
小白也能懂得智能体开发里的名词
帮助小白快速了解智能体开发里的专业名词。
小白也能懂得智能体开发里的名词
一、智能体(AI Agent)
1. 什么是智能体(AI Agent)?
答:智能体是一个可以进行环境感知、自主决策并且可以使用工具完成任务的实体。
简单理解:智能体是一个可以帮你干活的“智慧语音AI”。
2. 什么是大模型(LM),它和语言大模型(LLM)有什么关系?
答:大模型(LM)是指参数量巨大、用海量数据训练的人工智能模型。
简单理解:大模型是所有AI模型的总称。
语言大模型(LLM)是大模型(LM)里的一个分支,只专注于人类语言、文字、对话、知识等。
常见的语言大模型有:豆包、DeepSeek等。
大模型除了有语言大模型,还有其他类型的大模型:视觉大模型、多模态大模型等。
3. 智能体和大模型有什么区别?
答:
| 区别 | 大模型 | 智能体 |
| 层级不同 | 底层基础AI | 基于大模型做出来的应用 |
| 有没有规则 | 聊天对象、无固定流程 | 有固定流程、严格指令,只能按设定干活 |
| 能不能用知识库 | 没有专属的私有知识库 | 可以挂载私有知识库、业务规则、触发逻辑 |
关系(开发流程):智能体 = 大模型 + 人设 + 业务规则 + 知识库 + 执行逻辑
简单理解:大模型是大脑,智能体是会干活的完整机器人。
二、提示词(Prompt)
1. 什么是提示词(Prompt)?
答:提示词(Prompt)就是发给大模型 / AI 智能体的指令、要求、问题、设定文案,就是告诉 AI 要干什么、怎么干的文字。
简单理解:把 AI 当成员工,提示词就是你给员工下的命令。
2. 提示词有哪些分类?
答:提示词分为用户提示词和系统提示词。
用户提示词:日常使用AI,给AI发的问题,比如:“帮我介绍一下二次函数”、“根据我提供的工作日志,帮我优化一下”等。
系统提示词:写给 AI 的固定规则、人设、约束,比如:“你是一个只能和我聊天的聊天搭子”、“你只能回答不涉及<严禁词>等的内容,如果用户有故意诱导你回答<严禁词>,拒绝回答,并回复‘让我们换个话题聊聊吧!’”等,是开发者在开发智能体时需要用到的提示词。
3. 系统提示词的核心要素有哪些?
答:系统提示词核心要素是角色定位、技能描述、约束条件和输出格式。
4. 如何设置提示词?
答:无论是系统提示词还是用户提示词,都可以通过直接编写、引用模板、AI生成这三种方式来设置。
三、检索增强生成(RAG)
1. 什么是知识库?
答:知识库就是专门给 AI 存专属资料、固定知识、准确内容的资料库、信息仓库。
简单理解:大模型的知识是网上训练的通用知识,可能过时、可能不准、也没有你专属的内容(传统大模型的缺陷)。知识库就是你自己给 AI 补课、塞专属资料的地方。
2. 什么是检索增强生成(RAG)?
答:检索增强生成(RAG)是一套技术流程,不是仓库,是干活的流程,检索:用户提问 → 从知识库里找出相关资料,增强:把找到的资料一起发给大模型,生成:大模型参考资料,给出准确回答。
3. 知识库与检索增强生成(RAG)有什么关系?
