
多智能体三年反思:为什么 Agent 越多,系统反而越乱?

一、真实困境:三个 Agent,三套答案
先看一个很常见的场景。
你想做一个新功能,于是开了三个 AI agent:
-
• 一个产品经理 agent,负责理解需求。
-
• 一个架构师 agent,负责设计方案。
-
• 一个开发 agent,负责写代码。
听起来很合理。
像一个迷你软件公司。
但实际跑起来,经常是另一种画面:
产品经理说用户要 A。
架构师基于自己的理解画了 B。
开发 agent 没等两边对齐,直接写了 C。
最后你得到的不是一个功能,而是一堆彼此不兼容的中间产物。

这不是段子。
2024 到 2026 年,几乎所有深入做过 multi-agent 的团队,都踩过类似的坑。
多智能体最反直觉的地方就在这里:
Agent 越多,不一定越智能;很多时候,只是把混乱并行化了。
行业共识正在转向一件事:
“让更多 AI 参与”正在让位于“让更多 AI 不互相污染”。
这篇文章不做概念罗列。
我们直接从行业踩坑出发,讲清楚三个问题:
-
• 当前主流多智能体到底有哪些协作模式?
-
• 为什么有些模式能落地,有些模式只适合 Demo?
-
• 如果你要做真实系统,应该怎么选型?
二、行业正在集体转向同一件事:从自由发挥到受控协作
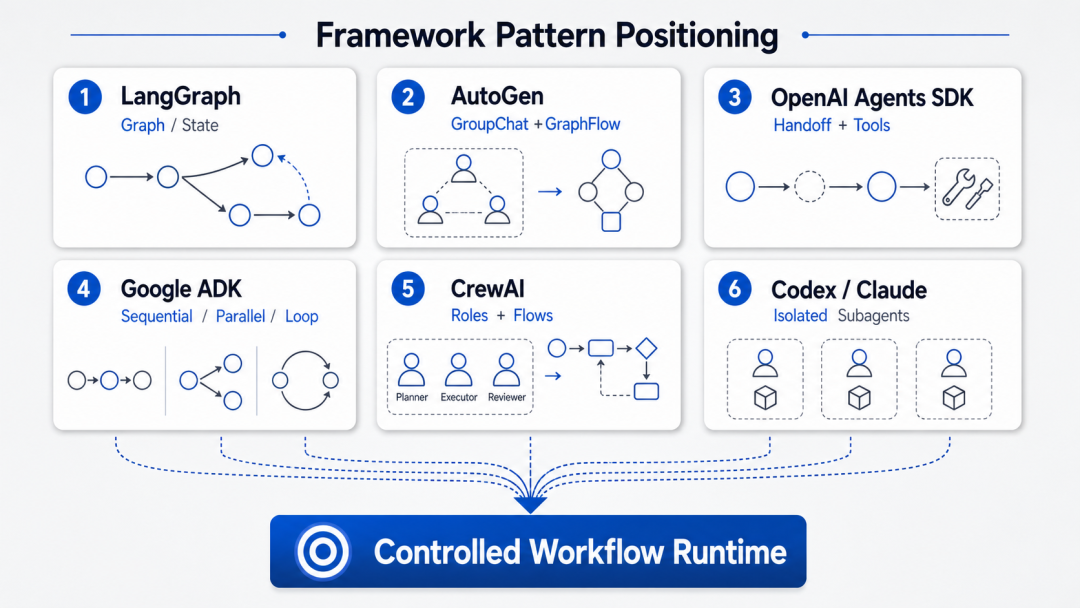
先看几个头部框架的方向变化。
| 框架 | 早期重点 | 当前重点 |
|---|---|---|
| LangGraph | 状态图编排 | Supervisor、子 agent 作为工具、handoff |
| AutoGen | GroupChat 群聊 | GraphFlow、Swarm、Magentic-One |
| OpenAI Agents SDK | Agent 定义 | Handoff 与 agents-as-tools 的清晰二分 |
| Google ADK | 单 agent 构建 | SequentialAgent、ParallelAgent、LoopAgent |
| CrewAI | 角色团队 | Flows 事件驱动、Delegation 工具化 |
