
全面解析数据智能体底层逻辑,深度分享数据智能体应用干货
在目前的办公环境下,我发现很多做业务运营或者数据分析的朋友都面临一个共同的痛点:取数流程太长。当你想看某个业务指标时,往往需要先和IT部门沟通需求,然后等待技术人员排期写代码,最后拿到的数据可能已经过时了。这种低效率的工作模式直接导致了决策的滞后。为了解决这一问题,数据智能体这种技术形态开始在企业内部落地。简单来说,数据智能体能够直接理解人的自然语言意图,并自主在数据库中完成查询、分析和绘图的过程。在数字化转型中,数据智能体扮演着连接人与数据的关键角色。用过来人的经验告诉你,数据智能体正彻底改变我们处理信息的方式。
开始之前给大家分享一份数字化全流程资料包,里面包括数据迁移的知识和企业数据应用的精选案例,帮你解决在数据应用、数字化转型中的实际困惑,更好地着手数据工作。有需要的自取:https://s.fanruan.com/pxb9h (复制到浏览器打开)
一、 深入解析数据智能体的核心逻辑与组成
要搞清楚数据智能体到底是什么,不能只看它的交互界面。说白了,它是一个具备逻辑推理能力的自动化执行单元,核心由四个部分协同运作。
业务意图的精准识别能力
当你输入一句话时,数据智能体的第一步动作是语义解析。它不是简单的关键词检索,而是利用大语言模型的参数权重,去理解你这句话背后的业务逻辑。比如你问“上个月毛利下降的原因”,它会识别出时间范围是自然月,核心指标是毛利,并且自动联想到需要进行多维度的对比分析。
严密的任务规划与逻辑拆解
我一直强调,一个专业的数据智能体最核心的竞争力在于它的规划模块。面对一个复杂问题,它不会直接写代码,而是先生成一个执行计划。它会思考:我需要先调取哪张表?是否需要进行表关联?是否需要进行环比计算?这种逻辑链条的生成,体现了它对数据结构的掌握程度。你懂我意思吗?这就像给电脑装上了一个懂业务的头脑。
自主的工具调用与执行反馈
在确定了计划后,数据智能体会自主调用底层工具,比如自动生成标准的SQL语句或Python脚本并下发执行。它能够直接与数据库通信,获取查询结果,并进行初步的数据清洗。如果执行过程中出现语法错误,它会根据报错信息进行自我修正,再次尝试。
长短期记忆与上下文关联
数据智能体具备记忆功能。短时记忆让它能承接上文的提问,比如你追问“那华东区的情况呢?”,它知道你是基于上一个关于销售额的问题在提问。长时记忆则让它记住你的分析偏好,从而在后续的交互中提供更符合你个人习惯的结果。
二、 数据智能体在实际业务中的落地场景分析
