
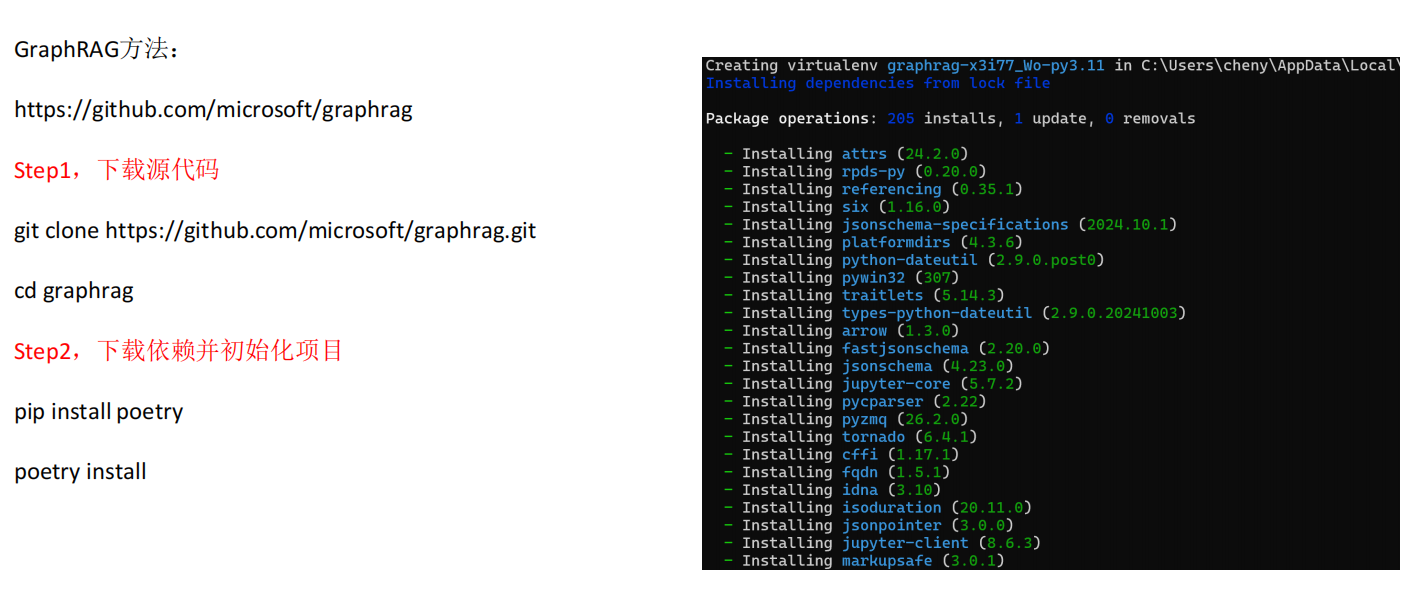
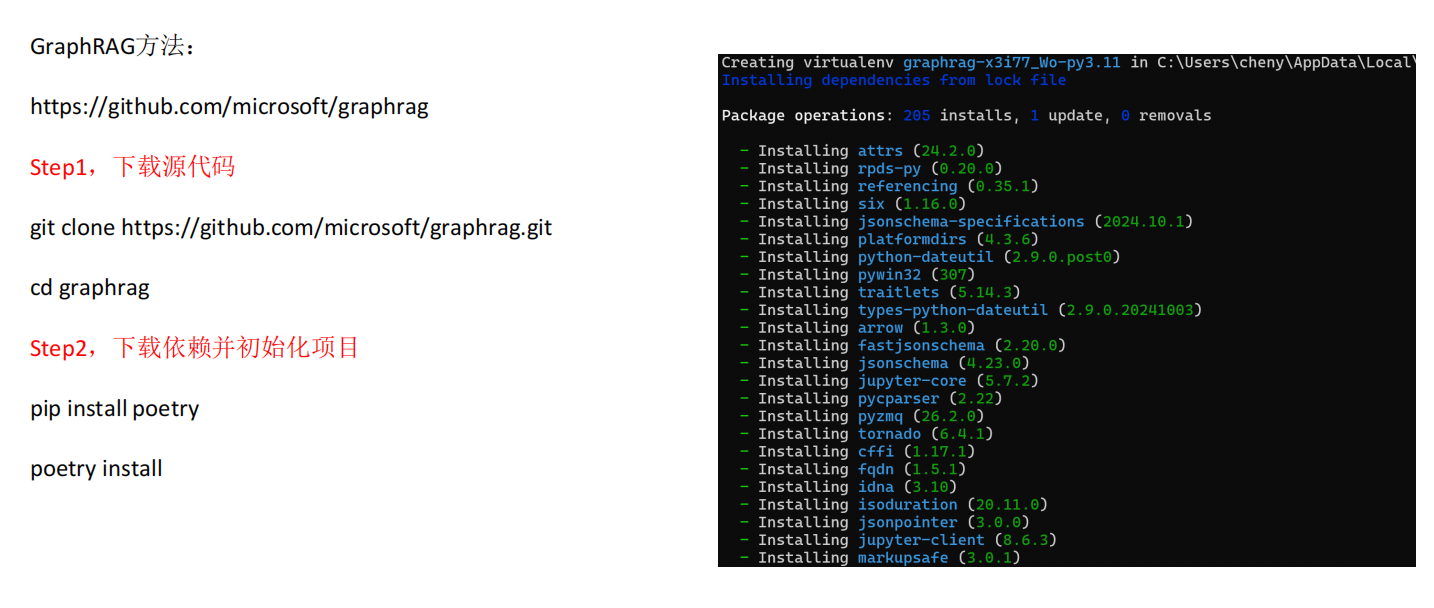
【大模型07】RAG高级技术与实战
embedding 过程中,神经网络的输入=单词,输出=输出 = 单词(作为邻居)的概率Q:怎么把调用模型API改为服务器部署好的大模型,另外知识库单个文件改为文件夹现在使用的是 dashscope 接口,我们也可以部署自己的大模型,通过 http serivce,按照dashscope/openai 接口进行返回内容server填写自己的 api url即可faiss。
这里写自定义目录标题
-
embedding 过程中,神经网络的输入=单词,输出=输出 = 单词(作为邻居)的概率
-
Q:怎么把调用模型API改为服务器部署好的大模型,另外知识库单个文件改为文件夹
现在使用的是 dashscope 接口,我们也可以部署自己的大模型,通过 http serivce,按照dashscope/openai 接口进行返回内容
server填写自己的 api url即可 -
faiss
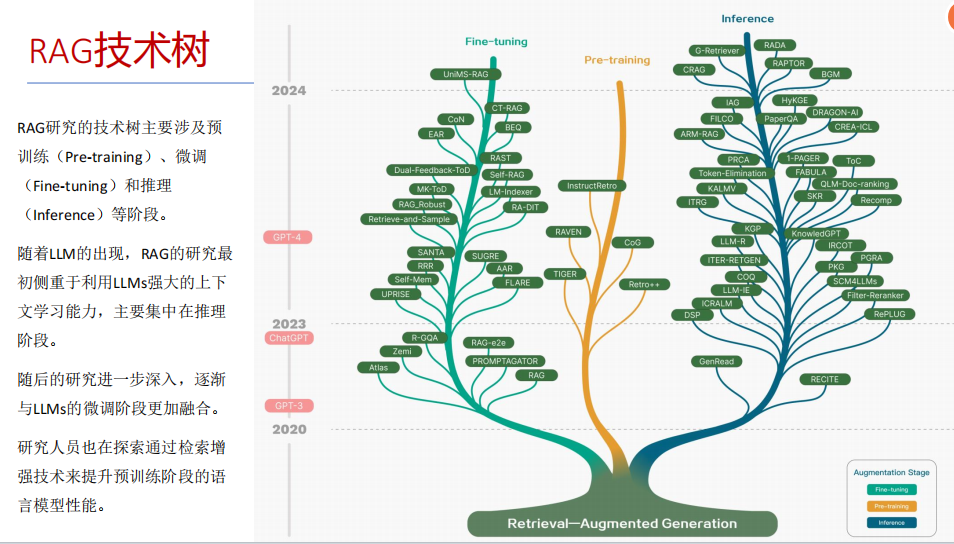
RAG技术树
NativeRAG
RAG的步骤
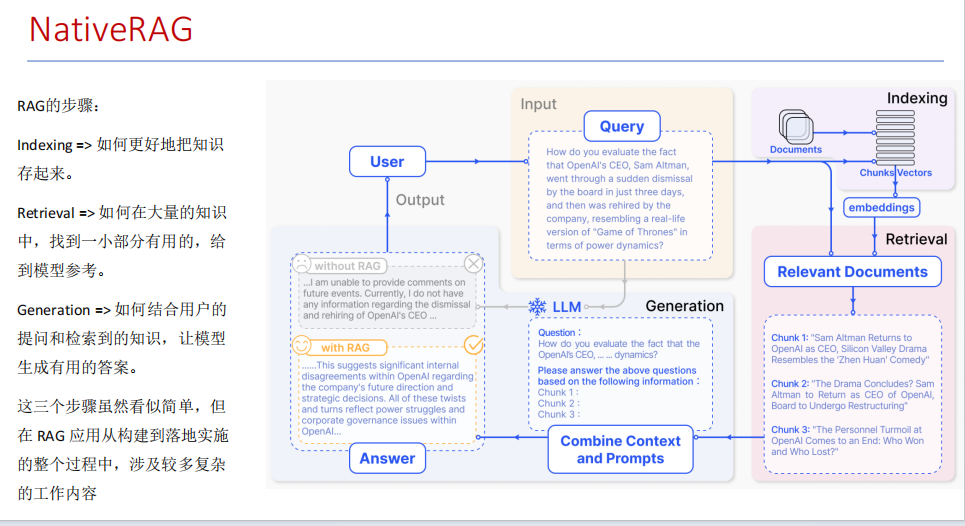
a. indexing 存储知识,比如将知识存入向量数据库 FASIS中
b.Retrival 在大量的知识中,找到一小部分有用的,给模型参考
c.Generation 结合提问和检索到的知识,让大模型生成有用的答案
RAFT 微调部分的RAG (Retrieval Augmented Fine Tuning)
