
大模型与网络安全方向综述论文《LLMs in Cyber Security: Bridging Practice and Education》——LLM在网安领域的发展和6个关键领域的应用
大模型与网络安全方向综述论文《LLMs in Cyber Security: Bridging Practice and Education》——LLM在网安领域的发展和6个关键领域的应用
·
文章目录
说明
- 本文并非传统的论文精读方式进行记录,从问题背景、研究方法、研究结果、缺陷和展望方面展开。这里仅仅总结与本人(网络空间安全方向相关的关键部分综述内容、结论),有关LLM与网络安全在教育和实践方面的具体内容,请参看原文。
- LLMs in Cyber Security: Bridging Practice and Education
- 论文提交日期为2025.5.8,发布日期为2025.7.8。各领域有关最新情况,随时间变化,请及时关注各领域内最新发展态势。
论文摘要
- Large Language Models (LLMs) have emerged as powerful tools in cyber security, enabling automation, threat detection, and adaptive learning. Their ability to process unstructured data and generate context-aware outputs supports both operational tasks and educational initiatives. Despite their growing adoption, current research often focuses on isolated applications, lacking a systematic understanding of how LLMs align with domain-specific requirements and pedagogical effectiveness. This highlights a pressing need for comprehensive evaluations that address the challenges of integration, generalization, and ethical deployment in both operational and educational cyber security environments. Therefore, this paper provides a comprehensive and State-of-the-Art review of the significant role of LLMs in cyber security, addressing both operational and educational dimensions. It introduces a holistic framework that categorizes LLM applications into six key cyber security domains, examining each in depth to demonstrate their impact on automation, context-aware reasoning, and adaptability to emerging threats. The paper highlights the potential of LLMs to enhance operational performance and educational effectiveness while also exploring emerging technical, ethical, and security challenges. The paper also uniquely addresses the underexamined area of LLMs in cyber security education by reviewing recent studies and illustrating how these models support personalized learning, hands-on training, and awareness initiatives. The key findings reveal that while LLMs offer significant potential in automating tasks and enabling personalized learning, challenges remain in model generalization, ethical deployment, and production readiness. Finally, the paper discusses open issues and future research directions for the application of LLMs in both operational and educational contexts. This paper serves as a valuable reference for researchers, educators, and practitioners aiming to develop intelligent, adaptive, scalable, and ethically responsible LLM-based cyber security solutions.
