
【Agentic RL / 强化学习 / OPD】OpenClaw-RL 源码阅读笔记 --- (2)--- On-Policy Distillation
概要
本系列的目的是:借着对 OpenClaw-RL 源码的学习,来梳理强化学习的一些相关概念和思想。所以,会有一些基础知识、扩展和发散,OpenClaw-RL 只是一个切入点。而且,因为整篇系列是一个整体,所以有些概念的解读/学习会在不同的文章中出现,还请大家谅解。
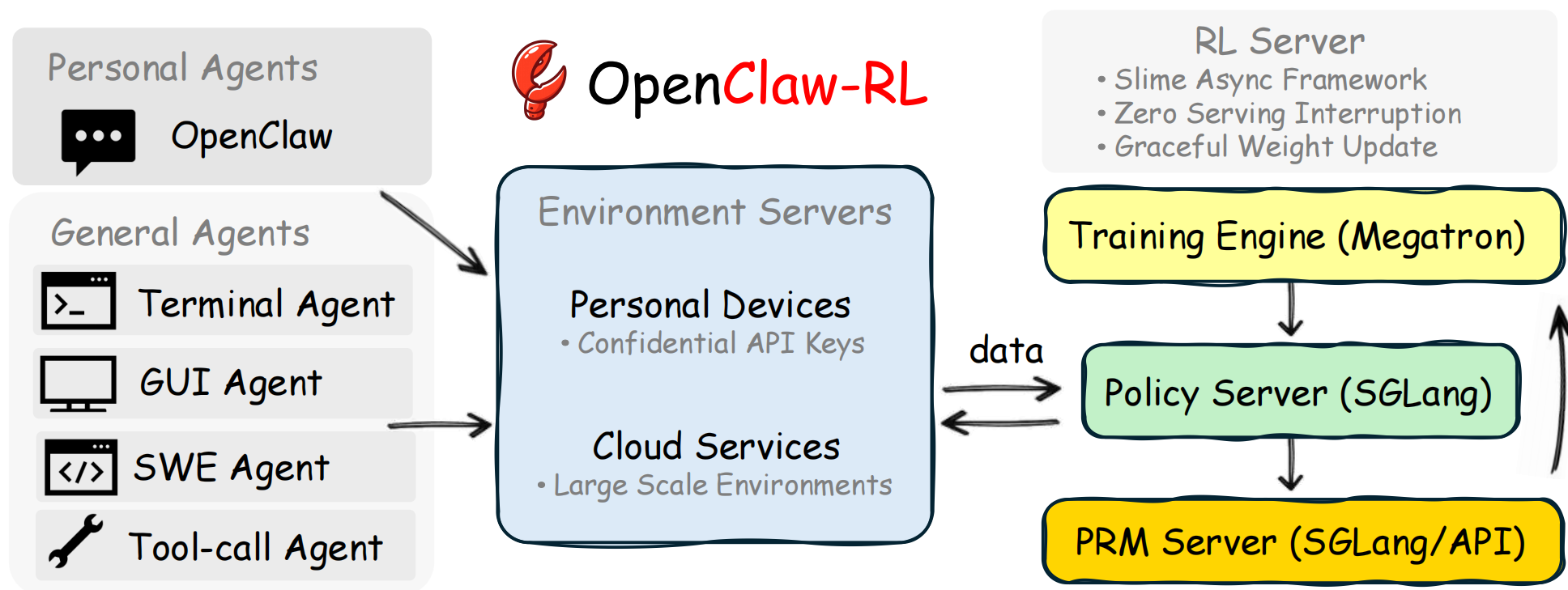
OpenClaw-RL 是一个用于在线强化学习(Online RL)的框架,专门针对智能体工具使用场景。它通过从环境反馈中提取过程奖励信号来训练语言模型,支持三种主要模式:
- openclaw-rl:基于二元奖励的强化学习(Binary RL / GRPO)
- openclaw-opd:基于后见之明提示的在线策略蒸馏(On-Policy Distillation, OPD)
- openclaw-combine:联合方法,在同一 PPO 更新中同时利用 RL reward 和 OPD teacher signal
0x01 On-Policy Distillation
OPD是整个架构中最深入、最有差别化的核心设计,是剖析整个框架优势的最佳切入点。
On-Policy Distillation(策略内蒸馏 / 同策略蒸馏) 是强化学习(RL)与知识蒸馏(KD)融合的训练范式,核心是让学生模型在自身生成的轨迹(On-Policy)上学习,同时获得教师模型提供的逐步骤密集监督信号,兼顾了传统 RL 的 “贴合自身分布” 与监督蒸馏的 “高效学习” 两大优势。
1.1 核心定位:解决传统方法的两难
传统 RL 与离线知识蒸馏存在固有缺陷,OPD 旨在打破此困境:
| 方法 | 样本来源 | 反馈信号 | 核心优势 | 致命缺陷 |
|---|---|---|---|---|
| 标准 RL (PPO) | On-Policy(学生自生成) | 稀疏(最终奖励) | 贴合自身策略、探索有效 | 反馈稀疏、训练极慢、成本高 |
