
大模型八股文的重要性
本文系统介绍了大模型技术及其应用。首先阐述了大模型的定义、特点及与传统模型的区别,重点分析了基于Transformer的架构及其核心组件。随后详细讲解了Transformer模型的技术原理,包括自注意力机制、多头注意力等关键技术。文章还探讨了大模型在自然语言处理中的应用场景,如机器翻译、文本摘要等,并提供了评估指标和优化方法。最后分享了实际开发经验,包括数据处理、模型训练等关键环节,以及应对大模型
在当今科技飞速发展的时代,大模型领域无疑是最热门的话题之一。随着 ChatGPT 等大语言模型的爆火,大模型技术掀起了一场席卷全球的 AI 风暴,其应用场景不断拓展,从智能客服、内容创作到医疗、金融等各个领域,都能看到大模型的身影。这一技术的崛起,不仅改变了人们的生活和工作方式,也为众多求职者带来了前所未有的机遇。
大模型领域的火热,使得相关岗位的竞争异常激烈。各大企业纷纷加大在大模型领域的投入,高薪招聘专业人才 ,以抢占技术高地。据相关数据显示,大模型相关岗位的薪资水平普遍较高,一些资深的大模型算法工程师甚至能拿到百万年薪 ,这无疑吸引了大量求职者的目光。然而,想要在众多竞争者中脱颖而出,并非易事。面试,作为进入大模型领域的关键门槛,让许多求职者望而却步。
在大模型面试中,八股文扮演着至关重要的角色。所谓八股文,并非是传统意义上的刻板文章,而是指那些在面试中经常被问到的、具有一定固定模式和套路的问题及答案。这些问题涵盖了大模型的基础知识、技术原理、应用场景、项目经验等多个方面,是面试官了解求职者专业能力的重要途径。掌握大模型面试八股文,对于求职者来说,就像是拿到了一把打开大模型领域大门的钥匙。它可以帮助求职者快速梳理知识体系,明确面试重点,提高面试的成功率。
干货满满,建议先赞后看,随时回查不迷路。更多开发 学习资料/视频/面试题库 请戳>>Github<< >>gitee<<

大模型基础概念问答
什么是大模型
大模型,即大规模机器学习模型,是指具有大规模参数和复杂计算结构的机器学习模型 ,通常基于深度学习技术构建。这些模型拥有数十亿甚至数千亿个参数,通过训练海量数据来学习复杂的模式和特征,具有强大的表达能力和泛化能力,可以对未见过的数据做出准确的预测,能够处理更加复杂的任务和数据,在自然语言处理、计算机视觉、语音识别和推荐系统等各种领域都有广泛的应用 。
大模型与传统模型相比,主要有以下几个方面的区别:
- 参数规模:传统模型的参数规模相对较小,可能只有几十万到几百万个参数,而大模型的参数规模通常在数十亿甚至数千亿以上 。例如,GPT-3 就拥有 1750 亿个参数,这使得大模型能够学习到更复杂的模式和知识。
- 结构复杂度:大模型的结构通常更为复杂,包含更多的层和组件,以处理海量数据和复杂任务。像 Transformer 架构,其包含了多头自注意力机制、前馈神经网络等多个复杂组件,相比传统的神经网络结构,能够更好地捕捉数据中的长距离依赖关系。
- 任务处理能力:传统模型往往针对特定的任务进行设计和训练,泛化能力较弱;而大模型具有更强的通用性和泛化能力,通过预训练和微调的方式,可以在多种不同的任务中表现出色 。以 GPT-4 为例,它不仅可以完成文本生成、翻译、问答等自然语言处理任务,还能在一定程度上理解和处理图像、代码等多模态数据。
- 资源需求:训练大模型需要大量的计算资源和数据,通常需要使用高性能的 GPU 集群进行训练,训练时间也可能长达数周甚至数月。而传统模型的训练相对来说对资源的需求较低,可能在普通的服务器甚至个人电脑上就可以完成训练。
主流开源模型体系