- 大型语言模型(LLMs)已成为网络安全领域强大的工具,能够实现自动化、威胁检测和自适应学习。它们处理非结构化数据并生成情境感知输出的能力,支持了操作任务和教育计划。尽管它们的应用日益广泛,当前研究往往集中于孤立的应用,缺乏对 LLMs 如何与特定领域需求及教学有效性相契合的系统理解。这凸显了在操作和教育网络安全环境中,针对集成、泛化和伦理部署挑战进行全面评估的迫切需求。因此,本文对 LLMs 在网络安全中的重要作用进行了全面且最前沿的综述,涵盖了操作和教育两个维度。它介绍了一个整体框架,将 LLM 应用分为六个关键网络安全领域,深入分析了每个领域,以展示它们对自动化、情境感知推理以及对新兴威胁适应性的影响。 该论文强调了 LLMs 在提升运营效能和教育效果方面的潜力,同时探讨了新兴的技术、伦理和安全挑战。论文还独特地关注了 LLMs 在网络安全教育中尚未得到充分研究的领域,通过回顾近期研究并说明这些模型如何支持个性化学习、实践培训和意识倡议。**主要研究发现表明,虽然 LLMs 在自动化任务和实现个性化学习方面具有巨大潜力,但在模型泛化、伦理部署和生产就绪方面仍存在挑战。**最后,论文讨论了 LLMs 在运营和教育背景下应用的开放性问题及未来研究方向。本文为旨在开发智能、自适应、可扩展且具有伦理责任感的基于 LLMs 的网络安全解决方案的研究人员、教育工作者和从业者提供了宝贵的参考。
主要贡献
论文的贡献可总结如下:
- 为网络安全中 LLM 的应用提供了全面、最前沿的综述,涵盖运营和教育领域。
- 提出了一种整体框架,系统地对 LLM 在六个核心网络安全领域的应用进行分类,突出了其在自动化、情境感知推理以及适应不断变化的威胁方面的作用。
- 探索了利用 LLM 在网络安全各项职能中实现多样化实践机会,突出了其新兴能力。
- 识别并批判性地考察将 LLMs 集成到网络环境中的新兴挑战,包括技术、伦理和安全相关的影响。
- 对网络安全教育中的 LLMs 进行深入综述,分析其在个性化学习、互动培训和意识建设中的应用,同时讨论关键挑战。
- 概述开放性问题,并为 LLMs 在网络安全实践和教育中的负责任和有效使用提出未来研究方向。
AI技术在网络安全的发展和应用史
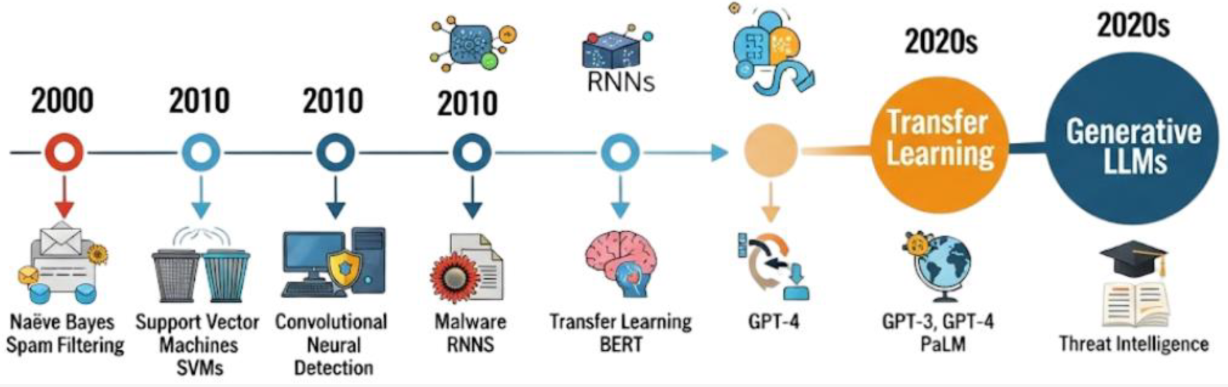
- 传统的网络安全机制,主要是基于规则的系统,在早期计算环境中有效,因为当时的威胁相对可预测且动态性较低。然而,零日漏洞、变形恶意软件和定向攻击的激增要求更具适应性和智能性的防御机制,从而推动了 AI/ML 技术的应用。
- 机器学习在网络安全领域的最初应用出现在2000年,特别是在垃圾邮件过滤和入侵检测系统(IDSs)中。最早的成功应用之一是使用朴素贝叶斯(NB)和支持向量机(SVM)进行垃圾邮件分类。
- 2010年代见证向深度学习(DL)技术的转变,这得益于计算能力的提升和大规模数据集的发展。循环神经网络(RNNs)和卷积神经网络(CNNs)被应用于检测僵尸网络、网络入侵和恶意软件。
- 近年来,迁移学习和预训练模型的兴起为网络安全应用开辟了新的前沿,BERT 和 GPT 等模型被应用于威胁情报、钓鱼检测和代码分析等方面。
- 传统的机器学习模型,如支持向量机(SVMs)和决策树,提供透明度和效率,但需大量的特征工程,并且难以适应新型威胁方面。
- 深度学习技术通过学习层次化特征提高了检测精度和可扩展性,但是缺乏可解释性、计算成本高。
- 预训练语言模型和大型语言模型(LLMs)在处理非结构化数据和执行复杂推理任务方面表现出色。但是受对抗性提示的影响、幻觉以及滥用相关的问题。
传统网络安全系统 VS 基于LLM安全系统
| 标准 | 传统网络安全系统 | 基于LLM的系统 |
|---|---|---|
| 方法 | 基于规则、统计和特征工程 | 上下文感知、语义和生成式 |
| 数据需求 | 标记数据集和广泛的特征工程 | 可以处理未标记数据并支持少样本/零样本学习 |
| 范围 | 特定领域. | 多领域 |
| 处理自然语言处理 | NLP 能力有限 | 具备对文本的本地理解和生成能力 |
| 对新威胁的适应性 | 速度慢。需要手动更新或重新训练 | 速度快。能够跨任务泛化并快速适应 |
| 可解释性 | 有限。通常需要外部解释 | 中等;输出可解释,但并不总是可说明 |
| 对抗性利用 | 较低,但易受混淆攻击。 | 较高,由于提示注入、幻觉和双重用途问题 |
| 与分析师的集成 | 提供警报或日志。 | 可作为智能助手或协作者。 |
| 可扩展性 | 受限于预定义规则和基础设施 | 由于基于云的推理和并行处理,具有高度可扩展性。 |
