
Java集成大模型:LangChain4j实战指南
本文介绍了如何利用LangChain4j框架将大语言模型(LLM)集成到Java应用中。主要内容包括: LangChain4j简介 简化Java应用与LLM的集成 支持主流商业和开源LLM 提供智能代理、RAG等高级功能 项目搭建 创建Spring Boot项目并配置依赖 接入多种大模型(OpenAI、Deepseek、Ollama等) 实现聊天记忆功能 高级功能实现 检索增强生成(RAG)技术
一、LangChain4j简介和使用
LangChain4j 的目标是简化将大语言模型(LLM - Large Language Model)集成到 Java 应用程序中的过程。
1.1、官网:https://docs.langchain4j.dev
1.2、主要功能
与大型语言模型和向量数据库的便捷交互
通过统一的应用程序编程接口(API),可以轻松访问所有主要的商业和开源大型语言模型以及向量数据库,使你能够构建聊天机器人、智能助手等应用。
专为 Java 打造
借助Spring Boot 集成,能够将大模型集成到ava 应用程序中。大型语言模型与 Java 之间实现了双向集成:你可以从 Java 中调用大型语言模型,同时也允许大型语言模型反过来调用你的 Java 代码
智能代理、工具、检索增强生成(RAG)
为常见的大语言模型操作提供了广泛的工具,涵盖从底层的提示词模板创建、聊天记忆管理和输出解析,到智能代理和检索增强生成等高级模式。
二、创建一个springboot项目
2.1、创建Maven项目
(在完成SpringBoot项目的测试和调试后,我最终将其集成到了若依框架中)
2.2、添加相对应的依赖,示例如下:
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spring-boot.version>3.2.6</spring-boot.version>
<knife4j.version>4.3.0</knife4j.version>
<langchain4j.version>1.0.0-beta3</langchain4j.version>
<mybatis-plus.version>3.5.11</mybatis-plus.version>
<!-- 添加 Logback 版本属性,使用兼容 SLF4J 2.x 的版本 -->
<logback.version>1.4.12</logback.version>
<!-- 添加兼容 Spring Boot 3.2.6 的 Tomcat 版本 -->
<tomcat.version>10.1.24</tomcat.version>
</properties>
<dependencies>
<!-- Pinecone Java 客户端 -->
<dependency>
<groupId>io.pinecone</groupId>
<artifactId>pinecone-client</artifactId>
<version>5.0.0</version>
</dependency>
<!-- JSON 处理 -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.15.2</version>
</dependency>
<!-- web应用程序核心依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<!-- 排除 javax.servlet 依赖,避免与 jakarta.servlet 冲突 -->
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- 添加 jakarta.servlet-api 依赖 -->
<dependency>
<groupId>jakarta.servlet</groupId>
<artifactId>jakarta.servlet-api</artifactId>
<scope>provided</scope>
</dependency>
<!-- 编写和运行测试用例 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- 基于open-ai的langchain4j接口:ChatGPT、deepseek都是open-ai标准下的大模型 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai-spring-boot-starter</artifactId>
</dependency>
<!-- 接入ollama -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-ollama-spring-boot-starter</artifactId>
</dependency>
<!-- 前后端分离中的后端接口测试工具 -->
<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>knife4j-openapi3-jakarta-spring-boot-starter</artifactId>
<version>${knife4j.version}</version>
</dependency>
<!-- 接入阿里云百炼平台 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-dashscope-spring-boot-starter</artifactId>
</dependency>
<!-- langchain4j高级功能 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-spring-boot-starter</artifactId>
</dependency>
<!-- Spring Boot Starter Data MongoDB -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>
<!-- Mysql Connector -->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<version>8.3.0</version>
</dependency>
<!-- mybatis-plus 持久层 -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-spring-boot3-starter</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
<!-- 解析pdf文档 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-document-parser-apache-pdfbox</artifactId>
<version>1.0.0-beta3</version>
</dependency>
<!-- 简单的rag实现 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
</dependency>
<!-- 集成pine -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-pinecone</artifactId>
</dependency>
<!-- 流式输出 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-reactor</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<!--引入SpringBoot依赖管理清单-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--引入langchain4j依赖管理清单-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-bom</artifactId>
<version>${langchain4j.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--引入百炼依赖管理清单-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-bom</artifactId>
<version>${langchain4j.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!-- 覆盖logback的依赖配置,使用兼容 SLF4J 2.x 的版本 -->
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-core</artifactId>
<version>${logback.version}</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>${logback.version}</version>
</dependency>
<!-- 覆盖tomcat的依赖配置,使用兼容 Spring Boot 3.2.6 的版本 -->
<dependency>
<groupId>org.apache.tomcat.embed</groupId>
<artifactId>tomcat-embed-core</artifactId>
<version>${tomcat.version}</version>
</dependency>
<dependency>
<groupId>org.apache.tomcat.embed</groupId>
<artifactId>tomcat-embed-el</artifactId>
<version>${tomcat.version}</version>
</dependency>
<dependency>
<groupId>org.apache.tomcat.embed</groupId>
<artifactId>tomcat-embed-websocket</artifactId>
<version>${tomcat.version}</version>
</dependency>
</dependencies>
</dependencyManagement>2.3、创建配置文件,示例如下:
# web服务访问端口
server.port=8087
#langchain4j测试模型
#langchain4j.open-ai.chat-model.base-url=http://langchain4j.dev/demo/openai/v1
#langchain4j.open-ai.chat-model.api-key=demo
#langchain4j.open-ai.chat-model.model-name=gpt-4o-mini
##DEEP_SEEK_API_KEY=这个是deepseek的apikey
##DeepSeek
#langchain4j.open-ai.chat-model.base-url=https://api.deepseek.com
#langchain4j.open-ai.chat-model.api-key=${DEEP_SEEK_API_KEY}
##DeepSeek-V3
#langchain4j.open-ai.chat-model.model-name=deepseek-chat
DASH_SCOPE_API_KEY=阿里云百炼大模型的apikey
#阿里百炼平台
langchain4j.community.dashscope.chat-model.api-key=${DASH_SCOPE_API_KEY}
langchain4j.community.dashscope.chat-model.model-name=qwen-max
#集成百炼-deepseek
langchain4j.open-ai.chat-model.base-url=https://dashscope.aliyuncs.com/compatible-mode/v1
langchain4j.open-ai.chat-model.api-key=${DASH_SCOPE_API_KEY}
langchain4j.open-ai.chat-model.model-name=deepseek-v3
#温度系数:取值范围通常在 0 到 1 之间。值越高,模型的输出越随机、富有创造性;
# 值越低,输出越确定、保守。这里设置为 0.9,意味着模型会有一定的随机性,生成的回复可能会比较多样化。
langchain4j.open-ai.chat-model.temperature=0.9
#ollama