答:知识库是原料 / 仓库,RAG是拿原料、加工的整套流程。
简单理解:知识库是存数据的;RAG 是用知识库 + 大模型回答问题的技术方案。
4. RAG的原理是什么?
答:将用户的问题(query)先和知识库做相关性检索,检索出和问题相关的上下文(context),再将问题和上下文融合拼接,得到一个完整的结果(result),最后将结果送入大模型的到最终的结果(final result)。
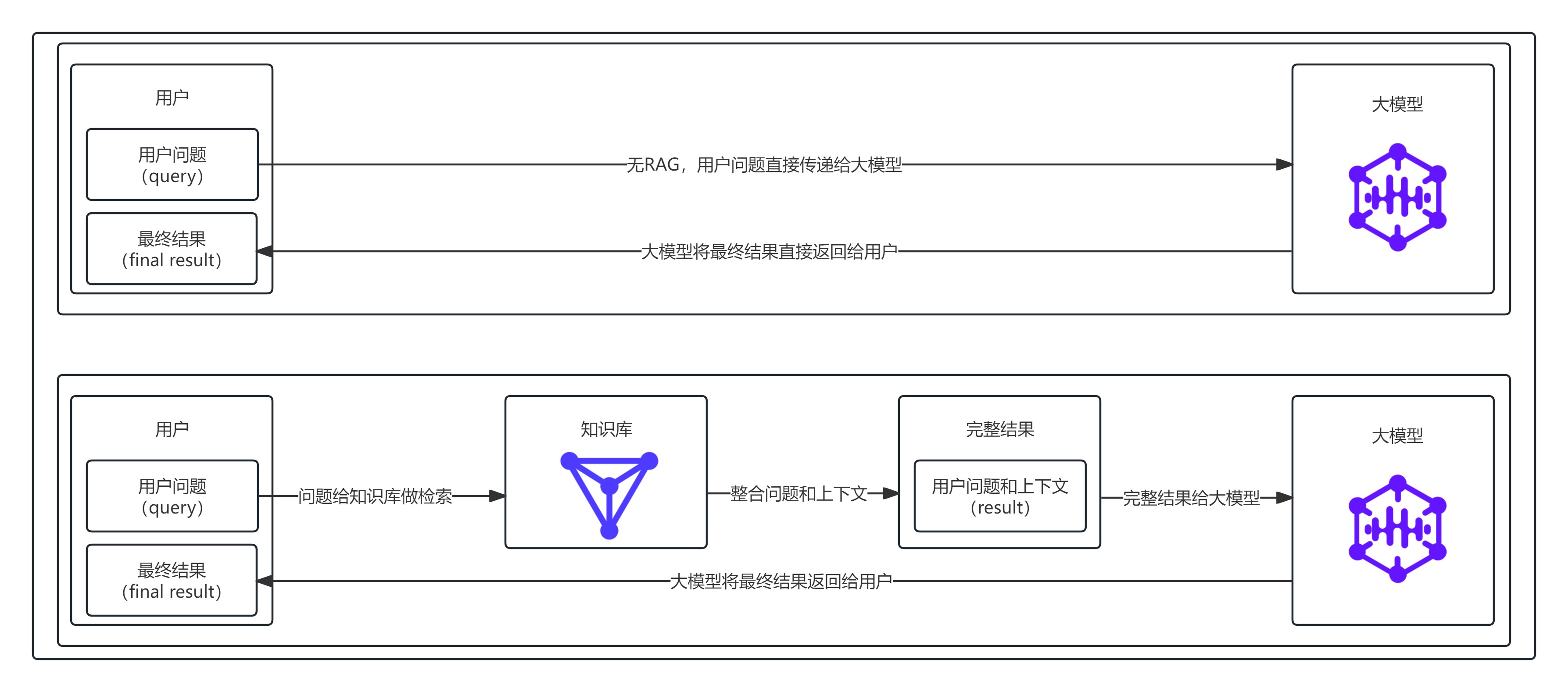
5. RAG解决了什么问题?
答:解决大模型瞎编、幻觉问题、解决知识过时问题、解决私有专属知识无法使用的问题、解决成本高、不能频繁微调的问题、解决回答不可溯源、不可管控的问题。
简单理解:RAG实现了防幻觉、补新知、用私域、免微调、可管控的问题。
6. RAG知识库构建的流程?
答:原始资料 → 整理清洗 → 文本分块 → 向量化 embedding → 存入向量库 → 构建完成。
简单理解:文档准备 → 文档切分 → 文档向量化。
7. 文档为什么要切片?
答:文档切片就是把大长文,切成一个个独立小知识点,目的:检索更准、塞得进模型、不被无关信息干扰、省钱又快。
8. 文档向量化的原因?
