
工作中如何使用claude code帮助自己精准开发(进阶)
书接上一篇
如何让AI更像员工一样执行工作
Hooks
Hooks 允许在 Claude Code 特定事件发生时自动执行脚本或 LLM 评估,实现自动化工作流。以下是他的触发事件类型:
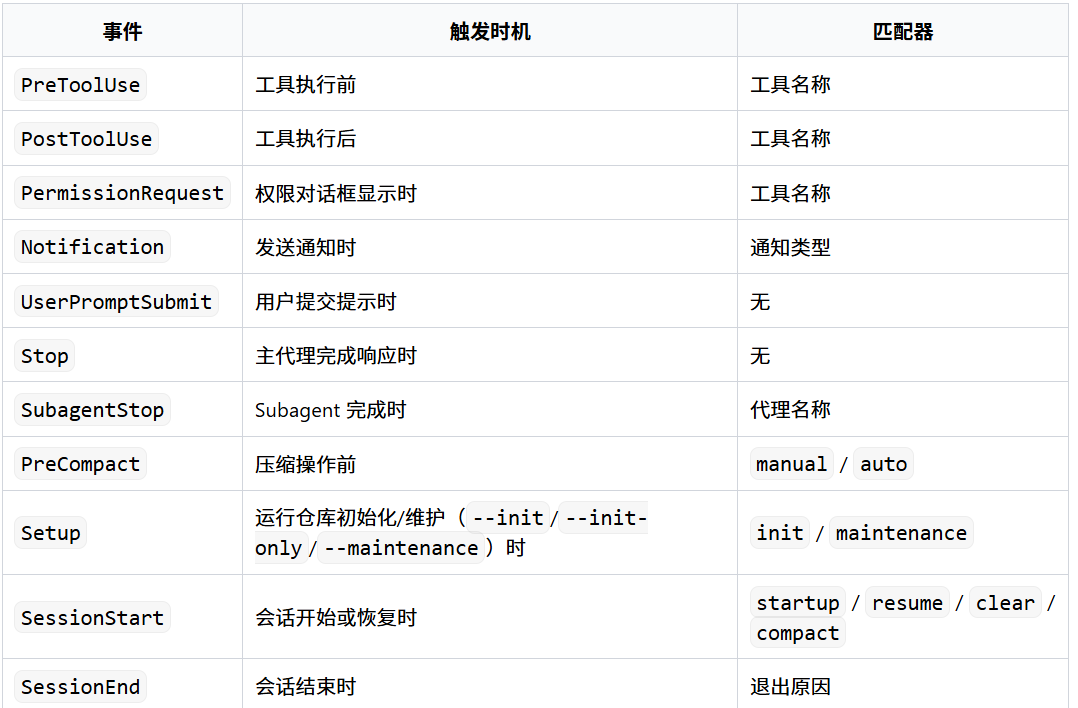
配置位置
~/.claude/ ← User 层级(全局)
└── settings.json ← 个人通用 hooks 配置
<你的项目根目录>/
├── .claude/
│ ├── settings.json ← Project 层级(团队共享,进 git)
│ ├── settings.local.json ← Local 层级(仅你本地,不进 git)
│ └── hooks/ ← 存放所有 hook 脚本(项目级)
│ ├── protect-sensitive.sh
│ ├── block-dangerous-bash.sh
│ └── auto-format.sh
├── CLAUDE.md ← 项目指令(可选)
└── src/ ...