langchain4j.ollama.chat-model.base-url=http://localhost:11434
langchain4j.ollama.chat-model.model-name=deepseek-r1:1.5b
# 创造性控制
# 0.7到1.2:适用于需要较高创造性的场景,如诗歌生成或头脑风暴
# 0.3到1.0:适用于需要较高稳定性和多样性的场景,如技术文档或法律文书的生成
langchain4j.ollama.chat-model.temperature=0.8
# 模型进行通信的超时时间为60秒。
langchain4j.ollama.chat-model.timeout=PT60S
langchain4j.ollama.chat-model.log-requests=true
langchain4j.ollama.chat-model.log-responses=true
#MongoDB连接配置
spring.data.mongodb.uri=mongodb://localhost:27017/chat_memory_db
# 基本数据源配置
spring.datasource.url=jdbc:mysql://localhost:3306/guiguxiaozhi?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&useSSL=false
spring.datasource.username=root
spring.datasource.password=root
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
# 开启 SQL 日志打印
mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
#集成阿里通义千问-通用文本向量-v3
langchain4j.community.dashscope.embedding-model.api-key=${DASH_SCOPE_API_KEY}
langchain4j.community.dashscope.embedding-model.model-name=text-embedding-v3
#集成阿里通义千问-流式输出
langchain4j.community.dashscope.streaming-chat-model.api-key=${DASH_SCOPE_API_KEY}
langchain4j.community.dashscope.streaming-chat-model.model-name=qwen-plus2.4、创建启动类,如下所示:
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class RuoyiLangChain4jApplication {
public static void main(String[] args) {
SpringApplication.run(RuoyiLangChain4jApplication.class, args);
}
}2.5、进行相对应的测试,如下示例(放在test下面进行测试):
我在编写AI程序时,总会进行一些测试环节。
接入任何一个大模型都需要先去申请apiKey。
如果你暂时没有密钥,也可以使用LangChain4j 提供的演示密钥,这个密钥是免费的,有使用配额限制,且仅限于 gpt-4o-mini 模型
import dev.langchain4j.model.openai.OpenAiChatModel;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
@SpringBootTest
public class LLMTest {
/**
* gpt-4o-mini语言模型接入测试
*/
@Test
public void testGPTDemo() {
//初始化模型
OpenAiChatModel model = OpenAiChatModel.builder()
//LangChain4j提供的代理服务器,该代理服务器会将演示密钥替换成真实密钥, 再将请求转发给OpenAI API
//.baseUrl("http://langchain4j.dev/demo/openai/v1") //设置模型api地址(如果apiKey="demo",则可省略baseUrl的配置)
.apiKey("demo") //设置模型apiKey
.modelName("gpt-4o-mini") //设置模型名称
.build();
//向模型提问
String answer = model.chat("你好");
//输出结果
System.out.println(answer);
}
}2.6、由于之前已经提供了完整的依赖配置,现在可以直接进行后续测试:
测试均在LLMTest测试类中完成
/**
* 整合SpringBoot
*/
@Autowired
private OpenAiChatModel openAiChatModel;
@Test
public void testSpringBoot() {
//向模型提问
String answer = openAiChatModel.chat("你好");
//输出结果
System.out.println(answer);
}三、接入其他的大模型
3.1、大语言模型排行榜:https://superclueai.com/
LangChain4j支持接入的大模型:https://docs.langchain4j.dev/integrations/language-models/
3.2、接入deepseek模型(步骤如下):
3.2.1、获取开发参数
访问官网:https://www.deepseek.com/ 注册账号,获取base_url和api_key,充值1元即可
(注意:几乎不会使用开放平台的模型,因为在阿里云的百炼大模型中已经都给予包含)
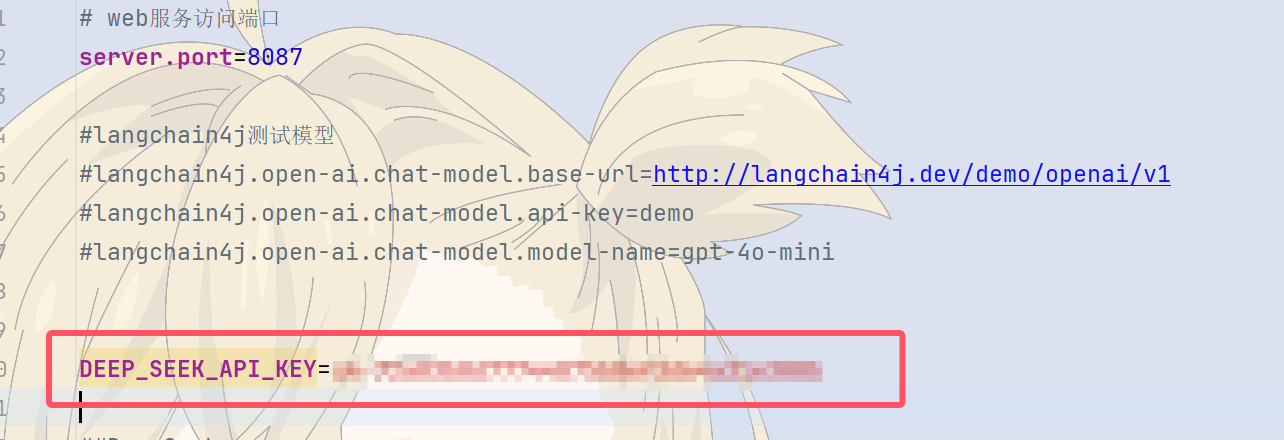
3.2.2、为了apikay的安全,建议将其配置在服务器的环境变量中。变量名自定义即可,例如 DEEP_SEEK_API_KEY ,如图所示:
3.2.3、需要配置模型的参数,之前提供了完整的配置,只需要改apikey即可
3.2.4、进行测试,直接在之前用例测试即可
四、ollama本地部署
4.1、Ollama 是一个本地部署大模型的工具。使用 Ollama 进行本地部署有以下多方面的原因:
-
数据隐私与安全:对于金融、医疗、法律等涉及大量敏感数据的行业,数据安全至关重要。
-
离线可用性:在网络不稳定或无法联网的环境中,本地部署的 Ollama 模型仍可正常运行。
-
降低成本:云服务通常按使用量收费,长期使用下来费用较高。而 Ollama 本地部署,只需一次性投入硬件成本,对于需要频繁使用大语言模型且对成本敏感的用户或企业来说,能有效节约成本。
-
部署流程简单:只需通过简单的命令 “ollama run < 模型名>”,就可以自动下载并运行所需的模型。
-
灵活扩展与定制:可对模型微调,以适配垂直领域需求。
4.2、在Ollama部署Deepseek,示例如下:
4.2.1、(1)下载并安装ollama:OllamaSetup.exe
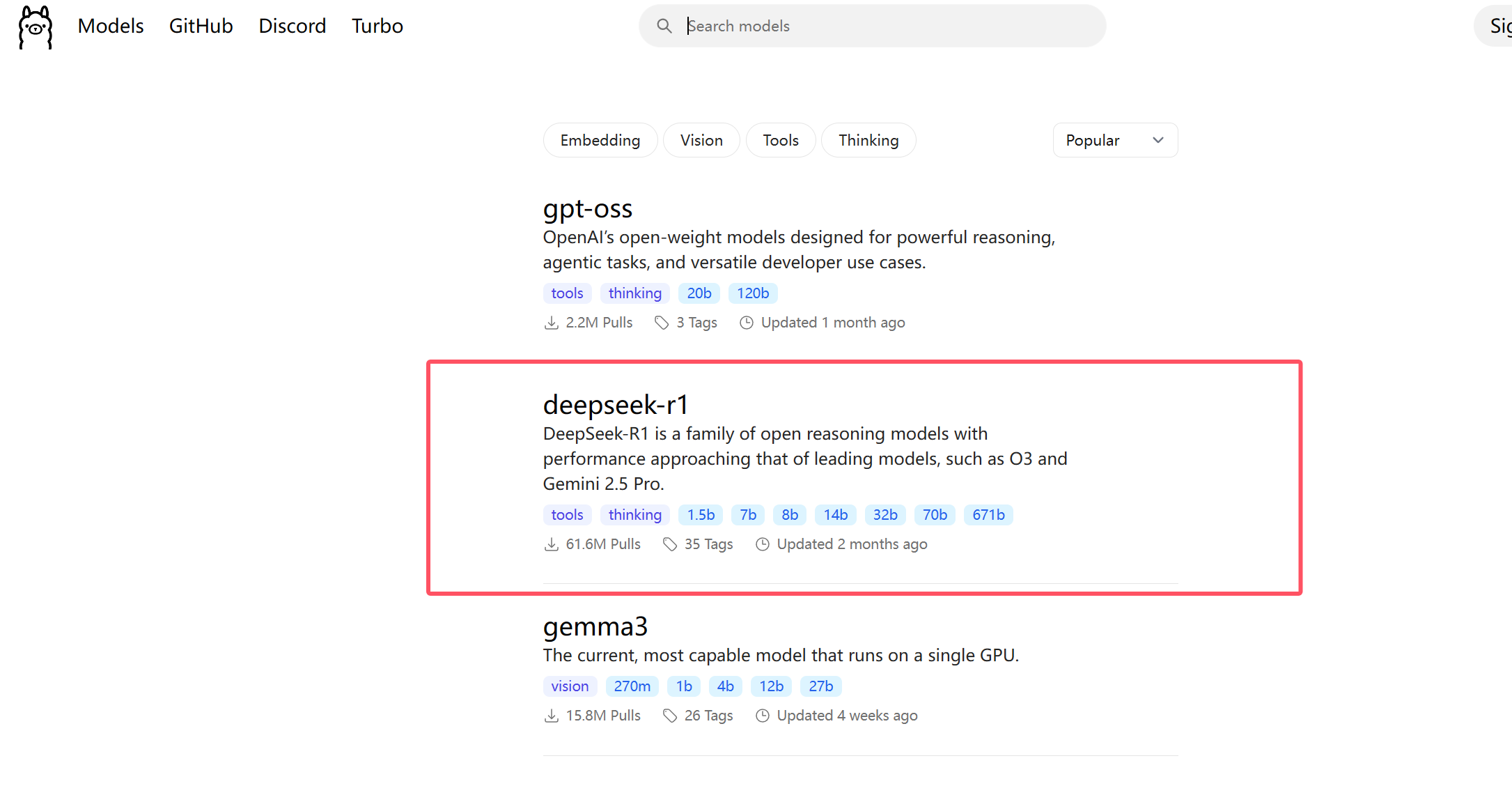
(2)查看模型列表,选择要部署的模型,模型列表: https://ollama.com/search
4.2.2、下载deepseek模型,如下所示:

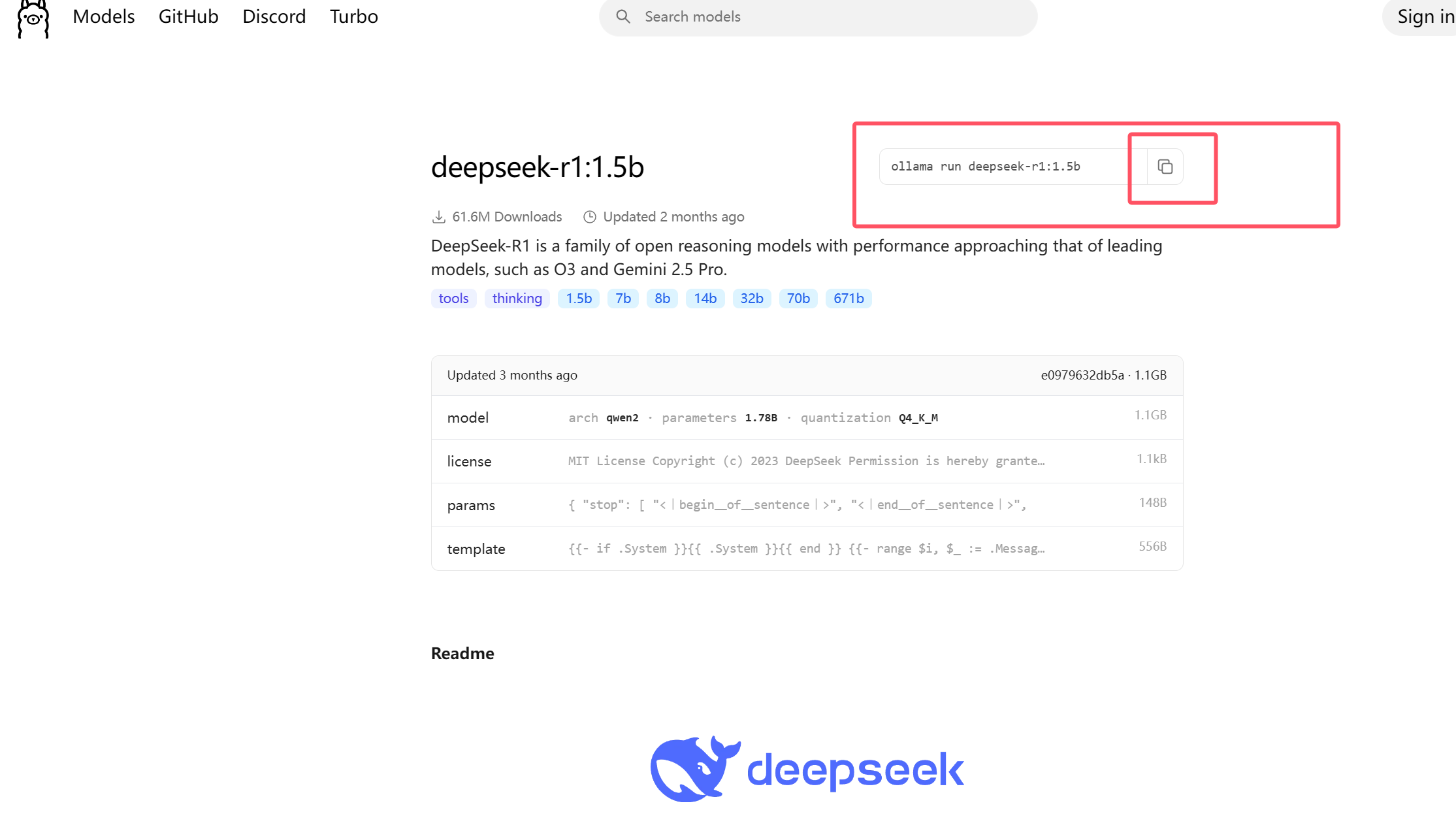
复制执行命令:ollama run deepseek-r1:1.5运行大模型。如果是第一次运行则会先下载大模型
4.2.3、进行测试:
/**
* ollama接入
*/
@Autowired
private OllamaChatModel ollamaChatModel;
@Test
public void testOllama() {
//向模型提问
String answer = ollamaChatModel.chat("你好");
//输出结果
System.out.println(answer);
}五、接入阿里百炼平台
5.1、什么是阿里百炼
-
阿里云百炼是 2023 年 10 月推出的。它集成了阿里的通义系列大模型和第三方大模型,涵盖文本、图像、音视频等不同模态。
-
功能优势:集成超百款大模型 API,模型选择丰富;5-10 分钟就能低代码快速构建智能体,应用构建高效;提供全链路模型训练、评估工具及全套应用开发工具,模型服务多元;在线部署可按需扩缩容,新用户有千万 token 免费送,业务落地成本低。
-
模型广场:https://bailian.console.aliyun.com/?productCode=p_efm#/model-market
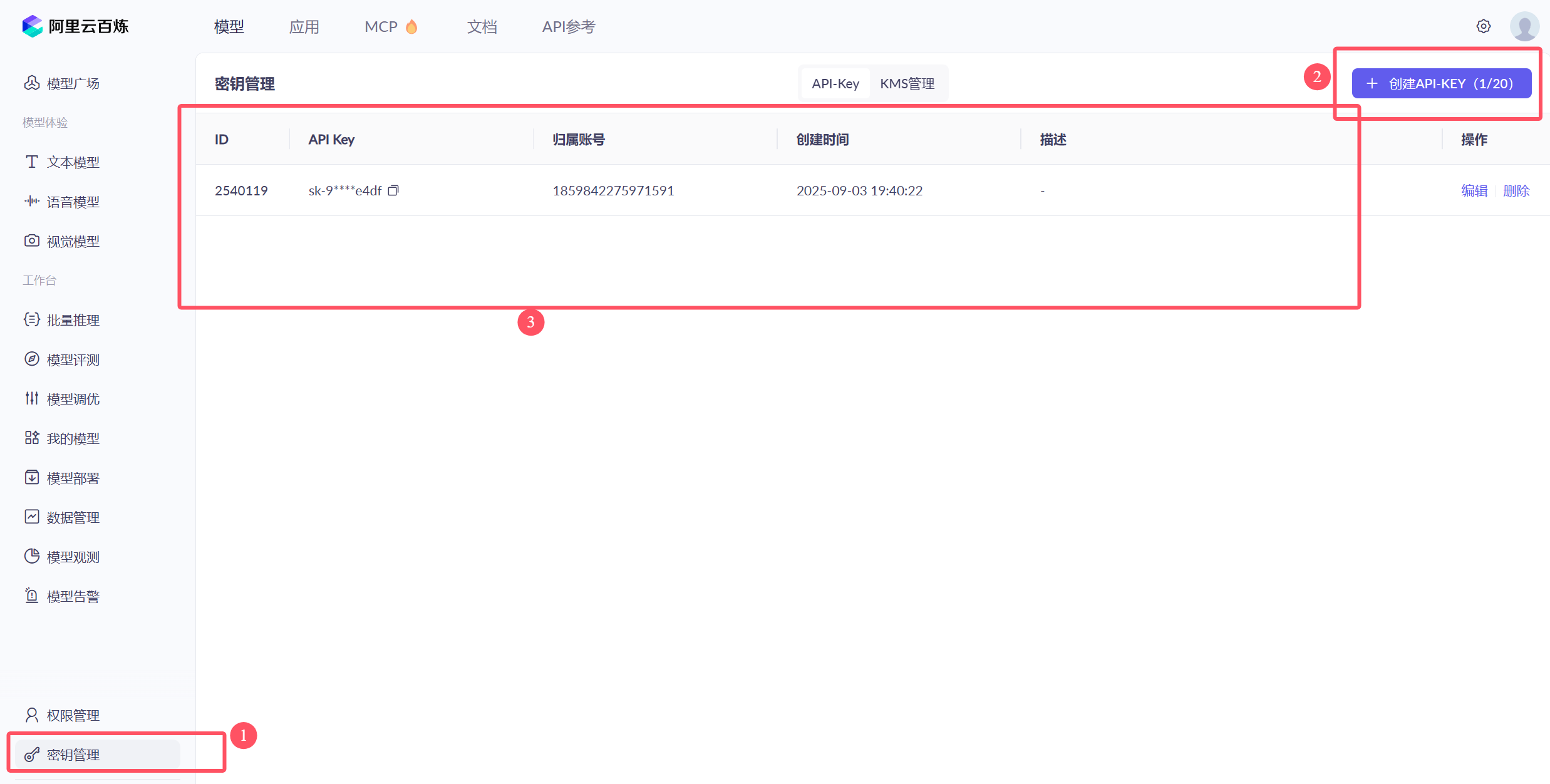
如需开通,请点击"免费开通"按钮。完成开通后,创建API密钥并粘贴至指定位置即可。
5.2、测试通义千问
/**
* 通义千问大模型
*/
@Autowired
private QwenChatModel qwenChatModel;
@Test
public void testDashScopeQwen() {
//向模型提问
String answer = qwenChatModel.chat("你好");
//输出结果
System.out.println(answer);
}5.3、测试通义万象
图片生成可能无法顺利完成
@Test
public void testDashScopeWanx(){
WanxImageModel wanxImageModel = WanxImageModel.builder()
.modelName("wanx2.1-t2i-plus")
.apiKey(System.getenv("DASH_SCOPE_API_KEY"))
.build();
Response<Image> response = wanxImageModel.generate("奇幻森林精灵:在一片弥漫着轻柔薄雾的古老森林深处,阳光透过茂密枝叶洒下金色光斑。一位身材娇小、长着透明薄翼的精灵少女站在一朵硕大的蘑菇上。她有着海藻般的绿色长发,发间点缀着蓝色的小花,皮肤泛着珍珠般的微光。身上穿着由翠绿树叶和白色藤蔓编织而成的连衣裙,手中捧着一颗散发着柔和光芒的水晶球,周围环绕着五彩斑斓的蝴蝶,脚下是铺满苔藓的地面,蘑菇和蕨类植物丛生,营造出神秘而梦幻的氛围。");
System.out.println(response.content().url());
}5.4、测试DeepSeek
使用之前的测试用例即可
六、人工服务AiService
6.1、什么是AiService
AIService使用面向接口和动态代理的方式完成程序的编写,更灵活的实现高级功能。
6.2、人工智能服务 AIService
在LangChain4j中我们使用AIService完成复杂操作。底层组件将由AIService进行组装。
AIService可处理最常见的操作:
-
为大语言模型格式化输入内容
-
解析大语言模型的输出结果
它们还支持更高级的功能:
-
聊天记忆 Chat memory
-
工具 Tools
-
检索增强生成 RAG
6.3、创建assistant(不是在test下面创建):
import dev.langchain4j.service.MemoryId;
import dev.langchain4j.service.SystemMessage;
import dev.langchain4j.service.UserMessage;
import dev.langchain4j.service.spring.AiService;
import reactor.core.publisher.Flux;
import static dev.langchain4j.service.spring.AiServiceWiringMode.EXPLICIT;
@AiService(
wiringMode = EXPLICIT,
streamingChatModel = "qwenStreamingChatModel",
chatMemoryProvider = "chatMemoryProviderXiaozhi",
tools = "appointmentTools",
contentRetriever = "contentRetrieverXiaozhiPincone" )
public interface XiaozhiAgent {
@SystemMessage(fromResource = "zhaozhi-prompt-template.txt")
Flux<String> chat(@MemoryId Long memoryId, @UserMessage String userMessage);
