
一文讲清楚 AI Agent 的核心概念:从 Token、Skill、RAG 到 MCP、SDD、Loop Engineering 和 Harness Engineering
一文讲清楚 AI Agent 的核心概念:从 Token、Skill、RAG 到 MCP、SDD、Loop Engineering 和 Harness Engineering
原创 智能体AI 智能体AI 智能体AI 2026年7月5日 08:00 湖南 19人
我最近收到一条私信,让我印象很深。
读者说他已经跟着各种教程学了三个月的 AI Agent,但感觉越学越乱——Token、RAG、MCP、Skill、SDD、Loop Engineering、Harness Engineering,这些名词好像每隔一段时间就会冒出一个新的,他看完一篇文章觉得懂了,再看下一篇又发现自己不懂。他问我:这些东西到底有没有一条主线?
有的。
但问题在于,大多数科普文章把这些概念当成平级的词条来解释,就像一本词典,解释完 A 再解释 B,读者看完还是不知道它们之间的关系。我认为这是一种根本性的叙事失败。
这些概念不是平行的,它们是一套分层递进的工程体系。每一层解决一个特定的问题,每一个新概念的出现都是因为上一层遇到了瓶颈。把这条主线理清楚,你会发现这些名词突然都有了各自落地的位置,不再互相干扰。
这篇文章,我就来把这条主线讲清楚。
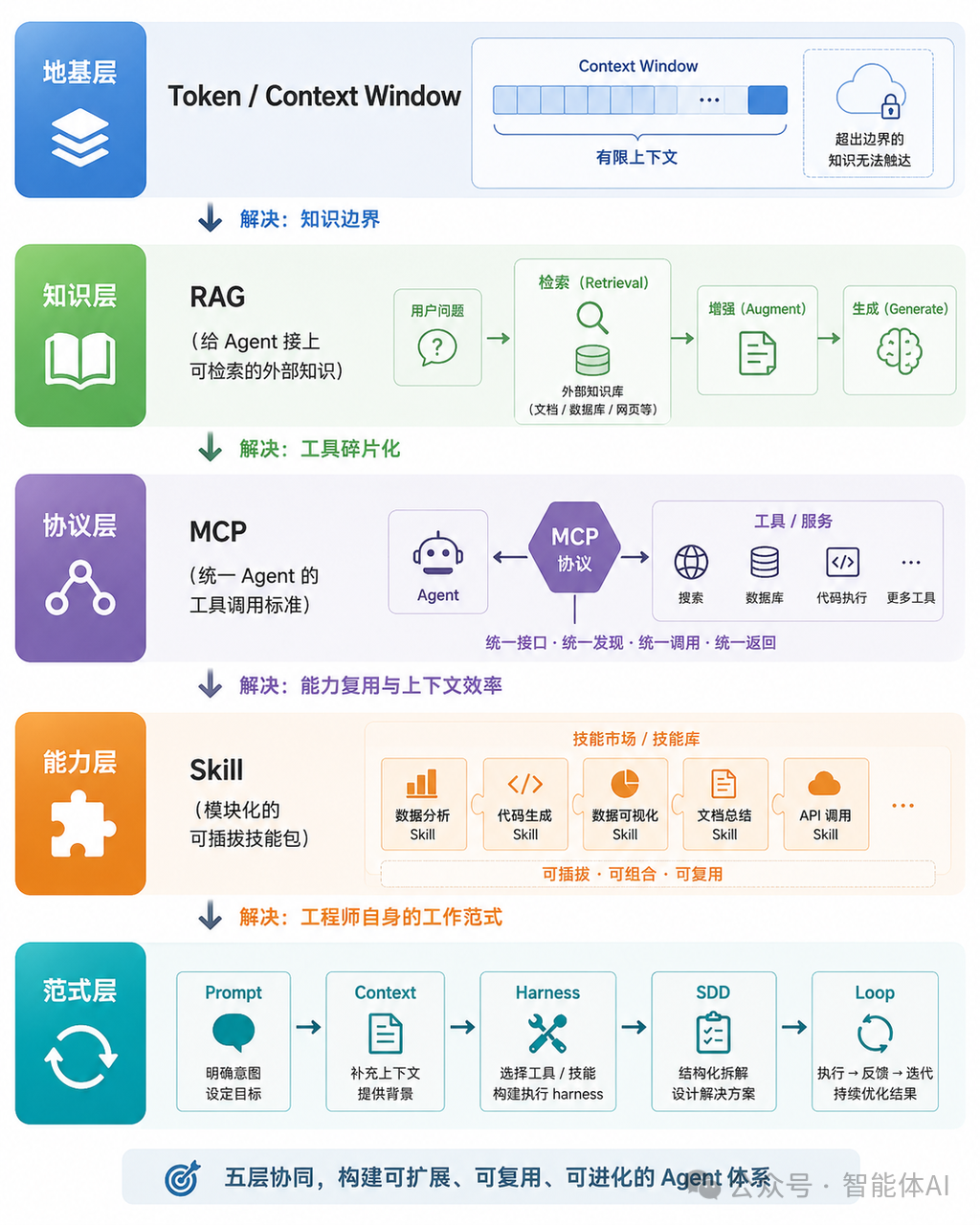
第一层:Token——一切的原材料,也是一切限制的根源
在讲任何 Agent 机制之前,必须先理解 Token。
很多人以为模型读的是"文字"。错。模型读的是 Token——把自然语言切分之后的最小单元。"人工智能"在中文分词里大概是 2-3 个 Token,一个英文单词通常是 1-2 个 Token。你现在读的这篇文章如果喂给模型,大概会是几千个 Token。
这个概念本身不复杂,但它有一个极其重要的推论:模型在任意一次推理中,能看见的 Token 数量是有上限的。 这个上限叫做 Context Window(上下文窗口)。
2024 年以前,主流模型的上下文窗口大概是 4K 到 32K Token,写一篇长文就能撑满。2025 年之后,Claude 支持 20 万 Token,Gemini 据称突破了 100 万。有人于是欢呼:上下文窗口问题解决了,后续那些什么 RAG、Memory 的机制都可以扔掉了。