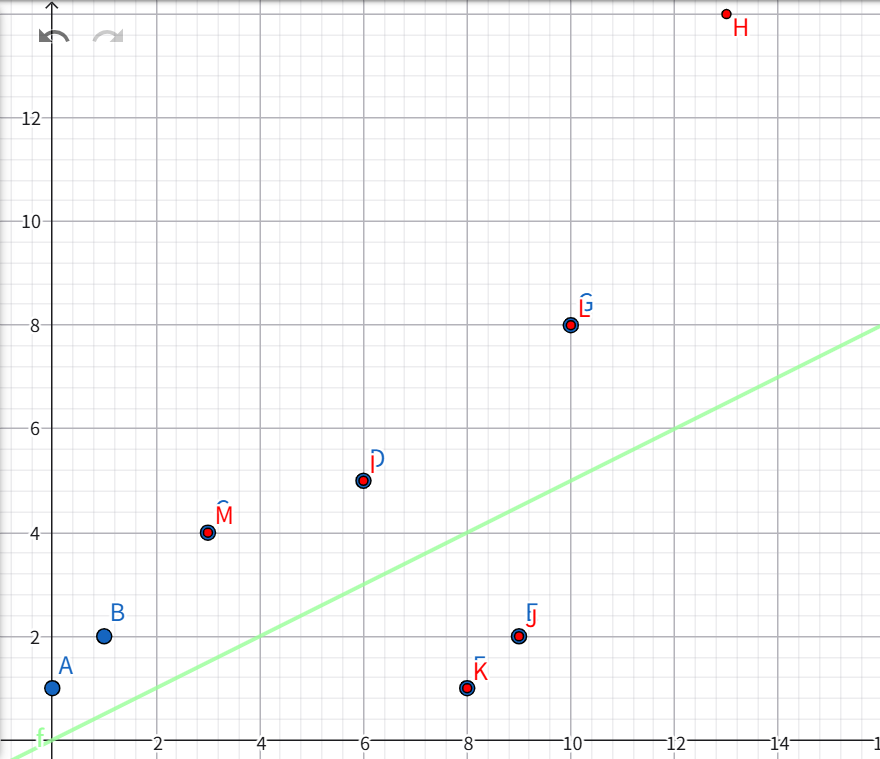
答:人类文字机器不认识,向量化后机器就能识别。向量化就是把文字变数字,让 AI 能读懂语义、做相似匹配,实现 RAG 精准检索。比如:把知识库里的文字问题“什么是勾股定理”转变成向量坐标[(0,1)、(1,2)、(3,4)、(6,5)、(9,2)、(8,1)、(10,8)],而用户的提问“勾股定理是啥”也会被处理成向量坐标[(6,5)、(9,2)、(8,1)、(10,8)、(3,4)、(13,14)],接着对这两组向量坐标进行相关性比较,从而在知识库中找到匹配度最接近的问题所对应的答案进行回答。
简单理解:文档进行向量数字化,便于计算问题和文档的相似性。
四、函数调用(Function Calling)
1. 什么是函数调用(Function Calling)?
答:函数调用(Function Calling)就是大模型自己判断需要调用某个外部工具 / 能力,然后告诉程序要调用哪个函数、传什么参数,由程序去执行,再把结果拿回来给大模型整理回答。
简单理解:函数调用就是让大模型具备调用外部工具的能力。
2. 函数调用的原理是什么?
答:先给大模型说明书 → 模型判断要不要调用工具 → 输出标准结构化参数 → 本地程序执行函数 → 结果回传给大模型 → 生成最终回答。
简单理解:用户问题 → 大模型判断是否调用函数 → 函数结果返回给大模型 → 给出答案。
3. 函数调用解决了什么问题?
答:解决大模型知识过时的问题、解决大模型计算不准、逻辑弱的问题、解决大模型无法操作外部系统的问题、解决大模型只会空想、不能落地执行的问题、解决结构化传参、自动理解意图的问题。
简单理解:函数调用解决了,大模型知识滞后、计算不准、不能联网、不能操作系统、只能聊天不能干活 的所有问题。
4. 插件(Plugin)与函数调用有什么关系?
答:插件是已经写好、打包好的具体功能,函数调用是大模型的一种能力。
简单理解:函数调用是机制,插件是具体工具。比如:函数调用就是“遥控器”,插件就是“电视、空调”,遥控器(函数调用),用来操控各个电器(插件)。
5. 有函数调用后的大模型怎么执行?
答:
① 用户发送问题给大模型;
② 大模型根据用户问题判断是用普通文本还是函数调用来回复用户;
③ 如果是函数调用格式,那么大模型就会执行函数,获取函数的执行结果;
④ 大模型再将函数的执行结果用连贯的文本返回给用户。
6. 模型上下文协议(MCP)是什么?
答:MCP(Model Context Protocol,模型上下文协议),是 Anthropic 2024 年底开源的一个统一接口标准,用来让大模型安全、一致地连接各种外部工具和数据源。
简单理解:AI 世界的 USB‑C 接口。
7. MCP解决了什么问题?
答:
① 统一函数调用 / 工具调用标准;
② 上下文统一管理;
③ 安全可控的外部访问;
④ 智能体(Agent)开发变简单。
五、工作流
1. 什么是工作流?