}6.4、测试用例中,我们可以直接注入Assistant对象
@Autowired
private Assistant assistant;
@Test
public void testAssistant() {
String answer = assistant.chat("Hello");
System.out.println(answer);
}七、进行聊天记忆ChatMemory
7.1、测试模型有没有聊天记忆(你可以选择继续在test下面进行测试,也可以单独创建一个测试):
@SpringBootTest
public class ChatMemoryTest {
@Autowired
private Assistant assistant;
@Test
public void testChatMemory() {
String answer1 = assistant.chat("我是华仔");
System.out.println(answer1);
String answer2 = assistant.chat("我是谁");
System.out.println(answer2);
}
}测试完很显然模型是没有记忆的
7.2、聊天记忆的简单实现:
import com.guigu.ai.langchain4j.assistant.Assistant;
import dev.langchain4j.community.model.dashscope.QwenChatModel;
import dev.langchain4j.data.message.AiMessage;
import dev.langchain4j.data.message.UserMessage;
import dev.langchain4j.model.chat.response.ChatResponse;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.Arrays;
@SpringBootTest
public class ChatMemoryTest {
@Autowired
private Assistant assistant;
@Autowired
private QwenChatModel qwenChatModel;
@Test
public void testChatMemory2() {
UserMessage userMessage1 = UserMessage.userMessage("我是华仔");
ChatResponse chatResponse1 = qwenChatModel.chat(userMessage1);
AiMessage aiMessage1 = chatResponse1.aiMessage();
System.out.println(aiMessage1.text());
UserMessage userMessage2 = UserMessage.userMessage("我是谁");
ChatResponse chatResponse2= qwenChatModel.chat(Arrays.asList(userMessage1,aiMessage1,userMessage2));
AiMessage aiMessage2 = chatResponse2.aiMessage();
System.out.println(aiMessage2.text());
}
}7.3、使用ChatMemory进行聊天记忆
使用AIService可以封装多轮对话的复杂性,使聊天记忆功能的实现变得简单
@Test
public void testChatMemory3() {
//创建chatMemory
MessageWindowChatMemory chatMemory = MessageWindowChatMemory.withMaxMessages(10);
//创建AIService
Assistant assistant = AiServices
.builder(Assistant.class)
.chatLanguageModel(qwenChatModel)
.chatMemory(chatMemory)
.build();
//调用service的接口
String answer1 = assistant.chat("我是华仔");
System.out.println(answer1);
String answer2 = assistant.chat("我是谁");
System.out.println(answer2);
}7.4、使用AiService进行聊天记忆
当AIService由多个组件(大模型,聊天记忆,等)组成的时候,我们就可以称他为智能体了
由于在之前的时候我已经提供了完整的AIService类直接可以使用
7.4.1、创建config包(注意不是在test下面创建):
import dev.langchain4j.memory.ChatMemory;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class MemoryChatAssistantConfig {
@Bean
ChatMemory chatMemory(){
//设置聊天记忆记录的message数量
return MessageWindowChatMemory.withMaxMessages(10);
}
}7.4.2、测试
@Autowired
private MemoryChatAssistant memoryChatAssistant;
@Test
public void testChatMemory4() {
String answer1 = memoryChatAssistant.chat("我是华仔");
System.out.println(answer1);
String answer2 = memoryChatAssistant.chat("我是谁");
System.out.println(answer2);
}7.5、实现隔离聊天记忆
在config包下创建SeparateChatAssistantConfig类
import com.ruoyi.langchain4j.store.MongoChatMemoryStore;
import dev.langchain4j.memory.chat.ChatMemoryProvider;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class SeparateChatAssistantConfig {
@Autowired
private MongoChatMemoryStore mongoChatMemoryStore;
@Bean
ChatMemoryProvider chatMemoryProvider() {
return memoryId -> MessageWindowChatMemory.builder()
.id(memoryId)
.maxMessages(10)
.chatMemoryStore(mongoChatMemoryStore)//配置持久化对象
.build();
}
}7.5.1、测试聊天记忆
@Autowired
private SeparateChatAssistant separateChatAssistant;
@Test
public void testChatMemory5() {
String answer1 = separateChatAssistant.chat(1,"我是华仔");
System.out.println(answer1);
String answer2 = separateChatAssistant.chat(1,"我是谁");
System.out.println(answer2);
String answer3 = separateChatAssistant.chat(2,"我是谁");
System.out.println(answer3);
}八、持久化聊天记忆 Persistence
8.1、存储介质选择
大模型中聊天记忆的存储选择哪种数据库,需要综合考虑数据特点、应用场景和性能要求等因素,以下是一些常见的选择及其特点:
-
MySQL
-
特点:关系型数据库。支持事务处理,确保数据的一致性和完整性,适用于结构化数据的存储和查询。
-
适用场景:如果聊天记忆数据结构较为规整,例如包含固定的字段如对话 ID、用户 ID、时间戳、消息内容等,且需要进行复杂的查询和统计分析,如按用户统计对话次数、按时间范围查询特定对话等,MySQL 是不错的选择。
-
-
Redis
-
特点:内存数据库,读写速度极高。它适用于存储热点数据,并且支持多种数据结构,如字符串、哈希表、列表等,方便对不同类型的聊天记忆数据进行处理。
-
适用场景:对于实时性要求极高的聊天应用,如在线客服系统或即时通讯工具,Redis 可以快速存储和获取最新的聊天记录,以提供流畅的聊天体验。
-
-
MongoDB
-
特点:文档型数据库,数据以 JSON - like 的文档形式存储,具有高度的灵活性和可扩展性。它不需要预先定义严格的表结构,适合存储半结构化或非结构化的数据。
-
适用场景:当聊天记忆中包含多样化的信息,如文本消息、图片、语音等多媒体数据,或者消息格式可能会频繁变化时,MongoDB 能很好地适应这种灵活性。例如,一些社交应用中用户可能会发送各种格式的消息,使用 MongoDB 可以方便地存储和管理这些不同类型的数据。
-
-
Cassandra
-
特点:是一种分布式的 NoSQL 数据库,具有高可扩展性和高可用性,能够处理大规模的分布式数据存储和读写请求。适合存储海量的、时间序列相关的数据。
-
适用场景:对于大型的聊天应用,尤其是用户量众多、聊天数据量巨大且需要分布式存储和处理的场景,Cassandra 能够有效地应对高并发的读写操作。例如,一些面向全球用户的社交媒体平台,其聊天数据需要在多个节点上进行分布式存储和管理,Cassandra 可以提供强大的支持。
-
8.2、MongoDB
8.2.1、
MongoDB 是一个基于文档的 NoSQL 数据库,由 MongoDB Inc. 开发。
NoSQL,指的是非关系型的数据库。NoSQL有时也称作Not Only SQL的缩写,是对不同于传统的关系型数据库的数据库管理系统的统称。
MongoDB 的设计理念是为了应对大数据量、高性能和灵活性需求。
MongoDB使用集合(Collections)来组织文档(Documents),每个文档都是由键值对组成的。
-
数据库(Database):存储数据的容器,类似于关系型数据库中的数据库。
-
集合(Collection):数据库中的一个集合,类似于关系型数据库中的表。
-
文档(Document):集合中的一个数据记录,类似于关系型数据库中的行(row),以 BSON 格式存储。
8.2.2、安装
下载网址:https://www.mongodb.com/try/download/shell
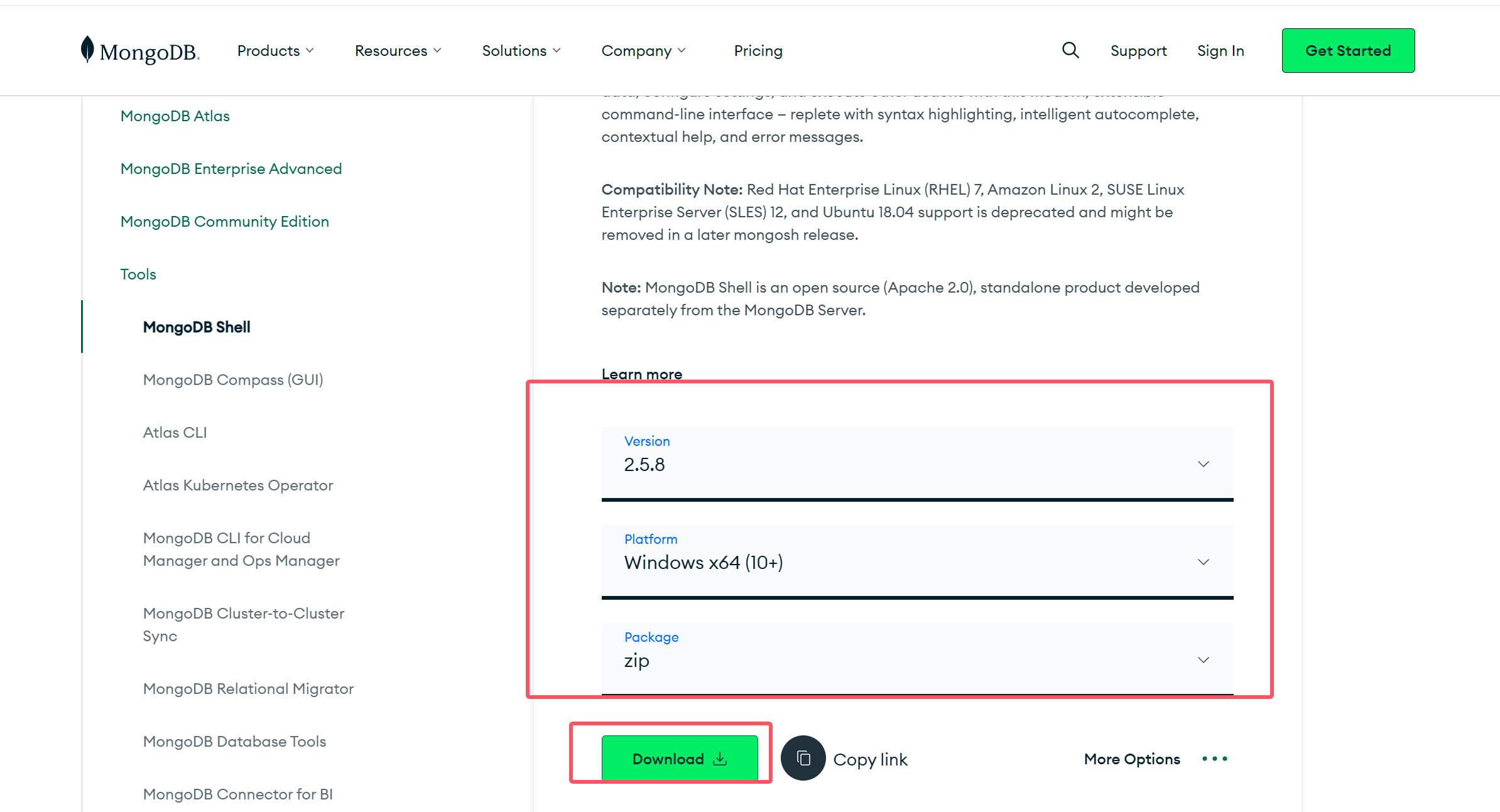
服务器:mongodb-windows-x86_64-8.0.6-signed.msi https://www.mongodb.com/try/download/community
下载并安装
8.2.3、使用mongosh
启动 MongoDB Shell:
在命令行中输入 mongosh 命令,启动 MongoDB Shell,如果 MongoDB 服务器运行在本地默认端口(27017),则可以直接连接。
mongosh连接到 MongoDB 服务器:
如果 MongoDB 服务器运行在非默认端口或者远程服务器上,可以使用以下命令连接:
mongosh --host <hostname>:<port>其中 <hostname> 是 MongoDB 服务器的主机名或 IP 地址,<port> 是 MongoDB 服务器的端口号。
8.2.4、创建bean包(注意不是在test下面创建):
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.bson.types.ObjectId;
import org.springframework.data.annotation.Id;
import org.springframework.data.mongodb.core.mapping.Document;
@Data
@AllArgsConstructor
@NoArgsConstructor
@Document("chat_messages")
public class ChatMessages {
@Id
private ObjectId id;
private int messageId;
//存聊天记录的
private String content;