这个判断是错的。窗口变大只是改变了权衡的起点,并没有消灭问题本身。把 100 万 Token 全部塞进去推一次,成本是多少?延迟是多少?把什么信息塞进去,又把什么排在外面?这些依然是工程问题,没有因为窗口变大而消失。
Token 是 AI 工程的原材料,也是所有后续机制存在的根本原因。理解了这一点,你才能理解为什么后面每一层都在做同一件事:在有限的 Token 预算里,放进去最有价值的信息。
第二层:RAG——给 Agent 接上一个可检索的"外脑"
模型训练完之后,它的知识就冻结在那一刻了。你问它昨天发生了什么,它不知道。你问它你们公司内部的产品文档,它更不知道。
RAG(Retrieval-Augmented Generation,检索增强生成)解决的就是这个问题。
它的思路非常朴素:在模型回答之前,先去外部知识库检索最相关的片段,把这些片段塞进上下文,再让模型基于这些材料回答。 模型本身没有变,只是临时"借阅"了一批外部资料。
你可以把 RAG 理解成给模型配了一个图书管理员。用户问问题的时候,图书管理员飞速跑去书架,把最相关的几本书的相关章节复印出来,塞进模型的视野里。模型看着这些资料,给出答案。
2025 年有一段时间,"RAG 已死"的论调甚嚣尘上。理由是:窗口这么大,干脆把整个知识库都塞进去,要什么检索?
但 2026 年的生产实践给出了明确的答案:RAG 没死,三个原因。
第一,成本。把 100 万 Token 全部加载一次,成本是检索相关片段的大约 100 倍。每天一千次查询,钱就烧光了。第二,延迟。超大上下文的推理速度明显慢于检索+短上下文组合,用户等不起。第三,新鲜度。RAG 可以随时更新知识库而无需重新训练模型,这对企业级应用至关重要。
RAG 在持续进化——Agentic RAG、GraphRAG、Contextual Retrieval——但底层逻辑没变:检索,然后增强。 它是 Agent 的"长期记忆外挂",解决的是知识边界问题,不是工具调用问题。这个区别很重要,后面会用到。
第三层:MCP——给工具调用立一个统一的标准
理解了 RAG,你可能会问:如果 Agent 要做的不是"查资料",而是"发一封邮件"、"往数据库里写一条记录"、"调一下外部 API",怎么办?
