
不写一行代码,搭出团队知识问答智能体——Nexent 完整实践
不写一行代码,搭出团队知识问答智能体——Nexent 完整实践
一、团队知识管理的老问题
新人入职第三天,加了七个群,收到了二十几份文档链接,然后打开了一个已经两年没更新的飞书文档,里面写着"具体流程见附件",但附件失效了。
这个场景几乎每个团队都经历过。文档分散在飞书、钉钉、本地硬盘、个人邮件附件里,格式五花八门,版本互相打架,搜索靠关键词,找不到的就直接问人。结果是:老员工每天被问同样的问题,新员工花大量时间找本可以直接看到的信息,知识沉淀在个人脑子里而不是团队系统里。
想用 AI 解决这个问题,方案不是没有。用 ChatGPT?它不知道你们公司内部的业务流程。搭一个 RAG 系统?需要开发、部署、维护,对大多数业务团队来说成本太高。Dify 可以做,但配置复杂度对非技术同事不友好。
Nexent 的定位就是给这个场景的:零代码构建智能体,内置知识库和向量检索,多用户权限管理,回答带来源标注。这篇文章完整记录用 Nexent 搭建团队知识问答助手的全过程——从部署到上线,从知识库配置到权限分配,侧重实际踩坑和真实使用感受。
二、平台部署与模型接入
为什么团队场景建议本地部署
在线试用环境适合个人快速摸底,但团队场景有两个原因必须本地部署:第一,团队内部文档是敏感数据,产品规划、客户资料、内部流程不应该上传到外部服务;第二,多人同时访问需要稳定的服务,在线试用环境的可用性没有保障,某天早上突然无法访问对业务影响很大。
另外,本地部署后数据完全在自己的服务器上,不经过任何第三方,这对有合规要求的团队(医疗、金融、政府等)来说是刚需,不是选项。
Nexent 支持 Docker Compose 一键部署,官方给出的最低配置要求是 2 核 CPU、6 GiB 内存,支持 x86_64 和 ARM64 架构。对于 5-20 人的小团队,一台 4 核 8G 的云服务器完全够用,按需付费的话一个月成本在几十到一百多元之间,比购买任何 SaaS 知识管理产品都便宜。
部署流程
Bash
git clone https://github.com/ModelEngine-Group/nexent.git
cd nexent/docker
cp .env.example .env
bash deploy.sh
执行 deploy.sh 后,系统会提示选择部署版本:
- Speed version(轻量版,默认):快速启动核心功能,适合个人和小团队
- Full version(完整版):提供企业级租户管理和资源隔离,适合有多部门隔离需求的企业
