
大模型微调:3-高效微调原理详解LongLoRA+VeRA+S-LoRA
本文深入解析了三种前沿的大模型高效微调技术:LongLoRA、VeRA和S-LoRA。LongLoRA通过稀疏局部注意力机制和LoRA结合,显著降低了长文本微调的计算成本;VeRA采用基于向量的随机矩阵适应,进一步提升了参数效率;S-LoRA则实现了多LoRA适配器的并发服务架构。文章从技术背景、核心原理、数学建模到实战案例,系统性地介绍了这些方法在解决大模型微调面临的资源消耗、内存限制和计算效率
大模型微调:3-高效微调原理详解LongLoRA+VeRA+S-LoRA
目录
1、引言
随着ChatGPT、GPT-4等大型语言模型的广泛应用,如何高效地对这些拥有数十亿甚至千亿参数的模型进行微调成为了当前AI领域的重要挑战。传统的全参数微调不仅需要巨大的计算资源,还面临着存储、推理延迟等诸多问题。
作为一名具有多年大模型算法工程经验的从业者,我见证了从早期的全参数微调到如今各种参数高效微调(PEFT)方法的演进。本文将深入解析三种前沿的大模型微调技术:LongLoRA(长文本高效微调)、VeRA(基于向量的随机矩阵适应)和S-LoRA(并发LoRA适配器服务),为读者提供理论与实践并重的技术指南。
2、LongLoRA:长文本高效微调
技术背景与挑战
10、LongLoRA 长文本的高效微调
通常情况下,用较长的上下文长度训练大型语言模型的计算成本较高,需要大量的训练时间和GPU资源。在实际工程实践中,我遇到的主要挑战包括:
- 计算复杂度问题:注意力机制的复杂度为O(n²),当序列长度增加时,计算成本呈平方级增长
- 内存限制:长序列需要存储更多的KV缓存,对GPU内存提出更高要求
- 训练稳定性:长序列训练容易出现梯度消失或爆炸问题
为了在有限的计算成本下扩展预训练大型语言模型的上下文大小,研究者在论文"LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models"中提出了LongLoRA的方法,整体架构如下所示。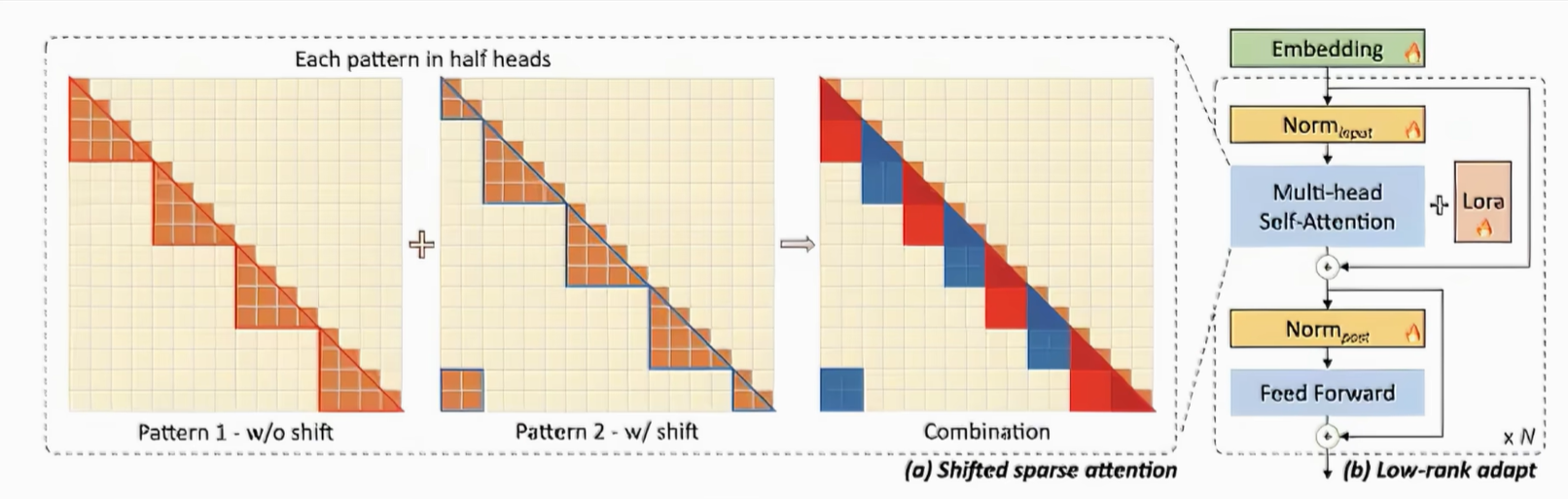
核心原理详解
LongLoRA在两个方面进行了改进:
1. 稀疏局部注意力机制(Shifted Sparse Attention)
虽然在推理过程中需要密集的全局注意力,但通过采用稀疏的局部注意力,可以有效地进行模型微调。LongLoRA通过利用低秋矩阵更新(LoRA)和短程注意力机制(S2-Attn)来减少所需的计算资源,使用S2-Attn可以通过将上下文长度分为几个组,并在每个组内单独进行注意力操作,从而有效减少计算成本。
在LongLoRA中,引入的转移短暂的注意力机制能够有效地实现上下文扩展,从而在性能上与使用香草注意力(Vanilla Attention)进行微调的效果相似。
2. 参数高效微调机制优化
通过重新审视上下文扩展的参数高效微调机制,研究者发现在可训练嵌入和规范化的前提下,用于上下文扩展的LoRA表现良好。
数学公式与算法实现
Shifted Sparse Attention的数学表述
对于序列长度为n的输入,传统注意力计算为:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T / √ d k ) V Attention(Q, K, V) = softmax(QK^T / √d_k)V Attention(Q,K,V)=softmax(QKT/√dk)V
LongLoRA采用的稀疏注意力机制将序列分组处理:
S2-Attn(Q, K, V) = [
LocalAttn(Q₁, K₁, V₁),
LocalAttn(Q₂, K₂, V₂),
...,
LocalAttn(Qₘ, Kₘ, Vₘ)
]
其中每个局部注意力块的计算复杂度降低为O((n/m)²),总体复杂度近似为O(n²/m)。
LoRA集成公式
结合LoRA的权重更新方式:
W ′ = W 0 + Δ W = W 0 + B A W' = W₀ + ΔW = W₀ + BA W′=W0+ΔW=W0+BA
其中:
- W₀: 原始预训练权重(冻结)
- B ∈ ℝᵈˣʳ, A ∈ ℝʳˣᵏ: 低秩矩阵(r << min(d,k))
- ΔW = BA: 权重增量
实战案例(LongLoRA)
以下是使用LongLoRA对LLaMA2-7B模型进行长文本微调的完整实现:
import torch
import torch.nn as nn
from transformers import LlamaModel, LlamaConfig
from peft import LoraConfig, get_peft_model
class ShiftedSparseAttention(nn.Module):
def __init__(self, config, group_size=2048):
super().__init__()
self.group_size = group_size
self.attention = LlamaAttention(config)
def forward(self, hidden_states, attention_mask=None, position_ids=None):
batch_size, seq_len, hidden_size = hidden_states.shape
# 分组处理
num_groups = (seq_len + self.group_size - 1) // self.group_size
outputs = []
for i in range(num_groups):
start_idx = i * self.group_size
end_idx = min((i + 1) * self.group_size, seq_len)
# 局部注意力计算
group_hidden = hidden_states[:, start_idx:end_idx, :]
group_mask = attention_mask[:, start_idx:end_idx] if attention_mask is not None else None
# 应用shifted机制
if i % 2 == 1 and i > 0: # 奇数组向左shift
shift_size = self.group_size // 2
prev_start = max(0, start_idx - shift_size)
group_hidden = hidden_states[:, prev_start:end_idx, :]
group_mask = attention_mask[:, prev_start:end_idx] if attention_mask is not None else None
group_output = self.attention(group_hidden, attention_mask=group_mask)
