
51c大模型~合集183
在并行推理的探索道路上,除了 ParaThinker,近年来也涌现出其他值得关注的思路,例如以 Multiverse(https://arxiv.org/abs/2506.09991)为代表的工作,但其主要目标侧重效率:根据原文分析,这些方法的主要目标是加速生成过程,即让模型「做得快」,而不是直接致力于提升最终答案的准确性。例如,向量化一切、RAG、多模态数据处理,数据平台被专家预测将从「仓库」进
我自己的原文哦~ https://blog.51cto.com/whaosoft/14180264
#ParaThinker
突破单链思考上限,清华团队提出原生「并行思考」scale范式
近年来,大语言模型(LLMs)在复杂推理任务上的能力突飞猛进,这在很大程度上得益于深度思考的策略,即通过增加测试时(test-time)的计算量,让模型生成更长的思维链(Chain-of-Thought)。
然而,这条路径正面临着一个明显的瓶颈:随着计算资源的持续投入,性能提升变得微乎其微,甚至陷入停滞。
来自清华大学 AIR 的一篇最新研究论文《ParaThinker: Native Parallel Thinking as a New Paradigm to Scale LLM Test-time Compute》对这一瓶颈发起了挑战 。

该研究一针见血地指出,这个单链 test time scaling 的天花板并非模型能力的固有极限,而是源于当前顺序推理策略的根本缺陷 —— 一种被研究者称为「隧道视野」(Tunnel Vision)的现象。
为此,团队提出了模型原生的并行化思考方案,训练 LLM 在一次推理中同时生成和综合多个不同的推理路径,从而有效规避「隧道视野」问题,解锁模型潜在的推理能力。
该研究证明,与串行扩展计算深度相比,并行扩展计算宽度是一种更有效、更高效的推理策略。
- 论文标题:ParaThinker: Native Parallel Thinking as a New Paradigm to Scale LLM Test-time Compute
- 作者:Hao Wen*, Yifan Su*, Feifei Zhang, Yunxin Liu, Yunhao Liu, Ya-Qin Zhang, Yuanchun Li (*Equal Contribution)
- 机构:清华大学
- 论文地址:https://arxiv.org/pdf/2509.04475
隧道视野:深度思考的阿喀琉斯之踵
扩展瓶颈(Scaling Bottleneck): 如下图所示,对于单个推理路径(P=1),当投入的计算资源(即 Token 预算)超过一定限度后,模型准确率便不再提升,甚至可能下降,这表明「想得更久」并不能持续带来回报。

隧道视野(Tunnel Vision): LLM 在生成思维链的初期,一旦迈出有瑕疵的第一步,就很容易被锁定在一条次优的推理路径上,难以在后续步骤中纠正或发现更优的解法 。模型仿佛走进了一条狭窄的隧道,无论走多远,都无法摆脱最初错误方向的束缚。
如下图 (b) 所示,研究者进行了一项实验:他们故意让模型从一个错误的推理前缀开始继续生成答案。结果显示,错误的前缀越长,模型最终能够 “拨乱反正” 得到正确答案的概率就越低。这证明了 LLM 一旦陷入错误的思维定式,就很难自行跳出。

新范式:从「深度」到「广度」
原生并行思考(Native Parallel Thinking)的核心思想是,与其让模型在一条路径上「死磕」,不如让它同时探索多条不同思路的推理路径,最后再综合提炼出最优答案。
为此,研究团队推出了一个名为 ParaThinker 的端到端框架。该框架能够训练 LLM 在一个统一的前向传播过程中,并行生成多个多样化的推理路径,并将它们融合成一个更高质量的最终答案。
ParaThinker 的实现主要依靠三大核心创新:

- 专用可控 Token:引入一系列可训练的特殊 Token(如 <think i>),用于显式引导模型开启第 i 条独立的思考路径,从而确保了推理路径的多样性。
- 思维特定位置嵌入:为了解决在汇总阶段多路径带来的位置信息混淆问题,ParaThinker 为每条推理路径设计了独特的、可学习的「思维嵌入」(Thought Embedding)。这让模型在最终综合时,能清晰地区分每个信息片段的来源,避免信息「串线」。
- 两阶段注意力掩码:在并行推理阶段,注意力被严格限制在各自的路径内部,确保各思路的独立性;在汇总阶段,则开放全局注意力,让模型可以审视所有路径并进行高效整合。
此外,一个关键的工程优势在于,ParaThinker 在汇总阶段能够重用并行推理过程中生成的 KV 缓存。这极大地节省了计算资源,避免了昂贵的重新计算(re-prefilling),使得整个过程的延迟开销极小。
超越 Majority Voting 与简单任务分解
并行推理并非一个全新的概念,类似「多数投票」(Majority Voting)的方法早已被用于提升模型在选择题或数值计算等任务上的表现。但这类方法的局限性也十分明显:它们依赖于可被轻易量化和验证的答案格式,而对于代码生成、数学证明、复杂智能体工作流等开放式、生成式的任务则束手无策。
ParaThinker 的优越性正在于此。它不是简单地对多个独立结果进行投票,而是学习如何智能地「整合」与「提炼」来自不同推理过程的信息。这使其成为一种更通用、更强大的并行推理框架,能够处理无法被简单投票的复杂任务,真正释放了并行思考的潜力。
在并行推理的探索道路上,除了 ParaThinker,近年来也涌现出其他值得关注的思路,例如以 Multiverse(https://arxiv.org/abs/2506.09991)为代表的工作,但其主要目标侧重效率:根据原文分析,这些方法的主要目标是加速生成过程,即让模型「做得快」,而不是直接致力于提升最终答案的准确性。
此外,其任务分解依赖任务结构:它们的成功很大程度上依赖于任务本身是否适合被显式地分解。对于许多不可分解的、需要整体性思维的复杂问题,这种方法的适用性便会受限。
相比之下,ParaThinker 提供了一种更具普适性的并行范式。它不假设任何子任务结构,也不试图对问题进行拆解。ParaThinker 的核心目标是通过思维的多样性来提升准确性。
实验结果:正确率随思维广度有效提升
在 AIME、AMC、MATH-500 等难度基准上,1.5B 参数模型用 8 条并行路径,平均准确率提升 12.3%;7B 模型提升 7.5%。

延迟开销较低:推理延迟并不随着同时思维链数而线性增长,在 batch size=1 时,并行路径数增加了 8 倍,但延迟仅增加了约 10%,这体现了并行计算在硬件层面的巨大优势。

与多数投票(Majority Voting)的结合
ParaThinker 与 majority voting 策略(即生成 k 个独立答案,选择出现次数最多的那个)并不冲突,两者叠加可以达到更高的正确率。

ParaThinker 教会大模型像人类一样「头脑风暴」,并行探索多种思路,再整合成最优答案。它预示着未来 LLM 的规模化发展之路,将从单纯的「深度」扩展转向更有效的「广度」扩展。
...
#LLM开源2.0大洗牌
60个出局,39个上桌,AI Coding疯魔,TensorFlow已死
卷王指南又更新了,这次还有番外篇。
开源 2.0 :变脸堪比整容
等了一百多天,悬念终于揭晓。
9 月 13 日上午,蚂蚁集团开源团队(「开源技术增长」)携《 2025 大模型开源开发生态全景图 》2.0 版,亮相上海外滩大会。
三个月前,「一场直播中的『现实世界的黑客松 』 (A Real-world Hackathon )」的断言,今天依然成立——
彼时「撕拉片」记录下生态初现的模样,而今,已经大变样。

- 访问地址:https://antoss-landscape.my.canva.site/
这一次,全景图收录了 114 个项目(比上一版减少 21 个),覆盖 22 个领域。其中,39 个是新晋项目,同时也有 60 个项目消失在舞台,其中不乏一度高光的 Star 王者——
如 NextChat、OpenManus、FastGPT、GPT4All,因迭代迟缓、社区乏力而被后来者超越。
最 drama的,当属 TensorFlow 的谢幕,这位昔日巨星最终没能抵挡 PyTorch 的攻势,后者自此一统江湖。

灰色部分,即为出局的开源项目
整体趋势是显而易见:生态正在经历一轮剧烈洗牌。就像寒武纪的「生命大爆发」,Agent 层最为汹涌,混沌之中,各类新物种层出不穷。
另一组数据,也侧面印证了这一旺盛的新陈代谢——
算上被淘汰的项目,整个大模型生态的「中位年龄」只有 30 个月,平均寿命不足三年,是一片极度年轻的丛林。
尤其是「GPT 时刻」之后( 2022 年 10 月),62% 的项目才诞生,其中 12 个甚至是 2025 年的新面孔。也就是说,几乎每个季度都能看到新人登场、旧人退场。
更夸张的是,这些年轻项目获得了前所未有的关注:平均 Star 数接近 3 万,远超以往同龄的开源项目。头部前十的项目几乎覆盖了模型生态的全链路,是当下最具代表性的社区力量。

最活跃的开源项目 Top 10
关键词词云也呼应了这一趋势:AI、LLM、Agent、Data成了最大、最亮的几个字。

大模型开发生态关键词 AI、LLM、Agent、Data 、Learning正是第一张图表中所列项目的主要领域。
另一个大变样是全景图的分类框架。
因为看过 1.0 版本,所以当我第一次看到 2.0 全景图时,最直观的感受就是:分类架构变得更具体、更细分:
从大而化之的 Infrastructure / Application,进化为 AI Agent / AI Infra / AI Data 三大板块,清晰勾勒出行业热点(智能体为中心),和技术演进的趋势。
如果说 1.0 的框架还带着传统开源软件生态的影子,那么 2.0 已经透出「智能体时代」的气质。
最后,从全球 366,521 位开发者群像来看,中美双雄贡献超过 55%,依然是项目的绝对领导者,其中美国以 37.41% 的比例位居第一。
在技术领域的细分贡献中,美国在 AI Infra 和 AI Data 上优势明显。
如,AI Infra,美国贡献度达 43.39%,是排名第二的中国的两倍多;而在 AI Data 的领先优势更为明显。

中国在具体应用层( AI Agent )则表现接近美国,两国贡献度分别为 21.5% 和 24.62% ,这与中国开发者在 Agent 层面的投入更多密切相关。
制图论的进化
为什么要把方法论放在前面讲?答案很简单——哪些项目能够进入 2.0 全景图,很大程度上取决于方法论变了。
1.0 版本的方法论是「从已知出发」——被广泛讨论的头部项目,比如 PyTorch、vLLM、LangChain,再通过它们的协作和依赖关系向外延伸。
但出发点决定边界:你从哪些种子项目出发,就决定了能看见的生态范围。那时的入选门槛是 OpenRank (华东师范大学 X-lab 开发的开源影响力指标)月均值 ≥ 10。
而 2.0 版本直接拉取 GitHub 全域项目的 OpenRank 排名,筛选出大模型相关项目,不仅大幅减少了起点偏见,也更敏感于新项目的爆发力。结果是,更多高热度、高活跃度的项目被发现,入选阈值也相应提高到当月 OpenRank > 50。
从这个角度说,2.0 更契合蚂蚁「开源技术增长」团队做这件事的初衷:对内,为企业决策提供依据;对外,为开源世界的「卷王们」点亮指南。
在这套新方法下,三大主力赛道脱颖而出:AI Coding、Model Serving 、LLMOps。



接下来,我们将从应用层一路追溯到底层 Infra,逐一梳理这股洪流中的关键变化。
AI Agent :AI Coding 疯魔了
2.0 全景图上的 AI Agent 已经从一个「百宝箱」式的工具堆,演化为类似云计算的分层体系——
AI Coding、Agent Workflow Platform、Agent Framework、Agent Tool 等类别齐备,专业与清晰度大幅提升,社区正经历从野蛮生长走向系统分化的过程。

2.0的AI Agent 层

AI Agent 的迭代经历犹如过山车。
目前,AI Agent 地表变动剧烈,就像一片新大陆,每个人都在抢先插旗。AI Coding、Chatbot、Workflow Platform 等方向接连涌现出新的高热度项目。
更有意思的是,2.0 版还敏锐捕捉到 AI 与物理世界深度结合的迹象——「小智」尝试把大模型跑在低功耗芯片上,Genesis 则面向通用机器人提供物理仿真平台。
接下来,我们逐一拆解细分领域的变化。
1、从疯到癫,AI Coding 增长曲线仍在陡升

除了 Cline、Continue、OpenHands 等常驻「霸榜」项目外,新面孔不断涌现——Gemini、marimo、Codex CLI,以及定位为 Claude Code 100% 开源替代的 OpenCode。事实再次证明,「Agent for Devs」仍是最高频、最刚需的应用场景。

2025 年的 AI Coding 已经完成了从「补代码」到「全生命周期智能引擎」的跨越:能做的事更多,从开发到运维全链路覆盖;做事的方式更聪明,支持多模态、上下文感知与团队协同。
报告预测,市场也将随之释放出巨大的商业化潜力——付费订阅、SaaS 服务与增值功能,将成为新的盈利模式。

AI Coding 已经完成了从「补代码」进化到能做的事更多,做事的方式更聪明。
这种趋势在行业交流中感受尤深。这次上海外滩大会上,有嘉宾直言 AI Coding 工具卷到用不过来;另一位深耕 AI 编码的 CEO 则透露,团队所有成员的 AI 工具报销已超 200 美元。
几个月前,AI 代码还需要大量人工修正;如今质量飞升,只需轻量修改即可。下一步,AI 编程或许会从「写代码」跃迁到「主导整个工作流」。
值得注意的是,Gemini CLI、Codex CLI 的走红也释放出大厂的战略信号:通过开源工具链绑定开发者,把他们锁入自家闭源模型的生态。
这与微软当年的 Windows + .NET、苹果的 iOS + Swift 如出一辙。今天的AI 巨头,正在用相同的路径重塑新一轮开发者生态。
2、Chatbot & Knowledge Management 高光后的理性回归
Chatbot 是 GenAI 应用的第一波爆款,Cherry Studio、Open WebUI、Lobe Chat、LibreChat 在 2025 年初迎来顶峰,收获了大量关注与贡献。但热度未能持续。5 月之后,Chatbot 进入平台期,逐渐降温。


Lobe-Chat 以日更节奏,用框架将「ChatGPT 式对话」降维到人人可自建的体验。然而,随着功能趋近完备,用户也发现 Chatbot 核心价值仍是「对话」,而对话在生产力上的突破有限。
Cherry Studio 开辟了另一条路径:把 Chatbot 与知识库/笔记结合,定位于「个人知识助理」,更贴近长期生产力需求。这可能也是它逆势上榜的原因——新进项目中活跃度第二,总体位列第七。
因此,降温并不意味着衰退。Lobe-Chat 依然保持 64.7k star 的体量,日更节奏从未停歇。只是相较 Memory、Agent 等更令人兴奋的方向,Chatbot 不再是唯一的焦点,而开始回归理性。
3、Agent Workflow Platform 沉淀为真正的基础设施
当 GPT-5、Claude、Gemini等顶尖模型趋同,AI 应用的差异化越来越依赖「记忆」。这催生了一大批 RAG + Agent 项目,成为开源热点。
RAGFlow、MaxKB(专注知识库问答)、FastGPT(轻量 RAG 平台)、Flowise AI(主打 RAG-based QA 的可视化工作流工具)都在这一波浪潮中走红。

尽管趋势回落,但 7 月份的 OpenRank (1418) 仍然远高于 1 月份的起始点。

相比之下,Dify 的布局更完整:不仅覆盖 RAG 和 Agent 工作流,还提供应用发布、用户管理、可观测性等企业级能力,形成从原型到生产的一站式平台,在社区影响力和商业化上明显领先。
与此同时,新的探索开始突破传统 RAG 的边界。如 Letta(尚未上榜)尝试引入「离线学习」,让 Agent 不仅能依赖检索,还能真正从经验中学习改进。这意味着 Agent Workflow 未来可能从「检索增强」走向「长期学习」,为应用开辟更广阔的空间。
4、Agent Tool 爆款频出
Agent Tool 针对大模型的硬伤,补齐短板,让 AI 从「能聊」走向「能做」。因此,这一领域成为当下最炙手可热的创新赛道,爆款频出。
LiteLLM、Supabase、Vercel、ComfyUI、mem0 各自切入关键环节,推理调用、数据存储、记忆管理、外部交互层层推进 AI 的能力边界。

比如 mem0 赋予 Agent 长期记忆与上下文感知;Supabase 快速进化成 GenAI 时代的数据基础设施,解决了实时信息与记忆管理的缺失问题。
而 Browser-use 更是在 9 个月拿下 60K star,让 Agent 真正学会操作网页,成为「落地最后一公里」的标志性项目。
5、Agent Framework下跌明显
2.0 版中,跌幅最大的项目有四个都属于 Agent 编排框架:Eliza、LangChain、LlamaIndex、AutoGen。

一方面这些头部项目在社区投入收缩;另一方面,社区注意力正从通用框架转向应用落地:记忆、工具调用、交互界面等更细颗粒度的创新,正在为未来更强自治的 AI 系统打下基础。
不过,Camel-AI、CrewAI、Agno、ELIZA.OS的冒头,显示「协作智能体」正收获更多关注。

LiveKit Agents 的上榜同样典型,它专注实时交互场景,如语音对话、多人协作,这在过去是图谱里几乎没有覆盖的。
AI Infra:
模型服务狂飙依旧、LLMOps接棒MLOps
虽然远不如 Agent 层的「生命大爆发」,但在 AI Infra 的静水深流中,仍能看到几道涌动的波澜——
云端推理持续内卷、轻量推理的开花、愈发专化的 LLMOps。

2.0版本的AI Infra
1、主力赛道 Model Serving,热力不减
在 2.0 版本里,唯二能与 AI Coding 正面对标的赛道就是 Model Serving。
大模型要落地,推理的效率、成本、安全性是绕不过去的门槛。从 2023 年以来,这条赛道就持续高烧不退,依然是 AI Infra 的主战场。


以 vLLM、SGLang 为代表的高性能云端推理方案仍是主流,生态和社区影响力不断扩张。尤其是 vLLM,稳定性和生态优势使其热度持续坚挺。
大厂也全力加码,NVIDIA TensorRT-LLM 热度居高,新晋的 NVIDIA Dynamo 与之配合,深度绑定 GPU 硬件,正把「推理框架」当作巩固算力垄断的新抓手。

与此同时,本地化也在狂飙。

ollama 让大模型从昂贵的云端「飞入寻常百姓家」,跑在个人电脑甚至移动端。近几个月它的热度虽有小幅下滑,但 GPUStack、ramalama 等新框架迅速补位,说明「轻量 + 云端优化」这条路径依然涌现新玩家。
2、模型运维:LLMOps 接棒 MLOps
除了 AI Coding、Model Serving,LLMOps 也是 2025 年以来增长最快的主赛道。
Phoenix、Langfuse、Opik、Promptfoo、1Panel、Dagger 等项目,几乎覆盖了从监控、提示词评测到工作流管理的各个环节。

这里的关键转变是,2.0 版本重新定义了「模型运维」:原本分散在模型评测和传统 MLOps 的内容,被整合进大模型的全生命周期管理。关注点也从「小模型时代」的训练精度、数据管道,转向「如何让模型稳定、可控地跑起来」。
换句话说,LLMOps 核心聚焦在监控、提示词效果、可观测性和安全可信上,成为推动大模型真正走向应用的关键支撑。
3、模型训练,跌破年初水平
与前两条赛道的高热不同,模型训练反而一路回调,不仅回吐了涨幅,还跌破了年初水平。


不同行业确实需要不同「口味」的模型。从零开始训练一个 GPT-4 级别模型成本过高,社区更关注如何低成本微调已有模型,比如 Unsloth 集成 QLoRA,在中低端硬件就能跑通。
问题在于应用层成了新的战场:围绕 Chatbot、Agent Tool、Workflow,对开发者更友好,贡献和创新空间更大。
PyTorch 等训练框架早已成熟,增长见顶;Swift、Unsloth、LLaMA-Factory虽短期吸睛,但没能形成持续突破。
4、此外,Ray 在分布式计算上一骑绝尘,TransformerEngine、DeepEP、Triton、Modular等专用内核库的崛起,标志着大模型正在催生属于自己的软件栈,从 Python API 到算子,都需要为 LLM 量身打造。
AI Data,依旧波澜不兴
相较于前两大领域的风云变幻,AI Data 领域显得格外平静。
生态链条已经相当完整,从标注、集成、治理,到向量数据库与搜索,再到上层应用框架,几乎覆盖了数据处理的所有环节。
大多数项目还都是老面孔,诞生于 2014至 2020 年,本质上为 AI 1.0(传统机器学习)时代而生。Chroma 是少数「赶上大模型浪潮」的新秀,2022 年亮相便切中了 RAG 应用的爆发点。
但在热度层面,AI Data 却在持续降温。

我们推测,一部分原因在于这些技术本身已足够成熟,没必要重复造轮子。
像 Iceberg、Delta Lake 这样的数据湖,Milvus、Weaviate、Elasticsearch等向量数据库,早已成为「基础拼图」,经过反复验证后,缺少新的突破口。
另一方面,AI Data 更偏向企业级场景,开发者个人难以直观感受到价值,GitHub 的社区关注度难以持久。
不过,波澜不兴往往孕育着更大的风暴。AI Data 的真正挑战,正在原生大模型时代逐渐显现。例如,向量化一切、RAG、多模态数据处理,数据平台被专家预测将从「仓库」进化为「中枢」——一个智能、动态、实时连接的系统,能持续为模型这个大脑提供真实世界的感知。
因此,旧框架虽依旧稳健,却正被逼近极限。新一代原生于大模型范式的数据基础设施正在酝酿中,AI Data 的下一次波澜壮阔还在蛰伏。
商业博弈,逐渐变味的「开源」
在 2.0 全景图出炉之前,我们就注意到一个微妙趋势:越来越多的大模型项目不再沿用 MIT、Apache 2.0 这类传统开源许可证,而是自拟「开源许可协议」( Open-Source License Agreement ),在开放、控制之间划下灰色地带。
这种新式协议往往保留了许可方更多的干预权。比如,传统协议下,授权一旦给出便不可撤销;但在一些大模型的自拟协议里,这一限制被取消,为后续商业博弈留足了回旋余地。
还有的项目直接按用户规模设限:月活跃用户超过某个数量,就必须另行商议授权。
巧合的是,2.0 全景图的数据也印证了这一观察:新晋项目的 License 多为带有限制性的变体,引发了「算不算开源」的争论。
例如,Dify 采用 BSL(Business Source License)变体,先开放代码,若干年后才切换为宽松协议,以保障商业利益。
n8n 使用 Fair-code,强调「防止大厂白嫖」,Cherry Studio 则在条款中明确了商用需额外授权,体现出对商业模式的防御。
而另一层模糊,来自 GitHub 本身。Cursor、Claude-Code 等项目甚至连代码都闭源,却依旧在 GitHub 上大热,成了厂商收集反馈的窗口。何为「开源社区」在这一波大模型浪潮中,似乎也在被挑战。
番外篇:大模型的战场
作为 Bonus,2.0 版本还特意梳理了 2025 年 1 月至今国内外主流厂商的大模型发布时间线,包含开源、闭源模型,发现了一些有趣的现象。

