
Agent最佳实践指导之 - Skills工程
当下有个相当火热的名词```Skill```,其已经在各个智能体应用中得到应用。Skill能够使大模型的执行、分析的准确性大大提升。简单理解其原理就是给大模型出示了一份份说明书,大模型需要按照说明书上的指示完成任务。本篇文章就是详细说明在搭建智能体应用时对于skills的配置方法,贴合企业级场景,考虑到各种真实场景可能会出现的问题并给出解决方案。本文大体会从0到1,具体关注架构层面出发,而减少具体的操作方法、代码等。
1.如何开始
我们知道,skill实际上就是一套任务规范,大模型需要在执行特定任务时找到对应的skill。所以Skills的结构就很重要,如果我们有2000个skill,这肯定是不能将skill一下子塞进大模型的上下文。
这里我可以点出本篇文章的主题“渐进式披露”,这是当下agent skill 工程的最佳实践
首先应该将所有的skills建立为一个个的MD文件,模型对于这种文件的理解最为高效。
大模型在默认情况下需要去遍历这2000个skill寻找正确的文件,这无疑相当消耗模型的上下文。所以skills结构的最佳实践应该是树状结构:
例如:

像这样,以目录-子目录的方式对skills进行构建,同时注意要在命名上保证功能的隔离性。
2.如何精确查找需要的Skill
当模型需要利用skill时,上面结构虽能够减少上下文的占用,但无法保证准确性和召回率。因为模型实际上还是依靠文件名称猜测病递归寻找的。那么为了解决这个问题,则还需对其进行升级。
既然目标是提高查找精确度,那么我们可以对skill建立一级索引,在启动时生成一个json文件,模型无需再去递归查找文件目录,而是去索引文件中查找。
索引块的结构类似这样:
{
"name": "deploy-k8s",
"content": "部署Kubernetes应用。用户可能说:上线服务、发布新版本、回滚Pod、查看部署状态。",
"file_path": "/skills/deploy.md"
}模型会先根据用户的需求然后与索引文件中的skill描述进行比对,从而找到正确的skill地址。
注意:skill的描述应当精炼、独特,这里content是实际被向量化的文本,而name和path作为元数据(Metadata)返回。描述越像真实用户提问,召回率越高。
3.如何进一步优化
上面其实已经是skills的标准规范了,但是如果想真正达到能够落地,生产环境使用的话,以下优化是必不可少的。
首先,如果将比对并查找skill的工作交给大模型的话,不仅会增加模型额外的上下文开销,又会导致效率的降低。在市面上绝大多数的Agent产品都是将大模型的职责归一化,专注于推理和顶层决策,多余的任务会影响模型的准确性。
3.1 向量数据库优化
这个时候我们可以引入向量数据库,将skill描述向量化,并将索引存入数据库中。在查询时,模型通过请求服务,将用户输入与skill描述进行语义相似度匹配,将相似度最高的数据进行返回。
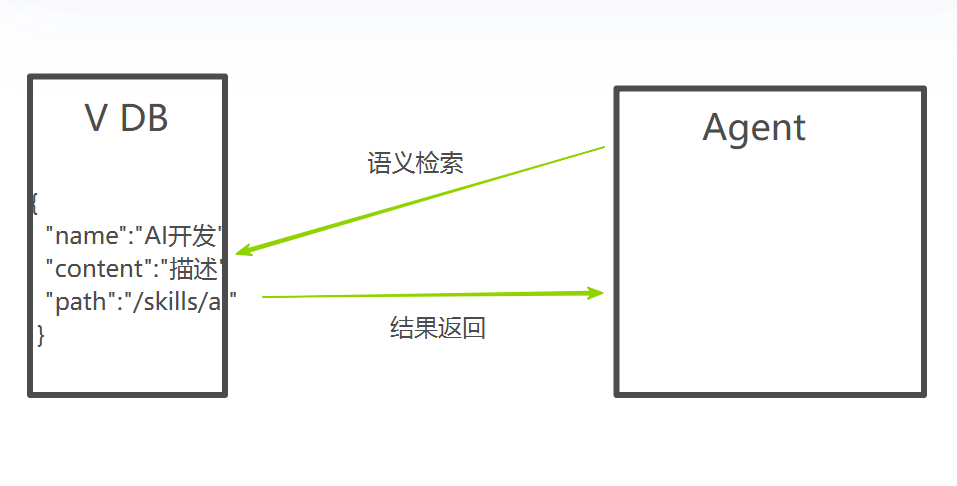
3.2 双路召回
在很多场景下,用户的输入可能不是常规的询问,而是一段错误码、日志等信息,这个时候单靠语义检索是不可靠的,因为向量模型并不理解其中的含义
-
做法:采用 语义向量召回 + 关键词BM25(或ES文本匹配) 并行检索,将两路结果加权合并(即混合检索Hybrid Search)。
-
效果:用户输入
"kubectl rollout undo"时,BM25能精确命中,弥补语义模型对特定术语的迟钝。
3.3 查询改写
用户的原始输入(如“帮我弄一下那个服务器”)太模糊,直接拿去搜向量库大概率匹配不准。
-
做法:在检索之前,先让模型(或小模型)将用户输入改写为面向技能库的搜索语句。
-
示例:将“帮我弄一下那个服务器”改写为“服务器运维、SSH连接、重启服务、环境部署”,再用改写后的句子去查向量库。
3.4 设定Top-k + 阈值
在实际运行时有时可能会遇到一次匹配得到大量的结果的情况,这个时候应该使用双重过滤:Top-K + 阈值过滤
-
策略:
-
向量检索取 Top-3 或 Top-5(不要取太多)。
-
设定相似度阈值(如 0.7),低于阈值直接告诉模型“没有找到相关技能”,而不是硬塞一个不相关的技能给模型(否则模型会幻觉)。
-
读文件限制:读取匹配到的
SKILL.md时,只读取核心指令部分,如果MD文件过长,只截取前 2000-3000 tokens 作为“核心指南”,剩余详细脚本(Scripts/References)留待模型在执行具体步骤时再次按需调用(即二次检索)。
-
3.5 引入缓存
缓存其实是业务场景下最有效的效率提升手段,我们需要对常用的和不常用的Skill分开处理,即将常用打分Skill进行缓存,这在Skill数量庞大的情况下十分有效。(冷热分离)
-
做法:在向量库前加一层 LRU(最近最少使用)内存缓存。
-
以当前会话(Session ID)为单位,如果用户持续在一个对话上下文中,将该上下文已加载过的技能文件路径缓存起来。
-
模型每次检索前,先问缓存:“这个用户之前用过的技能,和现在的输入匹配吗?”(通常用简单的关键词匹配),命中缓存则跳过向量检索,直接加载缓存中的
.md文件。
-

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)