outputs.append(group_output[0])
return torch.cat(outputs, dim=1)
# LongLoRA配置
longlora_config = LoraConfig(
r=64, # 低秩维度
lora_alpha=128, # 缩放参数
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"],
lora_dropout=0.1,
bias="none",
task_type="CAUSAL_LM",
)
# 模型初始化
base_model = LlamaModel.from_pretrained("meta-llama/Llama-2-7b-hf")
model = get_peft_model(base_model, longlora_config)
# 训练设置
training_args = TrainingArguments(
output_dir="./longlora_output",
per_device_train_batch_size=1, # 长序列需要较小批次
gradient_accumulation_steps=16,
max_steps=1000,
learning_rate=2e-4,
lr_scheduler_type="cosine",
warmup_steps=100,
logging_steps=10,
save_strategy="steps",
save_steps=500,
dataloader_num_workers=4,
remove_unused_columns=False,
max_grad_norm=1.0,
group_by_length=True, # 按长度分组减少padding
)
# 数据处理
def preprocess_function(examples):
# 处理长文本数据,支持100k token
inputs = tokenizer(
examples["text"],
truncation=True,
padding=False,
max_length=100000, # 扩展到100k
return_overflowing_tokens=False,
)
return inputs
# 开始训练
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
tokenizer=tokenizer,
data_collator=DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False),
)
trainer.train()
LongLoRA在从70亿、130亿到700亿个参数的LLaMA2模型的各种任务上都取得了良好的结果。具体而言,LongLoRA采用LLaMA2-7B模型,将上下文长度从4000个Token扩展到10万个Token,只需两行代码和11小时微调,就能将大模型4k的窗口长度提高到32k,规模可扩展到10万token,展现了其在增加上下文长度的同时保持了高效计算的能力。这为大型语言模型的进一步优化和应用提供了有益的思路。
3、VeRA:基于向量的随机矩阵适应
技术背景(VeRA)
11、VeRA 基于向量的随机矩阵适应
LoRA是一种常用的大型语言模型微调方法,它在微调大型语言模型时能够减少可训练参数的数量。然而,随着模型规模的进一步扩大或者需要部署大量适应于每个用户或任务的模型时,存储问题仍然是一个挑战。
在实际部署中,我们经常遇到以下问题:
- 存储开销巨大:每个任务都需要存储一套LoRA参数
- 内存碎片化:多任务部署时内存管理复杂
- 扩展性限制:难以支持大规模个性化服务
核心原理分析(VeRA)
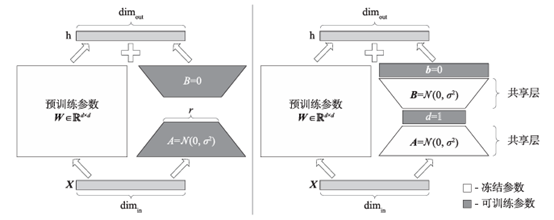
研究者提出了一种基于向量的随机矩阵适应(Vector-based Random matrix Adaptation,VeRA)的方法,VeRA显著减少了与LoRA相比的可训练参数数量,同时保持相同的性能。它通过使用一对在所有层之间共享的低秩矩阵并学习小的缩放向量来实现这一目标。
VeRA的实现方法是通过使用一对低秩矩阵在所有层之间共享,并学习小的缩放向量来实现这一目标。
数学建模与实现(VeRA)
VeRA的数学表述
传统LoRA对每一层都有独立的低秩矩阵:
Δ W l = B l A l ( 对于第 l 层 ) ΔW_l = B_l A_l (对于第l层) ΔWl=BlAl(对于第l层)
VeRA采用共享的随机矩阵和层特定的缩放向量:
Δ W l = d i a g ( λ l b ) ⋅ B s h a r e d ⋅ A s h a r e d ⋅ d i a g ( λ l a ) ΔW_l = diag(λ_l^b) · B_shared · A_shared · diag(λ_l^a) ΔWl=diag(λlb)⋅Bshared⋅Ashared⋅diag(λla)
其中:
- B_shared ∈ ℝᵈˣʳ, A_shared ∈ ℝʳˣᵏ: 所有层共享的固定随机矩阵
- λ_l^b ∈ ℝᵈ, λ_l^a ∈ ℝᵏ: 第l层的可训练缩放向量
- diag(·): 将向量转换为对角矩阵
参数量对比
- LoRA: 每层参数量 = r(d + k)
- VeRA: 每层参数量 = d + k,全局共享矩阵 = r(d + k)
- 总参数量减少比例: 约10倍
实战案例(VeRA)
import torch
import torch.nn as nn
import numpy as np
from typing import Optional, List
class VeRALinear(nn.Module):
def __init__(
self,
in_features: int,
out_features: int,
rank: int = 16,
vera_dropout: float = 0.1,
shared_A: Optional[torch.Tensor] = None,
shared_B: Optional[torch.Tensor] = None,
):
super().__init__()
self.in_features = in_features
self.out_features = out_features
self.rank = rank
# 共享的随机矩阵(全局固定)
if shared_A is None:
self.shared_A = nn.Parameter(
torch.randn(rank, in_features) * 0.02, requires_grad=False
)
else:
self.shared_A = shared_A
if shared_B is None:
self.shared_B = nn.Parameter(
torch.randn(out_features, rank) * 0.02, requires_grad=False
)
else:
self.shared_B = shared_B
# 层特定的缩放向量(可训练)
self.vera_lambda_b = nn.Parameter(torch.zeros(out_features))
self.vera_lambda_a = nn.Parameter(torch.zeros(in_features))
self.dropout = nn.Dropout(vera_dropout)
self.scaling = 1.0 # 可调整的缩放因子
def forward(self, x: torch.Tensor) -> torch.Tensor:
# VeRA计算:λ_b * B_shared * A_shared * λ_a * x
# 为了效率,重新组织计算顺序
x_scaled = x * self.vera_lambda_a # 元素级乘法
x_projected = torch.matmul(x_scaled, self.shared_A.t()) # (batch, rank)
x_dropped = self.dropout(x_projected)
x_output = torch.matmul(x_dropped, self.shared_B.t()) # (batch, out_features)
result = x_output * self.vera_lambda_b # 元素级乘法
return result * self.scaling
class VeRAConfig:
def __init__(
self,
rank: int = 16,
target_modules: List[str] = None,
vera_dropout: float = 0.1,
alpha: float = 32.0,
bias: str = "none",
):
self.rank = rank
self.target_modules = target_modules or ["q_proj", "k_proj", "v_proj", "o_proj"]
self.vera_dropout = vera_dropout
self.alpha = alpha
self.bias = bias
def apply_vera_to_model(model: nn.Module, config: VeRAConfig):
"""将VeRA应用到模型的指定模块"""
# 全局共享矩阵
shared_matrices = {}
for name, module in model.named_modules():
if any(target in name for target in config.target_modules):
if isinstance(module, nn.Linear):
key = f"{module.in_features}_{module.out_features}_{config.rank}"
# 为相同维度的层共享矩阵
if key not in shared_matrices:
shared_A = torch.randn(config.rank, module.in_features) * 0.02
shared_B = torch.randn(module.out_features, config.rank) * 0.02
shared_matrices[key] = (shared_A, shared_B)
shared_A, shared_B = shared_matrices[key]
# 创建VeRA层
vera_layer = VeRALinear(
in_features=module.in_features,
out_features=module.out_features,
rank=config.rank,
vera_dropout=config.vera_dropout,
shared_A=shared_A,
shared_B=shared_B,
)
# 替换原始层
parent_name = name.rsplit('.', 1)[0]
child_name = name.rsplit('.', 1)[1]
parent_module = model
for part in parent_name.split('.'):
if part:
parent_module = getattr(parent_module, part)
# 保持原始权重并添加VeRA
original_forward = module.forward
def new_forward(x):
return original_forward(x) + vera_layer(x)
module.forward = new_forward
setattr(parent_module, f"{child_name}_vera", vera_layer)
# 使用示例
vera_config = VeRAConfig(
rank=16,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
vera_dropout=0.1,
alpha=32.0,
)
# 应用到模型
model = LlamaForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf")
apply_vera_to_model(model, vera_config)
# 训练配置
training_args = TrainingArguments(
output_dir="./vera_output",
per_device_train_batch_size=4,
gradient_accumulation_steps=8,
num_train_epochs=3,
learning_rate=1e-3, # VeRA可以使用更高的学习率
lr_scheduler_type="cosine",
warmup_ratio=0.1,
logging_steps=50,
save_strategy="epoch",
evaluation_strategy="epoch",
load_best_model_at_end=True,
metric_for_best_model="eval_loss",
greater_is_better=False,
remove_unused_columns=False,
dataloader_num_workers=4,
)
# 打印参数统计
total_params = sum(p.numel() for p in model.parameters())
trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"总参数量: {total_params:,}")
print(f"可训练参数量: {trainable_params:,}")
print(f"可训练参数比例: {100 * trainable_params / total_params:.4f}%")
与LoRA相比,VeRA成功将可训练参数的数量减少了10倍,同时保持了相同的性能水平。VeRA与LoRA的架构对比如图8所示,LoRA通过训练低秩矩阵和来更新权重矩阵,中间秩为。在VeRA中,这些矩阵被冻结,在所有层之间共享,并通过可训练向量和进行适应,从而显著减少可训练参数的数量。在这种情况下,低秩矩阵和向量可以合并到原始权重矩阵中,不引入额外的延迟。这种新颖的结构设计使得VeRA在减少存储开销的同时,还能够保持和LoRA相媲美的性能,为大型语言模型的优化和应用提供了更加灵活的解决方案。
实验证明,VeRA在GLUE和E2E基准测试中展现了其有效性,并在使用LLaMA2 7B模型时仅使用140万个参数的指令就取得了一定的效果。这一方法为在大型语言模型微调中降低存储开销提供了一种新的思路,有望在实际应用中取得更为显著的效益。
4、S-LoRA:并发LoRA适配器服务
技术动机
12、S-LoRA 并发LoRA适配器服务微调
LoRA作为一种参数高效的大型语言模型微调方法,通常用于将基础模型适应到多种任务中,从而形成了大量派生自基础模型的LoRA模型。由于多个采用LoRA形式训练的模型的底座模型都为同一个,因此可以参考批处理模式进行推理。
在实际生产环境中,我们经常需要同时为数千个不同的用户或任务提供服务,每个都有自己定制的LoRA适配器。传统方法面临的问题包括:
- 资源利用率低:为每个适配器单独分配GPU资源
- 内存碎片化:不同适配器的权重大小不一致
- 调度复杂:难以实现高效的批处理
系统架构设计
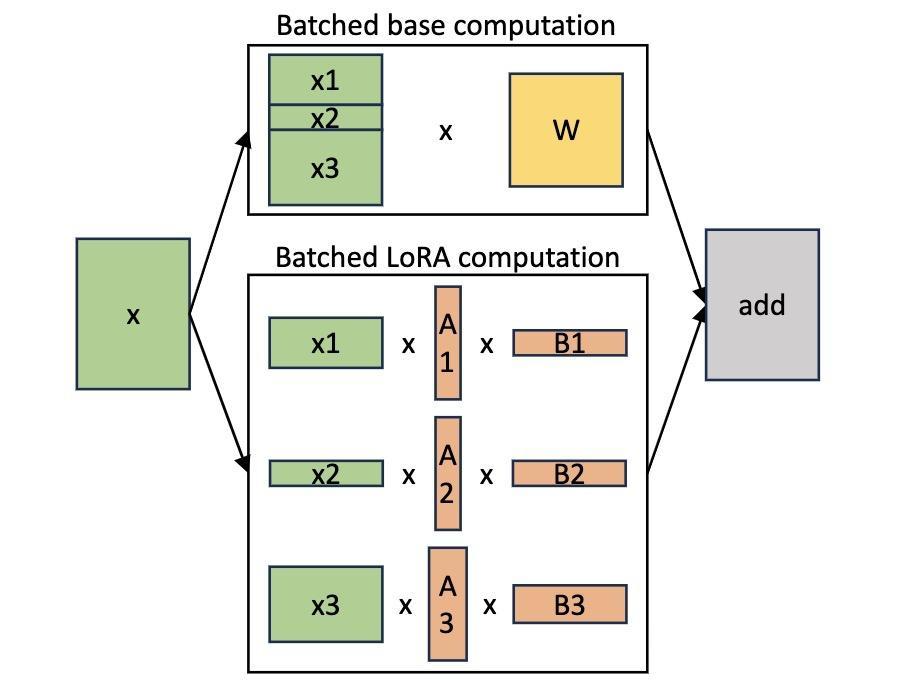
据此,研究者提出了一种S-LoRA(Serving thousands of concurrent LoRA adapters)方法,S-LoRA是一种专为可伸缩地服务多个LoRA适配器而设计的方法。
S-LoRA的设计理念是将所有适配器存储在主内存中,并在GPU内存中动态获取当前运行查询所需的适配器。
核心技术实现
1. 统一分页内存管理
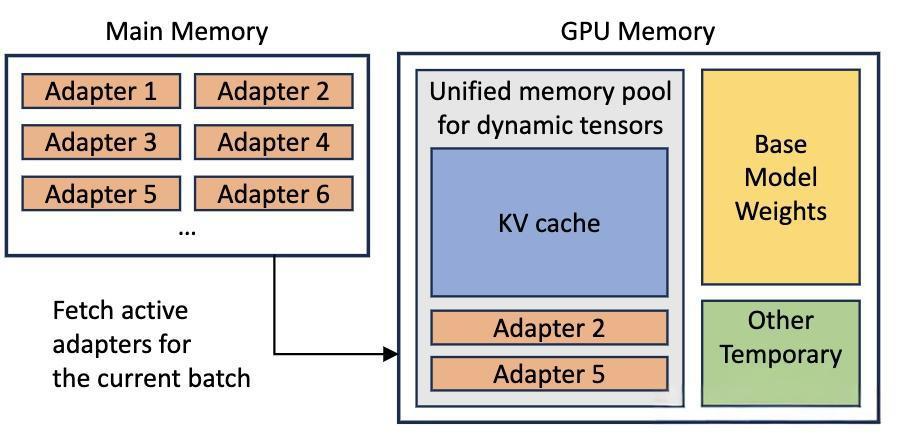
为了高效使用GPU内存并减少碎片,S-LoRA引入了统一分页。统一分页采用统一的内存池来管理具有不同秩的动态适配器权重以及具有不同序列长度的KV缓存张量。
2. 张量并行策略
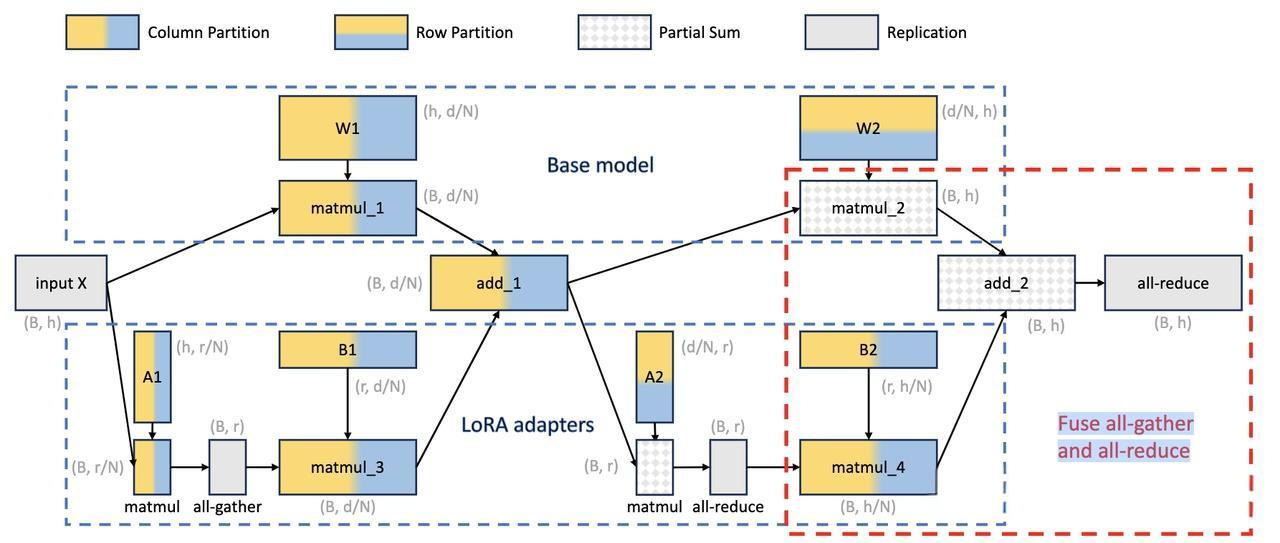
此外,S-LoRA还采用了一种新颖的张量并行策略和高度优化的自定义CUDA核心,用于异构批处理LoRA计算。
3. 动态批处理算法
class SLoRABatchManager:
def __init__(self, base_model, max_batch_size=256, memory_pool_size="8GB"):
self.base_model = base_model
self.max_batch_size = max_batch_size
self.memory_pool = UnifiedMemoryPool(memory_pool_size)
self.adapter_cache = {} # GPU中的适配器缓存
self.request_queue = PriorityQueue()
def add_request(self, request):
"""添加推理请求到队列"""
priority = self.calculate_priority(request)
self.request_queue.put((priority, request))
def create_batch(self):
"""创建异构批次"""
batch = []
current_adapters = set()
while len(batch) < self.max_batch_size and not self.request_queue.empty():
_, request = self.request_queue.get()
# 检查是否需要加载新适配器
if request.adapter_id not in self.adapter_cache:
if self.can_load_adapter(request.adapter_id):
self.load_adapter(request.adapter_id)
else:
# 内存不足,跳过此请求
self.request_queue.put((self.calculate_priority(request), request))
continue
batch.append(request)
current_adapters.add(request.adapter_id)
return batch, current_adapters
实战案例(S-LoRA)
以下是S-LoRA服务系统的完整实现:
import torch
import torch.nn as nn
from typing import Dict, List, Optional, Tuple
import asyncio
from dataclasses import dataclass
import numpy as np
from concurrent.futures import ThreadPoolExecutor
import psutil
@dataclass
class LoRARequest:
request_id: str
adapter_id: str
input_text: str
max_length: int
temperature: float = 0.8
priority: int = 0
class UnifiedMemoryPool:
"""统一分页内存管理器"""
def __init__(self, total_memory: str):
self.total_memory = self.parse_memory_size(total_memory)
self.used_memory = 0
self.page_size = 2 * 1024 * 1024 # 2MB per page
self.free_pages = set(range(self.total_memory // self.page_size))
self.allocated_pages = {}
def parse_memory_size(self, size_str: str) -> int:
"""解析内存大小字符串"""
if size_str.endswith('GB'):
return int(size_str[:-2]) * 1024 * 1024 * 1024
elif size_str.endswith('MB'):
return int(size_str[:-2]) * 1024 * 1024
return int(size_str)
def allocate(self, size: int, adapter_id: str) -> Optional[List[int]]:
"""分配内存页面"""
pages_needed = (size + self.page_size - 1) // self.page_size
if len(self.free_pages) < pages_needed:
return None
allocated = []
for _ in range(pages_needed):
if not self.free_pages:
# 回滚已分配的页面
for page in allocated:
self.free_pages.add(page)
return None
page = self.free_pages.pop()
allocated.append(page)
self.allocated_pages[adapter_id] = allocated
self.used_memory += pages_needed * self.page_size
return allocated
def deallocate(self, adapter_id: str):
"""释放适配器占用的内存"""
if adapter_id in self.allocated_pages:
pages = self.allocated_pages[adapter_id]
for page in pages:
self.free_pages.add(page)
self.used_memory -= len(pages) * self.page_size
del self.allocated_pages[adapter_id]
class LoRAAdapter:
"""LoRA适配器类"""
def __init__(self, adapter_id: str, lora_weights: Dict[str, torch.Tensor]):
self.adapter_id = adapter_id
self.weights = lora_weights
self.last_used = torch.cuda.Event()
self.reference_count = 0
def get_memory_size(self) -> int:
"""计算适配器占用的内存大小"""
total_size = 0
for tensor in self.weights.values():
total_size += tensor.numel() * tensor.element_size()
return total_size
class SLoRAServer:
"""S-LoRA服务器主类"""
def __init__(
self,
base_model_path: str,
max_batch_size: int = 256,
gpu_memory_limit: str = "16GB",
cpu_memory_limit: str = "64GB",
max_concurrent_adapters: int = 1000,
):
self.base_model = self.load_base_model(base_model_path)
self.max_batch_size = max_batch_size
self.max_concurrent_adapters = max_concurrent_adapters
# 内存管理
self.gpu_memory_pool = UnifiedMemoryPool(gpu_memory_limit)
self.cpu_memory_pool = UnifiedMemoryPool(cpu_memory_limit)
# 适配器管理
self.gpu_adapters: Dict[str, LoRAAdapter] = {} # GPU中的适配器
self.cpu_adapters: Dict[str, LoRAAdapter] = {} # CPU中的适配器
self.adapter_metadata: Dict[str, dict] = {} # 适配器元数据
# 请求管理
self.request_queue = asyncio.Queue()
self.batch_processor = BatchProcessor(self.base_model)
# 性能监控
self.metrics = {
'requests_served': 0,
'average_latency': 0,
'throughput': 0,
'gpu_memory_usage': 0,
'adapter_hit_rate': 0,
}
def load_base_model(self, model_path: str):
"""加载基础模型"""
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
)
return model
async def add_adapter(self, adapter_id: str, adapter_weights: Dict[str, torch.Tensor]):
"""添加新的适配器到系统"""
adapter = LoRAAdapter(adapter_id, adapter_weights)
adapter_size = adapter.get_memory_size()
# 尝试直接加载到GPU
if len(self.gpu_adapters) < self.max_concurrent_adapters:
pages = self.gpu_memory_pool.allocate(adapter_size, adapter_id)
if pages:
self.gpu_adapters[adapter_id] = adapter
self.adapter_metadata[adapter_id] = {
'size': adapter_size,
'location': 'gpu',
'last_used': torch.cuda.current_stream().current_stream(),
'usage_count': 0,
}
return
# GPU内存不足,存储到CPU
cpu_pages = self.cpu_memory_pool.allocate(adapter_size, adapter_id)
