
【全域智能营销实战】1、全域智能营销决策平台技术选型:为什么是 Spring AI + OpenClaw + Hermes + Harness?
全域智能营销决策平台技术选型:为什么是 Spring AI + OpenClaw + Hermes + Harness?
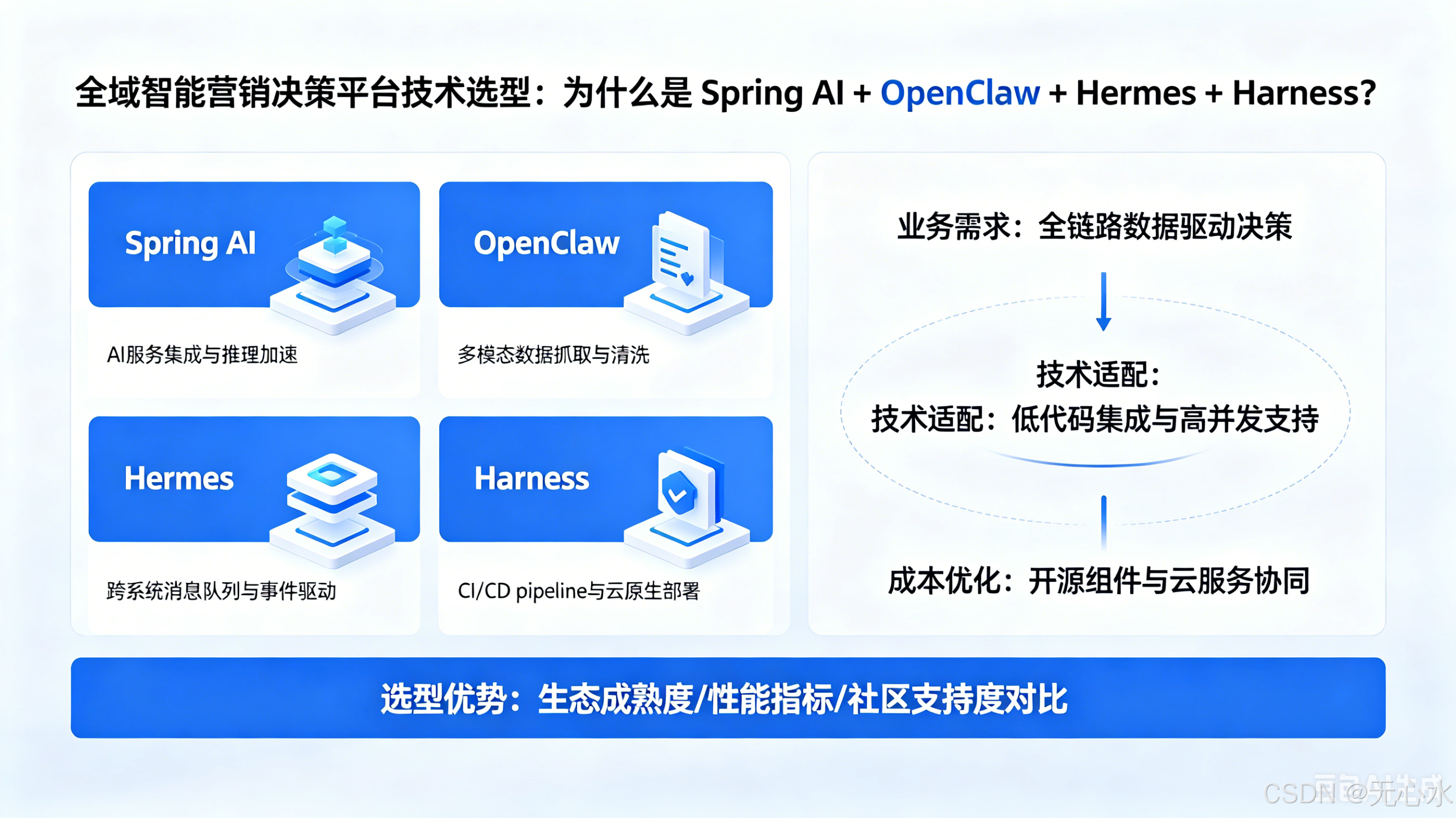
从架构蓝图到技术落地的完整决策链
📑 目录
- 一、引言:架构蓝图很美,技术选型怎么破?