- Transformer 体系:Transformer 是一种基于注意力机制的深度学习架构,最初是为了解决自然语言处理中的机器翻译任务而提出的,但现在已经广泛应用于各种序列处理任务中。它的核心是多头自注意力机制,能够让模型在处理序列数据时,同时关注不同位置的信息,从而更好地捕捉长距离依赖关系 。Transformer 体系的优点是并行计算能力强,能够大大缩短训练时间;缺点是计算资源消耗大,对硬件要求较高。目前基于 Transformer 体系的模型有很多,如 GPT、BERT 等,这些模型在自然语言处理领域取得了巨大的成功。
- PyTorch Lightning:PyTorch Lightning 是一个基于 PyTorch 的轻量级深度学习框架,它将深度学习的训练过程进行了高度抽象,使得开发者可以更专注于模型的设计和业务逻辑,而无需过多关注底层的训练细节 。PyTorch Lightning 的优点是简单易用,能够快速搭建和训练模型;同时它还支持分布式训练,能够充分利用多 GPU 环境加速训练过程。此外,PyTorch Lightning 还提供了丰富的回调函数和日志记录功能,方便开发者进行模型的监控和调试。
- TensorFlow Model Garden:TensorFlow Model Garden 是 TensorFlow 官方提供的一个模型库,包含了各种预训练模型和模型实现代码,涵盖了计算机视觉、自然语言处理、音频处理等多个领域 。使用 TensorFlow Model Garden,开发者可以快速获取和使用这些预训练模型,进行模型的微调或迁移学习,从而加速项目的开发进程。其优点是模型种类丰富,官方支持度高;缺点是对 TensorFlow 框架的依赖较强,灵活性相对较低。
- Hugging Face Transformers:Hugging Face Transformers 是一个专门用于自然语言处理的开源库,提供了大量的预训练模型,如 BERT、GPT、RoBERTa 等,同时还包含了一系列工具和接口,方便开发者进行模型的加载、训练、评估和部署 。Hugging Face Transformers 的优点是模型生态丰富,支持多种深度学习框架(如 PyTorch 和 TensorFlow);提供的工具和接口简单易用,能够大大降低自然语言处理任务的开发门槛。此外,Hugging Face 还提供了一个在线平台,方便开发者共享和管理模型。
|
开源模型体系 |
特点 |
应用场景 |
|
Transformer 体系 |
基于注意力机制,并行计算能力强,能捕捉长距离依赖关系 |
自然语言处理、计算机视觉等各种序列处理任务 |
|
PyTorch Lightning |
轻量级,基于 PyTorch,高度抽象训练过程,支持分布式训练 |
深度学习模型的快速开发和训练 |
|
TensorFlow Model Garden |
TensorFlow 官方模型库,模型种类丰富 |
计算机视觉、自然语言处理、音频处理等领域的模型开发和迁移学习 |
|
Hugging Face Transformers |
专注自然语言处理,模型生态丰富,支持多框架 |
自然语言处理任务,如文本分类、问答系统、文本生成等 |
大模型架构
大模型通常采用基于 Transformer 的架构,这种架构摒弃了传统的循环神经网络(RNN)和卷积神经网络(CNN),完全基于注意力机制构建,在自然语言处理和计算机视觉等领域取得了显著的成果。Transformer 架构主要由编码器(Encoder)、解码器(Decoder)、多头自注意力机制(Multi-Head Self-Attention)和前馈神经网络(Feed Forward Network)等部分组成 。
编码器的作用是对输入序列进行特征提取,它由多个相同的层堆叠而成,每个层包含多头自注意力机制和前馈神经网络。输入序列首先通过嵌入层(Embedding Layer)转换为向量表示,然后加入位置编码(Positional Encoding)以保留序列中的位置信息,接着向量流经编码器的各个层。在多头自注意力机制中,模型会计算输入序列中各个位置之间的相关性,从而让每个位置都能关注到其他位置的信息,更好地捕捉序列中的依赖关系。前馈神经网络则对每个位置独立应用,进一步提取特征。