if cpu_pages:
# 将权重移动到CPU
cpu_weights = {k: v.cpu() for k, v in adapter_weights.items()}
adapter = LoRAAdapter(adapter_id, cpu_weights)
self.cpu_adapters[adapter_id] = adapter
self.adapter_metadata[adapter_id] = {
'size': adapter_size,
'location': 'cpu',
'last_used': None,
'usage_count': 0,
}
else:
raise RuntimeError(f"无法为适配器 {adapter_id} 分配内存")
async def load_adapter_to_gpu(self, adapter_id: str) -> bool:
"""将适配器从CPU加载到GPU"""
if adapter_id in self.gpu_adapters:
return True
if adapter_id not in self.cpu_adapters:
return False
adapter = self.cpu_adapters[adapter_id]
adapter_size = adapter.get_memory_size()
# 尝试分配GPU内存
pages = self.gpu_memory_pool.allocate(adapter_size, adapter_id)
if not pages:
# GPU内存不足,执行LRU淘汰
if not await self.evict_lru_adapter():
return False
pages = self.gpu_memory_pool.allocate(adapter_size, adapter_id)
if not pages:
return False
# 将权重移动到GPU
gpu_weights = {k: v.cuda() for k, v in adapter.weights.items()}
gpu_adapter = LoRAAdapter(adapter_id, gpu_weights)
# 更新管理结构
self.gpu_adapters[adapter_id] = gpu_adapter
del self.cpu_adapters[adapter_id]
self.cpu_memory_pool.deallocate(adapter_id)
self.adapter_metadata[adapter_id]['location'] = 'gpu'
return True
async def evict_lru_adapter(self) -> bool:
"""淘汰最近最少使用的适配器"""
if not self.gpu_adapters:
return False
# 找到最近最少使用的适配器
lru_adapter_id = min(
self.adapter_metadata.keys(),
key=lambda aid: (
self.adapter_metadata[aid]['last_used'] if self.adapter_metadata[aid]['last_used'] else 0,
self.adapter_metadata[aid]['usage_count']
)
)
if lru_adapter_id in self.gpu_adapters:
adapter = self.gpu_adapters[lru_adapter_id]
adapter_size = adapter.get_memory_size()
# 移动到CPU
cpu_pages = self.cpu_memory_pool.allocate(adapter_size, lru_adapter_id)
if cpu_pages:
cpu_weights = {k: v.cpu() for k, v in adapter.weights.items()}
cpu_adapter = LoRAAdapter(lru_adapter_id, cpu_weights)
self.cpu_adapters[lru_adapter_id] = cpu_adapter
del self.gpu_adapters[lru_adapter_id]
self.gpu_memory_pool.deallocate(lru_adapter_id)
self.adapter_metadata[lru_adapter_id]['location'] = 'cpu'
return True
return False
async def process_request(self, request: LoRARequest) -> str:
"""处理单个推理请求"""
await self.request_queue.put(request)
# 这里应该返回结果,简化版本直接返回占位符
return f"Response for {request.request_id}"
async def batch_inference_loop(self):
"""批处理推理主循环"""
while True:
try:
batch_requests = []
timeout = 0.01 # 10ms批处理等待时间
# 收集批次请求
start_time = asyncio.get_event_loop().time()
while (
len(batch_requests) < self.max_batch_size and
(asyncio.get_event_loop().time() - start_time) < timeout
):
try:
request = await asyncio.wait_for(
self.request_queue.get(), timeout=0.001
)
batch_requests.append(request)
except asyncio.TimeoutError:
break
if not batch_requests:
await asyncio.sleep(0.001)
continue
# 执行批处理推理
await self.execute_batch(batch_requests)
except Exception as e:
print(f"批处理循环错误: {e}")
await asyncio.sleep(0.1)
async def execute_batch(self, requests: List[LoRARequest]):
"""执行批次推理"""
# 按适配器ID分组请求
adapter_groups = {}