- 二、回顾 Uni-MDP 总体架构:各层对技术栈的核心诉求
- 三、Spring AI:不止是“又一个 AI 框架”
- 四、四个开源项目的分工与选型逻辑
- 五、技术栈总览
- 六、系列文章路线图
- 七、总结:选型背后的思考
一、引言:架构蓝图很美,技术选型怎么破?
在上一篇文章中,我们完成了全域智能营销决策平台(Uni-MDP) 的架构设计——从数据层到交互层,六层三纵的完整架构蓝图已经铺开。
但架构图再漂亮,终究要落到代码层面。
一个现实的问题是:这些架构层分别用什么技术栈来实现? 是用 LangChain 还是 Spring AI?消息接入层是自己写 Webhook 还是用现成的框架?决策引擎用 Hermes 还是自己实现一套 ReAct 循环?可控性怎么保证?
这篇文章,我来详细拆解 Uni-MDP 的技术选型决策过程。为什么最终选择了 Spring AI + OpenClaw + Hermes + Harness 这套组合? 每个组件解决什么问题?它们之间如何协同?
本文是系列文章 《全域智能营销决策平台落地实战》 的第 1 篇,后续将逐篇深入代码实现。
二、回顾 Uni-MDP 总体架构:各层对技术栈的核心诉求
在开始选型之前,我们先快速回顾 Uni-MDP 的总体架构,明确每一层对技术栈的核心诉求。
各层对技术栈的核心诉求可以归纳为:
| 架构层 | 核心诉求 | 关键问题 |
|---|---|---|
| 交互层 | 多端适配、实时响应 | 前端框架选型、WebSocket 通信 |
| 应用层 | 业务编排、低代码 | 工作流引擎、规则引擎 |
| 中台层 | 能力复用、高并发 | 微服务框架、分布式事务 |
| 算法层 | 模型推理、在线学习 | LLM 集成、MLOps |
| 数据层 | 数据采集、治理、服务化 | 数据管道、特征存储 |
| 算力层 | 弹性计算、资源调度 | 混合计算、GPU 管理 |
| 基础设施层 | 高可用、可观测 | 服务治理、监控告警 |
其中最核心的挑战在于算法层和中台层的衔接——如何让 Java 生态的微服务高效地调用 LLM 能力?如何管理多模型的路由和切换?如何将 AI 的决策结果无缝对接到业务中台?
这正是 Spring AI 要解决的问题。
三、Spring AI:不止是“又一个 AI 框架”
3.1 Spring AI 的定位:AI 能力的 Spring 化抽象
很多人第一次看到 Spring AI 时,会问:“这不就是 Java 版的 LangChain 吗?”
