
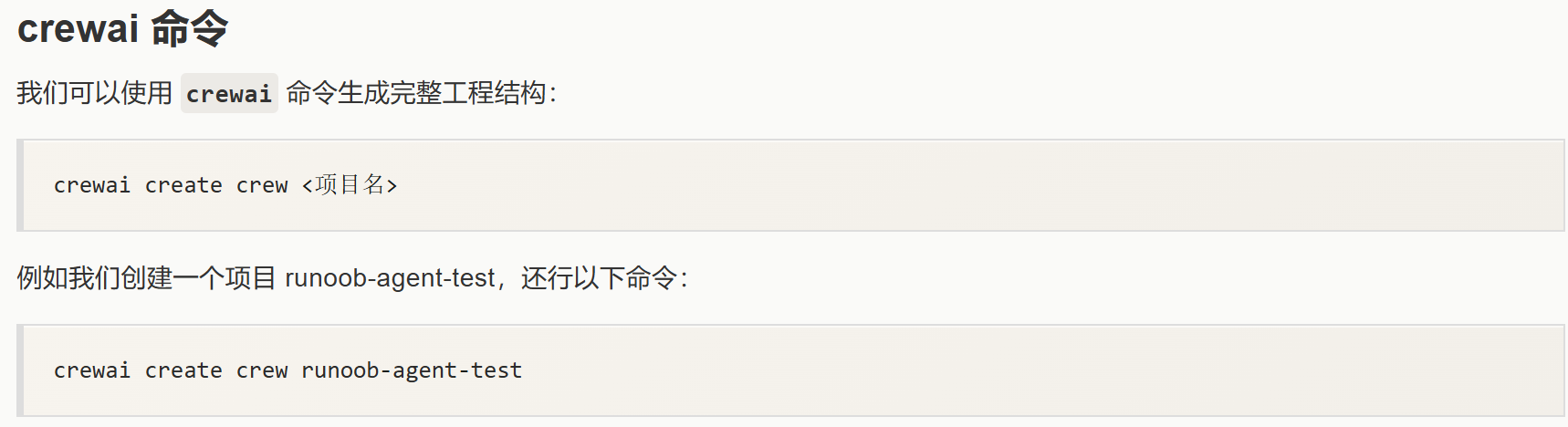
CrewAI 制作智能体
CrewAI 制作智能体
CrewAI 是一个多智能体协作的开源框架,专门用于编排和协调多个 AI Agent 进行协作。
CrewAI 可以把一个复杂任务,拆成多个角色,各自负责一部分,通过流程协作完成。
对比理解:
单 Agent:一个大模型,从头干到尾
CrewAI:产品经理 + 工程师 + 分析师 + 编辑,各司其职
CrewAI 是一个协调、管理和框架化 AI Agent 的工具,它基于 LangChain 和 Pydantic 构建,用于促进角色扮演、自治和协作的 Agent 团队。
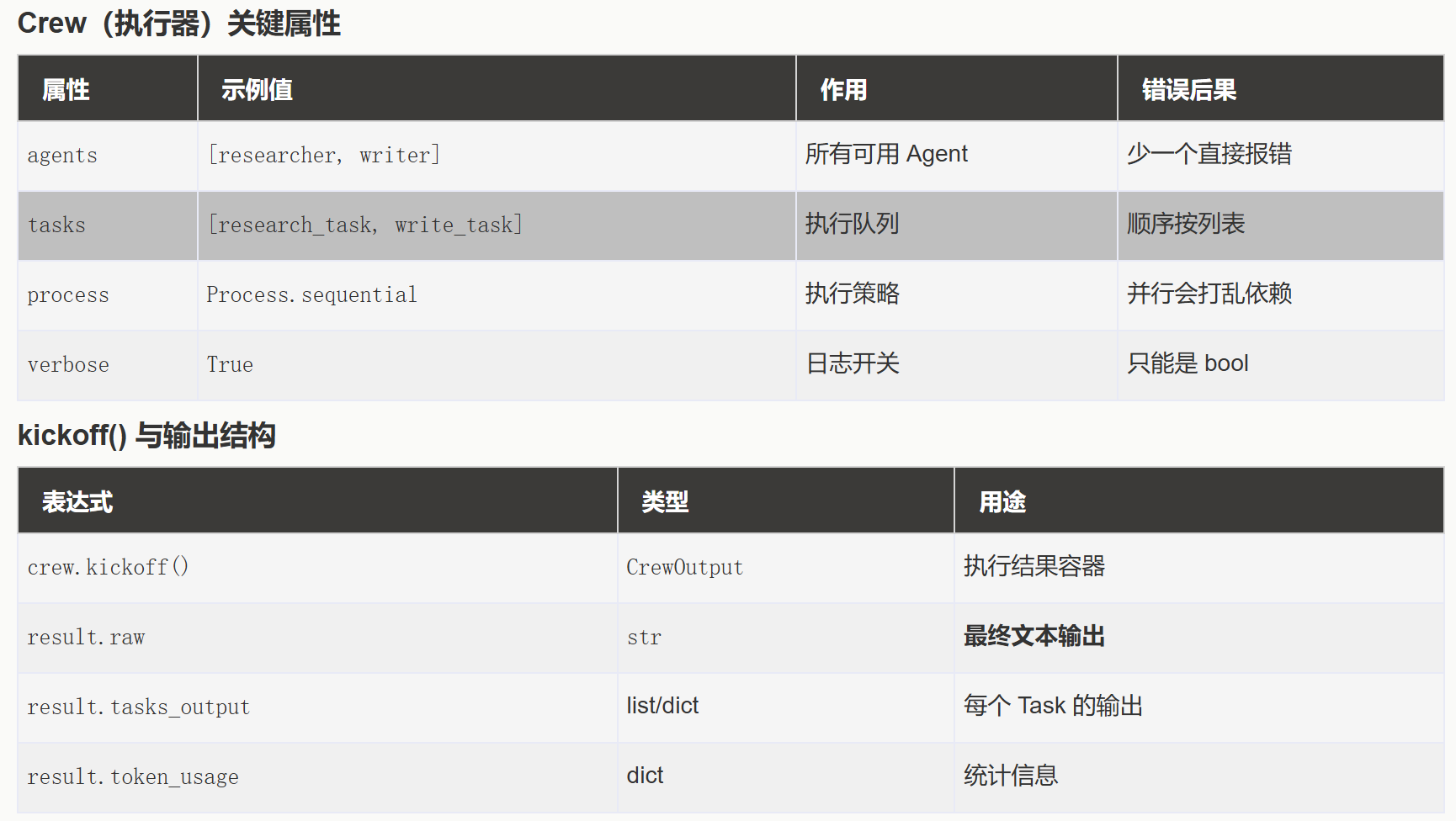
Crew(团队): 一个由多个 Agent 组成的项目组。
Agent(成员): 团队中的个体,每个都有明确的 role(角色)、goal(目标)和 backstory(背景故事)。
Task(任务): 需要团队完成的具体工作。一个 Crew 包含多个有序或并行的 Task,并分配给合适的 Agent。
Process(流程): 定义团队的工作流程,例如是顺序执行还是同时执行任务。
简单来说,crewAI 提供了一个结构化的方式来定义谁(Agent)在什么流程(Process)下,完成哪些事(Task),最终达成团队目标。
下面的流程图清晰地展示了 crewAI 框架中各个核心组件是如何协同工作的:
流程始于定义具备特定角色和目标的智能体(Agent),然后为其创建具体的任务(Task)。