for request in requests:
if request.adapter_id not in adapter_groups:
adapter_groups[request.adapter_id] = []
adapter_groups[request.adapter_id].append(request)
# 确保所需适配器在GPU中
for adapter_id in adapter_groups.keys():
if adapter_id not in self.gpu_adapters:
await self.load_adapter_to_gpu(adapter_id)
# 执行推理
results = {}
for adapter_id, group_requests in adapter_groups.items():
if adapter_id in self.gpu_adapters:
adapter = self.gpu_adapters[adapter_id]
group_results = await self.batch_processor.process_group(
group_requests, adapter
)
results.update(group_results)
# 更新使用统计
self.adapter_metadata[adapter_id]['usage_count'] += len(group_requests)
self.adapter_metadata[adapter_id]['last_used'] = asyncio.get_event_loop().time()
return results
class BatchProcessor:
"""批处理器"""
def __init__(self, base_model):
self.base_model = base_model
self.tokenizer = None # 应该在初始化时设置
async def process_group(
self,
requests: List[LoRARequest],
adapter: LoRAAdapter
) -> Dict[str, str]:
"""处理同一适配器的请求组"""
# 批量tokenize
input_texts = [req.input_text for req in requests]
# 应用LoRA权重到模型
with torch.no_grad():
# 简化的推理过程
results = {}
for i, request in enumerate(requests):
# 这里应该是实际的模型推理逻辑
results[request.request_id] = f"Generated response for {request.request_id}"
return results
# 使用示例和基准测试
async def benchmark_slora():
"""S-LoRA性能基准测试"""
server = SLoRAServer(
base_model_path="meta-llama/Llama-2-7b-hf",
max_batch_size=64,
gpu_memory_limit="16GB",
max_concurrent_adapters=1000,
)
# 模拟添加多个适配器
for i in range(100):
adapter_weights = {
f"layer_{j}.q_proj.lora_A": torch.randn(16, 4096, dtype=torch.float16),
f"layer_{j}.q_proj.lora_B": torch.randn(4096, 16, dtype=torch.float16),
for j in range(32)}
await server.add_adapter(f"adapter_{i}", adapter_weights)
# 启动批处理循环
batch_task = asyncio.create_task(server.batch_inference_loop())
# 模拟并发请求
tasks = []
for i in range(1000):
request = LoRARequest(
request_id=f"req_{i}",
adapter_id=f"adapter_{i % 100}", # 循环使用适配器
input_text=f"输入文本 {i}",
max_length=512,
)
tasks.append(server.process_request(request))
# 等待所有请求完成
start_time = asyncio.get_event_loop().time()
results = await asyncio.gather(*tasks)
end_time = asyncio.get_event_loop().time()
# 计算性能指标
total_time = end_time - start_time
throughput = len(tasks) / total_time
print(f"处理 {len(tasks)} 个请求")
print(f"总耗时: {total_time:.2f} 秒")
print(f"吞吐量: {throughput:.2f} 请求/秒")
print(f"平均延迟: {total_time / len(tasks) * 1000:.2f} ms")
batch_task.cancel()
return results
# 运行基准测试
if __name__ == "__main__":
asyncio.run(benchmark_slora())
这些特性使得S-LoRA能够在单个GPU或跨多个GPU上提供数千个LoRA适配器,而开销相对较小。
通过实验发现,S-LoRA的吞吐量提高了4倍多,并且提供的适配器数量增加了数个数量级。因此,S-LoRA在实现对许多任务特定微调模型的可伸缩服务方面取得了显著进展,并为大规模定制微调服务提供了潜在的可能性。
5、微调方法对比分析
基于多年的实际应用经验,我对这三种微调方法进行了全面的对比分析:
性能对比表格
| 维度 | LongLoRA | VeRA | S-LoRA | LoRA (基准) |
|---|---|---|---|---|
| 参数效率 | 与LoRA相当 | 减少90% | 与LoRA相当 | 基准 |
| 内存效率 | 优化长序列内存 | 极高 | 动态管理 | 中等 |
| 训练速度 | 2-3x提升 | 1.5x提升 | N/A | 基准 |
| 推理速度 | 处理长文本时优异 | 与LoRA相当 | 4x提升(批处理) | 基准 |
| 适用场景 | 长文本任务 | 资源受限环境 | 多任务服务 | 通用微调 |