- ~/.claude/settings.json - 用户设置
- .claude/settings.json - 项目设置
- .claude/settings.local.json - 本地项目设置(不提交)
- 插件的 hooks/hooks.json
- Skills、Subagents 的 frontmatter 中
虽然他们有多个层级,但是和skill不一样,优先级高的层级里定义的 hook 不会被低层级的覆盖掉,而是各层的同名事件 hooks 数组合并,然后整体按来源优先级+定义顺序排列执行。
核心配置骨架

{
"hooks": {
"事件名(PreToolUse/PostToolUse/...)": [
{
"matcher": "工具匹配表达式",
"hooks": [
{
"type": "command",
"command": "你的脚本路径",
"timeout": 10
}
]
}
]
}
}
allowed-tools管的是 Skill 激活期间的工具白名单;
hooks管的是 所有工具调用前后,统一的拦截/自动化——不管是不是 Skill 触发的。
多个hooks写在settings.json
{
"hooks": {
"PreToolUse": [
{
"matcher": "Edit|Write",
"hooks": [
{
"type": "command",
"command": "\"$CLAUDE_PROJECT_DIR\"/.claude/hooks/protect-sensitive.sh",
"timeout": 5
}
]
},
{
"matcher": "Bash",
"hooks": [
{
"type": "command",
"command": "\"$CLAUDE_PROJECT_DIR\"/.claude/hooks/block-dangerous-bash.sh",
"timeout": 5
}
]
}
],
"PostToolUse": [
{
"matcher": "Edit|Write",
"hooks": [
{
"type": "command",
"command": "\"$CLAUDE_PROJECT_DIR\"/.claude/hooks/auto-format.sh",
"timeout": 30
}
]
}
],
"Notification": [
{
"matcher": "",
"hooks": [
{
"type": "command",
"command": "notify-send 'Claude Code' 'Needs your attention'"
}
]
}
]
}
}
多个hooks组合之后,同一个事件下,claude会按照顺序执行每个command
LLM匹配的是用户输入内容吗?
不同的事件输入到Hooks中是不一样的,例如:
所以并不是一定不会检查用户输入内容。以下用一个例子讲解下:
你在聊天框输入
"帮我清理 node_modules 然后跑测试"
│
▼
┌─ UserPromptSubmit ─────────────────┐
│ hook 能拿到 user_prompt 文本 │ ← 这里的 LLM hook 分析「你说的话」
│ (可拦截/可注入额外 context) │
└────────────┬────────────────────────┘
▼ Claude 读完 prompt,开始规划
┌──────────────────────────────────────┐
│ Claude 决定执行: Bash("rm -rf ...") │
└────────────┬─────────────────────────┘
▼
┌─ PreToolUse ────────────────────────┐
│ hook 拿到 {tool_name:"Bash", │ ← 这里的 LLM hook 分析「Claude 要做的事」
│ tool_input:{command:"rm -rf..."}}│ (不是你说的原话!是它翻译后的工具调用)
│ 可以 exit 2 阻断 │
└────────────┬────────────────────────┘
▼ 放行后才真正执行
[实际跑 rm -rf]
│
▼
┌─ PostToolUse ───────────────────────┐
│ hook 拿到执行结果 │ ← 事后审查 / 善后
└──────────────────────────────────────┘
如何选择使用哪种类型的hooks
command适合确定性的场景使用,我的理解就是执行的脚本是确定的,比如我写好了一个shell脚本,它不会推断我发送的语义是否和这个shell有关,只要matcher匹配,就执行脚本。
所以适合如下一些应用场景:
-
安全过滤:黑名单匹配(如禁止 rm -rf、禁止修改 .env)
-
文件校验:检查文件是否存在、大小、权限
-
静态分析:调用 ESLint、Prettier、TypeScript 编译器
-
外部系统集成:发送 Webhook、写入审计日志、通知 Slack
-
环境检测:检查当前分支、Git 状态、磁盘空间
而LLM模式,就适合我们针对用户发送的语义或者做的事情无法用具体的脚本写清楚的,比如如下场景:
-