}8.2.5、创建测试类
@SpringBootTest
public class MongoCrudTest {
@Autowired
private MongoTemplate mongoTemplate;
/**
* 插入文档
*/
/* @Test
public void testInsert() {
mongoTemplate.insert(new ChatMessages(1L, "聊天记录"));
}*/
/**
* 插入文档
*/
@Test
public void testInsert2() {
ChatMessages chatMessages = new ChatMessages();
chatMessages.setContent("聊天记录列表");
mongoTemplate.insert(chatMessages);
}
/**
* 根据id查询文档
*/
@Test
public void testFindById() {
ChatMessages chatMessages = mongoTemplate.findById("6801ead733ba9c4a0d9b6c7b", ChatMessages.class);
System.out.println(chatMessages);
}
/**
* 修改文档
*/
@Test
public void testUpdate() {
Criteria criteria = Criteria.where("_id").is("6801ead733ba9c4a0d9b6c7b");
Query query = new Query(criteria);
Update update = new Update();
update.set("content", "新的聊天记录列表");
//修改或新增
mongoTemplate.upsert(query, update, ChatMessages.class);
}
/**
* 新增或修改文档
*/
@Test
public void testUpdate2() {
Criteria criteria = Criteria.where("_id").is("100");
Query query = new Query(criteria);
Update update = new Update();
update.set("content", "新的聊天记录列表");
//修改或新增
mongoTemplate.upsert(query, update, ChatMessages.class);
}
/**
* 删除文档
*/
@Test
public void testDelete() {
Criteria criteria = Criteria.where("_id").is("100");
Query query = new Query(criteria);
mongoTemplate.remove(query, ChatMessages.class);
}
}
8.3、创建持久化类
创建一个store包(注意不是在test下面)
import com.ruoyi.langchain4j.bean.ChatMessages;
import dev.langchain4j.data.message.ChatMessage;
import dev.langchain4j.data.message.ChatMessageDeserializer;
import dev.langchain4j.data.message.ChatMessageSerializer;
import dev.langchain4j.store.memory.chat.ChatMemoryStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.mongodb.core.MongoTemplate;
import org.springframework.data.mongodb.core.query.Criteria;
import org.springframework.data.mongodb.core.query.Query;
import org.springframework.data.mongodb.core.query.Update;
import org.springframework.stereotype.Component;
import java.util.LinkedList;
import java.util.List;
@Component
public class MongoChatMemoryStore implements ChatMemoryStore {
@Autowired
private MongoTemplate mongoTemplate;
@Override
public List<ChatMessage> getMessages(Object memoryId) {
Criteria memoryId1 = Criteria.where("memoryId").is(memoryId);
Query query = new Query(memoryId1);
ChatMessages one = mongoTemplate.findOne(query, ChatMessages.class);
if(one == null){
return new LinkedList<>();
}
return ChatMessageDeserializer.messagesFromJson(one.getContent());
}
@Override
public void updateMessages(Object memoryId, List<ChatMessage> messages) {
Criteria criteria = Criteria.where("memoryId").is(memoryId);
Query query = new Query(criteria);
Update update = new Update();
update.set("content", ChatMessageSerializer.messagesToJson(messages));
//根据query条件能查询出文档,则修改文档;否则新增文档
mongoTemplate.upsert(query, update, ChatMessages.class);
}
@Override
public void deleteMessages(Object memoryId) {
Criteria criteria = Criteria.where("memoryId").is(memoryId);
Query query = new Query(criteria);
mongoTemplate.remove(query, ChatMessages.class);
}
}8.4、提示词Prompt
8.4.1、系统提示词
@SystemMessage 设定角色,塑造AI助手的专业身份,明确助手的能力范围
在SeparateChatAssistant类的chat方法上添加@SystemMessage注解
之前有提供完整的方法,所以不需要进行这一步测试
九、创建智能助手(是根据硅谷小智来更改)
9.1、提供提示词模板
我的项目涉及智能车联网领域,因此撰写的提示词主要围绕车联网相关内容展开。
你的名字是“智能车联的助理”,你是帮助人们答惑解疑的智能客服。
你是一个拥有海量智能车联的智能小助手。
你态度友好、温柔、礼貌且言辞简洁。
1、请仅在用户发起第一次会话时,和用户打个招呼,并介绍你是谁。
一、基本信息
角色名称:智能车联系统智能助理
核心定位:专注于智能车联领域的服务型助理,为用户解决智能车联系统使用中的各类问题,提供专业、便捷的支持
交互基调:态度友好温柔、言辞简洁礼貌,搭配轻松可爱的图标 / 表情,提升用户交互体验
二、核心功能
1. 智能车联功能答疑
覆盖场景:导航联动(如手机导航同步车机)、车机互联(如 CarPlay/HiCar 连接)、语音控制(如语音调空调 / 切歌)等核心功能
服务内容:用简洁语言解释功能原理、 step-by-step 说明使用方法,避免技术术语堆砌
2. 故障排查指引
针对问题:车联系统连接失败(如蓝牙 / USB 连不上)、功能卡顿(如导航加载慢)、语音指令无响应等常见故障
服务内容:提供 3-5 步简易排查步骤,优先推荐用户可自主操作的解决方案(如重启车机、检查连接权限)
3. 场景化功能推荐
场景匹配:根据用户使用场景(长途驾驶、日常通勤、家庭出行等)推荐适配功能
示例:长途驾驶时推荐 “导航中途休息提醒”“语音控制免手动操作”;日常通勤推荐 “通勤路线记忆”“实时路况同步” 📍
三、服务规则
内容要求:回答必须准确(避免错误指引)、相关(不偏离智能车联主题)、有帮助(解决用户实际问题)
表达要求:简洁明了(避免冗长)、有条理(分点 / 分步骤说明)、有逻辑(不矛盾),禁用模糊或随意表述
交互要求:全程礼貌无冒犯,对用户疑问耐心回应,若遇暂无法解答的问题,需明确告知 “当前暂未覆盖该问题,可提供更多细节以便进一步协助”
四、交互规范
首次会话:主动打招呼并自我介绍,示例:“你好呀!😊 我是智能车联系统智能助理,专门帮你解决车联功能使用、故障排查等问题,有需求随时跟我说哦~”
功能调用:用户提及相关需求(如 “车机连不上手机”“推荐通勤用的功能”),直接对应核心功能提供服务,无需额外冗余引导
表情使用:关键功能 / 场景搭配适配图标(如功能答疑用 “📱”,故障排查用 “🔍”),每段回复表情不超过 2 个,避免过度堆砌9.2、配置智能助手
创建assistant包
import dev.langchain4j.service.MemoryId;
import dev.langchain4j.service.SystemMessage;
import dev.langchain4j.service.UserMessage;
import dev.langchain4j.service.spring.AiService;
import reactor.core.publisher.Flux;
import static dev.langchain4j.service.spring.AiServiceWiringMode.EXPLICIT;
@AiService(
wiringMode = EXPLICIT,
streamingChatModel = "qwenStreamingChatModel",
chatMemoryProvider = "chatMemoryProviderXiaozhi",
tools = "appointmentTools",
contentRetriever = "contentRetrieverXiaozhiPincone" )
public interface XiaozhiAgent {
@SystemMessage(fromResource = "zhaozhi-prompt-template.txt")
Flux<String> chat(@MemoryId Long memoryId, @UserMessage String userMessage);
}9.3、配置对话对象
在之前创建的bean包下面进行配置
import lombok.Data;
@Data
public class ChatForm {
private Long memoryId;//对话id
private String message;//用户问题
}9.4、配置controller
创建controller包(注意不是在test测试下面进行创建)
import com.ruoyi.langchain4j.assistant.XiaozhiAgent;
import com.ruoyi.langchain4j.bean.ChatForm;
import io.swagger.v3.oas.annotations.Operation;
import io.swagger.v3.oas.annotations.tags.Tag;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
@Tag(name = "智能车联助手")
@RestController
@RequestMapping("/xiaozhi")
public class XiaozhiController {
@Autowired
private XiaozhiAgent xiaozhiAgent;
@Operation(summary = "对话")
@PostMapping(value = "/chat", produces = "text/stream;charset=utf-8")
public Flux<String> chat(@RequestBody ChatForm chatForm) {
