
OpenClaw 完全实战手册:从零搭建 AI 自动化系统到如何成长为大神龙虾
1. 快速部署与环境配置
OpenClaw 的一键安装方案通过智能脚本解决了传统安装的三大痛点:环境依赖检测、版本兼容性管理和配置文件生成。脚本会自动识别操作系统类型、检测已安装的依赖项,并根据系统环境选择最优的安装路径。在 macOS 系统上,脚本使用 Homebrew 作为包管理器,自动安装 Node.js、Python 和必要的系统库,整个过程在 5-10 分钟内完成。Windows 系统使用 PowerShell 脚本实现类似功能,会自动请求管理员权限确保能够修改系统环境变量和安装全局包。安装完成后会自动启动 CC Switch 和 Cherry Studio 两个关键组件,前者是图形化的模型管理工具,后者提供直观的 Web 界面用于管理实例和监控状态。
1.1 一键安装详细步骤
# macOS 一键安装
curl -fsSL https://claw.moyuxl.top/install.sh | bash
# Windows 一键安装(管理员权限)
iex (irm https://claw.moyuxl.top/install.ps1)
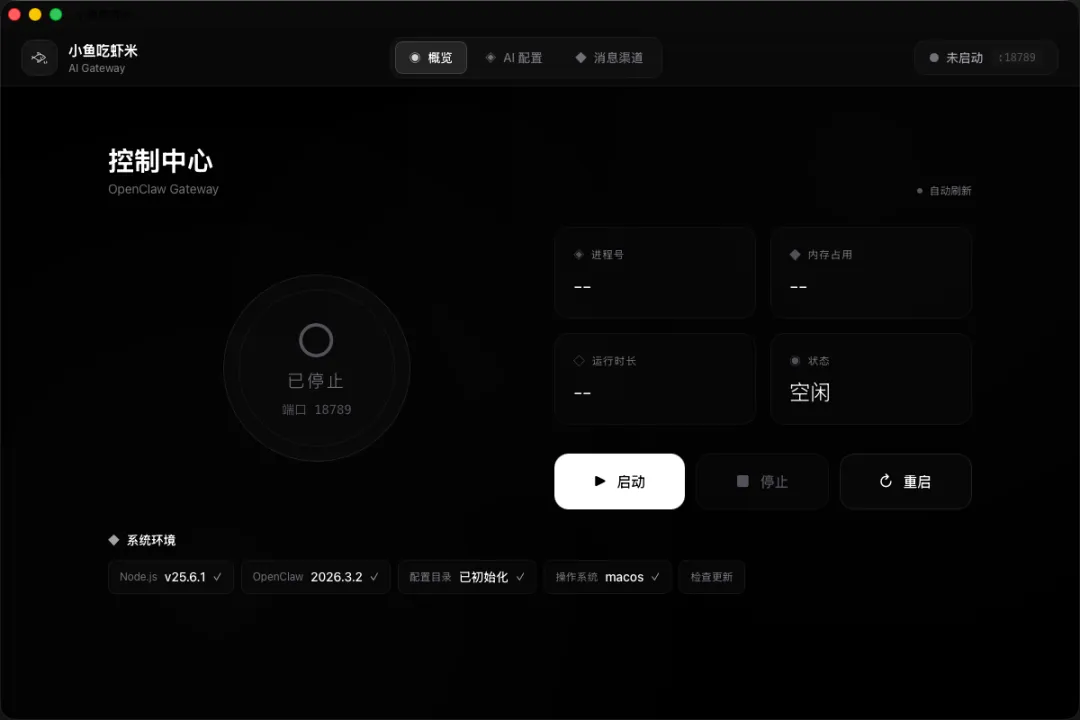
Windows 安装流程(以管理员身份运行 PowerShell):第一步,搜索 PowerShell 并右键选择"以管理员身份运行";第二步,复制安装命令并回车,脚本会提示选择安装版本(推荐选择最新稳定版);第三步,脚本自动检测环境、安装依赖、下载 OpenClaw 本体,期间会显示详细进度信息;第四步,按照引导选择是否接入飞书(也可以跳过后续配置);第五步,接入 AI 大模型,可以使用 CC Switch 图形界面添加供应商和模型,或使用 Cherry Studio 的龙虾页面选择模型并启动。整个过程全自动化,遇到问题脚本会给出明确提示。
安装验证三步法:第一步,检查终端输出,确认看到"安装成功"的提示信息;第二步,打开浏览器访问 Dashboard(通常是 http://localhost:3000),检查界面是否正常显示;第三步,在 Dashboard 中发送一条测试消息"你好",验证 AI 能否正常响应。如果任何一步出现问题,可以查看 ~/.openclaw/logs/ 目录下的日志文件定位错误。常见问题包括端口被占用(可以修改配置文件更换端口)、依赖版本不匹配(重新运行安装脚本自动修复)、网络连接失败(检查代理设置或防火墙),大多数问题都可以通过重新运行安装脚本或手动调整配置解决。
模型配置两种方式:方式一是使用 CC Switch,打开软件后点击顶部的 OpenClaw 选项,添加供应商(如 OpenAI、Anthropic、Kimi、DeepSeek),然后配置对应的 API Key 和模型。方式二是使用 Cherry Studio,打开龙虾页面后它会自动识别已配置的 OpenClaw 实例,选择想要使用的模型后点击启动即可。推荐国内使用 Kimi k2.5(性价比高、长文本处理能力强)、DeepSeek-V3(代码生成能力突出、价格极低)、通义千问(中文理解好、通用对话),国外使用 GPT-4(综合能力最强)、Claude(推理能力强、代码质量高)。配置完成后系统即可正常使用,后续可根据需求安装各类 Skills 扩展功能。
2. Skill 系统架构与核心技能配置
OpenClaw 的 Skill 系统采用插件化架构,每个 Skill 本质上是一个独立的功能模块,包含三个核心文件:SKILL.md(技能描述和使用说明,告诉 AI 何时调用这个技能)、skill.py 或 skill.js(实现代码,包含具体的业务逻辑)、config.json(配置参数,定义权限、依赖和环境变量)。这种设计使得 Skill 的开发、分发和维护都变得简单高效。系统启动时会扫描 .openclaw/skills/ 目录下的所有子目录,读取每个 Skill 的元数据,并根据依赖关系决定加载顺序。如果某个 Skill 依赖其他 Skill 或外部服务,系统会先检查这些依赖是否满足,不满足则跳过加载并记录警告信息。
Skills 按功能分为六大类:信息获取类(网络搜索、内容抓取、数据采集)、数据处理类(文本分析、格式转换、数据清洗)、自动化类(定时任务、工作流编排、批量操作)、集成类(第三方服务对接、API 调用、数据同步)、安全类(权限管理、审计日志、漏洞扫描)和工具类(辅助功能、开发调试、性能监控)。这种分类不仅便于用户查找和选择,也为 Skill 的版本管理和依赖解析提供了清晰的命名空间。
2.1 Skill 安装方式
安装 Skills 有三种方式:从 ClawHub 市场安装(最简单,类似 npm 或 pip 的包管理体验)、从 GitHub 仓库安装(灵活,可以安装未发布到市场的 Skill)、本地开发模式链接(调试用,将本地开发的 Skill 链接到 OpenClaw 实例)。安装前必须使用 ClawDex(https://clawdex.koi.security/)进行安全检查,检测未授权的文件系统访问、可疑的网络请求、敏感信息泄露风险、恶意代码注入、权限滥用等问题。
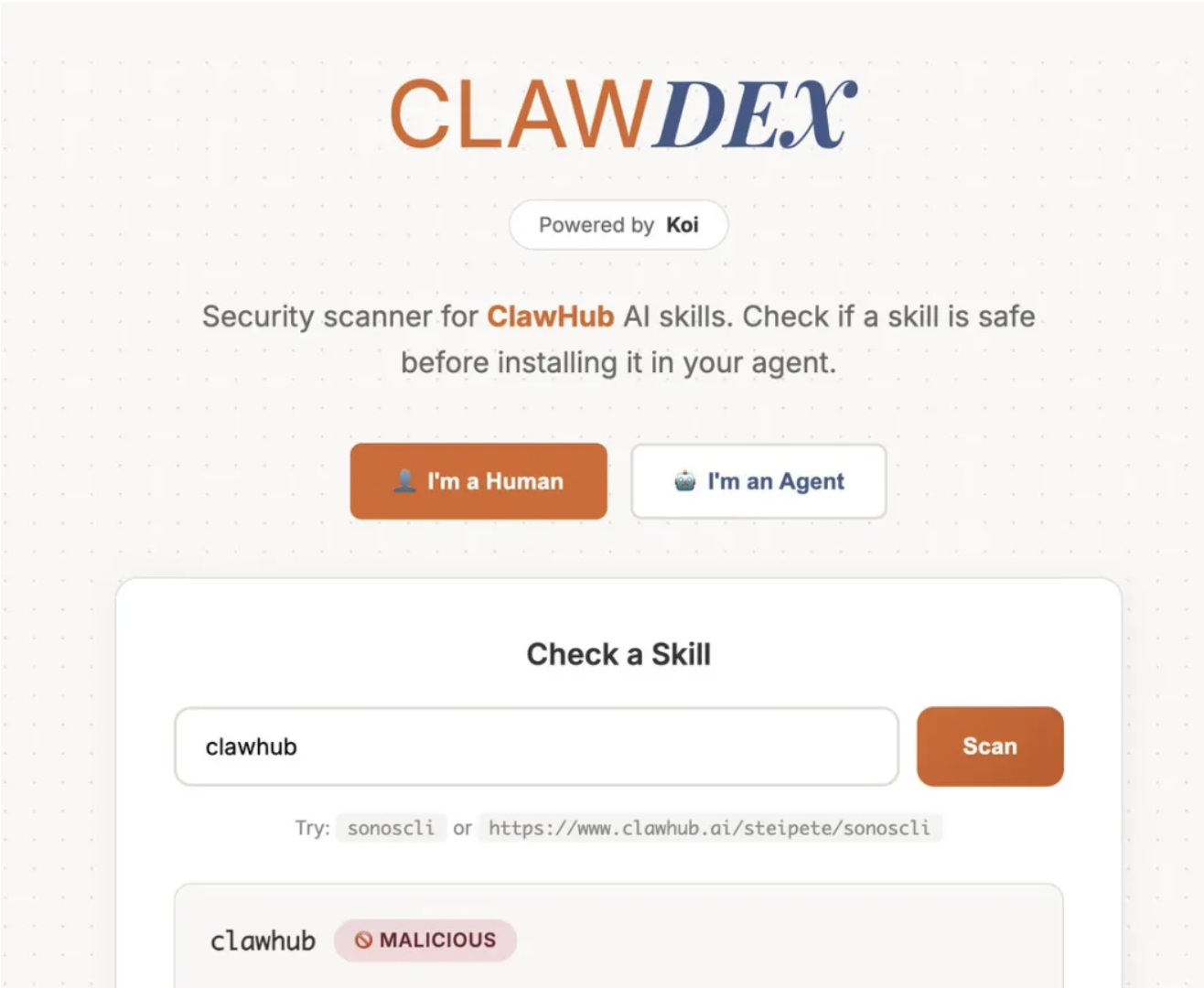
# 核心技能安装示例
npx clawhub@latest install summarize
openclaw skill install multi-search-engine
openclaw skill install tavily-search
2.2 必装核心技能清单
之前我在OpenClaw Skill 实战指南:跨境电商数据抓取从入门到精通当中做了一些工作,这里继续整理
Link-Reader(链接内容读取)。这是一个聚合型 Skill,能够解析各种平台的链接并提取结构化内容。它整合了多个平台的读取接口,使用门槛远低于传统的 x-reader。网页、公众号、推特等内容可以直接读取;B站、抖音、小红书等视频类内容,则调用 BibiGPT 的 API 进行视频转文案,按时长计费但速度快且非常稳定。首次使用时,OpenClaw 会引导你注册获取对应的 API Key。