RAFT: Adapting Language Model to Domain Specific RAG, 2024 https://arxiv.org/pdf/2403.10131
如何最好地准备考试?
(a) 基于微调的方法通过“学习”来实现“记忆”输入文档或回答练习题而不参考文档。
(b) 或者,基于上下文检索的方法未能利用固定领域所提供的学习机会,相当于参加开卷考试但没有事先复习。
© 相比之下,我们的方法RAFT利用了微调与问答对,并在一个模拟的不完美检索环境中参考文档——从而有效地为开卷考试环境做准备。
RAFT方法
让LLMs 从一组正面和干扰文档中读取解决方案,这与标准的RAG设置形成对比。因为在标准的RAG设置中,模型是基于检索器输出进行训练的,这包含了记忆和阅读的混合体。在测试时,所有方法都遵循标准的RAG设置,即提供上下文中排名前k的检索文档。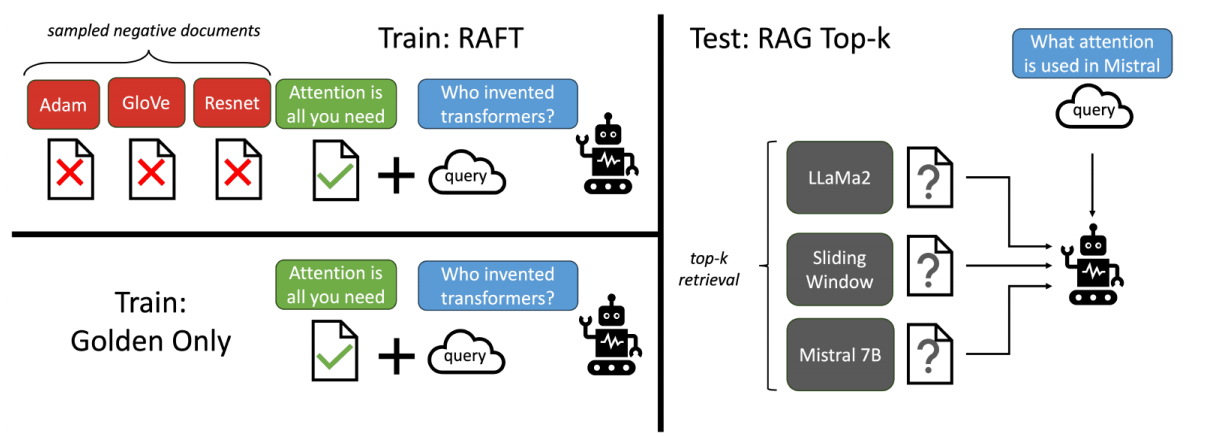
适应特定领域的LLMs对于许多新兴应用至关重要,但如何有效融入信息仍是一个开放问题。
• RAFT结合了检索增强生成(RAG)和监督微调(SFT),从而提高模型在特定领域内回答问题的能力。
• 训练模型识别并忽略那些不能帮助回答问题的干扰文档,只关注和引用相关的文档。
• 通过在训练中引入干扰文档,提高模型对干扰信息的鲁棒性,使其在测试时能更好地处理检索到的文档。
CASE : DeepSeek+Faiss

RAG 高效召回方法
(1). Thinking:如果要召回更多的片段,如何设置?
docs = knowledgeBase.similarity_search(query, k=10)
(2) Thinking:都有哪些RAG召回的策略,提升召回的质量?