团队内部知识问答这个场景,选轻量版完全够用。部署模式选"生产模式"——这个模式只暴露 3000 端口,安全性更好。
⚠️ 重要:首次部署必须看这里 首次部署 v1.8.0 及以上版本,Docker 日志会输出 suadmin
超级管理员账号的密码,这个密码只显示一次,日志关闭后无法找回。务必在部署时盯着日志,第一时间复制保存。
超级管理员账号仅用于创建租户和管理员,不能直接开发智能体,初次进入后需要先创建租户,再创建租户管理员账号,用管理员账号才能正常使用全部功能。
部署成功后访问 http://服务器IP:3000,登录超级管理员账号,按照提示创建租户和管理员即可。
模型接入:单个添加完整流程
团队场景下推荐用"单个添加"方式,字段填写更清晰,出了问题也好排查。进入"模型管理"页面,点"添加模型",需要填四个字段:
- 模型名称:格式是 提供商/模型名,我填的是 Qwen3.5-Plus
- API URL:AIping 的地址是 https://www.aiping.cn/api/v1
- API Key:从 AIping 控制台复制
- 模型类型:选"大语言模型"
填完点"连通性验证",绿色提示"连接成功"即可。
向量模型同样在这里添加,但有一个字段不同:向量模型的 API URL 后缀是 /v1/embeddings,不是 /v1。这个地方我第一次填错了,验证失败只显示"连接失败"四个字,没有任何具体报错,排查了二十分钟才找到原因。
强烈建议在操作前先通读官方用户指南:https://doc.nexent.tech/zh/user-guide/home-page.html,模型配置这块文档里有说明,能省掉很多自己踩坑的时间。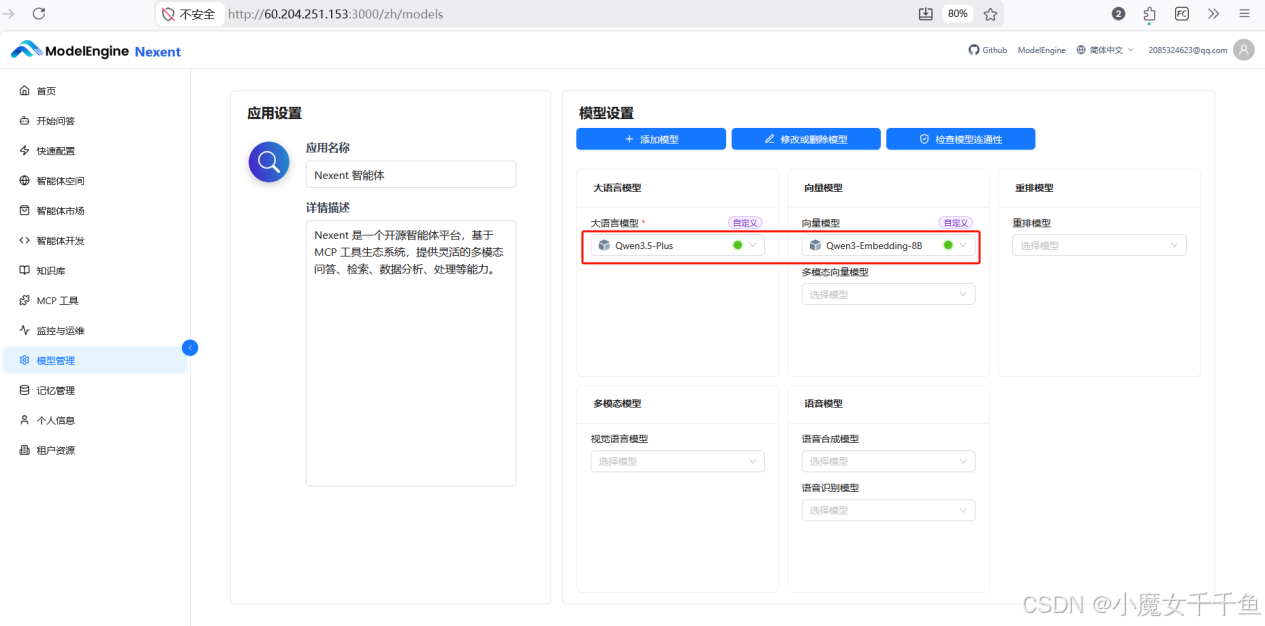
配置完模型,进入"快速配置"设置系统默认模型:大语言模型选 Qwen3.5-Plus,向量模型选对应的 Embedding 模型。这两个设置决定了知识库的检索质量和智能体的生成能力,选型要慎重。
三、知识库:把团队文档变成可检索的资产
这是整篇文章最重要的环节。知识库配置的质量,直接决定了后续智能体问答的效果上限。
准备文档:格式对质量影响很大
我为这个团队知识问答助手准备了三类文档:
- 产品使用手册(PDF):从官网下载的正式文档,排版规整,约 40 页
- 内部 FAQ(Markdown 格式):由团队成员整理,结构清晰,常见问题 + 对应答案,约 60 条
- 操作流程手册(Word 格式):包含截图和表格的业务流程说明,约 25 页