语义级别的安全检查:判断用户请求是否试图越狱、诱导删除生产数据
-
代码合规审查:检查即将写入的代码是否符合团队风格指南、是否包含敏感 API Key
-
上下文敏感的阻断:例如“只有 main 分支才允许部署,否则阻止”
-
自动分类/路由:根据用户意图将任务分发给不同的子 Agent
-
动态 prompt 注入:在 UserPromptSubmit事件中用 LLM 重写用户输入,补充缺失上下文
但LLM相比command,执行效率会低,所以对于需要极低延迟的实时拦截,使用command更适合。
安全实践
- 验证输入 - 始终验证和清理 stdin 中的 JSON 输入
- 避免硬编码密钥 - 使用环境变量存储敏感信息
- 限制文件访问 - 脚本应只访问必要的文件和目录
- 定期审查 - 定期检查 Hook 配置和脚本
- 使用 exit 2 - 阻止危险操作时使用退出码 2
可复现运行环境:MCP + 外部工具链(别让 Claude 盲猜环境)
配置方式
同名服务器的优先级:本地 > 项目 > 用户
文件格式
json文件:
{
"mcpServers": {
"api-server": {
"type": "http",
"url": "${API_BASE_URL:-https://api.example.com/mcp}",
"headers": {
"Authorization": "Bearer ${API_KEY}"
}
}
}
}
支持的语法:
- ${VAR} - 展开为环境变量值
- ${VAR:-default} - 未设置时使用默认值
本地作用域(默认)
存储在 ~/.claude.json 的项目路径下,仅在当前项目目录可用:
# 默认
claude mcp add --transport http server https://your-mcp-server.example.com/mcp
# 显式指定
claude mcp add --transport http server --scope local https://your-mcp-server.example.com/mcp
项目作用域
存储在项目根目录的 .mcp.json 文件,可提交到版本控制,团队共享:
claude mcp add --transport http server --scope project https://your-mcp-server.example.com/mcp
用户作用域
存储在 ~/.claude.json,跨所有项目可用:
claude mcp add --transport http server --scope user https://your-mcp-server.example.com/mcp
mcp配置存放策略
这个 MCP server 是"这个仓库的开发工作流必需的"吗?
(比如:项目用 GitHub Issues → github mcp;用内部 DB → readonly db mcp)
├─ 是 → 放 .mcp.json(--scope project)✅
│ 提交 git,队友 clone 即得,按需加载,不污染别的项目的 context
│
├─ 否,是你的私人工具(个人笔记、个人 Discord bot、实验性东西)?
│ ├─ 想在所有项目都能用 → --scope user → 进 ~/.claude.json(接受全局加载代价)
│ └─ 只想在当前项目试 → --scope local → 也进 ~/.claude.json 但按路径隔离
│ ↑ 这只是实验期,稳定后迁 .mcp.json
运行方式
远程 HTTP 服务器(官方推荐)
# 基本语法
claude mcp add --transport http <name> <url>
# 示例:连接 Notion
claude mcp add --transport http docs https://your-mcp-server.example.com/mcp
# 带认证头
claude mcp add --transport http secure-api https://api.example.com/mcp \
--header "Authorization: Bearer your-token"
本地运行
# 基本语法
claude mcp add [options] <name> -- <command> [args...]
# 示例:添加 Airtable 服务器
claude mcp add \ # 子命令:添加 MCP 服务器
--transport stdio \ # 通信方式:标准输入/输出(子进程管道)
--env AIRTABLE_API_KEY=YOUR_KEY \ # 设置环境变量(传给子进程)
airtable \ # 服务器名称(你起的标识名)
-- npx -y airtable-mcp-server # 启动命令(-- 后面的部分是实际执行的命令行)
使用建议
每启用一个 MCP 服务器,通常都会带来额外的工具描述与提示词开销。实际使用中,如果你同时打开太多 MCP,主对话的可用上下文会被明显挤占,表现为更容易“健忘/跑偏”。
建议做法:
- 先把启用的 MCP 控制在一个小集合里(例如不超过 10 个),用到再加,确认收益后再长期启用。
- 能用项目级 .mcp.json 固化的,就不要靠个人的 ~/.claude.json 口口相传。