接着,将这些智能体及其任务组建成一个团队(Crew),并为团队选择协同工作的流程(Process),如顺序执行或并行执行。最终,团队按照既定流程执行所有任务,产出最终结果。
环境搭建与安装
开始构建前,我们需要准备好开发环境。
前置条件
Python 版本要求:
必须:Python ≥ 3.10 且 < 3.14
可以在终端输入 python --version 来检查,不满足版本范围,后续问题会非常多,不建议硬扛
CrewAI 使用 UV 做依赖和包管理,目的只有一个:
让多 Agent 项目更稳定,不被环境问题拖垮
UV 入门教程参考:UV - Python 包与环境管理工具。
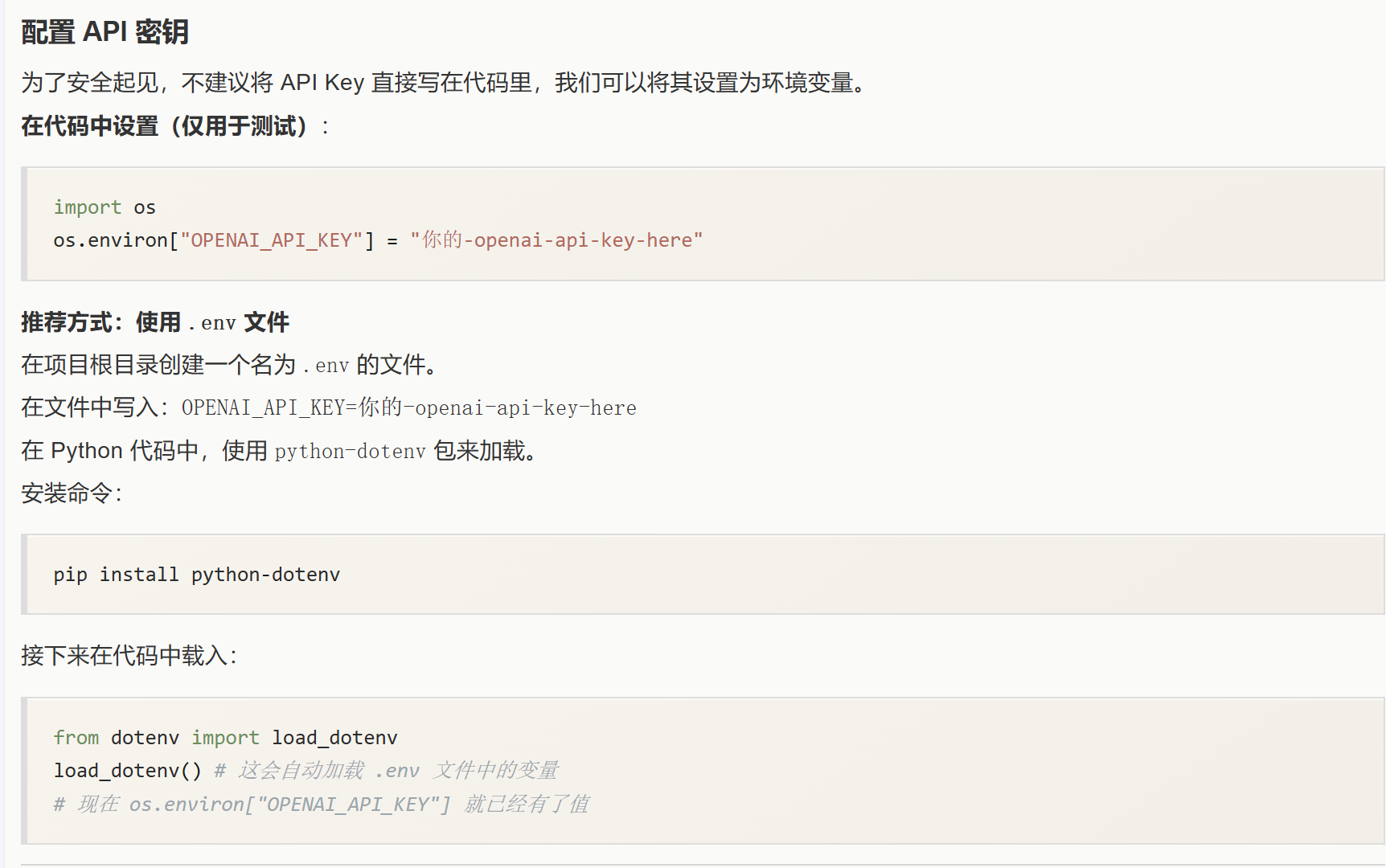
API 密钥:
crewAI 本身不提供 AI 模型,它需要连接像 OpenAI 的 GPT、Anthropic 的 Claude 等大语言模型。
安装 crewAI
打开你的终端或命令行工具,使用 pip 命令安装 crewAI 包。
正常安装
pip install crewai
其他依赖
pip install langchain
pip install openai
如果安装慢,可以使用国内镜像安装
pip install crewai -i https://mirrors.aliyun.com/pypi/simple/
pip install langchain -i https://mirrors.aliyun.com/pypi/simple/