| 实时分析 | 对已知特征有效,但在面对新型攻击时存在困难 | 能够近乎实时地处理和关联非结构化数据 |
| 误报/漏报率 | 由于规则僵化,导致高误报率 | 上下文感知过滤可以减少误报,但可能会引入幻觉 |
| 部署成本 | 中等(硬件/软件许可证)。 | 可能较高(API 成本和 GPU 计算),但定价模式灵活 |
| 维护开销 | 需要频繁更新规则/签名 | 通过微调实现自我改进,但需要监督以防止漂移/幻觉 |
| 伦理风险 | 已充分理解的监管一致性。 | 日益增长的担忧,例如偏见、隐私或生成内容的不当使用 |
| 示例 | Snort 入侵检测系统, ClamAV, NetFlow 分析器 | GPT-4 用于钓鱼检测,Copilot 用于安全编码,LLaMA-Guard等。 |
LLM应用在网安领域的6大应用
- LLM 应用网络安全领域可以划分为六个关键方面。这些领域基于研究的成熟度、实际影响以及 LLMs 在解决现实世界网络安全挑战中已证明其价值,包括漏洞检测、异常检测、网络威胁情报、区块链安全、渗透测试和数字取证。

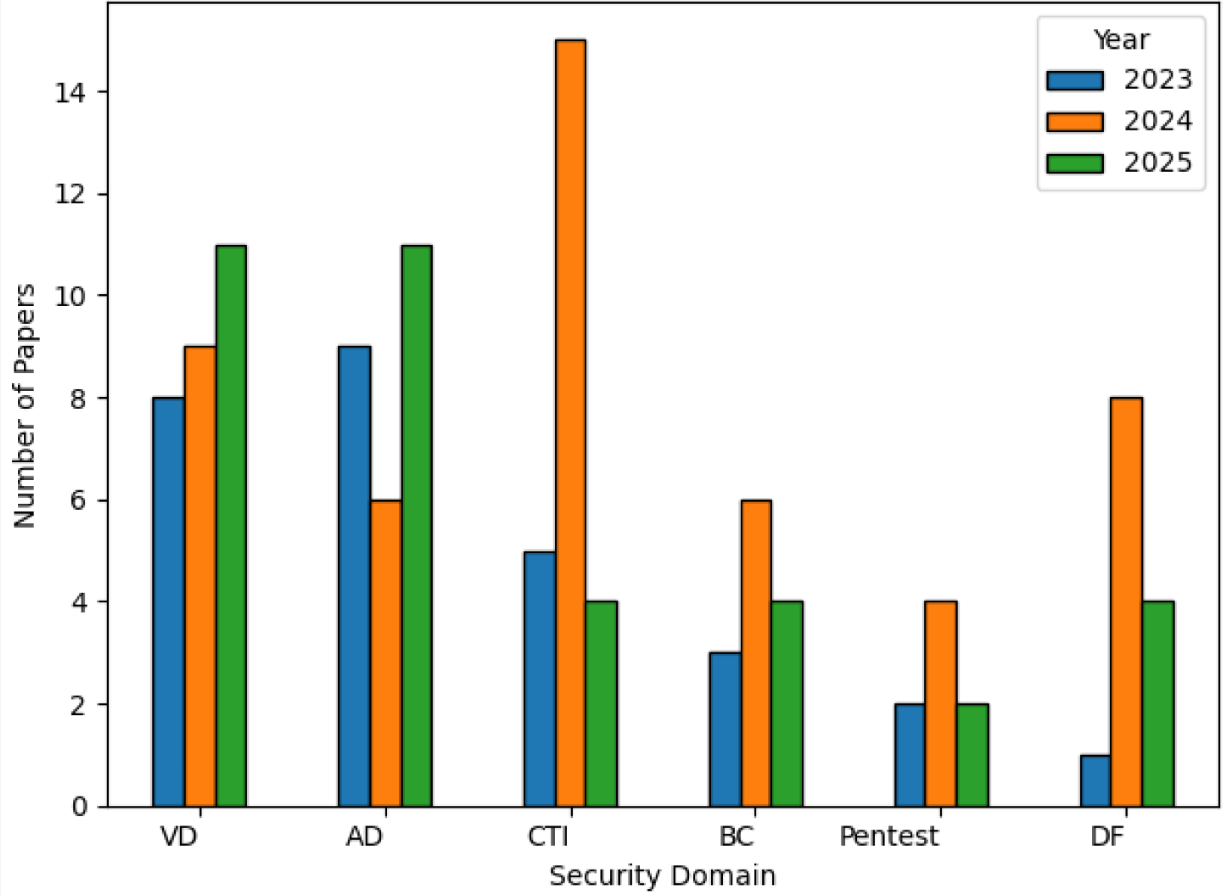
- 基于LLM的系统在6大领域每年在网络安全领域发表的的论文(2023-2025 年)
漏洞检测(vulnerability detection/VD)
- LLMs 在漏洞检测中的应用已迅速发展成为 LLM 驱动型网络安全研究中最活跃和最具影响力的领域之一。
- 近年有关基于LLM的系统在漏洞检测方面的贡献和局限。
| 作者 | 年份 | 贡献总结 | 局限性 |
|---|---|---|---|
| Tufekci et al. | 2023 | 设计了用于行级漏洞定位的LLM,并为检测到的问题提供了解释支持。 | 在代码混淆或多漏洞情况下准确性下降。 |
| Purba et al. | 2023 | 引入因果感知漏洞分析,利用LLM实现对代码缺陷根源的更深入推理。 | 计算密集且难以扩展到大代码库。 |
| Noever | 2023 | 将GPT-4与传统分析工具对比,识别出更多有可行修复方案的漏洞。 | 存在过度预测的风险,需要专家验证。 |
| Li et al. | 2023 | 在标记的漏洞数据集上微调LLM,以提高检测准确性。 | 需要标注良好、平衡的数据集以避免偏差。 |
| Wang et al. | 2023 | 结合代码嵌入与LLM,提升跨代码库的泛化能力。 | 需要大量计算资源和精细调整。 |
| Bakhshandeh et al. [59] | 2023 | 利用LLM检测Docker和Kubernetes环境中的配置相关漏洞。 | 对自定义或 evolving 的基础设施设置支持有限。 |
| Lin et al. | 2023 | 展示了LLM通过检索和解释CVE及CWE来辅助漏洞分析的能力。 | 在嘈杂环境中可能检索过时或不相关的漏洞。 |
| Kaheh et al. | 2023 | 提出交互式LLM,超越问答功能,可执行配置防御等操作。 | 未经验证的自动化可能危及生产系统。 |
| Zhou et al. | 2024 | 提出基于LLM的模型,用于检测源文件中的不安全代码模式。 | 跨代码库泛化能力有限。 |
| Mahyari | 2024 | 微调LLM分类代码库中的各种漏洞类型,强调跨语言泛化。 | 罕见或未见过的漏洞类型性能下降。 |
| Khare et al. | 2024 | 开发IDE集成的LLM工具,向开发者提供实时漏洞反馈。 | 需要大量工作确保IDE兼容性和用户信任。 |
| Jensen et al. | 2024 | 提出开发环境中的实时LLM顾问。 | 易受幻觉或不完整建议的影响。 |
| Shestov et al. | 2024 | 引入结合开发者上下文与LLM生成漏洞的报告机制,增强报告清晰度。 | 当开发者上下文嘈杂或不可用时性能下降。 |
| Mathews et al. | 2024 | 提出针对特定云环境的LLM模型,评估云配置中的错误配置风险。 | 可能无法在不同云平台间很好地泛化。 |
| Berabi et al. | 2024 | 提出DeepCode AI Fix,聚焦于相关代码片段以提升修复效率。 | 仅适用于函数或方法结构清晰的代码库。 |
| Dozono et al. | 2024 | 开发CODEGUARDIAN,提升多语言漏洞检测效率。 | 性能因编程语言和工具链集成而异。 |
| Kouliaridis et al. | 2025 | 通过将LLM输出与CVE分类法对齐,改进漏洞分类和筛选。 | 多类别或模糊案例中可能出现映射错误。 |
| Sheng et al. | 2025 | 提出LProtector,利用GPT-4o和RAG在C/C++代码库中进行有效漏洞检测。 | 高计算成本,需大上下文窗口以达到最佳效果。 |
| Tamberg & Bahsi | 2025 | 使用Transformer模型检测语义级漏洞。 | 高度依赖提示质量和预训练数据。 |
| Mao et al. | 2025 | 研究 C/C++ 代码的GPT-based漏洞扫描器,用少量监督数据提高分类精度。 | 难以处理复杂或深度嵌套的代码结构。 |