这张全景图也标注了每个模型的参数、模态等关键信息,帮助理解当下各家厂商的白热化竞争究竟是在哪些方向上展开的。
1. 路线分化:开源 vs 闭源
中国的开源模型依旧百花齐放,而国外顶尖厂商则持续押注闭源。曾凭 Llama 系列对抗闭源阵营的 Meta,如今也逐渐收紧开源节奏。扎克伯格在公开信中直言,「会更谨慎地选择开源什么」。Llama 4 口碑滑铁卢,更让 Meta 的处境尴尬。
这也Callback 了阿里云创始人、之江实验室主任王坚在上海外滩大会开幕式上的判断:开源与闭源的选择,已成为 AI 竞争的关键变量。
2. MoE 架构普及,参数直冲万亿
DeepSeek、Qwen、Kimi 等新旗舰,全面采用专家混合( MoE )架构。凭借「稀疏激活」,模型总参数可以飙升到万亿级别,却只在推理时激活一小部分。K2、Claude Opus、o3 等巨型模型相继登场,性能获得跃升,但也将训练和推理的算力消耗推至新高点。
3. Reasoning:新标配
如果说去年模型发布拼的是「规模」,今年比拼的就是「推理」。DeepSeek R1 借助强化学习大幅增强自动化推理和复杂决策能力,让Reasoning 成为今年模型发布的标配功能。Qwen、Claude、Gemini 甚至引入「快思/慢想」的混合模式,让模型像人一样在任务间切换反应速度。
4. 多模态:全面爆发
过去半年,最强的大脑们不再只盯在语言模型,多模态赛道开始卷了起来。语言、图像、语音交互成为标配,中国厂商在闭源与开源两条线上都取得全球领先。
与此同时,语音模态生态也在兴起:Pipecat、LiveKit Agents、CosyVoice 等工具链正在快速补全版图。
不过,距离视频模态真正成熟,甚至 AGI 的落地,仍有不短的路要走。
5. 模型评价:多元化
多模态的全面爆发,也带动了评价体系的多元化。有人依旧信赖 Design Arena、LMArena 这样的「人投票」平台,用主观偏好来判断模型优劣。也有人更看重客观测试集的分数,用标准答案来衡量模型表现。
与此同时,以 OpenRouter 为代表的 API 网关平台,凭借天然掌握的调用数据,正在形成一种「数据投票」的排行榜。而活跃度持续飙升的 LiteLLM,未来或许也会把调用统计转化为新型评测方式。
...
#Parallel-R1
腾讯AI Lab首创RL框架Parallel-R1,教大模型学会「并行思维」
自从 Google Gemini 将数学奥赛的成功部分归功于「并行思维」后,如何让大模型掌握这种并行探索多种推理路径的能力,成为了学界关注的焦点。
然而,现有方法多依赖于监督微调(SFT),模型一来只能模仿预先构造的 parallel thinking 数据,难以泛化到真实的复杂任务中,其次这种方式对数据要求很高,往往需要复杂的 data pipeline 来构造。
为解决这些难题,来自腾讯 AI Lab 西雅图、马里兰大学、卡内基梅隆大学、北卡教堂山分校、香港城市大学、圣路易斯华盛顿大学等机构的研究者们(第一作者郑童是马里兰大学博士生,本工作于其在腾讯 AI Lab 西雅图实习期间完成)首创了 Parallel-R1 框架 —— 这是第一个通过强化学习(RL)在通用数学推理任务上教会大模型进行并行思维的框架。该框架通过创新的「渐进式课程」与「交替式奖励」设计,成功解决了 RL 训练中的冷启动和奖励设计难题。
实验表明,Parallel-R1 不仅在多个数学基准上带来高达 8.4% 的平均准确率提升,更通过一种 “中程训练脚手架” 的策略,在 AIME25 测试中实现了 42.9% 的性能飞跃。
- 论文标题:Parallel-R1: Towards Parallel Thinking via Reinforcement Learning
- 论文地址:https://arxiv.org/abs/2509.07980
- 项目地址:https://github.com/zhengkid/Parallel-R1 (Coming Soon)
- 项目主页:https://zhengkid.github.io/Parallel_R1.github.io/
并行思维的挑战:为何注入并行思维如此困难?
并行思维,即同时探索多条推理路径再进行归纳总结。

图 1:并行思考流程示意图。
目前最主流的注入并行思维的范式是监督微调 (SFT),但这种方式本质上是行为克隆,强迫模型模仿固定的、预先生成的数据,导致模型只会进行表面上的模式匹配,而无法真正习得和泛化并行思维这一内在的推理能力。其次,这类方式对数据质量和多样性的要求非常高,只有非常高质量的数据才能让模型学习到很好的 parallel thinking 能力。然而,遗憾的是,在现实世界中,人们很难天然获取高质量的这类数据,因此只能依赖于人工合成。而对于真实世界的推理任务,构造这些数据的难度很大,需要复杂的数据管道。
另一方面强化学习(RL)是一种更扩展性强的,但在通用、真实的复杂任务中进行并行思维训练却面临两大核心挑战:
- 冷启动问题(Cold-Start):由于预训练模型从未见过并行思维的特定格式(如同时生成多个解题路径),在 RL 探索初期,它根本无法自发产生这类轨迹,导致学习无从下手。这时候就需要一个冷启动阶段。但是上文提到,对于真实世界的难题,这种数据很难构造。
- 奖励设计困境(Reward Design):如何平衡「解题正确率」和「思维方式」是一个难题。如果只奖励最终答案的正确性,模型会倾向于走最简单、最熟悉的单路径「捷径」,从而「遗忘」更复杂的并行思维;而如果强行要求使用平行格式,又可能导致模型为了格式而牺牲逻辑的严谨性,反而降低了准确率。

图 2:渐进式课程训练示意图
Parallel-R1 的解法:首个为真实世界推理任务打造的 RL 框架
为攻克上述难题,Parallel-R1 作为首个专为通用、复杂数学推理等真实世界任务设计的强化学习框架被提出。它通过一套精巧的组合拳,系统性地解决了训练困境。
渐进式课程:从「学格式」到「学探索」
研究者的一个关键发现是:用简单的提示工程,让强大的模型为简单数学题(如 GSM8K)生成高质量的并行思维数据是可行的(成功率 83.7%),但对于复杂难题(如 DAPO)则完全无效(成功率 0.0%)。

基于这一洞察,他们巧妙的避开了复杂的数据管道依赖,并设计了一种渐进式课程:
- 第一阶段(格式学习):首先,利用新建的 Parallel-GSM8K 数据集,在简单的数学任务上对模型进行 SFT。此阶段的核心目标并非解决难题,而是让模型学会并行思维的「语法格式」,例如如何使用
-

- 、
-

- 、
-

- 等控制标签 。
- 第二阶段(能力泛化):当模型掌握了基本格式后,再将其置于更困难的数学任务中,通过 RL 进行训练 。此时,模型已经具备了生成平行轨迹的 “火种”,可以在 RL 的驱动下自由探索、试错,并最终将这一能力泛化到未知难题上。
交替式奖励:在「准确性」与「多样性」间取得平衡
针对奖励设计的困境,研究团队试验了多种方案,最终提出了一种高效的交替式奖励策略。该策略在训练过程中,周期性地在两种奖励模式间切换:
- 80% 的时间使用「准确率奖励」:只根据最终答案是否正确给予奖励,确保模型的核心目标始终是解决问题。
- 20% 的时间使用「分层奖励」:在这一模式下,如果模型使用了并行思维并且答案正确,会获得一个额外奖励(+1.2 分);如果未使用并行思维但答案正确,则获得标准奖励(+1.0 分);否则将受到惩罚。
消融实验(见下表)证明了该策略的优越性。单纯奖励准确率,模型的并行思维使用率极低(13.6%);单纯奖励平行格式,模型性能会严重下滑。而交替式策略在将并行思维使用率提升至 63.0% 的同时,还能在 AIME 等高难度测试上取得最佳性能,完美实现了「既要并行行为又要准确率」的目标。

并行思考模型超过单一思考模型
根据下面提供的性能对比表,注入了并行思维能力的模型在各项数学推理基准测试中,其性能优于传统的单一(顺序)思考模型。

打开「黑箱」:模型如何悄然改变思维策略?
除了提出高效的训练框架,该研究还深入分析了模型在学习过程中的动态变化,揭示了一个有趣现象:模型的并行思维策略会随着训练的深入,从「探索」演变为 「验证」。
通过追踪

模块在解题过程中出现的位置,研究者发现,在训练初期,模型倾向于在解题的早期就使用并行思维,这相当于「广撒网」,同时探索多种可能性来寻找解题思路。然而,随着模型能力的增强,它变得更加自信,平行模块出现的位置逐渐后移。在训练后期,模型会先用一条自己最有把握的路径推导出一个初步答案,然后在解题的末尾才调用并行思维,从不同角度对该答案进行复核与验证,以确保万无一失。

图 3:训练过程中 < Parallel > 模块相对位置的变化,曲线稳步上升,表明其应用从早期探索转向后期验证。
意外之喜:作为「训练脚手架」的并行思维
研究还发现了一个更令人振奋的结论:并行思维本身可以作为一种临时的「结构化探索脚手架」,来帮助模型解锁更高的性能上限。
研究者设计了一个两阶段训练实验:
- 探索阶段(0-200 步):采用交替式奖励,强制模型高频率地使用并行思维,进行广泛的策略空间探索。
- 利用阶段(200 步后):切换为纯粹的准确率奖励。此时,模型会逐渐减少对平行格式的依赖,转而专注于提炼和利用在第一阶段发现的最优策略。
结果(见下图)显示,进入第二阶段后,尽管模型的并行思维使用率(绿线)骤降,但其在 AIME25 上的准确率(红线)却持续攀升,最终达到了 25.6% 的峰值。这一成绩相较于从头到尾只用标准 RL 训练的基线模型,实现了高达 42.9% 的相对提升。这证明了,短暂地「强迫」模型进行平行探索,能够帮助它发现一个更优的「能力区间」,即使后续不再使用这种形式,其学到的核心推理能力也得到了质的飞跃。

图 4:两阶段训练曲线。在探索阶段后,并行思维使用率下降,但模型准确率持续走高,超越基线。
总结
在这项工作中,研究者们提出了 Parallel-R1,这是首个能在真实的通用数学推理任务上,通过强化学习教会大模型进行并行思维的框架。除此之外,研究者们进一步对并行思考行为以及其潜在价值进行了深入探讨。
..
#AP2(Agent Payments Protocol )
「AI助手」真来了?谷歌牵头推进Agent支付协议AP2
近日,Agent 领域再次传来新进展,谷歌宣布推出 Agent 支付协议 ——AP2(Agent Payments Protocol ),这是一种开放的共享协议,为 Agent 和商家之间安全合规的交易提供通用语言。

换句话说,这一协议是用于 AI Agent 跨平台主导发起与处理的购买支付,为每笔交易提供可追溯的记录。
具体来看,AP2 可视为是 A2A 协议和 MCP 协议的扩展。
今年年初,Manus 在全球范围内掀起 Agent 热潮,带着 MCP 协议变热,而这一协议是由 Athropic 于 2024 年 11 月推出,为的是让 Agent 更好与外部资源、工具、API 接口集成,使 Agent 能够具备更多的能力。
之后今年 4 月,谷歌推出了开放的 A2A(Agent2Agent)协议,这面向的是 Agent 与 Agent 之间的「交互」,基于这一协议,Agent 之间可以相互协作、一起完成复杂任务。

其实很好理解,虽然 Agent 成为今年 AI 主流叙事,开启「百 Agent 混战」模式,但更多是聚焦垂类,距离通用还很遥远,如果用户想要处理一件事情需要用到多个 Agent 时,常规方法是手动操作,比如导入各种信息等,根本不「智能」。而基于 A2A 协议,不同框架和供应商的 Agent 之间就可以实现互通有无,更为智能。
而 AP2 在此基础上再进一步。

现在很多 Agent 扮演着「助手」的角色,用户会让它帮忙订酒店、买机票、买咖啡、抢演唱会门票等,这不仅涉及 Agent 之间的跨平台合作,更涉及跨平台支付,那自然而然就会出现一个问题:如何保证这些支付交易是安全的?如果出了问题,谁负责?
传统的支付系统是为人类点击「购买」而构建,但这一套法则并不适用于 Agent。而谷歌新推出的 AP2,很好地解决了这一问题。
据官方介绍, AP2 主要聚焦于解决三大问题:
- 授权:证明用户授予 Agent 进行特定购买的特定权限;
- 真实性:使商家能够确信 Agent 的请求准确反映了用户的真实意图;
- 问责:如果发生欺诈或不正确的交易,确定问责。
基于 AP2 这一开放共享协议,为 Agent 平台和商家之间安全合规的交易提供通用语言,有助于防止生态系统碎片化。它还支持多种支付类型 —— 从信用卡、借记卡到稳定币和实时银行转账。这有助于确保用户和商家获得一致、安全且可扩展的体验,同时也为金融机构提供有效管理风险所需的清晰度。
运作机制:通过授权和可验证凭证建立信任
根据官方介绍,AP2 通过使用 Mandates(授权书)来建立信任。授权书是一种防篡改、加密签名的数字合约,可作为用户指令的可验证证明。这些授权书由可验证凭证 (VC) 签名,并作为每笔交易的基础证据。
授权书涵盖用户通过 Agent 购物的两种主要场景:
- 实时购买(人工参与):当用户向 Agent 提出「帮我找双新的白色跑鞋」时,用户的请求会被记录在初始「意向授权」中。这为整个交易流程中的交互提供了可审计的背景信息。当 Agent 将用户想要的鞋子放在购物车中后,用户的确认操作将签署一份「购物车授权」。这一步至关重要,它将创建商品明细与价格的防篡改记录,确保所见即所付。
- 委托任务(无人参与):当用户向 Agent 委托「演唱会门票一经发售立即购买」这样的任务时,需要提前签署一份详细的意向授权书。该授权书详细规定了参与规则 —— 价格限制、时间安排和其他条件。它将作为可验证的预授权凭证,一旦满足用户的具体条件,Agent 便可自动为用户生成购物车授权书。
在这两种情况下,这条证据链最终都能安全地将用户的付款方式与购物车授权中已验证的内容关联起来。从「意向」到「购物车」,再到「付款」的完整闭环,形成了不可否认的审计追踪,有效解答了授权与真实性等关键问题,为「权责界定」提供清晰依据。
从这也不难看出,谷歌牵头的 AP2,试图解锁一种更为简单、全新的 AI 时代商业新模式。
比如,用户在计划一次周末旅行,并告诉他们的 Agent:「帮我预订 11 月第一个周末的往返机票和棕榈泉的酒店,总预算为 700 美元。」 那么,Agent 可同时对接航空公司、酒店 Agent 以及在线旅行平台,一旦发现符合预算的组合方案,即刻同步执行加密签名的双项预订。
资料显示,目前谷歌已经与 60 多个不同类型的企业达成了合作,包括美国运通、阿里巴巴、蚂蚁国际、携程、Coinbase、Etsy、Forter、Intuit、JCB、万事达卡、Mysten Labs、Paypal、Revolut、Salesforce、ServiceNow、银联国际、Worldpay 等。

目前,谷歌已经在 GitHub 上公开了该项目,包括完整的技术规范、文档和参考实现。
协议地址:https://github.com/google-agentic-commerce/AP2
快速入门
导航存储库:

目录包含一系列精选场景,旨在展示Agent支付协议的关键组件。
可以在

和

目录中找到这些场景。
每个场景包含:
-

- 描述场景及其运行说明的文件。
- 一个
-

- 脚本,用于简化本地运行场景的过程。
该演示包含各种Agent和服务器,大部分源代码位于

。使用 Android 应用作为购物助手的场景的源代码位于

。
先决条件:
- Python 3.10 或更高版本
设置:
确保你已从 Google AI Studio 获取 Google API 密钥 。然后

以以下两种方式之一声明变量。
- 将其声明为环境变量:
-

- 将其放入
-

- 存储库根目录的文件中。
如何运行场景:
要运行特定场景,请按照其 中的说明进行操作 README.md。它通常遵循以下模式:
- 导航到存储库的根目录。
-

- 运行脚本来安装依赖项并启动 Agent。
-

- 导航至购物 Agent URL 并开始参与。
安装 AP2 类型包:
协议的核心对象定义在

目录中。稍后官方将会发布一个 PyPI 包。在此之前,用户可以使用以下命令直接安装 types 包:

参考链接:
https://github.com/google-agentic-commerce/AP2
...
#Ling-flash-2.0
6.1B打平40B Dense模型,蚂蚁开源最新MoE模型
今天,蚂蚁百灵大模型团队正式开源其最新 MoE 大模型 ——Ling-flash-2.0。作为 Ling 2.0 架构系列的第三款模型,Ling-flash-2.0 以总参数 100B、激活仅 6.1B(non-embedding 激活 4.8B)的轻量级配置,在多个权威评测中展现出媲美甚至超越 40B 级别 Dense 模型和更大 MoE 模型的卓越性能。
这不是一次简单的 “模型发布”。在 “大模型 = 大参数” 的共识下,Ling-flash-2.0 用极致的架构设计与训练策略,在推理速度、任务性能、部署成本之间找到了一个新平衡点。这不仅是 Ling 系列开源进程中的又一重要节点,也为当前大模型 “参数膨胀” 趋势提供了一种高效、实用、可持续的新路径。
一、从 “参数军备” 到 “效率优先”:MoE 的下一步怎么走?
在当前大模型竞争愈发激烈的背景下,参数规模似乎成为衡量模型能力的 “硬通货”。但 “参数越多 = 能力越强” 的公式,正在失效:
- 训练成本指数级上升
- 推理延迟成为落地瓶颈
- 多数参数冗余,激活效率低
MoE(Mixture of Experts)架构被寄予厚望:通过 “稀疏激活” 机制,用更少的计算,撬动更大的参数容量。但问题在于 —— 如何设计一个 “真高效” 的 MoE?
Ling-flash-2.0 的答案是:从架构、训练到推理,全栈优化。
以小博大:6.1B 激活参数,撬动 40B 性能
Ling Team 早期的关于 MoE Scaling Law(https://arxiv.org/abs/2507.17702)的研究揭示了 MoE 架构设计 scaling 的特性。在此研究工作的指导下,通过极致的架构优化与训练策略设计,在仅激活 6.1B 参数的前提下,实现了对 40B Dense 模型的性能超越,用最小激活参数,撬动最大任务性能。为此,团队在多个维度上 “做减法” 也 “做加法”:
- 1/32 激活比例:每次推理仅激活 6.1B 参数,计算量远低于同性能 Dense 模型
- 专家粒度调优:细化专家分工,减少冗余激活
- 共享专家机制:提升通用知识复用率
- sigmoid 路由 + aux-loss free 策略:实现专家负载均衡,避免传统 MoE 的训练震荡
- MTP 层、QK-Norm、half-RoPE:在建模目标、注意力机制、位置编码等细节上实现经验最优
最终结果是:6.1B 激活参数,带来约 40B Dense 模型的等效性能,实现 7 倍以上的性能杠杆。

换句话说,6.1B 的激活参数,带来了接近 40B Dense 模型的实际表现,而在日常使用上推理速度却提升了 3 倍以上,在 H20 平台上可实现 200+ tokens/s 的高速生成,输出越长,加速优势越明显。

1/32 激活比例 + 7 倍性能杠杆,这一 “以小博大” 的背后,是 Ling 团队在 MoE(Mixture of Experts)架构上的深度探索。
强大的复杂推理能力
为了全面评估 Ling-flash-2.0 的推理能力,蚂蚁百灵大模型团队在模型评估中覆盖了多学科知识推理、高难数学、代码生成、逻辑推理、金融与医疗等专业领域,并与当前主流模型进行了系统对比。从下面的多个榜单分数对比可以看出,Ling-flash-2.0 不仅优于同级别的 Dense 模型(如 Qwen3-32B、Seed-OSS-36B),也领先于更大激活参数的 MoE 模型(如 Hunyuan-A13B、GPT-OSS-120B)。


尤其在以下三类任务中表现尤为突出:
- 高难数学推理:AIME 2025、Omni-MATH
得益于高推理密度语料 + 思维链训练的预训练策略,Ling-flash-2.0 在高难数学推理 AIME2025、Omni-MATH 数学竞赛级题目中展现出稳定的推理链路与多步求解能力。
- 代码生成:LiveCodeBench、CodeForces
在功能正确性、代码风格、复杂度控制方面,Ling-flash-2.0 表现优于同规模模型,甚至在部分任务中超越 GPT-OSS-120B。
- 前端研发:与 WeaveFox 团队联合优化
通过大规模 RL 训练 + 视觉增强奖励(VAR)机制,模型在 UI 布局、组件生成、响应式设计等前端任务中,实现了 “功能 + 美学” 的双重优化。
二、不只是 “跑分”:代码生成、前端研发、推理优化全面突破
Ling-flash-2.0 的性能优势不仅体现在 “跑分” 上,更在多个实际应用场景中展现出强大能力。
丰富的用例展示
1. 代码生成与编辑
prompt1:
编写一个 Python 程序,实现10个小球在旋转六边形内部弹跳的效果。球应受到重力和摩擦力的影响,并且必须真实地碰撞旋转的墙壁。
prompt2:
提示
Traceback (most recent call last):
File "/Users/zzqsmall/Documents/code/test.py", line 131, in <module>
if is_point_in_hexagon(x, y, hex_center, hex_radius):
NameError: name 'is_point_in_hexagon' is not defined
看看哪里错了
prompt3:
输出下修改后的完整代码
prompt4:
需要考虑球和球之间的碰撞,再优化下现在的代码实现
2. 前端研发
在前端研发方面,Ling 团队携手 WeaveFox 团队,基于大规模强化学习全面升级 Ling-flash-2.0 的前端代码生成能力,为开发者打造更强大的智能编程体验。
- WeaveFox 生成:计算器生成
Prompt:做一个计算器,采用新粗野主义风格,大胆用色、高对比度、粗黑边框(3-4px)和强烈的阴影。通过原始的字体和略微不对称的布局,营造一种刻意“未经设计”的美感。按钮应采用粗边框和强烈的色彩对比度。避免使用渐变和微妙的阴影,而应采用鲜明大胆的设计元素。,时长00:23
- WeaveFox 生成:旅游攻略网站制作
Prompt:制作一个多语言旅游攻略网站 - 提供不同国家和城市的旅行指南,用户可以分享自己的旅行经验和照片。,时长00:20
- 模型直出:网页创作
Prompt:创作一个万相 AIGC 模型的海外 Landing page,黑色风格,搭配渐变紫色流动,体现 AI 智能感,顶部导航包括 overview、feature、pricing、contact us
- 模型直出:贪吃蛇
prompt:帮我写个贪吃蛇小游戏
3. 数学优化求解
- 数独问题
下面是一个数独问题,请你按照步骤求解:
1. 建模成运筹优化问题,给出数学模型。
2. 编写能够求解的 pyomo 代码。
问题是:
|_ _ _|_ _ 2|9 3 _|
|_ _ _|_ _ _|_ 1 5|
|_ 4 6|_ _ _|_ _ 7|
-------------------
|_ 6 _|8 _ 4|_ _ 9|
|_ _ 8|1 _ 7|6 _ _|
|4 _ _|2 _ 9|_ 5 _|
-------------------
|3 _ _|_ _ _|2 9 _|
|7 9 _|_ _ _|_ _ _|
|_ 2 5|3 _ _|_ _ _|,时长00:19
4. CLI 接入
Ling-flash-2.0 模型可以方便的融合进去 Qwen Code 等 CLI 服务中,只需要在环境变量(.bashrc, .zshrc)中加入以下变量
export OPENAI_API_KEY="自己的key"
export OPENAI_BASE_URL="提供服务的url"
export OPENAI_MODEL="Ling-flash-2.0",时长00:08
三、20T 语料 + 三阶段预训练:打造高质量基础模型
Ling-flash-2.0 的优异表现,离不开其扎实的预训练基础。百灵大模型团队构建了一套基于统一数据湖宽表设计的 AI Data System,支持样本级血缘管理,完成了 40T+ tokens 的高质量语料处理,并从中精选出最高质量的部分用于支持 Ling-flash-2.0 的 20T+ tokens 的预训练计划。
为了充分提升模型的知识压缩和基础推理能力,百灵大模型团队将预训练分成 3 个阶段:
- Pre-training Stage 1:10T tokens 高知识密度语料,夯实知识基础
- Pre-training Stage 2:10T tokens 高推理密度语料,提升推理能力
- Mid-training Stage:扩展至 32K 上下文,引入思维链类语料,为后训练做准备
训练过程中,关键超参数(如学习率、batch size)均由百灵大模型团队自研的 Ling Scaling Laws 给出最优配置。此外,团队还创新性地将传统的 WSD 学习率调度器替换为自研的 WSM(Warmup-Stable and Merge)调度器,通过 checkpoint merging 模拟学习率衰减,进一步提升了下游任务表现。

为增强多语言能力,Ling 2.0 将词表从 128K 扩展至 156K,新增大量多语言 token,并在训练中引入 30 个语种的高质量语料,显著提升了模型的跨语言理解与生成能力。
四、后训练创新:解耦微调 + 演进式 RL,让模型 “会思考”,也会 “说话”
高效推理能力只是起点,百灵大模型团队更希望打造一款 “能思考、能共情、能对话” 的模型,实现 “智理相济,答因境生”。
为此,团队设计了一套四阶段后训练流程:

1. 解耦微调(DFT):双模式能力奠基
通过完全解耦的系统提示词设计,模型在微调阶段同时学习 “即时回答” 与 “深度推理” 两种模式。微调数据涵盖数理科学、创意写作、情感对话、社科哲思等多个领域,并引入金融建模、工业调度、供应链优化等数学优化任务,赋予模型解决实际问题的能力。
2. ApexEval:精准筛选潜力模型
在 RL 前,团队提出 ApexEval 评测方法,聚焦模型的知识掌握度与推理深度,弱化格式和指令遵循,筛选出最具探索潜力的模型进入强化学习阶段。
3. 演进式 RL:动态解锁推理能力
在 RL 阶段,模型以简洁思维链为起点,根据问题复杂度动态 “解锁” 更深层的推理能力,实现 “遇简速答、见难思深” 的智能响应。
针对代码任务,团队统一采用测试用例驱动的功能奖励机制,并创新引入视觉增强奖励(VAR),对前端任务的 UI 渲染效果进行美学评估,实现功能与视觉体验的协同优化。
在开放域问答中,团队构建了组内竞技场奖励机制(Group Arena Reward),结合 RubriX 多维度评价标准,有效抑制奖励噪声,提升模型的人性化与情感共鸣能力。
4. 系统支撑:高效奖励系统保障训练质量
后训练奖励系统由奖励服务调度框架、策略引擎、执行环境三部分组成,支持异步奖励计算、GPU 资源时分复用,支持 40K 并发执行,为高质量数据筛选与模型迭代提供底层保障。
结语: 高效大模型的未来,不是 “更小”,而是 “更聪明”
Ling-flash-2.0 的意义,不在于 “参数小”,而在于重新定义了 “效率” 与 “能力” 的关系。
它用 6.1B 激活参数告诉我们:模型的智能,不止于规模,更在于架构、训练与推理的协同优化。
在 “参数即能力” 的惯性思维下,百灵大模型团队用 Ling-flash-2.0 提供了一种可部署、可扩展、可演进的新范式。
即:模型的智能,不止于规模,更在于架构、数据与训练策略的深度融合。
此次开源,Ling 团队不仅放出了 Ling-flash-2.0 的对话模型,也同步开源了其 Base 模型,为研究者和开发者提供更灵活的使用空间。
Base 模型在多个榜单上已展现出强劲性能,具备良好的知识压缩与推理能力,适用于下游任务的进一步微调与定制。
随着 Ling-flash-2.0 的开源,我们有理由相信,高效大模型的时代,已经到来。
Ling-flash-2.0 可在以下开源仓库下载使用:
- HuggingFace:https://huggingface.co/inclusionAI/Ling-flash-2.0
- ModelScope:https://modelscope.cn/models/inclusionAI/Ling-flash-2.0
- GitHub:https://github.com/inclusionAI/Ling-V2
.....
#FireRedASR
没想到,音频大模型开源最彻底的,居然是小红书
不难发现,近几个月,开源频频成为 AI 社区热议的焦点。尤其是对于国内科技公司来说,开源成为主旋律。根据 Hugging Face 中文 AI 模型与资源社区的数据显示,国内厂商在七八月接连开源 33 款、31 款各类型大模型。
这些开源成果大多落在了文本、图像、视频、推理、智能体以及世界模型领域,而音频生成占比很小。

图源:zh-ai-community
一方面是因为音频生成在技术和数据上面临着特殊挑战,音频信号的计算和建模复杂,数据获取难度更大;另一方面,出于安全、版权等风险的考量,OpenAI、ElevenLabs 等主流玩家大都选择闭源或半开源。
直到今年尤其最近一波开源潮掀起以来,AI 音频领域又热闹了起来,包括字节 MegaTTS3、阿里 Qwen2.5-Omni-7B 和 CosyVoice 3、月之暗面 Kimi-Audio、阶跃星辰 Step-Audio 2 等。
在这些国内大厂和人工智能新势力之外,我们发现,自去年开始,来自小红书的技术团队在音频领域保持了稳定的开源节奏。他们推出了一系列成果,逐步构建起了系统级音频能力,并以开放的姿态将这些成果向社区开放。
这些成果中既有 TTS(文本转语音)方向的 FireRedTTS,也有 ASR(语音识别)方向的 FireRedASR,在当时取得了 SOTA 级别的效果。在实现研究突破之外,模型也具备工业级可商用属性,在关键指标上满足了实际应用需求,并通过开放许可降低商用落地门槛。
因此,发布之后,这些模型吸引了 AI 社区大量研究者与开发者的关注与好评。很多用户在实际项目中直接部署使用并二次开发,可用性和工程化潜力得到了验证。

对于小红书来说,开放高质量音频模型不仅可以提升其在这一细分赛道的技术影响力与话语权,也释放出一个明确的信号:将开源作为长期战略来布局。通过一系列技术开放,小红书正在构建起高粘性的音频大模型开源社区。
就在过去几天,小红书智创音频团队(FireRed)又放出了多项最新开源成果。
SOTA 级音频能力持续注入开源社区
系统级音频能力并非简单地依靠堆砌模型,而需要跨越多重技术门槛。无论是语音合成还是语音识别,都要求在延迟、准确率、自然度、真实性与鲁棒性等维度进行持续优化。
小红书对音频大模型的探索始于去年 9 月开源的 FireRedTTS 语音合成系统,构建了一套由数据处理、基座系统与下游应用组成的基座语音合成框架,先训练基座模型以将文本序列转换为自然、有表现力的语音序列,后利用上下文学习、监督微调等方法高效地服务于配音、自然对话等下游应用。
效果十分显著:只需要一段给定文本和几秒参考音频,无需二次训练,FireRedTTS 就可以模仿任意音色、任意说话风格,比如搞怪风、女友风等,实现自由定制。
今年 2 月开源的 FireRedASR 在语音识别上带来新突破,这类技术广泛应用于智能语音交互(如语音助手)与多模态内容理解场景。该系列包含两个模型,FireRedASR-LLM 追求极致的语音识别精度,FireRedASR-AED 在保证语音识别准确率的同时兼顾推理效率。
结果显示,在 AISHELL-1/2、WenetSpeech 等中文普通话测试集上,FireRedASR 在关键指标字错率(CER)上取得了 SOTA。FireRedASR 的 CER 为 3.05%,优于豆包的闭源大模型 ASR 方案 Seed-ASR 的 3.33%,也优于阿里通义 9 月 8 号最新发布的闭源 Qwen3-ASR-Flash 的 3.52%。

目前,该模型已在 GitHub 上收获了 1.3k 的 star。
GitHub 地址:https://github.com/FireRedTeam/FireRedASR
延续 FireRedTTS 的 SOTA 级表现,新一代的 FireRedTTS-2 进一步瞄准了语音合成现有方案的痛点,包括灵活性差、发音错误多、说话人切换不稳和韵律不自然,在升级离散语音编码器与文本语音合成模型两大核心模块的基础上,为长对话语音合成提供了更优的解决方案。

FireRedTTS-2 架构概览。
FireRedTTS-2 主打上下文建模与多轮对话能力,在涉及音色克隆、交互式对话和播客生成的多项主客观测评中均实现了行业领先,让开源模型在复杂音频场景建模效果上达到新高点。
音色克隆只需提供对话中发音人的一句语音样本即可模仿其音色与说话习惯,自动生成后续整段对话;同时多说话人音色切换的稳定性与韵律自然度均处于开源模型 SOTA,为今年火热的 AI 播客场景提供了工业级解决方案,一跃成为当前最强开源播客生成大模型。

在 zero-shot 播客生成中,FireRedTTS-2 全面优于 MoonCast、ZipVoice-Dialogue、MOSS-TTSD 等开源竞品。
听完下面一段关于「Taylor Swift 恋爱消息」的双人多轮对话播客,你能分得清是真人录音还是 AI 合成吗?
以下视频来源于
小红书技术REDtech
,时长03:27
目前,FireRedTTS-2 可以支持 4 位说话人的多轮对话生成,还可以通过扩展数据进一步扩展至更多说话人和更长时长,从而根据实际需求进行快速适配。用户对这款新模型的反馈也不错。

- 论文地址:https://arxiv.org/pdf/2509.02020
- 代码地址:https://github.com/FireRedTeam/FireRedTTS2
另一大开源新成果是 FireRedChat—— 业内首个完全开源的全双工语音对话系统,它在智能判停与延迟等关键指标上也达到了开源 SOTA,端到端性能已接近工业级水准。
此次的亮点还在于:在提供完整模型之外,一站式提供 VAD、ASR、TTS、上下文感知 TTS、音频 LLM、Dify 支持等核心模块,支持私有化部署。这在业内迄今没有任何一家企业或机构将这样的一整套完整方案开源出去。
这就意味着,即使不是语音领域的专业人士,也可以直接克隆代码,快速部署一个自己的语音助手,例如豆包的「打电话」语音对话助理。
基于内置的情绪感知与情感合成能力,通过 FireRedChat 构建的不是一个冷冰冰的机器人,而是一个「知冷暖、能共情、懂表达」的好朋友,她能细腻感知你的情绪变化:在你失落时,轻声安慰、真诚鼓励;在你遇到惊喜时,和你一样心潮澎湃、享受 surprise;在你开心时,陪你分享喜悦、一起欢笑。
FireRedChat 让 AI 聊天助手不只是回应文字,更能用富有温度的声音、情感和表达方式,带给你一种被理解、被陪伴的真实感受,让 AI 真正拥有「人感」。
,时长03:12
短短一年时间,小红书围绕文本转语音、语音识别和语音对话形成了比较完整的技术栈,并已经探索出一些好玩的功能,比如以 FireRedASR 技术为支撑的语音评论,通过唱歌、说方言、模仿有梗台词等一系列新的玩法,让评论区的互动性与趣味性更浓,也提升了用户粘性。

音频开源的「执牛耳者」
从小红书已经开源的一系列音频大模型中,我们看到了其对开源生态的长期承诺与战略耐心。
一方面,几乎覆盖了语音交互的核心环节,从 TTS、ASR 到语音对话,技术矩阵日趋完善。由点及面的布局,显示出其在技术积累上的底气,利用系统性开源降低行业准入门槛,形成生态级的牵引力。
未来,小红书还计划推出音乐大模型 FireRedMusic、多语种高精度语音识别系统 FireRedASR-2 以及音频感知大模型,让更多细分方向的开发者用上高质量模型。
另一方面,开源正在从模型层走向体系层,不再只是停留在单一模型的开放,而是扩展到了全链路模块。这意味着,开源的价值上升到了提供系统化能力。
以全双工语音对话系统 FireRedChat 为例,VAD、ASR、TTS、对话框架等在内基础模块的开放,降低了开发者的集成与部署门槛,使他们在开箱即用的基础上快速构建应用,进而扩大音频生态的创新边界。
通过开源这个推动技术演进与生态共建的关键支点,小红书的开源「野心」已逐渐显现。
小红书智创音频团队负责人解奉龙称,他们的目标是建立首个工业级可商用的音频大模型开源社区,涵盖语音识别及理解、语音 / 音效生成、全双工语音交互、音乐理解及生成四大方向,一步步将自身打造成为开源音频领域的「执牛耳者」。
这些模型具备的工业级可商用属性将释放更大的价值。开发者和企业用户在生产环境中直接部署与使用,大大缩短从技术到产品的周期,降低试错成本。
随着语音交互赛道的参与者越来越多,应用创新与落地场景更丰富,反过来又将进一步扩展以小红书为主导的音频开源社区。
小红书智创团队负责人汤旭表示,团队将持续深耕多模态大模型,勇于突破 SOTA 边界,探索 AI 在内容理解与创作中的更多可能。我们坚持开放共享,通过开源生态与全球开发者协同进化,共同推动行业标准演进,让 AI 不仅赋能小红书,更为全球创作者创造价值,开启内容生产的新范式。
写在最后
作为一种正在重塑行业格局的力量,开源让先进的 AI 能力不再被少数巨头垄断,而是沉淀为整个行业可以共享的底层资源。
从八年前的 Transformer,到年初的 DeepSeek,再到前一段的 Qwen,开源一直都是推动大模型技术跃迁的关键因素之一。在共享基线之上,开发者可以进行低成本地差异化探索。
AI 大厂选择「闭门造车」,本质上是通过技术壁垒构筑护城河,并以此维持商业模式的可持续性和竞争优势,如 OpenAI 等。在资本驱动与市场回报的逻辑下,这种路径无可厚非。然而,推动产业加速演进往往不单靠这些巨头的独角戏,更在于开源社区的多点突破与百花齐放。
在开源生态中,模型、框架和工具可以快速迭代、自由组合,通过更多创新尝试,加快新技术落地。尤其是在 AI 应用的长尾场景中,整个社区的广泛参与更有潜力让 AI 真正从实验室走向产业化。
小红书正在用自己一次次的开源践行这一切,持续推动音频大模型的技术演进,向所有人释放前沿能力,并希望通过更大的开源社区共建实现技术平权。这些 SOTA 级音频大模型为开发者和中小型企业提供了平等的技术起点,让他们在同一基准线上进行创新与应用开发。
在开源生态主导权上的长远布局,可以为小红书在未来的 AI 音频市场竞争中抢占先机。
除了音频, 小红书智创团队还在多模态、AIGC、CV、编辑渲染、算法工程等方向多有建树,并向公司内部社交、直播、电商、商业化广告和生态审核在内的各业务线提供业界领先的技术解决方案,成功落地了语音评论、文字功能等爆款功能。
目前,小红书校招正在进行中,加入智创团队,一起挑战 AI 前沿技术,推动开源生态的未来。
...
#InternVLA·N1
上海AI实验室开源首个端到端双系统导航大模型|长程空间推理与敏捷执行的有机融合
上海人工智能实验室开源的首个端到端双系统导航大模型 InternVLA·N1。该模型基于“书生”xx全栈引擎构建,实现了长程空间推理与敏捷执行的有机融合,能在实际应用中实现跨场景、跨本体的零样本泛化。
9月15日,上海人工智能实验室(上海 AI 实验室)开源首个端到端双系统导航大模型 InternVLA·N1。
InternVLA·N1基于『书生』xx全栈引擎Intern-Robotics构建,实现了高层远距离目标空间推理规划和底层敏捷执行的双系统解耦。以纯合成数据驱动异步架构的两阶段课程训练,让InternVLA·N1不仅保留了更强的语义理解和长程指令跟随能力,还可与高频动态避障策略有机融合。性能表现上,InternVLA·N1在6个主流基准测试中的得分达到国际领先水平;实际应用中,该模型可以60Hz的连续推理效率实现跨场景、跨本体的零样本泛化。
,时长01:30
技术报告:
https://internrobotics.github.io/internvla-n1.github.io/static/pdfs/InternVLA_N1.pdf
项目主页:
https://internrobotics.github.io/internvla-n1.github.io/
InternVLA·N1 Huggingface 链接:
https://huggingface.co/InternRobotics/InternVLA-N1
InternData·N1 Huggingface 链接:
https://huggingface.co/datasets/InternRobotics/InternData-N1
代码 GitHub 链接:
https://github.com/InternRobotics/InternNav
亮点速览:
- 端到端双系统导航大模型架构:以最远可见像素目标点作为导航大模型双系统初始化训练的中间媒介,在联调阶段免除人为先验,引入可学习隐式规划表征,异步联调和推理实现双系统联合优化和紧密协同。
- Intern-Robotics 开源全栈引擎底层支持:基于桃源仿真引擎和多源场景资产,以基于传统优化策略的轨迹合成和自动化拆分标注管线为核心构建起数据引擎,形成目前场景最丰富的大规模导航数据集 InternData·N1;构建训测工具链 InternNav 全流程支撑双系统不同阶段迭代需求,涵盖传统评测 Habitat VLN-CE R2R/RxR 和基于 Isaac Sim 物理仿真评测 VLN-PE 等。
- 纯仿真训练,60Hz 异步推理真机零样本泛化:InternVLA·N1 在大模型空间推理规划(R2R-CE/RxR-CE)、泛化执行避障(ClutteredEnv/InternScenes-100)、端到端全系统执行(VLN-PE-Flash/VLN-PE)等6个主流基准上领先;通过端到端从数据合成到真机部署的协同优化,仅使用合成数据训练,真实场景部署即可实现 60Hz “跨楼宇长距离”听令行走和密集障碍物间敏捷避障的丝滑融合。

图1:InternVLA·N1 的主要特性展示:系统2长时序空间推理退化和系统1敏捷执行的有机融合,在6个主流基准上实现了3%-28%的性能提升
创新双系统架构,实现长程空间推理与敏捷执行有机融合视觉语言导航是xx智能体基础能力之一。受限于基准的设置和有限的模型方法尝试,当前大部分工作采用大模型直接预测离散的动作空间(向前,左转15°,右转15°,停止),忽略了大模型的长程推理规划能力,同时限制了导航模型的移动能力和执行效率。
InternVLA·N1 则针对性设计了更加符合直觉的双系统架构:多模态大模型理解语言指令,并根据视觉观测低频地在图像上预测下一步执行的目标像素;另有一个导航扩散策略网络给定目标像素,负责高频响应敏捷避障并确保能够准确到达目标点。其中,目标像素作为连接双系统的要点,如何自动化标注也影响了模型的预训练有效性。考虑到不同规划长度的歧义性,像素点的标注在设计中统一设置为可视范围内能看到真值路径上最远可达的点,当这一点不存在于目标视角时,会设置当前行为为相应转向。
基于这种设置,双系统大模型的训练共分两个阶段:
(1)预训练阶段:多模态大模型(系统2)给定转向/移动到目标像素的规划拆解真值进行监督微调,导航扩散策略(系统1)给定目标像素和轨迹真值学习避障执行到目标点的移动能力;
(2)联合微调阶段:固定多模态大模型,在系统 2 输入侧插入 learnable queries,让系统 2 除了可以输出显式的语言和目标外,额外生成 latent plans 作为 goal condition 传至系统 1,以端到端的语言指令输入-轨迹输出作为监督微调连接层和系统1,实现更优的双系统协作。
为了实现异步执行的最优效果,系统1可以给定同一个时刻的 latent plans 和不同时刻的观测学习不同时刻的执行策略,由此实现训练和推理时的一致性。值得一提的是,这种范式还可以进一步延伸通过增加一个世界模型作为预测式解码器进行视频生成预训练,利用海量的、无需人为先验引入标注的真实视频数据可扩展地训练得到更好的 latent plans(实验发现可提升双系统联调效率50%),使得模型可以更好更快地适应动态环境,并实现真实环境的泛化。

图2:InternVLA·N1 的端到端双系统架构
构建大规模多元场景导航数据集,Sim2Real 零样本泛化
导航大模型的训练离不开高质量多元化的场景数据和可扩展的数据飞轮。因此,团队广泛收集了开源的场景数据集构造了目前场景最多元的大规模导航数据集 InternData·N1,涵盖了HM3D、3D-Front、Gibson、HSSD、Matterport3D、Replica 等主流场景数据,以自动化可扩展的数据管线构建了包含超过 5000 万帧第一视角图像、4839公里导航里程的大规模数据集。另外,面向不同阶段和系统的训练需求,团队进一步推出了 VLN-CE 和 VLN-N1 两个数据子集。
其中 VLN-CE 子集面向 HM3D 相应的 benchmark,基于自建轨迹合成管线进行了相应的轨迹数据优化,并面向目标像素的标注进行了片段切分和自动化标注,主要用于系统2的预训练和双系统联调;另一方面 VLN-N1 子集基于多元的场景数据,主打场景的多元性,轨迹合成也充分加入视角、光照的随机化增强,通过大模型的自动化指令标注、改写和筛选管线构造了一批更多元化的轨迹数据,主要用于系统1的预训练和双系统联调泛化性的加强。
VLN-N1 的数据合成共分成三个阶段:
(1)轨迹数据渲染合成:基于场景资产、全局地图和本体信息,通过传统运控方法设置规则合成相应的轨迹数据;
(2)语料标注和改写:通过大模型对轨迹视频进行语言描述,形成初版指令,再根据需求微调和改写语言指令;
(3)数据筛选:通过轨迹中涉及有意义语义信息/物体数量进行打分,分三档滤除分数为0的数据,最终筛选了23%的低质量数据。经验证,筛选掉数据并未影响模型性能的同时,显著降低了训练成本;同时,多元场景使得模型性能以可扩展的方式持续提升。

图3:InternData·N1中的VLN-N1子集的数据构造流程

图4:InternData·N1中的VLN-N1子集的数据分布统计
训练-评测、规划-控制联合优化,软硬协同高效迭代模型性能
具备基础的数据并训练出导航大模型后,一套系统的评测基准和真机部署方案才能最终实现模型的高效迭代和落地应用。由此,面向双系统的评测,一方面团队在传统 R2R 和 RxR 基准上实现了双系统方案和端到端离散预测+最短路径执行的直接比较,方便有一个相对直观的性能比较结果;另一方面,面向连续轨迹控制以及和物理世界更加一致的评测需求,构造了一套基于 Isaac Sim 物理仿真的评测机制,具体包括面向系统1各种目标的视觉导航评测基准(杂乱环境 ClutteredEnv 和桃源场景 InternScenes-100),面向整体系统考虑本体运动的基准 VLN-PE,提供了更多元场景和更全面的系统评测方法,进一步加速模型的有效迭代。


图5:InternVLA·N1 双系统在传统 VLN-CE 和物理仿真评测 VLN-PE 中的推理示例。对应语言指令分别为“离开浴室进入卧室,从卧室出去到走廊,在楼梯上面等待”、“经过厨房从右边进入房间,路过桌子和椅子停在沙发前”

图6:系统1在物理仿真评测(InternScenes-100)中的推理示例,从左到右依次为推理第一视角、目标达到的第一视角图像、实时推理轨迹
在真机部署方面,以宇树机器狗 Go2 为例,首先在视觉传感器方面采用 Intel Realsense D455 以实现移动过程中较优的图像清晰度,进一步对齐高度(0.6米)和朝向(斜向下15°)以保证和仿真评测效果的相对一致性;在机器人本体控制和模型推理方面,InternVLA·N1 输出的轨迹通过定位信息转换到世界坐标系并通过 MPC 控制器进行跟踪,模型方面通过系统2在多轮对话时的 KV-cache 机制优化和系统1的 TensorRT 部署,分别可在单卡 RTX 4090 上实现 2Hz 和 30Hz 的实际推理速度,进而通过异步机制可实现综合推理速度近 60Hz,再通过 200Hz 的控制器跟踪轨迹,由此也可看出双系统推理机制在敏捷反应上相比纯系统2大模型的显著优越性。这一推理效率可通过模型结构等方式进一步优化,配合端侧芯片以实现更优的部署应用体验。