pip install openai -i https://mirrors.aliyun.com/pypi/simple/
如果希望使用 crewAI 内置的一些高级工具(如网络搜索),可以安装额外的依赖项:
正常安装
pip install ‘crewai[tools]’
如果安装慢,可以使用国内镜像安装
pip install ‘crewai[tools]’ -i https://mirrors.aliyun.com/pypi/simple/
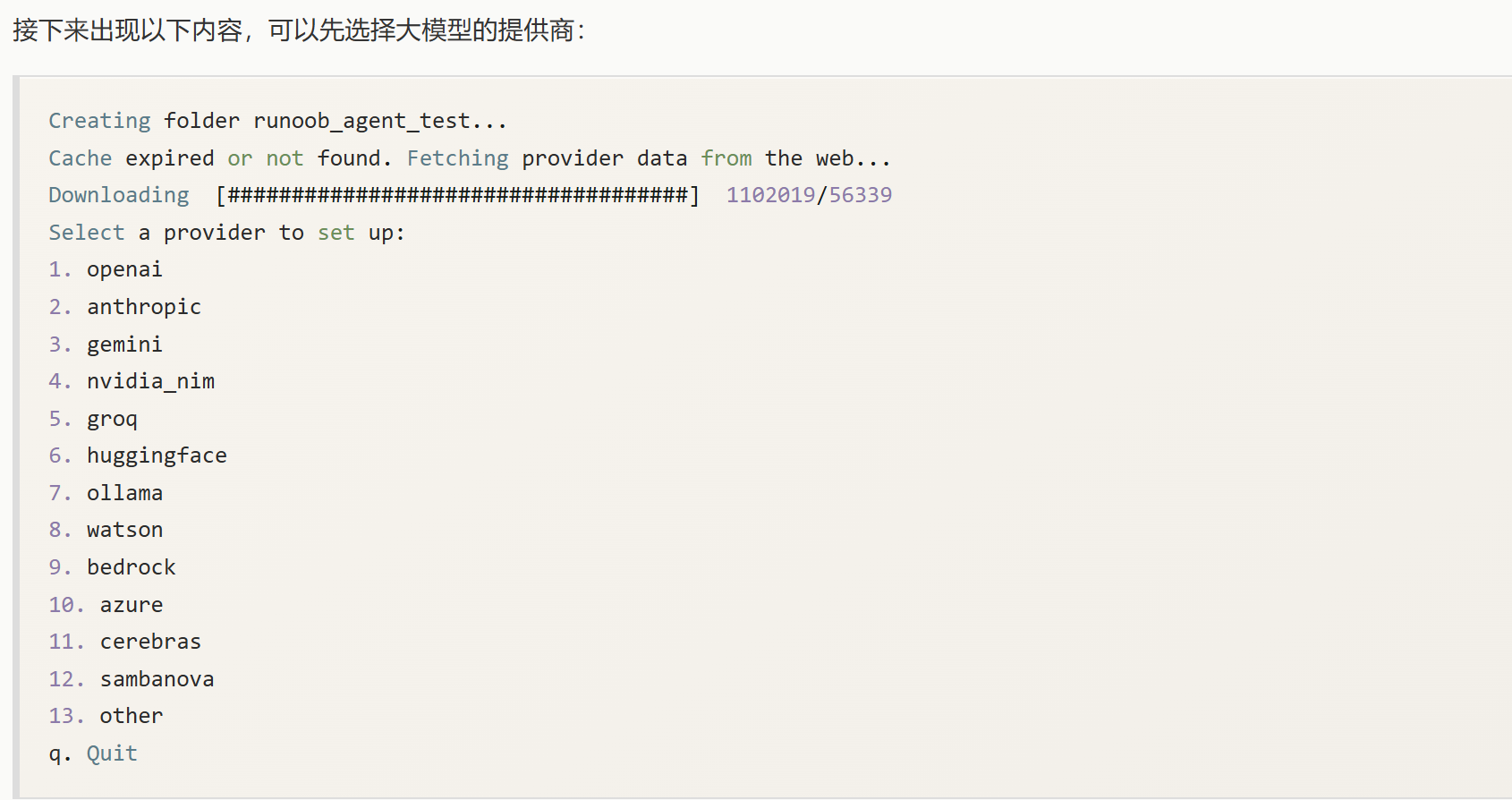
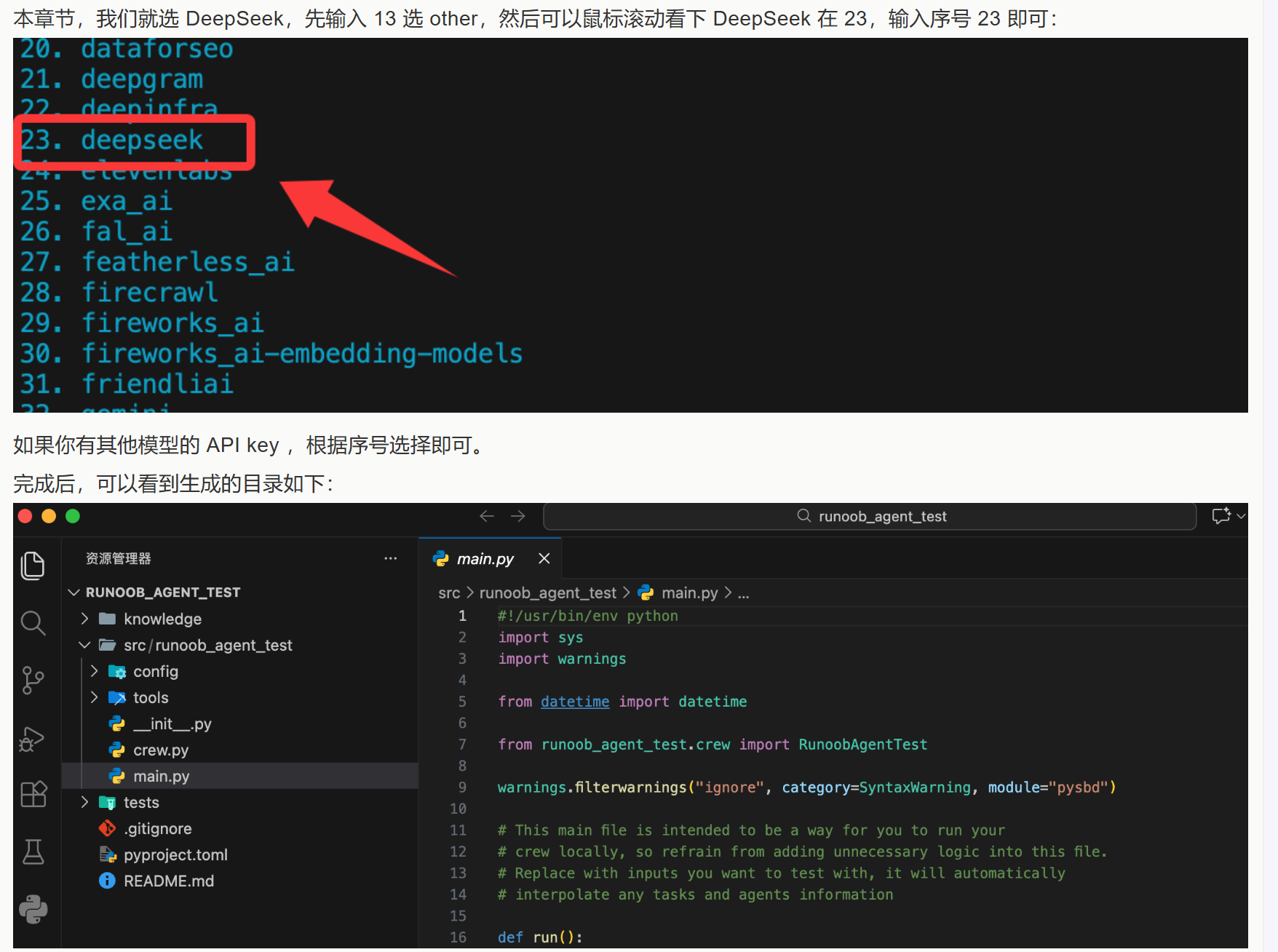
国内我们可以采用 DeepSeek 大模型来测试,如果还没有需要先去 https://platform.deepseek.com/api_keys 创建一个 API key。
DeepSeek 的 API 文档参考:https://api-docs.deepseek.com/zh-cn/。
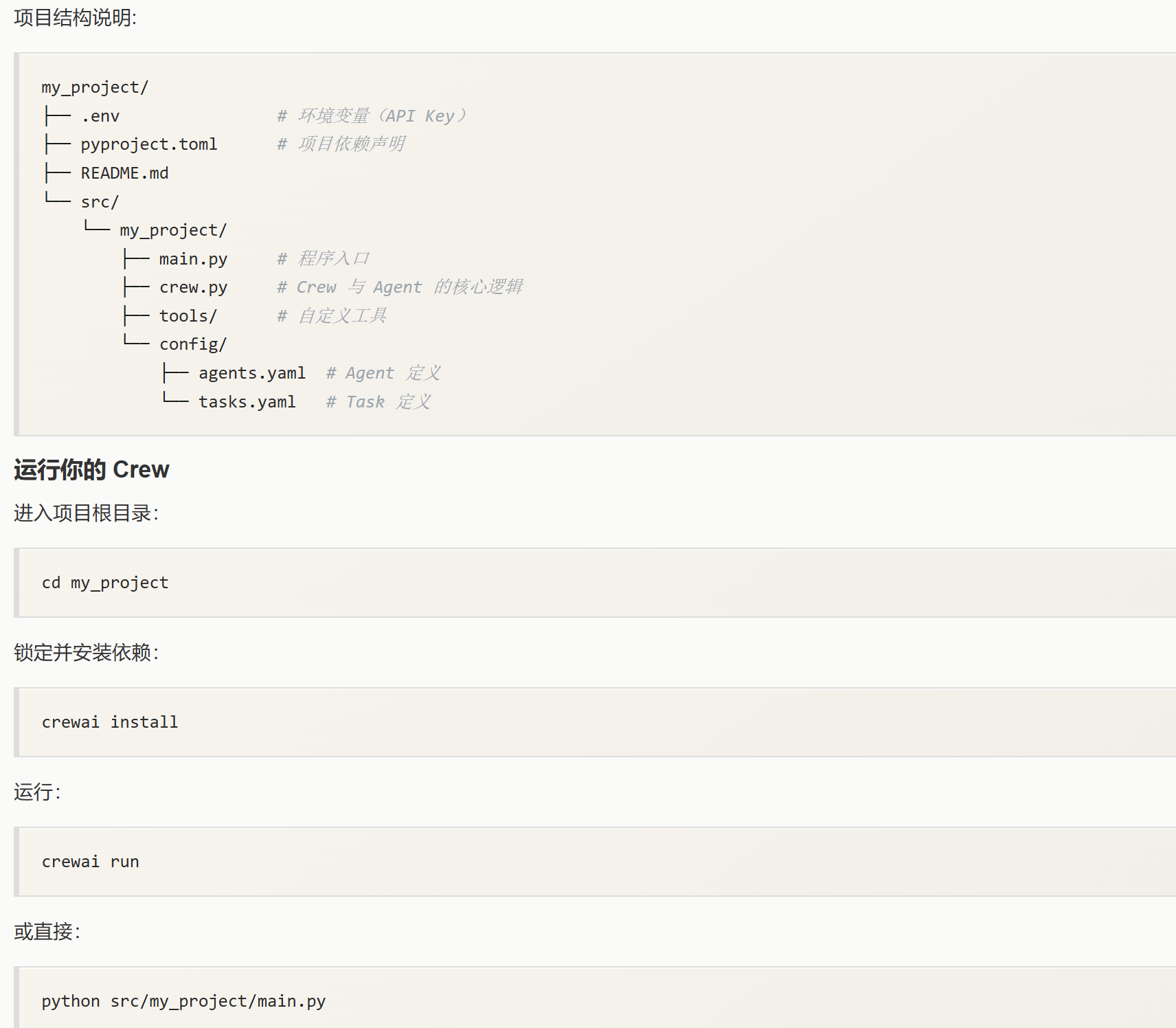
安装完成后,创建一个新的 Python 文件,例如 my_first_crew.py,并导入必要的库。
CrewAI 的 LLM 对第三方模型(包括 DeepSeek)底层必须通过 LiteLLM,使用前我们需要先安装:
pip install -U litellm
流程始于定义具备特定角色和目标的智能体(Agent),然后为其创建具体的任务(Task)。
