
【AI Agent 全栈开发】LLM的接入方式

🚀 欢迎来到我的CSDN博客:Optimistic _ chen
✨ 一名热爱技术与分享的全栈开发者,在这里记录成长,专注分享编程技术与实战经验,助力你的技术成长之路,与你共同进步!
🚀我的专栏推荐:
| 专栏 | 内容特色 | 适合人群 |
|---|---|---|
| 🔥C语言从入门到精通 | 系统讲解基础语法、指针、内存管理、项目实战 | 零基础新手、考研党、复习 |
| 🔥Java基础语法 | 系统解释了基础语法、类与对象、继承 | Java初学者 |
| 🔥Java核心技术 | 面向对象、集合框架、多线程、网络编程、新特性解析 | 有一定语法基础的开发者 |
| 🔥Java EE 进阶实战 | Servlet、JSP、SpringBoot、MyBatis、项目案例拆解 | 想快速入门Java Web开发的同学 |
| 🔥Java数据结构与算法 | 图解数据结构、LeetCode刷题解析、大厂面试算法题 | 面试备战、算法爱好者、计算机专业学生 |
| 🔥Redis系列 | 从数据类型到核心特性解析 | 项目必备 |
🚀我的承诺:
✅ 文章配套代码:每篇技术文章都提供完整的可运行代码示例
✅ 持续更新:专栏内容定期更新,紧跟技术趋势
✅ 答疑交流:欢迎在文章评论区留言讨论,我会及时回复(支持互粉)
🚀 关注我,解锁更多技术干货!
⏳ 每天进步一点点,未来惊艳所有人!✍️ 持续更新中,记得⭐收藏关注⭐不迷路 ✨
📌 标签:#技术博客 #编程学习 #Java #C语言 #算法 #程序员
前言
前面几篇博客我们分别讲述了RAG、Agents、MCP、Tool Calling、Prompt等属于大语言模型的技术组件,是让原生LLM突破能力限制,落地实际业务的关键技术。而所有应用开发的前提是完成大模型服务对接,不同部署形态对接不同接入方法,这篇博客主要介绍LLM不同的的接入方式。
API接入
通过HTTP请求直接调用模型服务商提供部署在云端的服务模型,这也是目前最流行、最方便的LLM接入方式,尤其适用于快速开发、集成到现有应用不用管理硬件资源的场景。
接入流程:
- 注册账号并获取API Key:在模型提供商的平台注册,获取用于身份验证的密钥
- 阅读API文档:了解请求的端点、参数和发返回的数据格式
- 构建HTTP请求:在代码中使用HTTP客户端库构建一个包含API Key的请求(API一般在Header中,请求体是JSON格式,包含提示词和相关参数)
