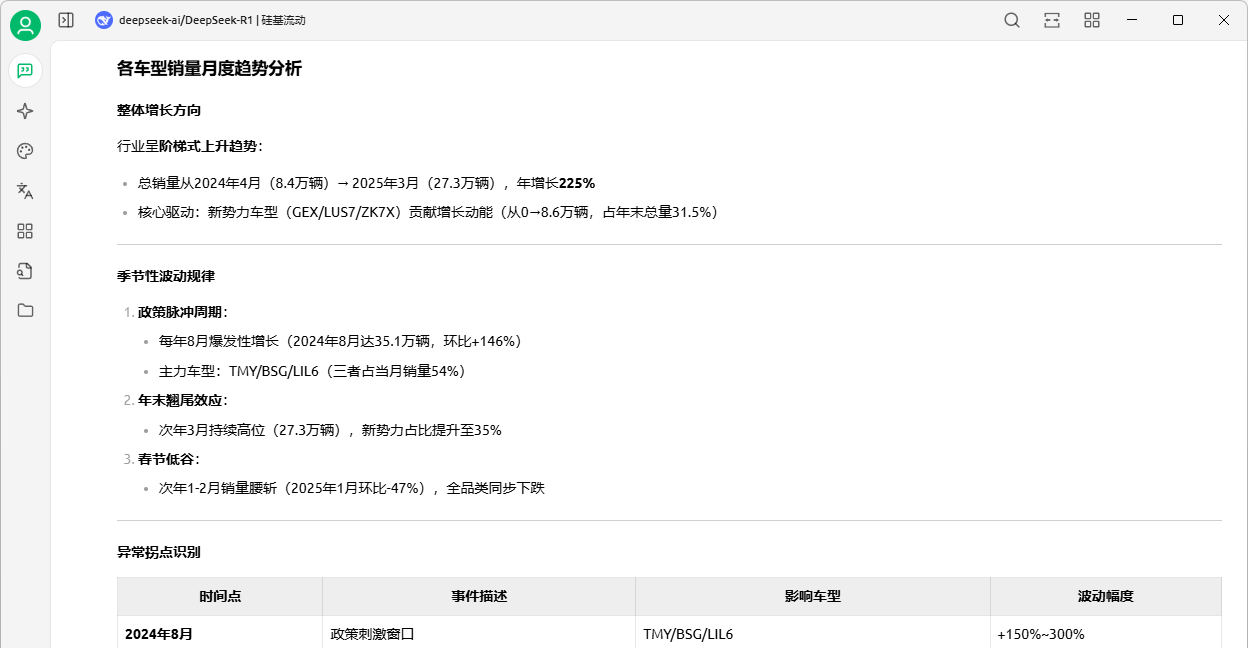
图8-4:使用DeepSeek对数据进行趋势分析
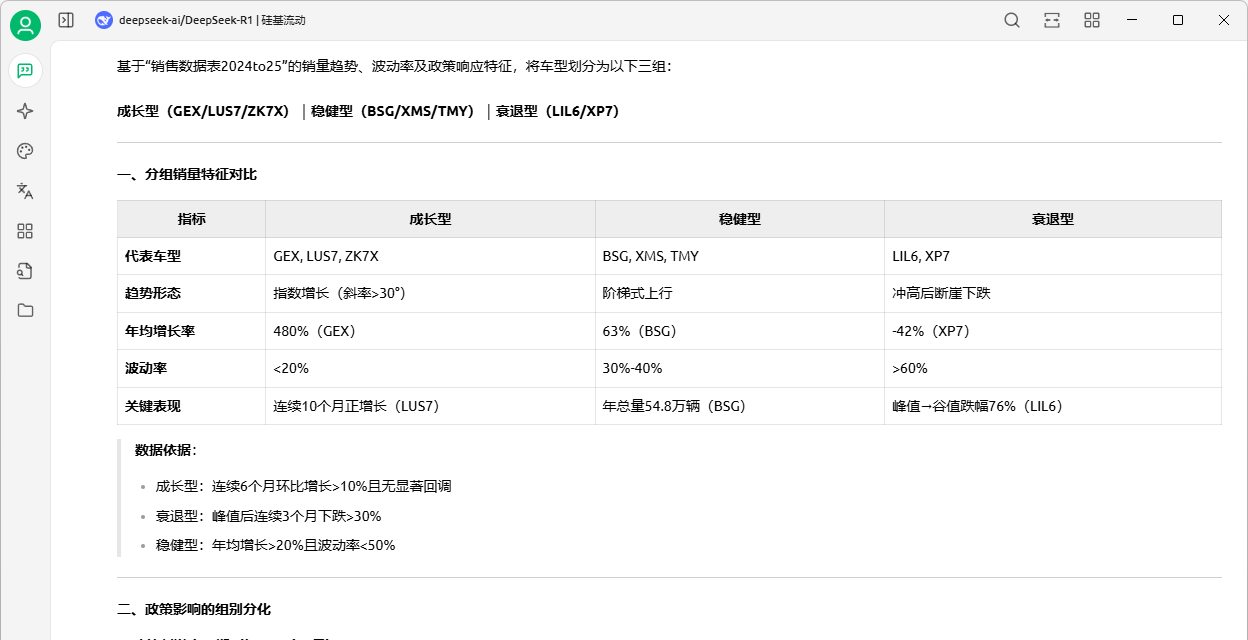
图8-5:使用DeepSeek对数据进行对比分析
对比分析
对比分析是通过将不同类别、时间或区域的数据进行比较,找出其差异与优劣,以支持判断与决策。
对新能源汽车销售数据进行对比分析,向DeepSeek提问的指令示例如下。
【请根据上传文件“销售数据表.csv”,将车型分为成长型、稳健型和衰退型3个组别,对比其销量特征,分析政策、季节对不同组别的影响。】。
如图8-5所示,DeepSeek基于销售数据将车型分组并给出了分组依据,对比分析不同组别的销量特征,政策影响、季节波动的组别分化,还可以给出行动建议。
关联性分析
关联性分析用于发现数据中的隐藏关系,适用于市场购物篮分析、用户行为研究、医学数据挖掘等场景。使用DeepSeek进行关联性分析的典型案例和指令示例如下。
【请根据观察数据分析学习时间、睡眠质量与成绩之间的相关性。】。
【请根据超市交易数据分析顾客购买商品的关联性,找出支持度>0.1、置信度>0.5的关联规则,并用通俗语言解释结果。】。
【请根据数据文件,使用PrefixSpan算法分析用户页面浏览序列的频繁模式,并解释其业务意义。】
因果分析
因果分析用于确定变量间的因果关系(如X是否导致Y?),而不仅是相关性。使用DeepSeek进行因果分析的典型案例和指令示例如下。
【请根据观察数据分析学习时间、睡眠质量与成绩之间的因果关系,并输出因果图。】。
【测试“推荐算法”是否提高在线平台的学生完课率。分析 A/B 测试数据,判断新算法(实验组)是否显著提高完课率(对照组 vs 实验组),计算 ATE(平均处理效应),并检查随机化是否平衡。】。
回归分析
回归分析是用于探究两个或多个变量之间关系的统计方法,常用于预测、趋势建模或因果关系判断。使用DeepSeek进行回归分析的典型案例和指令示例如下。
【用逻辑回归预测学生选课意愿,自变量为:专业相关性、课程口碑、学分难度比和教师知名度,因变量为是否选修该课程。】。
【用多元线性回归分析哪些因素影响学生的成绩,自变量为:基础课成绩、作业平均分、课堂测试成绩、出勤率、每周学习时间、课程难度,因变量为课程期末成绩。】。
【总结回归分析结果,解释每个变量的影响,并就如何提高学生成绩提出建议。】。
数据分析的Python程序
复杂的数据分析往往需要编程实现。DeepSeek能根据需求自动生成代码,快速完成数据清洗、建模和可视化。只要清晰描述问题,DeepSeek即可提供完整的 Python代码和结果解释,大幅提升分析效率,让数据洞察触手可及。
例如,在使用DeepSeek分析影响学生成绩的原因时,指令示例如下。
【用Python语言写一个多元线性回归程序,读取文件math_score_data.xlsx加载数据,分析高等数学成绩的影响因素,自变量包括基础课成绩、作业平均分、课堂测试成绩、出勤率、每周学习时间、课程难度,因变量为课程期末成绩。要求:1、输出回归系数和显著性检验结果,2、检查模型假设。】。
DeepSeek生成的Python程序代码如下。
import pandas as pd
import statsmodels.api as sm
from statsmodels.stats.diagnostic import het_breuschpagan
from statsmodels.stats.outliers_influence import variance_inflation_factor
# 1. 数据加载与预处理
try:
# 从Excel文件读取数据
df = pd.read_excel('math_score_data.xlsx')