图7:真机测试比较示例:InternVLA·N1 能以更丝滑的推理过程和更快的执行速度,在长程导航任务中完成敏捷避开障碍物的同时更好地完成指令跟随
当前,以导航大模型 InternVLA·N1 为代表的全链条数据集-训测工具链已全部开放。其中,包含三部分子集 VLN-N1、VLN-CE 和 VLN-PE 的全量数据集 InternData·N1 已开源至 Hugging Face 和魔搭社区,同时提供 mini 版本以方便社区开发者更轻量化地进行体验。训测工具链 InternNav 除了支持了最新版本的 InternVLA·N1 预训练模型的推理和测试外,同时系统性支持了双系统各模块(系统1/2)、不同平台(Habitat,Isaac Sim)主流和自建6个数据集、10余种 baselines 的训练和闭环评测,欢迎广大开发者体验。
...
#强化学习的新突破
无需标注!大语言模型的“内生奖励”机制
本文用“逆强化学习”视角拆解大模型奖励:把 logits 直接变成 Q 函数,让模型能够自我评估并给予奖励,无需依赖人类标注,这种方法不仅在数学推理等任务上取得了与传统强化学习人类反馈(RLHF)相当甚至更好的效果,显著降低了奖励模型(RM)标注的成本,使强化学习能够更广泛地应用于开放任务。
众所周知,在强化学习训练中的关键环节就是奖励信号的获取,准确的奖励信号对于训练的效果至关重要。在经典RL 中,奖励信号可以看作环境的一部分 —— 即行动后环境的真实反馈,而在 RL 训练 LLM 中,奖励值的来源主要有两种方式:
- 批判式:即 RLHF 中的 RM,该方式给出的是一个连续的标量值,但是由于 OOD 的问题,在一些样本上可能结果并不准确;
- 验证式:即 RLVR 中的 Verifier, 通过与预设的答案或规则相比较,给出一个二元值,这种方式仅适用于有标准答案的场景,而在开放问题中则不太适用
而无论是以上的哪种情况,其奖励值都是旁证式的、外在的,那么在 LLM 与上下文构成的环境中,是否存在内在的奖励呢?即谜底是否存在在谜面上呢?本文将围绕该问题展开讨论,具体问题包括:
- 为什么会有内在奖励,其底层逻辑和原理是什么?
- 内在奖励的形式有哪些,受哪些因素影响?
- 内在奖励的准确度如何,与外在奖励相比怎样?
01 隐式奖励角度
在 LLM 后训练领域主要存在两种方法论途径:
- 第一种途径是SFT,通过专家演示学习,或模仿学习, 使用正样本来训练模型。
- 第二种途径侧重于从环境信号中学习,主要通过强化学习方法 (PPO, GRPO 等)
在两种路径之间,还有一种特殊的方法 DPO,一方面相较于 SFT,DPO 增加了负样本和隐式奖励学习;另一方面相较于 RL,DPO 的训练数据又是完全 off-policy 的, 且省略了显式的奖励信号的训练过程, 下面我们尝试一探究竟。
1.1 DPO 及其隐式奖励
事实上,最早提出隐式奖励的工作就是 DPO 了,接下来我们还是不厌其烦地梳理一下其中的核心过程及要点。
RLHF 的损失可表示为:
提取常数 并应用恒等变换,有:
这样的话实际上构造出来了一个新的分布,即:
其中 是一个归一化常数,确保 是一个合适的概率分布(即概率之和为 1 ):
虽然这个针对 的解决方案本身是不可解的,但它可以用来将奖励表示为最优策略的函数,即得到最优策略后就可以反解出奖励模型,该解只需要对上述公式稍加变换即可:
这样,从定义整体对齐目标,到推导最优策略,最终将奖励模型与对齐模型连接起来,而不需要直接训练奖励模型。
1.2 理解隐式奖励
上文中,我们得到了奖励与最优模型的基本关系,在此基础上有很多工作进行了更多细化,在此不加证明地介绍引文[8]中的结论,即
其中 代表 LLM 的输入输出对 的奖励, 是最优策略, 是最优策略的价值函数。
初始奖励 可以被视为 ,对所有 适用,在此假设下,初始策略 是相对于初始奖励的最优策略。稍微对上式进行变化可得到 SFT 形式的目标,即:
由此可知,SFT 过程沿着最优策略-奖励子空间进行搜索,试图对专家演示中隐含的奖励进行建模。在优化过程中,模型迭代的过程,也即策略-奖励的最优子空间的搜索过程。
采用该方案进行 RL 训练的典型案例即 PRIME,即通过以下方式获得过程奖励:

这样的好处是显而易见的,即可以通过收集 response-level 数据并训练一个 ORM 来简单地获得 PRMs,而无需高成本的数据标注。
值得一提的是 ORM 的损失函数,与正常的 ORM 训练一样,唯一的不同是将 替换为 ,即
在训练过程中,策略模型和 PRM 都使用 SFT 模型进行初始化。在每个 RL 迭代中,策略模型首先生成 rollouts。然后,隐式 PRM 和结果验证器对 rollouts 进行评分,隐式 PRM 在 rollouts 上使用结果奖励进行更新。最后,结果奖励 和过程奖励 被结合并用于更新策略模型。
总结一下,此类隐式奖励是通过 策略模型或者 impolicity PRM 与 SFT 相比较产生的,其奖励的是相比 SFT 获得更高分数的 token,换句话说,该方式会加强 SFT 中的行为,使得在最终模型中的概率分布更加集中。
02 逆强化学习角度
在经典的使用 RL 训练 LLM 的流程中,其过程是:SFT -> RM (verifier) -> PPO (GRPO) , 当缺少 rule-based verifier 时,该流程关键依赖于在人类偏好上训练的奖励模型(RM)来评分模型输出,最终对齐的 LLM 的质量基本上由该 RM 的质量决定。而训练 RM 需要构建大规模、高质量的人类偏好数据集,这是缓慢、昂贵且难以扩展的。
那么如果不去构造偏好数据集是否还可以得到准确的奖励信号呢?在上节中,我们提供了一种基于DPO 方式的隐式奖励,本节中我们将尝试通过另一个角度,即逆强化学习的方式来审视这一过程。
2.1 逆强化学习原理与 LLM 奖励信号建模
RL 是给定交互环境与奖励函数 后求解一个最优策略 使得期望累积奖励最大化。而逆强化学习(Inverse Reinforcement Learning,IRL)则相反:假设我们有一批采集于专家策略 (可看作最佳策略)的离线轨迹数据 ,希望找到一个奖励函数 来解释数据中的行为,即认为专家策略 的生成是通过一个内在奖励函数 得到的。
求解IRL的核心在于建立从奖励函数 到专家策略 的映射,从而通过专家数据求解反问题来恢复 。典型的求解方法有两种:
- 一种是直接概率建模,即通过线性规划来直接建模\pi_E在r_E下的MDP的在最优性, 典型方法即最大熵逆强化学习;
- 一种则是最大边际算法, 即最大化\pi_E的值函数与其他策略的值函数的差距来建立最优性, 典型方法即最大边际逆强化学习。
2.1.1 最大熵逆强化学习
通过寻求一个既能够合理解释专家演示结果,同时对数据中未明确体现的行为保持最大程度中立态度的奖励函数,从而解决了多种奖励函数均可解释同一行为所导致的模糊性问题。这导致了一个极小极大优化问题:
其中,期望 是基于专家策略 (由数据集 近似)的轨迹分布计算的,而期望 是基于学习到的策略 生成的轨迹分布计算的。此外 表示 的熵, 是正则化系数。目标是在相同的奖励 下,寻找一个奖励函数 ,使得专家的预期回报与最优策略 的熵正则化回报之间的差距最大化。
接下来尝试求解以上问题。一种方法是inverse soft Q-learning,即寻找一个能够最好地解释静态数据集 中专家数据的 Q 函数。目标是解决以下优化问题:
一旦我们找到最大化该目标的最佳 函数 ,则可以通过逆软贝尔曼算子恢复相应的理想奖励函数 :
那么 该如何求解呢?事实上,它已经体现在任何使用标准下一个词预测目标训练的语言模型的 logits 中。
公式(2)中的目标函数可以通过变换,表示为一个最大似然问题:
其中策略 这正是通过 NTP 来训练语言模型的目标。在训练过程中,语言模型 会被优化以最大化数据的对数似然,即 。由此产生的策略 按定义是数据生成分布的最大似然估计,即被参数化为模型 logits 上的 softmax。
通过这种方式,LLM 的输出 logits 直接是式(3)中 irl 优化问题的 Q 函数的有效解。即语言模型的 logits 不仅仅是随机的分数,还是一种原则性的 Q 函数,隐式地表示模型训练所用数据的最佳奖励函数,这一观点在引文 中都有所证明。
现在令 ,代入公式(3)则有:
可以看到这个结果与第一节中推导的结果殊途同归,所不同的是该结果中都不需要参考模型了。
总结一下:
1.任意一个 LLM 的token 生成策略 ,都可以对 logit 函数 通过逆强化学习诱导出一个内在奖励
使得 满足贝尔曼最优方程。
2.给定任意一个LLM生成策略 ,在其诱导出来的内在奖励 上进行 RL 训练,本质上优化的是
会将策略 与 的高概率分布对齐。因此 本质上提供了一个模仿 生成的 token- level 奖励。
3.内在奖励 的好坏,依赖于 的生成质量的好坏。因为 的高奖励区域是 的高概率区域,这就与第一节中的隐式奖励产生了完美的呼应。
2.2 RLPR:无参考策略
理解了上述论证的过程,我们就理解了内生奖励的核心,细心的读者可能也会意识到所谓的“内生”却仍然依赖于一个参考策略,那么这个参考模型是否可以去除呢?RLPR 做了这方面的重要尝试,下面我们来一探究竟。
RLPR的思想源于这样一个认知:模型给 正确答案 的 token 概率高,给 错误答案 的概率低, —— 这个 内在置信度 本身就是对“推理好坏”的自然评价。因此,RLPR直接用 参考答案 token 的平均概率 当奖励,无需外部验证器。
尽管这个过程没有参考模型,但是却有参考答案,对于输入问题 ,输出答案前的推理内容 ,生成答案 ,参考答案 ,其奖励计算的过程如下:
- 用参考答案 替换 得到序列
- 前向一次模型,取 对应 token 的概率
- 计算奖励值 ,其中 长度归一化 避免长答案天然吃亏,均值而非连乘 减少长尾低概率 token 的方差
- 去偏,直接用 r 会受 prompt 或答案风格干扰。额外计算一次 无推理 时直接给出 的概率 ,用差值 只奖励因为推理 而带来的概率提升。
通过这种方式,RLPR 让 RLVR 走出“数学孤岛”,用 模型照镜子的方式 告诉自己“答得好不好”,从而在任何能写 prompt 的地方都能做强化学习。
参考资料
[1] [2505.19590] Learning to Reason without External Rewards
[2] RLPR: Extrapolating RLVR to General Domains without Verifiers
[3] Generalist Reward Models: Found Inside Large Language Models
[4] [2507.00018v1] Implicit Reward as the Bridge: A Unified View of SFT and DPO Connections
[5] 逆强化学习与内在奖励
[6] https://arxiv.org/abs/2507.07981
[7] Process Reinforcement through Implicit Rewards
[8] From r to Q*: Your Language Model is Secretly a Q-Function
[9] Explicit Preference Optimization: No Need for an Implicit Reward Model
[10] https://arxiv.org/pdf/2305.18290
[11] https://levelup.gitconnected.com/your-complete-guide-to-maximum-entropy-inverse-reinforcement-learning-c9d17b3144ac
...
#DeepResearch
通义DeepResearch震撼发布!性能比肩OpenAI,模型、框架、方案完全开源
通义 DeepResearch 重磅发布,让 AI 从 “能聊天” 跃迁到 “会做研究”。在多项权威 Deep Research benchmark 上取得 SOTA,综合能力对标并跑赢海外旗舰模型,同时实现模型、框架、方案全面开源,把深度研究的生产力真正带到每个人手里。
相比于海外的旗舰模型昂贵和限制的调用,通义 DeepResearch 团队做到了完全开源!开源模型,开源框架,开源方案!在 Humanity's Last Exam、BrowseComp、BrowseComp-ZH、GAIA、xbench-DeepSearch, WebWalkerQA 以及 FRAMES 等多个 Benchmark 上,相比于基于基础模型的 ReAct Agent 和闭源 Deep Research Agent,其 30B-A3B 轻量级 tongyi DeepResearch,达到了 SOTA 效果。

通义 DeepResearch 团队也在 Blog 和 Github 完整分享了一套可落地的 DeepResearch Agent 构建方法论,系统性地覆盖了从数据合成、Agentic 增量预训练 (CPT)、有监督微调 (SFT) 冷启动,到强化学习 (RL) 的端到端全流程。尤其在 RL 阶段,该团队提供了集算法创新、自动化数据构建与高稳定性基础设施于一体的全栈式解决方案。在推理层面,模型展现出双重优势:基础的 ReAct 模式无需提示工程即可充分释放模型固有能力;而深度模式 (test-time scaling) 则进一步探索了其在复杂推理与规划能力上的上限。
- Homepage: https://tongyi-agent.github.io/
- Blog: https://tongyi-agent.github.io/blog/introducing-tongyi-deep-research/
- Github: https://github.com/Alibaba-NLP/DeepResearch
- Hugging Face: https://huggingface.co/Alibaba-NLP/Tongyi-DeepResearch-30B-A3B
- Model Scope: https://modelscope.cn/models/iic/Tongyi-DeepResearch-30B-A3B
1 数据策略:基于全合成数据的增量预训练和后训练
模型能力的提升,主要得益于通义 DeepResearch 团队设计的一套多阶段数据策略。这个策略的核心目标是,不依赖昂贵的人工标注,也能大规模地生成高质量的训练数据。
1.1 增量预训练数据
团队引入了 Agentic CPT(增量预训练)来为模型打下坚实的 Agent 基础。为此,开发了一个系统化、可扩展的数据合成方案。它能利用后续训练流程产生的数据,形成一个数据生成的正向循环。
- 数据重组和问题构建 基于广泛收集和增量更新的知识文档、公开可用的爬虫数据、知识图谱以及后训练产生的轨迹数据和工具调用返回结果(例如,搜索结果和网页访问记录)等,团队构建了一个以实体为锚定的开放世界知识记忆。进一步,研究者基于采样的实体和相关知识构造多风格的(问题,答案)对,以尽可能涵盖智能体所面临的真实场景。

- 动作合成 基于多风格问题和历史轨迹数据,团队分别构建了三种类型的动作数据,包含规划、推理和决策动作。该方法能够在离线环境下大规模、全面地探索潜在的推理 - 动作空间,从而消除了对额外商业工具 API 调用的需求。特别地,对于决策动作合成,该研究将轨迹重构为多步骤决策过程,以增强模型的决策能力。
1.2 Post-training 数据
通义 DeepRsearch 团队开发了一套全自动的合成数据生成方案,旨在全自动化生成超越人工标注质量的数据集,以挑战模型的能力极限。这个方案经过了多次迭代,从早期的 WebWalker,到更系统的 WebSailor 和 WebShaper,数据质量和可扩展性都得到了保证。
为了生成能应对复杂问题的问答数据,团队开创性得设计了一个新流程。首先,通过知识图谱随机游走和表格数据融合等方式,从真实网站数据中提取信息,保证数据结构的真实性。然后,通过策略性地模糊或隐藏问题中的信息来增加难度。团队将问答难度建模为一系列可控的 “原子操作”,这样就可以系统性地提升问题的复杂度。
为了减少推理捷径,团队还基于集合论对信息搜索问题进行了形式化建模。这帮助他们以可控的方式生成更高质量的问题,并解决了合成数据难以验证正确性的问题。
此外,该团队还开发了一个自动化数据引擎,用于生成需要多学科知识和多源推理的 “博士级” 研究问题。它会让一个配备了网络搜索、学术检索等工具的代理,在一个循环中不断深化和扩展问题,使任务难度可控地升级。
2 推理模式
Tongyi DeepResearch 既有原生的 ReAct Mode,又有进行上下文管理的 Heavy Mode。
2.1 ReAct Mode
模型在标准的 ReAct 模式(思考 - 行动 - 观察)下表现出色。128K 的上下文长度支持大量的交互轮次,团队遵循大道至简,认为通用的、可扩展的方法最终会更有优势。
2.2 Heavy Mode
除了 ReAct 模式外,通义 DeepResearch 团队还开发了 “深度模式”,用于处理极端复杂的多步研究任务。此模式基于该团队全新的 IterResearch 范式,旨在将 Agent 的能力发挥到极致。
IterResearch 范式的创建是为了解决 Agent 将所有信息堆积在一个不断扩展的单一上下文窗口中时出现的认知瓶颈和噪音污染。相反,IterResearch 将一项任务解构为一系列 “研究轮次”。

在每一轮中,Agent 仅使用上一轮中最重要的输出来重建一个精简的工作空间。在这个专注的工作空间中,Agent 会分析问题,将关键发现整合成一个不断演变的核心报告,然后决定下一步行动 —— 是收集更多信息还是提供最终答案。这种 “综合与重构” 的迭代过程使 Agent 能够在执行长期任务时保持清晰的 “认知焦点” 和高质量的推理能力。
在此基础上,团队还提出了 Research-Synthesis 框架:让多个 IterResearch Agent 并行探索同一个问题,最后整合它们的报告和结论,以获得更准确的答案。

3 训练

打通整个链路,引领新时代下 Agent model 训练的新范式
通义 DeepResearch 团队对 Agent model 训练流程进行革新!从 Agentic CPT (contine pre-training) 到 RFT (rejected fine-tuning) 再到 Agentic RL (reinforment learning),打通整个链路,引领新时代下 Agent model 训练的新范式。
端到端 Agent 训练流程

Tongyi DeepResearch Agent 建立了一套连接 Agentic CPT → Agentic SFT → Agentic RL 的训练范式。下面重点介绍该团队如何通过强化学习来完成最后的优化。
- 基于策略的强化学习(RL)
通过强化学习构建高质量的 Agent 是一项复杂的系统工程挑战;如果将整个开发过程视为一个 “强化学习” 循环,其组件中的任何不稳定或鲁棒性不足都可能导致错误的 “奖励” 信号。接下来,团队将分享他们在强化学习方面的实践,涵盖算法和基础设施两个方面。
在强化学习(RL)算法方面,通义 DeepResearch 团队基于 GRPO 进行了定制优化。他们严格遵循 on-policy 的训练范式,确保学习信号始终与模型当前的能力精准匹配。同时,团队采取了一个 token 级别的策略梯度损失函数来优化训练目标。其次,为了进一步降低优势估计(advantage estimation)的方差,团队采用了留一法 (leave-one-out) 策略。此外,团队发现未经筛选的负样本会严重影响训练的稳定性,这种不稳定性在长时间训练后可能表现为 “格式崩溃”(format collapse)现象。为缓解此问题,他们会选择性地将某些负样本排除在损失计算之外,例如那些因过长而未能生成最终答案的样本。出于效率考虑,该团队没有采用动态采样,而是通过增大批次(batch size)和组规模(group size)的方式,来维持较小的方差并提供充足的监督信号。

训练过程的动态指标显示,模型学习效果显著,奖励(reward)呈持续上升趋势。同时,策略熵(policy entropy)始终维持在较高水平,这表明模型在持续进行探索,有效防止了过早收敛。团队人员将此归因于 Web 环境天然的非平稳性,该特性促进了稳健自适应策略的形成,也因此无需再进行显式的熵正则化。
通义 DeepResearch 团队认为,算法固然重要,但并非 Agentic RL 成功的唯一决定因素。在尝试了多种算法和优化技巧后他们发现,数据质量和训练环境的稳定性,可能是决定强化学习项目成败的更关键一环。一个有趣的现象是,团队曾尝试直接在 BrowseComp 测试集上训练,但其表现远不如使用合成数据的结果。研究者推测,这种差异源于合成数据提供了一致性更高的分布,使模型能进行更有效的学习和拟合。相比之下,像 BrowseComp 这样的人工标注数据,本身就含有更多噪声,加之其规模有限,导致模型很难从中提炼出一个可供学习的潜在分布,从而影响了其学习和泛化(generalize)能力。这一发现对其他智能体的训练同样具有启发意义,为构建更多样、更复杂的智能体训练方案提供了思路。

在基础设施方面,使用工具训练智能体需要一个高度稳定高效的环境:
- 仿真训练环境:依赖实时 Web API 进行开发成本高昂、速度慢且不一致。团队利用离线维基百科数据库和自定义工具套件创建了一个模拟训练环境来解决这一问题。并且通过 SailorFog-QA-V2 的流程,为该环境生成专属的高质量数据,创建了一个经济高效、快速可控的平台,显著加快了研究和迭代速度。
- 稳定高效的工具沙盒:为了确保在智能体训练和评估期间对工具的稳定调用,团队开发了一个统一的沙盒。该沙盒通过缓存结果、重试失败的调用以及饱和式响应等改进来高效地处理并发和故障。这为智能体提供了快速且鲁棒的交互环境,可以有效防止工具的错误响应破坏其学习轨迹。
- 自动数据管理:数据是提升模型能力的核心驱动力,其重要性甚至超过了算法。数据质量直接决定了模型是否能通过自我探索提升分布外泛化能力。因此,团队在训练动态的指导下实时优化数据,通过全自动数据合成和数据漏斗动态调整训练集。通过数据生成和模型训练之间的正向循环,这种方法不仅确保了训练的稳定性,还带来了显著的性能提升。
- 基于策略的异步框架:团队在 rLLM 之上实现了异步强化学习训练推理框架,多个智能体实例并行与(模拟或真实)环境交互,独立生成轨迹。
通过这些措施,通义 DeepResearch 团队实现了智能体强化训练的 “闭环”。从基座模型开始,团队进行了 Agentic 持续预训练以初始化工具使用技能,然后使用类似专家的数据进行监督微调以实现冷启动,最后进在 on-policy 的强化学习,使模型进行自我进化。这种全栈方法为训练能够在动态环境中稳健地解决复杂任务的 AI 代理提供了一种全新的范例。
4 应用落地
目前通义 DeepResearch 已赋能多个阿里巴巴内部应用,包括:
高德出行 Agent:
高德 App 作为通义在集团内长期共建的重点客户,其 “地图导航 + 本地生活” 的业务场景,以及高德内部丰富的专用工具,具备构建这类 Agent 的土壤,高德也将这类 Agent 能力作为 25 年暑期大版本 V16 的一个亮点功能。通义团队近期在地图 + 本地生活场景,基于纯 agentic+ReAct 执行复杂推理的垂类 agent 技术建设,可以为高德提供更好效果的模型。因此,双方团队共建合作,“通义团队提供模型 + 高德团队提供工具和 Agent 链路”,打造了高德 App 中助手高德小德的复杂查询体验,在地图行业内打出影响力。

通义法睿:
通义法睿,作为大模型原生的 “法律智能体”,致力于为大众及法律从业者提供专业、便捷的法律智能服务。集法律问答、案例法条检索、合同审查、文书阅读、文书起草等功能于一体,全面满足法律用户需求。依托创新的 Agentic 架构与迭代式规划(Iterative Planning)技术,通义法睿全新升级司法 DeepResearch 能力,可高效执行多步查询与复杂推理,实现权威类案精准检索、法条智能匹配与专业观点深度融合。我们以真实判例、官方法规和权威解读为基础,打造可追溯、高可信的法律分析服务,在法律问答的深度研究三大核心维度 —— 答案要点质量、案例引用质量、法条引用质量上领先行业。


通义 DeepResearch 也拥有丰富的 Deep Research Agent 家族。您可以在以下论文中找到更多信息:
[1] WebWalker: Benchmarking LLMs in Web Traversal
[2] WebDancer: Towards Autonomous Information Seeking Agency
[3] WebSailor: Navigating Super-human Reasoning for Web Agent
[4] WebShaper: Agentically Data Synthesizing via Information-Seeking Formalization
[5] WebWatcher: Breaking New Frontier of Vision-Language Deep Research Agent
[6] WebResearch: Unleashing reasoning capability in Long-Horizon Agents
[7] ReSum: Unlocking Long-Horizon Search Intelligence via Context Summarization
[8] WebWeaver: Structuring Web-Scale Evidence with Dynamic Outlines for Open-Ended Deep Research
[9] WebSailor-V2: Bridging the Chasm to Proprietary Agents via Synthetic Data and Scalable Reinforcement Learning
[10] Scaling Agents via Continual Pre-training
[11] Towards General Agentic Intelligence via Environment Scaling
通义 DeepResearch 团队长期致力于 Deep Research 的研发。过去六个月,以每月持续发布一篇技术报告,迄今为止已发布五篇。今天,同时发布六篇新报告,并在开源社区发布了通义 DeepResearch-30B-A3B 模型。
...
#Nav-R1
让机器人「不只是走路」,Nav-R1引领带推理的导航新时代
在机器人与智能体领域,一个长期的挑战是:当你给机器人一个「去客厅把沙发上的书拿来」或者「沿着楼道走到门口,再右转」这一类指令时,机器人能不能不仅「看见环境」,还能「理解指令」、「规划路径」、然后「准确执行动作」?