- 改进检索算法
知识图谱:利用知识图谱中的语义信息和实体关系,增强对查询和文档的理解,提升召回的相关性。
2.引入重排序(Reranking)
重排序模型:对召回结果进行重排,提升问题和文档的相关性。常见的重排序模型有BGE-Rerank和Cohere Rerank。
3.混合检索:结合向量检索和关键词检索的优势,通过重排序模型对结果进行归一化处理,提升召回质量
(3)thinking 什么是重排序
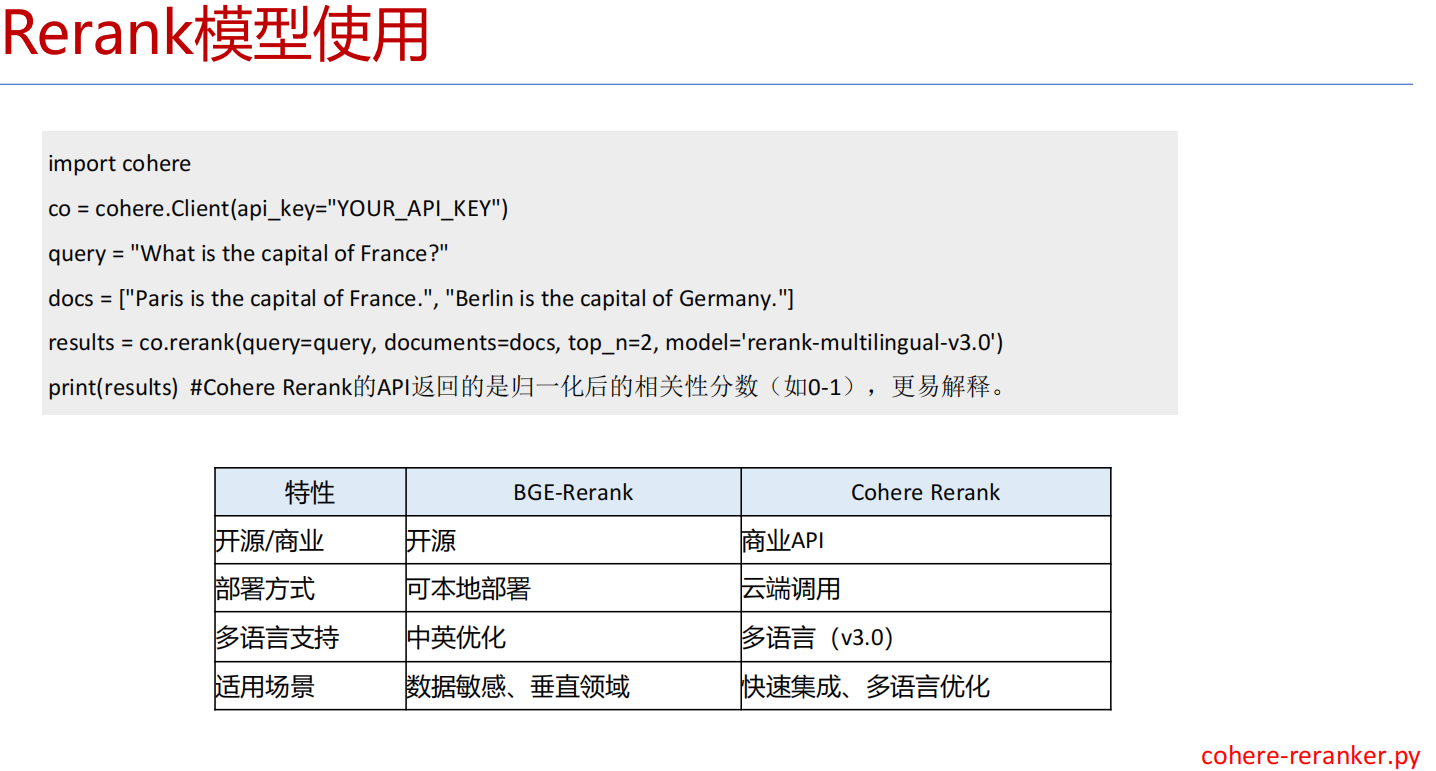
重排序Rerank主要用于优化初步检索结果的排序,提高最终输出的相关性或准确性。BGE-Rerank和Cohere Rerank是
两种广泛使用的重排序模型,它们在检索增强生成(RAG)系统、搜索引擎优化和问答系统中表现优异。
1 BGE-Rerank
 * Rerank 模型使用
* Rerank 模型使用
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-reranker-large')
model = AutoModelForSequenceClassification.from_pretrained('BAAI/bge-reranker-large')
model.eval()
pairs = [['what is panda?', 'The giant panda is a bear species endemic to China.']]
inputs = tokenizer(pairs, padding=True, truncation=True, return_tensors='pt')
scores = model(**inputs).logits.view(-1).float()
print(scores) # 输出相关性分数 4.9538
在BGE-Rerank模型中,相关性分数scores是一个未归一化的对数几率(logits)值,范围没有固定的上
限或下限(不像某些模型限制在0-1)。不过BGE-Rerank的分数通常落在以下范围:
高相关性: 3.0~10.0
中等相关性:0.0~3.0
低相关性/不相关:负数(如-5.0以下)
2 Cohere-Rerank

3 优化查询方法
相似语义改写:使用大模型将用户查询改写成多个语义相近的查询,提升召回多样性。例如,LangChain的MultiQueryRetriever支持多查询召回。
# 加载向量数据库,添加allow_dangerous_deserialization=True参数以允许反序列化
vectorstore = FAISS.load_local("./faiss-1", embeddings, allow_dangerous_deserialization=True)
# 创建MultiQueryRetriever
retriever = MultiQueryRetriever.from_llm(
retriever=vectorstore.as_retriever(),
llm=llm
)
query = "客户经理的考核标准是什么?"