这三类文档基本覆盖了大多数团队知识管理的典型场景。在准备文档阶段我就意识到一件事:文档质量是知识库效果的天花板。AI 不能从混乱的文档里提炼出清晰的答案,但可以从清晰的文档里精准检索到目标内容。所以在上传之前,我花了半天时间把那份 Markdown FAQ 重新整理了一遍,给每条问题加上了清晰的分类标签(如"入职流程"“报销规则”“工具使用”),这个额外的整理工作在后续检索时回报很大。
上传文件后,系统依次经历三个状态:解析中 → 入库中 → 已就绪。
各格式的处理时间差异明显:
PDF 处理最慢,原因是需要先解析排版提取正文,再做分块和向量化,步骤最多。Word 含图片时图片会被跳过,只处理文字部分,这点要留意——如果流程说明关键信息全在截图里,那这部分内容不会进入知识库。
自动总结:决定多知识库场景的检索精度
每份文档入库后,系统会自动生成一段摘要。这个功能很容易被忽视,但在团队场景下尤其重要。
原因是:当智能体同时挂载多个知识库时,它会先读每个知识库的摘要,判断"这个问题应该去哪个库找",再去对应库做向量检索。如果摘要不准,检索可能直接走错库,回答就会牛头不对马嘴。
我对三份文档的自动总结质量做了对比:
Markdown FAQ 的总结:质量最好。因为文档本身结构化程度高,有明确的问题分类标签,系统提取出来的摘要包含了所有主要问题类别,关键词精准。后续用这个库来路由检索时,命中率明显最高。
**Word 文档的总结:**质量居中。流程类文档的文字描述比较规范,总结能抓住主要业务流程名称,但表格中的细节信息提取不完整。
**PDF 产品手册的总结:**相对笼统。提取出来是"产品功能介绍、使用说明"这类泛化描述,用于路由时有时会和其他库产生混淆,需要用更强的模型来提升总结质量。
**实践建议:**团队文档上传前,优先把核心内容整理成 Markdown 格式。FAQ 类文档尤其适合用 Markdown 写,结构清晰,总结质量好,检索路由最准。PDF 和 Word 作为补充材料,不作为主要检索来源。
创建多个知识库,按职能分类
一个知识库存所有文档,检索时容易产生干扰。我按职能方向分了三个库:
- 产品知识库:存产品手册、功能说明、版本日志
- 业务流程库:存各部门操作流程、审批规范、标准 SOP
- 新人入职库:存 FAQ、常见问题、入职指南
三个库各司其职,智能体在收到问题时,先根据每个库的摘要判断应该去哪里找,再做向量检索。这种分库策略比把所有文档堆在一个库里,检索准确率高很多。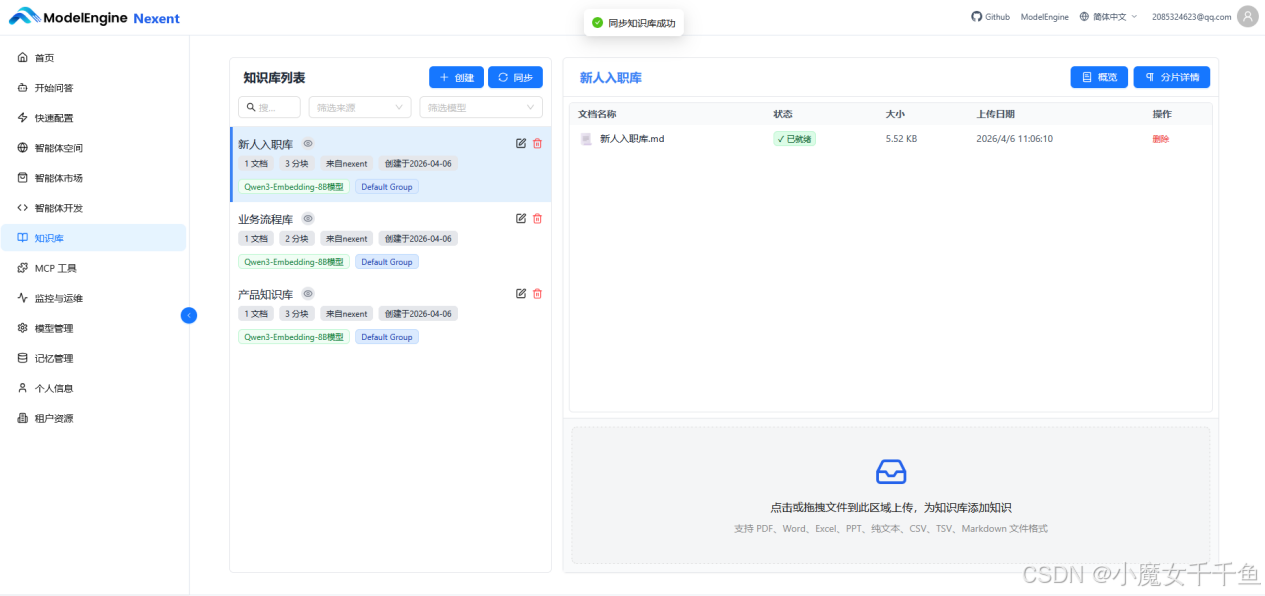
接入 Dify 已有知识库
如果团队之前已经在 Dify 里积累了大量文档,不需要重新导入,Nexent 支持直接接入 Dify 的知识库。配置路径:知识库 → 添加外部知识库 → 填入 Dify 的 API Endpoint 和 Key。
