
如何提高AI生成测试用例的质量,我总结了这套思路...
现阶段很多测试同学都会用大模型辅助编写测试用例,但大家应该都遇到过同一个问题:同样让AI生成用例,别人产出的内容贴合业务、覆盖全面,自己得到的用例却残缺不全、脱离实际,甚至完全无法直接使用。
其实抛开大模型本身的能力差异,核心关键点只有一个:AI生成用例的质量上限,永远由原始需求决定。
如果需求资料零散杂乱、关键交互缺失、页面状态不完整,哪怕使用顶级大模型,也无法输出专业、完整、适配业务场景的测试用例。
一、当下团队需求承载现状
目前绝大多数互联网及传统研发团队,都不会只用单一格式传递需求。日常工作中,产品的需求、原型、交互逻辑,基本分散在各类主流协作平台中:
-
文字需求:飞书文档、Word、PDF
-
UI设计&交互:蓝湖、Figma
-
业务原型:Axure
但市面上绝大多数通用AI工具,都存在同一个硬伤:无法直接解析外部平台链接。没办法直接读取原型、设计稿内的页面元素、交互规则、隐性状态。
二、传统处理方式的弊端
为了解决这个问题,绝大多数测试人员只能采用最原始的方式:手动搬运需求。
逐段复制文字需求、单独截图保存页面、手动导出原型页面,再统一打包投喂给AI。这种模式看似能解决问题,实则弊端非常明显:
-
效率极低:重复的复制、截图、导出操作,耗费大量无效时间;
-
信息残缺:只能搬运显性文字内容,极易丢失交互逻辑、弹窗状态、字段约束、页面跳转等隐性核心需求;
-
理解偏差:碎片化的资料,会导致AI无法串联完整业务链路,最终产出的用例片面化、实用性差。
三、我的方案:MCP+Skill +CLI
针对这类痛点,我采取了不同的需求解析方案。通过接入飞书、蓝湖、Figma、Axure官方MCP能力,再封装整合为通用 Skill。
整套方案的核心逻辑:直接对接平台底层接口,一键拉取完整需求数据,自动生成结构化Markdown需求文档,给AI提供完整的上下文,从源头解决用例质量差的问题。