.
之前的许多方法表面上看起来也能完成导航任务,但它们往往有这样的问题:推理(reasoning)的过程不够连贯、不够稳定;真实环境中路径规划与即时控制之间难以兼顾;在新的环境里泛化能力弱等。
Nav-R1 出场:什么是 Nav-R1?
- 论文标题:Nav-R1: Reasoning and Navigation in Embodied Scenes
- 论文地址:https://arxiv.org/pdf/2509.10884
这篇题为《Nav-R1: Reasoning and Navigation in Embodied Scenes》的新论文,提出了一个新的「身体体现式(embodied)基础模型」(foundation model),旨在让机器人或智能体在 3D 环境中能够更好地结合「感知 + 推理 + 行动」。简单说,它不仅「看到 + 听到+开动马达」,还加入清晰的中间「思考」环节。
核心创新
1.Nav-CoT-110K:推理轨迹的冷启动(cold-start)基础

作者构造了一个大规模的数据集 Nav-CoT-110K,包含约 11 万(110K)条 Chain-of-Thought(推理链 / 思考链、CoT)轨迹。每条轨迹里不仅有任务描述(导航指令),还有机器人从环境中看到的 egocentric 视觉输入 (「我从这里看到了墙、看到了桌子、右边是沙发…」 等),以及每一步可能的行动选项,再加上明确格式化的思考与动作输出。
这些轨迹用于冷启动训练(即监督训练阶段),使模型「先学会怎么思考 + 怎么根据环境和指令决定动作」,在进入强化学习 (RL) 优化之前就已有了一个较为稳定的推理与行动基础。
2.三种奖励(rewards):格式、理解、路径

在强化学习阶段,Nav-R1 不只是简单地奖励「到达目的地」,它引入了三种互补的奖励机制,使得行为更精准、更有逻辑、更符合人类期待:
- Format Reward(格式奖励):确保模型输出遵守结构化格式,比如有 <think>…</think> 和 <action>…</action> 或 <answer> 等标签的分明区分,这样既便于机器解析,也让内在推理清晰。
- Understanding Reward(理解奖励):鼓励模型不仅「走到目标」,还要能语义上理解环境,例如回答场景问题、视觉与语言间对齐、语义正确。包括对正确答案的精确匹配,也包括与视觉输入(如 RGB-D 图像)的语义对齐。
- Navigation Reward(导航奖励):关注路径的 fidelity,也就是路径与参考路径的匹配度 (trajectory fidelity)、终点精度 (endpoint accuracy) 等。通过这一奖惩机制,保证机器人走出来的不仅只是到达目的地,而是走出一条合理、不绕弯、不浪费时间的路径。
3.Fast-in-Slow 推理范式:脑子快 + 身体稳
一个非常有意思的设计灵感是借鉴人类认知中的 “双系统理论”(Thinking Fast and Slow 等),即一个系统擅长深思熟虑、长远规划;另一个系统擅长快速反应、实时控制。

- Slow 系统(System-2):以较低频率工作,处理更宏观、更长时段的语义信息和历史观察(视觉历史、语言指令等),负责制定长期目标和语义一致性。
- Fast 系统(System-1):以高频率执行,负责即时响应,控制短期动作,比如避障、调整姿态、走直线或转弯等。它借助 Slow 系统的 latent 指导,但自己要轻量、低延迟。
- 两者异步协调:Slow 提供大致方向和语义指导,Fast 则负责执行,保证在复杂环境中既不丢失目标语义一致性,也能快速响应环境变化。
实验与效果:真的有用吗?
Nav-R1 给出的实验证据很有说服力,既有模拟环境中的各种基准(benchmarks)也有真实机器人部署。
- 在多个导航任务(如视觉 - 语言导航 Vision-Language Navigation 的 R2R-CE、RxR-CE,以及物体目标导航 ObjectGoal Navigation 等)中,Nav-R1 的成功率(success rate)、路径效率 (SPL, 路径长度加权指标) 等指标相比于其他先进方法提升了约 8% 或更多。

VLN 任务结果

ObjectNav 任务结果
- 在真实硬件上的部署也通过了测试:机器人平台(WHEELTEC R550,Jetson Orin Nano + LiDAR + RGB-D 摄像头等硬件)在会议室、休息室、走廊这些不同的室内场景中执行导航任务,表现稳健。

Robot Setup

在三个不同的室内环境中进行真实世界实验结果
- 延迟 / 实时性方面也做了设计优化:Nav-R1 虽然推理能力强,但通过云端推理 + 本地执行命令 + Fast-in-Slow 架构,使得在资源受限的边缘设备上仍可近实时运行(服务器端推理延迟在约 95 ms 左右)对比只在本地推理的大延迟优势明显。

平均推理延迟比较
Demo 展示:从仿真到现实的双重验证
为了让大家更直观地理解 Nav-R1 的能力,研究团队还准备了视频 Demo,涵盖仿真环境和真实机器人环境两类典型场景。
仿真环境:VLN 与 ObjectNav
在 Habitat 仿真平台中,Nav-R1 接收自然语言导航指令,例如「从走廊穿过客厅,到达右边的沙发」。
- 在 VLN (Vision-Language Navigation) 任务中,Nav-R1 能够理解复杂的语言描述。
指令:Walk past brown leather recliner. Walk through open french doors. Make hard left opposite zebra painting. Wait at mirror.
,时长00:05
,时长00:05
- 在 ObjectNav (Object Goal Navigation) 任务中,给定目标类别(如「找到电视显示器」),Nav-R1 会主动探索、识别物体,并规划合理路径,避开障碍物,快速到达目标。
指令:Search for a tv monitor.
,时长00:04
,时长00:04
真实世界:VLN ObjectNav 机器人部署
研究团队还把 Nav-R1 部署在 WHEELTEC R550 移动机器人平台(配备 Jetson Orin Nano、RGB-D 摄像头和 LiDAR)。在会议室、走廊、休息区等真实场景中,Nav-R1 执行类似的 VLN 指令和 ObjectNav 任务。
- 在 VLN (Vision-Language Navigation) 任务中,Nav-R1 能够理解复杂的语言描述,并在真实环境中执行指令。
指令:Go to the black chair on your left and pause, then move forward to the front-right and stop at the blue umbrella.
,时长00:23
- 在 ObjectNav (Object Goal Navigation) 任务中,给定目标类别(如「找到电视显示器」),Nav-R1 会主动探索真实环境、识别物体,并规划合理路径,避开障碍物,快速到达目标。
指令:Move straight ahead and look for the keyboard along the wall in front.
,时长00:17
意义与应用场景
Nav-R1 它带来了一些比较实际且有影响力的可能性。
1. 服务机器人 / 家庭机器人
在家里,机器人要在杂乱的环境中穿行、按指令找东西、与人交互时,不仅要走得快、走得稳,还要走得「懂」。Nav-R1 的结构化推理 + 路径精准性 + 实时控制恰好能提升用户信心与使用体验。
2. 助老 / 医疗 / 辅助设备
在医院、养老院、辅助设施中,环境复杂,人多物杂,需要机器人能安全、可靠地导航,且对错误能够有语义上的理解与纠正能力。
3. 增强现实 / 虚拟现实
AR 或 VR 中,如果虚拟智能体或助手要在用户的物理环境中导航(或通过视觉输入理解环境为用户指路),这样的推理 + 控制结合非常关键。
4. 工业 / 危险环境
在工厂、矿井甚至灾害现场,机器人需要在未知或危险环境中执行任务。Nav-R1 的泛化能力与稳健性使得它可以作为基础模块进一步应用。
作者介绍
刘庆祥是上海工程技术大学电子电气工程学院在读硕士,研究方向聚焦于视觉语言导航、xx智能。曾参与多项科研项目,致力于构建具备xx世界模型。
黄庭是上海工程技术大学电子电气工程学院在读硕士,Zhenyu Zhang 和 Hao Tang 老师的准博士生,研究方向聚焦于三维视觉语言模型、空间场景理解与多模态推理。曾参与多项科研项目,致力于构建具备认知与推理能力的通用 3D-AI 系统。
张泽宇是 Richard Hartley 教授和 Ian Reid 教授指导的本科研究员。他的研究兴趣扎根于计算机视觉领域,专注于探索几何生成建模与前沿基础模型之间的潜在联系。张泽宇在多个研究领域拥有丰富的经验,积极探索人工智能基础和应用领域的前沿进展。
唐浩现任北京大学计算机学院助理教授 / 研究员、博士生导师、博雅和未名青年学者,入选国家级海外高水平人才计划。曾获国家优秀自费留学生奖学金,连续两年入选斯坦福大学全球前 2% 顶尖科学家榜单。他曾在美国卡耐基梅隆大学、苏黎世联邦理工学院、英国牛津大学和意大利特伦托大学工作和学习。长期致力于人工智能领域的研究,在国际顶级期刊与会议发表论文 100 余篇,相关成果被引用超过 10000 次。曾获 ACM Multimedia 最佳论文提名奖,现任 ACL 2025、EMNLP 2025、ACM MM 2025 领域主席及多个人工智能会议和期刊审稿人。更多信息参见个人主页: https://ha0tang.github.io/
...
#DeepSeek-R1论文登上Nature封面
通讯作者梁文锋
太令人意外!
却又实至名归!
最新一期的 Nature 封面,竟然是 DeepSeek-R1 的研究。
也就是今年 1 月份 DeepSeek 在 arxiv 公布的论文《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning》。这篇Nature论文通讯作者正是梁文锋。
论文链接:https://www.nature.com/articles/s41586-025-09422-z
在封面的推荐介绍中,Nature 写到:
如果训练出的大模型能够规划解决问题所需的步骤,那么它们往往能够更好地解决问题。这种『推理』与人类处理更复杂问题的方式类似,但这对人工智能有极大挑战,需要人工干预来添加标签和注释。在本周的期刊中,DeepSeek 的研究人员揭示了他们如何能够在极少的人工输入下训练一个模型,并使其进行推理。
DeepSeek-R1 模型采用强化学习进行训练。在这种学习中,模型正确解答数学问题时会获得高分奖励,答错则会受到惩罚。结果,它学会了推理——逐步解决问题并揭示这些步骤——更有可能得出正确答案。这使得 DeepSeek-R1 能够自我验证和自我反思,在给出新问题的答案之前检查其性能,从而提高其在编程和研究生水平科学问题上的表现。
此外,在这周期刊中,Nature 还盛赞 DeepSeek-R1 的这种开放模式。
值得注意的是,R1 被认为是首个通过权威学术期刊同行评审的大语言模型。
Hugging Face 的机器学习工程师、同时也是该论文审稿人之一的 Lewis Tunstall 对此表示:「这是一个备受欢迎的先例。如果缺乏这种公开分享大部分研发过程的行业规范,我们将很难评估这些系统的潜在风险。」
为回应评审意见,DeepSeek 团队不仅在论文中避免了对模型的拟人化描述,还补充了关于训练数据类型和安全性的技术细节。俄亥俄州立大学 AI 研究员 Huan Sun 评论道:「经历严格的同行评审,无疑能有效验证模型的可靠性与实用价值。其他公司也应效仿此举。」
显而易见,当前 AI 行业充斥着发布会上的惊艳演示和不断刷新的排行榜分数。
但正如文中所指,基准测试是可被「操控」的。将模型的设计、方法论和局限性交由独立的外部专家审视,能够有效挤出其中的水分。
同行评审充当了一个公正的「守门人」,它要求 AI 公司从「王婆卖瓜」式的自我宣传,转向用扎实的证据和可复现的流程来支持其声明。
因此,DeepSeek-R1 论文本身固然有其科学价值,但作为首个接受并通过主流期刊同行评审的 LLM,其「程序价值」可能更为深远。
可以预见的是,将 LLM 纳入独立的同行评审体系,是从「技术竞赛」迈向「科学纪律」的关键一步,对于遏制行业乱象、建立公众信任至关重要。
接下来,就让我们回顾下这篇重磅研究。但也建议大家细看下 Nature 上发表的论文,有更多补充细节:

DeepSeek-R1的多阶段pipeline
以往的研究主要依赖大量的监督数据来提升模型性能。DeepSeek 的开发团队则开辟了一种全新的思路:即使不用监督微调(SFT)作为冷启动,通过大规模强化学习也能显著提升模型的推理能力。如果再加上少量的冷启动数据,效果会更好。
为了做到这一点,他们开发了 DeepSeek-R1-Zero。具体来说,DeepSeek-R1-Zero 主要有以下三点独特的设计:
首先是采用了群组相对策略优化(GRPO)来降低训练成本。GRPO 不需要使用与策略模型同样大小的评估模型,而是直接从群组分数中估算基线。
其次是奖励设计。如何设计奖励,决定着 RL 优化的方向。DeepSeek 给出的解法是采用准确度和格式两种互补的奖励机制。
第三点是训练模版,在 GRPO 和奖励设计的基础上,开发团队设计了如表 1 所示的简单模板来引导基础模型。这个模板要求 DeepSeek-R1-Zero 先给出推理过程,再提供最终答案。这种设计仅规范了基本结构,不对内容施加任何限制或偏见,比如不强制要求使用反思性推理或特定解题方法。这种最小干预的设计能够清晰地观察模型在 RL 的进步过程。

在训练过程中,DeepSeek-R1-Zero 展现出了显著的自我进化能力。它学会了生成数百到数千个推理 token,能够更深入地探索和完善思维过程。
随着训练的深入,模型也发展出了一些高级行为,比如反思能力和探索不同解题方法的能力。这些都不是预先设定的,而是模型在强化学习环境中自然产生的。
特别值得一提的是,开发团队观察到了一个有趣的「Aha Moment」。在训练的中期阶段,DeepSeek-R1-Zero 学会了通过重新评估初始方法来更合理地分配思考时间。这可能就是强化学习的魅力:只要提供正确的奖励机制,模型就能自主发展出高级的解题策略。
不过 DeepSeek-R1-Zero 仍然存在一些局限性,如回答的可读性差、语言混杂等问题。
利用冷启动进行强化学习
与 DeepSeek-R1-Zero 不同,为了防止基础模型在 RL 训练早期出现不稳定的冷启动阶段,开发团队针对 R1 构建并收集了少量的长 CoT 数据,以作为初始 RL actor 对模型进行微调。为了收集此类数据,开发团队探索了几种方法:以长 CoT 的少样本提示为例、直接提示模型通过反思和验证生成详细答案、以可读格式收集 DeepSeek-R1-Zero 输出、以及通过人工注释者的后处理来细化结果。
DeepSeek 收集了数千个冷启动数据,以微调 DeepSeek-V3-Base 作为 RL 的起点。与 DeepSeek-R1-Zero 相比,冷启动数据的优势包括:
- 可读性:DeepSeek-R1-Zero 的一个主要限制是其内容通常不适合阅读。响应可能混合多种语言或缺乏 markdown 格式来为用户突出显示答案。相比之下,在为 R1 创建冷启动数据时,开发团队设计了一个可读模式,在每个响应末尾包含一个摘要,并过滤掉不友好的响应。
- 潜力:通过精心设计具有人类先验知识的冷启动数据模式,开发团队观察到相较于 DeepSeek-R1-Zero 更好的性能。开发团队相信迭代训练是推理模型的更好方法。
推理导向的强化学习
在利用冷启动数据上对 DeepSeek-V3-Base 进行微调后,开发团队采用与 DeepSeek-R1-Zero 相同的大规模强化学习训练流程。此阶段侧重于增强模型的推理能力,特别是在编码、数学、科学和逻辑推理等推理密集型任务中。
为了缓解语言混合的问题,开发团队在 RL 训练中引入了语言一致性奖励,其计算方式为 CoT 中目标语言单词的比例。虽然消融实验表明这种对齐会导致模型性能略有下降,但这种奖励符合人类偏好,更具可读性。
最后,开发团队将推理任务的准确率和语言一致性的奖励直接相加,形成最终奖励。然后对微调后的模型进行强化学习(RL)训练,直到它在推理任务上实现收敛。
拒绝采样和监督微调
当面向推理导向的强化学习收敛时,开发团队利用生成的检查点为后续轮次收集 SFT(监督微调)数据。此阶段结合了来自其他领域的数据,以增强模型在写作、角色扮演和其他通用任务中的能力。
开发团队通过从上述强化学习训练的检查点执行拒绝采样来整理推理提示并生成推理轨迹。此阶段通过合并其他数据扩展数据集,其中一些数据使用生成奖励模型,将基本事实和模型预测输入 DeepSeek-V3 进行判断。
此外,开发团队过滤掉了混合语言、长段落和代码块的思路链。对于每个提示,他们会抽取多个答案,并仅保留正确的答案。最终,开发团队收集了约 60 万个推理相关的训练样本。
用于所有场景的强化学习
为了进一步使模型与人类偏好保持一致,这里还要实施第二阶段强化学习,旨在提高模型的有用性和无害性,同时完善其推理能力。
具体来说,研究人员使用奖励信号和各种提示分布的组合来训练模型。对于推理数据,遵循 DeepSeek-R1-Zero 中概述的方法,该方法利用基于规则的奖励来指导数学、代码和逻辑推理领域的学习过程;对于一般数据,则采用奖励模型来捕捉复杂而微妙的场景中的人类偏好。
最终,奖励信号和多样化数据分布的整合使我们能够训练出一个在推理方面表现出色的模型,同时优先考虑有用性和无害性。
蒸馏:让小模型具备推理能力
为了使更高效的小模型具备 DeepSeek-R1 那样的推理能力,开发团队还直接使用 DeepSeek-R1 整理的 80 万个样本对 Qwen 和 Llama 等开源模型进行了微调。研究结果表明,这种简单的蒸馏方法显著增强了小模型的推理能力。
得益于以上多项技术的创新,开发团队的大量基准测试表明,DeepSeek-R1 实现了比肩业内 SOTA 推理大模型的硬实力,具体可以参考以下结果:


更多技术细节请参阅原论文。
...
#OpenAI/Gemini共斩ICPC 2025金牌
OpenAI满分碾压横扫全场
历史性一夜:OpenAI与谷歌Gemini同步拿下ICPC 2025金牌,前者12题满分AK,后者独解人类全军覆没的C题,首度在最顶级编程赛场全面超越人类。
真是疯狂!
刚刚,谷歌和OpenAI同时拿下ICPC金牌,尤其OpenAI还是满分!
ICPC全称国际大学生程序设计竞赛,是世界上最负盛名的编程竞赛之一!
规则是在五个小时内,求解十几个极其复杂的编程和算法难题!
最终,Gemini成功解答了12道题目中的10道,荣获金牌。
OpenAI则全部解答正确,获得满分,拿下金牌!
人类呢?
139支人类参赛队伍中,只有3支队伍取得了和Gemini 10/12一样的成绩,没有人类队伍获得满分。
其中和Gemini战平的唯一中国队伍,是北交大,我们在ICPC全球总决赛放榜的第一时刻也做了深入报道,解析了这支中国最强战队是如何炼成的。
尤其是,谷歌也特地提到,问题C所有人类队伍都没有解答出来,而谷歌Gemini在半个小时内成功求解!
OpenAI则是解决了所有问题,拿下满分!
真的是令人震撼的时刻,历史性的一夜,AI在最顶级的编程比赛中彻底的超过了人类!
Gemini解出所有参赛人类队伍
没有解决的问题C
谷歌官方账号宣布了Gemini 2.5 Deep Think的高级版本在ICPC 2025上取得了金牌级别的成绩。
据谷歌称,它并没有像今年早些时候为类似国际数学奥林匹克(IMO)那样,为ICPC创建全新训练的模型。
参加ICPC的Gemini 2.5与我们在Gemini应用中使用的模型相同。
不过,它经过了一些增强,能够在五个小时里不断思考!
在ICPC比赛中,只有正确的答案才能得分,而得出答案所需的时间会影响最终得分。
比赛开始后,Gemini迅速攀升至前几名,仅用45分钟就正确解答了8道题目。
Gemini最终答对了10道题,在大学队伍中获得了第二名。
谷歌特别地提到,在比赛中,Gemini成功解决了问题C——其他人类团队均未解决这个问题。
问题C要求找到一种解决方案,将液体通过互连的管道网络分配到一组储液器中,目标是找到一种管道配置,使液体尽快充满所有储液器。
由于每个管道可能是开放的、关闭的,甚至是部分开放的,因此可能的配置数量无穷无尽,因此寻找最佳配置非常困难。
Gemini的解决方法是假设每个储液罐都有一个优先级值,这使得模型能够使用动态规划算法找到最高效的配置。
经过30分钟的反复思考,Gemini使用嵌套三元搜索确定了正确的答案。
我们对谷歌公布的答案让Cursor进行了评价,Cursor也认为谷歌的求解方法非常完美。
其他题目谷歌已经全部公布在GitHub上,感兴趣可以挑战一下~
https://github.com/google-deepmind/gemini_icpc2025
OpenAI AK ICPC背后的秘密
Gemini已经通过解出了让人类全军覆没的超高难度的C题证明了自己的强大实力。
但是,还有高手!OpenAI的推理模型直接通关了全场12道题目,AK(All Kill,指解出全部题目) ICPC!
背后的研究团队也是连发8条推文来庆祝这一历史性时刻。
其中值得注意的是,其中11道题目,都是直接用了大家都能用的GPT-5解决的,只有最难的一道题(可能指的是难倒全部人类的题目C,可能是指最后一个问题L,也可能是其他对大模型而言更困难的问题)是用一个未公布型号的神秘实验推理模型解决的。
这个神秘实验模型,会不会就是下一代的全新推理模型呢?
最后一条推文中,几位幕后关键研究人员也纷纷被@出来亮相了。
查询身份后得知,他们都是o1及之后的这些推理模型的关键研究人员。
其中有一位,更是ICPC的2015年世界冠军队伍成员,Borys Minaiev。
他为人熟知的算法界ID是:qwerty787788。
在当年的这支夺冠队伍的三人中,还有另一位更广为人知的传奇人物,那就是tourist,算法界最强王者,世界第一人!
此外,OpenAI首席科学家Jakub Pachocki也是ICPC世界金牌得主,赛后也转发了推文,对该团队的优异表现表达了热烈祝贺。
众多ICPC世界顶尖选手加盟OpenAI,是OpenAI能最终训练出AK ICPC的大模型的强大支柱。
历史性一夜
上次OpenAI抢先谷歌公布IMO结果的时候,还闹出了小小的风波。
谷歌和OpenAI都想争一争谁是第一个拿下IMO这种级别赛事的AI。
而这一次,两者同时宣布,意义非凡!
ICPC全球执行董事,BILL POUCHER博士认为:
Gemini成功加入这一领域并取得黄金级成果,标志着定义下一代所需的人工智能工具和学术标准的关键时刻。
AI在ICPC上斩获金牌对软件开发有着直接且实际的意义。
这表明人工智能可以成为程序员真正的问题解决伙伴。
不论是谷歌的CEO劈柴,还是OpenAI的首席科学家都是亲自为自家的AI站台!
除了编程和数学,AI这种强大的抽象推理能力可以应用于许多科学和工程领域,如设计新药或芯片。
人工智能正在从单纯的信息处理转向真正帮助解决世界上一些最棘手的推理问题,从而造福全人类。
参考资料:
https://x.com/merettm/status/1968363783820353587
https://x.com/MostafaRohani/status/1968360976379703569
https://x.com/GoogleDeepMind/status/1968361776321323420
https://github.com/google-deepmind/gemini_icpc2025
...
#OneSearch
揭开快手电商搜索「一步到位」的秘技
还有一个多月,一年一度的“双十一”购物节就要来了!
作为消费者,你通常会如何寻找心仪的商品呢?或许你兴致勃勃地在搜索框里敲下关键词,却发现呈现出来的商品列表总是差强人意。那么,问题究竟出在哪里?
这一切,还要从电商平台常用的传统搜索架构说起。目前主流系统采用“召回 -> 粗排 -> 精排” 的级联式架构。
- 召回层:比如你搜索 “红色连衣裙”,系统会迅速从数亿商品中筛选出上万个包含 “红色”“连衣裙” 关键词的商品。这步追求快和全,但精度不高 —— 难免会出现一些标题党商品(比如标题强行蹭热点,写 “红色连衣裙” 但其实卖的是搭配的开衫)
- 粗排层:系统使用轻量级模型对这上万个商品粗略排序,去掉一些明显不相关的商品。
- 精排层:采用更复杂、精细的模型,对几百个剩余商品进行最终排序。它会综合考量点击率、销量、价格、用户历史偏好等多种因素,返回你最终看到的商品列表。