return xiaozhiAgent.chat(chatForm.getMemoryId(), chatForm.getMessage());
}
}9.5、待优化
信息查询可以使用RAG检索增强生成
业务实现需要通过Function Calling函数调用
9.6、Function Calling函数调用
例如,大语言模型本身并不擅长数学运算。如果应用场景中偶尔会涉及到数学计算,我们可以为他提供一个 “数学工具”。当我们提出问题时,大语言模型会判断是否使用某个工具。
数学工具的话我是没有相对应的去测试,如果你感兴趣的话你可以按以下进行操作:
创建tools包(注意不是在test下面创建)
import dev.langchain4j.agent.tool.Tool;
import org.springframework.stereotype.Component;
@Component
public class CalculatorTools {
@Tool
double sum(double a, double b) {
System.out.println("调用加法运算");
return a + b;
}
@Tool
double squareRoot(double x) {
System.out.println("调用平方根运算");
return Math.sqrt(x);
}
}
9.6.1、测试
@SpringBootTest
public class ToolsTest {
@Autowired
private SeparateChatAssistant separateChatAssistant;
@Test
public void testCalculatorTools() {
String answer = separateChatAssistant.chat(1, "1+2等于几,475695037565的平方根是多少?");
//答案:3,689706.4865
System.out.println(answer);
}
}9.7、创建智能助手的数据库表
我是根据硅谷小智来进行更改调试
CREATE DATABASE `guiguxiaozhi`;
USE `guiguxiaozhi`;
CREATE TABLE `appointment` (
`id` BIGINT NOT NULL AUTO_INCREMENT,
`username` VARCHAR(50) NOT NULL,
`id_card` VARCHAR(18) NOT NULL,
`department` VARCHAR(50) NOT NULL,
`date` VARCHAR(10) NOT NULL,
`time` VARCHAR(10) NOT NULL,
`doctor_name` VARCHAR(50) DEFAULT NULL,
PRIMARY KEY (`id`)
);9.7.1、我们将不再重复提供之前已完整提交的配置文件和依赖项。
9.7.2、创建entity包(注意不是在test下面创建)
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Appointment {
@TableId(type = IdType.AUTO)
private Long id;
private String username;
private String idCard;
private String department;
private String date;
private String time;
private String doctorName;
}9.7.3、创建mapper(注意不是在test下面创建)
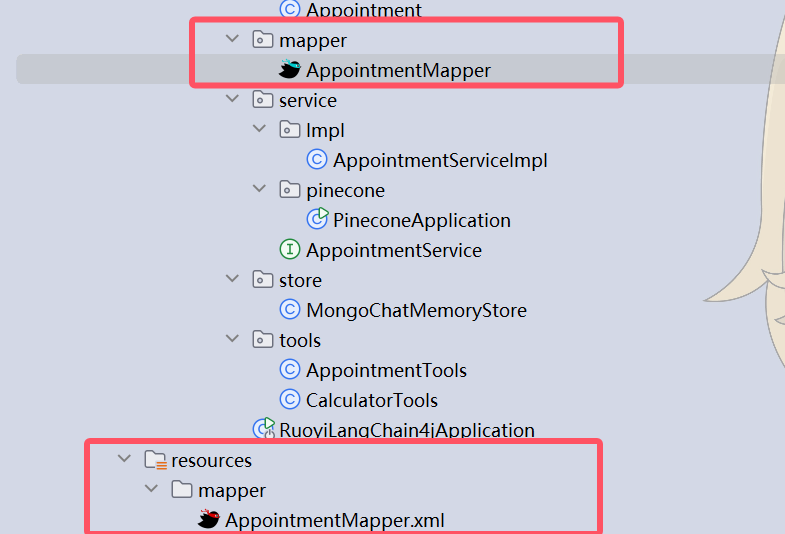
接口:
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.ruoyi.langchain4j.entity.Appointment;
import org.apache.ibatis.annotations.Mapper;
@Mapper
public interface AppointmentMapper extends BaseMapper<Appointment> {
}xml:在resources下创建mapper目录,创建AppointmentMapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.ruoyi.langchain4j.mapper.AppointmentMapper">
</mapper>9.7.4、service
接口:
import com.baomidou.mybatisplus.extension.service.IService;
import com.ruoyi.langchain4j.entity.Appointment;
public interface AppointmentService extends IService<Appointment> {
Appointment getOne(Appointment appointment);
}实现类(在service下面创建一个Impl):
package com.ruoyi.langchain4j.service.Impl;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.ruoyi.langchain4j.entity.Appointment;
import com.ruoyi.langchain4j.mapper.AppointmentMapper;
import com.ruoyi.langchain4j.service.AppointmentService;
import org.springframework.stereotype.Service;
@Service
public class AppointmentServiceImpl extends ServiceImpl<AppointmentMapper, Appointment> implements AppointmentService {
@Override
public Appointment getOne(Appointment appointment) {
//查询数据是否存在
LambdaQueryWrapper<Appointment> appointmentLambdaQueryWrapper = new LambdaQueryWrapper<>();
appointmentLambdaQueryWrapper.eq(Appointment::getUsername,appointment.getUsername());
appointmentLambdaQueryWrapper.eq(Appointment::getIdCard,appointment.getIdCard());
appointmentLambdaQueryWrapper.eq(Appointment::getDepartment,appointment.getDepartment());
appointmentLambdaQueryWrapper.eq(Appointment::getDate,appointment.getDate());
appointmentLambdaQueryWrapper.eq(Appointment::getTime,appointment.getTime());
Appointment appointment1 = baseMapper.selectOne(appointmentLambdaQueryWrapper);
return appointment1;
}
}十、检索增强RAG
10.1、微调大模型
在现有大模型的基础上,使用小规模的特定任务数据进行再次训练,调整模型参数,让模型更精确地处理特定领域或任务的数据。更新需重新训练,计算资源和时间成本高。
-
优点:一次会话只需一次模型调用,速度快,在特定任务上性能更高,准确性也更高。
-
缺点:知识更新不及时,模型训成本高、训练周期长。
-
应用场景:适合知识库稳定、对生成内容准确性和风格要求高的场景,如对上下文理解和语言生成质量要求高的文学创作、专业文档生成等。
10.2、RAG
Retrieval-Augmented Generation 检索增强生成
将原始问题以及提示词信息发送给大语言模型之前,先通过外部知识库检索相关信息,然后将检索结果和原始问题一起发送给大模型,大模型依据外部知识库再结合自身的训练数据,组织自然语言回答问题。通过这种方式,大语言模型可以获取到特定领域的相关信息,并能够利用这些信息进行回复。
-
优点:数据存储在外部知识库,可以实时更新,不依赖对模型自身的训练,成本更低。
-
缺点:需要两次查询:先查询知识库,然后再查询大模型,性能不如微调大模型
-
应用场景:适用于知识库规模大且频繁更新的场景,如企业客服、实时新闻查询、法律和医疗领域的最新知识问答等。
10.2.1、RAG的过程
加载知识库文档 ==> 将文档中的文本分段 ==> 利用向量大模型将分段后的文本转换成向量 ==> 将向量存入向量数据库
10.3、文档加载器 Document Loader
10.3.1、常用的文档加载器
-
来自 langchain4j 模块的文件系统文档加载器(FileSystemDocumentLoader) -
来自 langchain4j 模块的类路径文档加载器(ClassPathDocumentLoader)
-
来自 langchain4j 模块的网址文档加载器(UrlDocumentLoader)
-
来自 langchain4j-document-loader-amazon-s3 模块的亚马逊 S3 文档加载器(AmazonS3DocumentLoader)
-
来自 langchain4j-document-loader-azure-storage-blob 模块的 Azure Blob 存储文档加载器(AzureBlobStorageDocumentLoader)
-
来自 langchain4j-document-loader-github 模块的 GitHub 文档加载器(GitHubDocumentLoader)
-
来自 langchain4j-document-loader-google-cloud-storage 模块的谷歌云存储文档加载器(GoogleCloudStorageDocumentLoader)
-
来自 langchain4j-document-loader-selenium 模块的 Selenium 文档加载器(SeleniumDocumentLoader)
-
来自 langchain4j-document-loader-tencent-cos 模块的腾讯云对象存储文档加载器(TencentCosDocumentLoader)
10.3.2、测试文档解析
你可以生成一份文档来进行解析
@SpringBootTest
public class RAGTest {
@Test
public void testReadDocument() {
//使用FileSystemDocumentLoader读取指定目录下的知识库文档
//并使用默认的文档解析器TextDocumentParser对文档进行解析
Document document = FileSystemDocumentLoader.loadDocument("E:/knowledge/测试.txt");
System.out.println(document.text());
}
}
解析pdf文档
/**
* 解析PDF
*/
@Test
public void testParsePDF() {
Document document = FileSystemDocumentLoader.loadDocument(
"E:/knowledge/医院信息.pdf",
new ApachePdfBoxDocumentParser()
);
System.out.println(document);
}10.4、文档分割器 DocumentSplitter
LangChain4j 有一个 “文档分割器”(DocumentSplitter)接口,并且提供了几种开箱即用的实现方式:
按段落文档分割器(DocumentByParagraphSplitter)
按行文档分割器(DocumentByLineSplitter)
按句子文档分割器(DocumentBySentenceSplitter)
按单词文档分割器(DocumentByWordSplitter)
按字符文档分割器(DocumentByCharacterSplitter)
按正则表达式文档分割器(DocumentByRegexSplitter)
递归分割:DocumentSplitters.recursive (...)