Agent-Reach(全平台触达)。一条命令打通 13 个平台(Twitter、YouTube、B站、小红书、抖音、Reddit、GitHub、知乎、微博、豆瓣、即刻、V2EX、Hacker News),把各平台的连接和认证都搞定,让 OpenClaw 直接触达数据。安装很简单,对 OpenClaw 说:“帮我安装 Agent Reach:https://raw.githubusercontent.com/Panniantong/agent-reach/main/docs/install.md”。
Self-Improving-Agent(自我改进)。让 OpenClaw “长记性”:自动记录每次错误和你的纠正,以后同类任务基本不会重犯。用得越多,越懂你的习惯。
Proactive-Agent(主动代理)。让 OpenClaw 拥有自主规划能力:主动拆解多步任务、提前预判需求,像个真正聪明的专属助手。
Security-Audit(安全审计)。每当给 OpenClaw 装完一批 Skill,都应该立刻让它进行安全检查,防止装的 Skill 有安全隐患。
2.3 联网搜索详细配置:三层防护体系
联网搜索是 OpenClaw 最关键的能力之一,它决定了 AI 能否获取实时信息和准确数据。一个完善的搜索系统需要三层架构:搜索引擎层、内容提取层和结果优化层。
Brave Search 配置(首选方案)。Brave Search 是目前最好用的联网搜索引擎,也是 OpenClaw 官方推荐方案,提供专为 AI 优化的搜索结果,包含结构化数据和相关性评分。访问 https://brave.com/zh/search/api/ 注册账号,需要绑定 Visa 卡(国内银行的 Visa 卡即可,如招商银行 Visa)。每月提供 5 美元免费额度(约 1000 次搜索),超出后按使用量计费,价格相对合理。注册后在控制台申请 API Key,然后在 openclaw.json 的 tools.web.search 下配置:
{
"tools": {
"web": {
"search": {
"provider": "brave",
"apiKey": "你的apikey",
"options": {
"count": 10,
"safesearch": "moderate",
"freshness": "week"
}
}
}
}
}
建议在 Brave 控制台设置每月最大额度(如 5 美元),防止无限烧钱。配置完成后,直接对 OpenClaw 说"用 web_search 看下今日 AI 热点"即可验证,打开 Brave Search 控制台的 Usage 面板可以看到调用量开始增长,就说明配置成功了。
Tavily Search 配置(备选方案)。Tavily 是第二选择,它不需要绑定信用卡,注册即可使用。Tavily 的特点是针对研究型任务优化,返回的结果包含更多的上下文信息和引用来源,特别适合需要深度分析的场景,比如学术研究、市场调研、竞品分析等。访问 https://www.tavily.com/ 注册账号,登录后在 https://app.tavily.com/home 申请 API Key。安装方式:直接对 OpenClaw 说"安装下 https://github.com/tavily-ai/skills 这个 skill,安装到 .openclaw/skills 下"。推荐将 API Key 配置到 .openclaw/.env 文件中:
# 在 .openclaw 目录下新建 .env 文件
TAVILY_API_KEY=你的token
这样更安全且不会泄露到代码中。配置完成后,对 OpenClaw 说"用 tavily search 看下今日 AI 热点"验证,打开 Tavily 的 Usage 面板可以看到调用量统计。
Multi-Search-Engine 配置(兜底方案)。Multi-Search-Engine 是兜底方案,它聚合了 17 个搜索引擎的结果(百度、必应、搜狗、360 搜索、Google、DuckDuckGo 等),不需要 API 密钥即可使用。虽然搜索质量不如前两者,但在 API 额度用尽或服务不可用时,它能确保 OpenClaw 的搜索功能不会完全失效。这个 Skill 的实现原理是通过爬虫技术抓取各个搜索引擎的结果页面,然后解析 HTML 提取关键信息。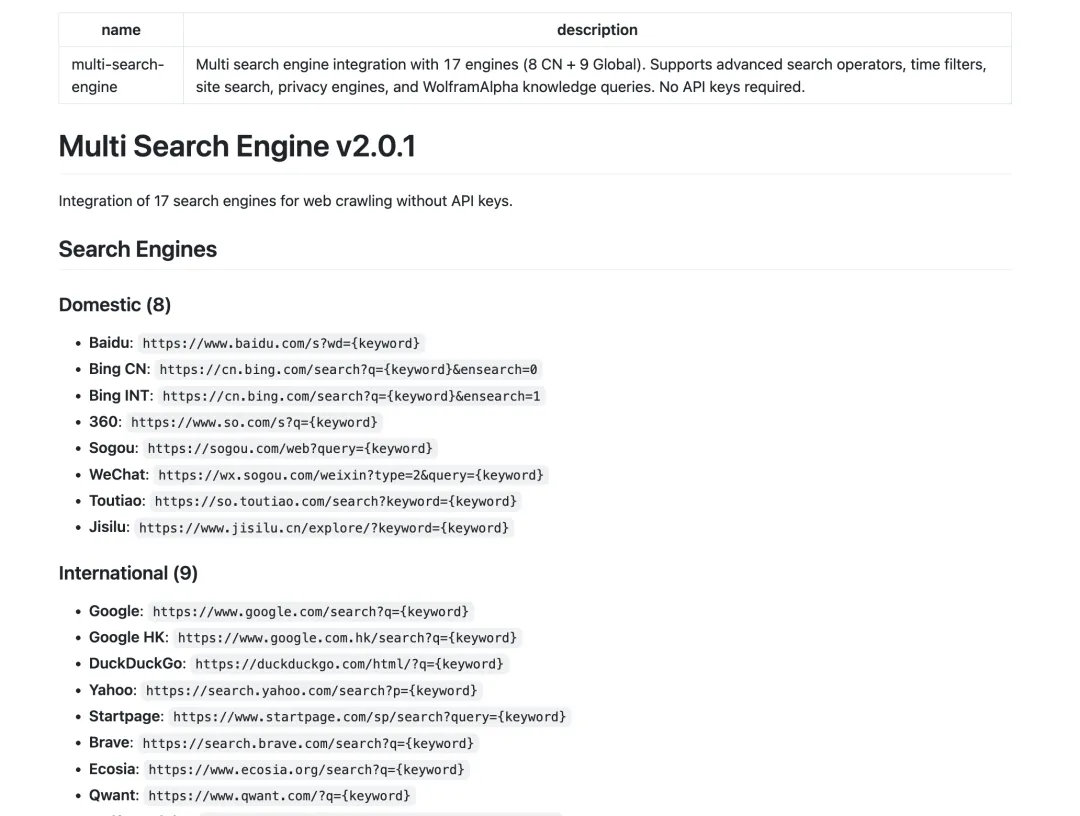
安装方式:对 OpenClaw 说"https://github.com/openclaw/skills/blob/main/skills/gpyangyoujun/multi-search-engine/SKILL.md,这个 skill 也安装下"。配置完成后,对 OpenClaw 说"用 multi-search-engine skill,看下今日 AI 热点"验证。
最佳实践:三者结合使用。在 AGENTS.md 中添加以下配置,让 OpenClaw 智能选择搜索引擎:
## 联网搜索优先级
1. **Brave Search**(`web_search` 工具)— 首选,速度快、质量高
2. **Tavily Search**(`search` skill)— Brave 额度用完后切换
3. **Multi-Search-Engine Skill**(`web_fetch` 拼 URL)— 最终兜底,无 API 限制
原则:能用 Brave 就不用 Tavily,能用 Tavily 就不用 multi-search-engine
这种配置确保了搜索功能的高可用性:Brave 提供最佳质量,Tavily 作为备选,Multi-Search-Engine 保证永不失效。一直白嫖一直爽,用不了 Brave 的用户,使用 Tavily + Multi-Search-Engine 方案也完全够用。