| Codex / Claude Code | 单线程 coding assistant | 隔离上下文的 subagent worker |
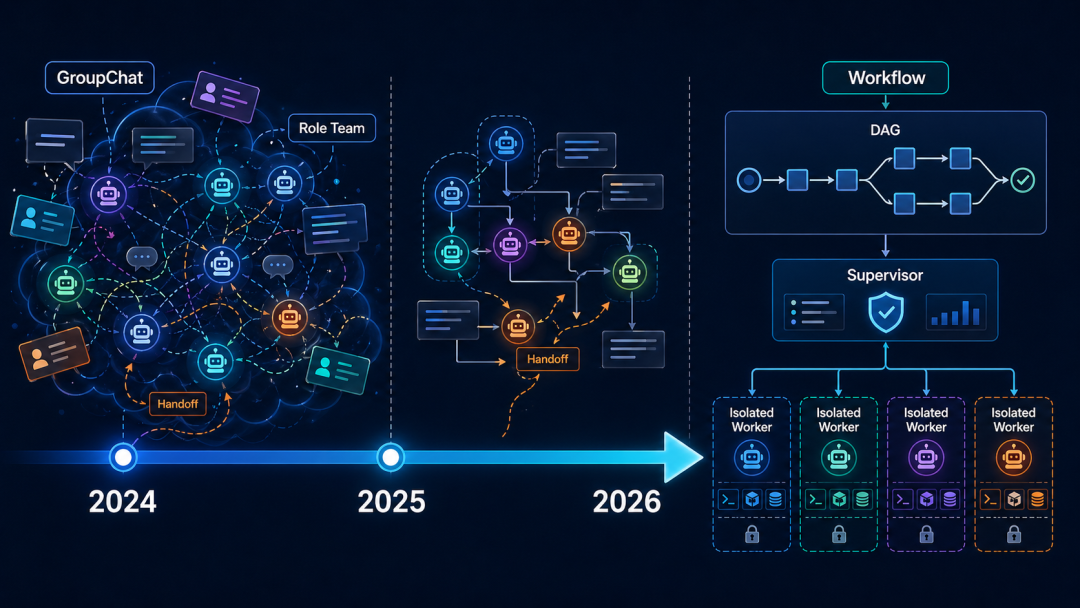
这些框架的接口不同,术语不同,生态也不同。
但方向非常一致:
从“让 agent 自由发挥”,走向“让 agent 在受控流程里发挥”。
这不是保守。
这是生产系统用失败换来的经验。
多一个 agent,就多一份上下文。
多一份上下文,就多一份污染风险。
多一次自由交接,就多一次丢失状态的机会。
如果没有控制,5 个 agent 的复杂度不是 5 倍,而更像 25 倍。
因为每个 agent 都可能和其他 agent 产生依赖、冲突、重复和误解。
多智能体不是“人多力量大”,而是“接口不清,人越多越乱”。
三、别再数 Agent 了:真正该问的是这六个问题
很多人评估多智能体系统,第一句话是:
你们用了几个 agent?
这个问题没问到点子上。
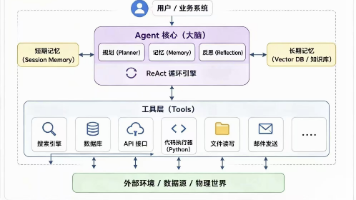
生产级多智能体真正要回答的是六个问题。
| 层次 | 问题 | 坏的设计 | 好的设计 |
|---|---|---|---|
| 控制层 | 谁决定下一步? | 所有 agent 都能随意发言和接力 | 有明确 supervisor、router 或 DAG runtime |
| 执行层 | 任务怎么流动? | 靠模型临场发挥 | 顺序、并行、DAG、循环显式定义 |
| 通信层 | agent 之间怎么传信息? | 所有内容塞进共享上下文 | 结构化 artifact,按需传递 |
| 状态层 | 信息放哪里? | 全部放聊天历史 | session state、memory、文件、数据库 |
| 质量层 | 结果好坏怎么判断? | 另一个 agent 说“不错” | 测试、lint、eval、人工审批 |
| 治理层 | 如何防止失控? | 没有边界 | tool policy、sandbox、timeout、checkpoint、trace |

