
PaddleOCR MCP Server 实战:3步将OCR和文档解析轻松集成到 AI智能体
PaddleOCR MCP Server 是一个轻量级 Model Context Protocol (MCP) 服务,专为将 PaddleOCR 的文档理解能力无缝集成到文档AI智能体而设计,让AI智能体能够按需调用文字识别或文档解析工具,如下图所示,实现从图像/PDF中提取结构化信息:OCR:文字识别工具,从图像/PDF 提取高质量文本。PP-StructureV3:文档解析工具,从图像/PD
一,为什么文档 AI 智能体需要PaddleOCR MCP Server?
在构建面向报告分析、合同信息提取或科研论文总结等场景的文档 AI 智能体时,解析PDF格式文件及扫描版图像文档往往成为大语言模型(LLM)的痛点。这是因为LLM本质是语言模型,能处理字符序列,却无法直接解析图像或PDF文件的内容。
PaddleOCR MCP Server 将 PaddleOCR 的文字识别和文档解析能力,以MCP工具的形式提供给 AI 智能体,从而让 AI 智能体能够直接处理文档内容,而无需手动提取文本。
二,什么是PaddleOCR MCP Server?
PaddleOCR MCP Server 是一个轻量级 Model Context Protocol (MCP) 服务,专为将 PaddleOCR 的文档理解能力无缝集成到文档AI智能体而设计,让AI智能体能够按需调用文字识别或文档解析工具,如下图所示,实现从图像/PDF中提取结构化信息:
-
OCR:文字识别工具,从图像/PDF 提取高质量文本。
-
PP-StructureV3:文档解析工具,从图像/PDF中提取表格、标题、段落和公式等文档元素,并以Markdown/JSON格式输出。
视频链接:PaddleOCR MCP Server 实战:3步将OCR和文档解析轻松集成到 AI智能体 (qq.com)
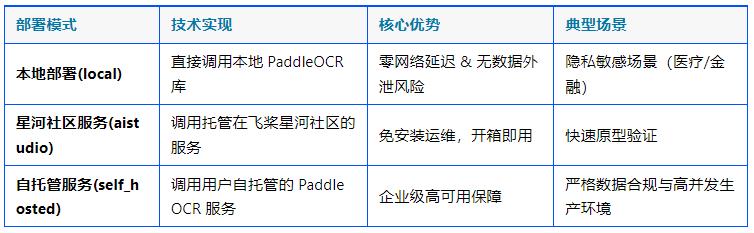