# 执行查询
results = retriever.get_relevant_documents(query)
RAG高效召回方法(双向改写)
双向改写:将查询改写成文档(Query2Doc)或为文档生成查询(Doc2Query),缓解短文本向量化效果差的问题
MultiQueryRetriever :将问题换多种方法描述
from langchain.retrievers import MultiQueryRetriever
from langchain_community.vectorstores import FAISS
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.llms import Tongyi
import os
# 获取环境变量中的 DASHSCOPE_API_KEY
DASHSCOPE_API_KEY = os.getenv('DASHSCOPE_API_KEY')
if not DASHSCOPE_API_KEY:
raise ValueError("请设置环境变量 DASHSCOPE_API_KEY")
llm = Tongyi(model_name="deepseek-v3", dashscope_api_key=DASHSCOPE_API_KEY) # qwen-turbo
# 创建嵌入模型
embeddings = DashScopeEmbeddings(
model="text-embedding-v1",
dashscope_api_key=DASHSCOPE_API_KEY,
)
# 加载向量数据库,添加allow_dangerous_deserialization=True参数以允许反序列化
vectorstore = FAISS.load_local("./faiss-1", embeddings, allow_dangerous_deserialization=True)
# 创建MultiQueryRetriever
retriever = MultiQueryRetriever.from_llm(
retriever=vectorstore.as_retriever(),
llm=llm
)
# 示例查询
query = "客户经理的考核标准是什么?"
# 执行查询
results = retriever.invoke(query)
# 打印结果
print(f"查询: {query}")
print(f"找到 {len(results)} 个相关文档:")
for i, doc in enumerate(results):
print(f"\n文档 {i+1}:")
print(doc.page_content[:200] + "..." if len(doc.page_content) > 200 else doc.page_content)
4. 索引扩展
1)离散索引扩展:使用关键词抽取、实体识别等技术生成离散索引,与向量检索互补,提升召回准确性。
2)连续索引扩展:结合多种向量模型(如OpenAI的Ada、智源的BGE)进行多路召回,取长补短。
3)混合索引召回:将BM25等离散索引与向量索引结合,通过Ensemble Retriever实现混合召回,提升召回多
样性。


Small-to-Big
Small-to-Big 索引策略:
一种高效的检索方法,特别适用于处理长文档或多文档场景。核心思想是通过小规模内容(如摘要、关键句或段落)建立索引,并链接到大规模内容主体中。这种策略的优势在于能够快速定位相关的小规模内容,并通过链接获取更详细的上下文信息,从而提高检索效率和答案的逻辑连贯性。

GraphRAG
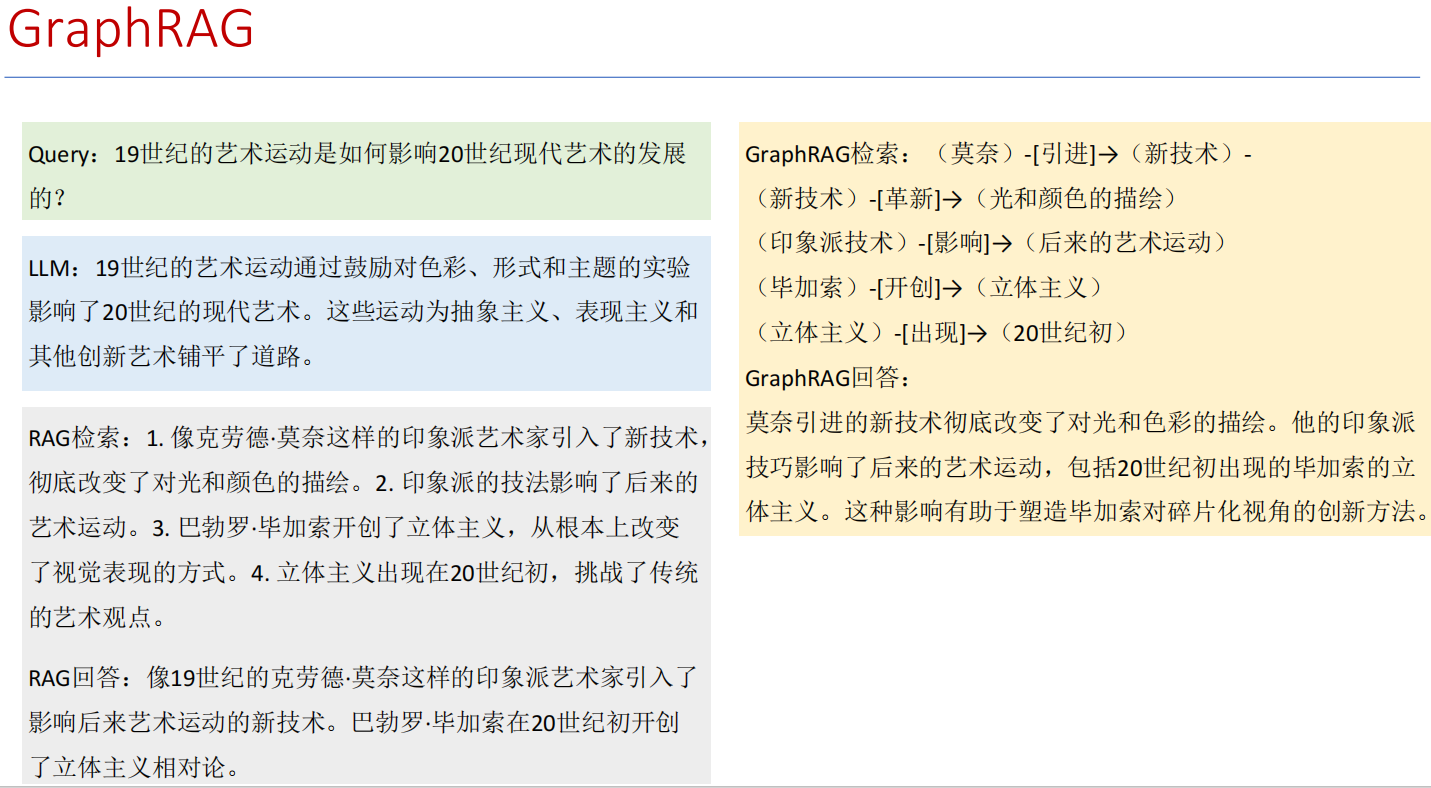
一、为什么需要 Graph RAG?
普通的 RAG 主要依赖向量检索:
优点:语义匹配能力强,能找到相关文本。
缺点:缺乏结构化关系理解,比如:
问:“爱因斯坦的学生有哪些?”