这六个问题,比 agent 数量重要一百倍。
一个系统可以只有两个 agent:planner 和 executor。
但只要它把控制权、状态、验证讲清楚,它就可能是生产级系统。
另一个系统可以开十个 agent 开会。
但如果控制权不清、状态乱传、没有验证,它只是十个昂贵的聊天窗口。
成熟的多智能体系统,首先不是智能问题,而是系统设计问题。
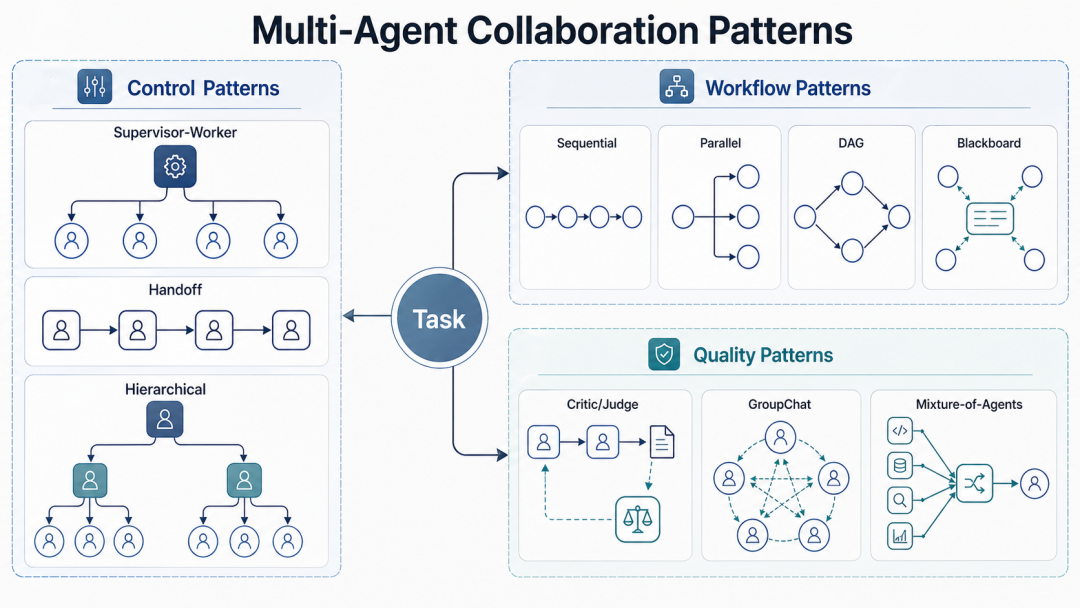
四、十种协作模式:先掌握三种,再警惕一种
先看全景图。
下面是当前业内主流的多智能体协作模式。
| # | 模式 | 一句话 | 适合场景 |
|---|---|---|---|
| 1 | Supervisor-Worker | 中心调度,专业 worker 执行 | 代码审查、金融研究、客服 |
| 2 | Sequential Pipeline | 固定顺序流水线 | 文档生成、合规审查、软件交付 |
| 3 | Parallel Fan-out/Fan-in | 并行分发独立子任务再汇总 | 多维审查、资料调研、方案生成 |
| 4 | Hierarchical | 多层管理,层层拆解 | 大型项目、多部门流程 |
| 5 | DAG / Graph Workflow | 有依赖的任务图,自动编排 | 复杂工程、审批流、数据管道 |
| 6 | Handoff / Swarm | 控制权在 agent 之间接力转移 | 客服分流、专家转接 |
| 7 | GroupChat / Mesh | 多 agent 共享上下文轮流发言 | 头脑风暴、评审会、多专家讨论 |
| 8 | Blackboard / Shared Memory | 多个 agent 读写共享状态 | 长期项目、知识沉淀 |
| 9 | Reflection / Critic / Judge | 生成、评审、修复、验收 | 代码生成、事实核查、架构评估 |
| 10 | Mixture-of-Agents | 多模型或多 agent 并行回答后聚合 | 多视角交叉验证、创意生成 |
这么多模式,从哪开始?