2.4 Skills 资源库推荐
Awesome-OpenClaw-Skills(社区精选库)。这是社区维护的精选列表,目前收录了 5,400+ 个高质量 Skill,按编程、自动化、运维、图像生成、PDF 处理等场景分类整理。能进这个列表的质量相对有保障,新手优先从这里找。访问 https://github.com/VoltAgent/awesome-openclaw-skills 浏览完整列表。
ClawHub 官方商店。clawhub.ai 上目前有 13,700+ 个 Skill,数量非常多、覆盖面也广,但质量参差不齐(之前还出过恶意 Skill 的安全事件)。强烈建议先用 Skill Vetter 扫一遍,同时执行 openclaw security audit,确认没问题后再正式启用。
Find-Skills(智能发现)。安装 find-skills 之后,直接对 OpenClaw 说:“帮我用 find-skills 找一个能 XX 的 Skill”。它会自动去 skills.sh 技能排名网站搜索、对比、推荐合适的,找到后确认一下就能直接安装,特别方便。
Agency Agents(55+ 专业 AI 专家库)。这是一个包含 55+ 个专业 AI 代理的资源库,涵盖 9 个部门:执行部门(CEO、COO、项目经理等)、产品部门(产品经理、UX 设计师等)、工程部门(前端、后端、DevOps 等)、数据部门(数据科学家、分析师等)、营销部门(内容营销、SEO 专家等)、销售部门(销售代表、客户成功等)、财务部门(财务分析师、会计等)、人力资源部门(招聘专员、培训师等)、法务部门(法律顾问、合规专家等)。访问 https://github.com/msitarzewski/agency-agents 获取完整列表和使用说明。每个 Agent 都有详细的角色定义、专业技能描述和使用场景,可以直接导入到 OpenClaw 中使用,构建完整的 AI 团队。
2.5 Skills 体系构建三步法
很多人装了一堆 Skills 却发现 OpenClaw 反而更慢更乱,问题不在于 Skills 本身,而在于缺乏系统化的管理思路。正确的做法是:先跑通核心链路(检索→执行→复盘),再逐步扩展场景覆盖,最后形成可维护的体系。
第一步:核心底座 Skills(必装,瞬间拉升 80% 战力)
网络搜索增强(信息输入质量):
- Summarize:把网页/播客/长文快速抽取成可分析文本,减少"读错源/漏重点",稳定内容输入质量
- Multi-Search-Engine:集成 17 个搜索引擎(8 个国内 + 9 个国际),无需 API Key 即可实现全网搜索
- Tavily-Search / Brave-Search:用于更高质量检索与研究型任务,输出更适合 AI 处理
工具增强(拓展能力边界):
- Mcporter:快速接入大量 MCP Server,连接数据库、Slack、Notion 等外部能力
- Find-Skills:主动发现"当前任务可用哪些 Skills",降低试错成本
- Proactive-Agent-1-2-4:用于多步骤任务的持续执行与迭代,复杂任务拆解成多步骤小任务,提高执行稳定性
- Skill-Creator:把高频任务沉淀为可复用 Skill,形成长期资产
记忆管理与成本控制:
- QMD:结构化记忆检索,降低上下文噪音与 Token 浪费
- Office-Automation:覆盖日程管理、邮件处理、文档编辑、数据统计等核心办公场景
- Session-Logs:复盘输出质量和错误模式,持续调优,这是"稳定性"核心工具
- Model-Usage:随时查看不同模型的成本/质量/时延,帮你建立"任务→模型"路由
第二步:安全检查(ClawDex 扫描)
Skills 具备执行权限,可能涉及文件读写、网络请求、系统调用,所以安全不是可选项,而是前提。所有 Skills 安装前必须使用 ClawDex(https://clawdex.koi.security/)进行安全检查。输入要安装的技能名称,如果提示安全风险,尽量不要安装。ClawDex 会检测:未授权的文件系统访问、可疑的网络请求、敏感信息泄露风险、恶意代码注入、权限滥用等问题。
第三步:进阶定制(打造专属技能系统)
把你的隐性能力(经验、SOP、标准)封装为 Skills,才能真正稳定复用。使用 Skill-Creator 可以从需求出发做轻量封装,不需要先精通底层机制。比如,将个人品牌规范封装成 Skill,每次写作内容后就调用规范 Skill 来审核优化。Skill 是所有 Agent 通用的格式,可以打造属于你最强的技能组合,沉淀成你的资产,不管未来出现什么更强的工具,都可以迅速嫁接切换。
2.7 Skills 执行稳定性优化
很多人反馈"让龙虾调用技能,它还是经常搞不定",常见原因包括:技能本身不稳定或依赖易变、提示词/参数不清晰、技能链条过长、上下文过杂、质量评估缺失。
最有效的 5 个优化方式:
- 明确目标 + 输出格式:“用 summarize 抽取 3 个观点,按’标题-要点-原文证据’输出”
- 缩短链条:能一步做完就一步做完,少做"连环技能",复杂任务拆成 2-3 个小任务而不是 1 个大任务
- 强制验收标准:“不包含来源链接就视为失败”、“三段式输出,不满足则重试”
- 固定模板:例如每次选题都用"问题-证据-结论"结构,模板会显著提升稳定性
- 为关键任务加复核:先生成→再让它自检(例如"检查是否有虚构来源"),这是最稳的输出控制手段
2.8 实战案例:11 个高价值应用场景
金融投资类:
- 股票助手(https://clawhub.ai/mbpz/akshare-stock):基于 AkShare 库获取 A 股实时行情、财务数据、板块信息,配置关注股票列表、技术指标(MACD、KDJ、RSI、BOLL)、预警条件,可搭配定时任务在买点和卖点实时推送