那么,到底是哪些环节导致我们总是看到不满意的商品?原因在于:
- 商品描述混乱:卖家为增加曝光,常在标题中堆砌大量不相关热词(如 “民族风复古流苏酒红色吊带连衣裙云南新疆西藏旅游度假长裙”),严重干扰系统判断。
- 相关性问题突出:用户搜索词往往很短(例如 “夏季阔腿裤”),但只要某一属性不匹配(如商品实际是 “裙裤” 款式),就不再相关,而系统难以精准捕捉这类差异。
- 级联结构存在瓶颈:级联式框架如同三道筛子,如果第一层召回效果差,后面再怎么排也难挽回。并且三层目标不一致,整体协同困难。
- 冷启动难题:新上架商品或搜索量极低的长尾词,因缺乏历史数据,很难被系统正确处理,导致曝光机会匮乏。
1、OneSearch:电商搜索端到端生成式框架
为解决传统电商搜索系统面临的诸多挑战,工业界通常采用级联式架构,以实现较高的商业效益和系统稳定性。然而,随着大语言模型的兴起,研究者开始探索如何借助其强大的语义理解与世界知识进一步优化搜索体验。
在此背景下,快手提出了业界首个工业级部署的电商搜索端到端生成式框架 ——OneSearch。
- 论文标题:《OneSearch: A Preliminary Exploration of the Unified End-to-End Generative Framework for E-commerce Search》
- 论文地址:https://arxiv.org/abs/2509.03236
该框架涵盖以下三大创新点:
1. 提出关键词增强层次量化编码(KHQE)模块,能够在保持层次化语义与商品独特属性的同时,强化 Query - 商品相关性约束;
2. 设计多视角用户行为序列注入策略,构建了行为驱动的用户标识(UID),并融合显式短期行为与隐式长期序列,全面而精准地建模用户偏好;
3. 引入偏好感知奖励系统(PARS),结合多阶段监督微调与自适应奖励强化学习机制,以捕捉细粒度用户偏好信号。

2、OneSearch 技术方案三大创新
2.1 关键词增强层次量化编码(KHQE)模块

商品语义涵盖标题、关键词、详情页、商家、价格、图片等多维度信息。然而,商家为提升曝光度,常在标题中堆砌大量关键词,导致出现多主体甚至属性冲突的问题,例如:“法式挂脖连衣裙女夏宽松显瘦绝美温柔初恋优雅皮靴搭配红色浅蓝色粉色”。此类混杂表述易掩盖商品的核心特征。
为实现多元化搜索意图下 query 与商品的精准匹配,首先必须对商品的丰富语义进行充分建模。快手团队设计了四个任务来对齐协同和语义表征:
1. Q2Q 和 I2I 对比损失:用于对齐协同相似对的表征;
2. Q2I 对比损失:增强 Query - 商品对的语义相关性,确保表征模型理解业务特性;
3. Q2I 边际损失:进一步学习具有不同行为级别(如曝光、点击、下单)的 < q, i > 对的协同信号偏差;
4. 基于 LLM 的难样本纠偏:保证难样本相关性水位。
第一步:提取核心属性
使用 Qwen-VL/AC 自动机分别识别出商品 /query 的关键属性(如品牌、品类、颜色、材质)。例如,从前述混乱标题中精准提取 “连衣裙”、“法式”、“挂脖”、“夏季” 等核心属性,弱化 “绝美”、“皮靴” 等无关或冲突词汇。
第二步:生成层次化编码(SID)
传统 SID 编码方法(如 RQ-VAE、RQ-Kmeans)倾向于编码商品间的共性特征,导致语义相近的商品被映射到相同编码中,无法充分保留个性化差异,从而制约生成式检索模型的性能。
为解决该问题,快手搜索技术团队提出 RQ-OPQ 编码方案,融合 RQ(残差量化)和 OPQ(优化乘积量化)的优势,从纵向与横向两个维度建模商品特征:
- RQ:负责处理层次化语义特征,通过多层残差量化捕捉从粗粒度到细粒度的商品语义。
- OPQ:负责量化独特特征,专门编码每个商品的差异化属性。
首先使用 RQ-Kmeans 进行 3 层层次化编码,构建商品的主体语义表示。可视为从粗到细的分类标签体系。例如:第一层为 “服装”,第二层为 “连衣裙”,第三层为 “法式款式”。经过聚类后所剩余的残差信息,包含商品最独特、最细粒度的属性。进一步对残差向量应用 OPQ 进行 2 层编码,以捕获商品的细微差异特征,如 “iPhone 17 Pro” 的 “星宇橙色”、“256GB 内存” 等关键属性。缺失此类信息将导致模型无法区分同类别商品的细微差别。
最终每个商品由 5 层 SID 组成:前 3 层来自 RQ 聚类中心,后 2 层来自 OPQ 量化结果。该结构相当于为每一个商品生成了一个具备丰富语义层次的 “智能身份证”,显著提升了生成式检索的区分能力和准确性。
2.2 多视角用户行为序列

传统搜索系统往往难以有效捕捉用户的近期偏好与长期兴趣。其核心原因在于传统排序模型中的用户 ID 仅为一串随机数字(如 “12345”),缺乏语义信息。而在 OneSearch 中,依据用户的长 / 短期行为序列构建具有区分性的用户标识(distinctive User ID)。例如,若用户近期频繁浏览露营装备,并长期表现出对高性价比商品的偏好,系统会为其生成一个精准描述这些行为的标识,而非无意义的编号。具体而言,采用有序加权方式基于用户的长 / 短期行为序列计算 distinctive User ID:

2.2.1 显式引入短行为序列
用户最近的搜索 Query 和点击商品可反映其即时意图。例如,若用户近期频繁搜索 “开学必备”、“宿舍神器”,系统可推断其可能为准大学生,进而在搜索结果页中围绕此进行展示。为实现这一目标,系统将用户最近的搜索 Query 序列和 SID 形式的点击商品序列直接编码至模型输入(prompt)中,以显式方式强调这些近期行为特征。同时,为缓解新用户行为稀疏性问题并模拟兴趣演化,采用滑动窗口策略进行数据增强。
2.2.2 隐式引入长行为序列
长期行为序列旨在从用户历史行为(如点击、购买等)中提炼稳定的偏好特征,形成整体用户画像。例如,用户长期购买高端电子产品和小众设计师品牌,可体现其消费层次和审美倾向。
在电商场景中,用户行为序列长度常高达~10³,无法以显式方式完整引入。考虑到 BART 等模型的最大输入长度限制(如 1024)以及长序列对线上推理延迟的影响,可通过嵌入(embedding)方式隐式融合用户个性化信息。与 OneRec 等方法直接对海量视频 ID 进行建模(嵌入维度达几十亿)不同,OneSearch 提出基于 SID 维度建模,具有以下优点:
- embedding 维度低,仅几千维 emb 即可表征全量商品
- SID 本身已经包含了类目、材质等层级化信息,无需引入额外特征
为进一步降低线上计算复杂度,对用户行为 SID 序列分层(L1/L2/L3)进行均值池化,并利用 QFormer 对序列表征进行压缩,最终得到一组(n, 768)维向量,即 n 个用户序列 token。消融实验表明,去除长期行为序列会导致离线性能显著下降,证明了隐式引入长序列的必要性。
该方法使系统能够更全面、深层地理解用户意图,显著提升了个性化搜索的准确性与用户体验。
2.3 引入偏好感知奖励系统(PARS)
当然,光能识别商品和理解用户还不够,最终得把所有匹配的商品排好顺序。
相比于推荐系统中的序列一致性,搜索中 query 和 item 之间的强相关性约束对生成式模型提出了更大的挑战。对于 GR 模型,不仅需要实现 SID 与 query/item 之间的语义对齐,还需要根据序列信息直接生成满足相关性约束和用户偏好的 item。因此,OneSearch 提出了一个偏好感知奖励系统,包括多阶段监督微调(SFT)和自适应奖励系统,以增强模型的个性化排序能力。

2.3.1 监督微调(SFT)阶段
用于搜索的生成式模型,需要同时准确把握〈query, item〉对的相关性以及用户的个性化偏好。OneSearch 创新性地设计了三阶段 SFT 训练任务:分别实现语义内容对齐、协同信息对齐、用户个性化建模。这就类似于 “上课” 的过程,从易到难,进行课程学习。
- 第一节课:认识 query/item 的 SID 与类目(比如 “薄款衬衫” 对应哪个 SID、哪一类目);
- 第二节课:学习 query 和 item 的共现关系(比如搜索了 “极简风” 的用户,常买哪些商品);
- 第三节课:结合用户的兴趣档案做练习(比如给 近期看露营 + 长期爱性价比 的用户,高优展示哪款类型帐篷)。

这一分阶段的学习策略有效提升了模型对相关性约束和用户偏好的联合建模能力。
2.3.2 强化排序学习(RL4Ranking)阶段
为了使生成式模型具备排序能力,一种直观的思路是借助强化学习,对用户有交互和无交互行为的区别学习。OneSearch 引入了一套自适应的奖励系统,首先通过 reward model 实现与线上精排模型的分布对齐,再结合用户真实交互行为进行监督训练,进一步激发生成式模型的推理能力。
样本自适应权重构建
电商搜索场景中用户意图多样,既包括强购买意图,也包含浏览、比价等弱意图行为。与视频推荐使用时长、次留等指标不同,电商搜索更关注 CTR、CVR、订单量与营收等直接转化指标。因此,如何对不同行为样本赋予合理的奖励权重,就显得非常重要。OneSearch 引入规则奖励机制(reward model),将用户行为划分为六个等级,并为每一类设置基础奖励值。在此基础上,进一步引入动态调节因子,基于商品近 7 天内的 CTR、CVR 等实时表现动态微调样本权重,缓解新品曝光不足带来的偏差。这种机制使得即使同为高等级样本(如两个成交商品),也会因历史转化效率的不同而在奖励权重上呈现细微差异,从而帮助模型捕捉更细粒度的用户偏好。
奖励模型(Reward Model)设计
为了对齐线上精排分布,OneSearch 首先设计了一个直观且高效的奖励模型。保持模型结构 & 损失函数与原精排一致、特征输入与 OneSearch 对齐,即用更少的特征拟合线上精排模型的分布,这样可以继承原有精排模型的稳定性。奖励模型训练好后,可以从线上日志中拉取用户真实搜索过的 query 等信息,使用 SFT 后的 OneSearch 模型生成候选 item 列表,再使用奖励模型进行进一步的排序;可以筛选出顺序发生变化的样本,这些差异样本反映了当前生成模型与线上精排在对用户偏好理解上的差距。利用这批数据进行监督训练,可有效增强模型的偏好学习能力。
用户交互引导,突破模型推理限制
在初步获得精排排序能力后,OneSearch 进一步引入用户真实交互数据监督训练,以激发生成模型的深层推理能力。训练中将以有点击、成交等正向反馈的样本作为正例,曝光未点击等作为负例,通过混合排序建模的方式,使模型在提升排序性能的同时,不损害生成多样性,避免 “奖励破解”(reward hacking)问题。
总结而言,OneSearch 的强化学习机制分为两步:首先通过奖励模型促使 OneSearch 拟合线上精排模型分布,学习基础的排序;再通过基于 Listwise DPO 进一步对齐用户偏好,突破排序性能的上限。
3、效果评测
离线实验效果
基于线上真实用户行为日志构建的离线测试集表明,OneSearch 提出的 RQ-OPQ 编码与自适应奖励系统相结合的方法效果最优,相比现有级联式系统(OnlineMCA),各项指标均有显著提升。

在线实验结果
为了验证 RQ-OPQ 编码和用户序列引入的有效性,OneSearch 先后进行了两版实验,v1 版本仅使用 RQ 编码,取得了和线上级联式系统相近的效果;引入 RQ-OPQ 编码和用户序列建模后,v2 版本在 CTR 和 CVR 上有了显著的提升;额外地,在生成式模型的基础上进一步引入奖励系统,能获得转化指标的全面提升,最终版本订单量提升 3.22%,买家数提升 2.4%。
该实验验证了 OneSearch 模型在真实电商环境中的有效性。这是在大规模工业场景下,生成式模型第一次取代搜索全链路的可落地方案。目前该系统已在快手的多个电商搜索场景中成功部署,每日服务数百万用户,产生数千万 PV。

人工评测与在线性能
在人工评测中,OneSearch 系列模型不仅在 CVR 和 CTR 上表现优异,同时在页面整体满意度、商品质量及 query-item 相关性方面均显著优于线上级联式系统。此外,在线性能方面,机器计算效率(MFU)提升显著,从 3.26% 提高到 24.06%,相对提升达 8 倍;线上推理成本(OPEX)降低 75.40%,资源利用效率显著优化。


泛化性和场景分析
OneSearch 在绝大多数行业类别中均带来 CTR 的稳定提升,展现出良好的泛化能力。按 Query 频次、商品冷启动及用户层级下探表明,OneSearch 在高、中、低频 query 上均实现了 CTR 提升,尤其在中长尾 query 上的改善更为显著。此外,该系统在冷启动(cold-start)场景下表现尤为突出,效果显著优于常规(warm)场景,说明生成式检索模型能够更有效地应对长尾用户和新上架商品的排序挑战。


4、始终追踪技术前沿
快手搜索技术部作为公司的核心算法研发部门,始终站在大数据与人工智能技术发展的前沿,致力于将大模型(LLM)技术与海量数据深度融合,打造行业领先的智能搜索平台,持续推动用户体验与技术能力的协同进化。部门业务覆盖视频搜索、电商搜索与 AI 搜索等多个核心方向,聚焦于构建精准、高效、智能的新一代搜索系统。
其中,OneSearch 所属的电商搜索团队以实际业务需求为驱动,坚持 “技术‑业务” 双轮迭代机制,多项技术突破已发表在 RecSys、CIKM、KDD、EMNLP、AAAI、ACM MM 等国际顶级会议上,多次引起业界广泛关注。面向未来,团队将持续深耕多模态理解、生成式搜索与 AI 搜索等关键方向,致力于实现更智能、更流畅、更人性化的搜索交互体验,以技术驱动业务创新,不断攀登智能搜索的新高峰。
5、未来展望
在后续研究中,快手电商搜索团队将致力于探索在线实时编码方案,缩小预定义编码与流式训练之间的差异。此外,还将引入更强大的强化学习机制以更精准地匹配用户偏好,并结合图像、视频等多模态商品特征,进一步提升模型的推理效果与用户体验。
...
#OpenAI在ICPC 2025编程赛上满分登顶
Gemini也达到金牌水平
IMO 之后,OpenAI 与 Gemini 双双加冕 ICPC 2025 金牌。
就在刚刚,OpenAI 和 Gemini 都声称达到了 ICPC 金牌水平。
其中,OpenAI 在 5 个小时内解决了所有 12 个问题,相当于人类排名第 1 位,超过了所有参赛大学团队。

而 Gemini 解决了 12 个问题中的 10 个,总用时 677 分钟,达到了金牌水平,如果与人类团队比较,将排名第 2。

人类团队方面,俄罗斯圣彼得堡国立大学的参赛队伍排名第 1,解决了 11 个问题。北京交通大学、清华大学、北京大学、中国科学技术大学的参赛队伍分别排名 2、4、5、9。

ICPC,即国际大学生程序设计竞赛,是全球公认的历史最悠久、规模最大、最负盛名的大学级算法编程竞赛,它比 IMO 等高中奥林匹克竞赛更高一级。每年,来自近 3000 所大学和 103 个国家的参赛者齐聚一堂,挑战现实世界的编程难题。
今年的 ICPC 世界决赛于 9 月 4 日在阿塞拜疆的巴库举行,汇集了来自竞赛早期阶段的顶级队伍。在五小时的比赛中,每支队伍解决了一组复杂的算法问题。最终排名严格依据两个原则:只有完美的解决方案才能得分,每一分钟都至关重要。在 139 支参赛队伍中,只有前四支队伍获得了金牌。
下面是 ICPC 的原题,感兴趣的读者可以亲自尝试一下。
https://worldfinals.icpc.global/problems/2025/finals/index.html
OpenAI 5 小时内解决 12 个问题
超过人类团队
OpenAI 的 与人类顶尖选手在完全同等的条件下竞技:面对完全相同的赛题,拥有相同的 5 小时时限,并由与 ICPC 全球总决赛标准一致的本地系统进行实时评判。
整个过程中,AI 系统在没有任何定制化测试工具的辅助下,独立分析问题并自主决定提交最终答案。
比赛结果令人瞩目:在全部 12 个问题中,该 AI 系统对其中 11 个问题的首次提交便获得了正确答案。即便是全场难度最高、困住所有人类队伍的最后一个问题,AI 也在经过 9 次尝试后成功攻克。相比之下,本次竞赛表现最出色的人类团队成功解决了 11 个问题。

其中问题 G,OpenAI 尝试 9 次后成功解决,该问题也是 DeepMind 未能解决的两道难题之一。作为参考,解题速度最快的人类选手也耗时 270 分钟(竞赛总时长 300 分钟)。

OpenAI 方面透露,此次参赛的 AI 由一个「通用推理模型集成体」构成,并未针对 ICPC 竞赛进行任何专门的优化或训练。
在解题过程中,系统结合了其下一代模型 GPT-5 与一个前沿的实验性推理模型。其中,GPT-5 精准地解答了 11 题,而那款实验性模型则最终完成了对最难题目的关键一击。
这一成果是 OpenAI 一系列展示推理系统惊人进步速度的绝佳里程碑。同一组模型已在国际数学奥林匹克(IMO)和国际信息学奥林匹克(IOI)等竞赛中证明了其实力,充分印证了其强大的通用性与广泛的适用潜力。
OpenAI 员工 Borys Minaiev 和 Mostafa Rohaninejad 也在 X 上发文庆贺。
Borys Minaiev
Borys Minaiev 是 OpenAI 的研究员,专注于大规模推理模型的开发与应用,尤其在编程竞赛和复杂推理任务中展现了卓越能力。
他毕业于圣彼得堡国立信息技术、机械与光学大学(ITMO University),并在编程竞赛领域取得了显著成就。2015 年,他作为 ITMO 大学队员之一,赢得了国际大学生程序设计竞赛(ICPC)世界总决赛的冠军,这是该赛事历史上唯一一支在比赛结束前解决所有问题的队伍。

在加入 OpenAI 后,Borys Minaiev 成为大型推理模型研究的核心成员之一,参与了多个关键项目,包括 o1、o3 和 o4-mini 等模型的开发。
此外,Borys Minaiev 还活跃于开源社区,在 GitHub 上分享了多个项目,并在个人博客中深入探讨了模拟退火算法、Rust 编程语言以及 AI 在教育中的应用等主题。
Mostafa Rohaninejad
Mostafa Rohaninejad 是 OpenAI 的研究科学家,专注于元学习、强化学习和人工智能系统的推理能力。
他于 2023 年加入 OpenAI,参与了多个关键项目,包括 GPT-5 和 OpenAI o1 等大规模推理模型的开发。
在加入 OpenAI 之前,Mostafa 曾在加州大学伯克利分校攻读计算机科学硕士学位,并在该校的 BAIR 实验室与 Pieter Abbeel 教授合作,研究元学习和生成模型。他是著名的 SNAIL 架构的共同作者,该架构在少样本学习任务中表现出色。

Mostafa 的研究兴趣主要集中在如何使人工智能系统具备更强的推理能力和适应性,特别是在复杂任务和动态环境中的表现。他在 OpenAI 的工作不仅推动了 AI 技术的发展,也为实现更智能、更人性化的 AI 系统奠定了基础。
谷歌 Gemini 解决 10 个难题
达到金牌级别
Gemini 2.5 Deep Think 的高级版本在 ICPC 规则下,以远程在线环境参与竞赛,并在比赛组织者的指导下进行。
它比人类参赛者晚了 10 分钟开始,但在五小时的时间限制内正确解决了 12 个问题中的 10 个,达到了金牌级表现。
Gemini 2025 ICPC 世界总决赛代码:https://github.com/google-deepmind/gemini_icpc2025
Gemini 在仅 45 分钟内就解决了 8 个问题,接着在三小时内又解决了两个问题,使用了各种高级数据结构和算法来生成解决方案。通过 677 分钟的总时间解决了 10 个问题,若与大学队伍的成绩相比,Gemini 2.5 Deep Think 将排名第二。

图片显示了在 2025 年 ICPC 世界决赛中每个问题的解题时间。Gemini 的时间以蓝色表示,最快的大学队伍时间以灰色表示。
值得一提的是,Gemini 在半小时内成功解决了 C 题,而这道题在竞赛中没有任何大学队伍解出。

这道题目要求找到一种解决方案,通过一系列相互连接的管道将液体分配到多个水库中,目标是找到一种配置使液体尽快充满所有水库。由于每个管道可能是开放的、关闭的,甚至是部分开放的,因此存在无限多种可能的配置,这使得寻找最优配置变得非常困难。
Gemini 找到了一种有效的解决方案:它首先假设每个水库都有一个「优先级值」,表示该水库相对于其他水库的偏好程度。在给定一组优先级值后,可以通过动态规划算法找到最优的管道配置。Gemini 发现,通过应用极小极大定理,可以将原问题转化为寻找使得流量最受限制的优先级值。利用优先级值与最优流量之间的关系,Gemini 通过嵌套三分查找迅速找到最优的优先级值,从而成功解决了 C 题。
据谷歌内部研究表明,类似版本的 Gemini 2.5 Deep Think 也可以在 2023 年和 2024 年 ICPC 世界总决赛中取得金牌级别的表现,与全球前 20 名的编程选手表现相当。
此外,谷歌官方博客还感谢了一众这个项目背后的贡献者。其中 Hanzhao (Maggie) Lin 领导了 Gemini 竞赛编程和 ICPC 2025 工作的整体技术方向,并与 Heng-Tze Cheng 共同领导了整体研究和执行工作。
Hanzhao (Maggie) Lin
Hanzhao (Maggie) Lin 是 Google DeepMind 的高级研究科学家,专注于大规模语言模型和多模态系统的研究与开发。
她的研究方向主要涵盖大规模语言模型、系统架构以及其在教育和复杂推理中的应用。她在 AI 领域的贡献包括参与了 Google DeepMind 的 LaMDA 和 PaLM 2 等大型语言模型的后训练研究,并推动了模型在多模态理解、推理和工具使用等方面的能力提升。
此外,她还主导了 Gemini Deep Think 模型在国际数学奥林匹克(IMO)竞赛中的应用,取得了金牌级别的表现,展示了 AI 在复杂数学推理中的潜力。
Heng-Tze Cheng
Heng-Tze Cheng 是 Google DeepMind 的研究总监兼首席研究科学家,专注于大语言模型和对话 AI 的研究与应用。他在自然语言处理(NLP)、推荐系统、强化学习和多模态推理等领域具有深厚的研究背景。
他本科毕业于台湾大学电机工程系,2013 年于卡内基梅隆大学获得电气与计算机工程博士学位,研究方向包括机器学习和多模态信号处理,2014 年加入 Google,先后在 Google Brain 和 DeepMind 担任技术领导职务。

ICPC 所要求的技能,比如理解复杂问题、制定多步骤的逻辑计划并精准执行,正是许多科学和工程领域所需的核心能力。
AI 此次在 ICPC 中获得金牌级成绩凸显了 AI 在提供创新性解决方案方面的独特优势,能够有效补充人类专家的技能和知识。这也表明,AI 正从单纯的信息处理工具,转变为协助解决复杂推理问题的关键力量。
参考链接:
https://x.com/HengTze/status/1968359525339246825
https://x.com/MostafaRohani/status/1968360976379703569
https://x.com/bminaiev/status/1968363052329484642
.....
#好用的Agent,究竟需要什么?
从一个公众号智能体说起
Agent 今年这么火,AI 圈几乎人人都在讨论。但抛开那些花哨的概念,一个好用的 Agent 究竟应该是什么样的?
咱们不妨接地气一点,从每天都刷一刷的「公众号」聊起。
不知道读者们有没有过这样的困扰:关注的公众号每天推送的文章堆积如山,一不留神,真正感兴趣的、有价值的内容就被淹没在了信息的海洋里。想找某个特定领域的动态?难道真的要一篇篇手动翻阅,跟大海捞针一样吗?
以腾讯元器平台上的「公众号智能体」为例,它提供了一种可能的解决方案。

它最大的特点,是经过公众号创作者授权后,可自动读取该公众号发布的文章,并实时更新为知识库。对于我们前面提到的困惑,这个功能简直是打瞌睡送来了枕头。

基于此,我们构建了一个最基础也最实用的功能:文章推荐小助手。你只需要告诉它你的需求,它就会立刻从知识库中筛选、总结,并精准推荐最相关的几篇文章给你。


除此之外,我们还能衍生出更多神奇的功能,相当于为团队增加了好几个不知疲倦的「数字员工」。
这个看似简单的「公众号智能体」,恰恰揭示了当前行业在喧嚣过后,回归理性的两个核心追问:一个能真正「干活」的 Agent,需要怎样一套工业化的平台来支撑?一个被「造」出来的 Agent,如何才能无缝地「用」在最需要它的地方?
在近期举办的 2025 腾讯全球数字生态大会 AI Agent 产业峰会上,腾讯给出的答案,正是围绕着这两个问题展开。