我的建议是:
先掌握最常落地的三种:
-
• Supervisor-Worker。
-
• Parallel Fan-out/Fan-in。
-
• DAG / Graph Workflow。
再重点警惕最容易误用的一种:
- • 自由 GroupChat。
4.1 优先掌握一:Supervisor-Worker,工业系统的底座
这是当前最稳、最常落地的模式。
结构很简单:
User
↓
Supervisor
├─ Worker A
├─ Worker B
└─ Worker C
↓
Final synthesis
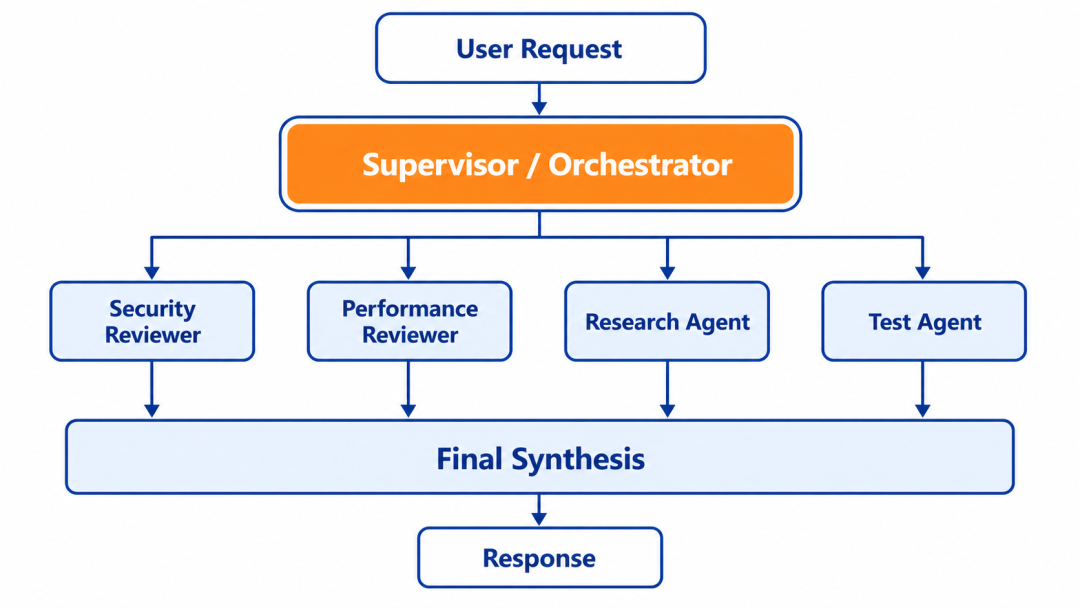
一个中心 agent 负责拆任务。
多个 worker agent 做具体工作。
worker 之间不直接对话,结果回传给 supervisor 合成。
它的优势是控制清楚。
错误主要从 supervisor 往下传播,不会在 worker 之间横向扩散。
你只要重点盯住 supervisor 的任务拆解质量,就能控制大部分风险。
适合场景:
- 代码审查。
- 金融研究。
- 客服分流。
- 企业流程。
- 复杂报告生产。
最大风险:
supervisor 是单点。
它拆错任务,整个系统都会歪。
所以不要让 supervisor 输出散文式计划。
让它输出结构化计划:
{
"tasks": [
{
"id": "review_auth_security",
"agent": "security_reviewer",
"scope": "auth模块",
"permission": "read_only"
},
{
"id": "review_db_perf",
"agent": "performance_reviewer",
"scope": "数据库查询",
"permission": "read_only"
}
],
"synthesis_rule": "按风险等级排序,合并前3项"
}
输出越结构化,系统越稳定。
Supervisor-Worker 的本质不是“领导和员工”,而是“全局一致性和局部专业化”。
