
大模型学习日记之前两周总结
就在今天,我也是成功微调了Qwen模型。这两周的模型部署与微调不涉及到代码部分,所以比较简单,我来总结一下,希望一些细节可以帮助到一些和我一样的大模型小白。在一开始学习大模型时,大家应该都会去B站上找一找教程,而且一般都是通过ollama来部署模型,博主也一样,是从Ollama开始自己的大模型之旅的。Ollama的下载这里就不多赘述,网页上直接搜索就会出现。然后是模型的下载,这个在Ollama网页
就在今天,我也是成功微调了Qwen模型。这两周的模型部署与微调不涉及到代码部分,所以比较简单,我来总结一下,希望一些细节可以帮助到一些和我一样的大模型小白。
1 Ollama本地模型的部署
在一开始学习大模型时,大家应该都会去B站上找一找教程,而且一般都是通过ollama来部署模型,博主也一样,是从Ollama开始自己的大模型之旅的。
Ollama的下载这里就不多赘述,网页上直接搜索就会出现。
然后是模型的下载,这个在Ollama网页里找到model就可以下载你所需要的模型了。(大家根据自己的电脑配置去下载模型,我的电脑显卡是4060的,跑qwen3:8b的模型还是有点勉强)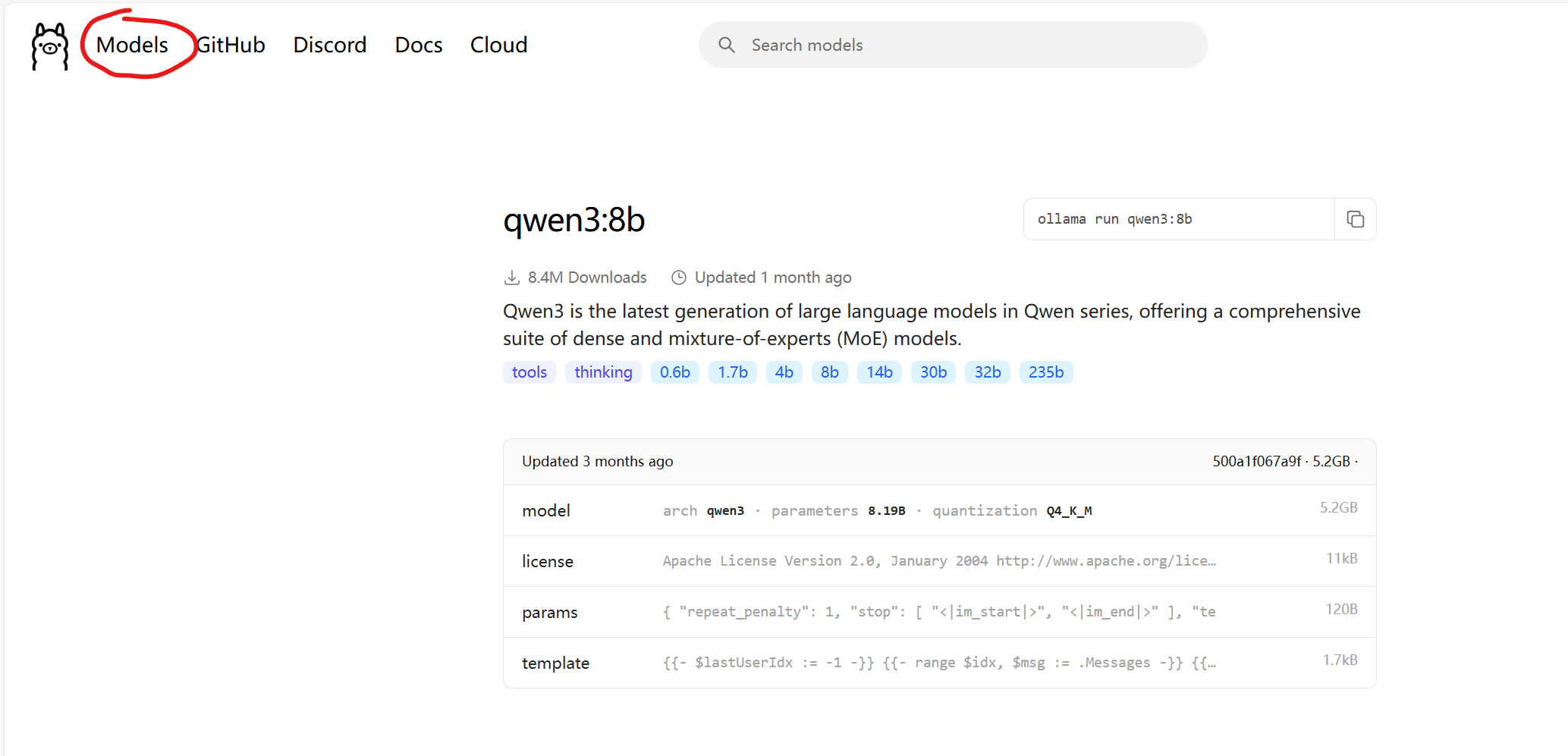
在模型下载结束后,就可以通过cmd运行本地下载的模型啦。首先先按win+r,然后输入cmd,会出现如下图所示的窗口:

然后输入这一行代码就可以运行了,大家根据自己下载的模型去输入相应的代码,我下载的模型是qwen3:8b。
ollama run <model_name>[:tag] [prompt]进行到这一步后可以与你下载的模型进行对话了。
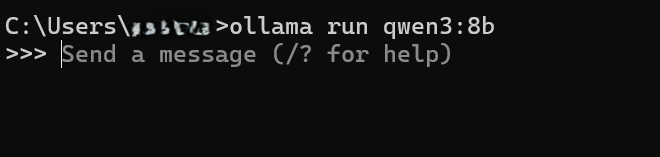
当然,大家也可以在ollama的客户端中去运行本地下载的模型。
2 通过LLama Factory实现模型的微调
这一步因为网上教程的误导导致我在这一步卡了很久,不过通过这个方法并不涉及到代码,还是很好上手的。具体的流程待我细细讲来。