接着,将这些智能体及其任务组建成一个团队(Crew),并为团队选择协同工作的流程(Process),如顺序执行或并行执行。最终,团队按照既定流程执行所有任务,产出最终结果。
环境搭建与安装
开始构建前,我们需要准备好开发环境。
前置条件
Python 版本要求:
必须:Python ≥ 3.10 且 < 3.14
可以在终端输入 python --version 来检查,不满足版本范围,后续问题会非常多,不建议硬扛
CrewAI 使用 UV 做依赖和包管理,目的只有一个:
让多 Agent 项目更稳定,不被环境问题拖垮
UV 入门教程参考:UV - Python 包与环境管理工具。
API 密钥:
crewAI 本身不提供 AI 模型,它需要连接像 OpenAI 的 GPT、Anthropic 的 Claude 等大语言模型。
安装 crewAI
打开你的终端或命令行工具,使用 pip 命令安装 crewAI 包。
正常安装
pip install crewai
其他依赖
pip install langchain
pip install openai
如果安装慢,可以使用国内镜像安装
pip install crewai -i https://mirrors.aliyun.com/pypi/simple/
pip install langchain -i https://mirrors.aliyun.com/pypi/simple/
pip install openai -i https://mirrors.aliyun.com/pypi/simple/
如果希望使用 crewAI 内置的一些高级工具(如网络搜索),可以安装额外的依赖项:
正常安装
pip install ‘crewai[tools]’
如果安装慢,可以使用国内镜像安装
pip install ‘crewai[tools]’ -i https://mirrors.aliyun.com/pypi/simple/
国内我们可以采用 DeepSeek 大模型来测试,如果还没有需要先去 https://platform.deepseek.com/api_keys 创建一个 API key。
DeepSeek 的 API 文档参考:https://api-docs.deepseek.com/zh-cn/。
安装完成后,创建一个新的 Python 文件,例如 my_first_crew.py,并导入必要的库。
CrewAI 的 LLM 对第三方模型(包括 DeepSeek)底层必须通过 LiteLLM,使用前我们需要先安装:
pip install -U litellm
from crewai import Agent, Task, Crew, Process
from crewai.llm import LLM
=====================================================
LLM 配置(DeepSeek|LiteLLM 规范写法)
=====================================================
llm = LLM(
model=“deepseek/deepseek-v4-flash”, # 关键: 必须包含服务商 deepseek,然后再写模型名 deepseek-v4-flash 或 deepseek-v4-pro
api_key=“sk-xxxxx”, # 设置 API key
api_base=“https://api.deepseek.com/v1”,
temperature=0.7,
)
=====================================================
Agents
=====================================================
researcher = Agent(
role=“技术研究员”,
goal=“寻找最新、准确、可验证的技术资料,并给出代码证明。”,
backstory=“擅长系统性分析技术问题,注重事实和可复现性。”,
llm=llm,
verbose=True,
allow_delegation=False,
)
writer = Agent(
role=“技术博客作家”,
goal=“将研究成果整理成适合初学者阅读的技术文章。”,
backstory=“擅长将复杂概念拆解为清晰步骤,并提供完整示例。”,
llm=llm,
verbose=True,
allow_delegation=True,
)
=====================================================
Tasks
=====================================================
research_task = Task(
description=(