- Polymarket 预测市场交易机器人(https://clawhub.ai/hiehoo/polymarket-analysis):分析预测市场,寻找交易优势,查询赔率和赛事
新媒体运营类:
3. 小红书全自动运营(https://clawhub.ai/Borye/xiaohongshu-mcp):写文案、做封面图、发布笔记、回复评论,一整套运营流程全自动,虾薯账号就是真实案例
4. 公众号文章自动写作发布(https://clawhub.ai/hahacatlsq/wechat-mp-writer-skill-mxx):输入选题,AI 自动生成标题、正文、配图,定时发布
5. X(Twitter) 全自动运营(https://clawhub.ai/zizi-cat/chirp):每天自动推送选题、发推、回复评论、归档数据
信息获取类:
6. 每日新闻定时播报(https://clawhub.ai/kenxcomp/ai-news-collectors):每天早上自动抓取 AI、科技、财经等领域最新新闻,整理成简报推送
7. 跨平台内容搜索(https://github.com/runningZ1/union-search-skill):一句话搜索 B 站、抖音、小红书、GitHub、Twitter 等 20+ 平台内容
办公自动化类:
8. 会议纪要自动生成(https://github.com/EvoLinkAI/awesome-openclaw-usecases-moltbook):把会议录音文字版粘贴给 AI,生成格式化会议纪要
9. 自动总结网站或文件内容(https://clawhub.ai/steipete/summarize):对 URL 或文件进行汇总(包括网页、PDF、图像、音频、YouTube 等)
数据监控类:
10. 网站信息监控(https://clawhub.ai/rogue-agent1/web-monitor):监控网页内容变更并接收提醒,支持 CSS 选择器定向监控
11. OpenClaw 运行状态监控(https://clawhub.ai/jorgermp/task-monitor):实时监控 OpenClaw 运行状态、API 调用次数、成本开销,可视化界面
2.9 数据采集神器:Scrapling
Scrapling 是 OpenClaw 的"最强外挂",专门解决网页抓取时频频翻车的问题。它能穿透各种防爬虫的网页护盾,把网页源码直接清洗成干净的结构化数据。发布一年多后因为成为龙虾神器而人气大爆发,狂揽 2.3 万 stars,冲上 GitHub 单日趋势榜第一名。

核心能力:
- StealthyFetcher 隐身获取器:完美模拟最新版浏览器的指纹和操作行为,开箱即用地绕过各种拦截和真人验证
- 智能自适应算法:即使网站彻底打乱 HTML 结构,解析器也能通过相似度比对自动感知数据位置,重新定位到正确的关键信息
- MCP 模式:精准提取正文,剔除废话、广告和冗余代码,大幅降低 API 调用的 Token 费用
- 断点记忆功能:遇到断网或断电,爬取进度会被保存,恢复后无缝接力继续干活
- 开箱即用的命令行工具:不需要会 Python,照着教程敲一行简单指令就能调用全部采集能力
项目地址:https://github.com/D4Vinci/Scrapling
原作者已明确表示正在把 Scrapling 做成 OpenClaw 的 Skill,每个普通用户都有希望轻松给自己的 OpenClaw 武装上一双看透全网、精准抓取数据的眼睛。
2.10 五个神器联动:让 OpenClaw 真正强大
很多人抱怨 OpenClaw 不如 ChatGPT 好用,其实是没有理解它的核心优势。OpenClaw 不是用来聊天的,而是用来构建自动化系统的。要让它真正发挥作用,需要"强强联合"——将五个神器组合起来使用。
神器一:模型与设备选择。模型是 OpenClaw 的大脑,设备是它的手脚。选对模型能省力一半:国内推荐 Kimi k2.5(长文本处理、200K 上下文窗口)、DeepSeek-V3(代码生成、价格极低)、通义千问(通用对话、中文理解好),国外推荐 GPT-4(综合能力最强)、Claude(推理能力强、代码质量高)。设备选择同样重要:VPS 只能做爬虫和对话,NAS 可以读取本地文档,个人电脑才能实现定时提醒、自动化工作流、浏览器交互等完整功能。非程序员不要在 VPS 上部署,至少要用 NAS,最好用个人电脑。这不是技术问题,而是功能限制——VPS 没有图形界面,无法运行需要浏览器的任务;NAS 虽然有存储优势,但性能有限;只有个人电脑才能发挥 OpenClaw 的全部潜力。
| 模型名称 | 整体智能打分 (0-10) | 擅长领域(通俗解释 + 场景适配) |
|---|---|---|
| Claude Opus 4-5 (Anthropic) | 9.5 | 超级大脑: 能解开复杂谜题(如分析商业策略、法律问题);代码一流: 适合开发App或调试程序bug;文学创作: 创作小说或营销文案;长文本处理: 阅读整本书总结要点;建议靠谱: 在道德敏感话题(如隐私保护)上表现很稳。 |
| GPT-5.2 (OpenAI) | 9.0 | 万金油选手: 聊天超自然(日常问答或闲聊);全才: 懂各种语言和知识(翻译文件、解释科学概念);多模态强: 能看图说话(分析照片或生成图片描述);创意脑暴: 帮你写博客或设计产品想法。 |
| Gemini (Google) | 8.8 | 图文视频高手: 能看懂多媒体(描述视频内容或识别物体);搜索快准狠: 实时查看新闻或找教程;知识库强大: 解答历史事件或技术问题;场景适配: 帮你规划旅行(结合地图和图片推荐路线)。 |
| Qwen 2.5 72B (开源) | 8.5 | 中文处理王者: 写中文报告或翻译古诗;数学/代码达人: 解方程或写脚本自动化任务;开源好用: 适合在本地电脑跑模型,隐私不外泄;学生友好: 辅助算题或编程练习。 |