首先,网上有一个教程是通过docker来搭建环境,并通过LLama Factory Webui来实现模型微调的,但是他的那种方法,好像是有错误,我并不能很好地进行微调过程,其中有问题的部分包括但不限于:web ui里没有办法显示数据集,通过modelscope下载下来的模型在本地找不到,无法在web ui中加载模型进行聊天等等。由于这个过程我实在搞不明白,所以这里给出一种更为简单的教程,现在让我来详细说说这一个过程。
这个方法使用conda来搭建环境,所以大家需要先自行下载anaconda等一系列程序。在下载好之后我们就可以开始进行模型的微调了。
2.1 创建一个全新的 Conda 环境
打开我们的Anaconda Prompt 或终端,执行以下命令,创建一个名为 llamafactory_cu12 的新环境(大家也可以取一个自己喜欢的名字),并指定 Python 版本为 3.10(这是 LLaMA Factory 推荐的版本)。
conda create -n llamafactory_cu12 python=3.10在创建完成这个环境后就可以运行这个环境。激活后,大家会看到命令行前面出现了 (llamafactory_cu12 ) 的字样,表示已进入这个隔离的环境。

2.2 在新环境中安装指定 CUDA 版本的 PyTorch
我们要强制 pip 安装为 CUDA 12.1 编译的 PyTorch 版本。执行以下命令:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121虽然LLamafactory推荐的CUDA版本是12.2的,但是12.1也是可以的,因为我下载的12.1版本,所以这里给出12.1的下载命令。下载完成后基本的环境便搭建完成了。
2.3 下载LLamafactory
大家可以前往https://github.com/hiyouga/LLaMA-Factory下载LLamafactory
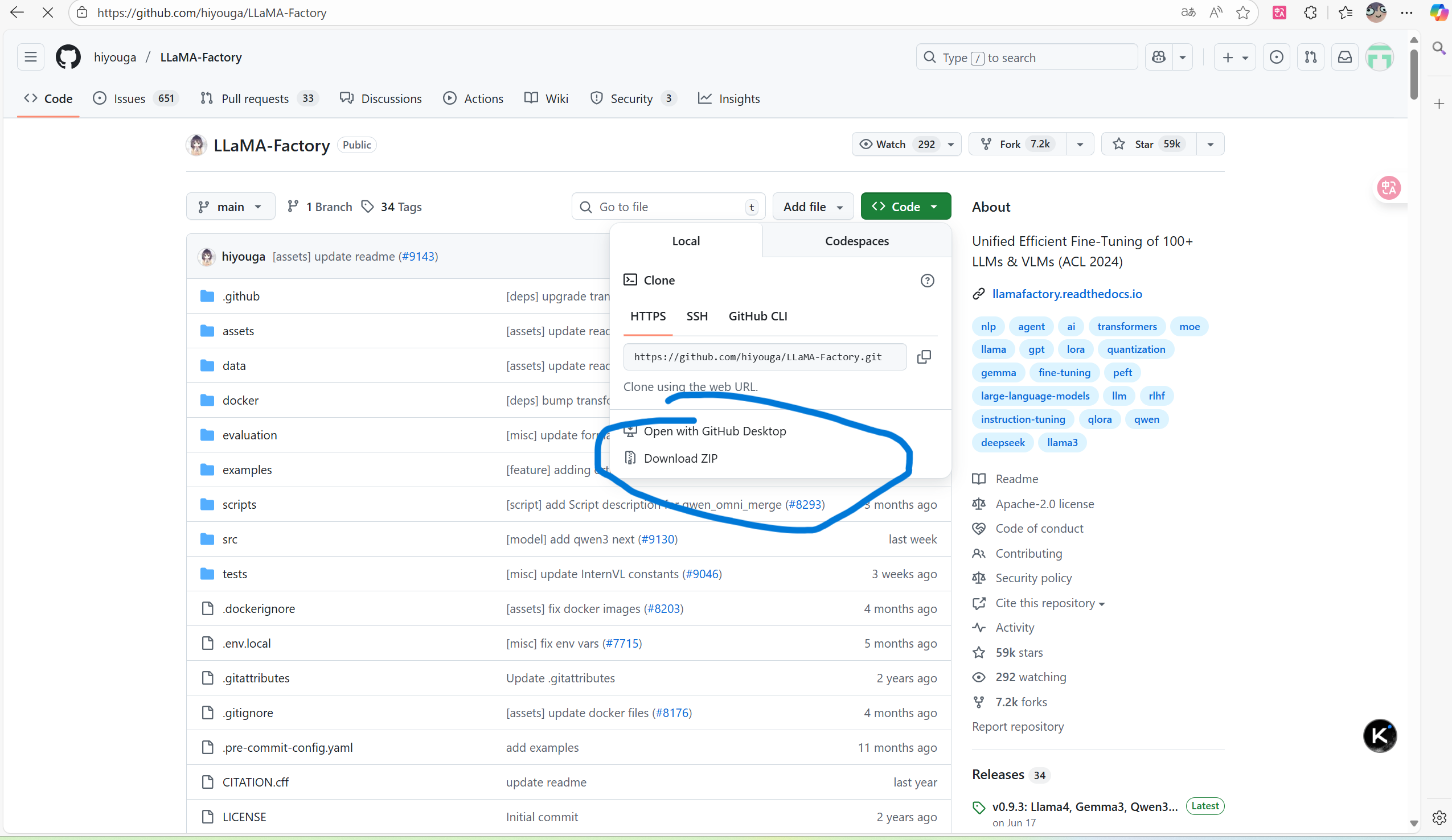
点击download就可以经行下载,然后把文件解压缩到d盘的指定位置(确保自己可以找得到就行)。
下载完成后,我们又可以回到anaconda prompt,用 cd 命令进入您之前下载的 LLaMA-Factory 项目根目录。