- 所有密钥用占位符或环境变量注入,避免把真实密钥写进可提交文件。
为何用.mcp.json 固化的可以减少上下文的
MCP 工具不是"懒加载图标"——它们是占上下文的实体
每个 MCP server 连上后,Claude Code 必须把它提供的 tools 注册进当前 session 的 tool registry。每一个 tool 的:
name + description + inputSchema(JSON Schema)
会被序列化进 system prompt / tool definitions 区域,吃掉 context window。10 个 server × 每个 5~15 个 tool × 每段 schema……积少成多,轻轻松松几百到上千 token,还没开始干活就没了。

个人学习时遇到的误解
以为mcp需要使用/mcp指令注册才能使用。其实他的功能只是将mcp的配置自动生成到json中。所以只要我们自己手动配置好mcp的json配置,就不要敲指令一个个注册。
Session 纪律:成本/清理/交接(让用法可团队协作)
每一次你在某个目录下跑 claude,它就会开一个 session:
-
有一个工作目录(workspace root)
-
有一组加载的上下文:内置工具 + MCP tools + settings.json的权限/模式 + CLAUDE.md
-
有 token 消耗(你看到的 cost 行就是结算单位)
Session 结束时(/exit、Ctrl+C、idle timeout),Claude Code 会把 transcript / conversation log 存到本地目录里(主要在 ~/.claude/下),用于 resume、history、debug。
所以「Session 纪律」本质是:让这个『运行时状态』可控、可清理、可复现,而不是靠人肉记忆。
成本:先搞清楚钱和时间花在哪
最大的隐性成本不是"它回得多",而是上下文膨胀
典型烧钱路径:
-
CLAUDE.md / 项目文件太多 + 没裁剪 → 每次启动就吃一大块
-
PreToolUse 里反复 Allow / 手动点确认 → retry →重跑 → 同一段上下文被反复重建
-
让它"自由探索大目录"(无 .claudeignore)→ Read/Edit 扩散
-
长对话不截断:你聊了 3 小时,它还在扛 80K token 的 transcript
你不需要记账,但需要三条硬纪律

清理:哪些能清、哪些别碰(谨慎)
通常不该手动删的
-
~/.claude/settings.json(那是你的全局配置)
-
.claude/settings.json/ .claude/settings.local.json(项目规则/权限)
-
.mcp.json(除非你确实想拆掉注册表)
可以安全清除的:
# 1) 看体积
du -sh ~/.claude/projects/ 2>/dev/null || true
ls -lh ~/.claude/projects/<项目hash>/
# 2) 清某个项目的旧 session transcripts(一般在这里)
# ⚠️ 这会丢失 resume 能力,但绝大多数时候你不在乎
rm -rf ~/.claude/projects/<项目hash>/sessions/20*.jsonl
# 3) 清全局缓存(比 sessions 更安全)
rm -rf ~/.claude/cache/
交接/协作:让用法「可复现」而不是「口口相传」
交付的最小集合:
your-project/
├── .claude/
│ ├── settings.json ← 项目级规则(deny/allow、defaultMode 等)
│ ├── settings.local.json ← ❌ 不进 Git(本地覆盖/调试)
│ └── hooks/ ← 你的 protect-sensitive / auto-format 脚本
├── .mcp.json ← 需要哪些 MCP server(密钥用 ${ENV})
├── .claudeignore ← 锁扫描范围
└── CLAUDE.md ← 项目宪法(目录结构、合约、禁区、开工步骤)
CLAUDE.md 里加一段「Session 规矩」(让接手人秒懂)
## Claude Code 使用约定
- 入口:只在 `src/` 和 `scripts/` 作业,不要让它扫 `dist/`
- 会话原则:**一个意图一个 session**(别把「加接口」和「改 CI」混一起)
- 遇到不确定先 `/permissions` 看规则,再动手
- 离开前:`/compact` 或退出;不要把 100K token 的对话当长期记忆
- 环境变量(交给接手人看一眼):
- `GITHUB_TOKEN` 需要 `repo` 只读
- `DB_READONLY_DSN` 连的是只读副本
新同事 onboarding 变成一条路径
git clone ...
cd your-project
cp .claude/settings.json.example .claude/settings.json # 如果你们用 example 模式
export GITHUB_TOKEN=ghp_...
export DB_READONLY_DSN=...