PaddleOCR MCP Server 提供三种部署模式,适配大多数智能体场景:
三,三步将 PaddleOCR MCP Server 集成到你的 AI 智能体
本节将以本地部署为例,介绍如何将 PaddleOCR 集成到你的智能体中。
步骤 1️⃣:安装 PaddleOCR MCP Server
# 创建并激活虚拟环境 (推荐)
conda create -n ocr-env python=3.11
conda activate ocr-env
# 安装PaddlePaddle GPU版本 (根据您的CUDA版本选择合适的版本)
pip install paddlepaddle-gpu==3.1.1 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/
python -c "import paddle; paddle.utils.run_check()" # 验证PaddlePaddle安装是否成功
# 安装PaddleOCR
pip install paddleocr[doc-parser]
# 安装PaddleOCR MCP Server
git clone https://github.com/PaddlePaddle/PaddleOCR.git
cd PaddleOCR
pip install -e mcp_server安装完毕后,运行以下命令,若出现下图所示的运行信息,则说明安装成功:
paddleocr_mcp --pipeline OCR --ppocr_source local --port 8234 --http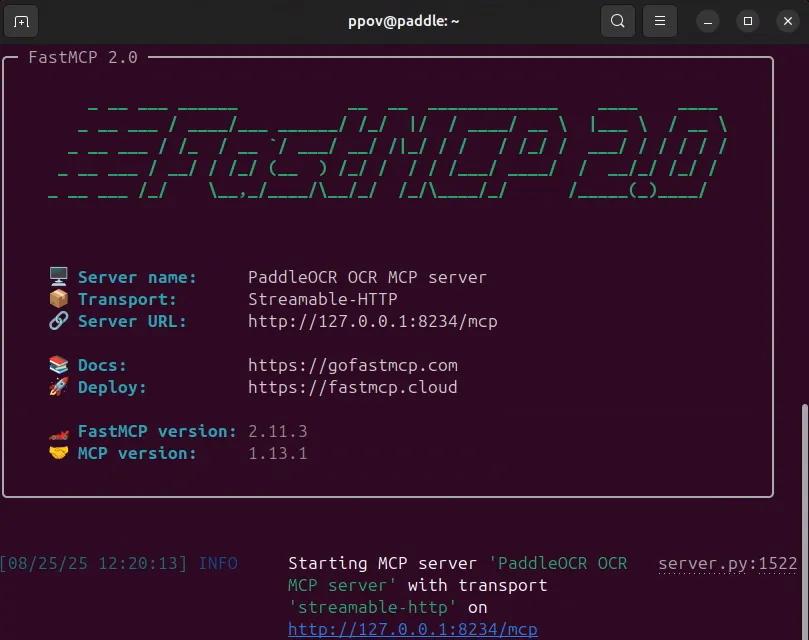
步骤 2️⃣:配置PaddleOCR MCP Server
首先,打开两个命令行窗口,分别运行以下命令,启动PaddleOCR MCP Server的OCR和PP-StructureV3服务:
# 启动PaddleOCR OCR MCP Server
paddleocr_mcp --pipeline OCR --ppocr_source local --port 8234 --http
# 启动PaddleOCR PP-StructureV3 MCP Server
paddleocr_mcp --pipeline PP-StructureV3 --ppocr_source local --port 9234 --http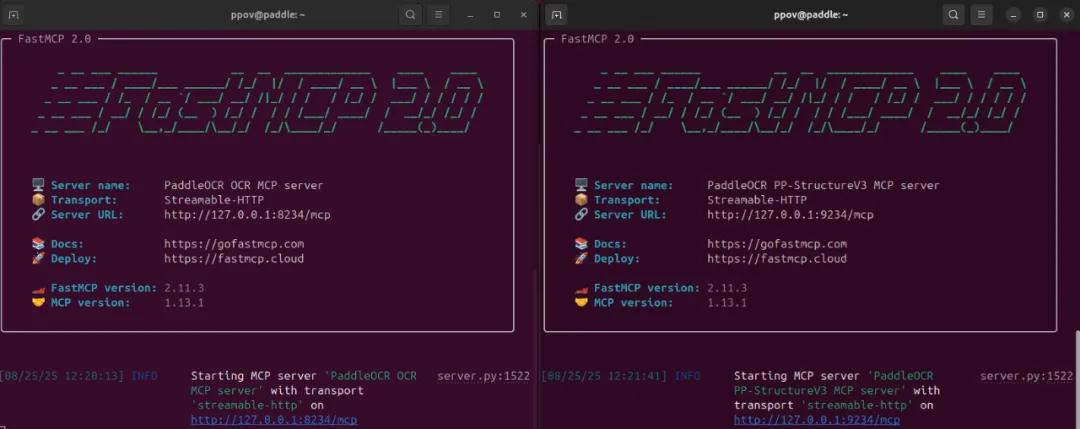
然后,在你的 AI 智能体 MCP 配置文件中(例如:mcp_settings.json)添加以下内容:
{
"mcpServers": {
"pp-ocrv5": {
"isActive": true,
"name": "PP-OCRv5 (local)",
"type": "streamableHttp",
"description": "Local PP-OCRv5 pipeline for text recognition.",
"tags": [],
"baseUrl": "http://127.0.0.1:8234/mcp"
},
"pp-structurev3": {
"isActive": true,
"name": "PP-StructureV3 (local)",
"type": "streamableHttp",
"description": "Local PP-StructureV3 pipeline for document parser.",
"tags": [],
"baseUrl": "http://127.0.0.1:9234/mcp"
}
}
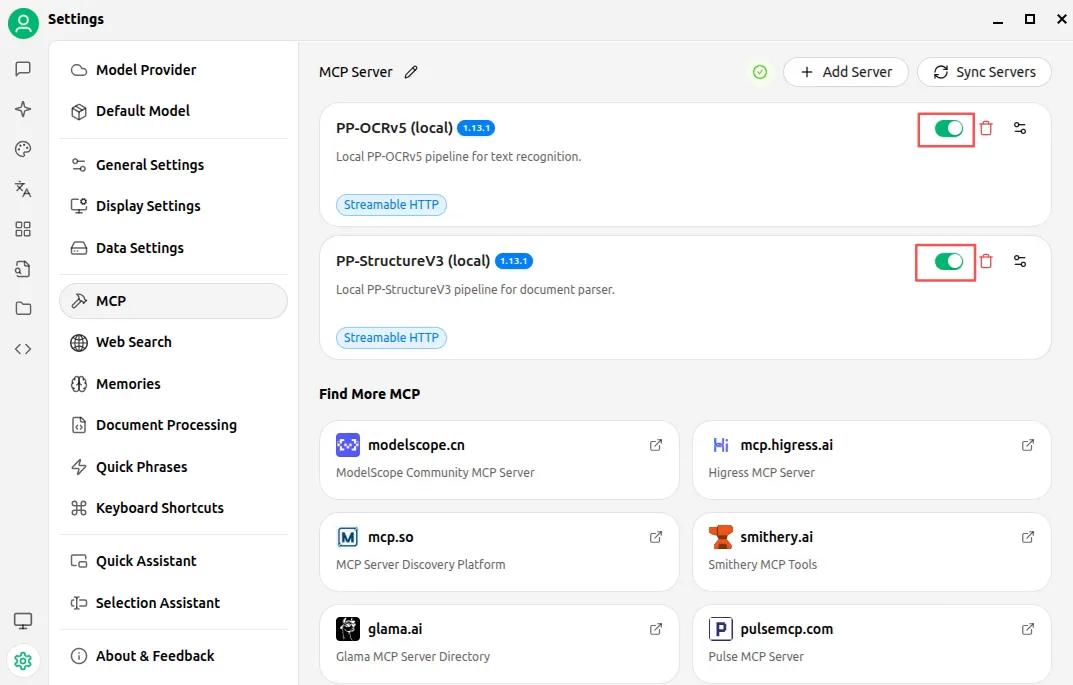
}以Cherry Studio为例,在Settings中选择 MCP,并把上述配置复制到JSON编辑框,然后点击OK按钮即可。
https://www.cherry-ai.com/
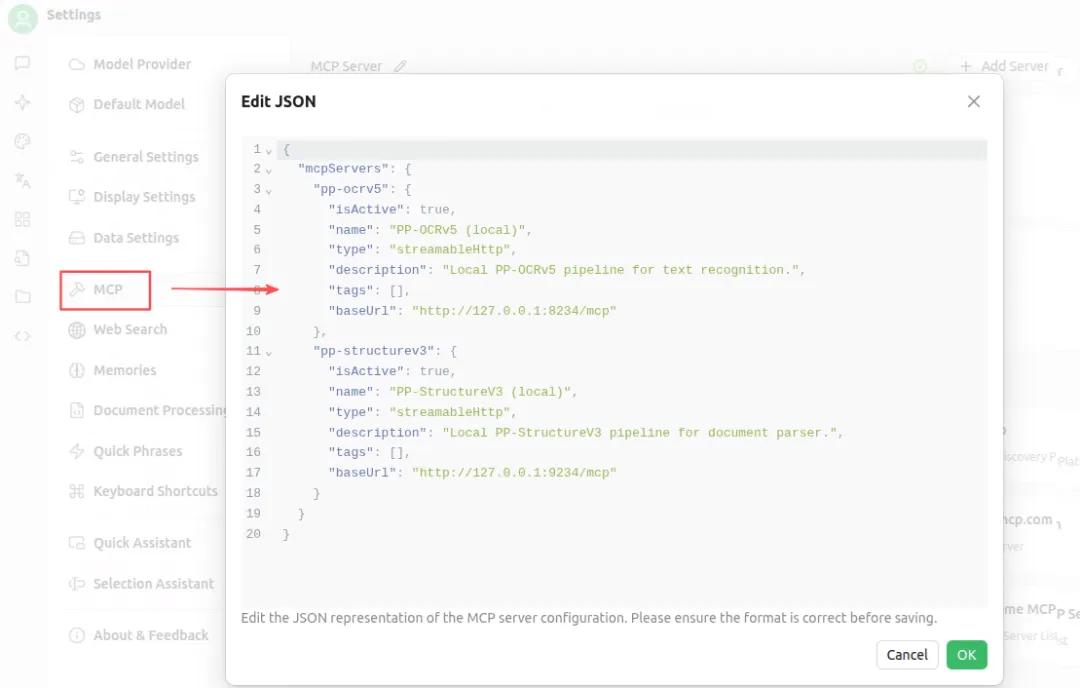