# 示例: cd /d D:\projects\LLaMA-Factory然后,在这个配置正确的环境中,重新安装 LLaMA Factory 及其所有依赖,这个过程可能时间会比较长,大家耐心等待,它自动就会下载好。
pip install -e .[torch,bitsandbytes]然后确保仍然在 (llamafactory_cu12) 环境下,输入下面的命令就可以进入Web ui了。
llamafactory-cli webui3 数据集下载与模型微调
3.1 数据集准备
数据集下载这一步是非常核心的环节,微调的效果很大程度上取决于准备的数据集质量。我们这里使用的数据集可以前往魔搭社区进行下载https://www.modelscope.cn/datasets。
我们今天就找一个角色扮演(甄嬛)的数据集来微调。
https://www.modelscope.cn/datasets/kmno4zx/huanhuan-chat
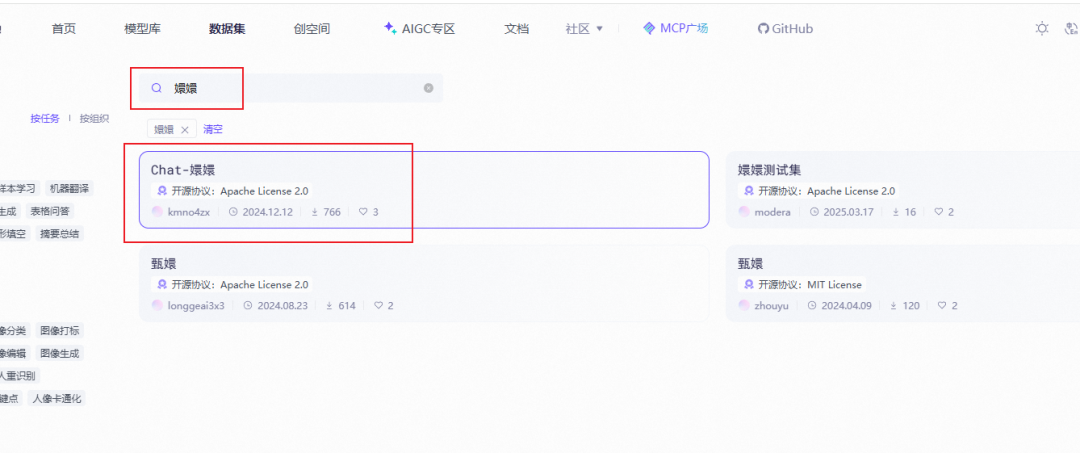 进入该界面后,点击这个数据集,然后点击下载即可。
进入该界面后,点击这个数据集,然后点击下载即可。
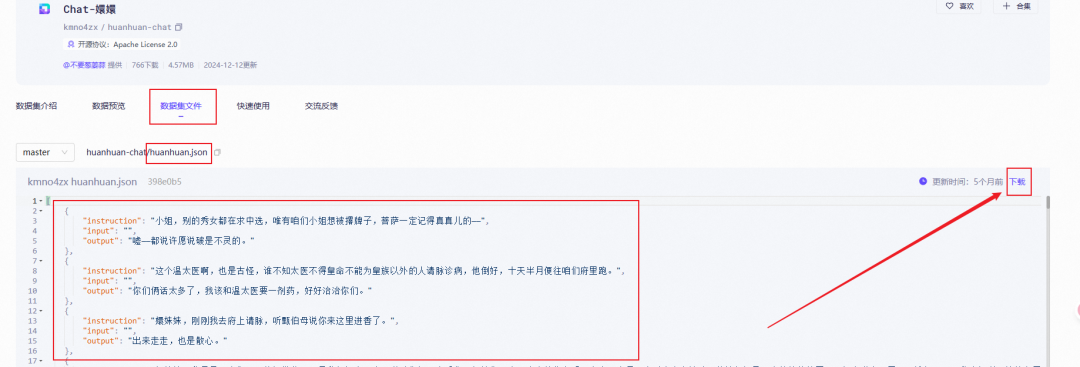
在下载下来后,我们就将这个json文件放入LLamafactory文件夹中的data文件夹。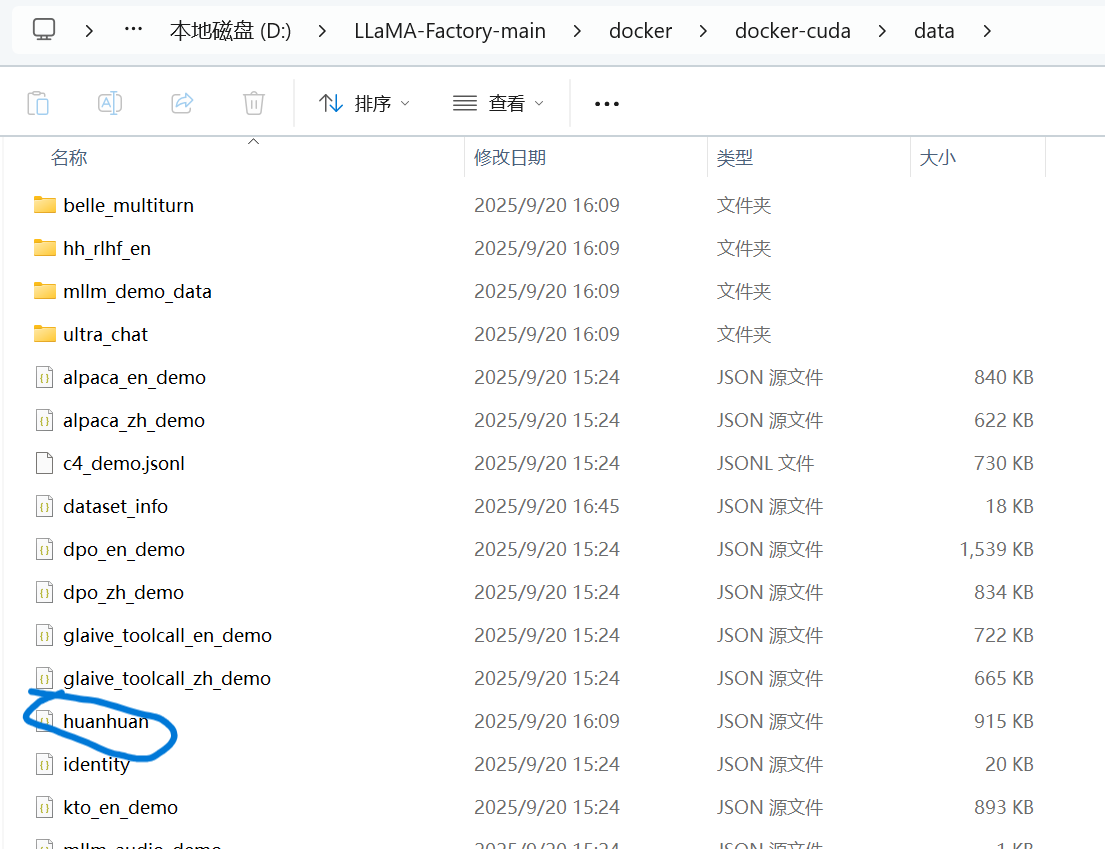
这里需要注意一下,我们需要把data文件复制一份到docker/docker-cuda中,这样往里面放的数据才会在网页上显示出来。由于我也是一个小白,不知道为什么需要进行这一步,但是这也是我在卡了好几天后得出来的结论,大家知道为什么的可以告诉我。
同时我们还需要在配置文件dataset_info.json里面添加一条该数据集的记录。只有这样,数据集才能被LLamafactory识别到。
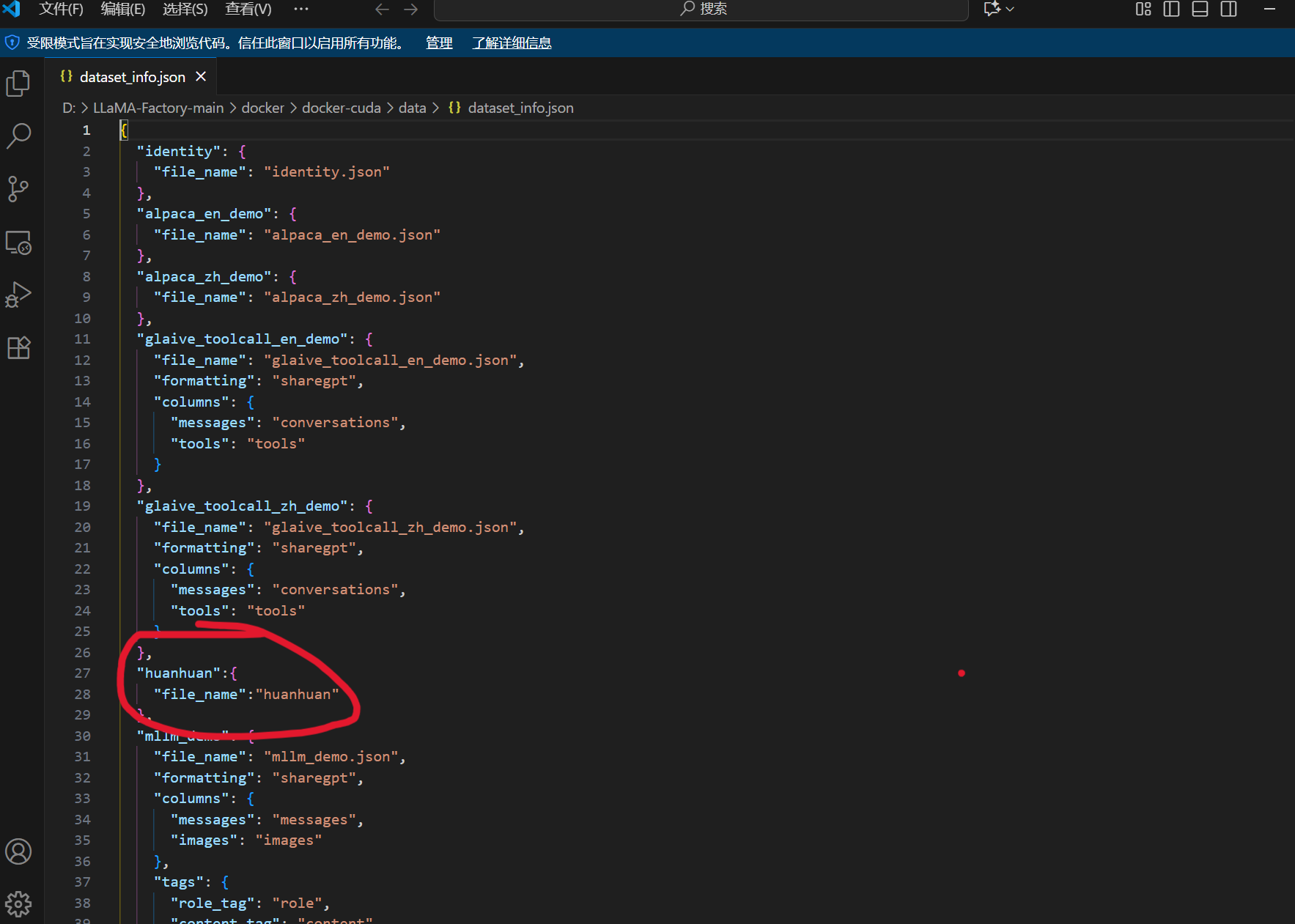
3.2 微调