claude
> /mcp # 看哪些需要 approve
配置在仓库、密钥在外、规则写在 settings.json、禁区写在 deny+ CLAUDE.md。
如何实现可复用的任务
用一个例子来讲解
如何组合使用不同的skill完成复杂的功能
用 Skill 组合构建一个CRUD 生成器
- 创建基础skill

- 创建复合 Skill full-crud.md
---
name: full-crud
description: 为一个数据模型完整生成 CRUD(schema→service→routes→tests)
trigger: 完整 CRUD
---
## 参数
- modelName: 模型名称(首字母大写,单数)
- fields: 字段定义(JSON 格式)
## 步骤
1. 用 `@skill plan-crud` 展示计划并让我确认
2. 用 `@skill gen-schema` 追加 Prisma 模型
3. 用 `@skill gen-service` 生成增删改查服务
4. 用 `@skill gen-routes` 生成 5 个 API 端点(GET list, GET by id, POST, PUT, DELETE)
5. 用 `@skill add-tests` 为 service 和 routes 添加测试
6. 运行 `pnpm prisma migrate dev` 更新数据库
7. 运行 `pnpm test --run` 确认全绿
8. 运行 `pnpm lint` 确保无报错
- 使用
完整 CRUD,模型名 Product,字段:name string required, price float required, description text optional
团队合作时有什么需要注意的
token消耗控制
- CLAUDE.md 写规矩(让重要规则不靠对话史活着)
- /clear换任务(单条最高 ROI 命令)
- 限制它读的范围(不要让它"探索整个 src/",给它精确路径)
权限模型 + deny
目的:作为最后一道安全屏障,避免claude绕过一些禁止的操作
权限评估顺序:
- deny
- ask
- allow
即便同一个操作同时命中 allow 与 deny,最终也会被 deny 拦截。
参考配置:
{
"permissions": {
"deny": [
"Read(./.env*)",
"Edit(./.env*)",
"Write(./.env*)",
"Bash(rm -rf *)",
"Bash(sudo *)",
"Bash(dd if=*)",
"Bash(mkfs.*)",
"WebFetch"
]
}
}
和hooks的区别

代码审查习惯
不要想着ai自己就会帮你审核,类似:
# ❌ 这些等于废纸
- "确保代码高质量"
- "注意安全漏洞"
- "不要引入bug"
- "自己review一遍再给我"
正确的做法是在claude.md中写好审核的具体流程
# CLAUDE.md(节选:交付门槛)
## 交付前强制自检(每个任务完成后必须跑,不等我说)
每次声称"done"之前,**必须按顺序**执行:
1. `pnpm lint` → 有 error 就修,不准 skip
2. `pnpm typecheck` → 零 error,有 error 就修(尤其 `any` 泄漏)
3. `pnpm test --run` → 你改到的范围必须全绿
4. 安全快检(手工规则):
- 搜索本次改动有没有 `jwt.decode(`(应为 `jwt.verify`)→ 有就阻断
- 搜索 `.env` / `secret` / `password` 有没有出现在 console.log → 有就阻断
- 搜索字符串拼接 SQL(`${` + `SELECT` 模式)→ 有就阻断
5. 改动范围 sanity check:
- `git diff --stat` 把改动文件列表打出来
- 如果我没让你动 prisma/schema,它不该出现在 diff 里
- 如果我没让你加 dep,node_modules 不该变
只有 1-4 全绿灯 + 5 范围合理,才能说 "done"。
否则:列出没过的项 → 修 → 重跑 → 再报。
审核架构
Layer 1 — 生成时约束(CLAUDE.md / .claude/rules/)
↓ 让它"从一开始就少犯错"
↓ 约束:命名、分层、不允许的写法、必须跑的check
Layer 2 — 独立视角检查(≠同一session自审)
↓ 两种做法:
↓ a) 新 session 开干净上下文审(无锚定偏置)[18](@ref)
↓ b) 专用 review 工具(CodeRabbit/Qodo/甚至另一个模型)[14](@ref)
Layer 3 — 人工终审(按风险分级,不是每PR都逐行)
↓ 人只看需要人类判断的东西

转换成工作流程:
你提需求 → Claude 写代码
↓
CLAUDE.md 的交付序列自动拦住低级问题(它自己修到自己通过)
↓
你 git diff 扫一眼范围(5秒:"它有没有乱改不该碰的文件?")
↓
高风险路径? → 你逐行读,重点审 auth / data integrity / concurrency
中低风险? → 你读 diff 的"意图层"(对不对?缺不缺边界?),跑一遍手动冒烟
↓
merge

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)