连通后,Dify 侧的数据集出现在 Nexent 的知识库列表里,智能体可以直接检索,没有额外的同步延迟。对于已经在 Dify 有沉淀的团队,这个接入方式省去了大量重复导入的工作。
四、智能体开发:搭出团队知识问答助手
知识库配置完,进入智能体开发。这个场景的工具组合很简单,只用两个内置工具:knowledge_base_search 和联网搜索,不需要接任何外部 MCP。
为什么这个场景不需要 MCP
MCP 工具的价值在于"获取实时外部数据",比如搜 ArXiv 论文、查 GitHub Trending。但团队内部知识问答的需求恰恰相反——你需要的是从已有的、确定的内部文档里找答案,而不是去外网搜索。
引入联网搜索工具是为了处理极少数"内部文档没有覆盖、但确实需要回答"的边缘情况,比如用户问到一个行业通用标准或者外部法规。这类问题让智能体通过联网补充,比让它直接说"不知道"体验更好,但要在提示词里明确说明优先级。
工具选配与知识库绑定
创建新智能体,在工具选择区域选中两个:
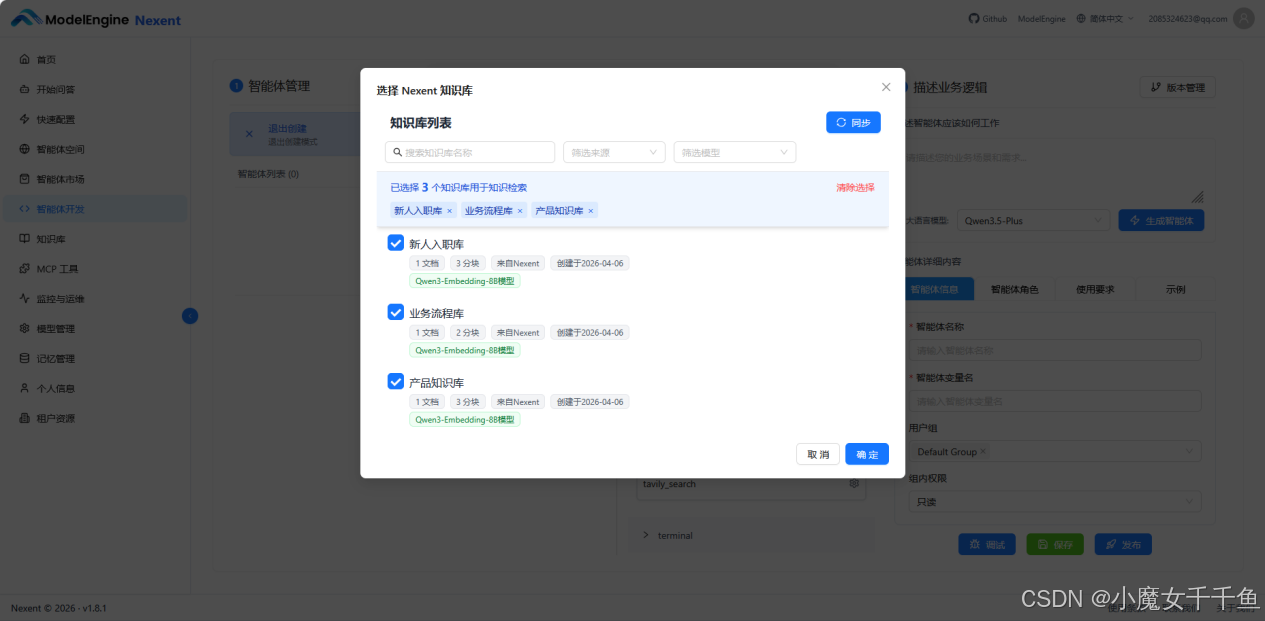
选中 knowledge_base_search 后,点击工具旁边的齿轮图标,进入配置面板,把三个知识库(产品知识库、业务流程库、新人入职库)全部绑定。绑定后智能体在检索时会自动根据问题内容,路由到最相关的知识库,不需要用户指定"去哪个库找"
用自然语言描述,生成完整提示词
描述框里我写了这段:
你是一个团队内部知识问答助手,帮助团队成员快速找到内部文档中的信息,包括产品使用手册、业务操作流程和常见问题解答。回答问题时,必须注明信息来源(文档名称
- 章节或条目),不允许基于推测或通用知识作答。如果内部文档中没有找到相关信息,先告知用户文档中没有覆盖这个问题,再通过联网搜索补充行业通用信息,并明确说明"以下来自外部资料,请结合实际情况判断"。
选模型 Qwen3.5-Plus,点"生成智能体",等几秒,系统生成了完整的提示词结构:角色定义、工作流程、工具调用规则、输出格式规范、边界限制。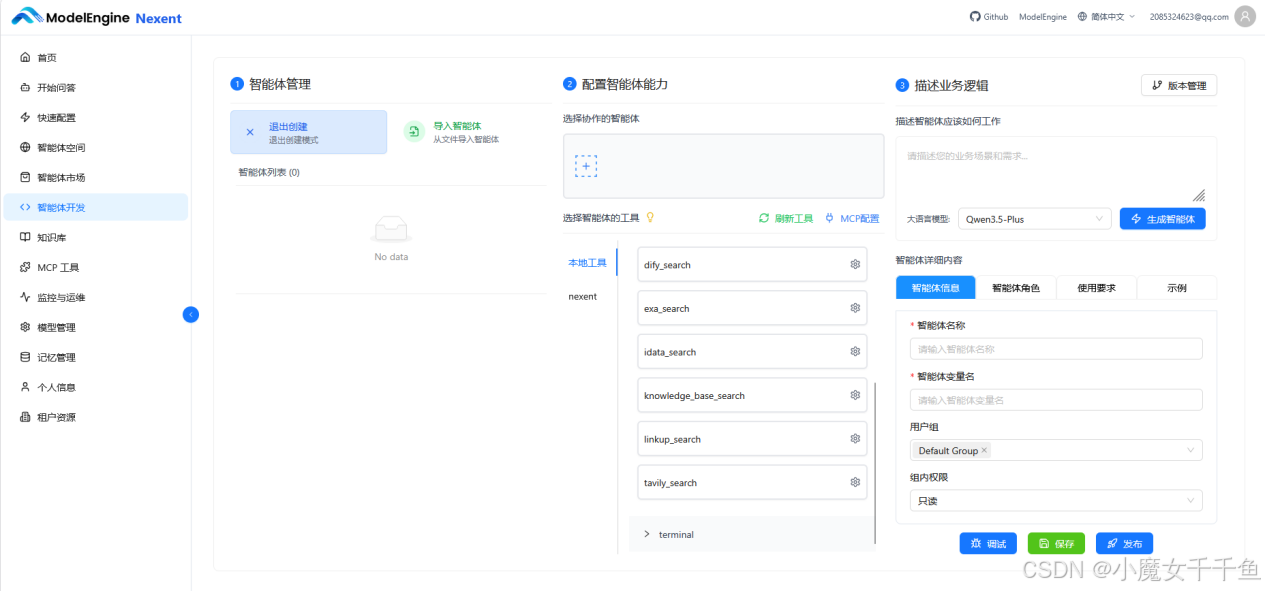
提示词修改:三处关键调整
自动生成的提示词完整度不错,但有几处需要人工判断调整:
修改一:来源引用要求必须更硬
自动生成版:回答时尽量引用文档来源
这个"尽量"给了模型太多余地,遇到难以匹配的问题时可能直接忽略引用。对团队场景来说,没有来源的回答比没有回答危害更大,因为用户可能直接按照错误信息执行。改成:
改后:每一条回答必须注明来源:[文档名称] + 章节标题或条目编号。无法找到明确来源的内容,禁止出现在回答中。