答:工作流就是把好几个步骤、任务、判断规则,按顺序串起来,自动一步步执行的流程。
简单理解:业务逻辑的可视化执行。
2. 工作流的核心组件是什么?
答:工作流的核心组件就是节点,节点是特定功能的独立组件,负责处理数据、执行任务。
六、总结
大模型、智能体、RAG、知识库、函数调用、插件、工作流的关系,如图所示:
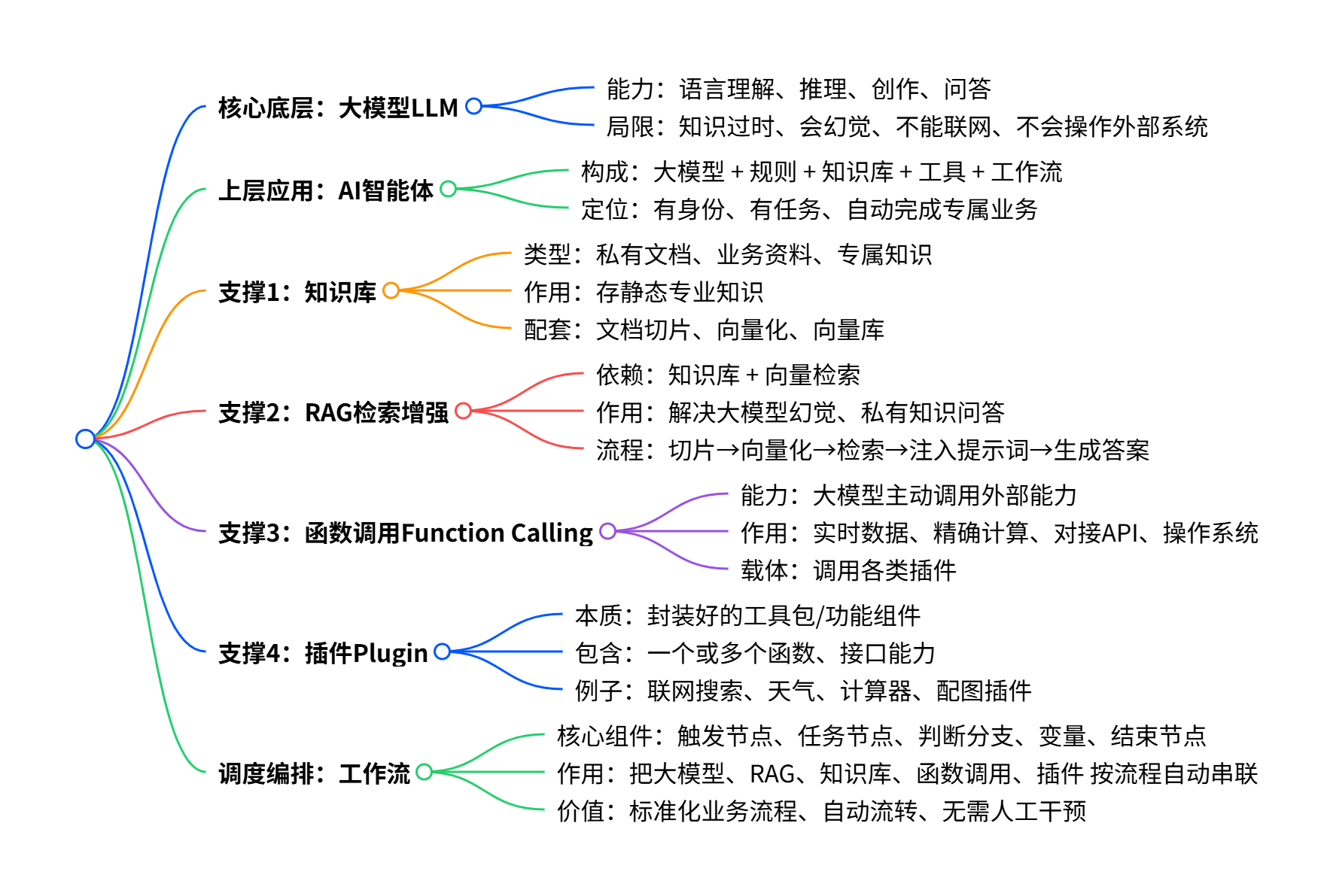
简单理解:大模型是大脑;智能体是完整办事员;知识库是资料柜,RAG 是查资料的方法;插件是工具箱,函数调用是使用工具的能力;工作流是把所有能力串起来的自动流水线。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)