解码器的主要功能是根据编码器的输出和已生成的部分输出,生成最终的输出序列。它同样由多个相同的层堆叠而成,每个层除了包含多头自注意力机制和前馈神经网络外,还多了一个用于关注编码器输出的多头注意力机制(Encoder-Decoder Attention)。解码器接收移位的输出序列的嵌入表示和位置编码,在生成输出时,通过掩码自注意力机制(Masked Multi-Head Attention)防止当前位置看到未来位置的信息,然后结合编码器的输出,逐步生成完整的输出序列。
多头自注意力机制是 Transformer 架构的核心,它通过多个头并行计算注意力,能够让模型在不同的表示空间中学习到信息,增强了模型的表达能力。具体来说,多头自注意力机制将输入向量分别映射到多个不同的线性空间中,得到多个查询(Query)、键(Key)和值(Value)向量,然后分别计算每个头的注意力分数,并将结果拼接起来,最后通过一个线性变换得到最终的输出。
前馈神经网络则是对自注意力机制的输出进行进一步的处理,它由两个线性层和一个非线性激活函数(如 ReLU)组成。前馈神经网络的作用是对每个位置的特征进行独立的变换,从而进一步提取特征,增强模型的表达能力 。
Transformer 架构图如下:
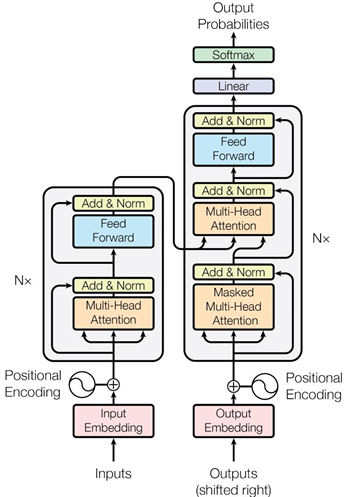
大模型技术原理与应用
Transformer 模型
Transformer 是一种基于注意力机制的深度学习架构,由谷歌于 2017 年在论文《Attention Is All You Need》中提出 ,最初用于机器翻译任务,如今已广泛应用于自然语言处理、计算机视觉等多个领域,成为大模型的核心架构。
Transformer 的基本结构主要由编码器(Encoder)和解码器(Decoder)两大部分组成 。编码器负责对输入序列进行编码,提取特征;解码器则根据编码器的输出和已生成的部分输出,生成最终的输出序列。在编码器和解码器中,都包含了多头自注意力机制(Multi-Head Self-Attention)和前馈神经网络(Feed Forward Network)等关键组件。
自注意力机制是 Transformer 的核心创新点之一,它允许模型在处理序列数据时,动态地关注输入序列中不同位置的信息,从而更好地捕捉长距离依赖关系 。以句子 “我喜欢苹果,因为它很美味” 为例,当模型处理 “它” 这个词时,通过自注意力机制,能够计算出 “它” 与 “苹果” 之间的高相关性,从而准确理解 “它” 指代的是 “苹果”。自注意力机制的工作方式如下:
- 生成查询、键和值向量:将输入序列分别通过三个不同的线性变换,生成查询(Query)、键(Key)和值(Value)向量。
- 计算注意力分数:通过点积运算计算查询向量与键向量之间的相似度,得到注意力分数。公式为\(Attention(Q,K,V)=softmax( \frac{QK^T}{\sqrt{d_k}} )V\),其中\(Q\)为查询向量,\(K\)为键向量,\(V\)为值向量,\(d_k\)是键向量的维度,\(\sqrt{d_k}\)用于缩放点积,防止梯度消失 。
- 归一化和加权求和:使用 Softmax 函数对注意力分数进行归一化,将其转换为概率分布,表示每个位置对其他位置的关注程度。然后,将归一化后的注意力分数与值向量进行加权求和,得到自注意力机制的输出。
多头自注意力机制则是在自注意力机制的基础上,通过多个头并行计算注意力,进一步增强模型的表达能力 。每个头可以学习到不同的语义信息,从不同角度捕捉序列中的依赖关系,然后将多个头的输出拼接起来,通过线性变换得到最终的输出。
