
实战ELK与AI MCP:构建高可用的智能化日志可观测体系
通过本文的实践,我们成功构建了一套基于ELK的分布式日志解决方案,实现了日志的集中管理和高效查询。更进一步,我们探索了如何利用AI MCP将大语言模型的能力赋予系统可观测性,从传统的“手动检索”升级为“智能分析”,这无疑为我们日后的系统维护和故障排查工作提供了强大的助力。随着技术的发展,AI与运维(AIOps)的结合将越来越紧密,值得我们持续关注和学习。
引言
在现代微服务架构中,用户的单次请求往往会穿行于多个后台服务之间。当系统发生故障时,从海量且分散的日志中快速定位问题根源,是一项巨大的挑战。因此,建立一套集中式、可观测的日志系统对于保障业务稳定至关重要。本文将以一个典型的业务系统为例,分享如何整合ELK技术栈实现分布式日志的采集与查询,并进一步引入AI MCP,让我们能以自然语言的方式智能检索和分析系统日志。
ELK技术栈:日志处理的核心组件
ELK是三个开源项目的首字母缩写,它们协同工作,提供了一套功能完备的日志解决方案:
- E - Elasticsearch:基于Apache Lucene构建的分布式搜索和分析引擎。它的核心优势在于强大的全文检索能力和近实时的海量数据分析,是存储和索引日志数据的理想选择。
- L - Logstash:一个灵活的数据采集管道工具。Logstash可以从各种来源(如文件、TCP/UDP端口等)收集数据,通过过滤器进行转换和丰富,然后将其发送到指定的目的地,比如Elasticsearch。
- K - Kibana:数据可视化和探索平台。Kibana提供了一个友好的Web界面,让开发者可以直观地查询、分析和展示Elasticsearch中存储的数据。通过图表、地图和仪表盘,我们可以轻松洞察系统运行状态。
这三个组件的工作流程清晰明了:Logstash负责收集和预处理日志,Elasticsearch负责存储和索引,Kibana则负责将这些数据以直观的方式呈现给用户。
搭建ELK环境
我们采用Docker Compose来快速部署ELK环境,这种方式屏蔽了底层环境的复杂性,实现了“一次配置,随处运行”。
1. 部署脚本
在项目的dev-ops目录下,我们准备一个elk.yml文件。这个脚本会分别拉取Elasticsearch, Logstash和Kibana的镜像并启动容器。
# elk.yml - Docker Compose 配置文件
# ...此处省略具体的docker-compose配置细节...
# 关键是定义elasticsearch, logstash, kibana三个服务
# 并确保它们之间的网络互通以及端口映射正确
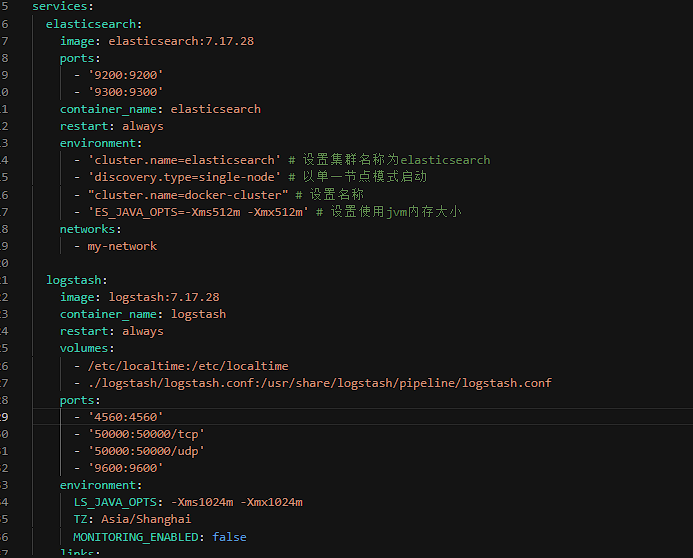
注意:执行docker-compose up -d命令前,请确保Docker环境已正确安装并运行。如果镜像拉取速度过慢,可以考虑配置国内的Docker镜像加速器。
2. 部署效果
部署成功后,通过Portainer或其他Docker管理工具,可以看到elasticsearch, kibana, logstash三个服务都处于正常运行状态。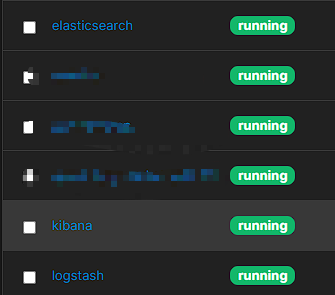
Spring Boot项目集成日志上报
环境就绪后,我们需要让业务系统的Spring Boot应用将日志上报到ELK中。
1. 添加Maven依赖
首先,在项目的pom.xml中引入logstash-logback-encoder,它是Logback与Logstash之间的桥梁。
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>7.3</version>
</dependency>
2. 实现全局Trace-ID
为了在分布式系统中追踪一次完整的请求链路,我们需要为每一条日志添加一个唯一的trace-id。通过MDC (Mapped Diagnostic Context)机制,我们可以轻松实现这一点。
@Component
public class TraceIdFilter extends OncePerRequestFilter {
private static final String TRACE_ID = "trace-id";
@Override
protected void doFilterInternal(@NotNull HttpServletRequest request, @NotNull HttpServletResponse response, FilterChain filterChain)
throws ServletException, IOException {
try {
// 为每个请求生成唯一的ID
String traceId = UUID.randomUUID().toString();
MDC.put(TRACE_ID, traceId);