| 离线蒸馏 (SFT) | Off-Policy(教师生成) | 密集(逐 token) | 学习高效、收敛快 | 分布偏移、学生易 “纸上谈兵”、难泛化 |
| On-Policy Distillation | On-Policy(学生自生成) | 密集(逐 token) | 兼顾贴合自身 + 高效学习 | 需维护教师模型、计算成本略增 |
1.2 通俗类比
1.2.1 概述
- RL:自己下棋,只知输赢,不知错步,要自己摸索
- 离线蒸馏:看大师棋谱,照搬但不理解自身棋局。
- OPD:自己下棋,大师实时逐步点评,精准纠错。有具体建议+正确示范,学得更快。
所以,OPD就像是给AI配了一个超级耐心的老师,让它在帮你做事的过程中,不断地变得更聪明、更贴心!
1.2.2 详述
想象你在玩两款不同的学习游戏!
普通 RL 游戏
普通RL游戏:“猜对了才有分“
- 游戏规则:
-
你做题:老师给你一道题,你给出答案
-
老师打分:老师只说“对!“或“X错!“
-
自己琢磨:如果错了,你要自己想“到底哪里错了?“
-
- 举个例子:
-
题目:小明有5个苹果,吃了2个,还剩几个?
-
你的答案:还剩8个!
-
老师反馈:错!(就这一个字!)
-
你的困惑:“啊?到底是加法错了?还是减法错了?还是数字算错了?“
-
- 这个游戏的特点:
-
很难学:因为只知道对错,不知道怎么改进
-
要试很多次:可能要猜好多次才能找到正确方法
-
容易放弃:总是被说“错”,但不知道为什么错
-
- AI助手是怎么学习的?
-
像独自摸索的学生
-
被用户说“不对“时,只能自己猜哪里错了
-
需要很多很多次练习才能变聪明
-
OPD 游戏
OPD游戏:“超级老师手把手教“
-
游戏规则:
-
你做题:老师给你一道题,你给出答案
-
智能提示:系统自动分析你的错误,给出具体建议
-
老师示范:超级老师现场演示正确做法
-
对比学习:你可以看到自己的答案和老师的答案有什么不同
-
-
举个例子:
- 题目:小明有5个苹果,吃了2个,还剩几个?
- 第一步:AI开始尝试
- 你的答案:还剩:8个!
