手把手教你调用大模型 API:从密钥获取到代码实现
API 密钥(API Key)是你访问大模型服务的 "身份证",它用于验证你的身份和权限,确保只有授权用户才能使用相关服务。每个平台的 API 密钥都是独一无二的,需要妥善保管,避免泄露。不同平台的 API 调用方式略有差异,但核心流程一致:获取密钥→配置客户端→发送请求→处理响应。下面我们分别介绍 DeepSeek 和阿里云通义千问的密钥获取方法和调用示例。
在 AI 大模型时代,直接调用成熟的大模型 API 是快速实现 AI 功能的最佳方式。本文将以 DeepSeek 和阿里云通义千问为例,详细介绍如何获取 API 密钥并通过代码调用大模型,即使是编程新手也能轻松上手。
一、什么是 API 密钥?为什么需要它?
API 密钥(API Key)是你访问大模型服务的 "身份证",它用于验证你的身份和权限,确保只有授权用户才能使用相关服务。每个平台的 API 密钥都是独一无二的,需要妥善保管,避免泄露。
不同平台的 API 调用方式略有差异,但核心流程一致:获取密钥→配置客户端→发送请求→处理响应。下面我们分别介绍 DeepSeek 和阿里云通义千问的密钥获取方法和调用示例。
二、获取 API 密钥的详细步骤
1、获取deepseek秘钥
这里要注意的是deepseek需要付费才能调用API-key,但是10块钱就能用很久,完全够我们学习使用。以下就是网址:
①进入API开发平台

②然后注册登录账号:这里没有展示
③创建API-key
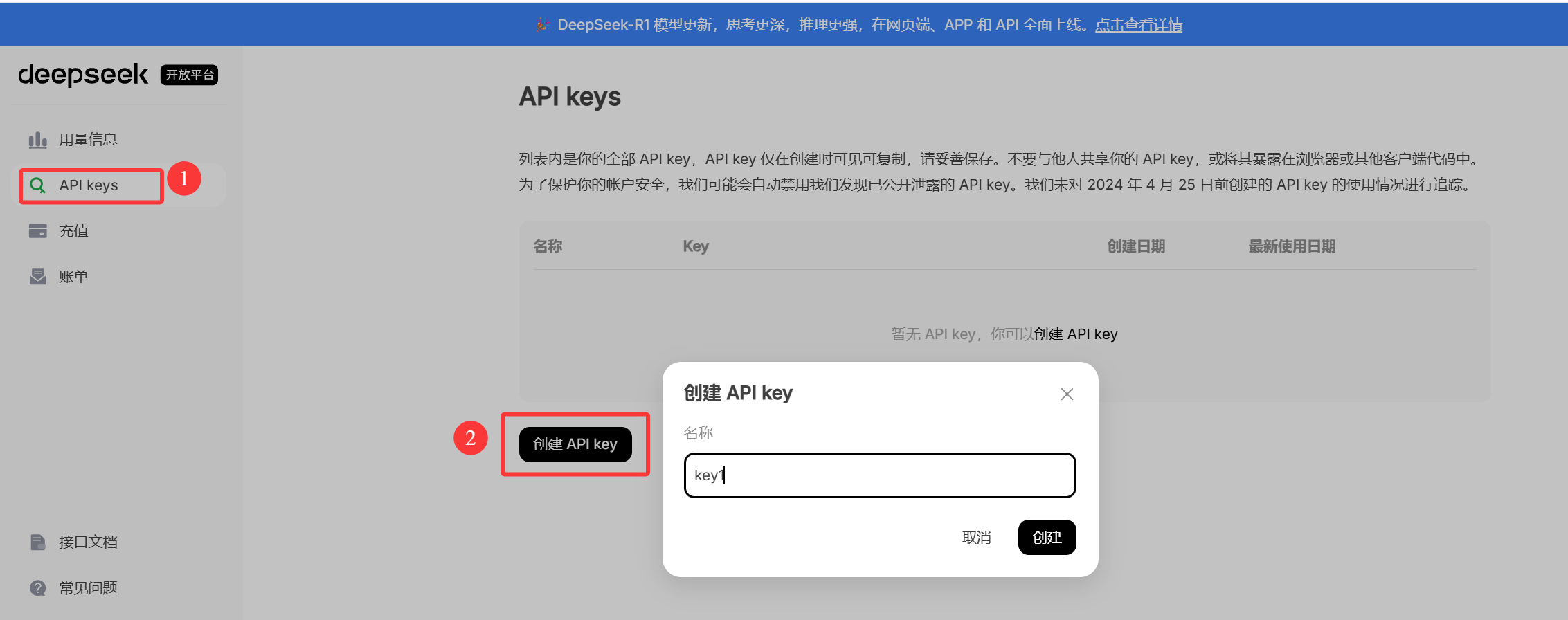
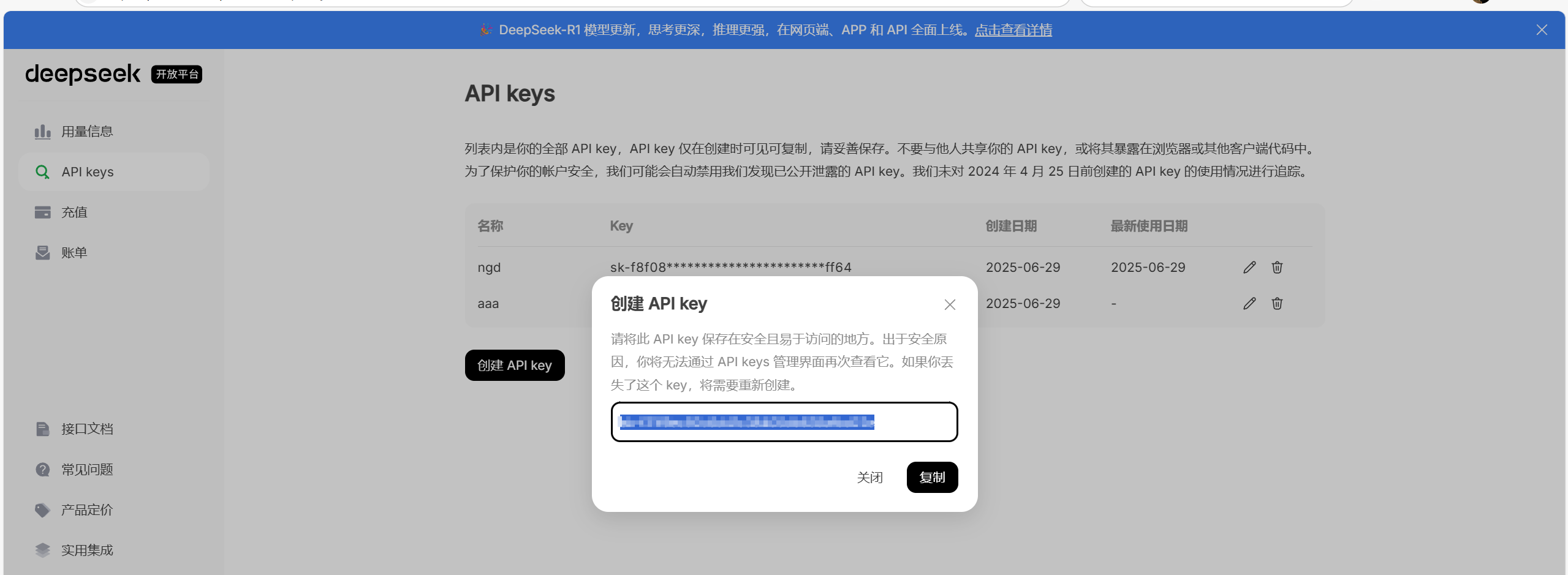
④复制秘钥
这里需要特别注意,一点要复制API-key,后续会用到,只会出现一次!!!