由于 Transformer 是并行处理输入序列的,本身没有顺序信息,因此需要引入位置编码来给模型注入位置信息,帮助模型更好地理解序列的结构和语义 。位置编码的维度和嵌入的维度一样,常见的实现方式是正弦余弦位置编码。对于偶数维度(2i),使用正弦函数:\(PE(pos,2i)=sin(\frac{pos}{10000^{2i/dmodel}})\);对于奇数维度(2i+1),使用余弦函数:\(PE(pos,2i+1)=cos(\frac{pos}{10000^{2i/dmodel}})\),其中,pos 表示词在序列中的位置,i 表示当前维度,dmodel 是嵌入向量的维度 。这样设计的位置编码能够让模型捕捉到序列中词语之间的相对和绝对位置信息。
大模型在自然语言处理中的应用
大模型在自然语言处理领域取得了显著的成果,为各种自然语言处理任务带来了质的飞跃。以下是大模型在自然语言处理中的一些常见应用案例:
- 机器翻译:大模型在机器翻译任务中表现出色,能够实现多种语言之间的高质量翻译。以谷歌的神经机器翻译系统为例,它基于 Transformer 架构,通过在大规模的平行语料库上进行训练,能够学习到不同语言之间的语义和语法对应关系,从而准确地将一种语言翻译成另一种语言 。例如,将英文句子 “The quick brown fox jumps over the lazy dog” 翻译成中文,大模型可以准确地输出 “敏捷的棕色狐狸跳过了懒惰的狗”,翻译结果自然流畅,语义准确。
- 文本摘要:大模型可以根据给定的长篇文本,自动生成简洁、准确的摘要。如 BART 模型,它能够理解文本的核心内容,提取关键信息,并将其整合为精炼的摘要 。在处理新闻报道时,大模型可以快速生成包含事件主要内容、时间、地点等关键信息的简短摘要,帮助用户快速了解新闻的要点。
- 问答系统:大模型在问答系统中发挥着重要作用,能够理解用户的问题,并从大量的文本数据中检索和生成准确的答案。像 OpenAI 的 GPT 系列模型,在经过大量的训练后,能够回答各种领域的问题,包括历史、科学、技术等 。当用户提问 “谁发明了电灯?” 时,大模型可以迅速给出答案 “托马斯・阿尔瓦・爱迪生发明了电灯”。
- 文本生成:大模型具备强大的文本生成能力,可以生成连贯、富有逻辑的文本,如文章、故事、诗歌等。以 GPT-3 为例,它能够根据用户输入的提示,生成高质量的文本内容 。给定提示 “写一篇关于春天的散文”,GPT-3 可以生成一篇描绘春天美景、充满诗意的散文,语言优美,内容丰富。
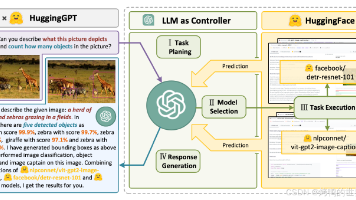
大模型在自然语言处理中的应用流程图如下:

大模型在自然语言处理中的应用,不仅提高了任务的准确性和效率,还为人们的生活和工作带来了极大的便利。通过理解和生成自然语言,大模型能够实现智能客服、智能写作助手、信息检索等多种应用,推动自然语言处理技术向更加智能化、人性化的方向发展。
大模型性能与优化
评估指标
在大模型的训练和应用过程中,需要一系列科学合理的评估指标来衡量模型的性能表现。这些指标不仅能够帮助我们了解模型的优势和不足,还能为模型的优化和改进提供方向。常见的评估指标包括准确率、召回率、F1 值等,这些指标在分类任务中应用广泛 。
准确率(Accuracy)是指模型预测正确的样本数占总样本数的比例,反映了模型预测的准确性。公式为\(Accuracy = \frac{TP + TN}{TP + TN + FP + FN}\),其中\(TP\)(True Positive)表示真正例,即实际为正类且被模型预测为正类的样本数;\(TN\)(True Negative)表示真反例,即实际为反类且被模型预测为反类的样本数;\(FP\)(False Positive)表示假正例,即实际为反类但被模型预测为正类的样本数;\(FN\)(False Negative)表示假反例,即实际为正类但被模型预测为反类的样本数 。例如,在一个图像分类任务中,共有 100 张图片,其中猫的图片有 60 张,狗的图片有 40 张,模型正确预测出了 50 张猫的图片和 30 张狗的图片,那么准确率为\((50 + 30) / 100 = 80\%\)。