| Ghosh et al. | 2025 | 提出CVE-LLM,利用本体论和LLM自动化漏洞评估。 | 依赖于结构化本体论,对新CVE处理困难。 |
| Sheng et al. | 2025 | 回顾基于LLM的漏洞检测研究,梳理技术映射和未来趋势。 | 缺乏实证验证。 |
| Sovrano et al. | 2025 | 提出“丢失在末端”效应:LLM在大文件末尾遗漏漏洞。 | 模型存在位置偏差。 |
| Torkamani et al. | 2025 | 提出CASEY,一种用于漏洞分类中CWE和严重性分类的LLM系统。 | 组合分类具有挑战性。 |
| Lin & Mohaisen | 2025 | 评估Java漏洞检测中的LLM,强调令牌长度敏感性。 | 性能波动大,受输入截断影响。 |
| Dolcetti et al. | 2025 | 结合LLM与测试、静态分析,自动修正有缺陷的代码生成。 | 无监督场景下鲁棒性不足。 |
| Feng et al. | 2025 | 提出CGP-Tuning,将代码图结构整合到LLM提示调整中。 | 无法泛化到所有编程语言。 |
异常检测(anomaly detection/AD)
- 异常检测在网络安全中发挥着关键作用,近期研究越来越多地利用 LLMs 来增强这一能力,涵盖从系统日志到电子邮件过滤和流量检查等不同场景。
- 近年有关基于LLM的系统在异常检测方面的贡献和局限。
| 作者 | 年份 | 贡献总结 | 局限性 |
|---|---|---|---|
| Liu et al. | 2023 | 提出 ScaleAD,结合 Trie 基础检测与 LLM 验证,用于云日志异常检测。 | LLM 查询延迟可能限制实时响应。 |
| Qi et al. | 2023 | 提出 LogGPT,一个模块化的 LLM 基础日志异常检测框架。 | 依赖提示设计和解析准确性。 |
| Han et al. | 2023 | 采用 Top-K 奖励策略增强 GPT-2,专注于日志异常检测。 | 需要对每种日志类型进行任务特定的微调。 |
| Jamal & Wimmer | 2023 | 构建 IPSDM,一个基于 RoBERTa 和 DistilBERT 微调的钓鱼/垃圾邮件检测器。 | 在新型电子邮件攻击格式上的表现不佳。 |
| Heiding et al. | 2023 | 评估 GPT-4 生成和检测钓鱼邮件的能力,优于传统方法。 | 双重用途风险和钓鱼生成可能被滥用。 |
| Vörös et al. | 2023 | 使用知识蒸馏检测恶意 URL,采用轻量级学生模型。 | 性能取决于教师模型的质量。 |
| Gu et al. | 2023 | 提出 AnomalyGPT,利用 LVLMs 进行工业异常检测。 | 需要合成数据生成和微调。 |
| Elhafsi et al. | 2023 | 提出 LLM 基础的机器人语义异常监控方法。 | 仅关注特定机器人应用。 |
| Ali & Kostakos | 2023 | 提出 HuntGPT,整合 LLMs 与 XAI 和 ML,增强异常可解释性。 | 依赖于模型可解释性工具。 |
| Liu et al. | 2024 | 提出 LogPrompt,一种使用 LLMs 结合 CoT 推理和上下文学习的日志分析方法。 | 需要高质量训练数据,且在嘈杂日志中表现不佳。 |
| Nahmias et al. | 2024 | 开发了一种鱼叉式网络钓鱼检测器,使用 LLM 生成的上下文向量。 | 需要 LLM 访问进行推断和向量解释。 |
| Guastalla et al. | 2024 | 应用 LLMs 到云和物联网数据集上进行 DDoS 检测,采用少样本学习。 | 大规模流量下的可扩展性问题。 |
| Alnegheimish et al. | 2024 | 引入 sigllm,使用 LLMs 进行零样本时间序列异常检测。 | 性能落后于专用深度学习模型。 |
| Li et al. | 2024 | 展示了使用 LLMs 在表格数据进行零样本异常检测。 | 有效性与数据表示质量有关。 |
| Su et al. | 2024 | 全面回顾了 LLMs 在预测和异常检测中的应用。 | 缺乏关于数据和计算成本的实证结果。 |
| Gandhi et al. | 2025 | 开发了混合 APT 检测方法,结合图、统计模型和 LLMs 解释 kill chain 上下文中的警报。 | 需要仔细的图调整和高质量日志以确保语义一致性。 |
| Zhang et al. | 2025 | 提出 LEMUR,通过语义分析增强日志聚类和模板合并。 | 熵采样的计算成本很高。 |
| Si et al. | 2025 | 评估 ChatGPT 在垃圾邮件检测中的表现,显示其在低资源环境下的优势。 | 在复杂和大规模数据集上性能下降。 |
| Guan et al. | 2025 | 提出 LogLLM,使用 LLMs 检测系统日志中的异常。 | 需要适应不同的日志格式。 |
| Liu et al. | 2025 | 开发了一个 LLM 驱动的助手,用于异常解释和缓解支持,使用 CTI 增强的对话和提示。 | 需要大量的微调和上下文建模。 |