这个理解对,但不全对。
Spring AI 的核心定位不是“又一个 AI 框架”,而是 AI 能力的 Spring 化抽象。它的设计目标非常明确:让 Java/Spring 开发者用他们熟悉的方式调用 AI 能力,就像使用 Spring Data 访问数据库、使用 Spring Cloud 调用微服务一样自然。
核心抽象接口包括:
ChatClient:统一的对话式 AI 调用接口,支持同步、响应式流(Reactive Streams)等多种调用模式EmbeddingClient:统一的文本向量化接口ImageClient:统一的图像生成接口ToolCallback:统一的工具/函数调用接口
这种抽象的价值在于:换模型就像换数据库驱动一样简单——只需要改一行配置,不需要改动业务代码。
3.2 2025 年模块化重构:从“大而全”到“按需引入”
2025 年,Spring AI 完成了一次根本性的模块化重构,这对企业级集成至关重要。
重构前的问题:spring-ai-core 包含所有核心接口,无论你用不用都得引入,导致应用臃肿、依赖冲突频繁。
重构后的模块结构:
| 模块 | 职责 | 依赖关系 |
|---|---|---|
| spring-ai-commons | 基础模块:核心领域模型、JSON 工具、可观测性支持 | 无依赖 |
| spring-ai-model | AI 功能抽象:ChatModel、EmbeddingModel、ToolCallback | 依赖 commons |
| spring-ai-vector-store | 向量数据库统一抽象 | 依赖 model |
| spring-ai-client-chat | 高级对话 API:ChatClient、Advisor 链 | 依赖 model |
| spring-ai-advisors-vector-store | RAG 支持:QuestionAnswerAdvisor | 依赖 client-chat + vector-store |
| spring-ai-rag | RAG 综合框架 | 依赖 client-chat + vector-store |
这种模块化设计的核心好处是:你只需要引入你真正用到的模块。比如只做基础对话,只需要 spring-ai-client-chat;需要 RAG,再引入 spring-ai-rag。
截至 2025 年 4 月,主分支的模块和构件结构已发生重大变化。以前
spring-ai-core包含所有核心接口,现在已拆分为专门的领域模块,以减少应用程序中的不必要依赖。
3.3 Spring AI 2.0:工具调用的 Agentic 架构
2026 年 6 月,Spring AI 2.0.0 GA 正式发布。这次升级对 Uni-MDP 来说意义重大——它将工具调用(Tool Calling)从“埋藏在模型实现中的私有逻辑”提升为“一等公民”。
1.x 时代的问题:每个 ChatModel 实现都包含自己的工具执行循环,功能是有的,但“埋得太深”——你无法钩入、无法观测中间步骤、无法组合其他行为。
2.0 的革新:将工具循环提升到 Advisor 链中,成为可组合的一流组件。
ToolCallingAdvisor 的工作原理:
- 提取所有
@Tool注解的方法,生成工具定义(名称、描述、输入参数的 JSON Schema) - 将工具定义注入到初始上下文(与用户问题和系统提示一起)
- 每次迭代:将累积的对话历史发送给 LLM
- LLM 返回结果——如果包含工具调用,
ToolCallingManager执行对应工具,追加结果到对话历史,继续循环 - 如果返回结果不包含工具调用,将最终答案返回给用户
这为 Uni-MDP 带来的核心价值:我们可以用 Spring AI 2.0 的 Advisor 链机制,标准化地实现 Agent 的 ReAct 循环,而不需要自己手写状态机。
四、四个开源项目的分工与选型逻辑
在 Uni-MDP 的架构中,四个开源项目各司其职、协同工作:
4.1 OpenClaw:消息接入层与渠道网关
选型理由:OpenClaw 是一个开源的、可自托管的 AI Agent 运行时,核心定位是将 LLM 连接到多样化的消息平台和本地工具。
在 Uni-MDP 中的职责:承担“消息接入层+渠道网关”——统一处理飞书、钉钉、企微、Telegram、Slack 等多渠道消息。
核心架构:
| 组件 | 职责 |
|---|---|
| Gateway | 单个长期运行的 Node.js 进程,管理所有入站和出站通信 |
| Channel | 抽象协议特定的集成(WhatsApp、Telegram、Slack 等) |
| Agent | 编排对话逻辑和决策 |
| Skill | 可扩展的模块,用于工具执行 |
Gateway 的核心机制:
- 单一 Gateway 拥有所有消息接口(WhatsApp、Telegram、Slack、Discord 等)
- 通过 WebSocket 暴露类型化的 API(请求、响应、服务端推送事件)
- 发出
agent、chat、presence、health、heartbeat、cron等事件 - 每台主机一个 Gateway,是唯一开启消息会话的地方
为什么选 OpenClaw 而不是自己写 Webhook?