| Llama 3.3 70B (开源) | 8.2 | 翻译总结神器: 多语言转换或浓缩长文;通用聊天: 客服模拟或日常咨询;隐私优先: 适合公司内部使用,防止数据泄露;企业办公: 总结会议记录或翻译合同。 |
| Kimi K2.5 (Moonshot AI) | 8.0 | 效率工具: 快速生成代码或分析数据;数据高手: 写Python脚本或Excel处理;开发者友好: 测试想法或小项目;初创团队: 快速原型开发或市场分析。 |
| MiniMax (Xiaomi) | 7.8 | 代码支持强: 帮写游戏脚本或自动化工具;多语言轻松: 中英混用聊天;易上手集成: 手机App开发或智能家居控制;趣味编程: 教小孩写简单游戏或机器人指令。 |
神器二:Skills 技能包。把 OpenClaw 比作厨房,对话模型是厨师,Skills 就是菜谱。没有菜谱,厨师再厉害也不知道做什么菜。官方仓库收录了 3000+ 技能,覆盖 99% 的需求。你可以直接使用现成技能,也可以让 AI 生成符合你需求的自定义技能,还可以把多个技能整合成工作流 SOP。比如生成调研报告,可以调用 Google-search 或 Perplexity 的 AI 优化搜索 Skill,OpenClaw 会整合需求让模型按照标准流程输出报告。关键是要理解:Skills 不是可选项,而是必需品。没有 Skills 的 OpenClaw 就像没有 App 的智能手机,只能打电话发短信。
神器三:浏览器插件。80% 的日常操作都在浏览器中进行,安装 OpenClaw Browser Relay 后,AI 就有了"眼睛",能直接读取网页内容。对于反爬虫网站,你访问的同时 AI 也能看到,可以直接让它分析。Chrome 对插件限制较高,需要手动点击 ON 才能访问,切换标签页需要重新激活。Google Computer Use 项目更强大,能实现自动化控制、填写表单、模拟点击,但需要手动绕过验证且只能用 Gemini API。Chrome 自带的 Gemini 体验最好但集成度低。三种方案根据需求自由切换:偶尔读取网页用 Browser Relay,自动化复杂任务用 Computer Use,快速分析网页用 Chrome Gemini。
神器四:GitHub 开源工具。这个时代重复造轮子是最浪费生命的事。OpenClaw 能运行终端命令,意味着所有 GitHub 上的开源 CLI 工具都是它的武器库。想下载 YouTube 视频?直接调用 yt-dlp(30k+ stars)。想管理 GitHub 仓库?安装 gh CLI 工具。想处理视频?用 ffmpeg。想批量处理图片?用 ImageMagick。能用现成的 CLI 绝不自己写脚本,把 gh、yt-dlp、ffmpeg 这些神器装在电脑上,OpenClaw 就能直接调用,能力瞬间爆炸。这就是站在巨人肩膀上——你不需要重新发明轮子,只需要告诉 OpenClaw 调用哪个工具。
神器五:n8n 自动化工作流。这是最强辅助,能高效稳定地解决 80% 的重复性劳动。OpenClaw 负责理解意图,n8n 负责稳定执行。相比黑盒操作,n8n 的可视化节点更容易操作也更稳定。你可以把脏活累活拆解出来丢给免费或本地模型,输出内容再由高级模型分析整合。典型案例是全网情报抓取:你发指令"分析 AI Agent 热门玩法",OpenClaw 理解意图转化为 JSON 发送给 n8n,n8n 调用 Brave Search 抓取数据、用 Ollama 本地模型总结、生成结构化报告、通过 Telegram 发送。把复杂流程交给 n8n 可视化编排,OpenClaw 只做触发器和审核者,既稳定又灵活,还能大幅节约 Token 消耗。
OpenClaw 与 n8n 的分工演变。实战经验表明,OpenClaw 正在改变 n8n 的使用方式。以前用 n8n 搭内容自动化系统,需要花几个月时间设计节点、调试流程,还要专门招人操作。现在对着 OpenClaw 说一句话,它自己去找方法、自己执行、干完告诉结果。这种变化的本质是:OpenClaw 成为意图层(你告诉它想干什么,它来决策怎么干),n8n 变成执行层(在需要精确控制的场景被 OpenClaw 调用)。流程固定、逻辑复杂、需要精确控制每个节点的场景,n8n 的稳定性依然是最优解。但对于需要灵活决策、动态调整的任务,OpenClaw 的自主性更强。未来的趋势是两者重新分工,而不是谁取代谁。真正会被淘汰的,不是 n8n,是那些只会拖节点、却说不清楚自己在解决什么问题的人。
这五个神器给了 OpenClaw 大脑(模型)、手脚(设备)、专业技能(Skills)、眼睛(浏览器)、武器库(GitHub 工具)和自动化流水线(n8n)。不要沉迷于单一工具的参数微调,而是把它们链接起来,构建一个能 24 小时干活的系统。
2.11 分岗位 Skills 推荐清单
不同岗位有不同的痛点,选对 Skills 能让效率提升 10 倍。以下按 6 大高频岗位整理核心 Skills,每个都附带 GitHub 仓库和实战场景。
通用必装(所有岗位适用)
- find-skills(clawhub.ai/JimLiuxinghai/find-skills):AI 主动帮你发现新插件。不知道有什么插件可用时,跟 AI 说"我想订阅日历"、“帮我搜 Reddit”,它会主动去 ClawHub 找合适的 Skill 推荐安装
- skill-vetter(clawhub.ai/spclaudehome/skill-vetter):装陌生 Skill 之前先审查。检查有没有可疑权限、异常行为、潜在安全风险,不知道来路的插件别直接装
- summarize(clawhub.ai/steipete/summarize):一键总结网页、PDF、图片、音频、YouTube 视频。碰到长文或视频不想看完,先扔给它过一遍
- memory-setup(clawhub.ai/jrbobbyhansen-pixel/memory-setup):给 AI 配置持久记忆系统,从"金鱼脑"变"大象脑",你的偏好、工作习惯、历史决策都记得