| Wang & Yang | 2025 | 提出了一个联邦 LLM 框架,用于分布式系统的隐私保护、多模态异常检测。 | 联邦设置可能增加系统复杂性和延迟。 |
| Qian et al. | 2025 | 设计了一个多层 LLM 基础 Android 恶意软件检测框架,结合静态切片、CFG 和幻觉过滤器。 | 仅限于 Android 应用,且受混淆技术影响。 |
| Benabderahmane et al. | 2025 | 提出 APT-LLM,使用 provenance traces 的 LLM 基础嵌入与自编码器结合,在多个操作系统上检测 APT。 | 高计算成本和实际使用的泛化挑战。 |
| Meguro & Chong | 2025 | 开发了一个实时的钓鱼检测工具,使用 LLMs 和向量数据库支持。 | 基于 email 格式,需要大型历史数据集。 |
| Akhtar et al. | 2025 | 回顾了 LLMs 在日志分析中的应用,包括异常检测、根因分析和威胁追踪。 | 缺乏实证结果。 |
| Walton et al. | 2025 | 引入了基于 GPT-4o-mini 的 LLM 基础语义处理器,用于 Android 恶意软件分类。 | 依赖于提示质量和混淆技术。 |
网络威胁情报(cyber threat intelligence/CTI)
- 将 LLMs 集成到 CTI 已成为一个重要的研究领域,研究人员正在评估这些模型如何协助威胁检测、分析和决策。CTI 领域的最新进展利用 LLMs 将非结构化和分布式威胁数据转化为可操作的洞察。
- 近年有关基于LLM的系统在网络威胁情报方面的贡献和局限。
| 作者 | 年份 | 贡献总结 | 局限性 |
|---|---|---|---|
| Hu et al. | 2022 | 从威胁数据构建知识图谱,并使用 LLM 自动填充高质量关系。 | LLM 未经过验证即推断出不准确的关系。 |
| Perrina et al. | 2023 | 开发基于 LLM 的系统,从非结构化来源提取威胁数据并自动化生成 CTI 报告。 | 生成报告中存在幻觉和未经验证输出的风险。 |
| Fayyazi & Yang | 2023 | 使用 MITRE ATT&CK 和 CAPEC 微调 LLM,提升威胁技术描述的质量。 | 训练数据外泛化能力有限。 |
| Siracusano et al. | 2023 | 提出 aCTIon,结合 LLM 与结构化解析,将 CTI 导出为 STIX 格式以集成到 CTI 平台。 | 若解析失败或上下文误解,STIX 导出过程中会传播错误。 |
| Park & You | 2023 | 提出 CTI-BERT,一种基于 BERT 的模型,在网络安全数据上训练,提升 CTI 提取准确性。 | 受限于其微调数据所代表的领域。 |
| Singla et al. | 2023 | 展示 LLM 可分析供应链漏洞并识别威胁传播路径。 | 因聚焦特定软件,缺乏泛化能力。 |
| Jin et al. | 2024 | 提出 Crimson,通过 RAT 将 LLM 输出与 MITRE ATT&CK 对齐,减少幻觉。 | 需要结构良好的检索语料库才能有效运行。 |
| Shafee et al. | 2024 | 评估基于 LLM 的聊天机器人在 OSINT 数据中分类和提取实体方面的性能,提升威胁意识。 | 不同 LLM 的准确性差异大,且高度依赖提示设计。 |
| Schwartz et al. | 2024 | 提出 LMCloudHunter,从 OSINT 提取检测规则并将其转换为签名。 | 需要人工验证以确保签名的安全性。 |
| Clairoux-Trepanier et al. | 2024 | 评估 LLM 从 CTI 报告中提取 IOC 的能力,展示其在语义理解方面的优势。 | 在不一致或嘈杂的数据格式中有效性有限。 |
| Zhang et al. | 2024 | 提出一个四阶段管道,使用 LLM 重写、解析和总结威胁数据,形成结构化攻击知识图谱。 | 高复杂性,每个阶段都可能引入潜在故障点。 |
| Fieblinger et al. | 2024 | 利用 LLM 从 CTI 中提取实体 - 关系三元组,帮助自动化图结构和分析。 | 性能随实体一致性和文本清晰度变化。 |
| Gao et al. | 2024 | 提出 ThreatKG,一个自动化系统,从开源 CTI 报告构建和更新威胁知识图谱。 | 受不完整或不一致的实体链接影响。 |
| Wu et al. | 2024 | 提出基于 LLM 的验证方法,提升未经验证威胁情报的可信度。 | 需要稳健且更新的知识库进行验证。 |
| Fayyazi et al. | 2024 | 使用 RAG 增强 LLM 的 TTP 总结,提升事实准确性和深度。 | 依赖于检索源的质量和相关性。 |
| Zhang et al. | 2024 | 利用 LLM 的语义洞察改进 bug 报告去重,优于传统模型。 | 对措辞变化敏感。 |