# 检查必要的列是否存在
required_columns = ['基础课成绩', '作业平均分', '课堂测试成绩', '出勤率',
'每周学习时间', '课程难度', '期末成绩']
missing_cols = [col for col in required_columns if col not in df.columns]
if missing_cols:
raise ValueError(f"数据文件中缺少必要的列: {missing_cols}")
# 定义自变量和因变量
X = df_clean[['基础课成绩', '作业平均分', '课堂测试成绩',
'出勤率', '每周学习时间', '课程难度']]
y = df_clean['期末成绩']
# 添加常数项(截距)
X = sm.add_constant(X)
# 2. 多元线性回归分析
model = sm.OLS(y, X).fit()
# 输出回归结果
print("\n" + "="*80)
print("回归分析结果:")
print(model.summary())
# 3. 模型假设检查
print("\n" + "="*80)
print("模型假设检查:")
# 3.1 多重共线性检查(VIF)
print("\n方差膨胀因子(VIF):")
vif_data = pd.DataFrame()
vif_data["Variable"] = X.columns[1:] # 排除截距项
vif_data["VIF"] = [variance_inflation_factor(X.values, i)
for i in range(1, X.shape[1])] # 跳过截距项
print(vif_data)
# 3.2 异方差性检查(Breusch-Pagan检验)
print("\nBreusch-Pagan异方差检验:")
bp_test = het_breuschpagan(model.resid, model.model.exog)
print(f"LM统计量: {bp_test[0]:.3f}, p值: {bp_test[1]:.3f}")
print("异方差性解释: p < 0.05 表示存在异方差性")
# 4. 显著变量总结
print("\n" + "="*80)
print("显著影响因素总结 (p < 0.05):")
coef_df = pd.DataFrame({
'Variable': X.columns[1:], # 排除截距项
'Coefficient': model.params[1:],
'P-value': model.pvalues[1:]
})
significant_vars = coef_df[coef_df['P-value'] < 0.05]
if not significant_vars.empty:
print(significant_vars[['Variable', 'Coefficient', 'P-value']])
else:
print("没有发现显著的影响因素")
except FileNotFoundError:
print("错误: 未找到文件 'math_score_data.xlsx'")
except Exception as e:
print(f"发生错误: {str(e)}")8.1.3 解读分析结果
数据分析的方法与结果虽然重要,但真正的价值在于对分析结果的深度解读与应用。例如,为什么这个变量影响显著,如何基于分析结果优化决策。理解统计分析结果背后的逻辑、趋势与潜在含义并不容易,对于非专业背景的普通用户更具挑战。此时,DeepSeek能够用通俗、易懂的语言解释晦涩的分析结果,并结合上下文提出合理建议。