- 第二步:老师给出一个超级有用的“后见之明“提示
- 智能提示:“记住:吃了要用减法,不是加法哦!下次遇到吃了、用了、花了这样的词,要想到减法!“
- 这个提示就是“后见之明“一意思是“事后才知道的聪明建议”。
- 第三步:AI 重新思考
- 现在,AI助手拿到了这个提示,它会这样想:“哦!原来如此!题目里说吃了2个,应该是5-2=3个才对!“
- 第四步:老师示范正确做法
- 老师看到同样的题目和提示,会这样回答:“小明原来有5.个苹果,吃了2个,所以要用减法:5-2=3。答案是3个苹果。
- 第五步:学生AI向老师学习
- 你的领悟:“哦!原来吃了是要减掉的!我明白了!
-
这个游戏的特点:
-
学得快:直接告诉你怎么改进
-
不迷茫:知道具体的错误原因
-
有信心:有老师带着你一步步进步
-
-
AI助手是怎么学习的?
-
像有私人教练的学生
-
每次犯错都有“后见之明提示“告诉它怎么改进
-
还有“超级老师AI"给它做正确示范
-
所以学得特别快,很快就变得很聪明!
-
1.3 持续学习中的知识注入与能力保持困境
在构建能够持续进化的智能系统时,一个核心挑战在于如何平衡“可塑性”与“稳定性”。模型既要具备足够的可塑性以吸纳新知识,又要维持足够的稳定性来保护已有的能力储备。传统的监督微调(SFT)与强化学习(RL)作为两种主流技术路径,在这一目标上各自存在显著的局限性。
1.3.1 SFT的激进性与灾难性遗忘
监督微调(SFT)本质上是一种离策略(Off-Policy)的学习过程。它强制模型去拟合由外部专家数据定义的标注分布,这种做法相当于将模型参数强行拉向一个新的、往往是局部最优的解空间。由于缺乏对原始模型参数空间的显式约束,这种激进的优化方式极易破坏模型在预训练阶段习得的通用知识结构和底层表征,从而引发严重的灾难性遗忘。简而言之,SFT在高效注入特定领域知识的同时,往往会以牺牲模型的通用能力为代价,导致“学新忘旧”的现象。
1.3.2 RL的保守性与样本效率瓶颈
相比之下,强化学习(RL)通常表现出更强的稳定性。其在线策略(On-Policy)的特性意味着模型是在自身当前的认知边界内进行探索和优化,这天然地限制了其行为偏离原始能力的范围。然而,RL的短板在于其对稀疏奖励信号的依赖。它擅长通过试错来优化行为策略,却难以实现高密度、细粒度的知识传递。因此,RL的训练过程往往伴随着高昂的计算成本和较低的样本效率,使其在需要快速、精准注入大量新知识的场景下显得力不从心。
1.3.3 SFT vs RL
我们再回头对比下RL和SFT。
SFT 在改写模型;RL 在唤醒模型。改写需要小心,唤醒天然安全。
| 维度 | SFT | RL |
|---|---|---|
| 学什么 | 每token模仿固定 y | 在自己的输出空间里挑好答案 |
| 泛化机制 | 靠数据多样性外推 | 靠信息瓶颈+流形采样内推 |
| 遗忘控制 | 无显式机制 | KL锚点 + clip + on-policy |
| 失败模式 | 过拟合、暴力位移 | reward hacking、采不到目标解 |
训练分布不同:off-policy VS on-policy
SFT 是off-policy
训练数据来自人工/教师模型,模型从未自己生成过这些 trajectory。这导致两个问题:
-
Exposure bias:训练时 prefix 永远是 ground truth,推理时 prefix 是模型自己的输出→分布偏移
-
Catastrophic forgetting:要拟合外来分布,权重大幅偏移;与原模型分布远的样本会"挤压"已有能力
RL是on-policy(或近似)
训练数据永远从模型当前能产出的轨迹里挑。这有几个直接好处:
- 模型只在自己的"行为支撑集"内更新,权重不会被外来分布拽离原始流形
- 更新本质是重新加权(re-weighting)已有能力,而不是注入新映射