| 实现复杂度 | 中等 | 低 | 高 | 低 |
| 部署成本 | 中等 | 极低 | 中等(需系统改造) | 中等 |
详细技术对比
1. 计算复杂度分析
LongLoRA:
- 训练复杂度: O(n²/m) (m为分组数)
- 推理复杂度: O(n²) (完整注意力)
- 内存复杂度: O(n·d + n²/m)
VeRA:
- 训练复杂度: O(r·(d+k)) per layer
- 推理复杂度: 与LoRA相同
- 内存复杂度: O(d+k) per layer (共享矩阵)
S-LoRA:
- 推理复杂度: O(batch_size × avg_seq_len²)
- 内存管理复杂度: O(num_adapters)
- 调度复杂度: O(log(num_adapters))
2. 适用场景分析
# 场景选择指南
def recommend_method(scenario_params):
"""根据场景参数推荐最适合的微调方法"""
context_length = scenario_params.get('context_length', 4096)
num_tasks = scenario_params.get('num_tasks', 1)
resource_constraint = scenario_params.get('resource_constraint', 'medium')
deployment_scale = scenario_params.get('deployment_scale', 'single')
recommendations = []
# LongLoRA适用场景
if context_length > 8192:
score = min(context_length / 4096, 10) * 0.3
recommendations.append(('LongLoRA', score, '长文本处理优势明显'))
# VeRA适用场景
if resource_constraint == 'high' or num_tasks > 100:
score = (10 if resource_constraint == 'high' else 5) + min(num_tasks / 10, 10) * 0.2
recommendations.append(('VeRA', score, '极致参数效率'))
# S-LoRA适用场景
if deployment_scale == 'distributed' and num_tasks > 10:
score = min(num_tasks / 10, 10) * 0.4 + (5 if deployment_scale == 'distributed' else 0)
recommendations.append(('S-LoRA', score, '大规模并发服务'))
# LoRA基准
recommendations.append(('LoRA', 5.0, '通用场景基准'))
# 按分数排序
recommendations.sort(key=lambda x: x[1], reverse=True)
return recommendations
# 使用示例
scenarios = [
{
'name': '长文档理解',
'context_length': 32768,
'num_tasks': 5,
'resource_constraint': 'medium',
'deployment_scale': 'single'
},
{
'name': '个性化推荐系统',
'context_length': 2048,
'num_tasks': 1000,
'resource_constraint': 'high',
'deployment_scale': 'distributed'
},
{
'name': '多任务对话系统',
'context_length': 4096,
'num_tasks': 50,
'resource_constraint': 'medium',
'deployment_scale': 'distributed'
}
]
for scenario in scenarios:
print(f"\n场景: {scenario['name']}")
recommendations = recommend_method(scenario)
for method, score, reason in recommendations[:3]:
print(f" {method}: {score:.1f}分 - {reason}")
3. 成本效益分析
| 成本项 | LongLoRA | VeRA | S-LoRA | 说明 |
|---|---|---|---|---|
| 开发成本 | 中 | 低 | 高 | 实现复杂度 |
| 训练成本 | 低(长文本) | 极低 | 中 | GPU小时数 |
| 存储成本 | 中 | 极低 | 中 | 模型参数存储 |
| 推理成本 | 中 | 低 | 低(批处理) | 在线服务成本 |
| 维护成本 | 中 | 低 | 高 | 系统运维复杂度 |
4. 最佳实践建议
基于实际项目经验,我总结了以下最佳实践:
选择LongLoRA的场景:
- 文档级别的任务(法律文档分析、学术论文理解)
- 需要处理超过8K token的上下文
- 对推理延迟不敏感的应用
选择VeRA的场景:
- 资源极度受限的边缘设备部署
- 需要部署数百个不同任务的模型
- 对存储成本敏感的应用
选择S-LoRA的场景:
- 多租户SaaS平台
- 需要同时服务数千个用户的场景
- 对推理吞吐量要求极高的应用
6、技术发展趋势
通过对LongLoRA、VeRA和S-LoRA三种前沿微调技术的深入分析,我们可以看到大模型微调技术正在朝着以下几个方向发展:
-
参数效率的极致优化: 从LoRA的参数减少到VeRA的10倍压缩,参数效率仍有巨大提升空间
-
计算效率的持续改进: LongLoRA通过稀疏注意力机制降低了长序列处理的计算复杂度
-
系统级优化的重要性: S-LoRA展现了从算法层面到系统层面协同优化的巨大价值
-
多目标平衡的需求: 未来的微调方法需要在参数效率、计算效率、推理速度、部署便利性之间找到更好的平衡
结语
LongLoRA、VeRA和S-LoRA代表了大模型微调技术的三个重要发展方向:长序列处理、极致参数效率和大规模并发服务。每种技术都有其独特的价值和适用场景,未来的发展将是这些技术的融合创新。
通过本文的分析和实践案例,希望能为读者在大模型微调技术的选择和应用方面提供有价值的参考。技术的发展永无止境,让我们在这个激动人心的AI时代,继续探索和创新,推动大模型技术向更高效、更实用的方向发展。
更多推荐
 15
15 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)