2、获取前问秘钥
前问好的是可以免费使用半年,但是一定要去领取,以下就是前问的网址:
①登录注册
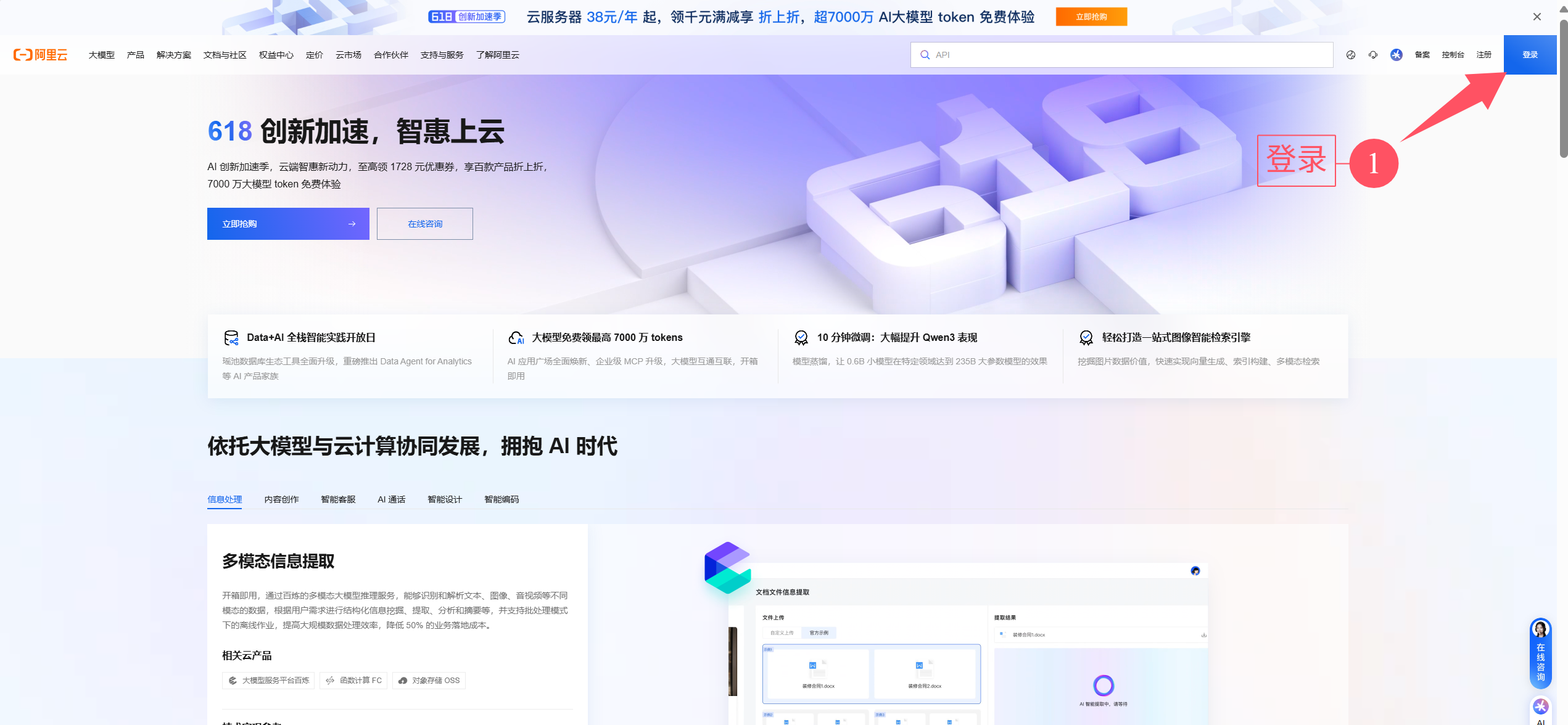
②进入大模型服务
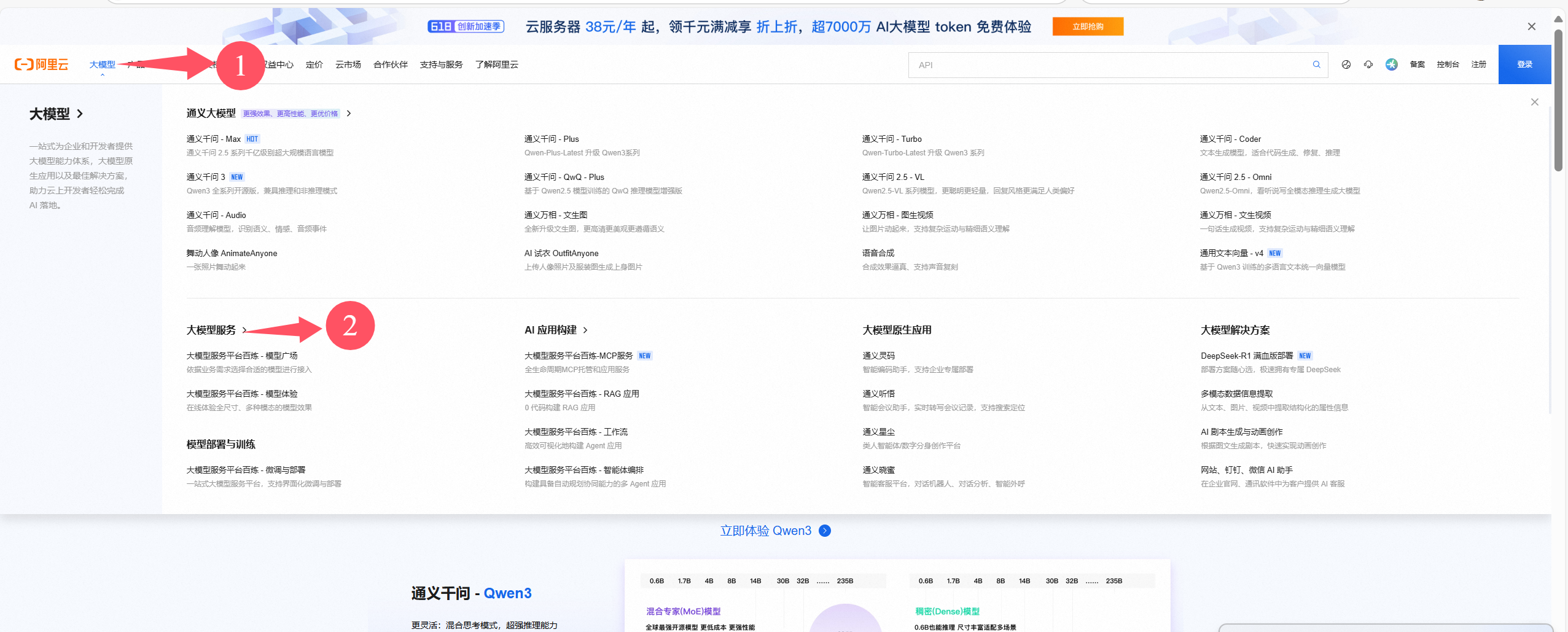
③进入API-key
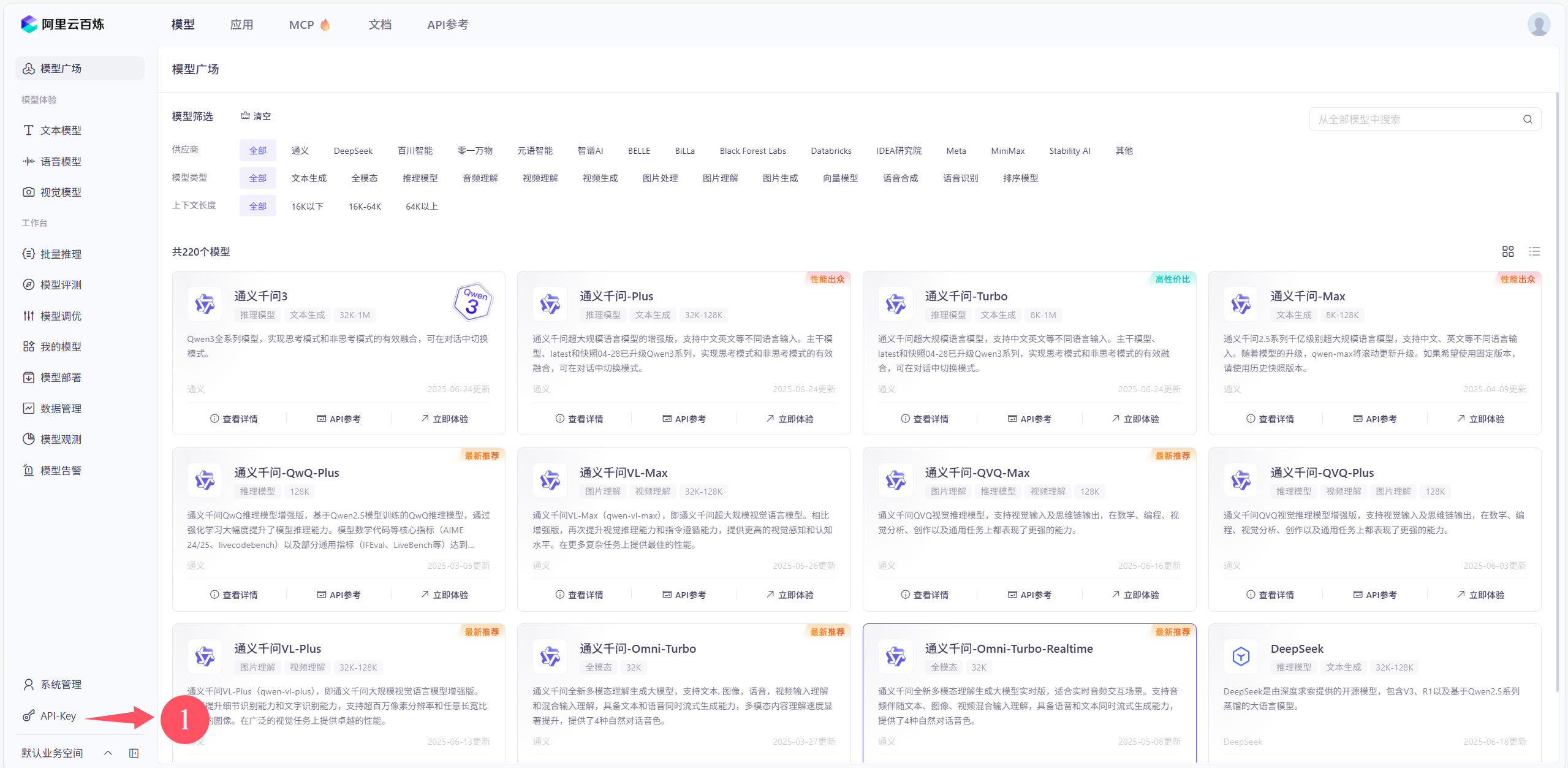
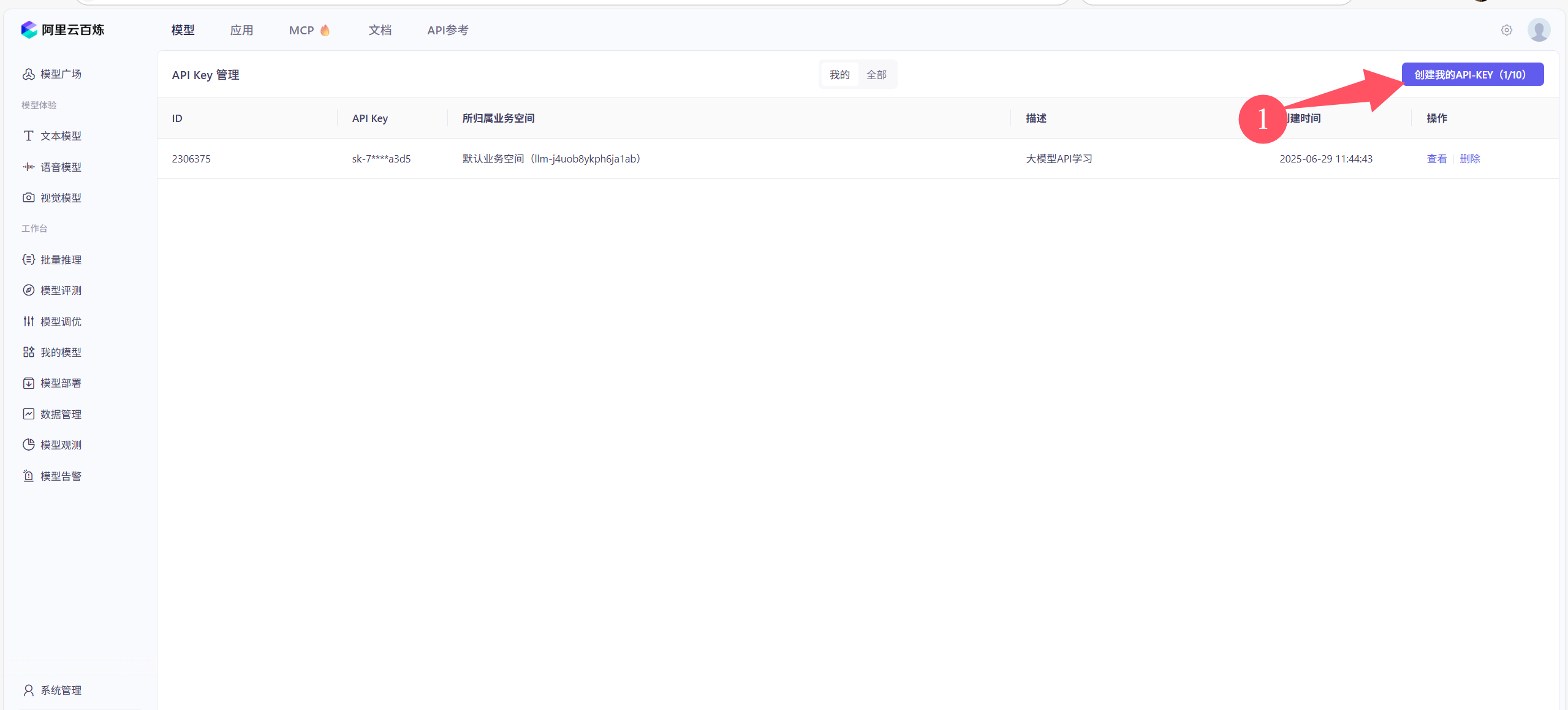
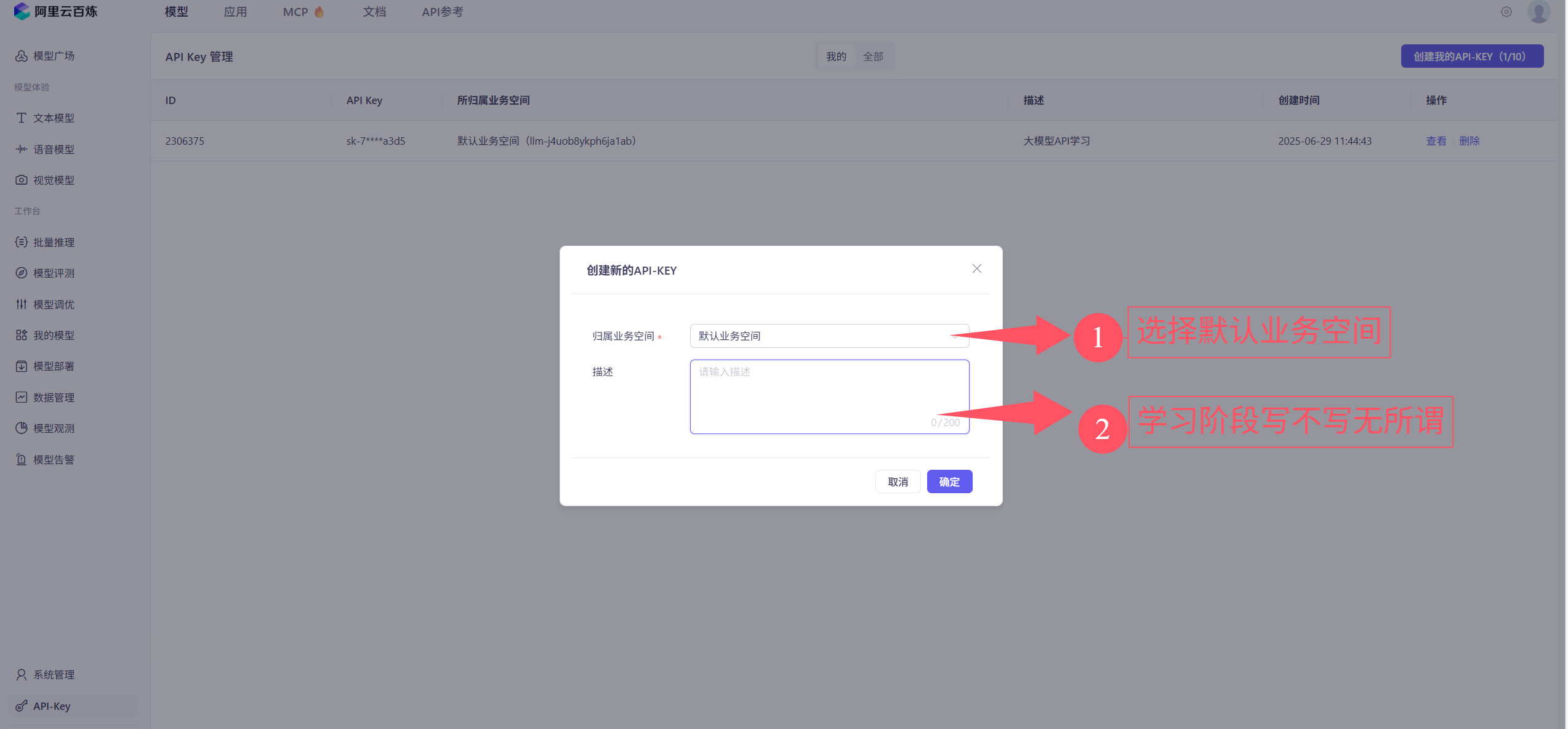
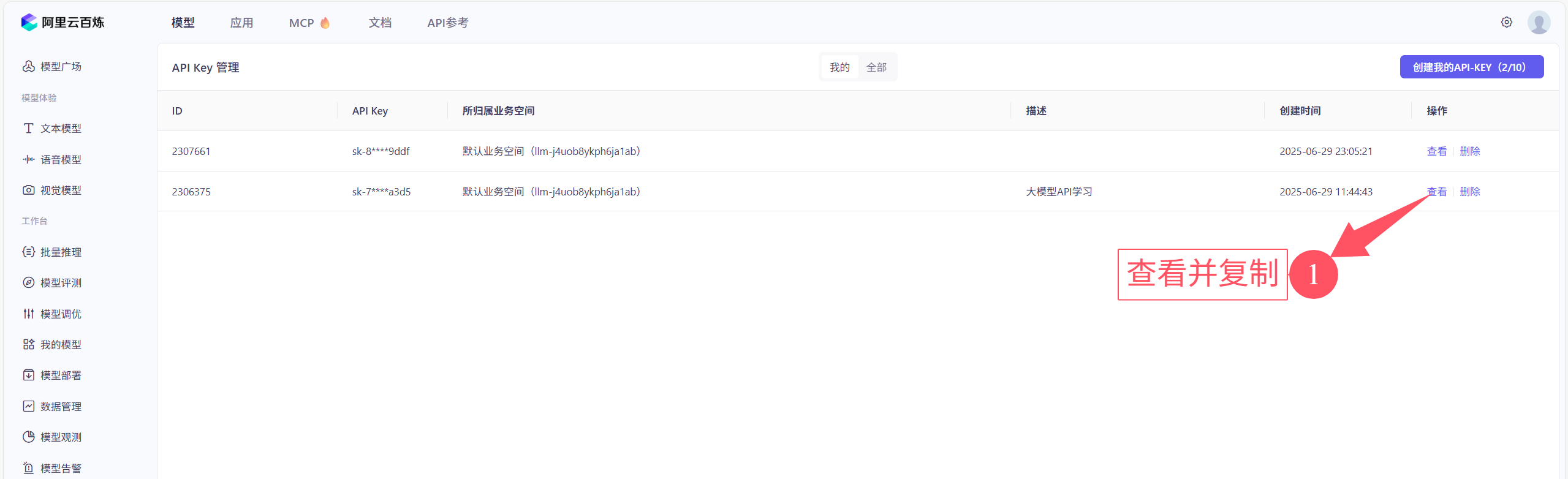
④创建和复制API-key
前问的API-key可以查看多次,但是建议大家把对应的API-key都建一个txt文件保存,使用的时候打开文件直接用就好了,没有那么麻烦。
三、代码实现:调用 DeepSeek 大模型