- 不需要的能力不会被显式抑制(reward 不惩罚它)
一个直观比喻
- SFT像强制让你抄一遍标准答案 → 你可能记住了这一题,但不一定理解
- RL像老师对你自己写的答案打+1/-1分 → 你被迫从"自己已会做的解法里"挑出最稳的那个,然后强化它
目标函数本质不同:模仿VS偏好
SFT的目标
LSFT=−E(x,y)∼D,logπθ(y∣x)
这是强匹配目标:要求模型在每一个 token 上复刻训练数据。问题在于:
- 数据集D里的y是众多可行解中的一条特定路径
- SFT不区分y的"答案正确"与"表达方式",两者一起被记忆
- 任何与y不同的输出都被视为"错",包括等价改写、不同推理顺序
因此,SFT在做行为克隆(behavior cloning),必然倾向记忆而非抽象。
RL的目标(以PPO/GRPO为例)
LCLIP=Et[min(rt(θ)^At,clip(rt(θ),1−ϵ,1+ϵ)^At)]
这是弱匹配目标:模型可以走任何路径到达高reward,区别仅在路径之间的相对优劣。
| 维度 | SFT | RL |
|---|---|---|
| 监督粒度 | 每token全监督 | 序列级标量 / token级advantage |
| 等价解 | 视为错误 | 视为同等优 |
| 探索性 | 零 | 强(采样自身) |
| 信号KL容量 | 高(把整个y烙进模型) | 低(只告诉"好/坏") |
RL的reward信号只携带1log(候选数)bit;SFT的cross-entropy信号每token都有loglVlbit。信号位数少→ 模型必须靠抽象去拟合,无法靠死记。这是RL泛化更强的最深刻原因:信息瓶颈强制泛化。
KL约束+重要性采样:天然的"防遗忘锚点"
PPO/GRPO 等 on-policy RL 算法都有:
L=Et[min(rt(θ)^At,clip(rt(θ),1−ϵ,1+ϵ)^At)]−β⋅KL(πθ||πref)
两个机制天然抑制遗忘:
- PPO clip:限制每步策略相对 πold的概率比变化在 [1−ϵ,1+ϵ](典型 0.2)→单步更新幅度被卡死
- KL惩罚:直接把πθ拉回参考模型 πref(通常是SFT后的模型)→显式锚定原能力_
SFT 没有任何与原分布的距离约束,loss=0时仍可能离 πref任意远。这就是为什么:
- SFT 上一个新领域→老领域大幅退化(catastrophic forgetting)
- RL上一个新任务→老能力基本保留(KL锚点+on-policy不引入分布外样本)
1.3.4 OPD:一种融合稳定与高效的协同范式
在线策略蒸馏(OPD)的出现,为解决上述两难困境提供了一种优雅的协同方案。它巧妙地结合了RL的稳定性和SFT的高效性。
该范式的核心机制在于,首先让学生模型依据其当前策略自主生成交互轨迹。随后,教师模型并非在一个预设的、静态的数据集上进行指导,而是在学生模型真实访问到的状态上,提供逐词元(Token-level)的监督信号。这种设计实现了双重优势:
- 继承稳定性: 由于监督信号是基于学生模型自身的在线策略产生的,整个学习过程天然地保持在模型原有的能力分布附近,极大地缓解了参数空间的剧烈偏移,从而有效抑制了灾难性遗忘。
- 提升效率: 教师提供的密集监督信号,如同为学生铺设了一条清晰的优化路径,避免了RL中因稀疏奖励而导致的盲目探索,显著提升了知识注入的效率和精度。
综上所述,OPD范式通过将对齐过程锚定于学生模型的实时策略之上,成功地在知识吸收的效率与既有能力的保持之间找到了一个更优的平衡点。它不仅是一种技术上的改进,更代表了一种新的持续学习思路:即通过引导模型在其自身的能力边界上进行自我修正与扩展,而非强行施加外部标准,从而实现真正意义上的稳健进化。
1.4 核心原理与数学形式
1.4.1 核心流程(三步闭环)
-
On-Policy 采样:学生模型 π_θ 基于输入 x 自主生成完整序列 y=[y1,y2,...,yt]。