修改二:工具调用优先级要明确
自动生成的工具调用逻辑没有明确优先级,有时候会先联网搜索再检索内部文档,顺序反了。对于内部问答助手,内部文档永远是第一优先级,联网搜索是兜底。改成:
改后:处理每个问题时,必须首先调用 knowledge_base_search 检索内部文档,只有在内部文档明确没有相关信息时,才允许调用联网搜索,并且联网结果必须与内部文档结果分开标注
修改三:拒答逻辑要清晰但不生硬
自动生成的边界限制是"礼貌拒绝超出范围的问题",太软且表述模糊。改成:
改后:如果问题与本团队的产品、业务流程、日常工作完全无关(如娱乐、个人生活话题),直接告知"这超出了我作为团队知识助手的服务范围",不尝试作答,不道歉,简洁回应即可
三轮调试
第一轮:内部流程查询
问:「新员工入职需要哪些材料,找 HR 流程?」
智能体调用 knowledge_base_search 检索,在新人入职库里命中了入职手册的第二章,回答了所需材料清单,末尾标注:[新人入职库] 《入职指南》第二章 - 入职材料清单。格式清晰,来源可追溯,通过。
第二轮:跨文档综合问答
问:「我要给客户演示产品,演示前需要准备什么,流程里有什么注意事项?」
这个问题涉及两个库:产品知识库(演示功能点)和业务流程库(演示前的审批和准备流程)。智能体分别检索了两个库,把两部分信息整合在一起回答,并分别标注了各自的来源。跨库综合问答通过。
这一轮让我特别注意了一件事:智能体的回答把产品功能点和业务流程说明自然地串联在一起,而不是分成两段独立列出。这说明 Nexent 不只是"找到了信息",而是在一定程度上理解了两条信息之间的逻辑关系,再组织成连贯的答案。这种跨文档的语义理解能力,是传统关键词搜索做不到的。
第三轮:边界拒答测试
问:「最近有什么好看的电影推荐?」
智能体回答:「这超出了我作为团队知识助手的服务范围。如果你有产品使用、业务流程或工作相关的问题,欢迎随时提问。」
简洁、不生硬,边界处理正确。三轮调试全部通过。
版本保存与发布
调试满意后点"保存",系统进入版本列表,标记为 v1。Nexent 支持多版本管理,后续修改提示词但效果变差时,可以在版本管理页面一键回滚,不用担心改坏了回不去。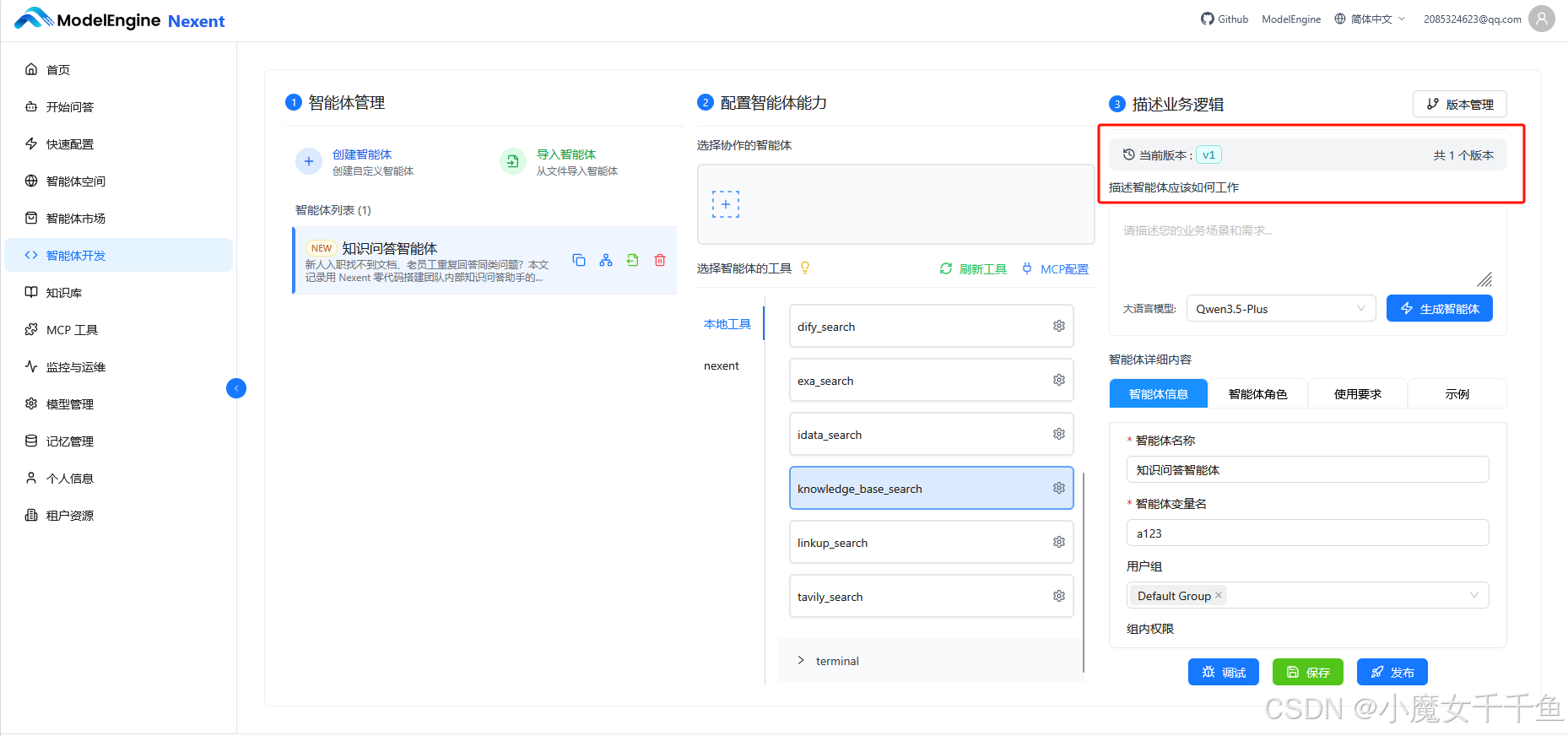
确认稳定后点"发布",智能体出现在"智能体空间"和"开始问答"里,正式可用。
五、用户权限体系:让对的人看到对的信息
这是 Nexent 在团队场景下最有价值、也最容易被低估的功能。权限体系设计得好,知识库的安全性和智能体的使用范围都能精确控制。
理解 Nexent 的角色体系