- self-improving(clawhub.ai/ivangdavila/self-improving):AI 做错了或被你纠正后,自动把经验记下来建立分层记忆库,下次同类问题不再犯错
- proactive-agent(clawhub.ai/halthelobster/proactive-agent):让 AI 学会主动预判需求、定时巡检、上下文丢了能自动恢复,从"被动工具"到"有主见的助理"
新媒体运营
核心痛点:灵感枯竭、琐事缠身、多平台管理。
- Media Ops Suite(medialab/claude-media-skills,5.7k Star):8 个新媒体专属 Skill,标题生成、文案撰写、排版优化、热点追踪、素材整理、数据统计、评论回复、多平台同步。直连 Canva、醒图、公众号编辑器,生成文案后可直接调用设计工具做配图,排版完成后一键同步到公众号、小红书
- Content Planner Pro(contenthub/awesome-claude-content-skills,3.2k Star):内容规划专家,内置 12 个行业内容模板,支持周/月/季度内容日历生成。热点预判、选题策划、内容分发、数据复盘,告诉你当下该追什么热点、写什么选题、发什么平台
- Comment Auto-Reply(ComposioHQ/awesome-claude-skills,38k Star):自动识别评论情绪(正面/负面/中性),按预设调性回复,支持批量回复、关键词筛选、违规评论拦截
- nano-banana-pro(clawhub.ai/steipete/nano-banana-pro):对话框里直接出图,支持 1K/2K/4K 分辨率,也支持把现有图片当输入再编辑——换背景、加文字、改风格都行
- humanizer(clawhub.ai/biostartechnology/humanizer):去掉 AI 味,把"值得注意的是"、"不仅……而且……"这类套话揪出来换掉,让内容读起来更像人写的
- video-frames(clawhub.ai/steipete/video-frames):用 ffmpeg 从视频里提取关键帧或短片段,方便内容分析和素材剪辑,不用自己一帧一帧截图
产品经理
核心痛点:画原型、写 PRD、整理需求、对接研发耗时过多。
- Product Toolkit(productdev/claude-product-skills,4.8k Star):15 个产品专用 Skill,PRD 自动生成、需求整理、用户反馈分析、竞品分析、路线图规划、原型标注。输入需求痛点、核心功能、用户场景,一键生成完整 PRD
- User Research Pro(userlab/claude-user-research-skills,1.9k Star):桥接问卷星、麦客表单,提供 5 种用户研究模式。用户访谈自动分析,上传访谈录音/文字,自动提取核心需求、用户痛点、潜在期望,生成可视化分析报告
- PRD Review Helper(devtools/claude-dev-skills,2.1k Star):PRD 自动审核、漏洞排查、逻辑校验,内置产品研发全流程规范,自动排查 PRD 中的逻辑问题、表述漏洞,标注需要修改的地方
程序员/开发
核心痛点:调试代码、排查 bug、重复编写代码片段。
- Code Helper Suite(anthropics/knowledge-work-plugins,8.1k Star):Anthropic 官方出品,6 个开发专用 Skill,代码调试、代码生成、语法检查。按编程语言(Python/Java/JavaScript 等)自动识别代码问题,标注错误位置,给出修改建议,甚至直接生成优化后的代码
- Claude-Code-Assistant(codelab/claude-code-assistant,3.7k Star):专攻代码生成与优化,基于 GitHub 海量开源代码库,支持 20+ 种编程语言。支持基础代码生成、复杂逻辑编写、第三方库调用、单元测试生成
- Awesome Code Skills(codecommunity/awesome-claude-code-skills,2.8k Star):首个开发领域 Skill 开放社区,目前已有 30+ 个独立开发 Skill,覆盖前端、后端、移动端、测试、运维
- github(clawhub.ai/steipete/github):在对话框里管代码,搜索 GitHub 开源项目、提 Issue、看 PR、查 CI,程序员不用来回切窗口
人力资源(HR)
核心痛点:招聘、考勤、绩效等基础工作繁琐。
- HR Ops Bundle(hrtech/claude-hr-skills,2.3k Star):22 个人力资源专用 Skill,招聘文案生成、简历筛选、面试问题设计、考勤统计、绩效评估、员工培训方案、离职分析。输出带数据可视化的 HR 报表
- Resume Analyzer Pro(hrassistant/claude-resume-skills,890 Star):两阶段简历分析法,Phase 1 筛选关键词、匹配岗位需求,Phase 2 深度分析候选人能力、经验、薪资预期。支持校园招聘、社招、猎头招聘等场景
- HR-Training / Performance-Assistant(alirezarezvani/claude-skills,2k Star):18 个 HR Skill,员工培训方案生成(按岗位、职级定制)、绩效评估表设计、薪酬方案建议、员工关系协调、企业文化宣传文案
电商运营
核心痛点:上架商品、优化标题、回复客服、盯数据。
- E-commerce Ops Suite(alirezarezvani/claude-skills,2k Star):16 个电商运营 Skill,横跨四大模块——商品上架(标题优化、详情页撰写、主图文案)、客服管理(自动回复、售后处理、差评应对)、数据复盘(销量分析、流量分析、转化率优化)、营销活动(文案生成、活动策划、优惠券设置)