用过来人的经验告诉你,理论讲得再多,最终还是要看它能不能在业务里派上用场。目前的数据智能体已经在多个环节展现出了极高的专业度。
这里给大家推荐一款我们团队正在用的工具FineChatBI,它是集实时数据同步、ELT/ETL 数据处理、数据服务于一体的数据集成工具,能解决迁移过程中很多核心痛点。它支持 40 多种数据源,不管是旧 CRM 系统、本地数据库还是云端平台,基本都能覆盖,拖拉拽就能完成数据同步和处理任务,不用写复杂脚本。而且它内嵌 Spark 计算引擎,支持批量表实时同步、增量更新 and 断点续传,能很好适配全量 + 增量结合的迁移场景,还能自动处理表结构变更,避免同步过程中出现数据错乱。工具链接我放在这里,感兴趣的朋友可以上手试试:https://s.fanruan.com/x2vqb (复制到浏览器打开)
实现敏捷化的自助取数分析
在传统的BI模式下,每一个新维度的查看都需要重新开发报表。但在数据智能体的帮助下,业务人员可以直接通过对话获取结果。比如在FineChatBI的实际应用中,用户只需要输入“各省份销售额占比”,系统就会自动生成饼图或柱状图。听着是不是很熟?这彻底解决了取数排期的问题。
异常指标的自动化诊断与预警
数据智能体可以 24 小时监控业务指标的变化。当某个指标偏离正常范围时,它不仅会发出预警,还会自动执行多维度的下钻分析,找出导致异常的具体因素,比如是某个特定的 SKU 出现了库存缺口。这种主动发现问题的能力,是传统工具无法比拟的。
复杂经营报表的快速生成
很多企业的月度分析报告需要耗费分析师大量精力去整理。数据智能体可以根据预设的模板,自动从各个数据库中抓取数据,并配上文字解读。它能够客观陈述数据变动,并提供基于历史趋势的初步预测,极大地降低了文案工作的负担。
非技术人员的低门槛决策支持
数据智能体将数据的访问权限真正交还给了业务人员。无论你是否懂编程,只要你懂业务,你就能调动企业内部的海量数据。通过FineChatBI这样的平台,这种交互变得非常简单直白,让数据驱动决策不再是一句口号。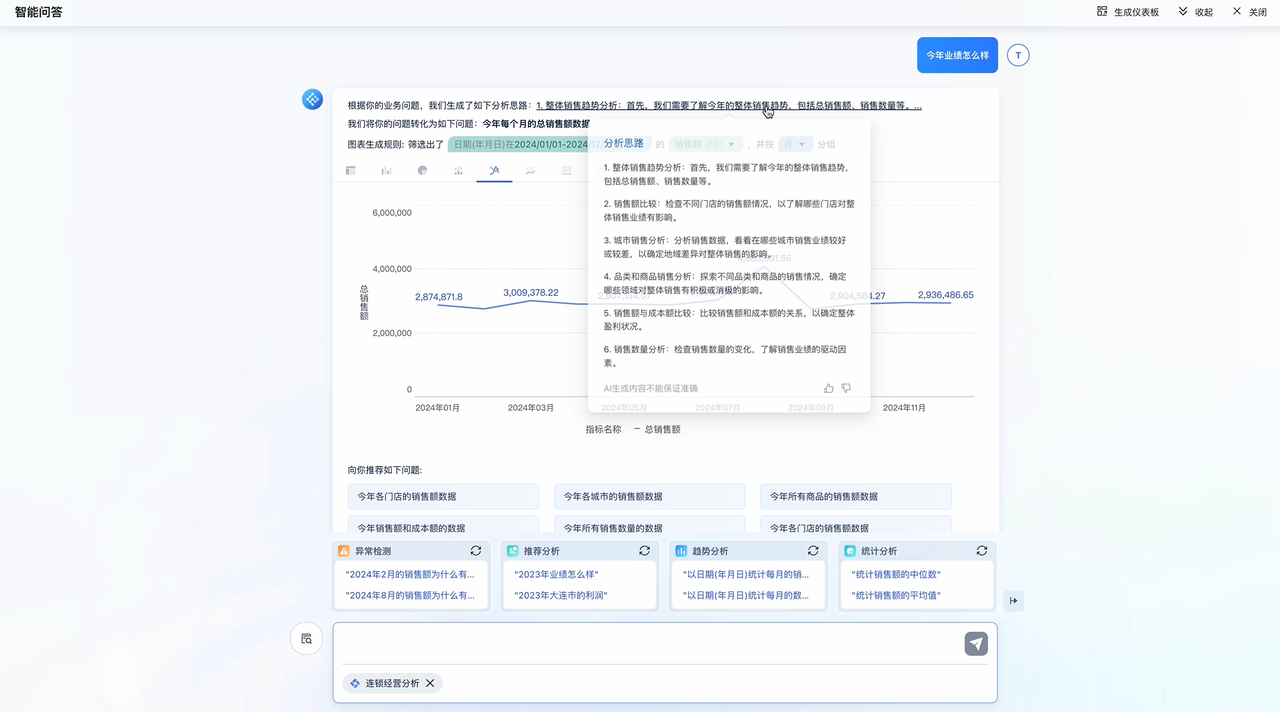
三、 数据智能体的未来发展趋势深度洞察
我一直强调,技术的发展是具有连续性的。未来的数据智能体将会在以下几个方向上产生深度的进化。
-
从“被动询问”转向“主动规划”
目前的数据智能体大多是基于人的指令在运作。未来的发展趋势是,它将具备更强的自主性。它会根据当前的业务状况,主动建议你查看某些数据点,或者预测可能出现的业务风险。简单来说,它会从一个“听命行事的下属”变成一个“主动出谋划策的助手”。