4.2 优先掌握二:Parallel Fan-out/Fan-in,性价比最高的并行模式
这个模式用并行 worker 扩大观察面。
不是让一个 agent 从头查到尾。
而是把研究、审查、分析任务拆成多个独立维度,同时交给多个 agent。
最后由 aggregator 汇总。
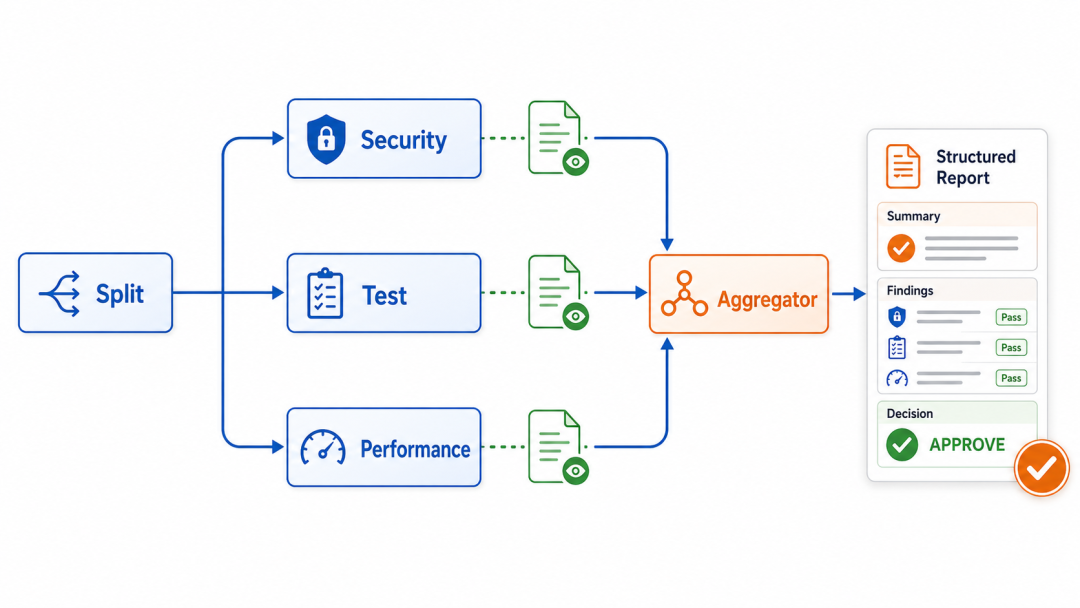
结构如下:
┌─ Security Reviewer
Task → Split ─ Test Reviewer
└─ Performance Reviewer
↓
Aggregator
它为什么性价比高?
因为大量子任务是只读的。
读代码、读资料、查文档、看测试、分析风险,这些天然可以并行。
只读任务没有写入冲突。
所以并行收益大,风险小。
适合场景:
- 多维代码审查。
- 多资料源研究。
- 多方案生成。
- PR review。
- 多模型交叉验证。
核心原则:
-
并行 worker 主要负责读和分析。
-
每个 worker 输出结构化 artifact。
-
汇总 agent 做合成决策。
-
写入操作交给单一线程。
Codex subagents 就很适合这类任务。
它可以让多个子 agent 同时探索代码库、做审查、找风险,最后由主线程合成。
但并行写代码要谨慎。
两个 agent 同时改同一个模块,不是效率提升,而是冲突放大。
并行最适合扩大观察面,不适合抢同一个方向盘。
4.3 优先掌握三:DAG / Graph Workflow,复杂任务的骨架
当任务依赖关系不再是简单的“做完 A 再做 B”,就需要 DAG。
DAG 是 Directed Acyclic Graph。
可以理解为有方向、无循环的任务图。
例如:
Requirement
├─ Codebase Exploration
├─ Risk Analysis
└─ Interface Design
↓
Implementation
↓
Tests
↓
Review
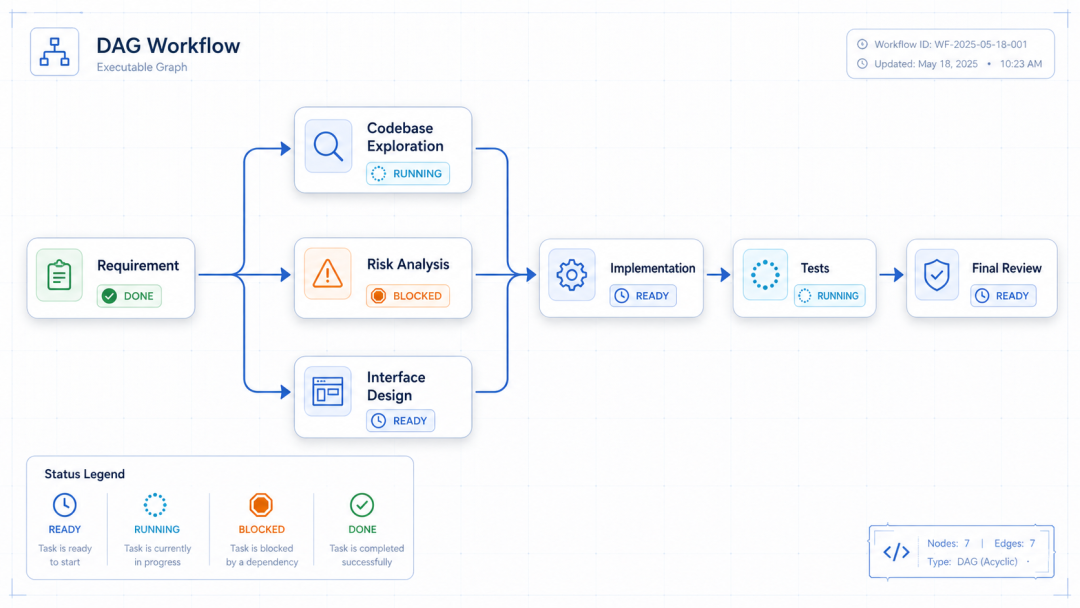
B 和 C 可以同时做。
D 必须等 B 和 C 都完成。