| Tseng et al. | 2024 | 提出基于 LLM 的代理,自动化 SOC 任务,包括正则表达式生成和从威胁报告中提取 CTI。 | 易生成过于通用或不安全的正则表达式。 |
| Rajapaksha et al. | 2024 | 开发基于 RAG 的 LLM QA 系统,用于攻击搜索,为 SOC 分析师提供上下文感知帮助。 | 外部检索失败或缓慢时响应性有限。 |
| Shah & Parast | 2024 | 探索 GPT-4o 和一次性微调以自动化 CTI 流程,减少人工工作量。 | 生成输出缺乏透明度。 |
| Alevizos & Dekker | 2024 | 提出增强型 CTI 处理管道,强调 AI - 人类协作,以实现及时且高保真度的威胁情报。 | 管道复杂性可能在时效性场景中延缓采用。 |
| Daniel et al. | 2024 | 评估 LLM(ChatGPT、Claude、Gemini)使用 MITRE ATT&CK 技术标记 NIDS 规则的性能,突出其可扩展性和可解释性。 | 与传统 ML 模型相比,LLM 在准确性指标上表现不佳。 |
| Mitra et al. | 2025 | 提出 LocalIntel,结合全局和局部知识,使用 LLM 为定制化威胁情报。 | 依赖于本地威胁数据的可用性和质量。 |
| Sorokoletova et al. | 2025 | 提出 O-CTI,一个支持监督学习和零样本学习的框架,用于 CTI 信息提取,输出与 STIX 对齐。 | 零样本性能随模糊或歧义语言急剧下降。 |
| Liu et al. | 2025 | 提出 CYLENS,一个基于 LLM 的助手,通过整合广泛威胁报告知识,支持威胁管理的各个阶段。 | 难以处理来自不同来源的冲突或重叠情报。 |
| Paul et al. | 2025 | 结合 LLM 与 RAG 处理实时威胁情报流,实现动态且上下文感知的威胁检测。 | 依赖于流式威胁馈送的质量和新鲜度。 |
区块链安全(blockchain security/BC)
- 区块链安全领域的最新进展已将 LLMs 集成到智能合约审计和异常检测中。
- 近年有关基于LLM的系统在区块链安全方面的贡献和局限。
| 作者 | 年份 | 贡献总结 | 局限性 |
|---|---|---|---|
| David et al. | 2023 | 评估 GPT-4 和 Claude 用于智能合约审计,正确识别率达 40%。 | 高假阳性率需要人工审计。 |
| Gai et al. | 2023 | 提出 BLOCKGPT,使用预训练 LLM 实现实时区块链交易异常检测。 | 效果依赖于高质量、广泛的训练数据。 |
| Hu et al. | 2023 | 提出 GPTLENS,一种两阶段 LLM 框架,通过分离生成和判别环节提升智能合约漏洞检测能力。 | 实现复杂,且在检测与假阳性之间平衡存在挑战。 |
| Sun et al. | 2024 | 提出 GPTScan,结合 GPT 与静态分析检测智能合约漏洞。 | 效果依赖于静态分析的质量。 |
| Yu et al. | 2024 | 提出 Smart-LLaMA,使用领域特定训练检测和解释漏洞。 | 需要大量标注数据以实现最佳性能。 |
| Zaazaa and El Bakkali | 2024 | 提出 SmartLLMSentry,使用 ChatGPT 和上下文学习进行漏洞检测。 | GPT-4 在规则生成方面不如 GPT-3 有效。 |
| Wei et al. | 2024 | 提出 LLM-SmartAudit,一种多智能体系统以增强智能合约审计。 | 多个 AI 智能体增加了系统复杂性。 |
| Ma et al. | 2024 | 提出 iAudit,采用两阶段微调方法进行检测和解释。 | 高度依赖于微调数据的质量。 |
| Chen et al. | 2024 | 评估 ChatGPT 检测智能合约漏洞的能力,注意到高召回率但精度有限。 | 不同漏洞类型的性能差异较大。 |
| Hossain et al. | 2025 | 结合 LLM 与 ML 模型检测智能合约漏洞,达到高准确率。 | 新兴区块链平台的验证有限。 |
| He et al. | 2025 | 回顾区块链安全领域中 LLM 的应用,涵盖审计、异常检测和修复。 | 缺乏实证结果。 |
| Ding et al. | 2025 | 提出 SmartGuard,结合 CoT 提示与 LLM 以实现高召回率检测。 | 当代码中存在多种漏洞时效果较差。 |
| Bu et al. | 2025 | 通过在大型智能合约数据集上微调 LLM,增强 DApps 中的漏洞检测。 | 微调需要大量计算资源。 |
渗透测试(penetration testing/PT)
- 将 LLMs 整合到渗透测试中通过最近的研究取得了显著进展
- 近年有关基于LLM的系统在渗透测试方面的贡献和局限。
| 作者 | 年份 | 贡献总结 | 局限性 |
|---|---|---|---|
| Temara [130] | 2023 | 探索 ChatGPT 在渗透测试侦察阶段的实用性。 | 需进一步验证数据准确性和可靠性。 |