- 发送请求并处理响应:将请求发送到模型提供商指定的API地址,返回解析返回的JSON数据,提取生成的文本。
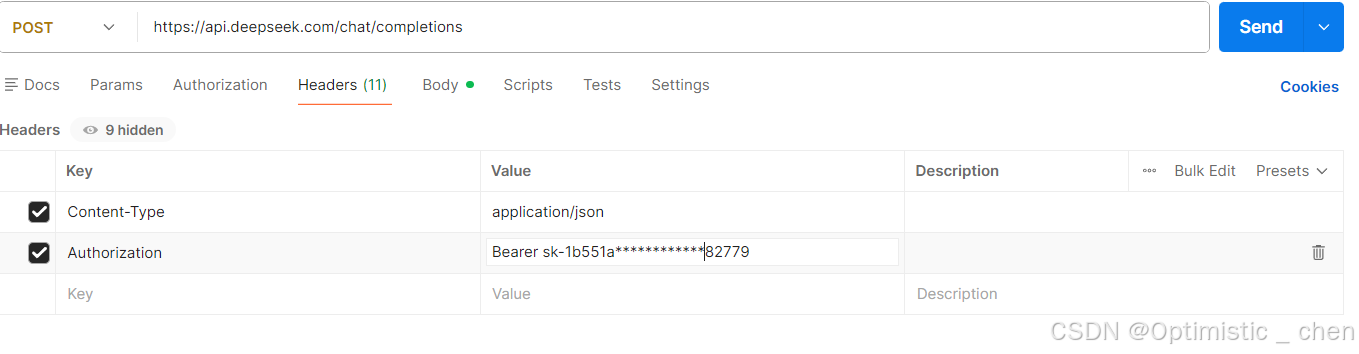
使用postman简单构建一个HTTP请求:
请求头中给出Content-Type和Authorization(API Key),请求体中按照接口文档给出模型的相关参数
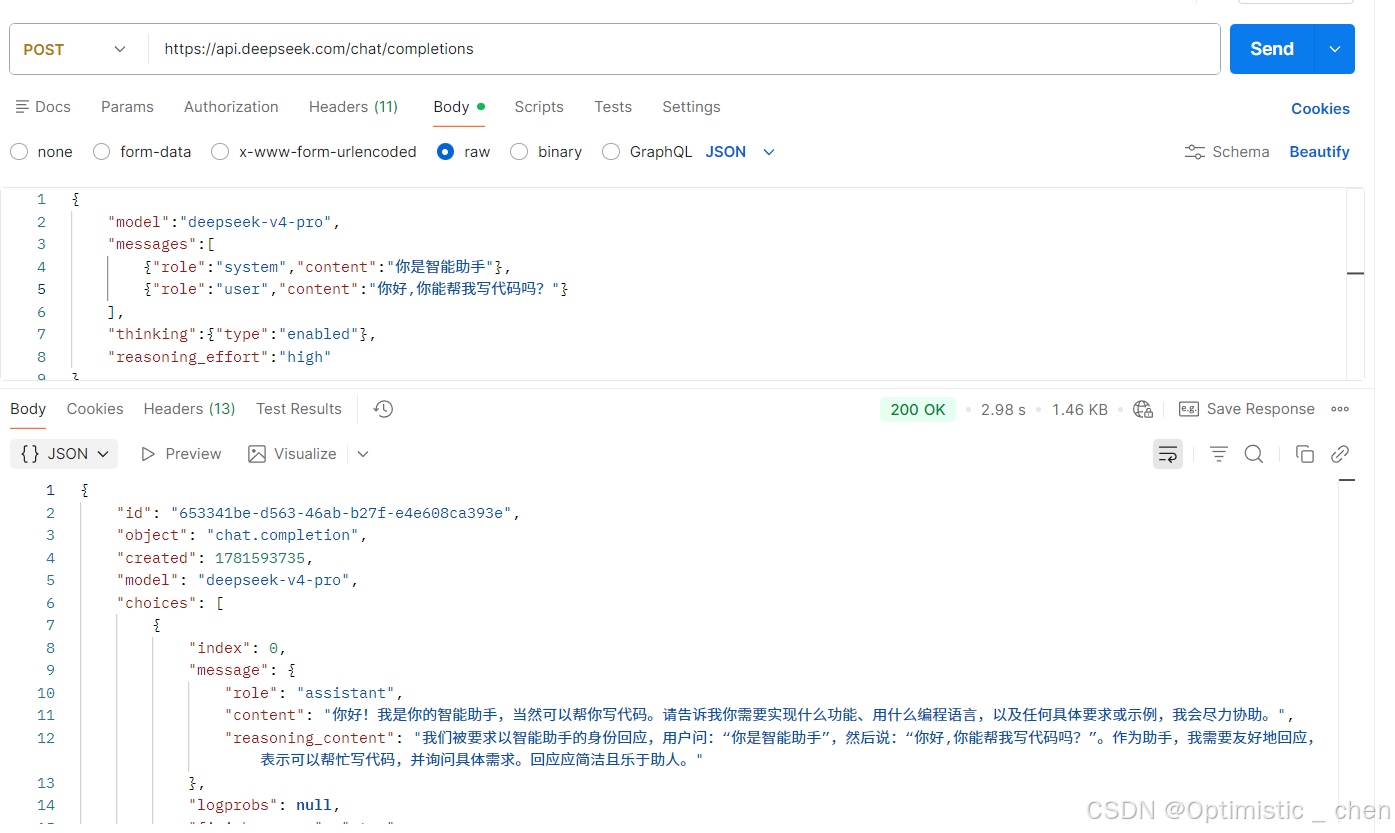
除了这种方式,在代码中的接入文档也有示例: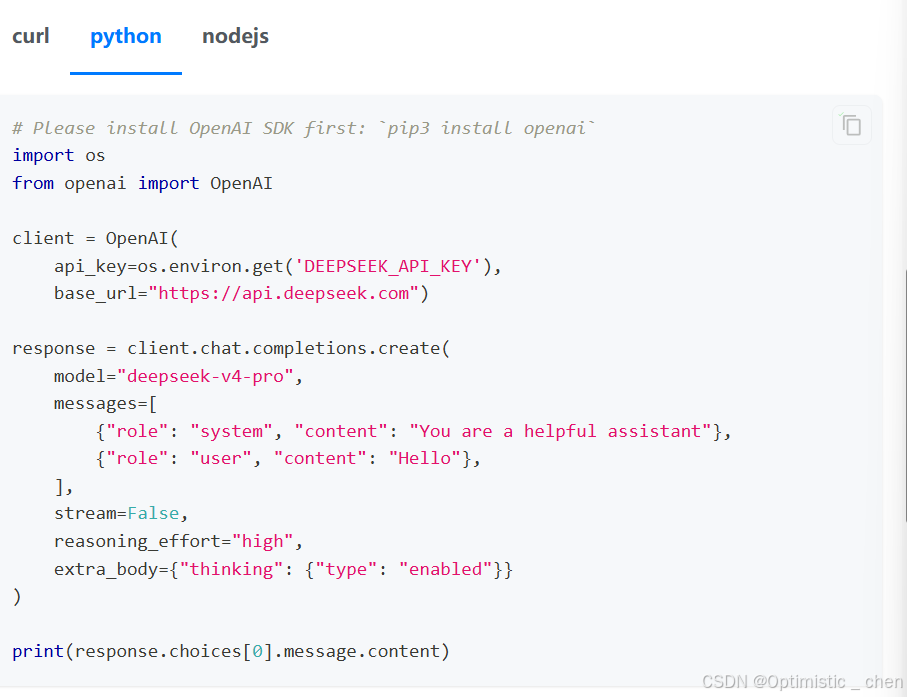
本地接入
大模型本地部署,这种方式是将开源的大语言模型部署在自己的硬件环境中。
部署流程:
- 获取模型:从Hugging Face、魔塔社区等平台下载开源模型
- 准备环境:硬件环境配置要有足够的显存,安装必要的驱动和框架
- 选择推理框架:Ollama一键拉取和运行模型
- 启动服务并调用:框架会启动一个本地API服务器,可以像HTTP一样发送请求
一般的笔记本只能安装7b或者8b的模型,感兴趣的同学可以自己玩一玩。
SDK接入
严格来讲,SDK 不属于独立的 LLM 接入方案,其本质只是对原生 HTTP 接口调用的上层封装,依附于公有云 API、私有化推理服务这两类基础接入方式。
各大模型厂商会推出适配 Java、Python、Go 等语言的官方 SDK,底层仍然是发送 HTTP/HTTPS 网络请求,只是把鉴权 Header、请求体序列化、异常捕获、流式回调、参数校验等底层逻辑全部封装完毕。
开发者无需手动拼接 curl 请求、处理 JSON 序列化、维护超时与重试逻辑,直接调用面向对象风格的函数 / 方法即可发起对话、工具调用、RAG 相关请求,大幅降低编码成本。
import os
from dotenv import load_dotenv
from openai import OpenAI
# 加载环境变量
load_dotenv()
# 初始化DeepSeek客户端
client = OpenAI(
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url=os.getenv("DEEPSEEK_BASE_URL")
)
def chat_normal():
response = client.chat.completions.create(
model="deepseek-v4=-pro", # 对话模型