-
教师密集评估:教师模型 π_teacher 对学生生成的每一步 yt 评估,输出分布概率。
-
反向 KL 优化:学生最小化与教师在自身生成轨迹上的方向 KL 散度(Reverse KL),即 DKL(πθ∥πteacher)。
LOPD(θ)=Ex∼D,y∼πθ[1T∑Tt=1DKL(πθ(⋅|x,y<t)∥πteacher(⋅|x,y<t))]
- 侧重让学生在自己会犯错的地方贴近教师,抑制低概率错误,稳定性更强。
1.4.2 与 RL 的理论等价性
OPD 本质是带密集隐式奖励的 KL 正则化 RL:
- 等价目标:maxθE[rt]−DKL(πθ∥πref)
- 密集奖励:rt=logπteacher(yt|x,y<t)(每步即时奖励)
- 标准 OPD 约束:奖励与 KL 正则项权重固定为 1:1
1.5 关键技术变体与演进
1.5.1 G-OPD (广义 On-Policy Distillation)
突破标准 OPD 的 1:1 约束,引入奖励缩放因子 α 与灵活参考模型:
LG-OPD=E[α⋅logπteacher]−DKL(πθ∥πref)
- ExOPD (奖励外推):当 α>1 时,学生可超越教师性能。
- 强师弱生优化:用教师预训练基模型作参考,提升蒸馏稳定性。
1.5.2 OPCD (On-Policy Context Distillation)
面向大模型上下文学习,让学生内化上下文知识:
- 学生无上下文生成 y → 教师带上下文评估 y → 学生优化以匹配上下文感知的教师分布。
1.5.3 SDPO (Self-Distilled Policy Optimization)
自我蒸馏:无需外部教师,以模型自身历史优策略为教师,实现闭环自我迭代。
1.6 核心优势
- 效率革命:训练成本降至传统 RL 的 1/10,收敛速度提升 10 倍。
- 分布对齐:在学生自身分布上学习,无分布偏移,泛化性强。
- 稠密反馈:逐 token 监督,精准定位错误,避免信用分配难题。
- 稳定可靠:Reverse KL(DKL(πθ∥πteacher))与 On-Policy 采样结合,训练过程极稳定、不掉点。
- 小模型利器:8B 小模型可高效继承 70B 大模型能力,支持低成本部署。
1.7 与 DPO/PPO/KD 的核心区别
- VS PPO:OPD 是密集奖励,PPO 是稀疏奖励;OPD 收敛更快、更稳。
- VS 离线 KD:OPD 是On-Policy(学生自生成),KD 是 Off-Policy(教师数据);OPD 无分布偏移。
- VS DPO:DPO 基于偏好排序,OPD 基于教师完整分布;OPD 监督更密集、信息更丰富。
为了更直观体现各方法的差异与适配场景, 下表从核心定位、样本来源、监督信号、损失核心、关键优势、核心缺陷、适配场景7 个核心维度梳理,同时标注各方法的核心关键词和训练效率(以★数量表示,★越多效率越高)。
| 对比维度 | On-Policy Distillation (OPD) | PPO (近端策略优化) | DPO (直接偏好优化) | 离线 KD (知识蒸馏) |
|---|---|---|---|---|
| 核心定位 | RL+KD 融合,学生自实践 + 教师实时逐步指导 | 经典 On-Policy RL,纯策略自我迭代优化 | 偏好对齐 RL,用人类 / AI 偏好替代奖励 | 纯监督蒸馏,教师教学生照搬已有经验 |
| 样本来源 | On-Policy(学生自身生成的轨迹 / 序列) | On-Policy(策略自生成的交互数据) | Mix-Policy(部分自生成 + 部分偏好样本) | Off-Policy(教师预生成的固定数据集) |
| 监督信号 | 密集逐步:教师模型的逐 token 概率分布 | 稀疏:环境反馈的最终奖励值 | 成对偏好:样本对的相对优劣排序 | 密集逐步:教师模型的逐 token 概率分布 |