| Happe and Cito [132] | 2023 | 展示 LLM 作为渗透测试人员的 AI 陪练伙伴,分析机器状态并建议攻击向量。 | 部署前需进一步改进和考虑伦理因素。 |
| Deng et al. [128] | 2024 | 提出基于 LLM 的渗透测试任务自动化框架。 | 任务间维持上下文的挑战。 |
| Fang et al. [129] | 2024 | 展示 GPT-4 利用 CVE 描述利用零日漏洞的能力。 | 无漏洞描述时效果下降。 |
| Deng et al. [131] | 2024 | 评估 PentestGPT 的模块化设计和任务完成改进。 | 复杂场景和上下文保留存在困难。 |
| Bianou et al. [133] | 2024 | 提出 PENTEST-AI,一个集成 MITRE ATT&CK 的多智能体 LLM 框架。 | 依赖预定义模式限制了应对新威胁的适应性。 |
| Isozaki et al. [40] | 2025 | 提出自动化渗透测试中评估 LLM 的基准。 | LLM 在无人工协助的情况下难以完成端到端测试。 |
| Happe et al. [41] | 2025 | 开发自动化工具评估 LLM 在权限提升任务中的能力。 | 测试中难以维持专注和管理错误。 |
数字取证(digital forensics/DF)
- LLMs通过自动化证据搜索、异常检测和报告生成等复杂任务,在提高数字取证的效率和准确性方面表现出了巨大的潜力。
- 近年有关基于LLM的系统在数字取证方面的贡献和局限。
| 作者 | 年份 | 贡献总结 | 局限性 |
|---|---|---|---|
| Scanlon et al. [1] | 2023 | 评估 ChatGPT 对数字取证的影响,呈现其在各类取证任务中的优势和局限。 | 需专业知识且引发隐私担忧。 |
| Bin Oh et al. [136] | 2024 | 提出 volGPT,一种基于 LLM 的勒索软件内存取证分类方法。 | 效果仅局限于勒索软件检测。 |
| Voigt et al. [137] | 2024 | 提出 Re-imagen,一个使用 LLM 生成合成取证数据集真实背景活动的框架。 | 无法在合成数据集中生成真实的背景活动。 |
| Michelet and Breitnger [138] | 2024 | 研究本地 LLM 在辅助编写数字取证报告中的应用。 | 需大量人工校对和验证。 |
| Bhandarkar et al. [139] | 2024 | 评估 DFIR 管线应对 LLM 时代 NTGs 威胁的准备情况。 | DFIR 方法需要更先进的防御策略。 |
| Loumachi et al. [140] | 2024 | 提出 GenDFIR,一个利用 LLM 和 RAG 增强网络事件时间线分析的框架。 | 缺乏可扩展性和透明度分析。 |
| Zhou et al. [141] | 2024 | 提出基于 LLM 的方法从移动数据构建 FIG,在识别证据实体和关系方面覆盖度高。 | 需要在多样数据集上进一步验证。 |
| Xu et al. [144] | 2024 | 通过教程和案例研究探索 LLM 在自动化数字调查中的潜力。 | 在现实世界的动态调查中实施复杂。 |
| Cho et al. [145] | 2024 | 讨论了 LLM 在 DF 中的集成,强调透明度和标准化的重要性。 | 部署前需要解决偏差和可解释性问题。 |
| Yin et al. [134] | 2025 | 全面概述 LLM 在数字取证中的能力与局限。 | 需要专家理解 LLM 的优缺点。 |
| Wicramaskara et al. [135] | 2025 | 探讨如何将 LLM 集成到 DF 调查中以解决挑战并提高效率。 | 需要控制 LLM 在取证中的集成。 |
| Kim et al. [142] | 2025 | 评估 LLM 在分析移动消息通信中的应用,提升模糊语言的解释精度和召回率。 | 依赖于提示工程的质量和模型选择。 |
| Sharma et al. [143] | 2025 | 提出 ForensicLLM,一个本地微调模型,增强取证问答任务和来源准确性。 | 受限于训练数据和计算能力。 |
主流LLMs在6个网络安全领域的适用性总结
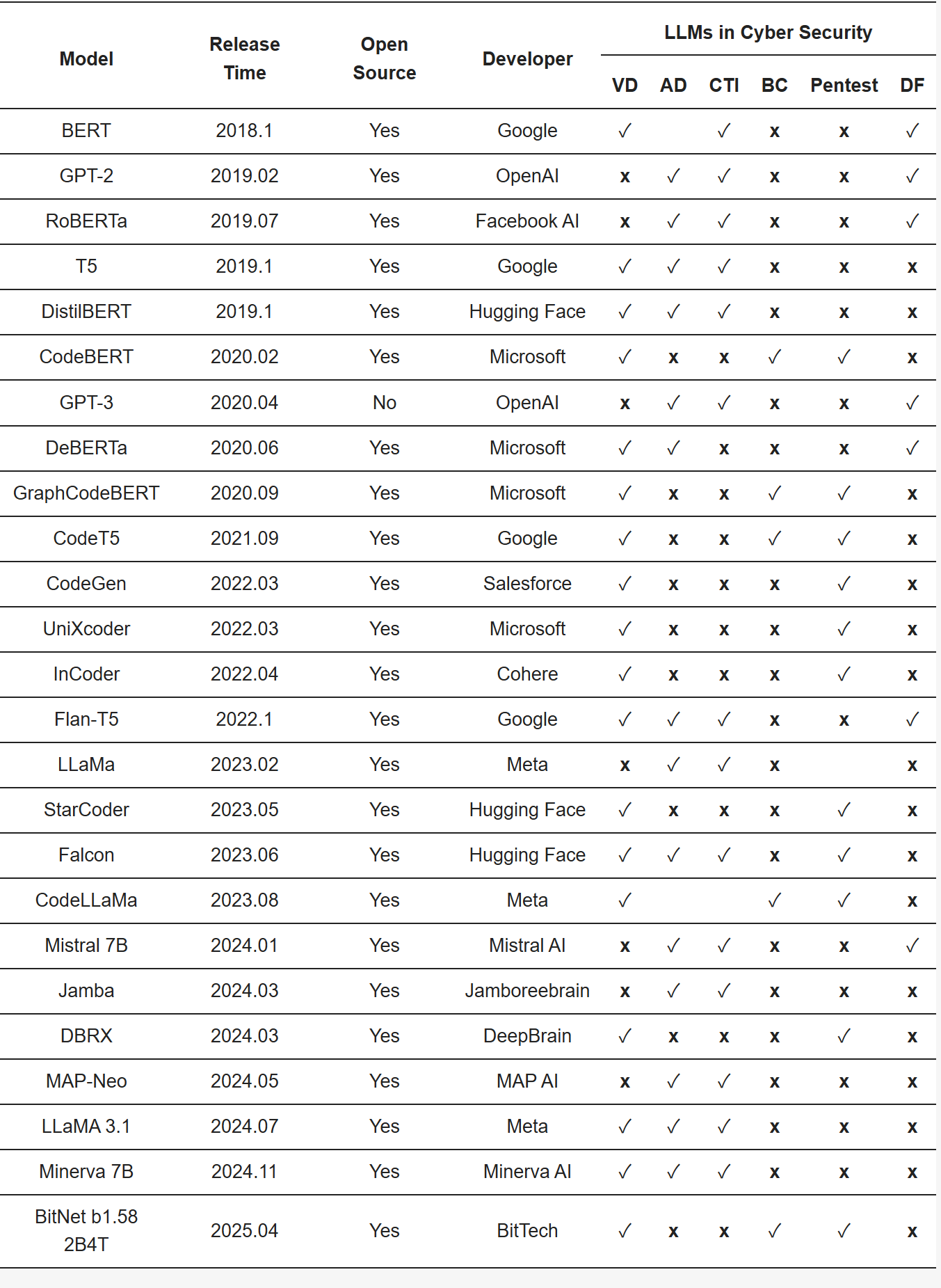
- 在先前提到的六个调查领域中,LLMs 引入了超越传统基于规则或统计方法范围的能力。大量实证研究表明,在关键性能指标上取得了可衡量的提升。当结合有针对性的领域知识时,LLMs 能够显著提高检测精度,减少误报,并提供更具上下文感知的安全洞察。存在的关键限制:跨领域的一个持续挑战是 LLMs 在对抗性、模糊性或高风险操作条件下的鲁棒性有限。
- 尽管大语言模型(LLMs)在技术创新方面展现出显著潜力,但其适用范围仍存在局限,尚无法作为独立系统实现完全可靠运行。诸如幻觉生成、部署成本高、响应延迟以及可解释性不足等关键风险,在各类应用场景中均持续存在。因此,尽管LLMs发展前景广阔,但在实际部署中应采用混合架构,即保留传统确定性安全措施,并支持人工监督回路,以确保系统的稳健性与可信度。
LLMs在网络安全中的机遇和挑战
LLMs在网络安全中的机遇