普通 RAG 可能找到含“爱因斯坦”的文本片段,但难以系统整理他的学生。
而 Graph RAG 引入了 知识图谱(Knowledge Graph,KG),把知识表示为 节点(实体)+ 边(关系),使得模型能利用结构化关系进行 推理和聚合。
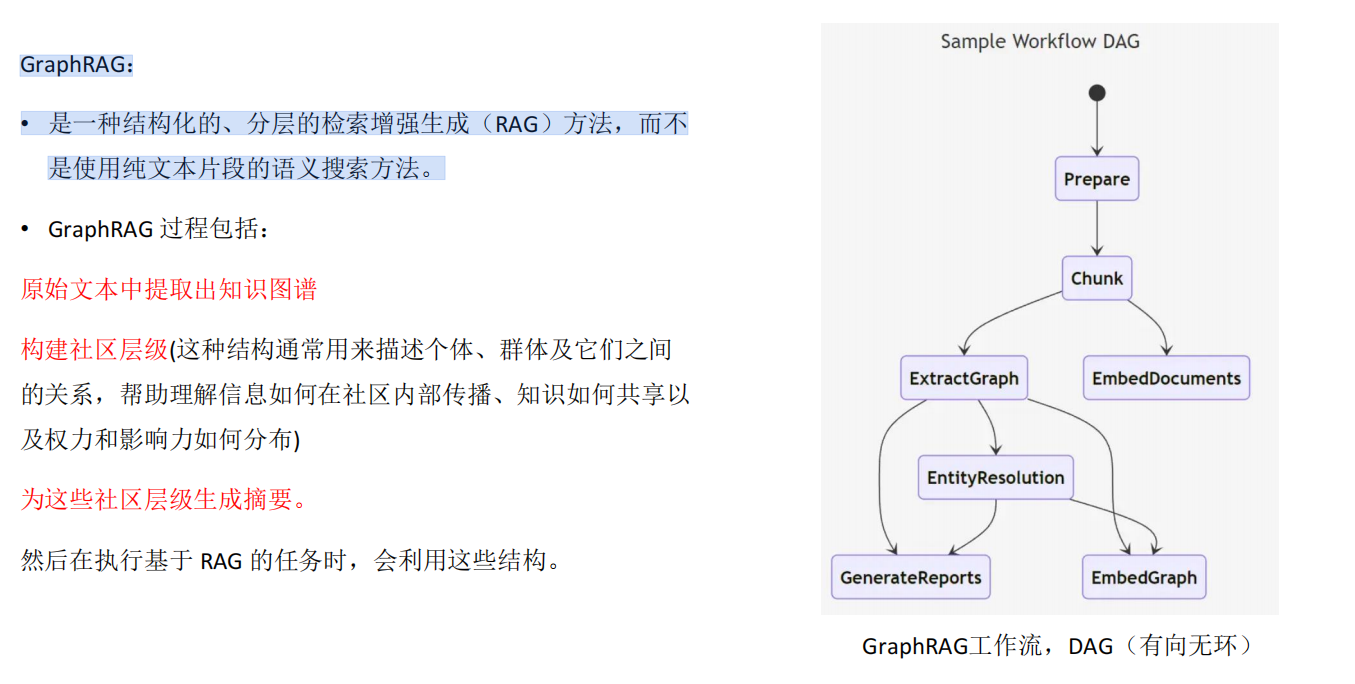
GraphRAG:
• 是一种结构化的、分层的检索增强生成(RAG)方法,而不是使用纯文本片段的语义搜索方法。
二、Graph RAG 的基本流程
构建知识图谱
节点:实体(如“爱因斯坦”、“广义相对论”)
边:关系(如“提出”、“指导学生”)
属性:时间、出处等信息
用户提问 → 语义理解
模型或嵌入向量把问题转化为查询意图。
图检索(Graph Retrieval)
遍历图数据库(Neo4j、TigerGraph 等)
找到相关节点和关系路径
增强提示(Prompt Augmentation)
把图查询结果转化为文本上下文(例如三元组:爱因斯坦 — 指导 — 玻尔)。
生成(Generation)
大模型基于问题 + 图谱上下文,生成更准确、逻辑清晰的回答。
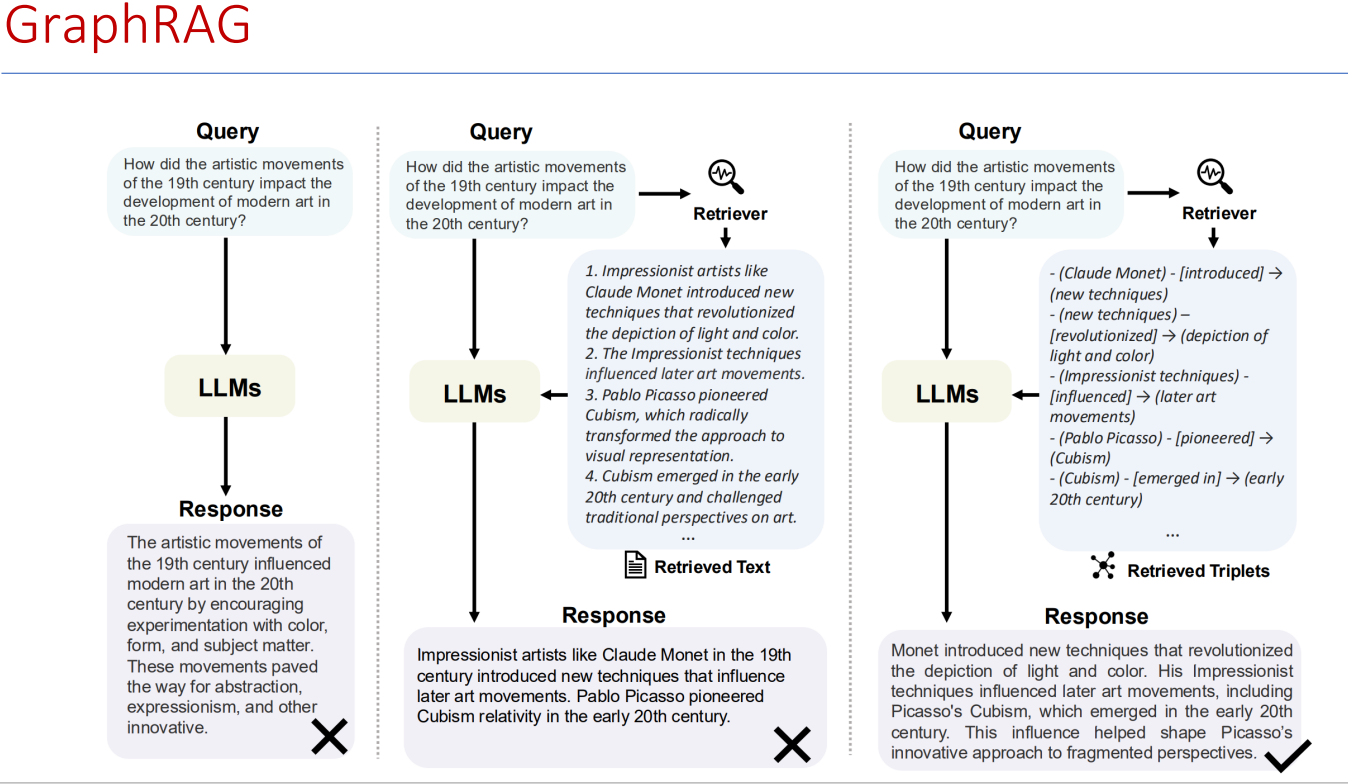
三、Graph RAG 的优势
更强的推理能力:能回答涉及关系链的复杂问题。
更高的可解释性:输出时能附带“推理路径”。
多模态融合:图谱不仅能存文本,还能挂载图片、公式、代码。
知识更新快:只需更新图谱,而非重新训练模型。

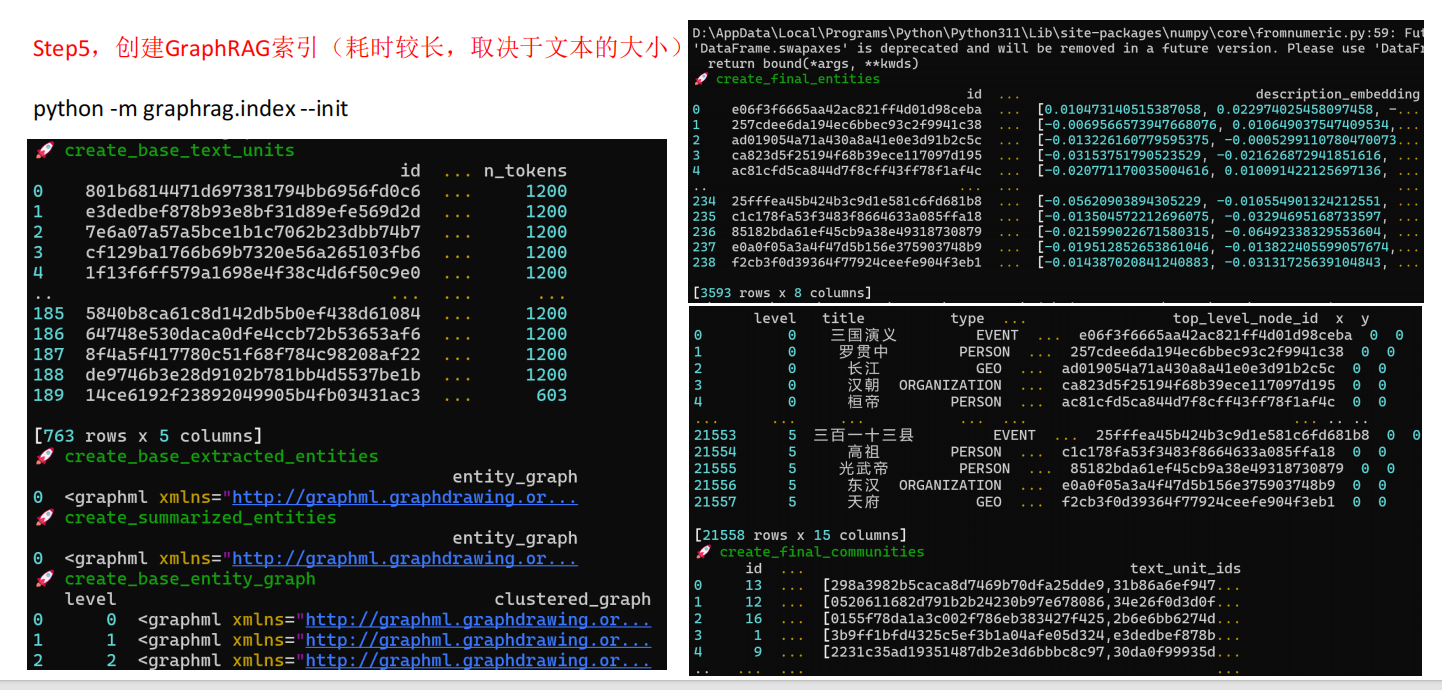
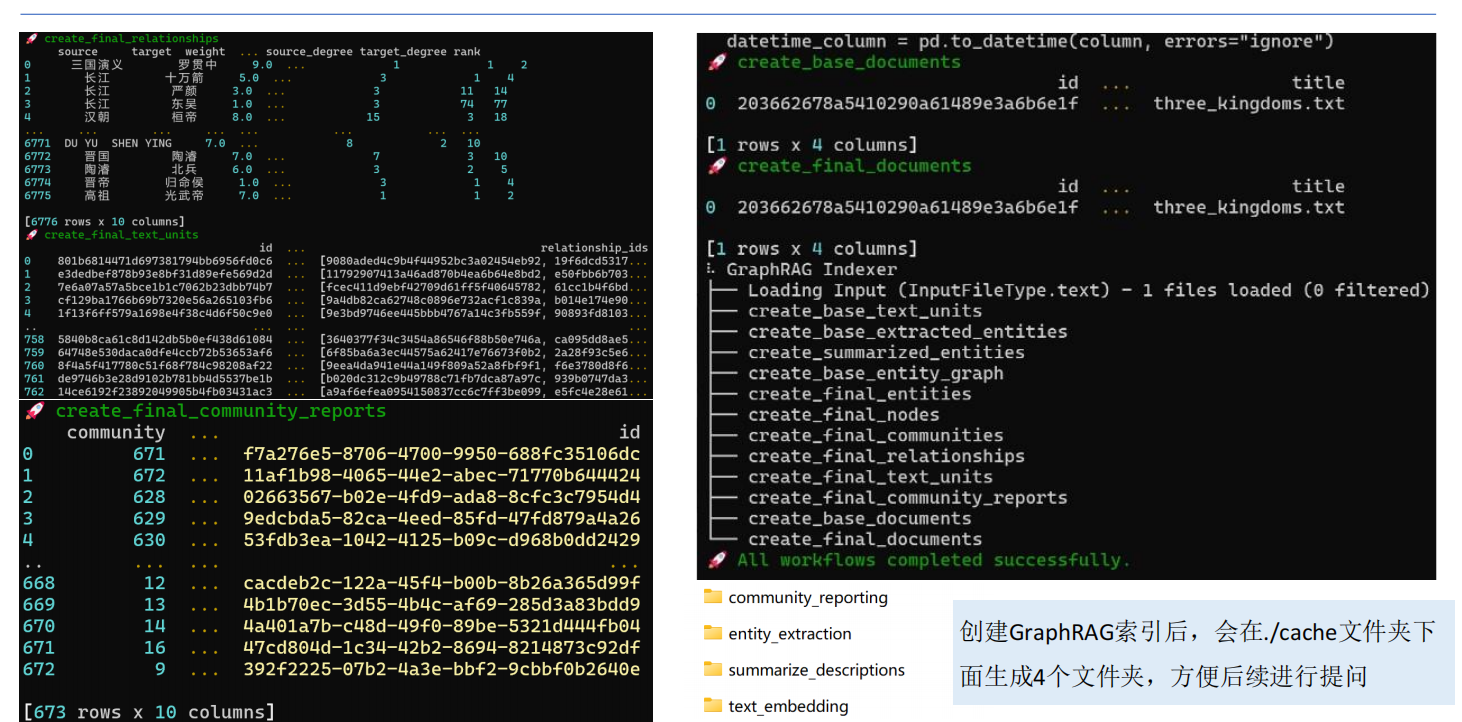
GraphRAG的基本步骤如下:
索引
• 将输入语料库分割为一系列的文本单元(TextUnits),这些单元作为处理以下步骤的可分析单元,并在我们的输出中提供细粒度的引用。
• 使用 LLM 从文本单元中提取所有实体、关系和关键声明。
• 使用 Leiden 技术对知识图谱进行层次聚类。每个圆圈都是一个实体(例如人、地点或组织),大小表示实体的度,颜色表示其社区层级。
• 自下而上地生成每个社区层级及其组成部分的摘要。这有助于对数据集的整体理解。
查询:
• 在查询时,使用这些结构为 LLM 上下文窗口提供材料来回答问