这类关系靠 prompt 临场判断,很容易出错。
DAG 的价值,不是引入复杂性。
而是把已经存在的复杂关系显性化。
谁在用?
-
LangGraph 核心就是 graph + state。
-
AutoGen 有 GraphFlow。
-
Google ADK 把顺序、并行、循环做成 workflow primitive。
-
Microsoft Agent Framework 也提供 workflow orchestration。
最大陷阱:
不要以为画个流程图就够了。
DAG 真正要跑起来,还需要:
-
• 状态 schema。
-
• 节点验收标准。
-
• 失败重试。
-
• checkpoint。
-
• trace。
没有这些,它只是一张好看的图。
DAG 的价值不是画流程,而是让流程可执行、可恢复、可审计。
⚠️ 4.4 最容易翻车:自由 GroupChat
GroupChat 是 Demo 里最吸引人的模式。
一个 AI 当 PM。
一个 AI 当架构师。
一个 AI 当开发。
它们共享一个聊天窗口,轮流发言,互相点评。
看起来像团队。
但在生产里,它最容易翻车。
原因很直接。
第一,成本爆炸。
每轮群聊都要把大量上下文传给多个 agent。
第二,废话循环。
agent 很容易互相复读、礼貌补充、继续展开。
第三,缺乏执行人。
讨论完了,谁负责写?谁负责验收?谁负责承担冲突?
第四,状态污染。
所有讨论记录塞进同一个上下文,越聊越乱。
工程落地怎么办?
GroupChat 外面必须套结构:
Supervisor 控制流程
+ Termination condition 控制停止
+ Judge 做质量把关
+ Synthesizer 做最终合成

群聊适合产生观点。不适合单独承担交付。
Demo 喜欢群聊,因为它好看;生产远离群聊,因为它难控。
五、热门框架到底怎么选:不要选框架,先选模式组合
很多文章会问:
LangGraph 和 CrewAI 选哪个?
AutoGen 和 OpenAI Agents SDK 选哪个?
这个问题本身就不完整。
真正应该问的是:
我的场景需要什么协作模式组合?