- 恶意软件分析与检测
LLMs 可通过分析代码、行为和网络流量识别未知恶意软件,比传统基于特征的方法更具适应性。例如,MalBERTv2 在语义特征分析中优于传统模型。LLMs 还支持动态分析,能识别不符合传统签名的可疑行为,并可用于生成恶意软件代码以辅助渗透测试。 - 实时钓鱼检测
LLMs 能分析邮件内容、识别误导性URL、附件和写作风格,有效检测复杂钓鱼策略。微调后的模型在识别零日钓鱼邮件方面表现突出,并可分析整个邮件线程以识别社会工程攻击。结合SIEM系统,LLMs 可实现实时威胁优先级排序。 - 自动化漏洞管理
LLMs 能预测代码缺陷(如SQL注入、XSS),辅助安全编码并自动修复漏洞。例如,Codex 能检测易受攻击的代码并建议安全替代方案。LLMs 还能生成安全代码片段,帮助开发者减少人为错误,提升软件安全性。 - 威胁情报自动化
LLMs 可从非结构化数据(如博客、暗网论坛)中提取威胁情报,识别新兴攻击趋势。它们能自动生成结构化报告,帮助分析师快速处理大量数据,并根据上下文对威胁进行分类和优先级排序。 - 社交媒体与暗网监控
LLMs 能监控社交媒体和暗网,识别非法活动(如漏洞利用套件交易)和攻击早期迹象。它们还可检测虚假信息运动和社会工程策略,通过语言分析追踪威胁行为者,揭露隐藏网络。 - 事件响应与剧本生成
LLMs 可根据攻击场景生成定制化响应剧本,减少人为错误。它们能与SOAR系统集成,自动化缓解措施(如隔离受感染系统),并将政策文档转换为可执行工作流,确保合规性。 - 高级渗透测试与红队演练
LLMs 能模拟复杂攻击(如APT),生成渗透测试脚本和攻击场景,辅助红队演练。它们还可构建定制载荷和混淆指令,提高测试真实性,并通过动态生成测试用例评估防御能力。
- LLMs 在网络安全中展现出多领域潜力,包括恶意软件分析、钓鱼检测、漏洞管理、威胁情报、暗网监控、事件响应和渗透测试。它们通过上下文理解和自动化能力,显著提升防御效率,但仍需结合传统安全措施和人工监督以确保可靠性。
LLMs 在网络安全中的挑战
- 模型可靠性与准确性
- 幻觉问题:LLMs 常生成看似合理但错误的信息,尤其在安全场景中,小误差可能导致严重后果(如误判威胁)。
- 知识滞后:多数 LLMs 缺乏对新兴威胁的实时认知,需结合检索系统或实时数据才能应对动态威胁。
- 解决方案:采用 RAG(检索增强生成)方法,通过外部知识库验证输出,但需持续更新知识库以匹配快速演变的威胁环境。
- 可解释性与透明度
- 黑箱特性:LLMs 决策过程不透明,难以验证输出合理性,影响安全决策的信任度(如入侵检测、事件响应)。
- 应用限制:虽可通过注意力热图或提示工程提升可解释性,但这些技术在复杂网络场景中效果有限,大规模集成仍存障碍。
- 影响:缺乏透明度限制了 LLM 生成的情报在取证或法律场景的使用价值。
- LLMs 的对抗性应用
- 恶意利用风险:
- 攻击者可通过提示工程生成混淆代码或钓鱼邮件,绕过基本安全防护。
- 低技能攻击者可借助 LLM 快速开发功能性恶意软件,增加防御难度。
- 社交工程威胁:LLMs 自然语言能力使其成为生成高仿真钓鱼内容的理想工具,大规模定制化诱饵易误导用户。
- 系统安全风险:提示注入攻击可破坏集成工作流,导致输出操纵或敏感数据泄露。
- 安全与隐私风险
- 数据泄露:LLMs 易发生提示泄露,敏感数据可能意外暴露于输出或日志中,违反隐私法规(如 GDPR)。
- 数据污染:攻击者可操纵训练数据植入后门或偏见,使模型忽略特定 IoCs 或错误分类恶意代码。
- 缓解措施:需采用差分隐私、数据审计和安全微调等技术,但实施成本高且需专业知识。
- 伦理与治理
- 军民两用性:LLMs 既可用于防御也可被威胁行为者利用,需严格管理模型发布和使用策略。
- 监管合规:需满足数据保护法规(如 GDPR),但 LLMs 的不可透明性增加了合规难度,尤其是自动化决策场景。
- 管理框架:需建立访问控制、使用策略和审计机制,防止滥用并确保负责任使用。
- 评估与基准测试
- 基准局限性:现有基准难以捕捉复杂威胁(如多态恶意软件、混淆代码),导致模型在特定领域表现不佳。
- 评估指标缺失:缺乏针对网络安全场景的标准化评估指标(如误报成本),跨子领域比较困难。
- 数据稀缺性:高质量、标注和最新的安全数据集稀缺,阻碍可重复性和性能评估。
- 资源与基础设施需求
- 计算密集:LLMs 训练和推理需大量硬件资源,实时处理场景中延迟可能影响操作效率。
- 部署门槛:低资源环境(如边缘设备)难以支撑 LLM 运行,限制了中小组织的采用。
- 运维负担:需定期更新模型、验证安全补丁并确保合规,增加运营复杂性。
- LLMs 在网络安全中的关键挑战的雷达图(0~10 表示严重程度↑)
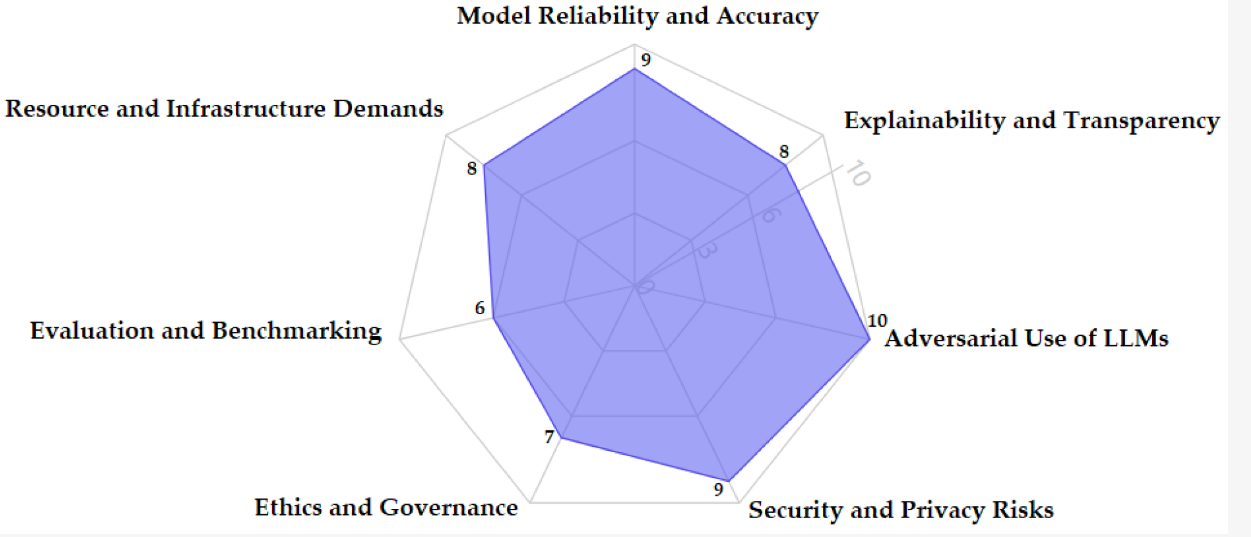
- LLMs 在网络安全中面临可靠性、透明度、对抗性利用、安全隐私、伦理治理、评估基准及资源需求等多重挑战。需通过技术手段(如 RAG、可解释性方法)、管理措施(如严格治理框架)和资源优化(如轻量化模型)逐步解决,以实现安全有效的部署。
更多推荐

 27
27 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)