在完成上述准备工作后,我们终于进入了模型微调部分。
首先进入网页,选择我们需要微调的模型:
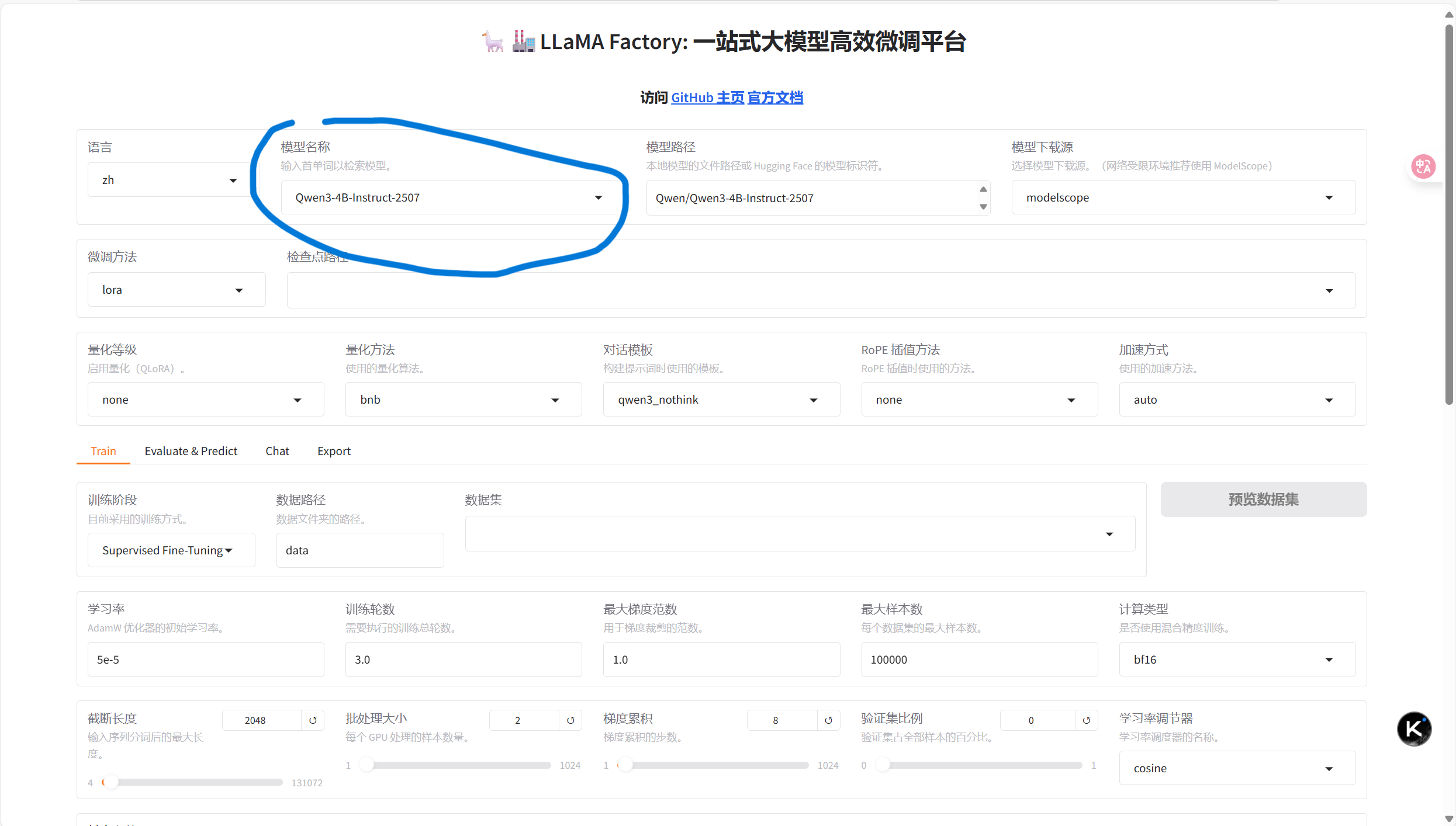
我这里选择了Qwen3-4B-Instruct-2507,instruct模型相对于base模型训练的效果更好。llamafactory会自动检测电脑上是否有相应的模型,如果没有它就会去下载源进行模型的下载。
其他的像微调方式、学习率、梯度累积等使用默认的就可以。比较重要的就是训练轮数,这里还是推荐大家去租一台虚拟机进行训练,不然普通电脑训练一轮就动辄四五个小时,太费时间了。
然后选择我们下载的数据集。
就可以正式开始我们的模型训练啦!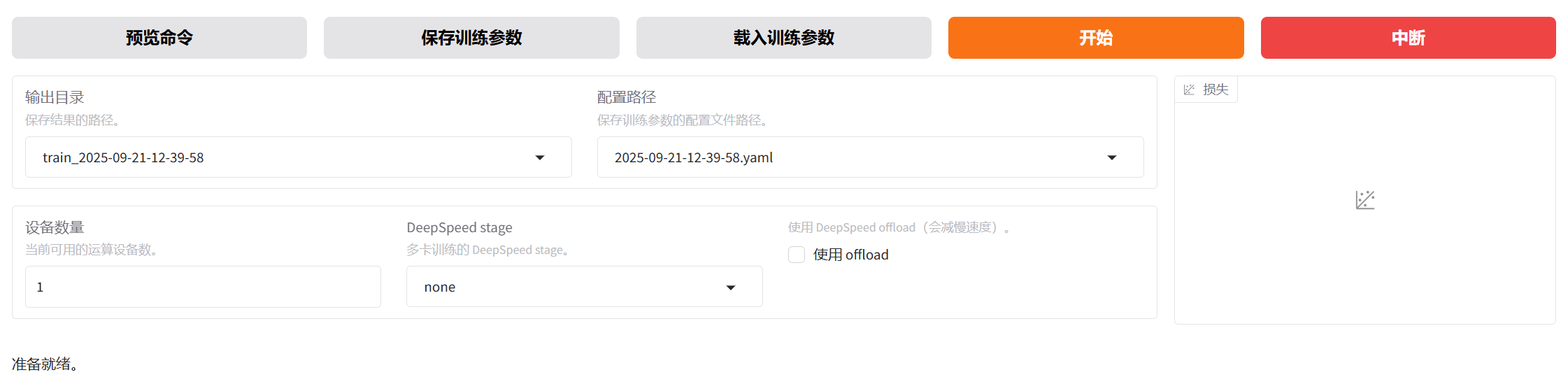
一般过几秒,就会在下面看到日志,橙色的条是进度条,web ui的控制台也可以看到训练进度。只要没有报错即可。
然后就可以将页面切换到chat,并在检查点路径选择我们训练的路径,然后点击加载模型就可以和我们训练好的模型进行聊天了。