这就是 MCP(Model Context Protocol,模型上下文协议)要解决的问题。
在 MCP 出现之前,每个 Agent 框架调用外部工具的方式都不一样。A 框架这样调 GitHub,B 框架那样调 Slack,换一个工具就要重写一套对接代码。这就像全世界的插座规格都不一样,你带着一台中国手机去英国,还得买个转换头。
MCP 就是那个统一插座标准。 它定义了模型发现工具、调用工具、接收结构化结果的统一方式。工具厂商只需要实现一次 MCP 接口,所有支持 MCP 的 Agent 都能直接调用。
这和 RAG 是完全不同的两件事:RAG 是知识检索,MCP 是动作执行。一个让 Agent 知道更多,另一个让 Agent 做到更多。把这两者混淆是很多初学者最常犯的错误。
当然,MCP 带来能力的同时也带来了风险。当你给 Agent 接上 MCP 工具,它就拥有了执行真实操作的能力。工具被攻破,Agent 就可能成为攻击向量。这不是小事。2026 年的企业级 MCP 部署,代码审计、权限范围控制、操作日志、速率限制,这些都是标配,不是选配。
如果 RAG 是 Agent 的外脑,那 MCP 就是 Agent 的手。外脑让 Agent 懂得更多,手让 Agent 做得更多。
第四层:Skill——让 Agent 的能力可以打包、复用、按需加载
学到这里你可能会发现一个问题:Agent 每次启动,它怎么知道自己"会什么"?
如果 Agent 处理的任务类型很多——写代码、查数据、发邮件、生成报告——难道要把所有的规则和工作流都堆在一个超长的 System Prompt 里?那个 System Prompt 本身就要烧掉几千个 Token,而且里面大量内容在特定任务中根本用不到。
Skill 就是为了解决这个问题出现的。
Skill 是一个标准化的能力模块,核心是一个叫 SKILL.md 的文件,里面定义了执行特定任务的工作流和规则。 Agent 在推理前,先扫描当前任务,判断需要激活哪个 Skill,然后只把那个 Skill 的规则动态注入到上下文里。其他 Skill 的内容,一个字都不进上下文。
这个设计思路叫"渐进式披露"——信息不是一次性全部展开,而是按需加载。就像一名有二十年经验的医生,他脑子里装着皮肤科、骨科、心脏科等无数知识,但你来问骨折的问题,他只会调用骨科那部分知识来回答,不会把皮肤科的内容也说一遍。
Skill 的出现让 Agent 的能力从"单体"走向了"模块化"。这是 Agent 工程从玩具走向生产的重要一步。
范式演化:Prompt → Context → Harness → SDD → Loop
上面四层讲的是 Agent 的"零件"——Token 是材料,RAG 是外脑,MCP 是手,Skill 是技能包。
接下来要讲的,是工程师本人的工作方式是如何一步步演化的。这条演化线,我认为才是理解 AI Agent 的真正主线。
︱Prompt Engineering(2022-2023):你在优化那句话
最早期,所有人都在研究怎么写出一个好 Prompt。给模型的指令怎么措辞?怎么举例?怎么让它按你想要的格式输出?
Prompt Engineering 有它的价值,但它本质上只是在优化"你发给模型的那句话"。工程师的注意力集中在单次交互的质量上。
︱Context Engineering(2025):你在管理模型能看见的所有信息
随着任务复杂度上升,大家发现单次 Prompt 的优化已经不够用了。真正决定 Agent 表现的,是它在推理时能看见什么——历史对话、检索到的文档、工具返回的结果、当前任务状态……这些加在一起,才是真正意义上的"输入"。
Shopify 创始人 Tobi Lütke 给出了一个我认为最好的定义:Context Engineering 就是"为任务提供所有上下文,使其对模型而言是可以合理解决的"。
工程师的注意力从"优化那句话"转移到了"管理模型能看见的所有信息"。Prompt Engineering 变成了 Context Engineering 的一个子集。
︱Harness Engineering(2026 年初):你在为 Agent 搭建运行环境
光管理信息还不够。Agent 开始做自主、多步骤的任务之后,你必须思考:它在什么环境里运行?它有哪些工具?有哪些限制?它做错了怎么反馈?谁来检查它的输出?