messages=[
{"role": "system", "content": "你是专业AI技术讲师,简洁回答问题"},
{"role": "user", "content": "解释RAG和Agent的区别"}
],
temperature=0.7,
max_tokens=1024
)
# 打印完整回复
print(response.choices[0].message.content)
if __name__ == "__main__":
chat_normal()
相比较直接构造HTTP请求,代码更简洁,更易维护。
三种接入方式优缺点
为了帮助您根据自身场景选择最合适的接入方式,以下是三种方式的优缺点对比:
| 接入方式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| API 接入 |
|
|
|
| 本地接入 |
|
|
|
| SDK 接入 |
|
|
|
选择建议
- 追求效率与快速启动:优先选择 API 接入,并配合官方 SDK 进行开发。
- 注重数据安全与长期成本:若具备硬件条件,选择 本地接入,并同样使用 SDK 来简化调用。
- 混合架构:对于大型企业,可采用混合模式——敏感业务使用本地模型,非敏感或创新业务使用云端 API,均通过统一的 SDK 层进行抽象,以平衡成本、安全与灵活性。
总而言之,SDK 是提升开发体验的最佳实践,而 API 与本地部署则是底层算力来源的路线选择。请根据您的具体需求在“便捷性”、“安全性”、“成本”和“可控性”之间做出权衡。
解决LLM的限制
首先明确一个点,所有的LLM都有固定的上下文窗口,我们无法将超过窗口的数据塞给模型;其次模型训练的数据截至它停止训练的那天,模型不能回答私有的数据的问题;最后模型的输出格式不可控,即使我们通过提示词要求模型输出JSON格式,但他仍可能产生错误的内容。
为了解决这些问题,我们就可以采用前面说过的技术组件,RAG 用来加载私有资料、压缩文本适配上下文窗口;Tool Calling 让模型可以调取外部实时数据,不用局限于训练时的旧知识;再搭配结构化输出约束和 Agent 自检,强制规范返回 JSON 等固定格式,解决输出混乱、解析报错的问题。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 2
2 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)