下面是调用 DeepSeek 大模型的完整代码示例:
# 导入OpenAI模块,用于调用OpenAI的API
from openai import OpenAI
# 使用指定的API密钥和基础URL创建OpenAI客户端实例
client = OpenAI(
# api_key:这是用于身份验证的 API 密钥。您需要使用有效的 API 密钥来向 DeepSeek 的 API 进行身份验证,以调用其服务。
# base_url:这是 DeepSeek API 的基础 URL。OpenAI 客户端将使用此 URL 来发送请求到 DeepSeek 的服务器。
api_key="替换成你自己的秘钥", base_url='https://api.deepseek.com/v1'
)
# 调用OpenAI的聊天完成接口
response = client.chat.completions.create(
model="deepseek-chat", # 指定使用的模型名称
messages=[ # 定义消息列表,包含系统角色和用户角色的消息
{"role": "system", "content": "我司AI智能助手,有什么需要帮助的吗?"}, # 系统角色消息
{"role": "user", "content": "什么是fastAPI"}, # 用户角色消息
],
stream=False # 设置非流式响应,回答的结果一次性输出
# stream=True # 设置流式响应,回答的一段一段输出
)
# 非流式输出
print(response.choices[0].message.content)
# 流式输出
# for chunk in response:
# print(chunk.choices[0].delta.content, end="", flush=True)
运行结果:
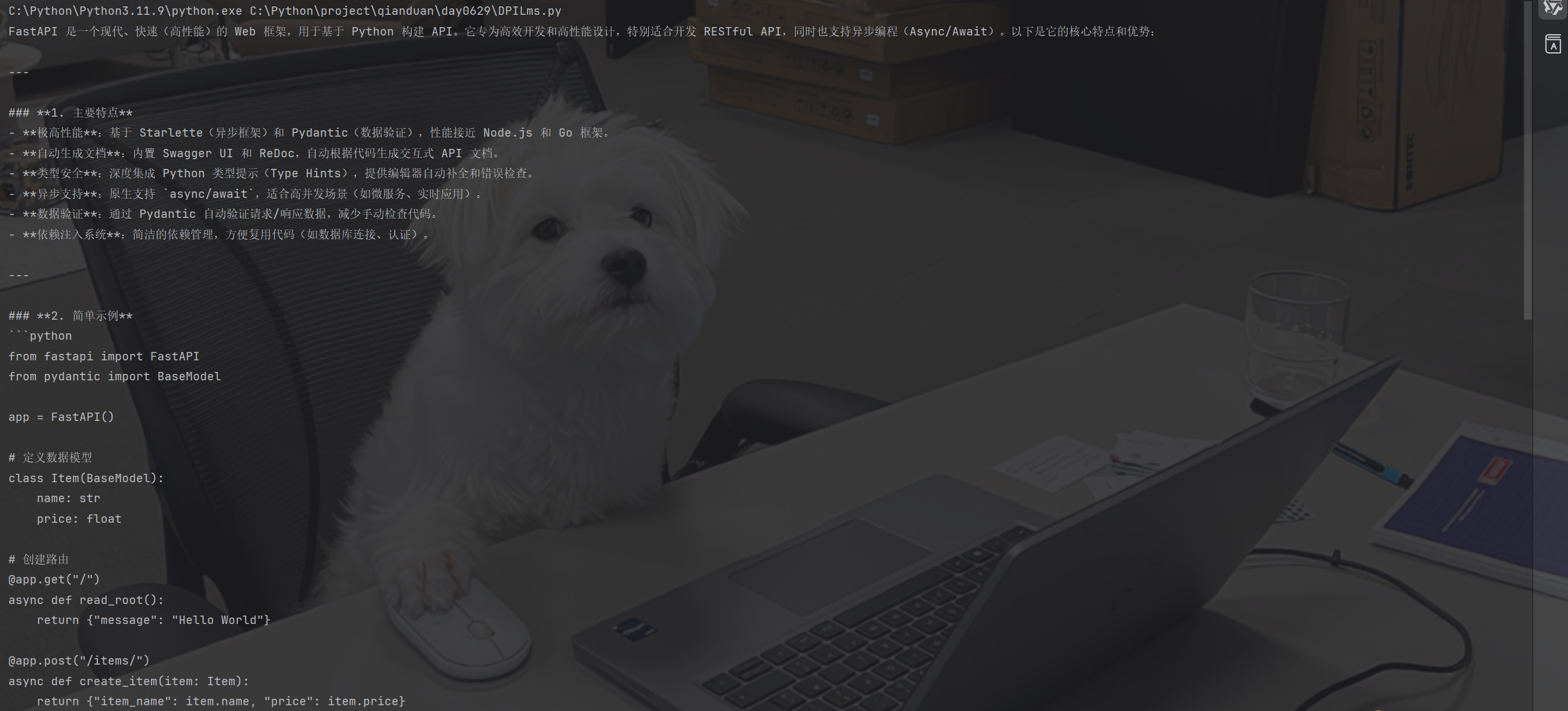
代码说明:
model参数指定要使用的模型,不同平台有不同的模型列表messages参数是对话历史,包含系统提示和用户消息stream=False表示一次性获取完整响应,适合简单问答场景
四、代码实现:调用阿里云通义千问
阿里云通义千问的调用方式类似,但需要注意基础地址和模型名称的差异:
import os
from openai import OpenAI
from dotenv import load_dotenv
# 加载环境变量(推荐方式)
load_dotenv()
client = OpenAI(
api_key=os.getenv("Qwen_API_KEY"), # 从环境变量获取密钥,防止API-key的泄露
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# 调用通义千问
completion = client.chat.completions.create(
model="qwen-plus", # 通义千问的模型名称
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "阿里云公司的简介"}
],
stream=True, # 流式输出,适合长文本响应
extra_body={"enable_thinking": False} # 控制思考过程
)
# 非流式输出
# print(completion.choices[0].message.content)
# 流式输出
for chunk in completion:
print(chunk.choices[0].delta.content, end="", flush=True)运行结果:

环境变量配置方法:
- 在项目根目录创建
.env文件 - 在文件中添加如下内容:
Qwen_API_KEY="你的阿里云API密钥"五、流式输出 vs 非流式输出:该怎么选?
代码中我们看到有stream=True和stream=False两种设置,它们的区别如下:
-
非流式输出(stream=False):
- 优点:一次获取完整结果,处理简单
- 缺点:等待时间长,不适合长文本生成
- 适用场景:短问答、快速查询
-
流式输出(stream=True):
- 优点:像聊天一样逐字显示结果,用户体验好
- 缺点:需要循环处理结果,代码稍复杂
- 适用场景:对话机器人、长文本生成
六、常见问题与解决方法
- API 密钥无效:检查密钥是否输入正确,是否过期(部分平台密钥有有效期)
- 连接超时:检查网络连接,确认 base_url 是否正确
- 权限不足:某些模型可能需要单独申请使用权限
- 密钥泄露风险:永远不要在代码中硬编码密钥,使用环境变量或配置文件管理

欢迎加入西安开发者社区!我们致力于为西安地区的开发者提供学习、合作和成长的机会。参与我们的活动,与专家分享最新技术趋势,解决挑战,探索创新。加入我们,共同打造技术社区!
更多推荐



 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)