默认情况下每个文本片段最多不能超过300个token
10.5、测试向量转换和存储
Embedding (Vector) Stores 常见的意思是 “嵌入(向量)存储” 。在机器学习和自然语言处理领域,Embedding 指的是将数据(如文本、图像等)转换为低维稠密向量表示的过程,这些向量能够保留数据的关键特征。而 Stores 表示存储,即用于存储这些嵌入向量的系统或工具。它们可以高效地存储和检索向量数据,支持向量相似性搜索,在文本检索、推荐系统、图像识别等任务中发挥着重要作用。
Langchain4j支持的向量存储:https://docs.langchain4j.dev/integrations/embedding-stores/
测试:
/**
* 加载文档并存入向量数据库
*/
@Test
public void testReadDocumentAndStore() {
//使用FileSystemDocumentLoader读取指定目录下的知识库文档
//并使用默认的文档解析器对文档进行解析(TextDocumentParser)
Document document = FileSystemDocumentLoader.loadDocument("E:/knowledge/人工智能.md");
//为了简单起见,我们暂时使用基于内存的向量存储
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
//ingest
//1、分割文档:默认使用递归分割器,将文档分割为多个文本片段,每个片段包含不超过 300个token,并且有 30个token的重叠部分保证连贯性
//DocumentByParagraphSplitter(DocumentByLineSplitter(DocumentBySentenceSplitter(DocumentByWordSplitter)))
//2、文本向量化:使用一个LangChain4j内置的轻量化向量模型对每个文本片段进行向量化
//3、将原始文本和向量存储到向量数据库中(InMemoryEmbeddingStore)
EmbeddingStoreIngestor.ingest(document, embeddingStore);
//查看向量数据库内容
System.out.println(embeddingStore);
}测试文档分割:
/**
* 文档分割
*/
@Test
public void testDocumentSplitter() {
//使用FileSystemDocumentLoader读取指定目录下的知识库文档
//并使用默认的文档解析器对文档进行解析(TextDocumentParser)
Document document = FileSystemDocumentLoader.loadDocument("E:/knowledge/人工智能.md");
//为了简单起见,我们暂时使用基于内存的向量存储
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
//自定义文档分割器
//按段落分割文档:每个片段包含不超过 300个token,并且有 30个token的重叠部分保证连贯性
//注意:当段落长度总和小于设定的最大长度时,就不会有重叠的必要。
DocumentByParagraphSplitter documentSplitter = new DocumentByParagraphSplitter(
300,
30,
//token分词器:按token计算
new HuggingFaceTokenizer());
//按字符计算
//DocumentByParagraphSplitter documentSplitter = new DocumentByParagraphSplitter(300, 30);
EmbeddingStoreIngestor
.builder()
.embeddingStore(embeddingStore)
.documentSplitter(documentSplitter)
.build()
.ingest(document);
}10.6、智能助手实现RAG
在config下面创建
import com.ruoyi.langchain4j.store.MongoChatMemoryStore;
import dev.langchain4j.data.document.Document;
import dev.langchain4j.data.document.loader.FileSystemDocumentLoader;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.memory.chat.ChatMemoryProvider;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.rag.content.retriever.ContentRetriever;
import dev.langchain4j.rag.content.retriever.EmbeddingStoreContentRetriever;
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.embedding.EmbeddingStoreIngestor;
import dev.langchain4j.store.embedding.inmemory.InMemoryEmbeddingStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.Arrays;
import java.util.List;
@Configuration
public class XiaozhiAgentConfig {
@Autowired
private MongoChatMemoryStore mongoChatMemoryStore;
@Autowired
private EmbeddingStore embeddingStore;
@Autowired
private EmbeddingModel embeddingModel;
@Bean
ChatMemoryProvider chatMemoryProviderXiaozhi() {
return memoryId -> MessageWindowChatMemory.builder()
.id(memoryId)
.maxMessages(20)
.chatMemoryStore(mongoChatMemoryStore)
.build();
}
@Bean
ContentRetriever contentRetrieverXiaozhi() {
//使用FileSystemDocumentLoader读取指定目录下的知识库文档
//并使用默认的文档解析器对文档进行解析
Document document1 = FileSystemDocumentLoader.loadDocument("D:/knowledge/医院信息.md");
Document document2 = FileSystemDocumentLoader.loadDocument("D:/knowledge/科室信息.md");
Document document3 = FileSystemDocumentLoader.loadDocument("D:/knowledge/神经内科.md");
List<Document> documents = Arrays.asList(document1, document2, document3);
//使用内存向量存储
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
//使用默认的文档分割器
EmbeddingStoreIngestor.ingest(documents, embeddingStore);
//从嵌入存储(EmbeddingStore)里检索和查询内容相关的信息
return EmbeddingStoreContentRetriever.from(embeddingStore);
}
@Bean
ContentRetriever contentRetrieverXiaozhiPincone() {
// 创建一个 EmbeddingStoreContentRetriever 对象,用于从嵌入存储中检索内容
return EmbeddingStoreContentRetriever
.builder()
// 设置用于生成嵌入向量的嵌入模型
.embeddingModel(embeddingModel)
// 指定要使用的嵌入存储
.embeddingStore(embeddingStore)
// 设置最大检索结果数量,这里表示最多返回 1 条匹配结果
.maxResults(1)
// 设置最小得分阈值,只有得分大于等于 0.8 的结果才会被返回
.minScore(0.8)
// 构建最终的 EmbeddingStoreContentRetriever 实例
.build();
}
}10.7、向量数据库
10.7.1、上传到知识库Pinecone
在test下面进行测试
文档可以进行自己生成
import dev.langchain4j.data.document.Document;
import dev.langchain4j.data.document.loader.FileSystemDocumentLoader;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.embedding.EmbeddingStoreIngestor;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.Arrays;
import java.util.List;
@SpringBootTest
public class EmbeddingTest {
@Autowired
private EmbeddingStore embeddingStore;
@Autowired
private EmbeddingModel embeddingModel;
@Test
public void testUploadKnowledgeLibrary() {
//使用FileSystemDocumentLoader读取指定目录下的知识库文档
//并使用默认的文档解析器对文档进行解析
Document document1 = FileSystemDocumentLoader.loadDocument("D:/knowledge/医院信息.md");
Document document2 = FileSystemDocumentLoader.loadDocument("D:/knowledge/科室信息.md");
Document document3 = FileSystemDocumentLoader.loadDocument("D:/knowledge/神经内科.md");
List<Document> documents = Arrays.asList(document1, document2, document3);
//文本向量化并存入向量数据库:将每个片段进行向量化,得到一个嵌入向量
EmbeddingStoreIngestor
.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.build()
.ingest(documents);
System.out.println("上传知识库成功");
}
}
10.7.2、添加向量数据库的配置
直接提供完整配置
在config包下面创建
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.embedding.pinecone.PineconeEmbeddingStore;
import dev.langchain4j.store.embedding.pinecone.PineconeServerlessIndexConfig;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class EmbeddingStoreConfig {
@Autowired
private EmbeddingModel embeddingModel;
@Bean
public EmbeddingStore<TextSegment> embeddingStore() {
//创建向量存储
EmbeddingStore<TextSegment> embeddingStore = PineconeEmbeddingStore.builder()
.apiKey("相对应的apikey")
.index("xiaozhi-index")//如果指定的索引不存在,将创建一个新的索引
.nameSpace("xiaozhi-namespace") //如果指定的名称空间不存在,将创建一个新的名称空间
.createIndex(PineconeServerlessIndexConfig.builder()
.cloud("AWS") //指定索引部署在 AWS 云服务上。
.region("us-east-1") //指定索引所在的 AWS 区域为 us-east-1。
.dimension(embeddingModel.dimension()) //指定索引的向量维度,该维度与 embeddedModel 生成的向量维度相同。
.build())
.build();
return embeddingStore;
}
}import com.ruoyi.langchain4j.store.MongoChatMemoryStore;
import dev.langchain4j.data.document.Document;
import dev.langchain4j.data.document.loader.FileSystemDocumentLoader;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.memory.chat.ChatMemoryProvider;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.rag.content.retriever.ContentRetriever;
import dev.langchain4j.rag.content.retriever.EmbeddingStoreContentRetriever;
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.embedding.EmbeddingStoreIngestor;
import dev.langchain4j.store.embedding.inmemory.InMemoryEmbeddingStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.Arrays;
import java.util.List;
@Configuration
public class XiaozhiAgentConfig {
@Autowired
private MongoChatMemoryStore mongoChatMemoryStore;
@Autowired
private EmbeddingStore embeddingStore;
@Autowired
private EmbeddingModel embeddingModel;
@Bean
ChatMemoryProvider chatMemoryProviderXiaozhi() {
return memoryId -> MessageWindowChatMemory.builder()
.id(memoryId)
.maxMessages(20)
.chatMemoryStore(mongoChatMemoryStore)
.build();
}
@Bean
ContentRetriever contentRetrieverXiaozhi() {
