
2026 上半年,真正变工作流的不是 ChatGPT,而是 Agent:Codex 最新使用数据透露了什么?
这半年如果你还把 AI 理解成一个更聪明的聊天框,说实话,已经有点像 2024 年还在认真争论“云计算是不是伪需求”了。
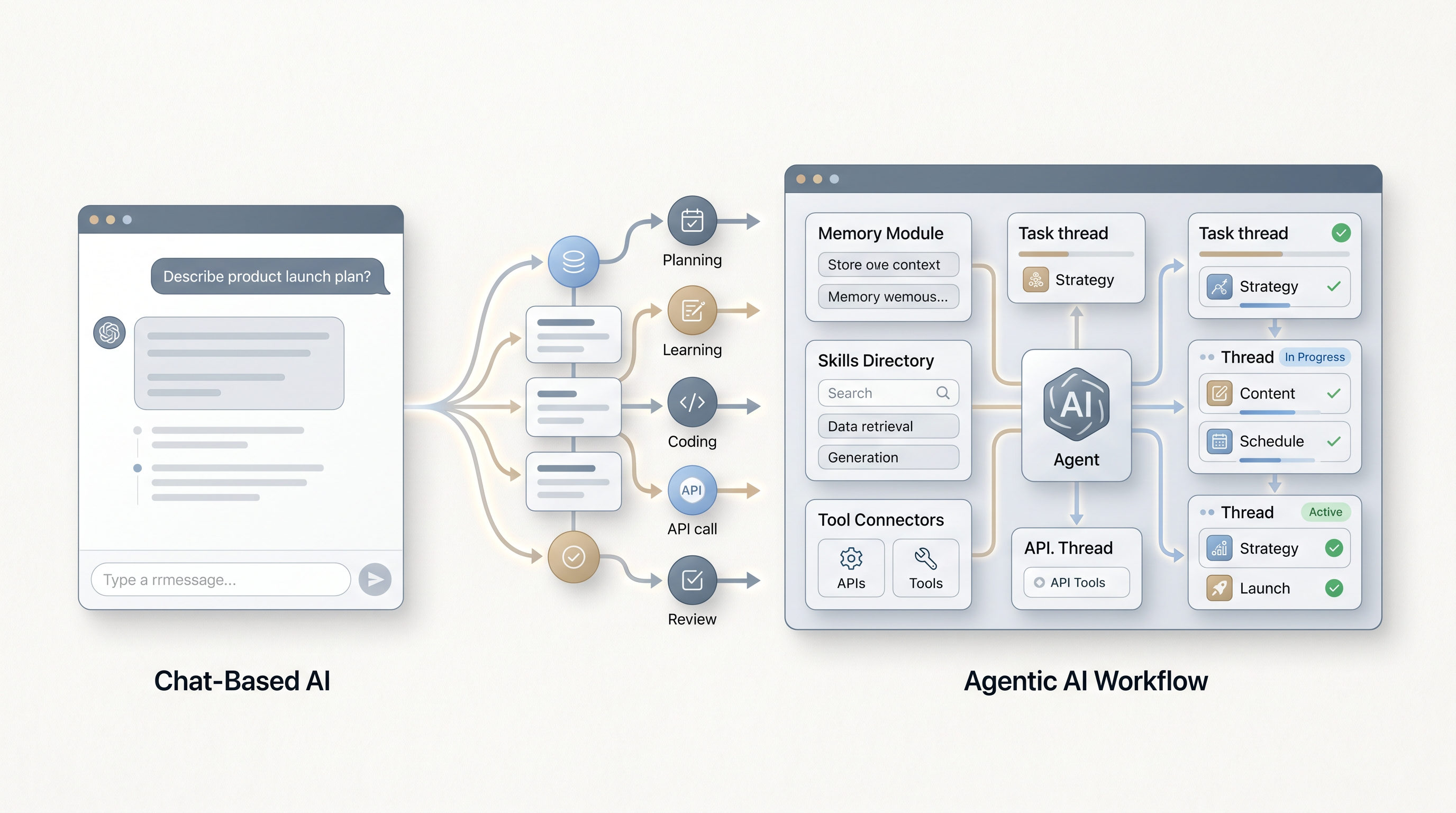
不是说聊天没用了。聊天当然还有用,甚至依然是绝大多数人接触 AI 的第一入口。问题是,真正开始改变工作方式的,已经不是“我问一句,它答一句”这件事,而是另一件更像生产工具的事:
AI 开始替你接任务、拆任务、并行跑任务,最后把结果交回来。
这听起来像一句很容易被说油的趋势判断,但最近 OpenAI 那篇新论文,倒是给了一个挺硬的观察窗口。论文名字叫《The Shift to Agentic AI: Evidence from Codex》,它不是在聊概念,而是在看真实使用数据里,到底发生了什么。
我看完后的第一反应是,这事已经不是“Agent 会不会来”了,它已经来了,只是很多人还在拿聊天的脑回路理解它。
一,Codex 数据里最值得注意的,不是用户变多,而是使用方式变了
论文里有几个数字很值得记一下。
第一,2026 年上半年,Codex 的活跃用户增长超过 5 倍。这当然重要,但还不是最有意思的部分。更有意思的是,增长最快的地方已经不只是传统的软件开发者圈子了,而是在往更广泛的组织场景外溢。
第二,超过 10% 的用户,每周会同时管理 3 个或更多并发 Codex agent。这句话翻成人话就是,已经有一批人不再把 AI 当单线程助手用了,而是在把它当一个可以同时开分身的执行系统。
第三,26.6% 的用户开始用 skills。这也很关键。因为 skill 这个东西,说到底不是给模型“加点设定”那么简单,它代表的是一件更工程化的事:用户开始把自己的工作方法、规则和流程,封装成能反复调用的资产,而不是每次重新打一遍 prompt。
第四,论文还提到一个很猛的变化,提交至少一个“对有经验的人类来说预计超过 8 小时”的任务的用户占比,比年初提高了接近 10 倍。这很说明问题。大家不再只是拿 AI 写段文案、改个函数、查点资料了,而是在试着把更大块、更完整、更像项目的事情丢给它。
所以这篇论文最有价值的地方,不是证明 Codex 火了,而是证明一件事:
用户对 AI 的期待,正在从“回答”切到“执行”。
这不是语义差别,这是产品范式差别。
二,为什么“Agent 化”会比“模型更强了”更重要
这几年 AI 领域有个很常见的错觉,大家特别喜欢把变化理解成“模型又更强了一点”。好像只要上下文更长、推理更稳、价格更低,这一轮就算进步。
但很多时候,真正改造工作流的,不是模型参数又涨了多少,而是交互结构变了。
聊天式 AI 的核心逻辑,其实很简单:
- 你发起
- 它响应
- 你继续追问
- 它继续补全
整个流程里,AI 更像一个高级响应器。
可一旦进入 Agent 模式,结构就完全不一样了。它会开始:
- 自己读取上下文
- 自己决定下一步该查什么
- 自己调用工具
- 自己把一个大任务拆成多个子任务
- 甚至自己并行推进几个支线
这就像什么呢。
以前你面对的是一个极其聪明的顾问,现在你面对的是一个会自己起表格、开线程、找资料、跑命令、还会回来汇报进度的同事。这个同事当然也会犯错,甚至有时候会一本正经地拐进沟里,但它的角色已经变了。
从“答题者”变成“执行者”,这是这轮变化真正的重心。
所以我一直觉得,2026 上半年最重要的 AI 变化,不是“又出了哪个新模型”,而是越来越多的人开始重新设计自己和 AI 的协作边界。
三,为什么 skills、记忆、资产包会一起冒出来
这其实是同一件事的连锁反应。
你让 AI 陪你聊十分钟,prompt 足够。
你让 AI 跟你一起做半天项目,prompt 立刻不够。
原因很简单,任务一变长,问题就全冒出来了:
- 上下文怎么不丢
- 固定流程怎么复用
- 不同任务之间怎么继承经验
- 哪些规则要靠模型理解,哪些规则必须靠脚本兜底
- 换一个 agent 以后,之前那套工作方法怎么迁过去
这也是为什么最近大家开始同时讨论这些关键词:
- skill
- memory
- workspace asset
- sub-agent
- orchestration
表面看是五六个话题,底层其实是一个问题:
当 AI 不再只是陪你聊天,而是开始介入持续工作流时,临时对话就装不下全部方法论了。
这时候就必须把一部分东西从“当场说的话”,升级成“可沉淀的结构”。
比如 skill,本质上是在沉淀流程。
比如 agent memory,本质上是在沉淀上下文。
比如资产包,本质上是在沉淀项目状态、规则、模板和依赖关系。
最近有个叫 EverOS 的项目,其实就是这个方向的一个很典型信号。它试图把 agent 的记忆做成 Markdown-first 的运行时,再配合 BM25 和向量检索,把“记住什么、什么时候想起来、怎么形成可复用技能”这件事体系化。
你会发现,大家现在不再满足于“模型真聪明”,而是开始认真处理“模型怎么长期稳定地干活”。
这就很像软件开发从脚本时代走向工程时代的那一步。前面拼的是灵感,后面拼的是结构。
四,普通团队真正该改的,不是换模型,而是换工作流颗粒度
这个地方是我觉得最容易被讲虚的,所以我尽量讲实一点。
如果你今天是一个开发者、内容团队、运营团队,看到 Agent 这个趋势,最有用的动作不是立刻去问“我该买 Claude 还是 Codex 还是 Gemini”,而是先反过来问:
我现在的工作流里,哪些环节已经适合被拆出来,交给 agent 长期接手?