filterChain.doFilter(request, response);
} finally {
// 请求结束后清理,防止内存泄漏
MDC.clear();
}
}
}
3. 配置Logstash地址
在application-dev.yml中指定Logstash服务地址。
# 日志;logstash部署的服务器IP
logstash:
host: 127.0.0.1
4. 配置Logback
最后,修改logback-spring.xml文件,增加一个指向Logstash的appender。
<springProperty name="LOG_STASH_HOST" scope="context" source="logstash.host" defaultValue="127.0.0.1"/>
<appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<destination>${LOG_STASH_HOST}:4560</destination>
<encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder"/>
</appender>
<root level="info">
<appender-ref ref="CONSOLE"/>
<appender-ref ref="ASYNC_FILE_INFO"/>
<appender-ref ref="ASYNC_FILE_ERROR"/>
<appender-ref ref="LOGSTASH"/>
</root>
至此,应用的日志就会在打印到控制台和文件的同时,被异步发送到Logstash。
验证日志采集与查询
配置完成后,启动业务项目并调用几个接口,以产生一些业务日志。
1. 检查索引
访问Kibana的开发工具(Dev Tools)界面 http://127.0.0.1:5601/app/dev_tools#/console,执行以下命令,可以看到Logstash已经为我们创建了新的索引。
GET _cat/indices
2. 创建索引模式
进入Kibana的管理(Management)界面,创建索引模式(Index Pattern),名称使用通配符 business-system-log-*,这样就可以匹配到所有按天生成的日志索引。
3. 查看日志
最后,在Kibana的Discover界面 http://127.0.0.1:5601/app/discover,选择刚刚创建的索引模式,就可以看到应用上报的日志了。你可以通过筛选trace-id来查看一次完整的请求链路日志。
引入AI MCP:实现日志的智能分析
虽然Kibana的查询功能很强大,但仍需要我们手动构建查询语句。AI MCP(Model Context Protocol)提供了一种新的可能性:通过AI大模型,用自然语言来查询和操作数据。
这里我们使用一个支持Elasticsearch的MCP服务,将其接入AI客户端(如Claude、Cursor等)。
1. 客户端配置
在AI客户端的配置文件中,添加一个MCP服务指向我们的Elasticsearch实例。
{
"mcpServers": {
"elasticsearch-mcp-server": {
"command": "npx",
"args": [
"-y",
"@elastic/mcp-server-elasticsearch"
],
"env": {
"ES_URL": "http://127.0.0.1:9200",
"ES_API_KEY": "your-api-key"
}
}
}
}
注意如果docker-compose中es没有设置密码这里可以不用填写apikey
2. 自然语言查询
配置重启后,我们就可以在AI对话框中直接提问了。例如,我们可以提出一个复杂的分析请求:
提问: “帮我找出所有触发了限流的用户,并将这些用户的ID写入到桌面上的
rate_limit_users.txt文件中。”
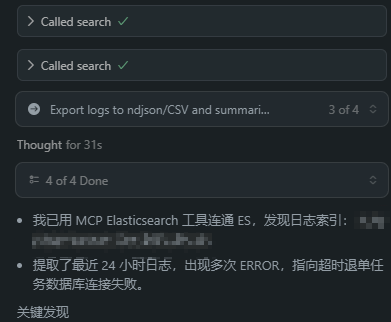
AI模型会理解这个意图,通过MCP调用Elasticsearch查询相关日志,然后调用文件系统工具将结果写入文件。
这种方式极大地降低了日志分析的门槛,使得非专业人员也能快速从日志中获取有效信息。
总结
通过本文的实践,我们成功构建了一套基于ELK的分布式日志解决方案,实现了日志的集中管理和高效查询。更进一步,我们探索了如何利用AI MCP将大语言模型的能力赋予系统可观测性,从传统的“手动检索”升级为“智能分析”,这无疑为我们日后的系统维护和故障排查工作提供了强大的助力。随着技术的发展,AI与运维(AIOps)的结合将越来越紧密,值得我们持续关注和学习。
更多推荐
 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)