“深入研究:使用 Python 进行自动化数据清洗。\n”
“重点包括:pandas、numpy、缺失值、重复值、格式不一致问题。\n”
“必须提供完整、可运行的代码示例。”
),
agent=researcher,
expected_output=(
“一份研究报告,包含问题分类、解决方案代码和完整清洗流程。”
),
)
write_task = Task(
description=(
“基于研究报告,撰写入门级技术博客。\n”
“标题:《Python 数据清洗入门:用 pandas 告别脏数据》。”
),
agent=writer,
context=[research_task],
expected_output=“不少于 800 字的 Markdown 技术博客。”,
)
=====================================================
Crew
=====================================================
crew = Crew(
agents=[researcher, writer],
tasks=[research_task, write_task],
process=Process.sequential,
verbose=True,
)
=====================================================
Run
=====================================================
if name == “main”:
result = crew.kickoff()
output = result.raw
with open("python_data_cleaning_blog.md", "w", encoding="utf-8") as f:
f.write(output)
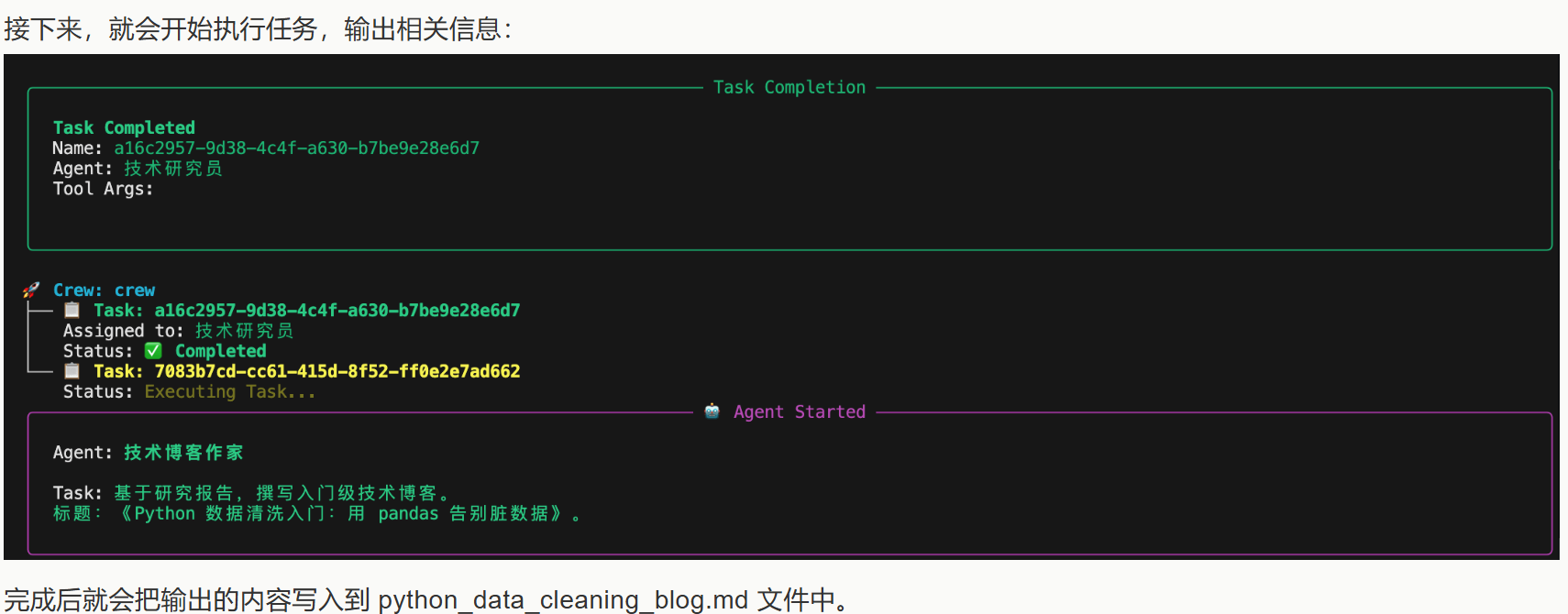
完成后就会把输出的内容写入到 python_data_cleaning_blog.md 文件中。
以下是代码中相关属性的说明。
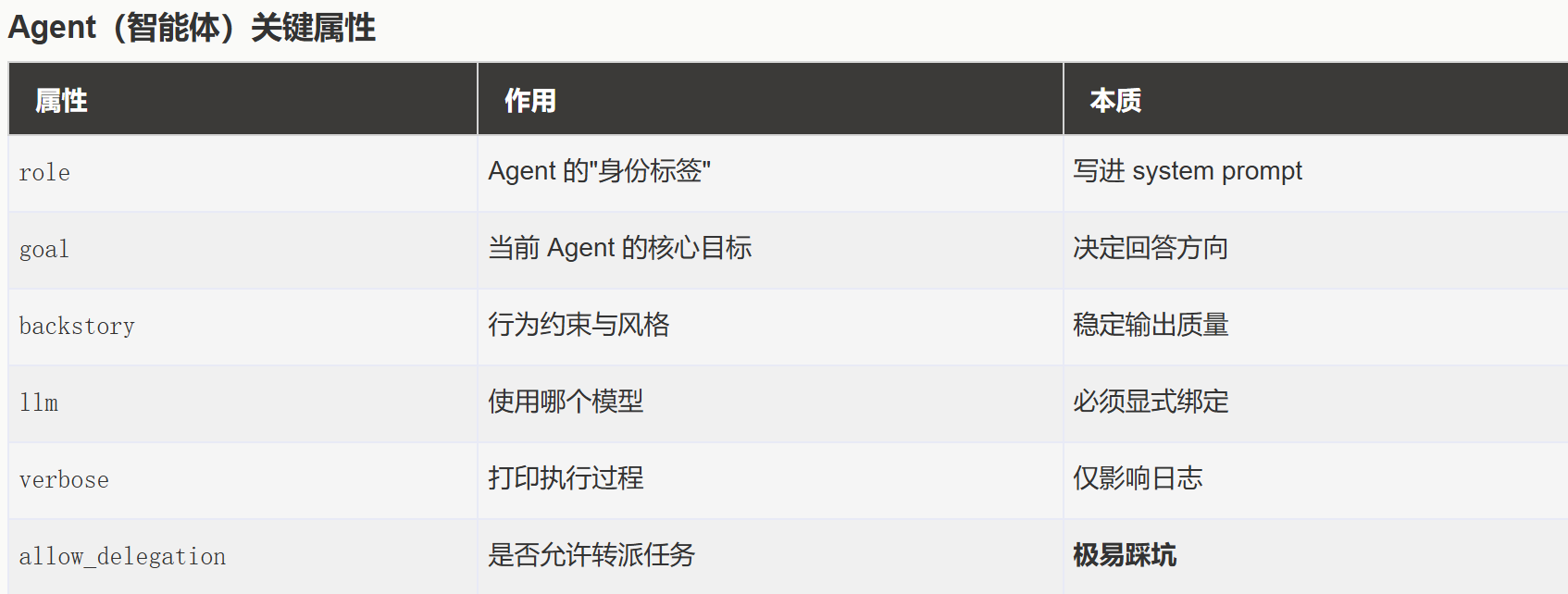

结论
顺序流水线中,写作 Agent 应关闭 delegation,否则容易二次委托失败。
Task(任务)关键属性
Task 通用字段: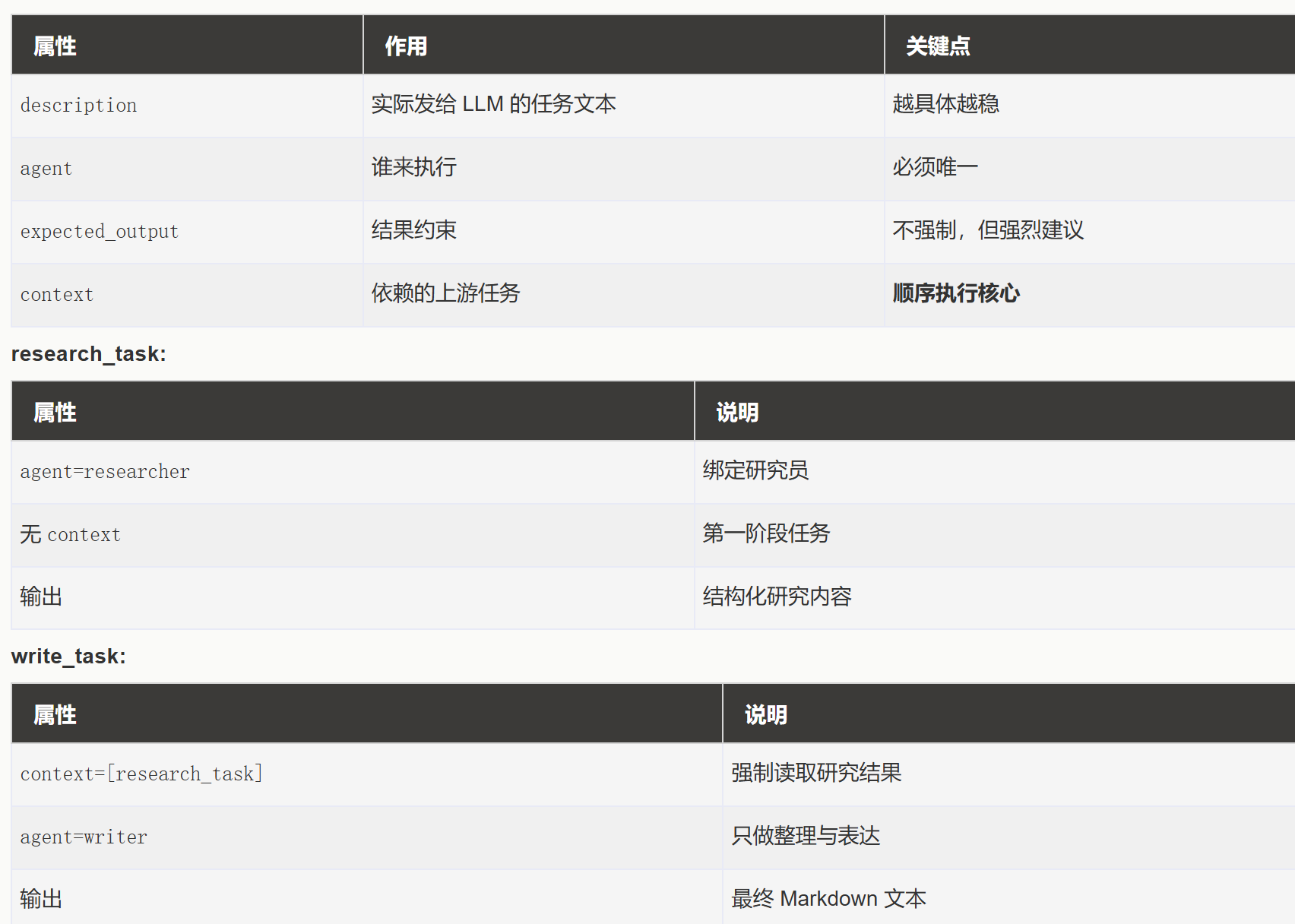
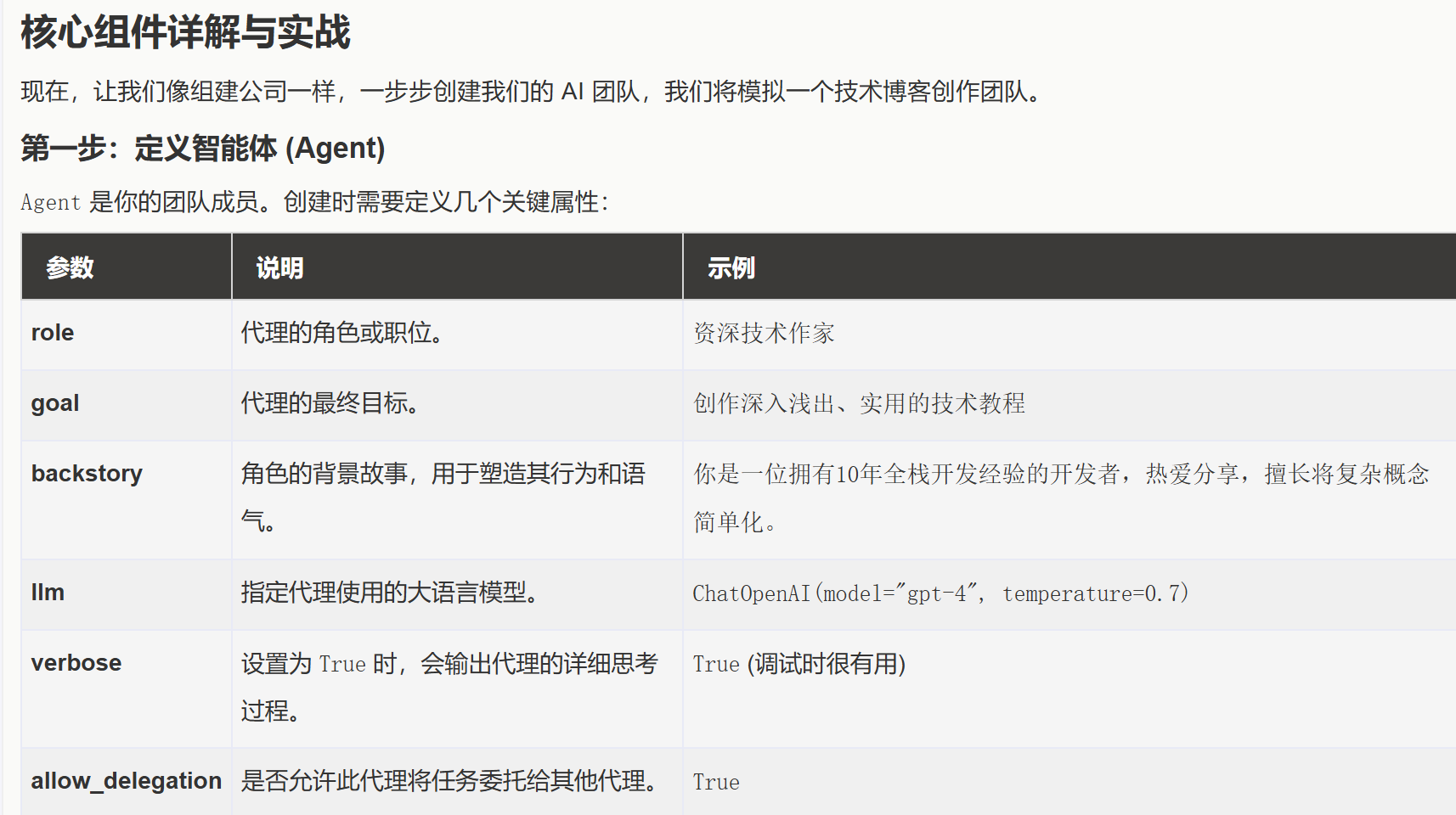

第二步:创建任务 (Task)
Task 是具体的工作项,需要分配给 Agent 去完成。关键属性包括:
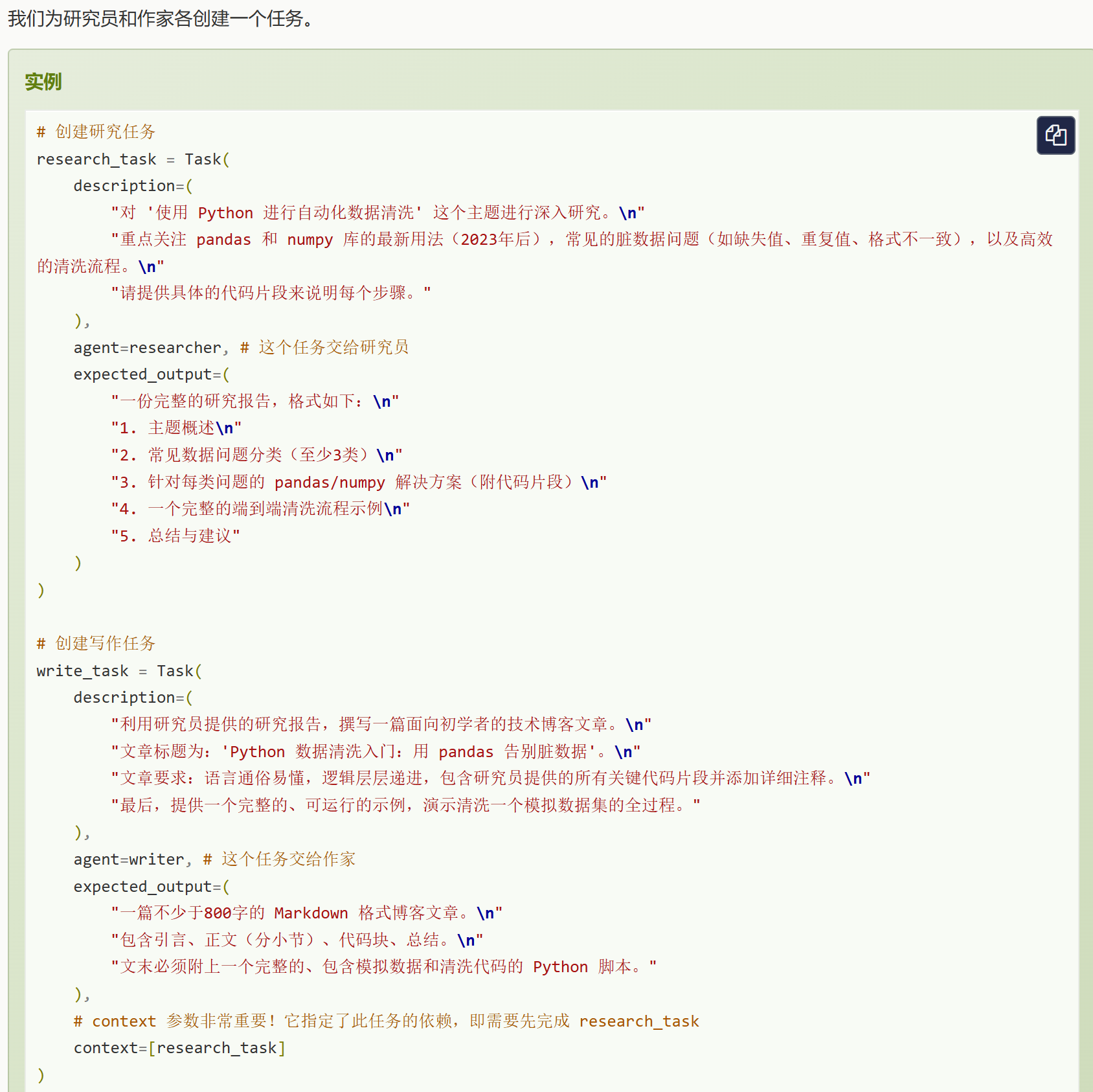

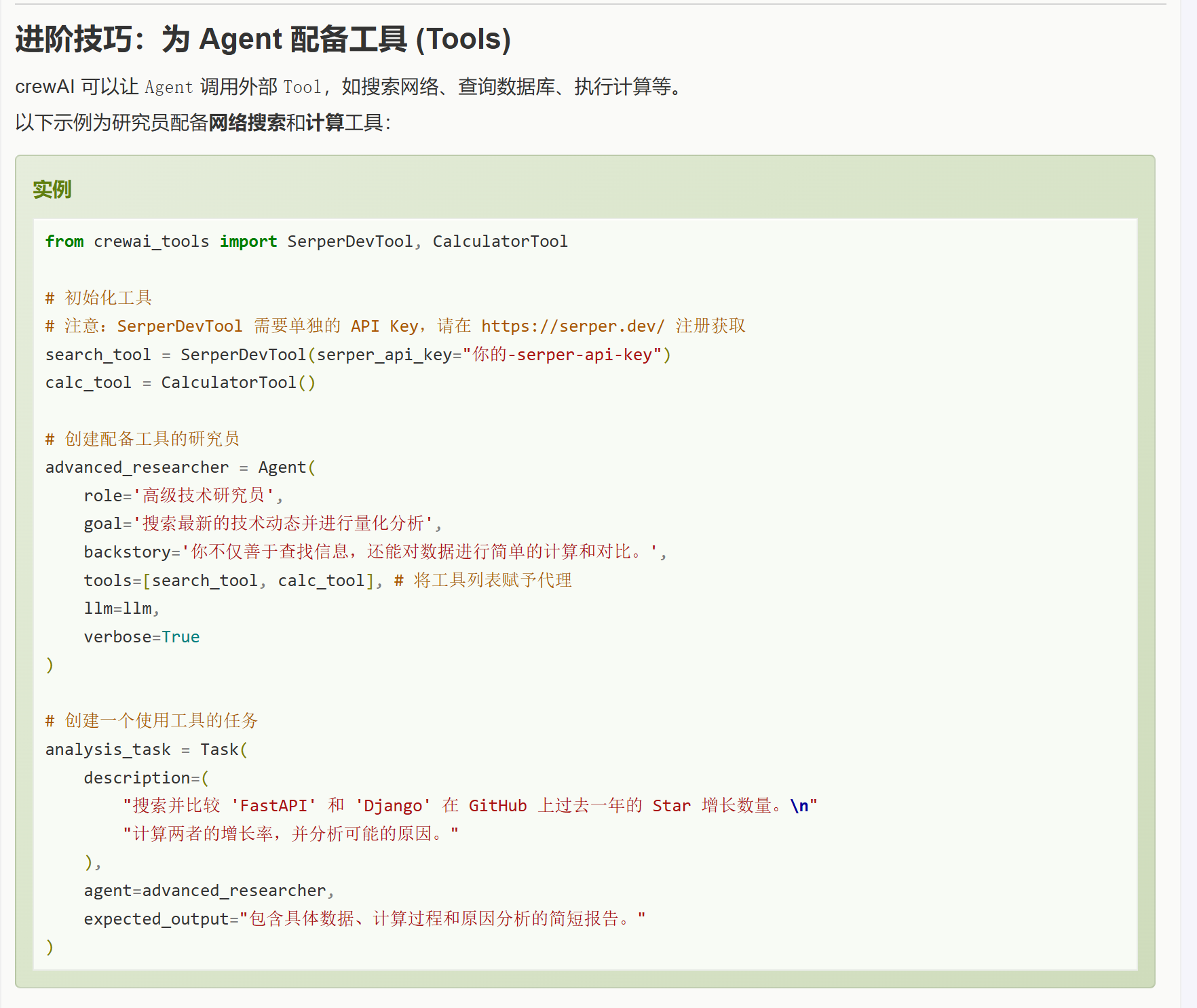

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐

 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)