行业垂直化的专业深度构建
通用的模型虽然博学,但在特定行业(如金融风控、医疗分析)的专业度上仍有欠缺。未来的趋势是会出现大量行业定制化的数据智能体。这些智能体内置了特定行业的计算公式、业务约束和分析模版,能够处理极度复杂的行业垂直问题。
多智能体协同办公的普及
未来的数据分析任务可能不是由一个智能体完成的。会有一个总控智能体负责任务拆解,若干个专门负责 SQL 编写、数据清洗、可视化排版的子智能体协同工作。这种分工协作的模式能大幅提高结果的准确性和输出的精美程度。
更完善的数据安全与隐私保护机制
随着数据主权意识的增强,未来的数据智能体将更加强调隐私保护。它会在不离开企业本地服务器的环境下完成推理和运算,确保核心商业机密不外泄。这种安全性将是数据智能体进入核心金融、政务系统的通行证。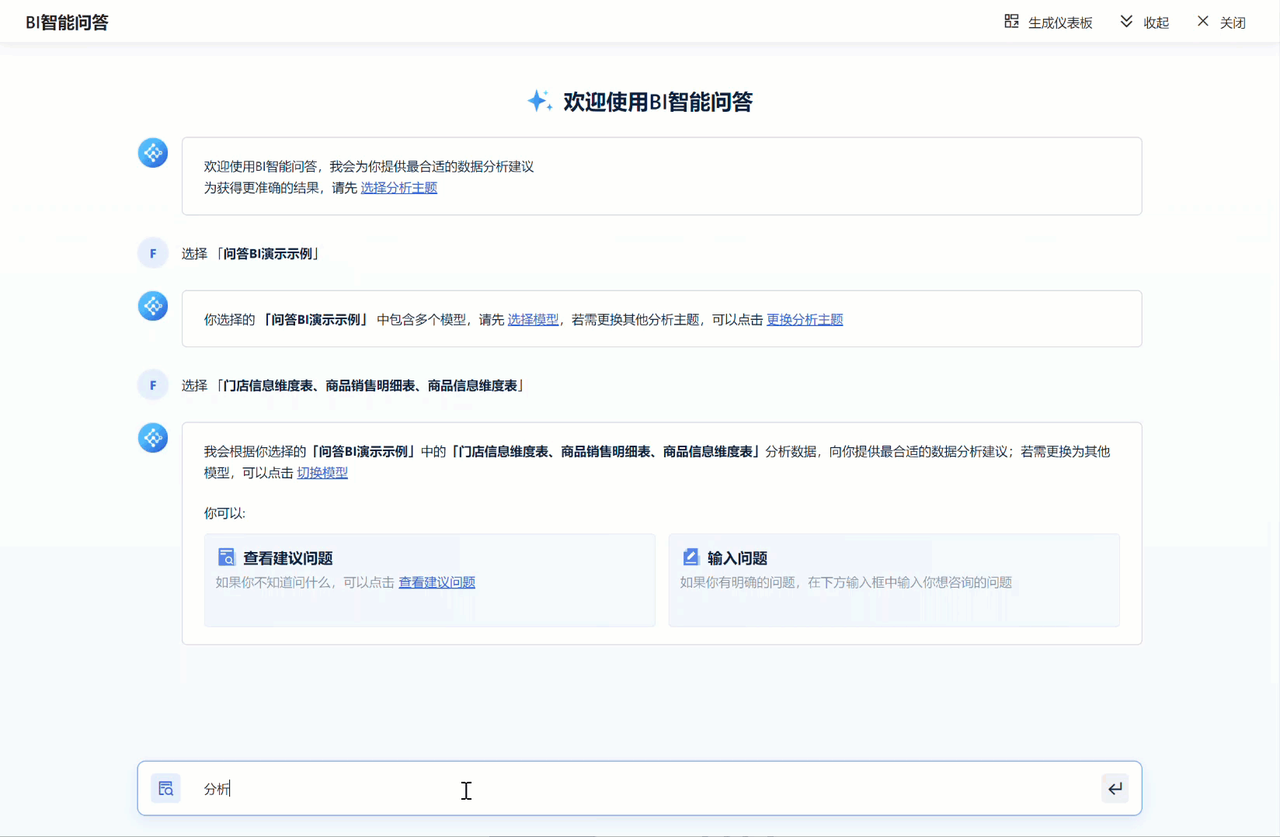
四、 总结与思考
说白了,数据智能体的出现不是为了取代人,而是为了让人从繁琐的代码工作中解脱出来。它能够处理海量的计算和逻辑匹配,而人类则负责定义业务的目标和最后的决策判断。用过来人的经验告诉你,越早接触并掌握数据智能体的使用方法,就越能在数据泛滥的时代保持清晰的判断力。
Q&A 常见问答
Q1:数据智能体生成的查询结果如果出错了怎么办?
A: 这是一个非常专业的问题。目前成熟的数据智能体系统都会引入“人在回路”的机制。比如在FineChatBI中,系统在给出结论的同时,会展示它所调用的逻辑和 SQL 语句。如果业务人员发现结果有偏差,可以直接查看逻辑并手动纠错,系统也会根据这次纠错进行学习,避免下次再犯。
Q2:对于普通小白来说,学习使用数据智能体的成本高吗?
A: 简单来说,它的学习成本几乎为零。因为它就是为了适配人类的语言习惯而设计的。你不需要去学习复杂的函数或者 SQL 语法。我一直强调,最好的工具应该是隐形的。你只需要专注你的业务问题,怎么把数据算出来,那是智能体该操心的事。
Q3:数据智能体可以处理非结构化的数据(如文档、图片)吗?
A: 这是目前技术突破的重点。通过多模态能力的引入,现在的数据智能体已经开始能够理解 PDF 报表或图片中的表格信息,并将其转化为可以计算的结构化数据。这意味着它能整合的资料范围已经远远超出了传统的数据库范畴。你懂我意思吗?它的分析维度正在变得前所未有的广阔。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)