
DeepSpeed - 超大LLM分布式训练框架 & ZeRO技术
技术,在多GPU 缓存模型参数、梯度和优化器状态的方式抽象为多个等级,以适应不同LLM的训练需求。DeepSpeed是微软开发的开源训练框架,在大规模集群训练千亿、万亿规模参数的大模型。2)支持训练、推理、压缩、科学赋能等领域,推动从训练到部署的全栈方案。3)适合拥有大规模GPU集群的机构。
DeepSpeed是微软开发的开源训练框架,在大规模集群训练千亿、万亿规模参数的大模型,如MT-530B、BLOOM等。
1)ZeRO技术,在多GPU 缓存训练参数的方式抽象为3个等级,以适应不同LLM并行训练需求。
2)支持训练、推理、压缩、科学赋能等领域,推动从训练到部署的全栈方案。
3)适合拥有大规模GPU集群的机构。

1 并行训练方式
当前分布式训练主要的三种并行模式:数据并行、模型并行和流水线并行。
数据并行,每个 GPU 复制一份模型参数,适合模型规模足够小能放到单个 GPU的LLM场景。
模型并行,模型比较大,单个 GPU装不下整个模型。将模型每层分成若干份,每份分配一个 GPU。训练过程中正向和反向传播的数据使用All gather/All reduce进行数据交换,通信成本和群组中的计算节点 (GPU) 数量正相关。
流水线并行,将不同的 layer 分配给指定 GPU 进行计算,层与层之间的计算以流水线的方式进行重叠。流水线并行只需相互依赖的GPU进行点对点通讯传递activations,对通讯带宽的需求降到更低。流水并行需要相对稳定的通讯频率来确保效率,并行效率依赖各卡负载的手动调优。
2 ZeRO并行
ZeRO 的本质,是在数据并行的基础上,对冗余空间占用进行深度优化。ZeRO 有三个不同级别,分别对应对模型参数,梯度和优化器状态不同程度的分片。
ZeRO-1,仅分片优化器状态
ZeRO-2,分片优化器状态和梯度
ZeRO-3,分片模型参数、优化器状态和梯度。
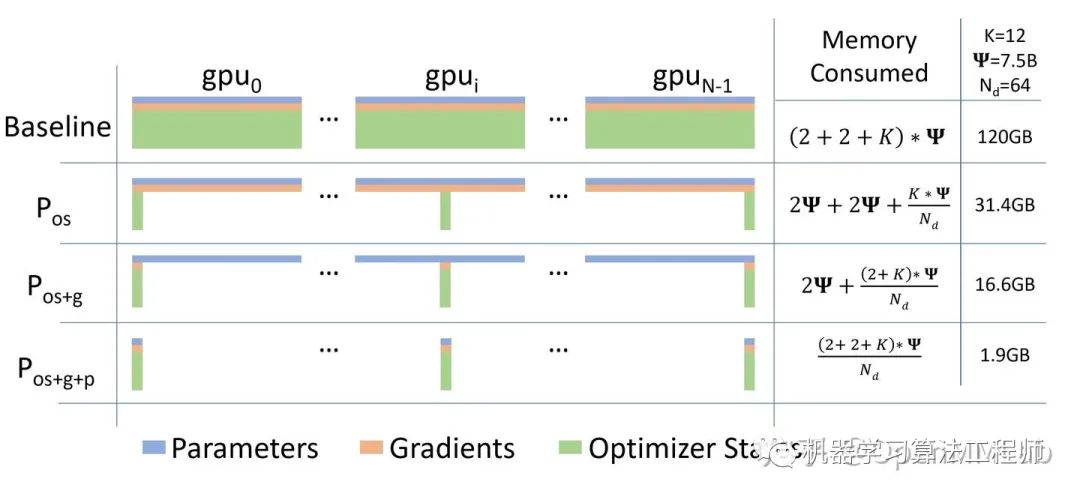
对于Adam类优化器,参数取值分别为Ψ = 7.5B and DP of Nd = 64 with K = 12:
其中K表示,如果原始参数量1,则优化器状态所占空间大小为12,分析如下。
1)fp32动量momentum,占用4份,4 = sizeof(float)。
2)fp32二阶动量variance,占用4份,4 = sizeof(float)。
3)优化器保持fp32参数一份,站4份,4 = sizeof(float)。
本来还应该以f32保存梯度一份,在实现中只需要保存部分梯度,相比其他开销可忽略。
随着划分等级的提升,GPU显存有限情况下可以容纳更大模型,但训练中GPU之间交换数据量也在增加。ZeRO-1仅交换优化器状态、ZeRO-2交换优化器状态和梯度,ZeRO-3则需要交换优化器状态、梯度和、激活状态Activation(与模型参数量有关)。
reference
---
optimizer state 都有些啥?
https://zhuanlan.zhihu.com/p/519264636
DeepSeepd
https://github.com/deepspeedai/DeepSpeed
GitHub上4大开源LLM微调框架对比,零基础小白收藏这一篇就可以了!!
更多推荐

 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)