Nexent 采用基于角色的访问控制(RBAC),有四个核心角色: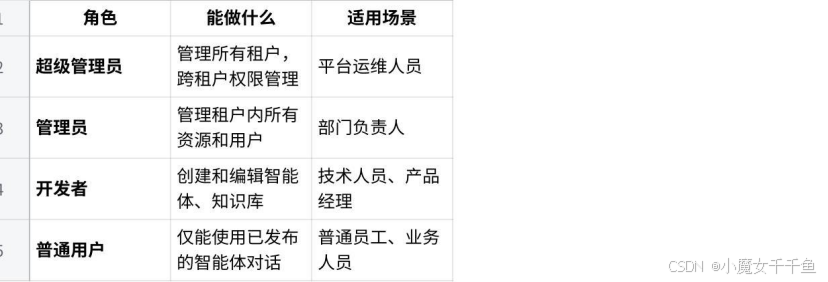
这个角色划分对团队场景很实用。大部分同事只需要"普通用户"权限——他们不需要知道知识库怎么配置、提示词怎么写,只需要在"开始问答"里选择已发布的智能体,输入问题得到回答就行。普通用户甚至看不到"知识库""智能体开发"这些菜单,界面对他们来说非常简洁。
租户与用户组:精确控制数据可见性
Nexent 在角色之上还有两个概念:租户和用户组。
- 租户:最上层的资源隔离单位,不同租户之间数据完全隔离。对于单个公司来说,通常只需要一个租户。如果是集团公司下有多个独立子公司,可以为每个子公司创建独立租户。
- 用户组:租户内的用户集合,一个用户可以属于多个用户组。知识库和智能体的可见性通过用户组来控制。
举个具体例子:公司有技术部、销售部、运营部三个部门。各部门都有自己的内部文档不想让其他部门看到,但有些公司级的通用文档所有人都能访问。
配置方案:
- 创建三个用户组:技术组、销售组、运营组
- 公司通用知识库:设置为"全租户可见"
- 技术部流程文档知识库:权限设为"指定用户组只读 - 技术组"
- 销售部客户资料知识库:权限设为"指定用户组只读 - 销售组"
这样技术部的人看不到销售部的客户资料,销售部的人也看不到技术部的研发文档,但大家都能访问公司通用 FAQ。
知识库权限的三个级别
根据官方文档,知识库权限有三种设置: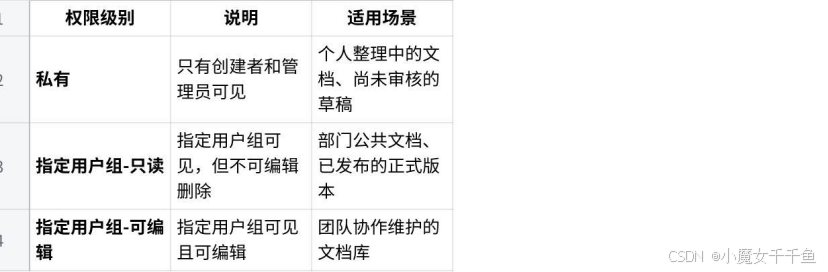
我为这次的团队知识库这样配置:
- 新人入职库:指定用户组只读,所有用户组都可见(新人需要,老员工也可能需要查)
- 产品知识库:指定用户组只读,所有用户组可见(产品信息全员共享)
- 业务流程库:指定用户组只读,按部门分别配置(各部门只看自己的流程)
智能体的权限也可以精确控制
不只是知识库,智能体也可以设置权限:
仅创建者可见:调试中的智能体,还没准备好对外
指定用户组:上线后只对特定用户组的成员可用
这个设计对 ToB 场景很有价值。比如给销售团队搭了一个销售话术助手,可以设置成只有销售组成员能用,其他部门不可见,也不会误用。
六、记忆系统、智能体市场与总结
记忆系统:四个层级,各有用途
配置完权限,开启记忆系统,这是 Nexent 比较有特色的设计,值得单独说一下。
Nexent 的记忆系统分四个层级,每个层级的作用域不同: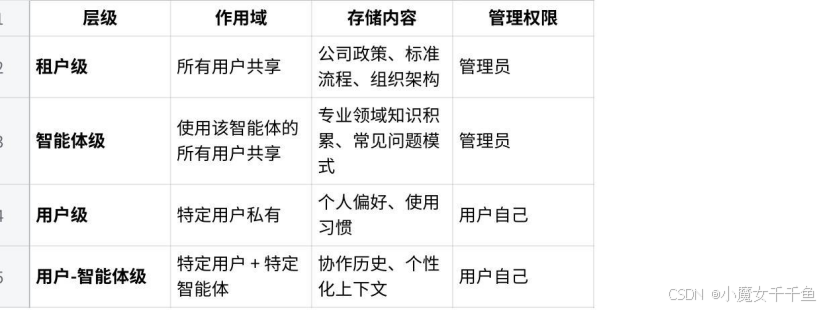