通常有三类最适合先改。
第一类,重复但不完全机械的活。
比如:
- 固定格式的日报、周报
- 选题整理和资料初筛
- 多版本文案改写
- Bug 初步定位和仓库检索
第二类,需要多步推进的活。
比如:
- 先搜资料,再归纳,再输出草稿
- 先读文档,再调接口,再整理返回结果
- 先拆任务,再并行跑几个支线,再汇总
第三类,需要和外部工具协作的活。
比如:
- 调 API 生图、生视频
- 读写本地文件
- 跑脚本、查日志、做校验
这三类事情,一旦你还用“单轮 prompt”思路去处理,迟早会越来越别扭。不是模型不够强,是交互单元太小了。
真正顺手的方式,是把它们拆成:
- 稳定的触发条件
- 清晰的输入输出
- 可复用的 skill
- 必要的脚本 guardrail
- 能继承上下文的资产包
这时候 agent 才不像“偶尔灵一下的黑箱”,而像一个能被接进组织流程的系统。
五,多模型生成能力,适合放在 Agent 工作流的哪一层
这个问题其实很实际。
很多团队现在不是没有模型,而是模型太多了。写作、配图、海报、视频、封面、商品图,各有各的强项。你真让一个内容工作流跑起来,最后会发现瓶颈通常不是“有没有 AI”,而是“怎么把这些能力组织得别那么散”。
所以这里就会出现一种很实用的工具形态,不是再多一个单点模型网站,而是一个把生图、生视频和多模型调用统一收口的平台。
像 iMini AI这种一站式生图生视频聚合平台,本质上更适合被理解成 Agent 工作流里的一层“多模型执行接口”。它的价值不在于让你多开一个网页,而在于把不同模型的调用入口、测试动作和执行链路尽量收在一起。
不是拿它当 headline,而是把它放在一个很顺的位置上:
- 上层是任务拆解和流程编排
- 中层是 skill、记忆和规则
- 下层是具体模型调用
这样你就不会每次做图、做视频、测模型,都重新切平台、重配参数、重接一遍流程。对内容团队来说,这种统一入口的价值,往往比“单个模型榜单排名第几”更实际。
换句话说,大家以后比拼的,未必是谁找到一个最神的模型,而是谁先把一整条工作流接顺。
六,最后说个不那么玄乎的判断
过去我们总爱问,AI 到底能不能替代一部分工作。
我现在反而觉得,这个问题有点老了。
更接近现实的问题应该是:
哪些工作已经开始被重新切块,好让 Agent 接进去。
Codex 这篇论文给出的信号很明确,越来越多用户已经不把 AI 当聊天伙伴,而是当成执行系统来用。并发 agent、skills、超长任务、组织内渗透,这些都不是热词堆砌,它们其实是在描述同一个转向。
AI 不是突然变成了一个无所不能的数字员工。别神化,这玩意儿离“无所不能”还差得远。
但它确实已经不再只是一个会说漂亮话的聊天框了。
而这,大概才是 2026 上半年真正值得认真看的变化。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 2
2 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)