详细教程和skill都放在【Raina的AI&测试实战圈】里面,感兴趣的可以了解看看
四、案例演示
案例1:蓝湖原型读取
输入指令:
在AI对话框中,直接调用对应的Skill,并输入蓝湖原型链接即可:
/lanhu-requirements-doc + 对应的蓝湖原型链接
Skill会自动调用蓝湖MCP能力,自主访问链接并解析全部内容,包含页面结构、UI元素、标注信息、交互规则、弹窗逻辑、字段限制等全部数据,无需人工二次干预。
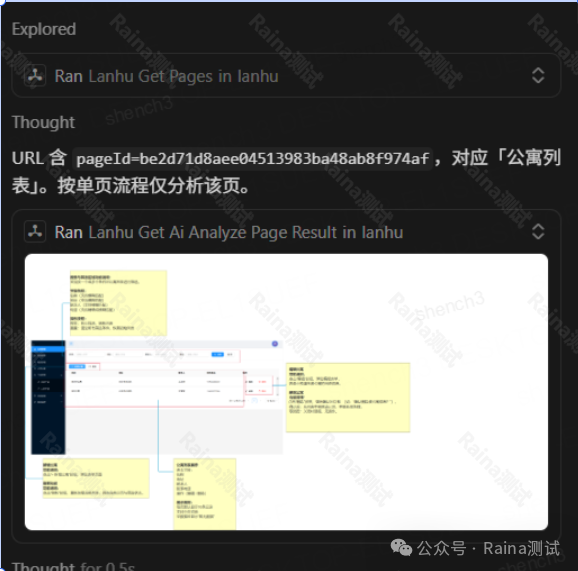
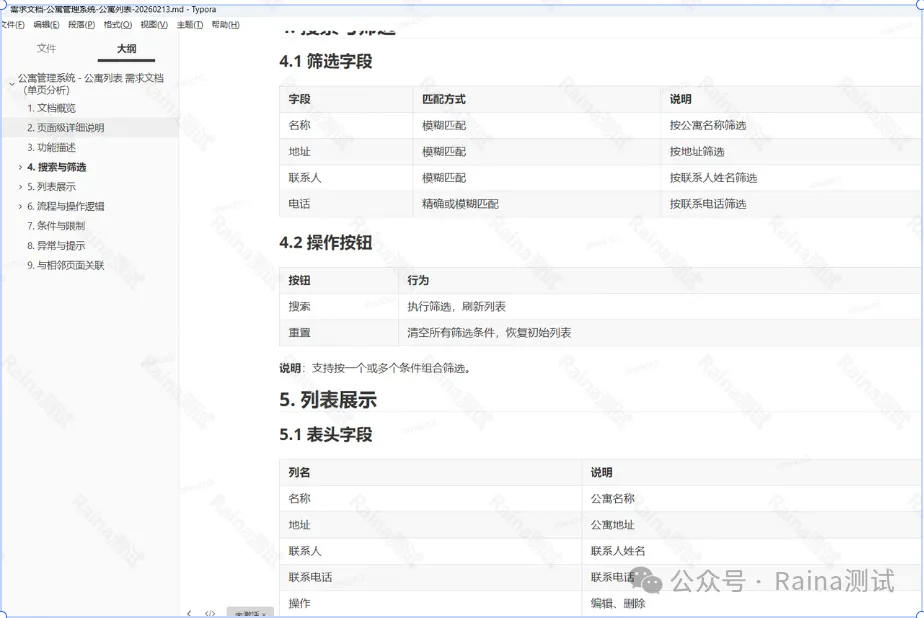
执行完成后,自动输出一份标准化的Markdown需求文档。文档结构清晰、内容完整,完整还原产品原始需求。
后续我们直接基于这份结构化MD文档,交给AI拆解功能点、编写正向/反向用例、梳理边界场景,生成的用例质量会得到质的提升。
案例2:figma原型读取
1、输入指令:

按下回车后,AI 会自动调用已启动的 Figma MCP,向 Figma 平台发起请求,完整读取对应原型的所有内容,包括页面布局、组件交互、输入框规则、备注信息、设计规范等
2、获取并使用标准化需求文档
等待解析完成后,AI 会自动将读取到的 Figma 原型信息进行结构化整理,生成完整的 Markdown 格式需求文档,文档覆盖概述、范围、页面与信息架构、详细功能说明、统一组件与设计规范、非功能性说明、待确认事项等核心模块,可直接用于后续测试工作。
以下是部分内容截图:

在实际的使用中,我们可以直接将我们需要的原型内容,一个一个链接提供给ai进行解析,例如我只要需要关注用户管理的这几个原型
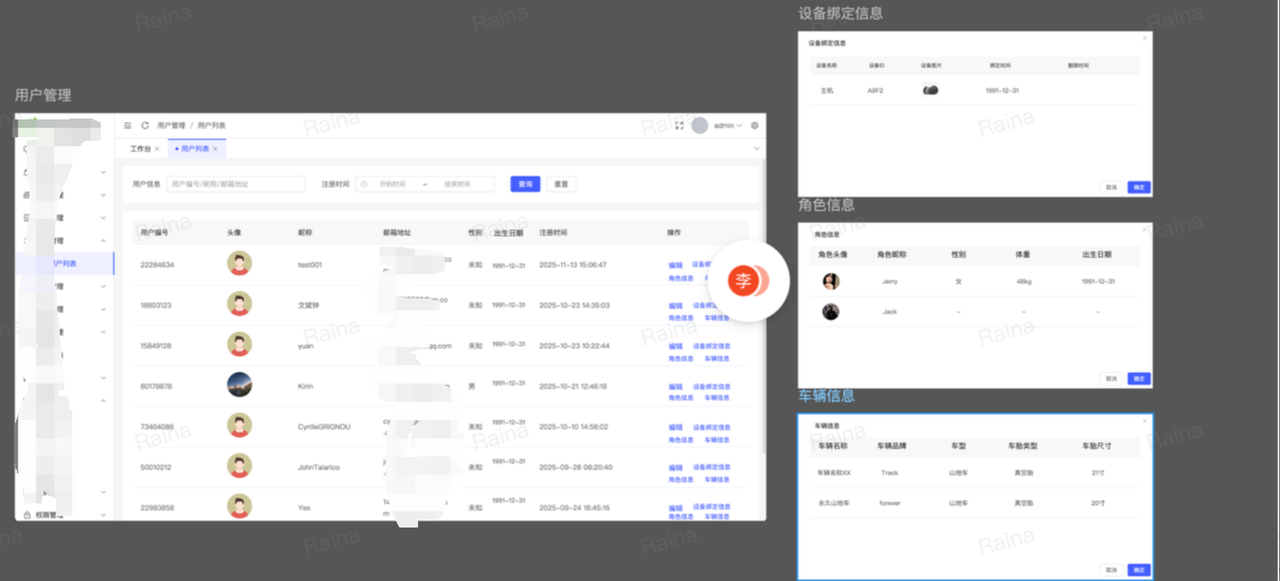
那么我这边就需要这样子处理,将这4个原型内容的链接进行复制提供给ai
这样子生成出来的部分内容效果如下:

后续大家要利用这份文档去生成测试用例时,就可以直接在对话框调用“生成测试用例的 skill + 需求文档”,进行生成了
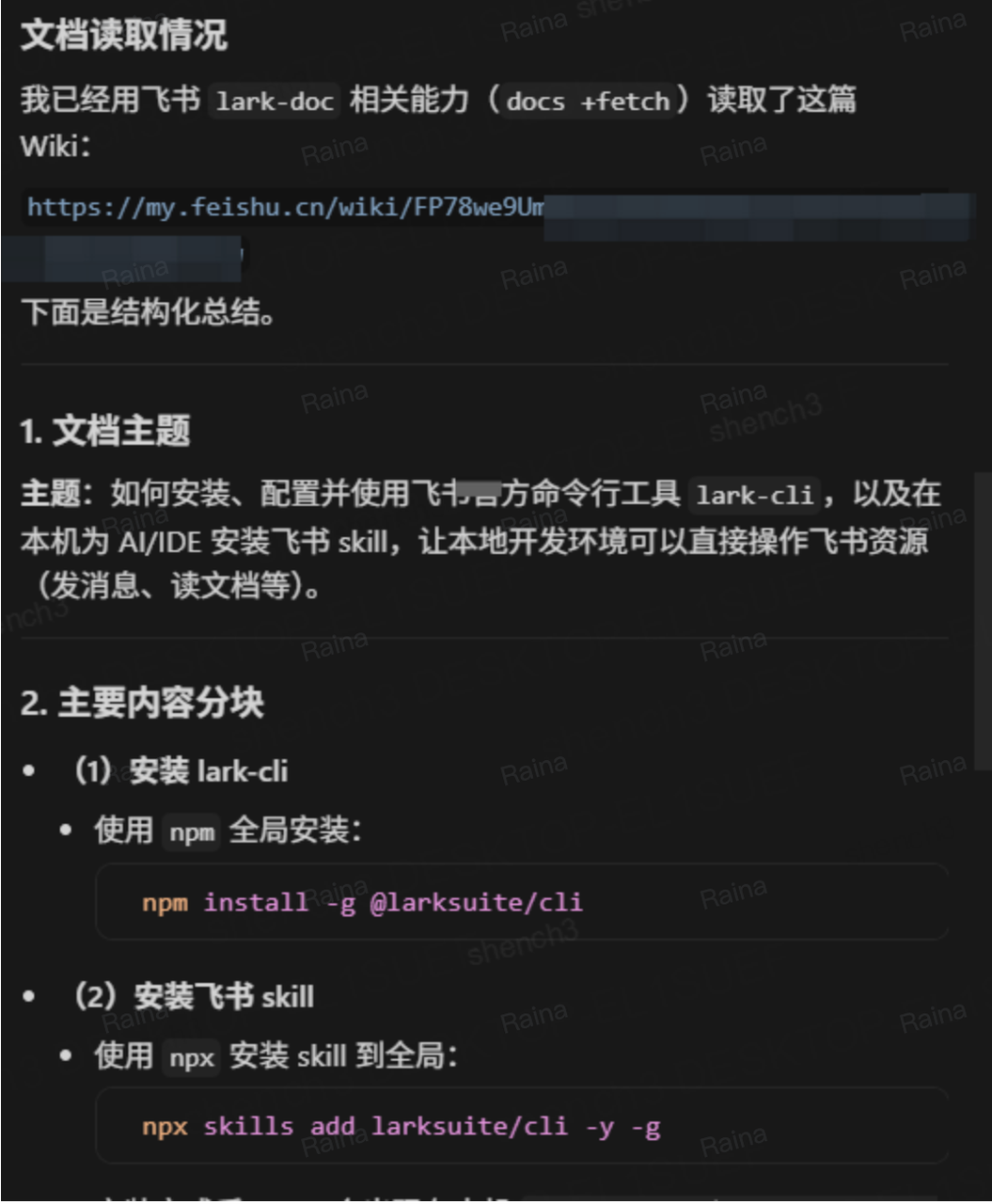
案例3:飞书CLI+Skill读取飞书需求文档
配置飞书cli以及安装相应的skill之后,
在对话框输入指令:

读取结果:
案例4:读取word/pdf/ppt格式的需求文档
1、pdf 需求文档 转 markdown 文件
输入:

输出:
AI 会自动创建 文件名_export 专属文件夹:
-
抽取所有图片自动放入 media 子目录;
-
生成 index.md 汇总全部文字内容;
-
正文自动关联引用图片,打开即可图文对照查看。

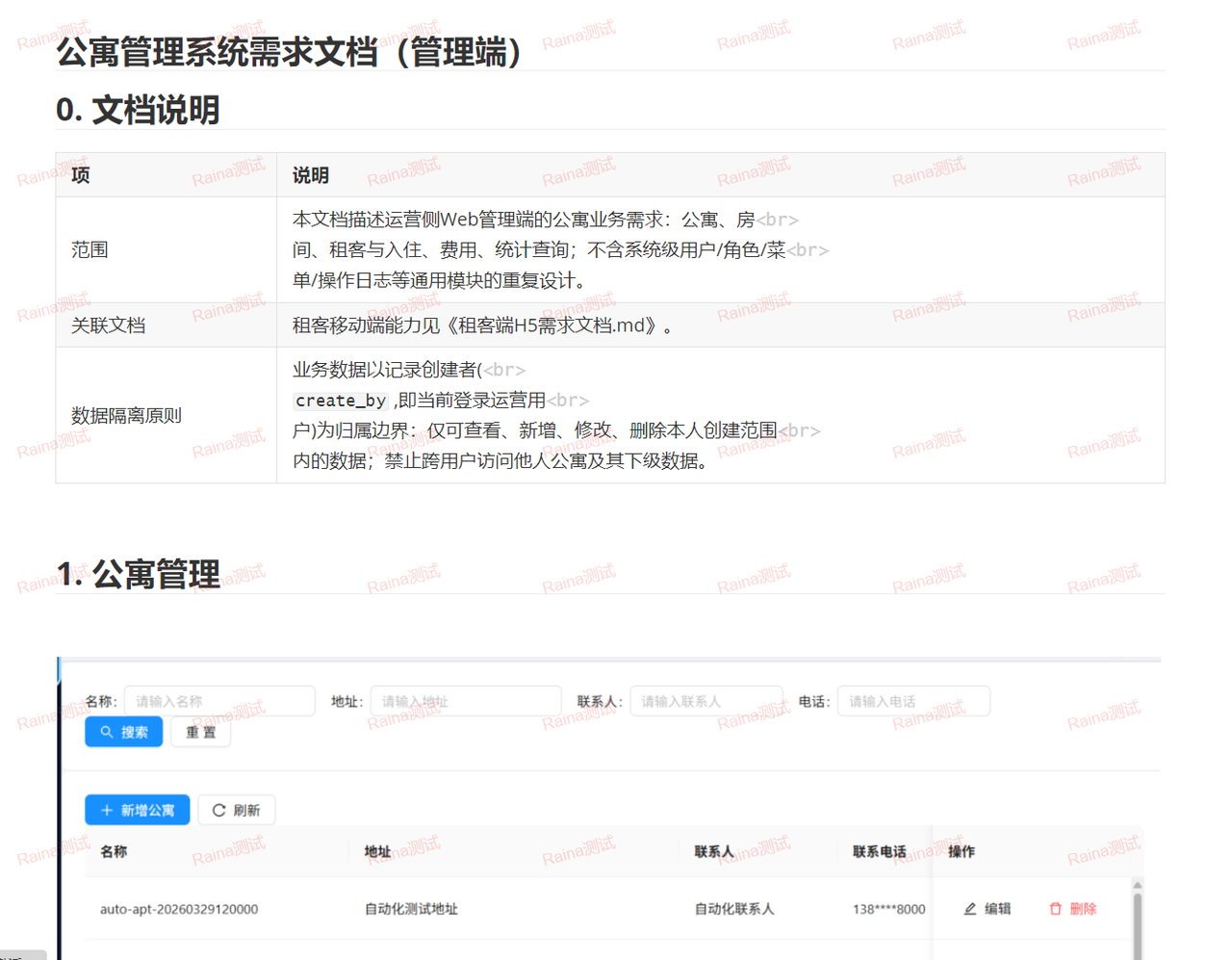
最终转换的效果如下:
整体转换还原度高,结构清晰,可直接交给 AI 做需求拆解、用例生成
2、word 转 markdown 文件
输入:

首次运行会自动检测并安装 Pandoc 依赖,无需手动折腾配置,等待自动安装完成后,即可生成结构标准、图文齐全的 Markdown 文档
最终生成效果
3、PPT转markdown文件
输入:

效果如下:
自动逐页抓取每页文字内容、配图信息,按页面顺序整理到 Markdown 中,一页一段落,结构清晰,方便做需求汇总、方案梳理、知识库归档。

五、方案核心优势
对比传统手动搬运模式,基于MCP、Skill、Cli的方案优势十分突出:
✅ 告别复制粘贴:仅需一条链接即可完成解析,彻底解放双手,减少无效重复工作
✅ 需求信息全覆盖:同步抓取文字、页面元素、交互逻辑、状态流转,守住隐性需求不丢失
✅ 标准化输出:统一输出Markdown格式文档,结构规整,适配所有大模型,AI理解效率更高
✅ 高复用低成本:一次配置永久生效,不仅适配个人日常提效,也能直接在团队内共享复用
小结
很多时候我们纠结AI生成用例质量差,一味去调试提示词、切换大模型,却忽略了最本质的问题:问题可能不在AI,而在输入的需求资料。优质的测试用例,前提一定是完整、结构化的需求上下文。
以上是今天分享的内容,以上提到的案例详细教程以及skill都已经在【Raina的 AI&测试实战圈】知识星球里进行分享了,跟着步骤操作就可以上手,提高日常测试工作效率。圈内还有很多AI赋能测试全流程的相关实战教程,感兴趣的小伙伴可以加入了解哦~

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 2
2 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)