如果你做代码工程
推荐组合:
Supervisor
→ DAG
→ Parallel Review
→ Single Writer
→ Tests
→ Fix Loop
更具体一点:
Planner
→ 代码拆分
→ 并行审查(安全 / 性能 / 架构 / 测试)
→ 单写入者实现
→ 测试
→ 修复循环
→ 最终审核
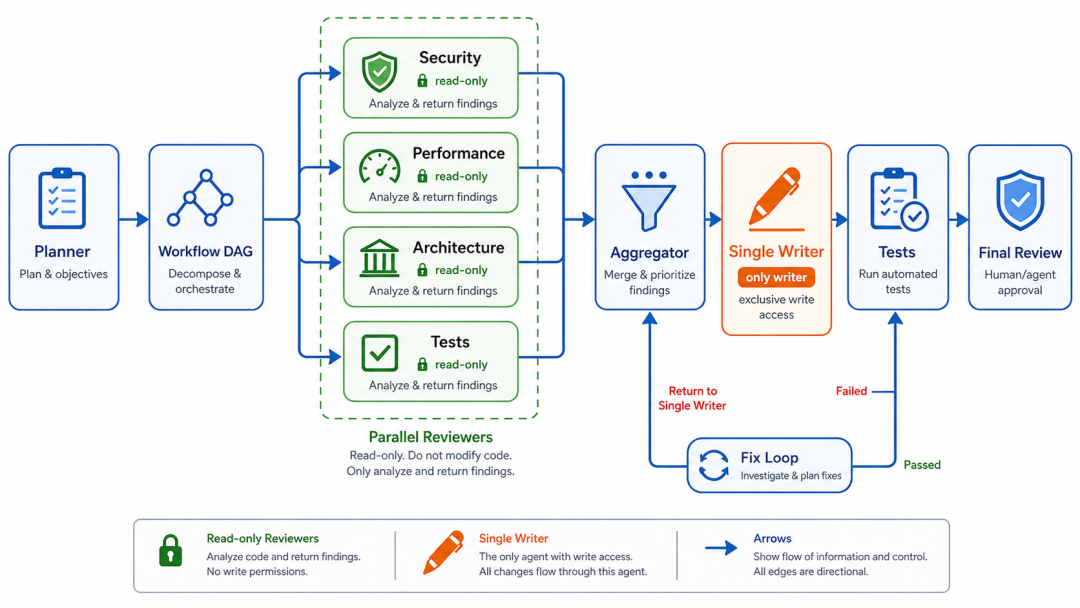
关键原则:
-
• 并行 agent 主要负责读。
-
• 写入由单 agent 或按文件分区的 agent 完成。
-
• 测试结果优先于 LLM 自评。
推荐框架:
-
• LangGraph。
-
• Codex subagents。
-
• Claude Code subagents。
如果你做客服 / 业务路由
推荐组合:
Triage
→ Router
→ Specialist Agent
→ Escalation
→ Human
关键原则:
-
• 设置最多转交次数。
-
• 高风险自动转人工。
-
• 保持统一用户上下文。
-
• 不同专家 agent 使用不同工具权限。
推荐框架:
-
• OpenAI Agents SDK。
-
• AutoGen Swarm。
-
• LangGraph handoff。
如果你做研究报告 / 内容生产
推荐组合:
Parallel Research
→ Outline
→ Writing
→ Fact Check
→ Editing
关键原则:
-
• 调研用并行。
-
• 写作用顺序。
-
• 事实核查独立于写作。
-
• 每个来源带引用。
推荐框架:
-
• CrewAI。
-
• Google ADK。
-
• LlamaIndex。
-
• LangGraph。
如果你做 RAG / 知识库
RAG 是 Retrieval-Augmented Generation。
意思是先检索资料,再让模型生成答案。
推荐组合:
User Question
→ Router
→ 多路检索(文档 / 数据库 / 网页)
→ Synthesis
→ Citation Check
关键原则:
-
• 各检索路径独立并行。
-
• 合成时保证引用可追溯。
-
• 低置信度答案要标注。
-
• 不要把未验证内容写入长期记忆。
推荐框架:
-
• LlamaIndex。
-
• LangGraph。
-
• Agno。
如果你做企业流程自动化
推荐组合:
Request
→ Approval DAG
→ Department Agents
→ Human Gate
→ Execution
→ Audit Log
关键原则:
-
• 每一步都要可审计。
-
• 高风险节点加人工审批。
-
• 状态持久化,支持失败恢复。
-
• 工具权限按角色限制。
推荐框架:
-
• LangGraph。
-
• Microsoft Agent Framework。
-
• Google ADK。
六、通用落地架构:一张图和一段伪代码
