
论文精读(7): DINO 系列自监督视觉学习发展与 DINOv3 深度解析
不依赖标注:通过多视角裁剪(Multi-Crop)保证特征一致性。中心化 + 温度锐化:稳定输出分布,防止坍塌。:ViT 的注意力自动对齐显著区域,实现类显著性特征。DINO:语义自监督,Emergent AttentionDINOv2:通用可迁移特征,Register Token 与大模型稳定策略DINOv3:多任务可塑性 + 动态 token + 掩码融合 + 分辨率混合训练。
·
DINOv3:https://arxiv.org/abs/2508.10104
DINOv3双语版PDF
近年来,自监督视觉学习(Self-Supervised Learning, SSL)取得了显著进展。从对比学习到掩码建模,再到统一多任务表示,视觉特征正逐步迈向“即插即用”的通用平台。本文将回顾 DINO 与 DINOv2,总结 DINOv3 的创新点,并探讨其应用与延伸方向。
1. 回顾 DINO 与 DINOv2
1.1 DINO 核心思想
DINO(Self-Distillation with No Labels)是基于教师-学生(teacher-student)结构的自监督学习方法:
- 不依赖标注:通过多视角裁剪(Multi-Crop)保证特征一致性。
- 中心化 + 温度锐化:稳定输出分布,防止坍塌。
- Emergent Attention:ViT 的注意力自动对齐显著区域,实现类显著性特征。
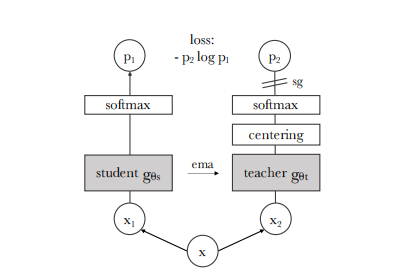
1.2 关键技术点
- Multi-Crop:2 个 global + N 个 local 视角,提高密集语义一致性。
- 动量教师:教师参数采用 EMA 平滑更新,训练稳定。
- 无负样本设计:避免大规模对比队列开销。
1.3 与同时期方法对比
| 方法 | 特点 |
|---|---|
| MoCo / SimCLR | 依赖大 batch 或队列,对比学习特征 |
| BYOL | 无显式负样本,但输出分布约束不显式 |
| MAE | 偏向结构重建,语义弱 |
| DINO | 偏语义全局,Emergent Attention 自发显著性 |
1.4 DINOv2 的改进
DINOv2 将目标从“语义自监督”升级为“可复用通用特征”:
- 数据管线优化:高质量图片筛选,去噪,类别均衡。
- Register Tokens:额外 learnable token 聚合多尺度语义,提升密集任务能力。
- Layer / Head Aggregation:不同任务使用不同层次输出组合。
- 大模型适配:ViT-L / ViT-g 在自监督下稳定收敛。
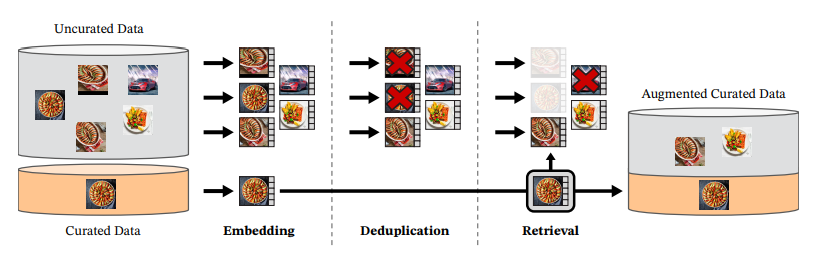
效果:零/少样本分类提升,检索与分割任务一体化,下游微调更 sample-efficient。
2. DINOv3 的新贡献与创新点
DINOv3 在 DINOv2 基础上进一步系统化,实现多任务、跨模态和高可控表征。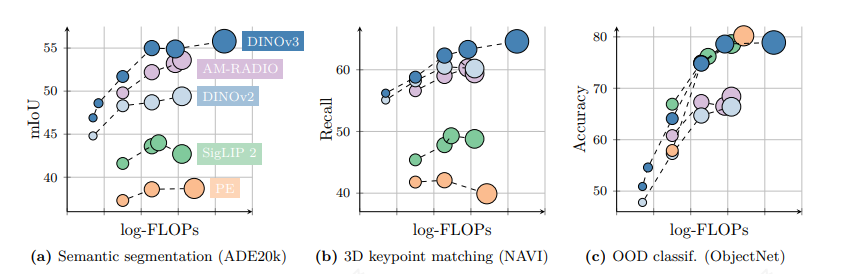
2.1 目标定位升级
- 从“通用视觉特征”向“统一表示平台”发展
- 支持视频、3D、文图检索、生成辅助等多领域任务
- 兼顾结构敏感与语义抽象
2.2 训练范式与损失结构
- 自蒸馏一致性延续 DINO 核心
- 掩码建模融合(部分 patch mask),提升几何与纹理保留
- 跨层一致性(Cross-layer / Multi-level alignment)
- 语义分布均匀化正则
- 可选 token-level contrast 改善细粒度区分