- Product Title Optimizer(ecomtools/claude-ecom-skills,1.6k Star):商品标题优化、关键词挖掘、搜索排名提升,支持淘宝、京东、抖音、拼多多等全平台。自动挖掘行业热门关键词、长尾关键词,结合商品核心卖点生成优化后的标题
- Ecom Data Analyst(trailofbits/skills,3k Star):Trail of Bits(全球顶级安全审计公司)出品,电商全平台数据整合与分析,自动同步淘宝、京东、抖音小店的销量、流量、转化率、客单价等数据,生成可视化分析报告
- stock-market-pro(clawhub.ai/kys42/stock-market-pro):本地优先的股市分析工具,输入股票代码直接出带 RSI/MACD/布林带等技术指标的高清图表,一键输出分析报告
行政/文员
核心痛点:整理文件、安排会议、录入数据、撰写通知等杂活。
- Admin Assistant Suite(K-Dense-AI/claude-admin-skills,4.2k Star):38 个行政专用 Skill,覆盖文件整理、会议安排、数据录入、通知撰写、日程管理、采购清单生成、访客登记、报销处理。直连 Office、企业微信、钉钉,自动同步日程、发送会议通知、整理会议纪要
- Document Organizer Pro(Galaxy-Dawn/claude-document-skills,760 Star):18 个文档处理 Skill + 10 个 Agent + 35 个命令。文件分类整理、数据自动录入、通知撰写、报告摘要。支持 PDF 转 Word、Excel 数据校验、文件归档
- Meeting Assistant(pedrohcgs/claude-code-my-workflow,443 Star):12 个会议相关功能,会议安排(自动匹配参会人日程、发送通知、预订会议室)、会议纪要生成(自动记录会议内容、提取核心要点、分配行动项)、会议后续跟进
- nano-pdf(clawhub.ai/steipete/nano-pdf):用说话的方式改 PDF,跟 AI 说"把第三页的标题改成 XX"、“在第二页末尾加一段”,它真的帮你改
- markdown-converter(clawhub.ai/steipete/markdown-converter):万能格式转换,PDF、Word、PPT、Excel、HTML、图片、音频——各种格式一键转成 Markdown
- openai-whisper(clawhub.ai/steipete/openai-whisper):免费本地语音转文字,把音频或视频的语音转成文字,本地运行不需要 API key,会议录音、采访录音、视频出字幕全能搞
- obsidian(clawhub.ai/steipete/obsidian):打通本地知识库,如果你用 Obsidian 做笔记,让 AI 直接读写你的 Vault——搜笔记、新建文档、更新内容
使用建议:不要贪多,先找到你岗位最痛的那个场景,给它配一个 Skill。跑通了,你就懂了——AI 不是来替代你的,是来帮你解放双手,做更有价值的事。
⭐ 特别推荐:web-content-fetcher(github.com/shirenchuang/web-content-fetcher):读取任意网页内容的终极方案。Jina Reader 读不到的页面、需要登录的网站、微信公众号文章——用这个都能读到,支持三级降级策略自动兜底,返回干净的 Markdown 格式正文。这是大多数其他抓取工具做不到的,特别是微信公众号文章抓取能力。开源免费,永久可用。
3. 浏览器集成与自动化工作流
浏览器集成让 OpenClaw 能够"看到"网页内容,处理动态加载页面和交互任务。三种方案各有优劣,实际使用中可以组合使用,根据任务类型动态选择方案。
3.1 三种浏览器集成方案
OpenClaw Browser Relay(官方插件)。这是官方提供的浏览器扩展,通过在浏览器工具栏显示图标,点击即可激活。激活状态下,OpenClaw 能够读取当前标签页的 DOM 结构、截图和文本内容。插件的工作原理是在网页中注入一个内容脚本(content script),这个脚本监听来自 OpenClaw 的消息,执行相应的操作(如截图、提取文本),然后将结果发送回去。优点是配置简单、兼容性好、安全性高;缺点是需要手动激活、无法自动切换标签页、不支持复杂交互。适用场景:偶尔需要读取网页内容、分析页面结构、提取特定信息。
Google Computer Use(完全自动化)。基于 Playwright 实现浏览器自动化,能够完全控制浏览器,包括点击、输入、滚动、切换标签页等所有操作:
# Computer Use 自动化示例
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch()
page = browser.new_page()
page.goto('https://example.com')
page.fill('#username', 'user')
page.fill('#password', 'pass')
page.click('button[type="submit"]')
page.wait_for_selector('.dashboard')
content = page.content()
browser.close()
Computer Use 特别适合需要复杂交互的任务,比如填写表单、模拟用户行为、绕过某些反爬虫机制。它能够模拟真实用户的操作节奏,包括随机的停顿时间和鼠标移动轨迹。优点是功能强大、完全自动化、支持复杂交互;缺点是只能使用 Gemini API、需要手动处理验证码、配置复杂。适用场景:自动化测试、数据采集、复杂表单填写、需要登录的操作。