召回率(Recall)也称为查全率,是指被正确预测为正类的样本数占实际正类样本数的比例,衡量了模型对正类样本的覆盖程度 。公式为\(Recall = \frac{TP}{TP + FN}\)。继续以上述图像分类任务为例,召回率为\(50 / 60 \approx 83.3\%\),表示模型在实际的 60 张猫的图片中,成功召回了 50 张。
F1 值(F1-Score)则是综合考虑了准确率和召回率的指标,它是准确率和召回率的调和平均数,能够更全面地反映模型的性能 。公式为\(F1 = \frac{2 \times Precision \times Recall}{Precision + Recall}\),其中\(Precision\)(精确率)即\(Precision = \frac{TP}{TP + FP}\)。F1 值越高,说明模型在准确率和召回率方面的表现越平衡。在上述例子中,精确率为\(50 / (50 + 10) \approx 83.3\%\),F1 值为\(2 \times 0.833 \times 0.833 / (0.833 + 0.833) \approx 83.3\%\)。
对于文本生成任务,除了上述指标外,还需要关注一些特定的指标,如流畅性、多样性和相关性等 。流畅性是指生成的文本在语言表达上是否自然、连贯,符合语法和语义规则。可以通过人工阅读或使用语言模型计算生成文本的困惑度(Perplexity)来评估,困惑度越低,说明文本越流畅。例如,对于句子 “我去商店买了苹果和香蕉”,语言模型计算出的困惑度较低,表明该句子流畅自然;而 “我去商店买了天空和星星”,困惑度会较高,因为不符合常理,不流畅。
多样性用于衡量生成文本的丰富程度,避免生成内容的重复和单调。可以通过计算生成文本中不同 n-gram 的数量或使用基于熵的方法来评估。例如,在生成故事时,如果模型总是生成类似 “从前有个小孩,他出去玩,然后回家了” 这样单调的内容,多样性就较低;而如果能生成丰富多彩、情节各异的故事,如 “从前有个勇敢的探险家,他踏上了神秘的岛屿,在那里遇到了会说话的动物,一起解开了古老的谜团”,则说明多样性较高。
相关性是指生成的文本与给定的主题或上下文是否紧密相关 。可以通过人工判断或使用语义匹配算法来评估,如计算生成文本与参考文本之间的余弦相似度等。例如,给定主题 “介绍人工智能的发展”,生成的文本 “人工智能在近年来取得了飞速的发展,从图像识别到自然语言处理,应用领域不断拓展”,与主题相关性高;而如果生成的是 “今天的天气真好,适合出去游玩”,则与主题完全不相关。
优化方法
为了提高大模型的性能和效率,需要从多个方面进行优化,包括模型结构优化、训练过程优化和模型压缩等。
在模型结构优化方面,不断探索和改进模型的架构是提升性能的关键。例如,Transformer 架构的提出,通过引入多头自注意力机制,有效地解决了传统循环神经网络(RNN)在处理长序列时的梯度消失和梯度爆炸问题,大大提高了模型对长距离依赖关系的捕捉能力 。在此基础上,许多研究对 Transformer 架构进行了进一步的改进和扩展。如 ALBERT(A Lite BERT)通过参数共享和因式分解等技术,在不降低性能的前提下减少了模型的参数数量,提高了训练效率;ELECTRA(Efficiently Learning an Encoder that Classifies Token Replacements Accurately)采用了生成对抗网络(GAN)的思想,通过判别器来预测输入 token 是否被替换,从而提高了模型的训练效率和性能 。