| 对比维度 | 自己实现 | OpenClaw |
|---|---|---|
| 渠道适配 | 每个渠道单独开发 | 内置 10+ 渠道适配器 |
| 会话管理 | 自己维护状态 | 内置会话管理与持久化 |
| 消息可靠性 | 自己实现重试/幂等 | 内置幂等性 key 与去重缓存 |
| 可观测性 | 自己埋点 | 内置 health/heartbeat 事件 |
| 开发周期 | 数周 | 数小时 |
4.2 Hermes:自进化决策引擎
选型理由:Hermes Agent 是首个实现“自我进化”的 AI 智能体,上线半年 GitHub 星标破 10 万。其核心差异化能力是 从执行轨迹中自动提炼并持续优化技能的学习闭环。
在 Uni-MDP 中的职责:承担“自进化决策引擎”——内置学习循环,能从任务经验中提炼 Skill,实现“越用越聪明”。
核心子系统:
子系统一:Skill Auto-Generation(技能自动生成)
当任务执行中调用了 5 次以上工具、出现错误并自行修复、或用户进行了纠正反馈时,系统会触发技能生成。Agent 将本次任务的执行轨迹进行提炼,生成标准化的 SKILL.md 文件。
子系统二:Skill Self-Evolution(技能持续进化)
技能生成后并非一成不变。Hermes 内置了一套离线批量进化算法(基于 DSPy 框架和 GEPA 核心算法),会定期对已有技能进行复盘和优化。
子系统三:Nudge Engine(提醒引擎)
任务完成后的“反思触发器”,定时提醒 Agent 回顾近期执行记录,判断是否有值得沉淀的经验。
实际效果:如果你让 Hermes 写一个部署脚本,遇到依赖版本兼容性问题并成功解决,系统会自动将“问题的现象、排查步骤、最终解决方案”写成技能文件。下次再执行类似任务时,Agent 会直接绕过这个坑,Token 消耗可能从 12 次工具调用降至 6 次。
为什么选 Hermes 而不是自己实现学习循环?
| 对比维度 | 自己实现 | Hermes |
|---|---|---|
| 技能自动生成 | 需手写规则引擎 | 内置触发条件与提炼逻辑 |
| 技能进化 | 需自己实现反馈回路 | 内置 DSPy + GEPA 算法 |
| 记忆管理 | 需自己设计三层存储 | 内置三层记忆架构 |
| 学习触发 | 需自己定义触发机制 | 内置 Nudge Engine |
4.3 Harness:可控性框架
选型理由:Harness Engineering 是 2026 年 AI 工程化的核心范式。其核心公式是 Agent = Model + Harness——再强大的模型,若没有适当的约束与引导,也难以发挥实际价值。
在 Uni-MDP 中的职责:承担“可控性框架”——提供约束、验证、审计能力,确保 AI Agent 在安全边界内运行。
Harness 的三大控制维度:
在 Uni-MDP 中的落地方式:
| Harness 维度 | Uni-MDP 实现 |
|---|---|
| 认知框架 | 通过 AGENTS.md 定义 Agent 的角色、目标、行为准则 |
| 能力边界 | Spring AI 的 ToolCallback 白名单 + 工具调用权限校验 |
| 行为流程 | Spring AI 2.0 的 Advisor 链实现“规划→执行→验证”标准化流程 |
| 审计 | 全量记录工具调用、决策路径,满足合规要求 |
4.4 Spring AI:集成胶水层
选型理由:前面三个项目(OpenClaw、Hermes、Harness)各有所长,但它们分别用 TypeScript、Python 和“方法论”实现——如何将它们整合到一个统一的 Java 微服务体系中?