对于团队知识问答这个场景,租户级记忆最有价值:管理员可以手动添加一些高频共识信息,比如"公司全称是 XX 科技有限公司"“客服邮箱是 support@company.com”“当前版本是 v3.2"这类基础事实,这些信息不适合放在文档里(太零散),但智能体在回答时可能用到,放在租户级记忆里是最合适的位置。
用户-智能体级记忆对普通用户也有用。用多了之后,智能体会记住"这位用户喜欢简洁回答”“这位用户更关注操作步骤而不是背景说明”,自动调整回答风格,不需要每次对话都重新说明偏好。
记忆共享策略在记忆管理页面可以配置:
- 总是共享:智能体之间自动共享记忆,适合工作流高度协同的场景
- 每次询问我:共享前询问用户确认,适合对隐私有要求的场景
- 禁止共享:智能体之间完全独立,适合不同职能智能体严格隔离的场景
团队场景下我选的"总是共享",让同一团队内的不同智能体能互相感知用户的使用习惯,减少重复配置的麻烦。
智能体市场:现成智能体的安装体验
Nexent 智能体市场里有官方和社区发布的现成智能体,我装了一个"企业知识问答助手"试了试流程:
选定智能体 → 选择本地使用的模型(不继承原作者选择,需手动指定)→ 确认工具权限 → 安装完成
流程整体顺畅,但有一个容易踩的坑需要提前知道:从市场安装的智能体,原作者的知识库在你的环境里不存在,系统会自动改为基于你当前有权限的知识库进行检索。
这个行为本身合理,但安装完成时没有任何提示,你可能会发现智能体回答的内容和预期不一致,不知道原因。解决方案是安装完成后,手动进入智能体开发页面检查知识库绑定配置,确认绑定的是正确的本地知识库。
建议官方在安装完成时加一条提示:「该智能体包含知识库检索工具,已自动改为基于你当前知识库运行,如需达到预期效果请检查知识库绑定。」这一句话能省掉很多人的困惑。
一周使用后的总结
这套配置跑起来之后,在一个 8 人的小团队里实际用了一周,收到的反馈比我预期的好。
对新员工来说,最直接的变化是不需要再在群里问"这个流程文档在哪里"——直接问智能体,它会找到并附上来源,确认无误后按文档操作。第一周就有人反馈说"感觉上手快了很多,不用怕问错人"。入职第一天就能自主查到报销规则、请假流程、工具使用说明,不需要等前辈有空才来解答,这种自主性对新员工体验的提升是实质性的。
对老员工来说,回答重复问题的负担减轻了。原来每天总有几条"XX 在哪里"“XX 怎么操作"的消息需要回复,现在这类问题基本都去问智能体了。有人开玩笑说"终于可以专心干活了”。
还有一个意外的收获:智能体在回答时附的来源标注,反过来暴露了一些文档质量问题。某个流程文档里有一处说法和另一个文档矛盾,以前大家各看各的,没注意到;现在智能体同时检索到了两条信息,回答时说"两份文档对这个问题的描述存在差异,建议确认以哪份为准",这才发现原来有文档版本不一致的问题。知识库的建设过程,也是团队文档梳理的过程。