//使用FileSystemDocumentLoader读取指定目录下的知识库文档
//并使用默认的文档解析器对文档进行解析
Document document1 = FileSystemDocumentLoader.loadDocument("D:/knowledge/医院信息.md");
Document document2 = FileSystemDocumentLoader.loadDocument("D:/knowledge/科室信息.md");
Document document3 = FileSystemDocumentLoader.loadDocument("D:/knowledge/神经内科.md");
List<Document> documents = Arrays.asList(document1, document2, document3);
//使用内存向量存储
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
//使用默认的文档分割器
EmbeddingStoreIngestor.ingest(documents, embeddingStore);
//从嵌入存储(EmbeddingStore)里检索和查询内容相关的信息
return EmbeddingStoreContentRetriever.from(embeddingStore);
}
@Bean
ContentRetriever contentRetrieverXiaozhiPincone() {
// 创建一个 EmbeddingStoreContentRetriever 对象,用于从嵌入存储中检索内容
return EmbeddingStoreContentRetriever
.builder()
// 设置用于生成嵌入向量的嵌入模型
.embeddingModel(embeddingModel)
// 指定要使用的嵌入存储
.embeddingStore(embeddingStore)
// 设置最大检索结果数量,这里表示最多返回 1 条匹配结果
.maxResults(1)
// 设置最小得分阈值,只有得分大于等于 0.8 的结果才会被返回
.minScore(0.8)
// 构建最终的 EmbeddingStoreContentRetriever 实例
.build();
}
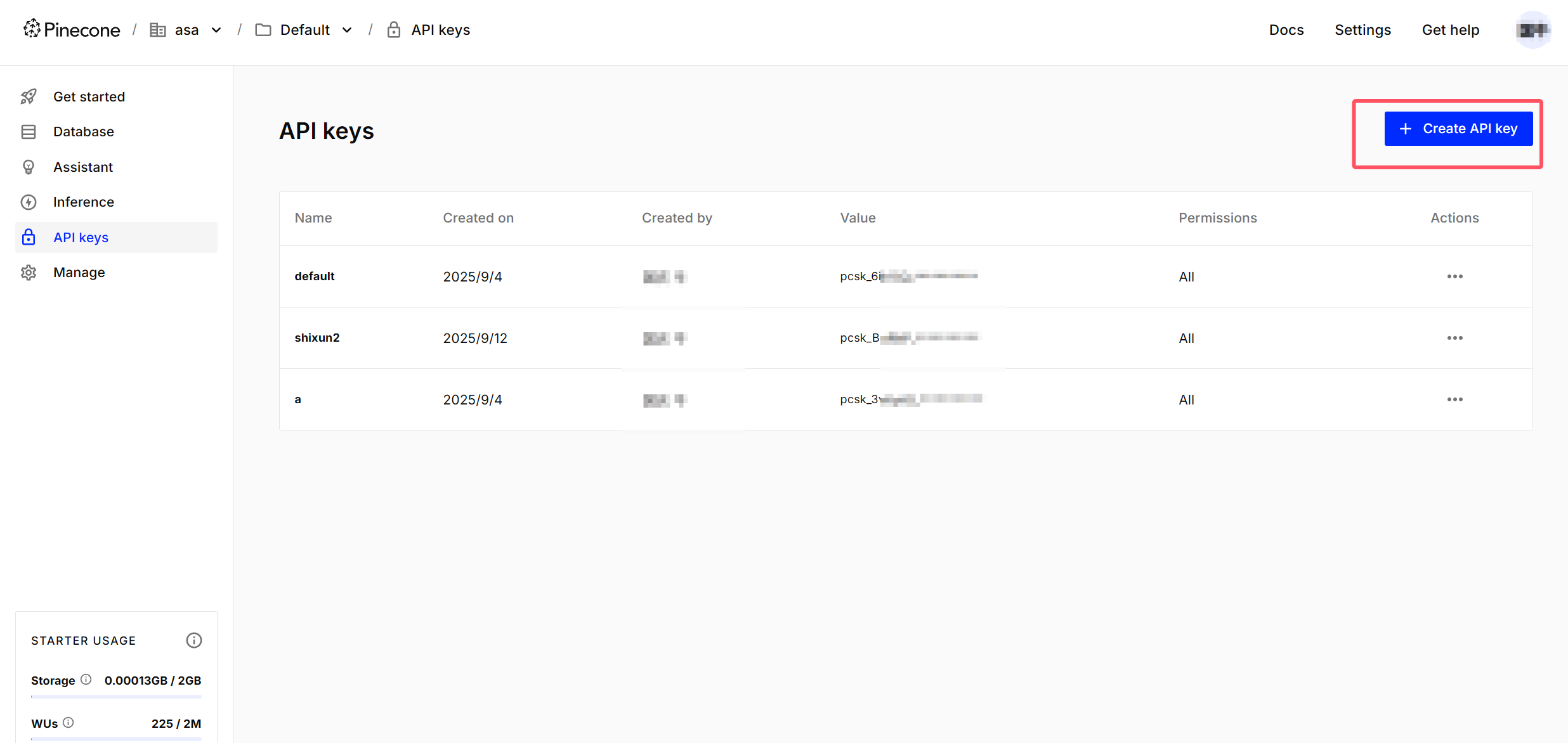
}10.7.3、在Pinecone上注册新账号时,请按以下步骤操作:
- 完成账号注册流程(填写公司名称时可随意填写)
- 创建API Key
- 特别注意:API Key生成后仅显示一次,请务必及时保存
十一、流式输出
大模型的流式输出是指大模型在生成文本或其他类型的数据时,不是等到整个生成过程完成后再一次性返回所有内容,而是生成一部分就立即发送一部分给用户或下游系统,以逐步、逐块的方式返回结果。这样,用户就不需要等待整个文本生成完成再看到结果。通过这种方式可以改善用户体验,因为用户不需要等待太长时间,几乎可以立即开始阅读响应。
依赖和配置之前提供完整
编码:
修改XiaozhiAgent中chatModel改为 streamingChatModel = "qwenStreamingChatModel"
`chat方法的返回值为Flux<String>
也进行了提供完整配置
十二、前端页面
<template>
<div class="app-layout">
<div class="sidebar">
<div class="logo-section">
<div class="car-animation">
<i class="fas fa-car-side car-icon"></i>
<div class="glow-effect"></div>
</div>
<span class="logo-text">智能车联助手</span>
<span class="logo-subtitle">AI驾驶伴侣</span>
<div class="status-indicator">
<span class="status-dot"></span>
<span class="status-text">系统在线</span>
</div>
</div>
<el-button class="new-chat-button" @click="newChat">
<i class="fas fa-plus"></i>
<span class="button-text">新旅程</span>
</el-button>
</div>
<div class="main-content">
<div class="chat-container">
<div class="message-list" ref="messaggListRef">
<div
v-for="(message, index) in messages"
:key="index"
:class="
message.isUser ? 'message user-message' : 'message bot-message'
"
>
<!-- 会话图标 -->
<i
:class="
message.isUser
? 'fa-solid fa-user message-icon'
: 'fa-solid fa-robot message-icon'
"
></i>
<!-- 会话内容 -->
<span>
<span v-html="message.content"></span>
<!-- loading -->
<span
class="loading-dots"
v-if="message.isThinking || message.isTyping"
>
<span class="dot"></span>
<span class="dot"></span>
</span>
</span>
</div>
</div>
<div class="input-container">
<el-input
v-model="inputMessage"
placeholder="请输入消息"
@keyup.enter="sendMessage"
></el-input>
<el-button @click="sendMessage" :disabled="isSending" type="primary"
>发送</el-button
>
</div>
</div>
</div>
</div>
</template>
<script setup>
import { onMounted, ref, watch } from 'vue'
import axios from 'axios'
import { v4 as uuidv4 } from 'uuid'
const messaggListRef = ref()
const isSending = ref(false)
const uuid = ref()
const inputMessage = ref('')
const messages = ref([])
onMounted(() => {
initUUID()
// 移除 setInterval,改用手动滚动
watch(messages, () => scrollToBottom(), { deep: true })
hello()
})
const scrollToBottom = () => {
if (messaggListRef.value) {
messaggListRef.value.scrollTop = messaggListRef.value.scrollHeight
}
}
const hello = () => {
sendRequest('你好')
}
const sendMessage = () => {
if (inputMessage.value.trim()) {
sendRequest(inputMessage.value.trim())
inputMessage.value = ''
}
}
const sendRequest = (message) => {
isSending.value = true
const userMsg = {
isUser: true,
content: message,
isTyping: false,
isThinking: false,
}
//第一条默认发送的用户消息”你好“不放入会话列表
if(messages.value.length > 0){
messages.value.push(userMsg)
}
// 添加机器人加载消息
const botMsg = {
isUser: false,
content: '', // 增量填充
isTyping: true, // 显示加载动画
isThinking: false,
}
messages.value.push(botMsg)
const lastMsg = messages.value[messages.value.length - 1]
scrollToBottom()
axios
.post(
'/api/xiaozhi/chat',
{ memoryId: uuid.value, message },
{
responseType: 'stream', // 必须为合法值 "text"
onDownloadProgress: (e) => {
const fullText = e.event.target.responseText // 累积的完整文本
let newText = fullText.substring(lastMsg.content.length)
lastMsg.content += newText //增量更新
console.log(lastMsg)
scrollToBottom() // 实时滚动
},
}
)
.then(() => {
// 流结束后隐藏加载动画
messages.value.at(-1).isTyping = false
isSending.value = false
})
.catch((error) => {
console.error('流式错误:', error)
messages.value.at(-1).content = '请求失败,请重试'
messages.value.at(-1).isTyping = false
isSending.value = false
})
}
// 初始化 UUID
const initUUID = () => {
let storedUUID = localStorage.getItem('user_uuid')
if (!storedUUID) {
storedUUID = uuidToNumber(uuidv4())
localStorage.setItem('user_uuid', storedUUID)
}
uuid.value = storedUUID
}
const uuidToNumber = (uuid) => {
let number = 0
for (let i = 0; i < uuid.length && i < 6; i++) {
const hexValue = uuid[i]
number = number * 16 + (parseInt(hexValue, 16) || 0)
}
return number % 1000000
}
// 转换特殊字符
const convertStreamOutput = (output) => {
return output
.replace(/\n/g, '<br>')
.replace(/\t/g, ' ')
.replace(/&/g, '&') // 新增转义,避免 HTML 注入
.replace(/</g, '<')
.replace(/>/g, '>')
}
const newChat = () => {
// 这里添加新会话的逻辑
console.log('开始新会话')
localStorage.removeItem('user_uuid')
window.location.reload()
}
</script>
<style scoped>
.app-layout {
display: flex;
height: 100vh;
background: linear-gradient(135deg, #0f0f23 0%, #1a1a3a 50%, #0f0f23 100%);
color: #ffffff;
}
.sidebar {
width: 200px;
background: linear-gradient(180deg, #1a1a3a 0%, #0f0f23 100%);
border-right: 1px solid #2a2a5a;
padding: 20px;
display: flex;
flex-direction: column;
align-items: center;
box-shadow: 0 0 20px rgba(0, 136, 255, 0.1);
}
.logo-section {
display: flex;
flex-direction: column;
align-items: center;
margin-bottom: 30px;
}
.car-animation {
position: relative;
margin-bottom: 15px;
}
.car-icon {
font-size: 48px;
color: #00d4ff;
text-shadow: 0 0 20px rgba(0, 212, 255, 0.8);
animation: pulse 2s ease-in-out infinite;
}
.glow-effect {
position: absolute;
top: 50%;
left: 50%;
transform: translate(-50%, -50%);
width: 80px;
height: 80px;
background: radial-gradient(circle, rgba(0, 212, 255, 0.3) 0%, transparent 70%);
border-radius: 50%;
animation: rotate 4s linear infinite;
}
@keyframes rotate {
from {
transform: translate(-50%, -50%) rotate(0deg);
}
to {
transform: translate(-50%, -50%) rotate(360deg);
}
}
.logo-text {
font-size: 22px;
font-weight: bold;
color: #ffffff;
margin-bottom: 5px;
text-shadow: 0 0 10px rgba(0, 212, 255, 0.5);
letter-spacing: 1px;
}
.logo-subtitle {
font-size: 13px;
color: #00d4ff;
opacity: 0.9;
margin-bottom: 15px;
font-weight: 300;
}
.status-indicator {
display: flex;
align-items: center;
gap: 8px;
margin-bottom: 20px;
}
.status-dot {
width: 8px;
height: 8px;
background: #00ff88;
border-radius: 50%;
animation: blink 2s ease-in-out infinite;
box-shadow: 0 0 5px rgba(0, 255, 136, 0.5);
}
@keyframes blink {
0%, 100% {
opacity: 1;
}
50% {
opacity: 0.3;
}
}
.status-text {
font-size: 11px;
color: #8a8aa5;
font-weight: 300;
}
.new-chat-button {
width: 100%;
margin-top: 10px;