Chrome 自带 Gemini(最佳体验)。Chrome Gemini 将 AI 能力直接集成到浏览器中。用户可以在任何网页上右键调用 Gemini,让它分析页面内容、回答问题或执行任务。优点是用户体验最好、无需配置、即开即用;缺点是与 OpenClaw 集成度低、功能受限、依赖 Chrome 浏览器。适用场景:快速分析网页、临时查询、辅助浏览。
3.2 n8n 深度集成
n8n 是开源的工作流自动化平台,与 OpenClaw 集成后成为 AI 的"执行引擎"。集成的核心是 Webhook 节点和 HTTP Request 节点,OpenClaw 通过 Webhook 触发 n8n 工作流,传递任务参数和上下文信息。n8n 执行完任务后,通过 HTTP Request 将结果回传给 OpenClaw。这种松耦合的架构使得两个系统可以独立升级和维护,互不影响。
…详情请参照古月居
草稿管理采用智能更新机制,首次发布时创建新草稿并将 media_id 写入 meta.json,后续修改文章后重新运行脚本会自动检测 media_id 存在,调用更新草稿接口而不是创建新草稿,避免草稿箱堆积大量重复内容。系统支持三种发布模式:首次发布(创建新草稿,保存 media_id,发送微信预览通知)、修改更新(检测到 media_id 存在,自动更新草稿内容)、强制新建(添加 --force-new 参数,忽略缓存创建全新草稿)。图文笔记和长文章走不同的发布接口,因为微信将它们视为两种不同的内容类型。图文消息必须使用永久素材接口上传所有图片,而文章内图片使用普通的 upload-img 接口。脚本层面做了区分处理,确保两种内容类型都能正确创建对应格式的草稿。整个发布流程只需要一行命令 python3 scripts/publish.py --article-dir ~/Documents/openclawworkspace/articles/2026-03-07/主题/,执行完成后在公众号草稿箱审核内容,确认无误后点击发布。
# 微信公众号图片上传示例
def upload_images_to_wechat(article_dir):
images = scan_images(article_dir)
wechat_urls = {}
for img_path in images:
# 检查缓存
if img_path in meta.get('wechat_image_map', {}):
wechat_urls[img_path] = meta['wechat_image_map'][img_path]
continue
# 上传到微信 CDN
with open(img_path, 'rb') as f:
response = requests.post(
f'https://api.weixin.qq.com/cgi-bin/media/uploadimg?access_token={token}',
files={'media': f}
)
wechat_url = response.json()['url']
wechat_urls[img_path] = wechat_url
# 更新缓存
meta.setdefault('wechat_image_map', {})[img_path] = wechat_url
# 替换 Markdown 中的图片链接
markdown = read_markdown(article_dir)
for local_path, wechat_url in wechat_urls.items():
markdown = markdown.replace(local_path, wechat_url)
return markdown
隐藏标签系统是整个方案的核心创新,通过在 Markdown 中插入 HTML 注释来标记需要特殊渲染的内容区块。渲染器识别这些注释后套用预设的样式模板,生成带完整内联样式的 HTML。目前支持六种样式标签:蓝色导读框(<!-- wechat head -->)、加粗高亮句(<!-- wechat highlight -->)、圆角卡片列表(<!-- wechat card -->)、提示词代码卡片(<!-- wechat code -->)、蓝色总结区块(<!-- wechat summary -->)、引导关注提示区块(<!-- wechat follow -->)。渲染器还会自动添加 header 和 footer,header 包含星标提示、封面图、署名,footer 包含结尾标记、关注二维码,这些内容不需要写在文章 Markdown 中。整个系统实现了内容与样式的分离,运营人员只需要专注于内容创作,排版和发布全部自动化处理,大幅提升了内容生产效率。
5. 故障排查与进阶技巧
5.1 常见问题诊断
常见问题诊断:OpenClaw 响应缓慢时检查系统资源占用和进程状态,考虑切换到更快模型;Skills 执行失败时查看日志并重新安装;网络连接问题时测试连接并配置代理。日志系统记录详细运行信息,分为 DEBUG(调试信息)、INFO(一般信息)、WARNING(警告)、ERROR(错误)、CRITICAL(严重错误)五个级别。使用 Task-Monitor Skill 监控 API 调用次数、响应时间、内存 CPU 使用率、Skills 执行成功率和错误统计。定期备份配置和数据,建议每周完整备份、重要操作前增量备份。
# 故障排查命令
tail -f ~/.openclaw/logs/openclaw.log # 查看实时日志
grep "ERROR" ~/.openclaw/logs/openclaw.log # 搜索错误
openclaw restart # 重启服务
openclaw skill logs skill-name # 查看特定 Skill 日志
5.2 进阶技巧
…详情请参照古月居

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 0
0 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)