这就是 Harness Engineering。
"Harness"这个词在英文里是"马具"或"安全带"的意思。Harness Engineering 就是给 Agent 配上一套"安全装备"——工具集、沙箱隔离、约束边界、反馈回路、可观测性追踪。没有这套装备,Agent 在生产环境里就是一个在无人区骑摩托的新手,随时可能翻车。
如果说 SDD 在回答"Agent 应该做什么",那么 Harness 在回答"Agent 应该在什么条件下做、做完怎么检查"。
︱SDD:Spec-Driven Development(2025-2026):让 Spec 成为唯一真相
2025 年之前,大多数人用 Agent 写代码的方式是这样的:跟 Agent 聊几句,看看它写了什么,不满意再改,改了再看,反复迭代。Andrej Karpathy 给这种方式起了一个名字:Vibe Coding。
Vibe Coding 在做原型的时候挺好用,但在生产环境里会翻车。原因很简单:Agent 没有长期记忆,没有对"意图"的稳定理解。 你今天跟它聊的方向,明天换一个会话就忘了。代码越来越多,前后越来越不一致,最后你发现自己在"自动化地制造遗留代码"。
SDD(Spec-Driven Development,规格驱动开发)就是为了解决这个问题。它的核心思想是:在让 Agent 动手之前,先写一份精确的、版本化的、可审查的 Spec(规格文档)。Agent 的所有实现都对着 Spec 来,而不是对着聊天记录来。
一个流传很广的说法是:"Spec 即 Prompt。" 这话乍听有点奇怪,但理解了 Vibe Coding 的失败模式,你就懂了——真正的 Prompt 不是你打在聊天框里那句话,而是那份精确定义了目标、约束、验收标准的 Spec 文件。
到 2026 年,GitHub Spec Kit、AWS Kiro、Claude Code、Cursor 都推出了自己的 SDD 工具链,DeepLearning.AI 开了专门的 SDD 课程。这个范式从"少数人的实验"走进了主流工程师的工作流。
︱Loop Engineering(2026 年 6 月):你不再是那个按回车的人
2026 年 6 月,一段话在开发者社区疯传。说这话的人是 Boris Cherny,Claude Code 的创始人:
"我不再直接提示 Claude 了。我有 Loop 在运行,是它们在提示 Claude,并决定做什么。"
这句话的信息密度极高,值得仔细解读。
过去两年,工程师使用 Agent 的方式是:发指令 → 看输出 → 发下一条指令。你是那个一直按着回车键的人,Agent 是你手里的工具。
Loop Engineering 把这个模式整个反过来。你不再是那个发指令的人,你设计的是那个代替你发指令的系统。 你定义目标(Goal),定义"完成"的可验证标准,定义预算上限,然后让 Loop 去运行——它自己找任务,分配给子 Agent,验证结果,记录状态,决定下一步,直到目标达成。
Addy Osmani 在给这个概念命名的文章里有一个比喻我很喜欢:如果你理解强化学习,这个东西一下就通了。你不是在告诉 Agent 每一步怎么做,你是在定义奖励函数——什么叫"对",什么叫"完成"——然后让 Agent 在你定义的环境里自己迭代。你的领域知识——你知道"正确"在你这个领域里意味着什么——才是真正的壁垒。模型是商品,奖励函数是你的。
Loop Engineering 与 Harness Engineering 的关系也值得说清楚:Harness 是为单次 Agent 运行装配环境,Loop 在 Harness 之上又加了一层——它跑在定时器上,会衍生出子 Agent,会自我反馈,会在多次运行之间积累状态。
Loop 是运转着的 Harness。
一个设计良好的 Loop,有六个必须想清楚的结构模块:
-
Goal Spec(目标定义):可验证的完成条件,不是"把这个功能做好",而是"所有测试通过、覆盖率超过 80%、没有安全扫描报警"
-
Action(动作执行):Agent 在每轮迭代里做什么
-
Feedback(反馈机制):外部信号如何告诉 Loop 当前进展
-
Stopping Rule(停止规则):什么时候判定"完成",什么时候判定"无法完成"——这一条是最多人漏掉的,也是最危险的漏洞
-
Memory(记忆持久化):每轮运行之间的状态保存在哪里,因为模型本身不记得上一轮做了什么
-
Governance & Cost(治理与成本):Token 预算上限、权限边界、人工介入触发条件
这里有一个反直觉的结论,很多 Loop Engineering 的文章都没有点透:Loop 的瓶颈不在模型,在验证器。 一个 Loop 能不能自主运行而不翻车,关键在于你有没有一套可靠的、独立于执行 Agent 的验证机制来判断"完成了"。让执行者自己评判自己的作业,这在任何工程体系里都是大忌。
2026 年,AI 工程师的真正稀缺能力是什么?
我的判断是:不是会用工具,是会定义"完成"。
模型越来越强,工具越来越多,Prompt 越来越容易写。但有一件事没有变,也不会变:你得知道你在这个领域里什么叫做"对"。 RAG 检索到的资料好不好,你得判断。SDD 的 Spec 写得够不够精确,你得审。Loop 的停止条件设没设对,你得验证。
Boris Cherny 说"我的工作是写 Loop",但他没说的是:能写出好 Loop 的人,一定是对自己领域有深刻理解的人。Loop 只是杠杆,撬动的还是你自己的专业判断。
工具换了,但工程师的核心价值没换——你知道在你的问题域里,什么叫做好。
这,才是 2026 年最难被替代的能力。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐

 0
0 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)