配置成功后,会有一个小绿点出现,如下图所示:
步骤 3️⃣:在智能体中调用PaddleOCR MCP Server的能力
当PaddleOCR MCP Server配置成功后,仅需要在智能体中使用具有function-call能力的大语言模型,即可调用 PaddleOCR MCP Server的工具。以Cherry Studio为例,在智能体中调用OCR工具的示例如下:
Prompt: What's in the picture: /home/ppov/Pictures/ocr_test.jpeg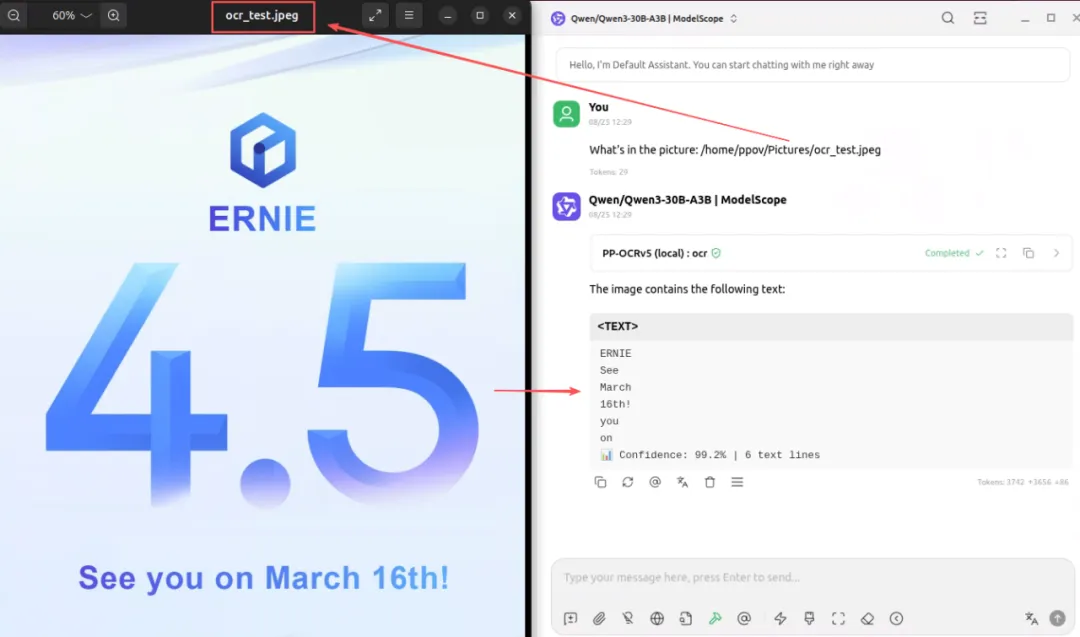
在智能体中调用PP-StructureV3工具的示例如下:
Prompt: Extract the table from:/home/ppov/Desktop/test_document.pdf, and output markdown format table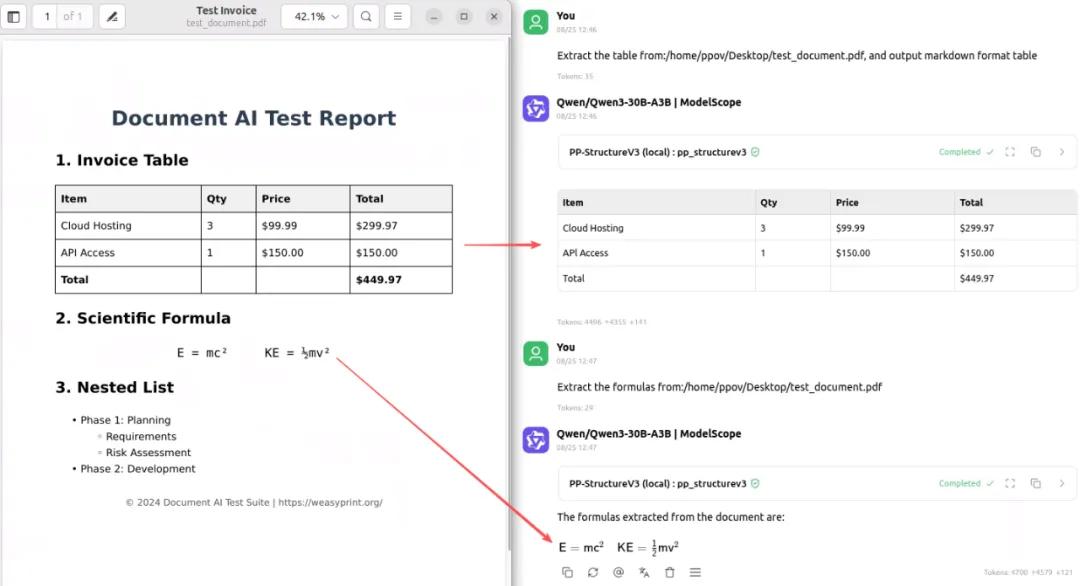
四,总结与展望
PaddleOCR MCP Server是 AI 智能体理解图片和PDF文档的桥梁。通过3 步将OCR和文档解析轻松集成到 AI 智能体 —— 相当于让AI智能体获得了“阅读”文档的能力,拓展了AI智能体的能力边界。
下一步与资源
📚 查阅完整文档:PaddleOCR官方文档
https://github.com/PaddlePaddle/PaddleOCR
🌐 PaddleOCR MCP Server部署指南
https://www.paddleocr.ai/latest/en/version3.x/deployment/mcp_server.html
如果你有更好的文章,欢迎投稿!
稿件接收邮箱:nami.liu@pasuntech.com
更多精彩内容请关注“算力魔方®”
更多推荐

 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)