题。主要查询模式有:
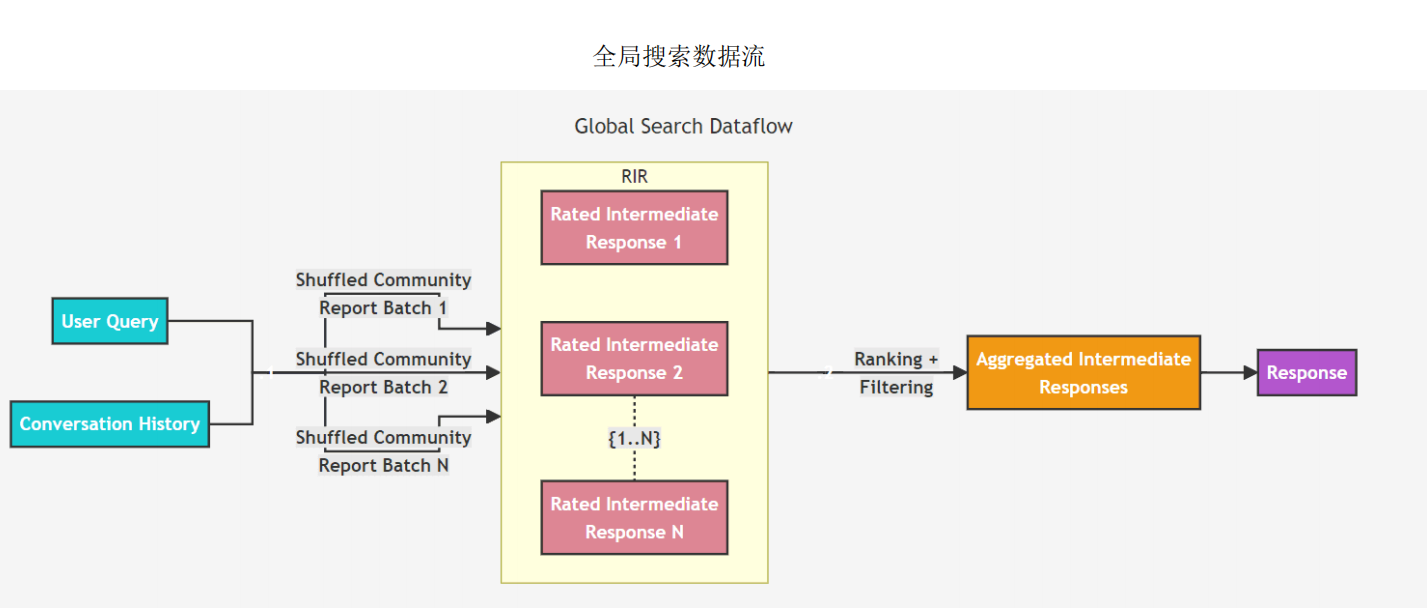
全局搜索,通过社区层级摘要来推理有关语料库的整体问题。
局部搜索,通过扩展到其邻居和相关概念来推理特定实体的情况。
GraphRAG方法是使用LLM构建基于图的文本索引,分两个阶段:
首先从源文档中派生出实体知识图谱
然后为所有密切相关的实体组预生成社区摘要。
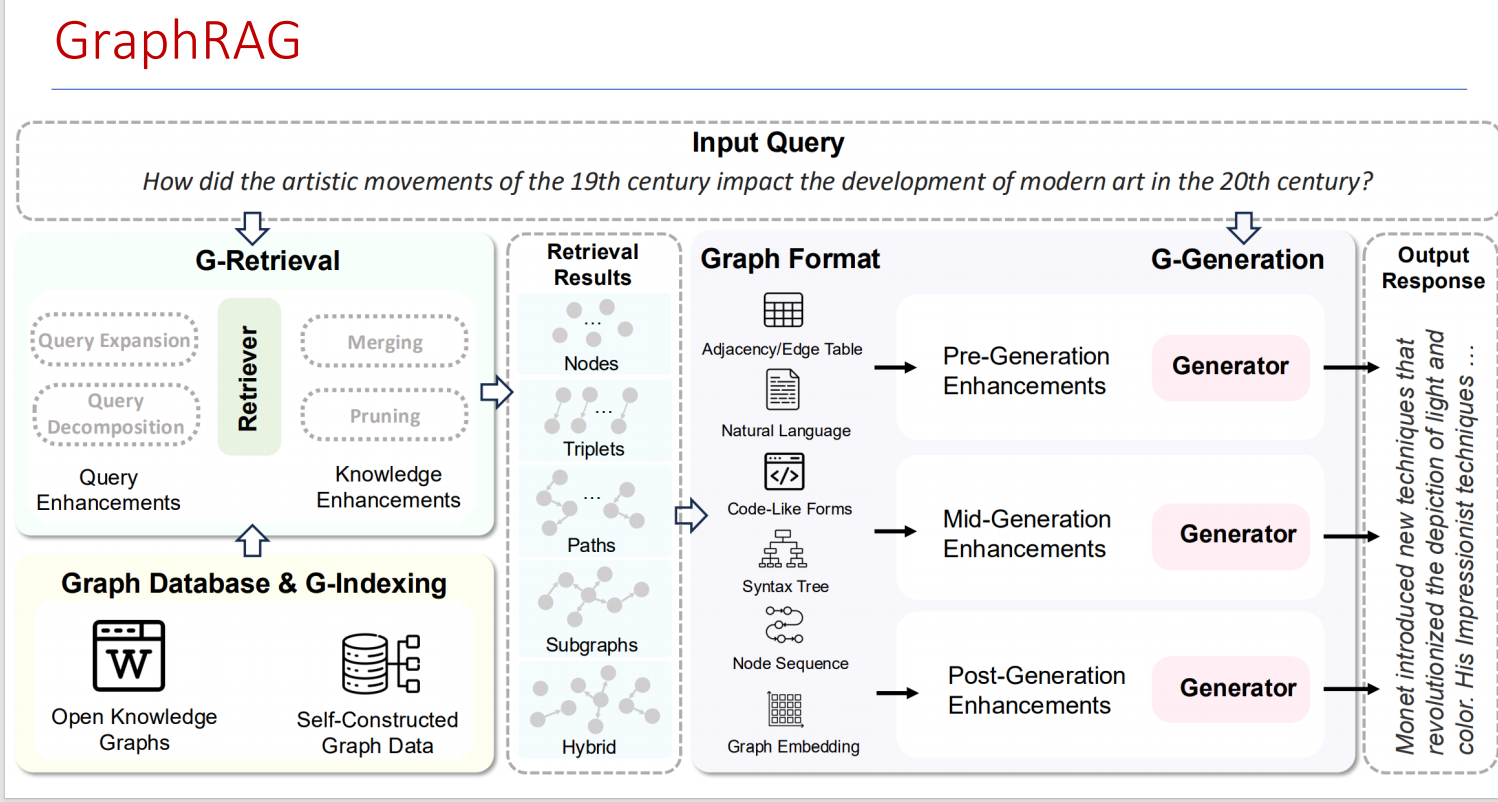
GraphRAG索引数据流




搭建RAG-使用Qwen-Agent
#!/usr/bin/env python
# coding: utf-8
# In[1]:
import pprint
import urllib.parse
import json5
from qwen_agent.agents import Assistant
from qwen_agent.tools.base import BaseTool, register_tool
import os
# 步骤 1(可选):添加一个名为 `my_image_gen` 的自定义工具。
@register_tool('my_image_gen')
class MyImageGen(BaseTool):
# `description` 用于告诉智能体该工具的功能。
description = 'AI 绘画(图像生成)服务,输入文本描述,返回基于文本信息绘制的图像 URL。'
# `parameters` 告诉智能体该工具有哪些输入参数。
parameters = [{
'name': 'prompt',
'type': 'string',
'description': '期望的图像内容的详细描述',
'required': True
}]
def call(self, params: str, **kwargs) -> str:
# `params` 是由 LLM 智能体生成的参数。
prompt = json5.loads(params)['prompt']
prompt = urllib.parse.quote(prompt)
return json5.dumps(
{'image_url': f'https://image.pollinations.ai/prompt/{prompt}'},