训练过程优化也是提高大模型性能的重要环节。优化算法的选择对训练速度和模型收敛性有着重要影响 。随机梯度下降(SGD)及其变种 Adagrad、Adadelta、Adam 等是常用的优化算法。其中,Adam 算法结合了 Adagrad 和 Adadelta 的优点,能够自适应地调整学习率,在大模型训练中表现出较好的性能。此外,合理设置超参数,如学习率、批次大小(batch size)等,也能显著影响训练效果 。学习率过大可能导致模型无法收敛,过小则会使训练速度过慢;批次大小的选择则需要在内存占用和训练效率之间进行权衡。例如,在训练图像识别大模型时,通过实验对比不同的学习率和批次大小,发现当学习率设置为 0.001,批次大小为 64 时,模型的训练效果最佳,收敛速度快且准确率高。
为了使模型能够学习到更丰富的语义信息,数据增强技术也被广泛应用 。在自然语言处理中,可以通过同义词替换、句子重组、随机插入或删除单词等方式对文本数据进行增强;在计算机视觉中,常用的方法包括图像旋转、缩放、裁剪、翻转等。例如,在训练图像分类模型时,对原始图像进行随机旋转和缩放,生成更多不同角度和尺寸的图像,能够增加训练数据的多样性,提高模型的泛化能力。
模型压缩是在不显著降低模型性能的前提下,减少模型的大小和计算量,提高模型的部署效率和运行速度 。常见的模型压缩方法包括剪枝、量化和知识蒸馏等。剪枝是通过去除模型中不重要的连接或神经元,减少模型的参数数量,从而降低模型的复杂度 。量化则是将模型中的参数和计算从高精度数据类型转换为低精度数据类型,如将 32 位浮点数转换为 8 位整数,以减少内存占用和计算量 。知识蒸馏是将一个大的教师模型的知识传递给一个小的学生模型,让学生模型学习教师模型的输出分布,从而在较小的模型规模下达到接近教师模型的性能 。例如,将一个拥有大量参数的 GPT-3 模型作为教师模型,通过知识蒸馏的方法,将其知识传授给一个参数规模较小的模型,使得小模型在保持一定性能的同时,计算成本大幅降低。
通过上述优化方法的综合应用,可以显著提高大模型的性能和效率,使其在实际应用中能够更好地发挥作用。在未来的研究中,随着技术的不断发展,相信会有更多更有效的优化方法出现,推动大模型技术不断向前发展。
大模型实际开发与应用案例
开发经验分享
在参与大模型开发项目的过程中,我积累了许多宝贵的经验,也遇到了不少挑战。以一个基于 Transformer 架构的自然语言处理大模型开发项目为例,我们的目标是构建一个能够实现多语言翻译、文本摘要和问答系统等多种任务的通用大模型 。
在项目的初期,数据收集和预处理是关键的一步。我们从互联网上收集了大量的多语言文本数据,包括新闻、小说、学术论文等,数据量达到了数 TB 级别 。然而,原始数据中存在着许多噪声和错误,如乱码、重复数据、格式不一致等问题,这给数据预处理带来了很大的困难。为了解决这些问题,我们采用了一系列的数据清洗和预处理技术,包括使用正则表达式去除乱码和特殊字符,通过查重算法去除重复数据,对文本进行统一的格式转换等 。同时,为了提高数据的质量,我们还引入了人工标注和审核的环节,对重要的数据进行人工校对和标注,确保数据的准确性和一致性。
在模型训练阶段,由于模型的参数规模巨大,计算资源的消耗成为了一个突出的问题 。我们使用了多台配备高性能 GPU 的服务器组成集群进行分布式训练,但训练过程中仍然遇到了内存不足、训练速度慢等问题。为了解决内存不足的问题,我们采用了模型并行和数据并行相结合的策略,将模型的不同部分分布在不同的 GPU 上进行计算,同时将数据分成多个批次在不同的 GPU 上并行处理,有效地减少了单个 GPU 的内存压力 。针对训练速度慢的问题,我们对优化算法进行了调整,采用了 AdamW 优化器,并结合学习率预热和余弦退火策略,使得模型在训练初期能够快速收敛,后期能够稳定地优化参数 。此外,我们还通过数据增强技术,如随机替换单词、句子重组等方式,增加了训练数据的多样性,提高了模型的泛化能力。