2.3 架构与 Token 机制增强
- 动态寄存 token:早期偏全局聚合,后期偏细粒度
- 分辨率混合训练(Multi-Resolution Batch Scheduling)
- Query 归一化 / QK-Norm / Flash Attention 2 提升长序列稳定性
- Hybrid Patch Stem:浅层卷积改善细节特征
2.4 数据与分布改良
- 真实 + 合成数据融合(AIGC、渲染)
- 自动难样本挖掘与重复采样
- 类别或 cluster-level 重加权去偏
2.5 表征性质
- 可控平衡语义不变性与几何保留
- 中层 token 可为姿态、细粒度检索提供高保真空间信息
- 上层 embedding 保持紧凑,便于检索与分类
2.6 工程优化
- 混合精度训练 + ZeRO / FSDP / Activation Checkpoint
- 渐进式多尺度 Multi-Crop,节省 FLOPs
- Token Pruning / Early Dropping 削减低注意权重 token
- 异步数据解码与缓存,降低 I/O 瓶颈
3. 典型应用场景展望
- 大规模视觉检索 / 多媒体搜索:向量库 + 轻量重排序
- 零样本/少样本工业缺陷检测:利用中层结构特征
- 细粒度识别:寄存 token + 中间层微调
- 医学影像:语义 + 结构兼顾
- 机器人与 Embodied AI:稳健感知特征输入策略规划
- 多模态对齐预处理:视频→文本、图像→语音描述
- AIGC 质量评估 / 伪造检测:利用真实与合成特征分布差异
- 远程遥感 / 3D / NeRF:多尺度一致性 + 稀疏图像集稳定语义 anchor
- 高效向量数据库:embedding 分层召回优化
4. 可结合或延伸的研究方向
- 自监督 + 指令调优:视觉特征指令语义化,适配 LLM
- 统一视觉-音频-文本 embedding:多模态三元对齐
- 结构保持正则:edge / depth 先验约束中层特征
- 可微数据筛选(Learned Data Curation)
- 表征解耦:颜色 / 纹理 / 形状子空间可控
- 连续学习:增量数据加入不破坏旧语义
- 高效量化:INT4/INT8 保持语义几何
- 隐私保持:私有 + 公有数据混合训练(DP-SGD + Representation Filtering)
- 安全鲁棒:对抗扰动 / 数据后门检测
- 结合扩散模型:引导更均匀的表征分布
5. 总结
DINO 系列的发展路径:
- DINO:语义自监督,Emergent Attention
- DINOv2:通用可迁移特征,Register Token 与大模型稳定策略
- DINOv3:多任务可塑性 + 动态 token + 掩码融合 + 分辨率混合训练
通过 DINOv3,视觉特征从单纯语义向“结构 + 语义平衡、可控粒度”的通用表示演进,为视觉检索、少样本学习、密集任务以及多模态对齐提供了更高效、稳健的基础。
如果你对 DINOv3 在实际落地、少样本分类或检索系统应用有兴趣,可参考以下策略:
- 数据规模 < 数百万:直接使用 DINOv3 预训练权重 + 线性层
- 少样本分类:冻结主干 + 轻 Adapter (LoRA / Prompt Tuning)
- 密集任务:提取中层 + register/dynamic token 组合
- 多模态任务:先固定视觉侧,再蒸馏到文本对齐模型(mini-CLIP 方式)
- 低资源部署:Token Prune + INT8 量化
- 医学 / 遥感:自建域数据少轮继续自蒸馏,保持全局结构
更多推荐


 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)