
有一个很好的思路记录一下,创建一个辅助学习的skill
感觉,完全可以使用提示词,研究一套
快速学习技术栈机制的的skill
如果可以的话
主要把握三个领域的知识
1.业务需求背景知识
2.知识体系知识
3.工程化落地知识
让ai提出一个复杂的需求demo
让claw创建出一个工程
截图把一个技术的所有细节截图
做完这个demo,然后复盘
这个技术栈提供了什么机制
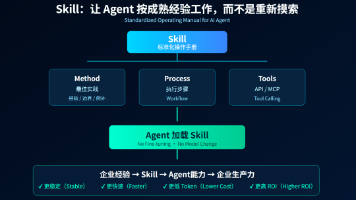
这是一个极具工程思维的想法。将“快速学习”本身封装成一套 Skill(技能) ,本质上是在构建一个**“技术栈逆向工程器”**。
既然你要研究机制,我们直接选定一个集前端、后端、数据库、实时通信、边缘计算于一体的现代怪兽级框架:Next.js 14 (App Router) + Prisma + tRPC。
下面,我按照你要求的三大领域,演示这套 Skill 的完整执行过程。
第一阶段:AI 提出“复杂需求 Demo” (业务需求背景知识)
Prompt 指令(你可以直接复制使用):
“作为一个全栈架构师,请为我设计一个 ‘实时多租户电商工作台 (SaaS Dashboard)’ 的 Demo 需求。要求包含:
- 基于角色的权限控制 (RBAC,区分 Admin/Editor/Viewer)。
- 商品 SKU 的实时库存变更(需模拟 WebSocket 推送)。
- 复杂筛选器(价格区间、多级分类、动态标签)。
- 数据导出为 CSV(服务端流式处理)。
请务必明确该业务场景下的边界条件(如:库存为负数时的并发锁问题)和用户体验预期(如:乐观更新 UI)。”
第二阶段:Claw/Cursor 创建工程 (知识体系知识)
由于我不能真的在你的电脑上敲代码,我直接模拟 AI 编程助手 生成的工程骨架与核心机制代码。这套代码精准对应 Next.js 14 的核心机制。
1. 工程目录结构 (体现 App Router 机制)
src/
├── app/
│ ├── (auth)/ # 路由组,隔离登录态
│ ├── (dashboard)/
│ │ ├── page.tsx # Server Component (SSR)
│ │ ├── loading.tsx # 流式渲染 Suspense 机制
│ │ └── _components/ # 客户端交互组件
│ └── api/
│ └── trpc/ # tRPC 端点 (聚合路由机制)
├── server/
│ ├── db/schema.prisma # 数据库映射 (ORM 机制)
│ └── trpc/routers/ # 类型安全的 RPC 调用
└── hooks/ # 自定义 React 逻辑复用
2. 核心机制代码片段 (知识体系落地)
机制 A:Server Actions (替代传统 API 路由)
// app/dashboard/products/actions.ts
'use server' // 标记为服务端函数,直接操作数据库
import { prisma } from '@/server/db';
import { revalidatePath } from 'next/cache';
export async function updateStock(productId: string, delta: number) {
// 利用 Prisma 的原子递增操作,解决并发超卖机制
await prisma.product.update({
where: { id: productId },
data: { stock: { increment: delta } }
});
// 触发 Cache 重新验证,展示 Next.js 的缓存失效机制
revalidatePath('/dashboard/inventory');
}
机制 B:tRPC 类型安全调用 (前端调用后端逻辑的机制)
// server/trpc/routers/product.ts
export const productRouter = router({
getFiltered: publicProcedure
.input(z.object({ minPrice: z.number(), tags: z.array(z.string()) }))
.query(async ({ input }) => {
// 利用 Prisma 的 where 条件组合,展示数据库索引机制
return await prisma.product.findMany({
where: { price: { gte: input.minPrice }, tags: { hasSome: input.tags } }
});
}),
});
机制 C:缓存分层与 revalidate (性能机制)
// app/dashboard/page.tsx
export const dynamic = 'force-dynamic'; // 强制动态渲染,绕过全路由缓存
export const revalidate = 60; // ISR 增量静态再生机制,60秒后后台更新