9 月 17 日,在 2025 腾讯全球数字生态大会上,腾讯云宣布智能体开发平台 3.0 (ADP3.0) 面向全球上线。
腾讯云副总裁、腾讯云智能负责人、腾讯优图实验室负责人吴运声
从「知识问答」到「工业化」平台
「公众号智能体」是面向 C 端用户、以知识问答为核心的典型应用,它出色地解决了特定场景下的信息获取问题,其背后是 RAG 等核心能力的支撑。
然而,当业务场景的复杂度从单纯的知识问答,跃升至为一家拥有 2.88 亿会员、上万家门店的酒店集团提供复杂的业务服务时,这种面向轻量级应用的开发模式,便会触及其工程能力的上限。
正如华住集团首席执行官金辉所言,「用领先科技改造传统服务业,是华住始终坚持的理念」。
面对海量宾客的个性化需求,他们需要的不是一个简单的聊天机器人,而是一个能处理复杂流程的「全能酒店管家」。
例如,当客人提出「需要一瓶水」,智能体不仅要理解需求,更要能在 5 秒内完成响应,自动生成工单并精准调度机器人完成配送。
这种能力的实现,依赖于一套强大的 Workflow 能力。在腾讯云智能体开发平台 (ADP) 上,华住协同搭建了 38 条这样的工作流,将「华小 AI」打造成了一个能处理住前、住中、住后各类复杂任务的「数字员工」,推动 AI 从「对话」到「干活」的跨越式提升,最终实现超 95% 的问答准确率。
这揭示了 Agent 从 Demo 走向生产的核心差异:一个真正好用的 Agent,必须构建在工业化的开发平台上。
腾讯云的思路,便是将 Agent 的开发,从依赖个人经验的「艺术创作」,转变为有标准、有工具、有保障的「工业流程」。其快速迭代的 ADP 3.0 平台,在近 3 个月内就完成了近 600 个功能开发,它提供的不仅是框架,更是一整套覆盖全链路的工程能力:

- 知识处理的进化 (Agentic RAG)
腾讯云副总裁、腾讯云智能产研负责人吴永坚分享道,平台已从传统 RAG 升级至 Agentic RAG。
面对「列出面积大于 100 平米且存在竞争关系的商户」这类复杂问题,智能体不再被动检索,而是能自主规划,将任务拆解为多步,调用不同工具,从多个文档中搜索、筛选并融合信息,最终形成完整回答。
这种从传统 RAG 向 Agentic RAG 的演进,是业界普遍认可的方向,旨在解决单一检索无法应对多维、复杂查询的瓶颈。其挑战在于如何提升大模型对复杂任务的拆解精度,以及对工具调用的成本控制。
其背后,是依托腾讯优图自研 OCR 大模型对复杂文档的高精度解析,以及结合 QQ 浏览器沉淀的工程能力,实现了模型与工程结合的降本增效。
- 确保执行力 (Workflow)
平台在业界率先支持「全局 Agent 视野」,让工作流中的每个节点都能感知全局状态,并支持节点智能回退,极大提升了复杂流程编排的稳定性和可靠性。
这正是华住集团能够实现自动化派单等高级能力的技术基石,对于酒店服务这类需要严谨 SOP (标准作业程序) 的行业,Workflow 的价值尤为突出。
它解决了单纯依靠大模型自由发挥可能导致的「不合规」或「流程错误」问题,通过将确定性流程与大模型的理解能力相结合,实现了可靠性与智能化的平衡,真正解决了 Agent「如何做」的问题。
- 应对复杂任务 (Multi-Agent)
平台新增了两种协同模式。一种是将 Agent 嵌入工作流编排,实现确定性流程与智能体的结合;另一种是 Plan-and-Execute (P&E) 协同模板,由 Planner Agent 负责统筹规划,将复杂任务拆解后分发给不同的 Executor Agent 执行。

腾讯云副总裁、腾讯云智能产研负责人吴永坚
Multi-Agent 机制虽然提升了处理复杂任务的能力上限,但也对开发和调试提出了更高要求,例如如何有效管理 Agent 间的通信与状态同步。
腾讯云提供的 P&E 模板,正是对此类问题的一种工程化解法,这让构建营销、客服、分析等协同工作的「数字员工团队」成为可能。
- 构建开放生态:模型与工具的解耦
工业化生产要求开放与兼容。ADP 平台新增的「模型广场」,不仅内置了腾讯混元,还支持引入月之暗面、Minimax 等行业优质三方模型。
平台开放第三方模型,反映出一种行业趋势:企业客户希望避免被单一模型供应商锁定,并能根据不同任务的性价比需求,灵活选择和组合模型。这考验的是平台的中立性和集成能力。
平台已上架超过 140 个高质量插件,并与腾讯云 TI-ONE 平台打通,用户可将在 TI-ONE 拥有的模型一键同步至 ADP 使用,灵活选择性价比最高的「大脑」。
平台的开放性不仅体现在「引入」,也体现在「输出」。腾讯宣布将陆续开源其优图实验室在 Agent 领域的核心技术,包括已发布的 Youtu-Agent (一个不依赖昂贵闭源模型即可获得优秀效果的智能体框架) 和 Youtu-GraphRAG (一个在 Token 成本和精度上更具优势的知识图谱框架)。
此举旨在推动技术普惠,与开发者共建生态,也反映出其在底层技术上的自信。
更底层,还有 Agent Infra 这样的基础设施:首先是安全执行环境,通过沙箱确保受控运行;其次是可观测与可运营,保证智能体运行可见可管;第三是安全合规,多维度保障合规与可追溯。这些构成了企业安心使用 Agent 的基础设施。
这套组合拳的目标很明确:将重心从「发明」聪明的 AI,转向「制造」可靠的 AI。
谁离用户最近,谁就拥有「最后一公里」
解决了「怎么造」的问题,下一个关键挑战是「怎么用」。一个无法便捷触达用户的 Agent,其商业价值将大打折扣。
让我们回到最初的「公众号智能体」。如果它只能存在于一个独立的 App 里,用户需要下载、注册、学习,那么它的价值便会大打折扣。但如果它能直接内嵌在用户每天使用的 App 里呢?
这就引出了腾讯在 Agent 落地上的一个关键优势:其庞大的用户生态。
绝味食品的案例展示了 Agent 如何深度融入营销链路。其「绝味 AI 会员智能体」基于腾讯企点营销云的 Magic Agent 产品,以及底层的腾讯云 ADP,直接工作在「企业微信」上。
通过企业微信,AI 可以直接与数百万会员进行个性化互动,分析偏好,推送优惠,并引导他们跳转至「微信小程序」完成购买。
官方披露的数据极具说服力:首次实现 AI Agent 参与全链路营销,AI 组的销售业绩是人工组的 3.1 倍,内容点击率 1.8 倍,支付转化率 2.4 倍,企微好友删除率降低 47%,推动营销从「千人一面」进入「万人万面」,迈入「AI 智能体时代」。
这构筑了一个在微信生态内,从触达、互动、转化到数据沉淀的营销闭环:在生态内触达 (企微) -> 在生态内互动 (AI) -> 在生态内转化 (小程序) -> 在生态内沉淀数据。
AI 不再是一个后台工具,而是首次被推到了业务的最前线,直接面对消费者创造增长。这种将 AI 能力无缝注入十亿级用户生态的模式,解决了 AI 应用最关键的「最后一公里」难题。
当 Agent 能够被无缝地嵌入到用户既有的高频使用路径中时,其价值才能被最直接地激发。
腾讯云副总裁、腾讯云智能解决方案负责人王麒表示:「腾讯云智能体开发平台的核心目标是希望将大模型和智能体技术变得真正可用、易用、好用」,让企业能低门槛地构建、集成并运营属于自己的 AI 智能体。期待通过技术引领、能力支持与深度共创,与客户共同打磨优质场景,推动价值实现。
腾讯云副总裁、腾讯云智能解决方案负责人王麒。
结语
从一个简单的公众号助手,到赋能大型连锁集团的复杂业务流程,路径已经清晰:Agent 的价值最终需要通过可靠的工程能力和无缝的用户触达来实现。
本次腾讯全球数字生态大会揭示了 Agent 赛道的关键信号。腾讯集团高级执行副总裁汤道生对此总结道:「向智能化要产业效率,向全球化要市场效率,已经成为企业增长的两大核心动力」。
竞争的焦点不再是模型的参数大小或单一能力的演示,而是转向了更为务实的工程化与生态化能力的比拼。
真正的竞争壁垒正在于此:谁能提供更成熟的工具链,帮助企业更低成本、更高效率地「制造」出可靠的数字员工;并且,谁能提供最短的路径,让这些数字员工直达最广泛的用户群体。
从这个角度看,一个务实、清晰的脚手架,或许比任何关于未来的宏大叙事,都更接近 Agent 的终局。
...
#IndexTTS2
B站出海的强有力支柱:最新开源文本转语音模型IndexTTS-2.0标志零样本TTS进入双维度时代
最近在 B 站上,你是否也刷到过一些 “魔性” 又神奇的 AI 视频?比如英文版《甄嬛传》、坦克飞天、曹操大战孙悟空…… 这些作品不仅完美复现了原角色的音色,连情感和韵律都做到了高度还原!更让人惊讶的是,它们居然全都是靠 AI 生成的!
,时长02:47
英文版甄嬛传他来了
,时长00:58
让坦克飞
,时长05:22
B 站开源 index-tts-2.0 长视频测试,效果真的强,曹操大战孙悟空
,时长15:34
如果让 AI 开中文苹果发布会,indextts2 效果展示
据悉,这些视频都是运用了哔哩哔哩 Index 团队最新开源的文本转语音模型 IndexTTS-2.0, 这一模型从 demo 发布起,就在海内外社区引发了不少的关注。目前该工作在 Github 已超过 10k stars 。


- 论文标题:IndexTTS2: A Breakthrough in Emotionally Expressive and Duration-Controlled Auto-Regressive Zero-Shot Text-to-Speech
- 论文链接:https://arxiv.org/abs/2506.21619
- github 链接:https://github.com/index-tts/index-tts
- 魔搭体验页:https://modelscope.cn/studios/IndexTeam/IndexTTS-2-Demo
- HuggingFace 体验页:https://huggingface.co/spaces/IndexTeam/IndexTTS-2-Demo
- 官宣视频:https://www.bilibili.com/video/BV136a9zqEk5/
近年来,大规模文本转语音(Text-to-Speech, TTS)模型在自然度和表现力上取得了显著进展,但如何让语音「在韵律自然的同时,又能严格对齐时长」仍是悬而未决的难题。传统自回归(Autoregressive, AR)模型虽然在韵律自然性和风格迁移上占优,却难以做到精准时长控制;而非自回归(Non-Autoregressive, NAR)方法虽能轻松操纵时长,却往往牺牲了语音的自然感和情绪表现力。如何在保留 AR 模型优势的同时,突破其核心限制,成为了前沿挑战。
来自哔哩哔哩的 IndexTTS 团队创新性地提出了一种通用于 AR 系统的 “时间编码” 机制,首次解决了传统 AR 模型难以精确控制语音时长的问题。这一新颖的架构设计不仅解决了时长控制问题,更引入了音色与情感的解耦建模,实现了前所未有的情感表现力和灵活控制,在多个指标上全面超越现有 SOTA 系统。
研究方法
IndexTTS2 由三个核心模块组成:Text-to-Semantic(T2S) 、Semantic-to-Mel(S2M) 以及 BigVGANv2 声码器 。首先,T2S 模块基于输入的源文本、风格提示、音色提示以及一个可选的目标语音 token 数,生成对应的语义 token 序列。然后,S2M 模块以语义 token 和音色提示作为输入,进一步预测出梅尔频谱图。最后,BigVGANv2 声码器将梅尔频谱图转换为高质量的语音波形,完成端到端的语音合成过程。
IndexTTS2 可以在零样本条件下生成自然流畅的多情感、跨语言语音。它还支持在自回归框架下精确控制语音时长,让合成既可控又不失自然。同时具备工业级性能,既适合研究探索,也能直接应用到实际场景中。

1、基于 AR 架构的时长控制
在 IndexTTS2 中,针对自回归 (AR) TTS 难以精确控制语音时长的问题,提出了基于 token 数量约束 的解决方案。核心思路是:在生成时可以指定所需的语义 token 数,模型通过一个专门的时长 embedding 将这个信息注入到 Text-to-Semantic 模块,通过对合成 token 的数量强约束来实现生成语音时长控制。训练阶段随机引入不同比例的信号层时长缩放 (如 0.75×、1.25×) 任务,使模型可以学会在各种长度要求下仍然保持语义连贯和情感自然。
实验表明,这种方法在不同语言(中 / 英)上的 token-number error rate 非常低,即模型几乎能严格按照指定的 token 数量生成语音,同时在合成质量、情感保真度和自然度上保持较好表现。换句话说,IndexTTS2 实现了在 AR 模型中罕见的高精度时长控制,使其既能保持逐帧生成带来的细腻表达,又能满足视频配音、音画同步等对时长严格敏感的场景需求。

2、多模态的情绪控制
IndexTTS2 对情感表达和说话人身份进行了有效解耦。模型不仅支持从单一参考音频中复刻音色与情感,还支持分别指定独立的音色参考和情感参考。这意味着用户可以用一个人的音色,说出另一个人的情感,极大地提升了控制的灵活性。
为了降低使用门槛,模型集成了两种情感控制方式。除了通过音频参考进行情感迁移,还引入了基于自然语言描述的情感软指令机制。通过微调大型语言模型(LLM),用户可以使用文本(如自然语言描述、场景描述)来精确引导生成语音的情绪色彩。
3、S2M 模块
为了提升在高强度情感(如哭腔、怒吼)下的语音清晰度,模型引入了 GPT 式潜在表征,并采用基于流匹配(Flow Matching)的 S2M 模块,显著增强了语音生成的鲁棒性和梅尔频谱图的重建质量。

研究结果
1、时长控制的准确性
IndexTTS2 在时长控制方面展现了极高的精确度。在对原始语音时长进行 0.75 倍至 1.25 倍的变速测试中,生成语音的 Token 数量误差率几乎不超过 0.03%,在多数情况下低于 0.02%,证明其时长控制能力精准可靠。

Table 1:不同设置下对持续时长控制的 token 数错误率
2、情感表现力
在情感表现力测试中,IndexTTS2 显著优于其他 SOTA 模型。其情感相似度(ES)高达 0.887,情感 MOS(EMOS)评分达到 4.22,合成的语音情绪饱满、渲染自然,同时保持了极低的词错误率(WER, 1.883%),实现了表现力与清晰度的完美结合。

Table 2:在情感测试集上的结果
3、零样本语音合成能力
在多个公开基准测试集(如 LibriSpeech, SeedTTS)上,IndexTTS2 在客观指标(词错误率 WER、说话人相似度 SS)和主观 MOS 评分(音色、韵律、质量)上均达到或超越了当前最先进的开源模型,包括 MaskGCT, F5-TTS, CosyVoice2 等,展现了其强大的基础合成能力和鲁棒性。

Table 3:在公开测试集上的结果
4、消融实验验证
实验证明,模型中的 GPT 潜在特征对于保证语音清晰度和发音准确性至关重要;而基于流匹配的 S2M 模块相比于传统的离散声学 Token 方案,极大地提升了合成语音的保真度和自然度。
生成效果
语速控制:支持自定义输入合成时长,精准控制语速
音色克隆:同时参考音色和情绪韵律,实现语音特征的高度还原
音色克隆-原始音频,xx,2秒
合成文本:你就需要我这种专业人士的帮助,就像手无缚鸡之力的人进入雪山狩猎,一定需要最老练的猎人指导
音色克隆-合成音频,xx,7秒
多元化的情绪输入:提供独立的情感参考音频、情感向量或文本描述等多种方式,显著提升生成语音的表现力与适用性
- 独立参考音频控制:
多元情绪输入-原始音色,xx,1秒
多元情绪输入-厌恶情绪,xx,0秒
合成文本:你看看你,对我还有没有一点父子之间的信任了。
多元情绪输入-合成音频-厌恶,xx,3秒
- 情绪向量控制:提供高兴、生气、悲伤、恐惧、讨厌、低落、惊喜、平静 8 种情绪向量,支持自由调整情绪权重,并提供随机采样
情绪向量控制-原始音色,xx,11秒
情绪向量 - 惊喜 0.45
合成文本:哇塞!这个爆率也太高了!欧皇附体了!
情绪向量控制-合成音频,xx,3秒
- 描述文本控制:还支持通过自然语言描述来判断情绪
描述文本控制-原始音色,xx,2秒
情绪文本 - You scared me to death! What are you, a ghost?
文本:快躲起来!是他要来了!他要来抓我们了!
描述文本控制-合成音频,xx,6秒
跨语种:支持中英文双语
合成文本:Translate for me,what is a surprise!
跨语种-合成音频,xx,3秒
该模型凭借高质量的情感还原与精准的时长控制,广泛提升了 AI 配音、视频翻译、有声读物、动态漫画、语音对话等系列下游场景的可用性,尤其值得关注的是,IndexTTS-2.0 为 B 站优质内容的出海提供了关键技术支持,在充分保留原声风格与情感特质的基础上,让海外用户享受更加自然、沉浸的听觉感受。这一技术突破不仅极大降低了高质量内容跨语言传播的门槛,也为 AIGC 技术在全球范围内的实际应用奠定了坚实基础,堪称零样本 TTS 技术迈向实用化阶段的重要里程碑。
,时长01:50
总结
IndexTTS2 的提出标志着零样本 TTS 进入「情感可控 + 时长精确」的双维度时代。它不仅大幅提升了 AI 配音、视频翻译等多种下游场景的可用性,同时,也为未来语音合成技术的发展指明了重要方向:如何在 AR 框架下实现对情感、语调等更复杂语音特征的细粒度控制,并持续优化模型性能,为更广泛的交互式应用提供支持。
研究团队现已开放模型权重与代码,这意味着更多开发者和研究人员能够基于 IndexTTS2 构建个性化、沉浸式的语音交互应用。
作者介绍:
本论文主要作者来自哔哩哔哩 Index 语音团队(Bilibili IndexTTS),Index语音团队是一支专注于音频技术创新的研究团队,致力于音频生成、语音合成与音乐技术的前沿探索,重点研究高保真、自然真实、可控性强的语音生成模型。团队推出的全新一代 zero-shot TTS 自回归大模型 IndexTTS2,具备出色的情感表现力,支持音色与情感的自由组合,并创新性地设计了“时长编码”,实现了模型层面的精准时长控制。团队通过深度学习与神经网络技术的不断突破,持续为学术界与工业界提供高质量的语音合成技术支持与创新方案,助力创作者用声音打破表达边界。
....
#英伟达50亿美元入股英特尔
将发布CPU+GPU合体芯片,大结局来了?
他们共同宣布,要把电脑上的 CPU 和 GPU 合成为超级 SoC。
周四晚间,英伟达收购 50 亿美元英特尔股份的新闻引爆了科技圈。
两家公司在 9 月 18 日同时发布公告,宣布达成长期战略合作。英伟达将投资 50 亿美元购买英特尔普通股,基于全新合作,两家公司将共同开发多代定制数据中心和 PC 产品。
在具体内容上,两家公司将专注于利用 NVIDIA NVLink 无缝连接 NVIDIA 和 Intel 架构 —— 将英伟达的 AI 和加速计算优势与英特尔领先的 CPU、x86 生态系统相结合,为客户提供顶尖解决方案。
对于数据中心,英特尔将构建英伟达定制版 x86 CPU,英伟达会将其集成到其 AI 基础设施平台中并提供给市场。
在个人计算领域,英特尔将打造并向市场推出集成 RTX GPU 芯片组的 x86 系统级芯片 (SoC)。这些全新的 x86 RTX SoC 将为各种需要集成世界一流 CPU 和 GPU 的 PC 提供支持。
英伟达计划将以每股 23.28 美元的价格向英特尔普通股投资 50 亿美元(相当于 5% 股份)。不过,此项投资仍需满足惯例成交条件,包括必要的监管批准。
受此消息刺激,在随后开始的交易时段两家公司的股票立即上涨。截至收盘,英伟达上涨了 3.49%,英特尔更是直接暴涨了 22.77%。

显然,现在人们对于英特尔的前景一致看好。
昨天宣布的投资发生后,率先受益的可能是前 OpenAI 超级对齐团队研究员,成立对冲基金的 Leopold Aschenbrenner。他的态势感知基金重仓英特尔股票(第二季度结算占比 20%),据说一天盈利了 10 亿美元以上。
此前,美国政府已持有这家芯片制造巨头约 10% 的股权(价格是 20.47 美元),软银还以每股 23 美元的价格购买了价值 20 亿美元的英特尔首次发行股票。
在昨天晚间的电话会议上,英伟达创始人、CEO 黄仁勋强调,这笔交易将使英伟达能够扩展其架构系统,将 72 块 GPU 与定制 CPU 相结合。
黄仁勋还表示,与英特尔合作意味着英伟达可以在个人设备市场占据更大的份额:「每年笔记本电脑的销量为 1.5 亿台…… 我们现在正在开发一款系统级芯片,将 CPU、GPU 融合成一个巨大的 SoC,这将成为世界上前所未有的新型集成笔记本电脑。」
黄仁勋估计,这笔交易意味着「每年 250 亿至 500 亿美元的商机」。他表示,谈判已持续近一年,美国政府完全没有参与这项合作,不过「他们当然会非常支持」。
英特尔 CEO 陈立武在 X 上发出了自己和黄仁勋的合影,并表示很高兴能与自己的好朋友合作开发多代定制数据中心和 PC 产品。

不过在公司层面上,英伟达和英特尔在过去曾有过漫长的竞争历史。在 2005 年,英特尔曾考虑以 200 亿美元的价格收购英伟达。2006 年,英特尔收回了给英伟达的 x86 交叉授权、总线授权。英伟达因此把英特尔告上法庭,最终以英特尔花费 15 亿美元专利费和解作为了结。
在本次合作中,成为重要股东的英伟达将再次获得多年来梦寐以求的 x86 授权。
人们猜测,除了声明中宣布的内容,英伟达应该也希望能够使用英特尔的先进制程芯片代工业务。目前,英伟达的 GPU 生产基本依赖于台积电。
不过在电话会议中,黄仁勋和陈立武都没有直接回答这个问题。陈立武表示,此次合作的宣布更像是一个「产品合作声明」,并指出英特尔将继续推进自身芯片的研发,两家公司将在稍后决定英特尔是否向英伟达提供这些服务。黄仁勋则强调了英伟达与台积电的合作关系。
对于人们感兴趣的超级 SoC 芯片,黄仁勋表示:「我们将打造革命性的产品,此前从未有过类似的产品。我们所有参与研发的人都对此非常兴奋,参与研发的架构师也同样如此。我们期待着随着时间的推移,向大家分享更多相关信息。」
参考内容:
.....
#Reconstruction Alignment, RecA
理解帮助生成?RecA自监督训练让统一多模态模型直升SOTA
谢集,浙江大学竺可桢学院大四学生,于加州大学伯克利分校(BAIR)进行访问,研究方向为统一多模态理解生成大模型。第二作者为加州大学伯克利分校的 Trevor Darrell,第三作者为华盛顿大学的 Luke Zettlemoyer,通讯作者是 XuDong Wang, Meta GenAl Research Scientist,博士毕业于加州大学伯克利分校(BAIR 实验室),这篇工作为他在博士期间完成。
背景:统一多模态理解与生成模型的挑战
统一多模态模型(Unified Multimodal Models, UMMs)旨在将视觉理解和生成统一于单一模型架构。UMM 继承了多模态大语言模型 (Multimodal Large Language Models, MLLMs) 可以很轻松地辨别物体的左右、颜色、种类。但是很多生成模型连「一只黑色的猫和白色的狗」,「黄色西兰花」都无法生成。这体现了当前统一多模态模型在视觉理解和生成能力上的不平衡:它们往往在理解图像内容方面表现出色,但在根据文本描述生成图像时却力不从心。这是为什么呢?
实际上,图片是一个「稠密」的模态,文字是一个「稀疏」的模态,从一个稠密的信息里提取稀疏的信息(VQA,Image Captioning)是相对轻松的,但是要从稀疏的信息去构建稠密的信息则更为困难。传统的文生图训练依赖大规模的图像 - 文本对数据,这些文本描述 (text caption) 无法完整的表述图片里的所有信息。比如物体位置关系、几何结构,物体的纹理和风格等。这可能导致图像生成模型学到不完整甚至有偏差的视觉概念(例如,将「西兰花」与「绿色」联系在一起,导致模型无法生成「黄色西兰花」)。我们称这种文本监督为「稀疏监督」(sparse supervision)。