在模型评估和调优阶段,我们使用了多种评估指标对模型的性能进行了全面的评估,包括 BLEU 指标用于评估机器翻译的准确性,ROUGE 指标用于评估文本摘要的质量,F1 值用于评估问答系统的性能等 。根据评估结果,我们发现模型在某些任务上的表现并不理想,如在处理长文本时,模型的翻译准确性和摘要质量会明显下降。为了解决这些问题,我们对模型的架构进行了改进,引入了长短期记忆网络(LSTM)和注意力机制的变体,以增强模型对长距离依赖关系的捕捉能力 。同时,我们还对模型的超参数进行了精细的调优,通过网格搜索和随机搜索等方法,寻找最优的超参数组合,进一步提升了模型的性能。
经过几个月的努力,我们的大模型终于开发完成,并在多个自然语言处理任务上取得了优异的成绩 。在机器翻译任务中,模型的 BLEU 得分达到了行业领先水平,能够实现高质量的多语言翻译;在文本摘要任务中,生成的摘要简洁明了,能够准确地概括原文的核心内容;在问答系统中,模型能够准确地回答各种问题,F1 值超过了 90% 。通过这个项目,我深刻地认识到了大模型开发的复杂性和挑战性,也积累了丰富的经验,这些经验将对我未来的工作产生重要的影响。
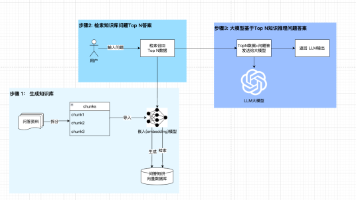
项目开发流程框架图如下:
实际应用案例分析
以某电商公司的智能客服系统为例,该系统基于大模型技术进行开发,旨在提高客户服务的效率和质量,降低人工成本 。
在项目背景方面,随着电商业务的快速发展,该公司每天接到的客户咨询量日益增多,传统的人工客服已经难以满足客户的需求,客户等待时间长、问题解决效率低等问题逐渐凸显 。因此,公司决定开发一套智能客服系统,利用大模型的自然语言处理能力,实现客户问题的自动解答和处理。
项目的目标是构建一个能够理解客户问题、提供准确答案,并能与客户进行自然交互的智能客服系统 。该系统需要具备多轮对话能力,能够处理复杂的业务场景和客户需求,同时要保证回答的准确性和及时性。
在技术和模型的选择上,我们采用了基于 Transformer 架构的预训练语言模型,并在此基础上进行了微调 。预训练模型选择了在大规模语料库上训练的 BERT 模型,它在自然语言处理任务中表现出色,能够学习到丰富的语言知识和语义信息 。为了使模型更好地适应电商领域的业务需求,我们使用了公司内部的历史客服对话数据、商品信息、常见问题解答等数据对模型进行了微调,让模型能够理解和回答与电商业务相关的问题 。
在项目实施过程中,首先进行了数据的收集和整理,从公司的客服系统中提取了大量的历史对话记录,对数据进行了清洗和标注,将客户问题和对应的答案整理成训练数据 。然后,对预训练模型进行了微调,使用整理好的训练数据在 GPU 集群上进行训练,通过反向传播算法不断优化模型的参数,使其能够更好地拟合电商领域的数据 。在模型训练完成后,进行了模型的评估和优化,使用测试数据集对模型的性能进行了评估,根据评估结果对模型进行了进一步的调整和优化,如调整超参数、增加训练数据等 。最后,将优化后的模型部署到生产环境中,与公司的客服系统进行集成,实现了智能客服的功能 。
经过一段时间的运行,该智能客服系统取得了显著的效果 。客户问题的平均响应时间从原来的 5 分钟缩短到了 1 分钟以内,问题解决率从原来的 80% 提高到了 90% 以上,客户满意度得到了大幅提升 。同时,智能客服系统的使用也大大降低了人工客服的工作量,公司可以将更多的人力资源投入到其他重要的业务环节中 。
通过这个实际应用案例可以看出,大模型技术在解决实际业务问题方面具有巨大的潜力,能够为企业带来显著的经济效益和社会效益 。在未来,随着大模型技术的不断发展和完善,相信会有更多的企业将其应用到实际业务中,推动各行业的数字化转型和智能化升级 。
应对大模型面试的建议
知识储备