ensure_ascii=False)
# 步骤 2:配置您所使用的 LLM。
llm_cfg = {
# 使用 DashScope 提供的模型服务:
'model': 'qwen-max',
'model_server': 'dashscope',
'api_key': os.getenv('DASHSCOPE_API_KEY'), # 从环境变量获取API Key
'generate_cfg': {
'top_p': 0.8
}
}
llm_cfg = {
# 使用 DashScope 提供的模型服务:
'model': 'deepseek-v3',
'model_server': 'https://dashscope.aliyuncs.com/compatible-mode/v1',
'api_key': os.getenv('DASHSCOPE_API_KEY'), # 从环境变量获取API Key
'generate_cfg': {
'top_p': 0.8
}
}
# 步骤 3:创建一个智能体。这里我们以 `Assistant` 智能体为例,它能够使用工具并读取文件。
system_instruction = '''你是一个乐于助人的AI助手。
在收到用户的请求后,你应该:
- 首先绘制一幅图像,得到图像的url,
- 然后运行代码`request.get`以下载该图像的url,
- 最后从给定的文档中选择一个图像操作进行图像处理。
用 `plt.show()` 展示图像。
你总是用中文回复用户。'''
tools = ['my_image_gen', 'code_interpreter'] # `code_interpreter` 是框架自带的工具,用于执行代码。
import os
# 获取文件夹下所有文件
file_dir = os.path.join('./', 'docs')
files = []
if os.path.exists(file_dir):
# 遍历目录下的所有文件
for file in os.listdir(file_dir):
file_path = os.path.join(file_dir, file)
if os.path.isfile(file_path): # 确保是文件而不是目录
files.append(file_path)
print('files=', files)
bot = Assistant(llm=llm_cfg,
system_message=system_instruction,
function_list=tools,
files=files)
# 步骤 4:作为聊天机器人运行智能体。
messages = [] # 这里储存聊天历史。
query = "介绍下雇主责任险"
# 将用户请求添加到聊天历史。
messages.append({'role': 'user', 'content': query})
response = []
current_index = 0
for response in bot.run(messages=messages):
if current_index == 0:
# 尝试获取并打印召回的文档内容
if hasattr(bot, 'retriever') and bot.retriever:
print("\n===== 召回的文档内容 =====")
retrieved_docs = bot.retriever.retrieve(query)
if retrieved_docs:
for i, doc in enumerate(retrieved_docs):
print(f"\n文档片段 {i+1}:")
print(f"内容: {doc.page_content}")
print(f"元数据: {doc.metadata}")
else:
print("没有召回任何文档内容")
print("===========================\n")
#break
current_response = response[0]['content'][current_index:]
current_index = len(response[0]['content'])
print(current_response, end='')
# 将机器人的回应添加到聊天历史。
#messages.extend(response)
更多推荐
 25
25 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)