方法:重建对齐 (Reconstruction Alignment, RecA)
有没有「稠密监督」(Dense Supervision),可以让模型学到更完整的视觉概念呢?答案是有的。图片本身正是最好的信息载体。UMM 提供了一个将图片作为「提示词」(prompt) 输入的机会。现在的 UMM 的视觉理解编码器 (Visual Understanding Encoder),如 CLIP, SigLIP,已经可以把图片映射到了 LLM 的语义空间 (language-aligned semantic space)。
以此为动机,我们提出了一种简单而有效的后训练方法 —— 重建对齐(Reconstruction Alignment, RecA)。RecA 并非对模型架构本身做出改动,而是在模型常规训练完成后,额外进行一阶段自监督的后训练。
- Arxiv:https://alphaxiv.org/abs/2509.07295
- 代码:https://github.com/HorizonWind2004/reconstruction-alignment
- 项目主页:https://reconstruction-alignment.github.io/
具体来说,在 RecA 训练过程中,模型首先利用其视觉理解编码器从输入图像提取出语义嵌入特征(例如采用预训练的 CLIP、DINO 等模型获取图像的高维语义表示),与一个模板文本嵌入相融合,再送入统一多模态模型,使其以此为条件试图重建出原始输入图像。根据生成的图像与原图像之间的差异计算自监督重建损失,RecA 将视觉理解分支中蕴含的细节知识有效对齐到生成分支。
值得一提的是,RecA 的训练不需要任何的图像 - 文本对,只需未标注的图像即可完成训练。训练完成后,模型在推理时并不需要额外输入这些视觉嵌入,仍然像普通生成模型一样,仅通过文本提示即可工作;换言之,RecA 是一种纯训练阶段的对齐策略,不会增加推理阶段的开销或改变使用方式。

实验结果
通用性(Generality)
为了验证 RecA 的有效性,我们在四种代表性的统一多模态模型上进行了实验。1. Show-o (AR), Harmon (AR+MAR), OpenUni (AR+Diffusion, Metaqueries 开源版), BAGEL (AR+Diffusion) 等模型,涵盖了当前的主流架构。可以发现,RecA 在所有模型上均带来了显著的性能提升,显示出其方法的通用性和稳健性。

SOTA 结果(State-of-the-art Results)
我们使用 RecA 后训练得到的 Harmon-1.5B 模型展现出了极强的提高,在不使用 GPT-4o-Image 蒸馏数据和 RLHF 的情况下,在 GenEval 和 DPGBench 上达到了 0.86 和 87.21 的成绩。如果使用 GPT-4o-Image 蒸馏数据 BLIP3o-60k,通过两阶段策略(先进行有监督微调 SFT,再进行 RecA 无监督训练),Harmon 模型的性能进一步提升到 GenEval 0.90,DPGBench 88.15,全面刷新了现有记录。

对于 BAGEL,我们发现其在图像编辑任务上也取得了显著提升。在 ImgEdit 基准上的评分从 3.38 提升至 3.75,GEdit 评分从 6.94 上升到 7.25。经过 RecA 的 BAGEL 模型在某些编辑能力上超越最新的 SOTA 模型,如 Black Forest Labs 推出的 12 亿参数图像编辑模型 FLUX.1 Kontext。

可视化效果
生成能力展示:

编辑能力展示:

训练前后的生成能力对比:

训练前后的编辑结果对比:

.......
#超强开源模型Qwen3、DeepSeek-V3.1,都被云计算一哥「收」了
在 AI 领域,亚马逊云科技有着自己的打法,模型选择权交给用户。
「云计算一哥」亚马逊云科技又「收」新模型了。
就在刚刚过去的 8 月,亚马逊云科技宣布,其 Amazon Bedrock 和 Amazon SageMaker 两大 AI 平台开始支持 OpenAI 新开源模型。
紧接着今天又传出新消息,两大重量级国产大模型 Qwen3 和 DeepSeek-V3.1 也被亚马逊云科技收入 Amazon Bedrock。
目前这两款模型均已在 Amazon Bedrock 全球上线,可用区域包括美国西部(俄勒冈)、亚太地区(孟买、东京)、欧洲(伦敦、斯德哥尔摩)等。
这一连串快速上新的动作,展现了亚马逊云科技在全球 AI 竞赛中的敏锐嗅觉和执行力。无论是来自 Meta、Mistral AI 和 OpenAI 等国际顶尖的开放模型,还是国产开源模型,亚马逊云科技都在第一时间将其纳入生态版图,为开发者与企业用户提供了前所未有的多样化选择。
这也恰恰是亚马逊云科技长期坚持的 「Choice Matters(选择大于一切)」战略的最佳注解:没有一个大模型可以解决所有问题,唯有通过多模型的互补与协同,才能让 AI 真正匹配现实世界的复杂需求。
此外,大家关心的模型安全问题,在亚马逊云科技这里也得到了保障:客户对他们自己的数据拥有完全的控制权,亚马逊云科技不会将模型的输入和输出数据与模型提供商共享,也不会用于改进基础模型。
两大顶尖国产模型登陆 Amazon Bedrock
随着 Qwen3 和 DeepSeek-V3.1 两大国产 AI 模型的正式发布,Amazon Bedrock 进一步扩展了其平台上管理完善、行业领先的模型阵容。
这两款模型的加入,不仅丰富了现有的开放权重模型选择,为全球客户提供更多创新的可能和灵活的应用场景,也进一步加强了亚马逊云科技在生成式 AI 领域的竞争力和影响力。

Qwen3 模型首次上线 Amazon Bedrock
作为国产 AI 模型的扛把子,Qwen3 模型首次亮相 Amazon Bedrock,成为该平台第 14 个模型提供商。此举不仅标志着中国 AI 开源生态与国际云计算的深度融合,也进一步推动了全球 AI 技术的合作与发展。
Qwen3 模型是阿里巴巴开源的新一代通义千问模型,在推理、指令遵循、多语言支持和工具调用等方面均大幅提升,创下了国产和全球开源模型的新性能纪录。与同类模型相比,Qwen3 模型的部署成本大幅下降,仅需 4 张 H20 便能实现其满血版部署,显存占用也只有性能相近模型的三分之一,极大地降低了硬件需求。
此次上线的 Qwen3 模型包括四个版本:Qwen3-Coder-480B-A35B-Instruct、Qwen3-Coder-30B-A3B-Instruct、Qwen3-235B-A22B-Instruct-2507 和 Qwen3-32B-Dense,并分别针对不同应用场景进行优化。
- Qwen3-Coder-480B-A35B-Instruct 专为复杂的软件工程任务设计,擅长高级代码生成、代码库分析和集成外部工具;
- Qwen3-Coder-30B-A3B-Instruct 特别优化了代码补全、重构及编程相关问题解答,适用于多种编程语言;
- Qwen3-235B-A22B-Instruct-2507 则提供了强大的通用推理和指令跟随能力,适用于需要平衡性能与效率的任务;
- Qwen3-32B-Dense 则适用于要求稳定性能、低延迟和成本优化的场景,如移动设备和边缘计算。
在模型架构方面,Qwen3 模型采用了 MoE 和密集型架构。其中,MoE 模型如 Qwen3-Coder-480B-A35B-Instruct 和 Qwen3-Coder-30B-A3B-Instruct,通过动态激活部分参数,实现高效推理,适用于复杂编程和智能体任务。而密集型 Qwen3-32B 则在所有参数上提供稳定一致的性能,适合低延迟和资源受限的环境。
同时,Qwen3 模型还具备强大的智能体能力,能够执行多步推理和结构化规划,可以在一次模型调用中生成输出并调用外部工具或 API,支持与外部环境的标准化通信,且能够在长时间会话中维持扩展上下文。
此外,Qwen3 还引入了混合思维模式,支持思维模式和非思维模式两种推理方式,思维模式适用于需要逐步推理的复杂任务,而非思维模式则提供快速响应,适合对速度要求更高的场景。这一创新帮助开发者在复杂任务和对响应速度要求高的任务之间找到平衡。Qwen3-Coder 模型原生支持 256K 个 token 的上下文窗口,使用外推方法可扩展到 100 万个 token,使其能够处理大规模的代码库、技术文档或长时间对话历史,进一步提升了长上下文处理的能力。
DeepSeek-V3.1 上线 Amazon Bedrock
除了 Qwen3,在提到国产开源模型时,DeepSeek 无疑是绕不开的名字。凭借高效的推理性能、极具竞争力的性价比以及活跃的社区生态,DeepSeek 已经成为企业在大规模应用 AI 时的重要选择。
亚马逊云科技也是首家提供全托管式 DeepSeek 模型的海外云厂商。
早在今年三月,亚马逊云科技率先在云服务商中以无服务器(serverless)的方式提供 DeepSeek-R1,并在 Amazon Bedrock 上将其作为完全托管、全面可用的模型正式上线。
延续这一先行一步的策略,亚马逊云科技在对合作伙伴最新大模型的支持上始终保持着及时快速响应。也正因如此,当 DeepSeek 发布新一代模型 DeepSeek-V3.1 时,他们便在第一时间官宣全面支持,将其迅速纳入Amazon Bedrock 的模型版图。

DeepSeek-V3.1 是一个混合推理模型,同时支持思考模式与非思考模式。在思考效率上,相比 DeepSeek-R1-0528,DeepSeek-V3.1-Think 能在更短时间内给出答案。这种可调节的推理机制,不仅提升了模型在不同应用中的适配性,也让 AI 的使用更加可控和高效。

与此同时,DeepSeek-V3.1 在代码生成、Agentic AI 工具调用等方面展现出强劲的性能。在模型上线 Amazon Bedrock 后,用户可借助其强大的代码生成、补全、调试能力,显著提升开发效率。此外,其优秀的工具调用能力,使开发者能够构建更智能、更自主的 AI Agent ,处理更复杂任务。
幸运的是,DeepSeek-V3.1 这些功能,现在全部都能在 Amazon Bedrock 上体验。
Qwen3 和 DeepSeek 最新模型的加入,Amazon Bedrock 上完全托管的大模型家族又进一步壮大。到目前为止,Amazon Bedrock 已提供了 249 款大模型,覆盖从通用对话、生成,到多语言理解与代码助手等多个应用类型,用户都能在此找到最适合自身业务的模型。
随着不断引入更多大模型厂商并扩充托管模型阵列,Amazon Bedrock 已汇聚包括 Anthropic 、DeepSeek、亚马逊云科技自研 Nova 模型在内的十四家主流厂商,构建起多模型并存、多场景适配的开放格局。这不仅极大丰富了技术多样性与选择空间,也为亚马逊云科技在未来 AI 生态中的话语权奠定了坚实基础。
大模型选型实战:性能稳定高速
xxx迫不及待地上手体验了一波。
在 Amazon Bedrock 上用于测评对比和挑选最合适业务的大模型的「大模型选型实战」Playground,我们测试了最新上线的 Qwen3 和 DeepSeek 模型。

先让 DeepSeek-V3.1 写一篇科幻微小说来简单测试一下可行性。

从生成的故事来看,Amazon Bedrock 版 DeepSeek-V3.1 的表现可圈可点,故事悬念和文笔都相当不错。
「大模型选型实战」Playground 还提供了「比较模式」,让我们可以直接让两个模型同台竞技,看它们在同样提示词下会有怎样的表现。
接下来我们就让 DeepSeek-V3.1 和 Qwen3-235B-A22B-Instruct-2507 同时登台,演示一下它们的混合推理能力,看看它们究竟能否根据任务难度自行决定是否推理和深度思考。先来个简单任务:
小明有 3 个苹果,吃掉了 1 个,还剩几个?请直接回答。

对于这个简单问题,两个模型几乎都是瞬时完成了任务 —— 都在半秒左右(模型名右侧第三个数据,前两个数据分别是输入和输出的 token 数量)给出了正确答案。很显然,对于这个简单任务,这两个模型都没有(也无需)进行深度思考。
接下来上一个难度更大一点、涉及到多步计算的任务:
小明有 24 个苹果。他先吃掉 1/3,剩下的平均分给 3 个朋友。后来,每个朋友又把自己的一半苹果还给小明。最后,小明手里一共有多少个苹果?请逐步推理。


可以看到,这两个模型同样正确地完成了任务并给出了整个推理过程。而仔细观察,我们又能发现这两个混合推理模型的回答各有风格。比如 Qwen3-235B-A22B-Instruct-2507 的计算过程分成了 5 步,而 DeepSeek-V3.1 用了 4 步;另外前者的推理过程中的 LaTeX 并没有渲染,而后者的完成了渲染。用户可以根据自身的业务流程需求及偏好选择合适的模型。
最后我们再让 Qwen3-Coder-480B-A35B-Instruct 上场,为我们编写一个「俄罗斯方块 + 贪吃蛇」游戏:
用 Python(使用 pygame)编写一个融合俄罗斯方块和贪吃蛇的小游戏:画面分为上下两部分,上半部分有一条会自动移动的蛇,玩家需控制下落方块左右移动以躲避蛇;当方块进入下半部分后,按照俄罗斯方块规则继续下落,玩家需要把它放入合适位置以消除整行。若方块与蛇相撞则游戏结束;支持方向键移动、空格键加速下落;蛇可随机改变方向。程序需包含初始化、事件处理、逻辑更新和渲染绘制等模块,并写清注释。

该模型仅用半分钟就完成了任务!下面将代码复制出去运行一下。

这个 Qwen3-Coder 首次完成的代码就基本正确地完成了提示词所述的所有游戏逻辑,即使不修改也基本可玩。对于其中显示不出的字符,我们也只需对代码中的字体设置做简单微调,即可解决。

整个过程中,Amazon Bedrock 提供的服务都非常稳定高速,提供的全量模型的性能也能得到充分保证。
亚马逊云科技:我们也很看重开放权重模型
我们不难发现,Qwen3 以及 DeepSeek-V3.1 都是国产开源阵列中的佼佼者,加上之前的 gpt-oss(120b 和 20b),亚马逊云科技都将它们纳入 Amazon Bedrock 平台,彰显了其对开源生态的重视与支持。
在亚马逊云科技看来,向客户提供多样化的专有模型和开源模型是解锁全球客户在生成式 AI 领域创新自由的关键。
一方面用户无需在不同供应商、不同环境之间辗转,即可在同一个平台上实验、比较、部署和优化来自多方的顶级模型能力。
另一方面,相比闭源模型,开源模型有着独特的优势,特别是在定制化开发和透明性方面,给用户带来了更大的灵活性和控制权。
举例来说,在 Amazon Bedrock 上,用户可以通过开源模型直接调用经过优化的托管推理服务,实现快速应用部署,而无需从头开始搭建基础设施。这种便捷的方式,可以帮助用户迅速将生成式 AI 集成到自己现有的工作流程和业务场景中。
此外,开源模型的真正价值不仅仅在于其即用性,更在于其开放权重的特性。用户可以在原始模型的基础上,利用自己的行业数据和特定需求,进行二次开发和定制训练。例如,某些行业可能需要更精确的语义理解,通过开源模型,用户可以根据自身的实际情况调整训练集、优化模型架构,甚至引入新的技术与算法。这种能力使得企业能够打造高度个性化、符合行业特色的智能解决方案,进而在市场中获得竞争优势。
更重要的是,开源模型拥有很高的透明性。企业和用户可以清晰了解模型的结构、训练数据和算法流程,这不仅增强了对模型行为的预测能力,也提高了在合规性和道德方面的可控性,真正体现了亚马逊云科技以用户为中心的服务理念。
正如 Amazon Bedrock 总监 Luis Wang 所言:「开放权重模型代表着 AI 创新的重要前沿,因此我们投入大量精力,致力于将亚马逊云科技打造为安全、大规模且经济高效地运行这些模型的最佳平台。我们认为,不存在一个适合所有用例的最佳模型…… 许多客户喜欢使用开放模型,而开放模型的优势之一就是您可以拥有更大的灵活性来使用它。」
Choice Matters
没有一个模型可以一统天下,选择更重要
在最近一次采访中,亚马逊云科技 CEO Matt Garman 将 AI 描述为「几十年来见过的可能发展最快的技术」。他认为,AI 不仅会像互联网和云计算一样引发深刻变革,未来几十年也将是持续创新的黄金期。
为了帮助各类公司在 AI 浪潮中不断创新和落地,亚马逊云科技一直秉持「Choice Matters」(选择大于一切)理念。
「Choice Matters」并非空洞的口号,而是根植于亚马逊云科技对技术演进和客户需求的深刻洞察。AI 应用场景复杂多样,没有任何一个 AI 模型能够成为所有问题和场景的「万能钥匙」,企业客户受性能、成本、具体任务、数据隐私与合规等多重因素影响,需求更是千差万别。因此,将客户锁定在单一技术路径,无异于限制其创新潜力。
正是在此背景下,亚马逊云科技推出了能够承载多样化模型的 Amazon Bedrock 和 Amazon SageMaker 两大平台,并于 2024 年 re:Invent 大会上正式将「Choice Matters」确立为其生成式 AI 的核心战略,旨在将选择权和技术自由度彻底交还给客户。
截至目前,亚马逊云科技在 Amazon Bedrock 和 SageMaker 上构建了一个拥有超过 400 款模型的模型库,让客户能够像在超市挑选商品一样,根据自身独特的业务需求,灵活比较、测试并组合最适合的模型,从而构建出端到端的 AI 应用。
于企业客户而言,这一策略意味着最大化业务价值与加速实现落地。企业无需削足适履地去适应某个固定模型,而是可以像搭积木一样,以多模型协作的方式,将不同模型精准应用于营销、客服、编程等不同环节,推动 AI 驱动的业务转型,形成 Matt 所言的「飞轮效应」。
对亚马逊云科技自身乃至整个行业来说,「Choice Matters」构成了其最核心的差异化竞争优势。它避免了亚马逊云科技与模型提供商陷入正面竞争,转而专注于其最擅长的领域,即成为中立、丰富且可靠的 AI 基础设施层。
这种开放共赢的策略,吸引了包括初创公司、大型企业在内的多样化客户生态,使各类企业都能找到适合自身的创新路径,从而巩固了亚马逊云科技作为 AI 时代创新基座的地位,为其长期增长奠定了坚实基础。
最后,想在Amazon Bedrock上尝试这两款模型的小伙伴,指路:https://dev.amazoncloud.cn/experience/cloudlab?id=67bc1b7c8ea6eb2ae682bde3&visitfrom=1P_social_0919&sc_medium=owned&sc_campaign=cloudlab&sc_channel=1P_social_0919
....
#Ring-flash-2.0
攻克大模型训推差异难题,蚂蚁开源新一代推理模型
“MoE+Long-CoT(长思维链)+RL(强化学习)” 这条技术路线存在难以兼顾训练稳定性和效果的难题。9 月 19 日,蚂蚁百灵大模型团队把 “难啃的骨头” 直接做成开源礼包 ——Ring-flash-2.0。100B 总参、6.1B 激活,数学 AIME25 拿下 86.98 分,CodeForces elo 分数 90.23,128K 上下文实测 200+token/s。
更关键的是,他们通过独创的棒冰(icepop)算法和长周期的 RL 训练,Ring-flash-2.0 在多项推理榜单上(数学、代码和逻辑推理)取得了显著突破,性能达到了 40B 以内 dense 模型的 SOTA 水平,甚至可与参数量更大的 MoE 模型相媲美。


Ring-flash-2.0 性能表现
xxx深度拆解,这一开源项目,为什么可能改写下一阶段大模型的竞争节奏。
一、从 “不能用” 到 “敢开源”:MoE 长思考的临界点
2025 年,业内流行一张 “死亡曲线”:在长思维链场景下,MoE 模型 RL 训练存在奖励崩溃的问题。于是大家只能把学习率调小、任务提前终止,无法继续训练。
棒冰(icepop)算法:让 RL 进行长周期的稳定训练
Ring-flash-2.0 的破冰点在于 “棒冰(icepop)”:双向截断 + 掩码修正,一句话总结 ——“把训推精度差异过大的 token 当场冻住,不让它回传梯度”。
最终,icepop 能够保持稳定的强化学习训练过程,避免了 GRPO 出现的训练崩溃问题。

左图为 GRPO 训练到 180-200 步开始崩溃,icepop 能实现持续稳定提升; 右图为 GRPO 训练不久出现梯度爆炸,icepop 能持续稳定在合理范围。
与 GRPO 相比,icepop 还将训推精度差异约束在合理范围内,显示出对于控制训推精度差异有效性。

左图为 GRPO 训推精度差异随着训练成指数上升,icepop 较为平稳;右图为训推精度差异最大值,GRPO 随着训练上升非常明显,icepop 维持在较低水位。
效果肉眼可见:训练再也不崩,百灵团队内部笑称,“终于不用担心训练无法长跑的问题”。
详细的棒冰(icepop)算法介绍参考技术博客:https://ringtech.notion.site/icepop
Two-staged RL:先 “算对”,再 “像人”
百灵大模型团队首先采用 Long-CoT SFT,采用包含数学、代码、逻辑和科学四大领域为主体的多学科高质量推理数据集,让模型 “学会思考”;第二步,通过可验证奖励的 RLVR(Reinforcement Learning with Verifiable Rewards),把推理逼到极限;随后,加入 RLHF,用高质量人类偏好数据,把格式、安全、可读性拉回舒适区。

百灵团队验证了直接融合 RLVR+RLHF 的联合训练和 Two-staged RL,两种方式在实验中效果差异不大。 但由于 RLVR 和 RLHF 的问题难度不一致,RLHF 的思维链长度相对较短,放在一起训练会有较多等待长尾现象,从工程效率角度,使用了 Two-staged RL 方案。
二、6.1B 激活打平 40B Dense,成本曲线出现 “拐点”
大模型竞争进入 “第二幕”,核心指标不再是 “谁参数多”,而是 “谁性价比高”。

Ring-flash-2.0 架构图。
继承 Ling 2.0 系列的高效 MoE 设计,通过 1/32 专家激活比、MTP 层等架构优化,Ring-flash-2.0 仅激活 6.1B (non-embedding 4.8B) 参数,即可等效撬动约 40B dense 模型的性能。
得益于小激活、高稀疏度的设计,Ring-flash-2.0 在 4 张 H20 部署下实现 200+ token/s 的吞吐,大幅降低高并发场景下 Thinking 模型的推理成本。同时,Ring-flash 借助 YaRN 外推可支持 128K 长上下文,随着输出长度的增加,其相对加速比最高可达 7 倍以上。
,时长01:13
生成速度对比
,时长00:46
竞赛数学视频
,时长00:56
贪吃蛇case
,时长01:15
arcprize case
,时长00:34
冒泡排序可视化

粒子烟花模拟
生成搜索引擎首页 query:请仿照 Perplexity,设计并生成一个搜索引擎首页,网站名称为 “想搜”,slogan 为 “想搜,才会赢”。请实现基本的搜索界面、风格化 Banner 和搜索输入区。
,时长00:19
生成搜索引擎首页
结语:大模型竞争进入 “高性价比” 时代
从 2022 年 ChatGPT 点燃生成式 AI,到 2024 年长思考成为新战场,行业一直在等一个 “既聪明又便宜” 的推理模型。Ring-flash-2.0 用 100B 总参、6.1B 激活、200+token/s 的速度,把「Long-CoT + RL」做到工程可落地,还顺手把训练稳定性、推理成本、开源生态一次性打包。
如果说 GPT-4 开启了 “大模型可用时代”,那 Ring-flash-2.0 或许正式拉开了 “MoE 长思考高性价比时代” 的帷幕。剩下的问题只有一个:你准备用它做什么?
开源地址:
- HuggingFace:https://huggingface.co/inclusionAI/Ring-flash-2.0
- ModelScope:https://modelscope.cn/models/inclusionAI/Ring-flash-2.0
- GitHub: https://github.com/inclusionAI/Ring-V2
- 技术博客: https://ringtech.notion.site/icepop
.......
更多推荐
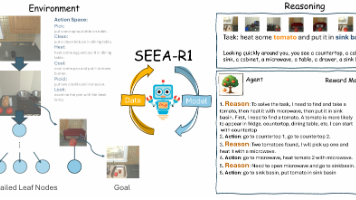
 31
31 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)