| 损失核心 | Reverse KL 散度 DKL(πθ∥πteacher)(学生∥教师),聚焦纠正自身错误。 | 裁剪优势函数 + KL 正则,限制策略更新幅度 | 偏好损失,最大化优选样本的相对概率 | KL 散度(学生∥教师)/MSE,拟合教师固定分布 |
| 核心关键词 | 同策略、密集监督、无分布偏移、教师依赖 | 同策略、稳定更新、纯强化、信用分配 | 偏好对齐、免奖励建模、易落地、弱监督 | 异策略、高效拟合、数据固定、强教师依赖 |
| 关键优势 | 1. 兼顾同策略分布对齐 + 密集监督效率;2. 无分布偏移,泛化性强;3. 精准纠正逐步错误,避免信用分配难题 | 1. On-Policy RL 中稳定性最优,不易发散;2. 纯自主探索,无需外部教师 / 偏好标注;3. 适配复杂环境交互,策略探索性强 | 1. 免手动设计奖励函数,对齐更贴合实际需求;2. 标注成本低于逐步监督,落地难度低;3. 可结合少量自生成样本优化 | 1. 训练效率最高,收敛速度极快;2. 无需环境交互,纯静态数据训练;3. 小模型快速继承大模型核心能力 |
| 核心缺陷 | 1. 需维护教师模型,额外占用计算资源;2. 教师性能上限决定学生最优性能;3. 相比离线 KD,采样阶段有少量计算成本 | 1. 奖励稀疏,训练周期长、成本高;2. 存在信用分配难题,难以定位逐步错误;3. 样本利用率低,需持续重新采样 | 1. 偏好监督信息较稀疏,优化粒度粗;2. 部分场景存在偏好偏移,泛化性弱于 OPD;3. 策略探索性弱于纯 PPO | 1. 严重分布偏移,学生 “纸上谈兵”,泛化性极差;2. 无自主探索能力,难以适配动态环境;3. 对数据集质量高度敏感,易过拟合 |
| 训练效率 | ★★★★(高效,约为 PPO 的 10 倍) | ★★(低效,样本利用率低) | ★★★(中高效,兼顾标注与优化) | ★★★★★(极高效,纯静态拟合) |
| 适配场景 | 1. LLM 精细对齐(数学推理 / 代码生成);2. 垂直领域小模型高效训练;3. 游戏 AI 实时策略学习(需精准逐步优化) | 1. 复杂动态环境交互(机器人 / 无人车);2. 无外部监督 / 教师的纯策略探索场景;3. 需强探索性的游戏 AI(如星际争霸) | 1. 大模型人类偏好对齐(对话 / 指令遵循);2. 标注成本有限,无法做逐步监督的场景;3. 对策略精细度要求不高的对齐任务 | 1. 小模型快速冷启动,继承大模型基础能力;2. 静态任务建模(如文本分类 / 固定问答);3. 无环境交互的纯生成任务快速拟合 |
1.8 小结
On-Policy Distillation 是当前大模型与强化学习融合的主流高效范式,以 “学生自主实践 + 教师实时点评” 为核心,完美解决了效率与性能的平衡问题,成为训练高性能、低成本小模型的首选技术。
0x02 Hindsight-Guided On-Policy Distillation
本节文字参考 神仙思路!普林斯顿提出OpenClaw-RL:Agent在线挨骂在线升级!。
2.1 理解难点识别
理解论文的关键在于如何把自然语言的反馈变成大模型能处理的梯度更新信号。其中最具挑战性的部分是后见之明引导的同策略蒸馏(Hindsight-Guided On-Policy Distillation, OPD)。传统的RLHF只能给出标量总分,但OPD能精确到每一个Token的修改方向。OPD机制是全文需要重点解释的核心概念。
2.2 实际信号
OpenClaw-RL 关心一个贴近真实部署的问题:”agent 在线运行时,每一步交互后天然产生的 next-state signal,能不能直接被回收成训练信号?” 。这里的 next state 可以是很多东西:用户下一句回复、工具执行结果、终端 stdout/stderr、GUI 状态变化、SWE 环境中的测试 verdict 或报错 trace。传统系统通常只把这些内容当成下一轮推理的上下文,而 OpenClaw-RL 的核心观察是:它们其实天然包含了对上一步动作的监督,而且这种监督几乎是”免费”的,因为 agent 本来就在持续收到这些信号。