解释统计术语
数据分析涉及很多统计术语,如置信区间、标准差、显著性水平等。DeepSeek 能够把专业的统计结果转化为普通人能理解的日常语言,例如:
1. 置信区间(Confidence Interval):变量的平均值为75,95%置信区间为 [72, 78]。
DeepSeek解释:这意味着我们有95%的把握认为,真实的平均值在72到78之间。也就是说,如果我们重复多次实验,有95%的把握说真实值就落在这个区间。
2. 标准差(Standard Deviation):变量的平均值为80,标准差为2.5。
通俗解释:这表示我们对平均值的估计有一定的不确定性,平均值上下浮动2.5分是常见的误差范围。标准误越小,说明估计越稳定。
3. 显著性差异(Statistical Significance):两组平均成绩差异具有统计显著性(p < 0.05)。
DeepSeek解释:这表示两组成绩之间的差异不是偶然产生的,而是在统计上是可信的,有95%以上的可能性反映了真实差异。
使用DeepSeek解释统计术语的指令:【请解释“学习时间的回归系数为0.5(p<0.01)”的含义。】。DeepSeek解释如下:【回归系数为0.5,表明每增加1小时学习时间,平均成绩会提高0.5分。p值小于0.01,说明这个关系具有高度统计显著性,也就是说结果非常可靠,不太可能是偶然的。通俗解释:学习时间越多,成绩通常越高,这种关系是可信的。】
挖掘隐藏逻辑
数据分析不仅要看到表面的数值变化,更需要深入地发现变量之间的潜在关系、影响路径或行为模式。通过自然语言向DeepSeek提问,可以发现表面数字无法直接揭示的因果关系或解释逻辑,提升分析深度。
1. 从异常结果反推原因。当分析结果不合逻辑时,引导DeepSeek提出可能的解释路径,例如提问如下:【请根据产品销售数据,分析2025年6月销量骤降40%的可能原因。】。
2. 结合外部环境因素推理。当结果变化可能受到外部事件影响时,引导DeepSeek从背景条件出发分析,例如提问如下:【分析就餐数据,请结合背景条件分析外部环境因素。】。
3. 从局部特例中发现规律。观察少数表现特殊的数据点,引导DeepSeek识别隐藏的共性或特性,例如提问如下:【某几位同学成绩远高于平价成绩,请分析其共同特征。】。
4. 对比解释差异与原因。对比不同群体或时间段的数据差异,通过DeepSeek解释可能的原因,揭示深层逻辑,例如提问如下:【请对比A、B车型的销售数据,分析B车型在2025年6月销量骤降的原因。】。
撰写分析报告
在完成数据处理与分析后,经常需要撰写分析报告,描述分析结果和结论。DeepSeek可以自动生成总结,特别适合理解或撰写分析报告。向DeepSeek提问的指令示例如下。
【请根据上传的数据文件“销售数据表.csv”, 生成月度销售报告,包括:1、销售数据概览,2、竞品对比分析,3、关键问题分析,4、行动建议。】。
【请根据整理的问卷统计表,帮我写一段分析总结。】。
【请根据以下数据,整理周会汇报的分析要点。】。
建议后续行动
基于数据分析结果,使用DeepSeek可以提出可能的改进方向或决策建议。这就将数据从“描述分析”上升为“决策支持”,是数据分析真正产生价值的关键步骤。向DeepSeek提问的指令示例如下。
【请根据对用户行为数据的分析,提出三个提升用户活跃度的可执行建议。】。
【请根据对学生反馈的调查结果,提出改进教学内容的具体方法。】。
【请根据对销售数据的分析,提出下个月促销策略的建议。】。
【请根据对异常模式的识别结果,提出有效应对措施。】。
往期回顾:
更多推荐


 29
29 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)