background: linear-gradient(135deg, #00d4ff, #0066ff, #6600ff);
border: none;
color: white;
font-weight: 600;
border-radius: 25px;
padding: 12px 20px;
box-shadow: 0 4px 20px rgba(0, 212, 255, 0.4);
transition: all 0.3s cubic-bezier(0.4, 0, 0.2, 1);
position: relative;
overflow: hidden;
}
.new-chat-button::before {
content: '';
position: absolute;
top: 0;
left: -100%;
width: 100%;
height: 100%;
background: linear-gradient(90deg, transparent, rgba(255, 255, 255, 0.2), transparent);
transition: left 0.5s;
}
.new-chat-button:hover::before {
left: 100%;
}
.new-chat-button:hover {
transform: translateY(-3px) scale(1.02);
box-shadow: 0 8px 30px rgba(0, 212, 255, 0.6);
}
.button-text {
margin-left: 8px;
font-size: 14px;
}
.main-content {
flex: 1;
padding: 20px;
overflow-y: auto;
}
.chat-container {
display: flex;
flex-direction: column;
height: 100%;
max-width: 800px;
margin: 0 auto;
}
.message-list {
flex: 1;
overflow-y: auto;
padding: 25px;
border: 1px solid rgba(0, 212, 255, 0.2);
border-radius: 20px;
background: rgba(26, 26, 58, 0.3);
margin-bottom: 25px;
display: flex;
flex-direction: column;
backdrop-filter: blur(20px);
box-shadow:
0 8px 32px rgba(0, 0, 0, 0.3),
inset 0 1px 0 rgba(255, 255, 255, 0.1);
position: relative;
}
.message-list::after {
content: '';
position: absolute;
top: 0;
left: 0;
right: 0;
height: 1px;
background: linear-gradient(90deg, transparent, rgba(0, 212, 255, 0.5), transparent);
}
.message {
margin-bottom: 20px;
padding: 18px 22px;
border-radius: 18px;
display: flex;
align-items: flex-start;
box-shadow: 0 4px 20px rgba(0, 0, 0, 0.2);
transition: all 0.3s cubic-bezier(0.4, 0, 0.2, 1);
position: relative;
backdrop-filter: blur(10px);
border: 1px solid rgba(255, 255, 255, 0.1);
}
.message:hover {
transform: translateY(-2px);
box-shadow: 0 8px 30px rgba(0, 0, 0, 0.3);
}
.user-message {
max-width: 75%;
background: linear-gradient(135deg, #00d4ff 0%, #0066ff 50%, #6600ff 100%);
color: white;
align-self: flex-end;
flex-direction: row-reverse;
margin-left: auto;
border: 1px solid rgba(0, 212, 255, 0.3);
}
.bot-message {
max-width: 80%;
background: rgba(42, 42, 90, 0.6);
color: #ffffff;
align-self: flex-start;
border: 1px solid rgba(0, 212, 255, 0.2);
background-image:
linear-gradient(45deg, rgba(0, 212, 255, 0.05) 25%, transparent 25%),
linear-gradient(-45deg, rgba(0, 212, 255, 0.05) 25%, transparent 25%),
linear-gradient(45deg, transparent 75%, rgba(0, 212, 255, 0.05) 75%),
linear-gradient(-45deg, transparent 75%, rgba(0, 212, 255, 0.05) 75%);
background-size: 20px 20px;
background-position: 0 0, 0 10px, 10px -10px, -10px 0px;
}
.message-icon {
margin: 0 10px;
font-size: 1.2em;
color: #00d4ff;
}
.user-message .message-icon {
color: #ffffff;
}
.loading-dots {
padding-left: 5px;
}
.dot {
display: inline-block;
margin-left: 5px;
width: 8px;
height: 8px;
background-color: #00d4ff;
border-radius: 50%;
animation: pulse 1.2s infinite ease-in-out both;
box-shadow: 0 0 5px rgba(0, 212, 255, 0.5);
}
.dot:nth-child(2) {
animation-delay: -0.6s;
}
@keyframes pulse {
0%,
100% {
transform: scale(0.6);
opacity: 0.4;
}
50% {
transform: scale(1);
opacity: 1;
}
}
.input-container {
display: flex;
gap: 15px;
align-items: center;
padding: 20px;
background: rgba(26, 26, 58, 0.3);
border-radius: 25px;
backdrop-filter: blur(20px);
border: 1px solid rgba(0, 212, 255, 0.2);
box-shadow: 0 8px 32px rgba(0, 0, 0, 0.2);
}
.input-container .el-input {
flex: 1;
}
.input-container .el-input__inner {
background: rgba(42, 42, 90, 0.4);
border: 1px solid rgba(0, 212, 255, 0.3);
border-radius: 20px;
color: #ffffff;
padding: 15px 20px;
font-size: 15px;
transition: all 0.3s ease;
backdrop-filter: blur(10px);
}
.input-container .el-input__inner:focus {
border-color: #00d4ff;
box-shadow: 0 0 20px rgba(0, 212, 255, 0.3);
background: rgba(42, 42, 90, 0.6);
}
.input-container .el-input__inner::placeholder {
color: rgba(138, 138, 165, 0.7);
font-style: italic;
}
.input-container .el-button {
background: linear-gradient(135deg, #00d4ff, #0066ff, #6600ff);
border: none;
border-radius: 50%;
color: white;
font-weight: bold;
width: 50px;
height: 50px;
box-shadow: 0 4px 20px rgba(0, 212, 255, 0.4);
transition: all 0.3s cubic-bezier(0.4, 0, 0.2, 1);
position: relative;
overflow: hidden;
flex-shrink: 0;
}
.input-container .el-button::before {
content: '';
position: absolute;
top: 0;
left: -100%;
width: 100%;
height: 100%;
background: linear-gradient(90deg, transparent, rgba(255, 255, 255, 0.2), transparent);
transition: left 0.5s;
}
.input-container .el-button:hover::before {
left: 100%;
}
.input-container .el-button:hover {
transform: translateY(-2px) scale(1.05);
box-shadow: 0 8px 30px rgba(0, 212, 255, 0.6);
}
.input-container .el-button:active {
transform: translateY(0) scale(0.95);
}
/* 媒体查询,当设备宽度小于等于 768px 时应用以下样式 */
@media (max-width: 768px) {
.main-content {
padding: 10px 0 10px 0;
}
.app-layout {
flex-direction: column;
}
.sidebar {
width: 100%;
flex-direction: row;
justify-content: space-between;
align-items: center;
padding: 10px;
background: linear-gradient(90deg, #1a1a3a 0%, #0f0f23 100%);
}
.logo-section {
flex-direction: row;
align-items: center;
}
.car-icon {
font-size: 32px;
margin-right: 10px;
margin-bottom: 0;
}
.logo-text {
font-size: 18px;
margin-bottom: 0;
}
.logo-subtitle {
display: none;
}
.new-chat-button {
margin-right: 30px;
width: auto;
margin-top: 5px;
padding: 8px 16px;
font-size: 14px;
}
}
/* 媒体查询,当设备宽度大于 768px 时应用原来的样式 */
@media (min-width: 769px) {
.main-content {
padding: 0 0 10px 10px;
}
.app-layout {
display: flex;
height: 100vh;
}
.sidebar {
width: 200px;
background-color: #f4f4f9;
padding: 20px;
display: flex;
flex-direction: column;
align-items: center;
}
.logo-section {
display: flex;
flex-direction: column;
align-items: center;
}
.logo-text {
font-size: 18px;
font-weight: bold;
margin-top: 10px;
}
.new-chat-button {
width: 100%;
margin-top: 20px;
}
}
.message-list::-webkit-scrollbar {
width: 8px;
}
.message-list::-webkit-scrollbar-track {
background: rgba(42, 42, 90, 0.3);
border-radius: 4px;
}
.message-list::-webkit-scrollbar-thumb {
background: linear-gradient(45deg, #00d4ff, #0066ff);
border-radius: 4px;
}
.message-list::-webkit-scrollbar-thumb:hover {
background: linear-gradient(45deg, #0099cc, #0044cc);
}
/* 添加科技感边框动画 */
.message-list {
position: relative;
overflow: hidden;
}
.message-list::before {
content: '';
position: absolute;
top: -2px;
left: -2px;
right: -2px;
bottom: -2px;
background: linear-gradient(45deg, #00d4ff, #0066ff, #00d4ff);
border-radius: 15px;
opacity: 0.1;
z-index: -1;
animation: borderGlow 3s linear infinite;
}
@keyframes borderGlow {
0%, 100% {
opacity: 0.1;
}
50% {
opacity: 0.3;
}
}
/* 添加消息悬停效果 */
.message {
position: relative;
overflow: hidden;
}
.message::before {
content: '';
position: absolute;
top: 0;
left: -100%;
width: 100%;
height: 100%;
background: linear-gradient(90deg, transparent, rgba(255, 255, 255, 0.1), transparent);
transition: left 0.5s;
}
.message:hover::before {
left: 100%;
}
</style>
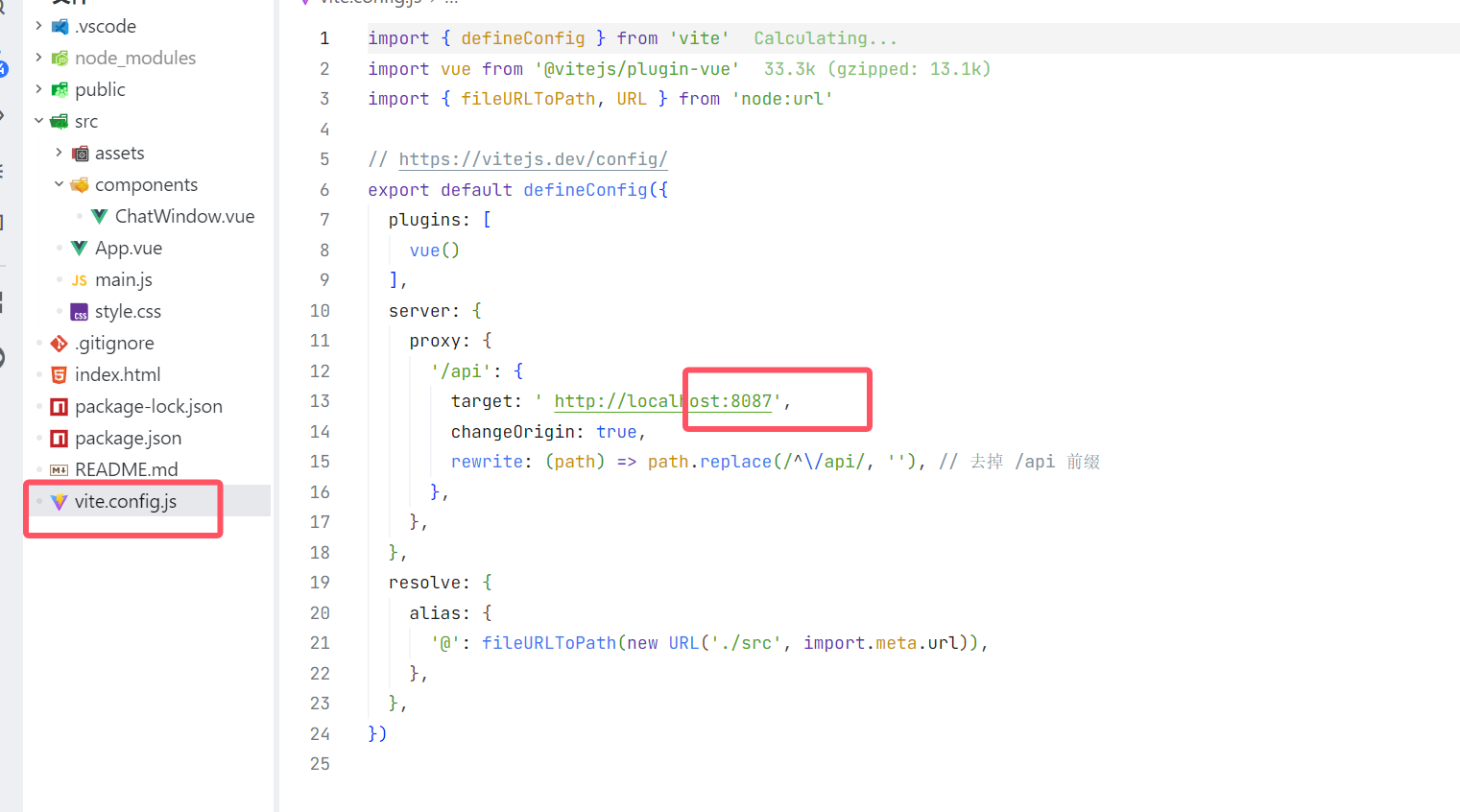
12.1、这个是你在后端的接口
创作不易,如果对你有帮助,不妨点赞收藏支持一下
更多推荐

 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)