(下图是引用了https://blog.csdn.net/Libra1313/article/details/149043530这篇文章里的,由于上面我所挑选的是基模型不对,这种基模型训练完不能合并。导致第二次加载模型出现错误,虽然我昨天晚上一训练完的时候还是可以加载的,大家注意就好。刚刚又去查了一下,发现不是基模的问题,而是量化等级和量化方法的问题,大家调一调这个,保持和训练模型时所用的量化等级和方法即可。)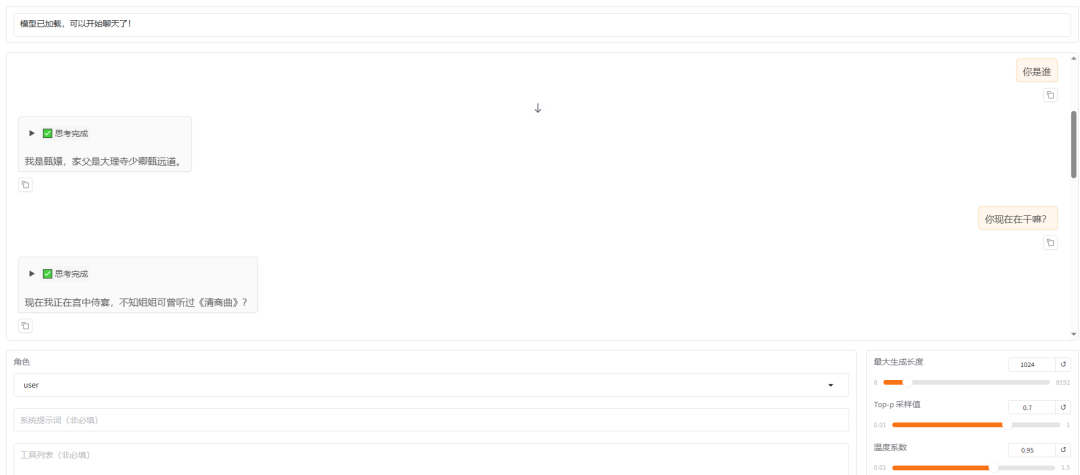
最后就是将模型导出即可。
目前我还在进行学习阶段,还没有开始学习微调后的模型的本地部署,这也是我之后要开始学习的,希望大家可以一起多多交流学习。
引用文章:《3步轻松微调Qwen3,本地电脑就能搞,这个方案可以封神了!》https://blog.csdn.net/Libra1313/article/details/149043530
更多推荐
 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)