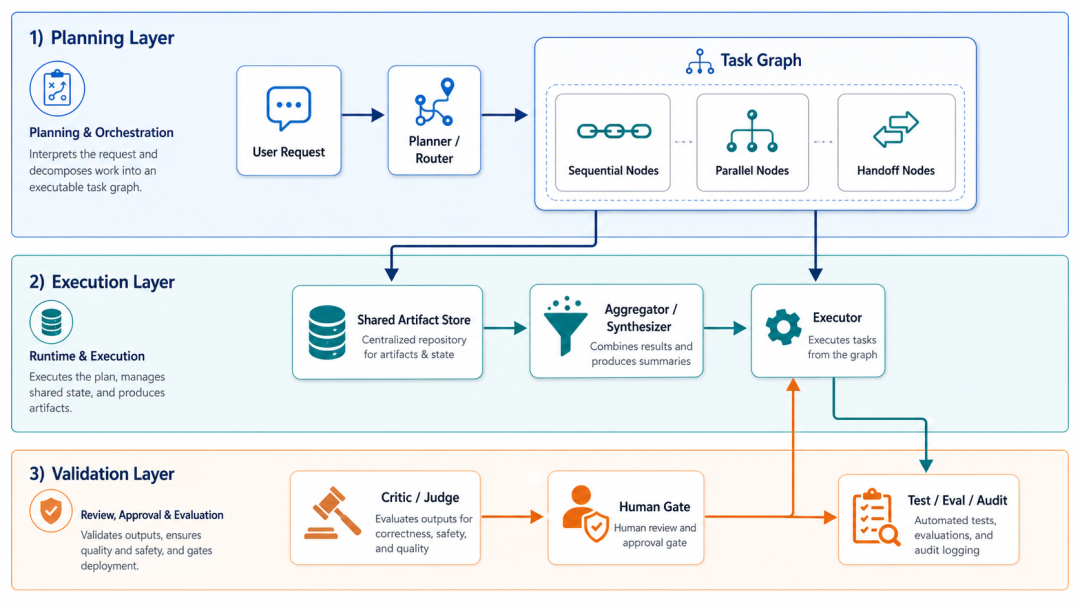
如果你还没想好用哪个框架,可以先从这个通用架构开始。
用户请求
↓
规划器 / 路由器
↓
任务图(DAG)
├─ 顺序节点
├─ 并行节点
└─ 转交节点
↓
共享状态存储(artifact / memory)
↓
汇总器 / 合成器
↓
审查器 / 评判器
↓
人工门禁(高风险时)
↓
执行器
↓
测试 / 评估 / 审计
七、五个常见误区,自查一下
误区一:agent 越多越高级
不一定。
简单任务,一个 agent 配工具就够了。
加 agent 就是在增加通信成本和状态管理难度。
误区二:所有 agent 应该共享同一个上下文
不要。
共享上下文等于让所有 agent 都被噪声淹没。
更好的方式是共享结构化 artifact 或 shared state。
误区三:Swarm 是最高级形态
Swarm 不是最高级形态。
它是一种路由和接力方式。
工程执行更常用 supervisor、DAG 和 workflow。
误区四:critic 可以替代测试
不能。
Critic 能发现风格问题、逻辑漏洞和明显风险。
但代码要跑测试。
数据要校验。
金融假设要核对来源。
企业流程要审计。
误区五:多智能体 = 自动化团队
这个说法只对一半。
它像团队,但更应该像系统。
团队可以靠默契补位。
系统必须靠接口、状态、权限和验证运行。

八、最终判断:多智能体的成熟标志不是 agent 数量
回顾 2024 到 2026 年的行业变化,五个趋势很明显。
第一,从 prompt swarm 转向 workflow runtime。
LangGraph、AutoGen GraphFlow、Google ADK 都在把多 agent 做成可控执行图。
第二,从共享大上下文转向隔离上下文 + artifact 传递。
Claude Code、Codex、LangChain subagents 都强调隔离和摘要传递。
第三,从自由讨论转向 supervisor / handoff / tools 三分法。
manager 调工具、agent 接管、代码显式编排,是三种生产级选择。
第四,从“更多 agent”转向“更强治理”。
timeout、sandbox、approval、checkpoint、trace,比 agent 数量更重要。
第五,从“看起来智能”转向“可审计、可恢复、可测试”。
生产系统不关心你的 agent 会不会表演团队协作。
它只关心任务能不能稳定交付。
最后收束成一句话:
多智能体的成熟,不在于 agent 数量增加,而在于控制权、状态和验证机制变清楚。
如果你只记住一件事:
先管好控制权和状态,再考虑加 agent。
不加控制的 agent,不是智能体团队。
是昂贵的混乱。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐

 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)