这正是 Spring AI 的职责。
在 Uni-MDP 中的职责:承担“集成胶水层”——统一管理模型调用、配置、生命周期。
具体集成方式:
- Spring AI → OpenClaw:通过
ToolCallback将 OpenClaw 的 Skill 注册为 Spring AI 的工具,实现统一调用 - Spring AI → Hermes:通过
ChatClient调用 Hermes 的 Python 服务(HTTP/gRPC),或将 Hermes 核心逻辑移植为 Spring Bean - Spring AI → Harness:通过 Advisor 链实现约束校验、权限检查、审计日志
五、技术栈总览
基于以上选型分析,Uni-MDP 的完整技术栈如下:
各语言/框架的职责边界:
| 技术组件 | 语言/框架 | 核心职责 |
|---|---|---|
| Spring Boot 3.x | Java | 微服务基座、业务中台实现 |
| Spring AI 2.0 | Java | 统一模型调用、工具注册、Advisor 链 |
| OpenClaw | TypeScript/Node.js | 多渠道消息接入、会话管理 |
| Hermes | Python | 自进化决策引擎、学习循环 |
| Harness | 配置文件 (YAML/Markdown) | 约束规则、行为准则 |
| Flink | Java/Scala | 实时数据流处理 |
| ClickHouse | C++ | 实时 OLAP 分析 |
| Kubernetes | Go | 容器编排与弹性伸缩 |
六、系列文章路线图
本文是系列文章的第 1 篇,后续 11 篇将从架构到代码逐层深入:
| 序号 | 主题 | 核心内容 |
|---|---|---|
| 第 1 篇 | 技术选型(本文) | 为什么是 Spring AI + OpenClaw + Hermes + Harness |
| 第 2 篇 | Spring AI 模块化架构 | 从 1.0 到 2.0 的演进、模块拆分、核心抽象 |
| 第 3 篇 | OpenClaw 源码解析 | Gateway、Agent、Skill、Memory 四大模块 |
| 第 4 篇 | Hermes 源码拆解 | 学习循环、三层 Prompt、Skill 自改进 |
| 第 5 篇 | Harness 工程实践 | 三大控制维度的代码落地 |
| 第 6 篇 | 统一数据模型设计 | User、Session、Memory、Skill、Task 五大实体 |
| 第 7 篇 | Spring AI + OpenClaw 集成 | 统一消息网关与多渠道接入 |
| 第 8 篇 | Spring AI + Hermes 集成 | 自进化能力注入营销决策引擎 |
| 第 9 篇 | Harness 约束层实现 | 安全可控的执行环境 |
| 第 10 篇 | 三大引擎协同工作流 | 从用户消息到智能决策的完整链路 |
| 第 11 篇 | 营销决策场景实战 | 新客欢迎、加购催付、流失召回 |
| 第 12 篇 | 生产部署与可观测性 | 从开发到上线的完整 Checklist |
七、总结:选型背后的思考
回顾整个选型过程,核心决策逻辑可以总结为以下三点:
7.1 不重复造轮子,但要能掌控轮子
消息接入层有 OpenClaw,决策引擎有 Hermes,可控性有 Harness——这些都是开源社区已经验证过的成熟方案。我们的策略是 “拿来主义 + 深度集成” :用 OpenClaw 解决渠道适配的“脏活累活”,用 Hermes 解决自进化的复杂逻辑,用 Spring AI 把它们“粘”在一起。
但“拿来”不等于“黑盒使用”。后续文章会深入每个项目的源码,确保我们有能力修改和扩展。
7.2 统一抽象优于分散实现
如果不用 Spring AI,我们可能需要:
- 为 OpenAI 写一套调用代码
- 为 Anthropic 写另一套
- 为 Ollama 再写一套
- 工具调用逻辑每个模型单独实现
Spring AI 的抽象层让这一切统一了。换模型就像换数据库驱动——这是企业级系统的基本要求。
7.3 架构设计要为 5-8 年预留空间
Spring AI 2.0 的 Advisor 链机制、Hermes 的自进化能力、Harness 的可控性框架——这些都不是“当下够用”的方案,而是面向未来的架构。它们的设计都考虑了扩展性,能够在未来 5-8 年内持续演进,而不会因为技术债务被迫重构。
下一篇预告:我们将深入 Spring AI 的模块化架构,从 1.0 到 2.0 的演进路径、核心抽象层的设计哲学,以及如何用 Spring AI 2.0 的 Advisor 链实现 Agent 的 ReAct 循环。
敬请期待!🚀
📌 本文收录于专栏:从 OpenClaw 到 Hermes:自改进 Agent 完全指南

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 0
0 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)