做得扎实的地方:
知识溯源机制是这个场景最核心的价值。每条回答附来源,团队成员可以验证信息是否是最新版,不会出现"AI 说的"这种无法追溯的回答。在团队协作场景里,信息可追溯是基本要求。尤其是涉及审批流程、合规要求这类重要内容,没有来源就不敢执行,有了来源才能放心操作。
权限体系设计合理且完整。四个角色、租户隔离、用户组控制、知识库三级权限,覆盖了从个人到团队到企业的不同规模场景,不是为了功能而功能,每个设计都有明确的适用场景。普通用户看到的界面很简洁,只有"开始问答",不会被复杂的配置界面吓到,这对非技术同事的推广很重要。
记忆的四层级设计很有前瞻性。租户级记忆存公司事实、智能体级存专业积累、用户级存个人偏好,层次清晰,管理员能清楚地知道哪条记忆在哪个层级、影响范围是什么,管理起来心里有数,比单一的"记忆功能"黑箱透明很多。
还需要改进的地方:
模型接入的错误提示太简单。"连接失败"四个字对排查问题没有任何帮助,加上 HTTP 状态码和具体请求路径,能解决 80% 的新用户困惑。
PDF 解析对排版复杂文档的处理质量不稳定,多栏布局和公式密集的文档,入库后总结质量明显下降。这对知识库的路由精度影响很大,团队里很多正式文档都是 PDF 格式,这块如果能改善,实用性会进一步提升。
智能体市场安装后缺少知识库绑定的引导提示,这个上面已经说过了。
整体来说,Nexent 做这个团队知识问答场景的核心链路已经通了:文档入库 → 向量化 → 智能体检索 → 答案溯源。权限体系足够完整,多用户场景下的数据隔离有保障。对于想快速搭一个内部知识助手、又不想写代码的团队,这是目前配置成本最低、能力相对完整的方案。如果你的团队也有类似需求,不妨先用一个下午把基础配置跑起来,实际用一周后再评估要不要深入投入。
GitHub:https://github.com/ModelEngine-Group/nexent
Gitcode:https://gitcode.com/ModelEngine/nexent
本地部署指南:https://modelengine-group.github.io/nexent/zh/quick-start/installation.html
官方文档:https://doc.nexent.tech

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐

 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)