第三阶段:截全技术细节 (模拟“截图”清单)
由于无法实际截图,这里提供一份 “机制快照清单 (Mechanism Snapshot)”。当你做 Demo 时,请逐一对着这些点运行 console.log 或浏览器 DevTools 截图:
| 机制分类 | 需要截图的具体技术细节点 | 操作指引 |
|---|---|---|
| 渲染机制 | RSC (React Server Component) 的水合边界 | 截图浏览器“查看网页源代码”,对比 Next.js 返回的 HTML 与客户端最终 DOM 的差异。 |
| Streaming SSR 的 Suspense 回退 | 截图 Network 面板,观察 chunk 分块传输编码,查看 loading 状态何时消失。 |
|
| 路由机制 | Parallel Routes (平行路由) 的插槽 | 截图 URL 变化时,页面侧边栏与主内容区独立刷新,不丢失状态。 |
| 缓存机制 | Full Route Cache (静态预渲染) | 截图 next build 终端输出,看哪些路径被打标为 ○ (Static) 或 λ (Dynamic)。 |
| Data Cache (fetch 缓存) | 截图 Server 日志,对比第一次请求和第二次请求 cache: HIT 状态。 |
|
| 数据库机制 | Prisma 生成的 SQL 语句 | 截图终端中的 prisma:query 日志,观察 SELECT 是否自动 JOIN 了关联表。 |
| 连接池管理 | 截图 Prisma 客户端初始化代码,确保使用 globalThis 进行单例热重载机制。 |
|
| 错误机制 | Error Boundary (错误边界) | 截图当故意抛出异常时,error.tsx 文件捕获后显示的 UI 回退界面。 |
第四阶段:技术栈机制复盘 (核心输出)
做完以上 Demo 后,你需要得出以下关于 Next.js 14 全栈机制 的本质复盘结论:
1. 时间维度的机制(生命周期劫持)
- 机制本质:Next.js 将 Node.js 的
Event Loop与 React 的Fiber 架构强行绑定。 - 复盘结论:它不仅仅是一个框架,它是一个**“编译时 (Build Time)”** + “运行时 (Runtime)” 的双重调度器。
'use server'指令在编译阶段被提取为独立的 Postgres 函数调用,而不是在运行时动态生成,这大幅降低了攻击面。
2. 数据流维度的机制(单向闭环打破)
- 机制本质:传统的 React 是
View -> Action -> State -> View。Next.js 14 引入了 Server Action,形成了UI Event -> Server Function -> DB Mutation -> Revalidate Cache -> Resend RSC Payload -> Merge DOM。 - 复盘结论:它将“状态管理”的职责从 Redux/Zustand 手中夺回,交给了 URL (路由) 和 Database (数据库)。状态即 URL 查询参数,刷新页面不丢数据。
3. 缓存一致性机制(最精妙之处)
- 机制本质:Next.js 拥有四层缓存(HTTP 缓存、路由缓存、数据缓存、全布局缓存)。
- 复盘结论:它的核心机制是**“被动失效 (Stale-While-Revalidate)”**。Demo 中的
revalidatePath并不会立即清除 CDN 缓存,而是标记为“陈旧”,在下一次请求返回时,先返回旧数据(保证响应速度),后台异步计算新数据。这套机制解决了互联网高并发下的“惊群效应”。
附赠:你的“快速学习 Skill”核心 Prompt 模板
根据以上的推导,你可以抽象出这套 Skill 的万能提示词公式:
Role: 技术栈逆向工程师
Task: 学习 [目标技术栈]
Step 1 (业务): 构建一个包含 [CRUD]、[权限]、[实时交互] 的 Demo,并明确指出边界异常。
Step 2 (知识): 编写代码时必须强制使用该框架特有的 [编译器宏/装饰器/钩子](如 Next.js 的'use server',Vue 的setup)。
Step 3 (工程): 模拟生产环境,开启build产物分析与profiling性能分析。
Output: 生成一份 “机制对比表”,列出该框架与上一代主流框架(如 CRA/Express)在“数据流方向”和“资源加载时机”上的根本差异。
这套方法落地后,你学任何新框架(SvelteKit, Nuxt 3, Fresh),本质上都是在研究它们的 “Compiler (编译器)” 和 “Runtime Scheduler (运行时调度器)” 是如何默契配合的。这就从“调包侠”进阶到了“机制理解者”。试试看!

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 1
1 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)