全面学习大模型相关知识是应对面试的基础。建议求职者从多个方面入手,构建完整的知识体系。深入研究大模型的基础概念,如模型的定义、特点、分类等,了解大模型与传统模型的区别和优势 。掌握大模型的技术原理,特别是 Transformer 模型的结构、工作原理和自注意力机制等核心内容,这是理解大模型的关键 。关注大模型在自然语言处理、计算机视觉等领域的应用场景和实际案例,了解大模型如何解决实际问题,以及在不同领域的应用效果和挑战 。
为了更好地学习大模型知识,以下是一些推荐的学习资料:
- 论文:《Attention Is All You Need》是 Transformer 模型的开创性论文,深入阐述了 Transformer 的原理和结构,是学习大模型的必读论文 ;《BERT: Pre - training of Deep Bidirectional Transformers for Language Understanding》介绍了 BERT 模型,展示了预训练语言模型在自然语言处理中的强大能力;《GPT-3: Language Models are Few-Shot Learners》详细介绍了 GPT-3 模型的架构、训练和应用,对理解大语言模型具有重要参考价值 。
- 书籍:《深度学习》是深度学习领域的经典教材,涵盖了深度学习的基本概念、模型结构和训练方法等内容,为学习大模型提供了坚实的理论基础 ;《动手学深度学习》通过大量的代码示例和实践案例,帮助读者快速上手深度学习和大模型开发,适合初学者 ;《Transformer 模型原理与实战》专注于 Transformer 模型,深入剖析了模型的原理、实现和应用,对学习 Transformer 架构的大模型非常有帮助 。
- 在线课程:Coursera 上的 “Deep Learning Specialization” 课程由深度学习领域的知名专家授课,系统地介绍了深度学习的基础知识和应用,包括大模型的相关内容 ;网易云课堂上的 “大模型实战训练营” 课程,结合实际项目案例,讲解了大模型的开发、优化和部署等实践技能,有助于提升实际操作能力 。
同时,关注行业动态和最新研究成果也是非常重要的。可以关注 OpenAI、Google AI、DeepMind 等知名研究机构的官方网站和社交媒体账号,及时了解大模型领域的最新进展 ;订阅 arXiv、ICML、NeurIPS 等学术平台上的相关论文,跟进大模型的前沿研究。
实践经验积累
参与大模型相关的项目实践是提升实际操作能力和积累经验的重要途径。通过实践,能够将理论知识应用到实际项目中,加深对大模型的理解,同时还能锻炼解决实际问题的能力,提高在面试中的竞争力 。
如果你是一名学生,可以积极参与学校的科研项目,寻找与大模型相关的课题,如基于大模型的文本分类、图像生成等 。在项目中,负责数据收集、预处理、模型训练和评估等工作,全面掌握大模型开发的流程和技术。此外,还可以参加开源项目,如参与 Hugging Face 上的大模型相关项目,与全球的开发者合作,学习他人的经验和代码规范,提升自己的技术水平 。
对于在职人员来说,可以在工作中争取参与大模型相关的项目,或者利用业余时间进行个人项目实践 。例如,搭建一个基于大模型的智能聊天机器人,实现基本的对话功能,并不断优化和改进;或者利用大模型进行数据分析和预测,解决实际工作中的问题 。在实践过程中,要注重总结经验教训,记录遇到的问题和解决方案,这些都是宝贵的面试素材。
除了实际参与项目,还可以通过参加竞赛来积累实践经验 。Kaggle、天池等平台经常举办与大模型相关的竞赛,如自然语言处理竞赛、计算机视觉竞赛等 。在竞赛中,与其他参赛者竞争,学习他们的思路和方法,同时也能检验自己的技术水平,发现不足之处,及时进行改进 。
更多推荐
 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)