OpenClaw-RL 把 next-state signal 明确拆成两类。
- 第一类是 evaluative signal,也就是”这一步做得好不好”的信号,比如用户重新追问往往意味着上一轮回答没有解决问题,测试通过意味着当前修改有效,命令报错或 GUI 没有产生预期变化则意味着这一步失败了。
- 第二类是 directive signal,也就是”这一步应该怎么改”的信号,比如用户说”你应该先检查文件再编辑”,或者环境返回的错误信息明确暴露出 bug 类型和出错位置。
前者最适合转成 scalar reward,用 RL 吃掉;后者则更适合转成 token-level 的 directional supervision,用 OPD 吃掉。也正因为此,OpenClaw-RL 的意义并不只是再提一个 OPD 变体,而是把 next-state 中本来混在一起的两类监督同时回收:一部分进入 binary / process RL,另一部分进入 hindsight-guided OPD。
2.3 具体实现
2.3.1 目标
目标:将指导性下一状态信号转化为Token级方向性监督信号。
OPD的核心洞察是:如果将原始提示与从st+1中提取的文本提示相结合,同一模型会产生不同的Token分布一这个分布“知道"响应应该是什么样的。由此计算得到Token级优势。
2.3.2 深入技术细节
传统的强化学习只能给出全局打分,但OPD通过对比两种状态下的输出概率,给出了每一个词的修改方向。核心数学公式如下:

这是一个策略蒸馏(Policy Distillation)或 OPD(Offline Policy Distillation)中的优势计算公式。其中符号的含义如下:
| 符号 | 含义 |
|---|---|
| At | 优势函数(Advantage) |
| πteacher | 教师策略(Teacher Policy) |
| at | 时刻 t 的动作 |
| senhanced | 增强后的状态/提示 |
| πθ | 当前策略(Student Policy,参数为 θ) |
| st | 原始状态 |
该公式的自然语言符号替换版本为: 某个词的优势值 = (老师模型在看到事后提示后生成该词的对数概率) - (普通学生模型在原始状态下生成该词的对数概率)。
这个式子本质上是:teacher 比 student 更认可这个 token 的程度。是教师策略在增强状态下的动作对数概率,减去学生策略在原始状态下的动作对数概率。差值越大,说明学生策略与教师策略的差距越大,需要更多优化。
- 如果某个 token 上 teacher 概率高、student 概率低 → advantage 为正 → 训练会推动 student 提高这个 token 的概率
- 如果 student 已经比 teacher 更高 → advantage 为负 → 训练会推动 student 降低这个 token 的概率
所以,On-Policy Distillation之所以更能避免知识遗忘,核心原因在于它让模型在自己的轨迹上学习,并且由教师提供密集、逐步的纠错信号,来重新对齐教师模型。是在 student 自己生成的 token 序列上,蒸馏 teacher 对这些 token 的概率分布。
2.3.3 提取 Hint
从 OPD 的角度看,OpenClaw-RL 的 teacher 构造方式其实非常接近前面总结的 self-distillation,而不是经典的”外部强教师蒸馏”。它不是固定

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)